RabbitMQ 驱动下的工厂模式:AI 对话式向量化架构的“消息派单”实战
引言:在 campusai 智慧园区项目中,我们是如何用工厂模式+消息队列,把“后台公告增删改”和“AI向量化”这两个看似不相关的东西,硬生生粘在一起的全过程。这不是什么高大上的理论,而是实打实的架构踩坑实录,重点剖析工厂模式如何在消息驱动架构中救场,实现业务与AI服务的解耦。
一、问题与场景:当后台操作遇上AI向量化
想象一下这个场景:管理员在若依后台对公告表(notice)一顿猛如虎的CRUD操作——新增、修改、删除。但问题来了,这些操作光存进MySQL可不够,还得让AI“看懂”这些内容,以便后续智能对话。
因为这个项目的后台管理主要是对数据库做一个基本的管理,如果说还想集成写入AI项目库的管理,那我们就要需要在后台管理集成AI相关的东西,这样就使它更加的复杂,没有起到松耦合的效果。而且我们在若一管理系统中,我们的back end的版本是1.8,如果需要集成AI,那需要将版本进行修改。因为现在企业中很多后台项目的版本都是比较低的那种,整体的没有修改,可能会带成更多的麻烦。所以我们可以通过其他方法来解决。
于是我们设计了一套标准:每次操作都发一条RabbitMQ消息,格式长这样:
{
"ids": ["123"],
"operation": "ADD|UPDATE|DELETE",
"type": "CAMPUSAI_NOTICE|CAMPUSAI_MATERIALS"
}核心挑战:消息是发出去了,但AI服务端怎么处理?
-
公告(notice)和资料(materials)的处理逻辑能一样吗?显然不能!
-
今天有公告,明天来个“失物招领”业务怎么办?总不能每次都改核心代码吧?
目标:设计一套“懒人架构”,让新增业务类型时,核心消息处理链路不用改变,只需加个新实现类就行。
SpringAI读取向量数据及知识库的更新如图所示:

公告栏逻辑说明:
- 管理员发公告:若依(后台)生成notice表给Mysql(包括controller,用一个id写入数据库),Mysql数据库表中的数据向量化为AI能识别的数据(知识库,用redis实现向量库)(引入rabbitMQ传递id进行知识库的写入)
- 修改后台生成的Controller,使若依后台在完成MySQL数据操作后,同步发送消息到RabbitMQ。消息中包含业务ID、操作类型和业务类型,由消息消费者(AI应用frontend)根据ID从MySQL查询对应数据,并将数据向量化后存入知识库(向量库vector)。向量库返回的文档ID与业务ID共同记录在中间表,用于后续精准删除操作。
- 管理员删除公告:若依后台删除Mysql表中的相关数据,将id号利用MQ传给消费者AI应用frontend,由frontend用id查找Mysql中的document_ids表(source_id & document_id:notice表的id号 & 向量库中的id号),获取到向量库中的对应id号,frontend再删除向量库中的对应数据。
二、架构全景
先来看完整的数据流转链
若依后台 → MySQL业务库 → RabbitMQ消息 → 向量化服务 → Redis向量库 → Spring AI对话
↑ ↑ ↑ ↑ ↑ ↑
CRUD操作 数据持久化 消息驱动 “工厂派单” 向量存储 智能检索各角色职责:
-
NoticeController:后台业务层控制器,负责接收前端请求并执行业务逻辑
-
RabbitSendService:消息发送服务,实现业务操作与向量化处理的异步解耦
-
CampusaiMessageReceiver:AI端监听RabbitMQ队列,解析消息内容并动态路由至对应的向量化服务
-
VectorServiceFactory:AI端维护type与IVectorService实现的映射关系,提供运行时服务实例获取能力
-
NoticeVectorServiceImpl:完成公告数据的向量化存储、更新与删除
-
DocumentIds中间表:维护业务数据主键与向量库文档ID的对应关系
场景:管理员在后台新增一条公告
第1步:业务数据入库(MySQL)
表操作:notice表新增记录
INSERT INTO notice (id, title, content, create_time)
VALUES ('1001', '作息与安全', '宿舍楼门禁时间...', NOW());触发代码:NoticeController.addSave()
int rows = noticeService.insertNotice(notice); // 插入MySQL
rabbitSendService.sendAddNotice(notice.getId()); // 发送消息第2步:消息驱动(RabbitMQ)
消息内容:
{
"ids": "1001",
"operation": 1,
"type": "CAMPUSAI_NOTICE"
}消息流转:
-
生产者:
RabbitSendService→ 发送到CAMPUSAI_NOTICE队列 -
路由:默认交换机 + 路由键匹配队列名
-
消费者:
CampusaiMessageReceiver监听队列并接收消息
第3步:向量化处理(核心业务)
INSERT INTO document_ids (source_id, document_id, type)
VALUES ('1001', 'vec_123456', 'CAMPUSAI_NOTICE');消费者处理:
// 1. 解析消息
MessageDto messageDto = JSON.parseObject(message, MessageDto.class);
// 2. 工厂模式选择服务
IVectorService vectorService = vectorServiceFactory.of("CAMPUSAI_NOTICE");
// 3. 执行新增向量化
vectorService.addDocument(messageDto);具体向量化操作:
-
查询业务数据:
Notice notice = noticeService.getById("1001")2.创建向量文档:
Document doc = new Document(notice.getContent(),
Map.of("id", "1001", "title", "作息与安全"));3.向量库:
store.add(List.of(doc)) 4.记录映射关系:document_ids表新增记录
INSERT INTO document_ids (source_id, document_id, type)
VALUES ('1001', 'vec_123456', 'CAMPUSAI_NOTICE');INSERT INTO document_ids (source_id, document_id, type) VALUES ('1001', 'vec_123456', 'CAMPUSAI_NOTICE');
第4步:AI对话检索
用户提问:"宿舍门禁时间是几点?"
-
Spring AI 查询向量库:检索与"门禁"相关的向量
-
返回匹配的公告内容
-
AI 生成回复:"宿舍楼门禁时间为周日至周四 23:00..."
三、表间流转关系
-
核心表结构
| 表名 | 用途 | 关键字段 |
| notice | 业务数据表 | id, title, content, create_time |
| document_ids | 映射关系表 | source_id, document_id, type |
| Redis向量库 | 向量数据存储 | 向量数据 + 元数据 |
-
表间数据流转
notice表 → document_ids表 → Redis向量库
↑ ↑ ↑
业务ID 映射关系 向量化数据数据关联:
-
notice.id=document_ids.source_id -
document_ids.document_id= Redis向量库中的文档ID -
通过
type="CAMPUSAI_NOTICE"区分业务类型
四、RabbitMQ的核心作用
1.异步解耦
问题:业务操作与向量化强耦合
// 不优雅的设计
int rows = noticeService.insertNotice(notice);
vectorService.addDocument(notice); // 同步向量化,阻塞业务RabbitMQ解决方案:
int rows = noticeService.insertNotice(notice);
rabbitSendService.sendAddNotice(notice.getId()); // 异步消息优势:
-
业务操作不等待向量化完成
-
向量化服务可独立部署和扩展
-
支持失败重试机制
2.消息缓冲
场景:短时间内大量公告更新
-
RabbitMQ 作为消息缓冲区,平滑处理峰值流量
-
向量化服务按自身处理能力消费消息
-
避免系统过载
3.可靠传递
配置保障:
// ConfirmCallback:确认消息到达交换机
rabbitTemplate.setConfirmCallback((correlationData, ack, cause) -> {
if (!ack) {
log.info("消息发送失败"); // 可触发重试
}
});
// ReturnCallback:确认消息到达队列
rabbitTemplate.setReturnCallback((message, replyCode, replyText, exchange, routingKey) -> {
log.info("消息丢失"); // 可记录异常
});4.灵活路由
多业务支持:
-
公告栏:
CAMPUSAI_NOTICE队列 -
资料管理:
CAMPUSAI_MATERIALS队列 -
工厂模式根据消息类型选择对应处理服务
五、不同操作的完整流程
新增操作
MySQL: notice表新增 → RabbitMQ消息 → 向量库新增 → 中间表记录修改操作
MySQL: notice表更新 → RabbitMQ消息 → 向量库删除旧数据 → 向量库新增新数据 → 中间表更新删除操作
MySQL: notice表删除 → RabbitMQ消息 → 中间表查询document_id → 向量库删除 → 中间表清理六、设计要点:工厂模式的“降维打击”
抽象接口:
为了让不同业务的实现类能统一调度,先定个标准接口:
public interface IVectorService {
void addDocument(MessageDto messageDto); // 新增向量
void updateDocument(MessageDto messageDto); // 修改向量
void deleteDocument(MessageDto messageDto); // 删除向量
}这就好比规定:不管你是修公告的还是修资料的,都得会“增、改、删”这三板斧。
工厂模式:AI端的“智能调度中心”
核心来了!VectorServiceFactory就是个“调度中心”,启动时就把所有实现类登记在册:
@Component
public class VectorServiceFactory {
@Autowired private MaterialsVectorServiceImpl materialsVectorService; // 资料
@Autowired private NoticeVectorServiceImpl noticeVectorService; // 公告
public IVectorService of(String messageType) {
switch(messageType) {
case "CAMPUSAI_MATERIALS": return materialsVectorService; // 派资料
case "CAMPUSAI_NOTICE": return noticeVectorService; // 派公告
default: return null; // 不认识这业务,拒单!
}
}
}精髓:前台接待(CampusaiMessageReceiver)不用管具体业务逻辑,只管把订单类型(messageType)扔给调度中心,调度中心自动派对应的方法。
3.3 消息接收:前台接待的“标准化操作”
CampusaiMessageReceiver的活儿特别简单,就是根据类型调用对应工厂的实例:
@RabbitListener(queuesToDeclare = {
@Queue("CAMPUSAI_NOTICE"),
@Queue("CAMPUSAI_MATERIALS")})
public void processMessage(String message) {
MessageDto dto = JSON.parseObject(message, MessageDto.class); // 拆包
IVectorService service = vectorServiceFactory.of(dto.getType()); // 派单
// 看操作类型
switch(dto.getOperation()) {
case 1: service.addDocument(dto); break; // 新增
case 2: service.updateDocument(dto); break; // 修改
case 3: service.deleteDocument(dto); break; // 删除
}
}设计哲学:前台接待的职责要单一,它不需要懂公告和资料的区别,它只需要会“拆包”和“派单”。
七、关键技术:公告师傅的“三板斧”
以公告向量化为例,看看 NoticeVectorServiceImpl怎么干活:
4.1 新增向量:从MySQL到Redis向量库的过程
public void addDocument(MessageDto messageDto) {
// 1. 查MySQL:根据业务ID找出公告内容
Notice notice = noticeService.getById(ids);
// 2. 造“向量原料”:文本+元数据
Document doc = new Document(notice.getContent(),
Map.of("id", notice.getId(), "title", notice.getTitle()));
// 3. 存入Redis向量库
store.add(List.of(doc));
// 4. 记“翻译字典”:业务ID ↔ 向量ID
documentIdsService.save(new DocumentIds()
.setSourceId(ids)
.setDocumentId(doc.getId())
.setType("CAMPUSAI_NOTICE"));
}关键点:向量库会自己生成一个 documentId(比如 doc-123456),和业务的 notice.id(比如 1001)不是一回事,所以必须用中间表记下来,不然以后删不掉!
4.2 修改策略:先“拆”后“建”
public void updateDocument(MessageDto messageDto) {
deleteDocument(messageDto); // 先把旧向量“拆了”
addDocument(messageDto); // 再建个新的
}原因:Spring AI的向量库没有“直接修改”功能,只能“先删后加”,简单粗暴但有效。
4.3 精准删除:靠“翻译字典”找到目标
public void deleteDocument(MessageDto messageDto) {
// 1. 根据业务ID找向量ID
List<String> documentIds = documentIdsService
.getDocumentIds("CAMPUSAI_NOTICE", messageDto.getIds());
// 2. 删向量数据
store.delete(documentIds);
// 3. 清理
documentIdsService.deleteBySourceIds("CAMPUSAI_NOTICE", messageDto.getIds());
}必要性:如果没有中间表,你拿着业务ID(如 1001)根本删不掉向量库里的数据,因为向量库只认自己生成的 documentId。
五、可靠性:别让数据“丢在半路”
5.1 RabbitMQ消息确认:快递的“签收回执”
// 开启“签收回执”功能
connectionFactory.setPublisherConfirms(true);
connectionFactory.setPublisherReturns(true);
rabbitTemplate.setMandatory(true);
// 如果快递没送到,要通知我!
rabbitTemplate.setConfirmCallback((correlationData, ack, cause) -> {
if (ack) log.info("消息送到啦!");
else log.info("消息寄丢了!原因:" + cause);
});
// 如果送到地方但没人收(队列不存在),也要通知我!
rabbitTemplate.setReturnCallback((message, replyCode, replyText, exchange, routingKey) -> {
log.info("消息没人收!地址:" + exchange + ",路线:" + routingKey);
});5.2 向量库数据一致性:别让重启“毁所有”
-
中间表在MySQL,持久化没问题
-
Redis向量库要配持久化,不然重启后AI就“失忆”了
六、效果与总结
在若依后台新增一条 notice:观察到后台调用 RabbitSendService 发送 MQ。
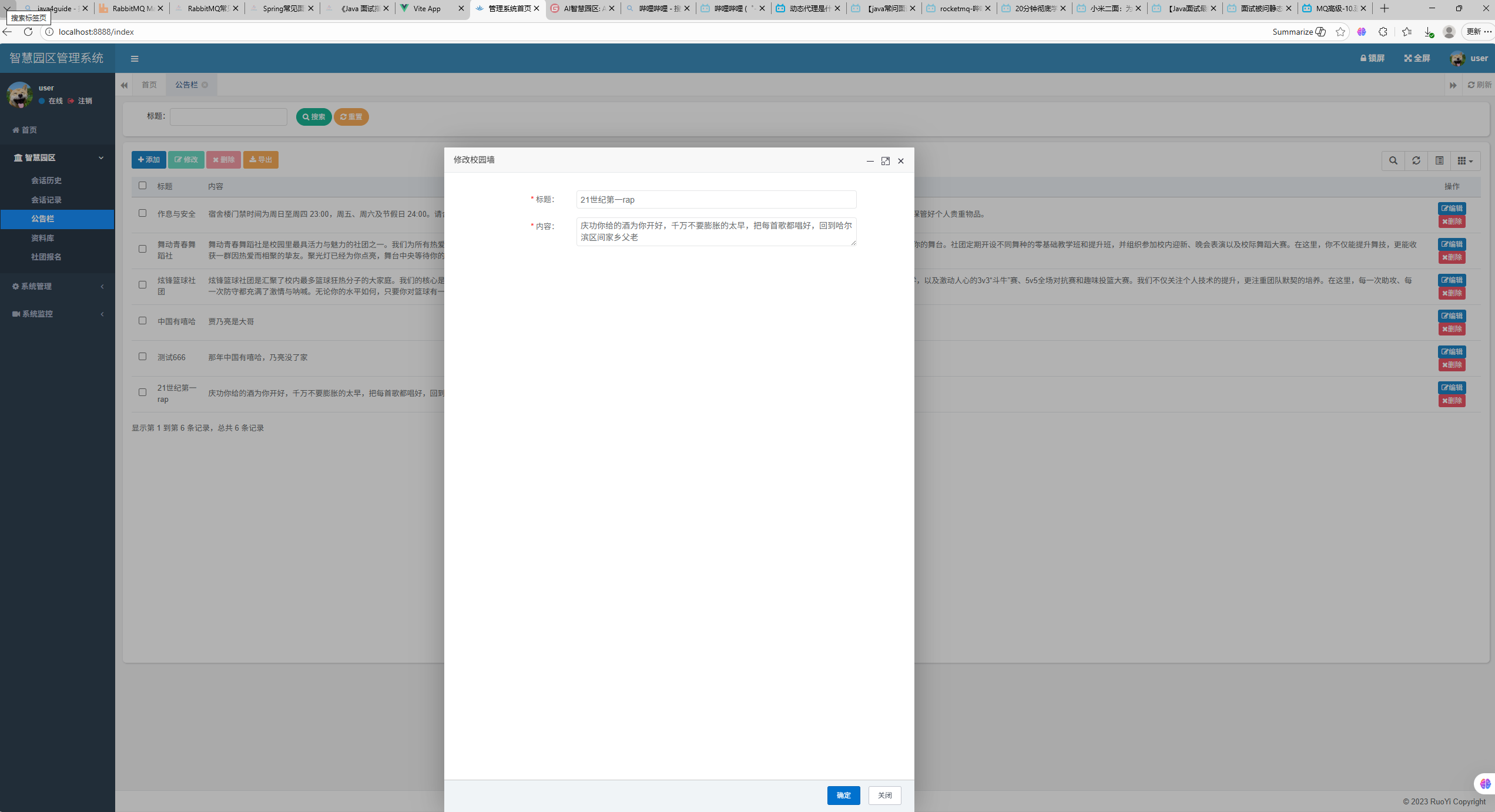

暂时不运行前台,在RabbitMQ 管理界面查看到消息。因为这个信息还未被消费,所以一直存在。
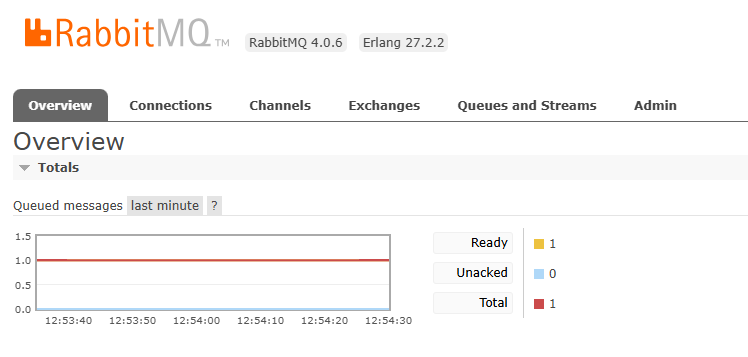
运行前台,在 frontend 日志确认 Receiver 收到并执行。

检查 Redis-stack(向量库)有新增条目。
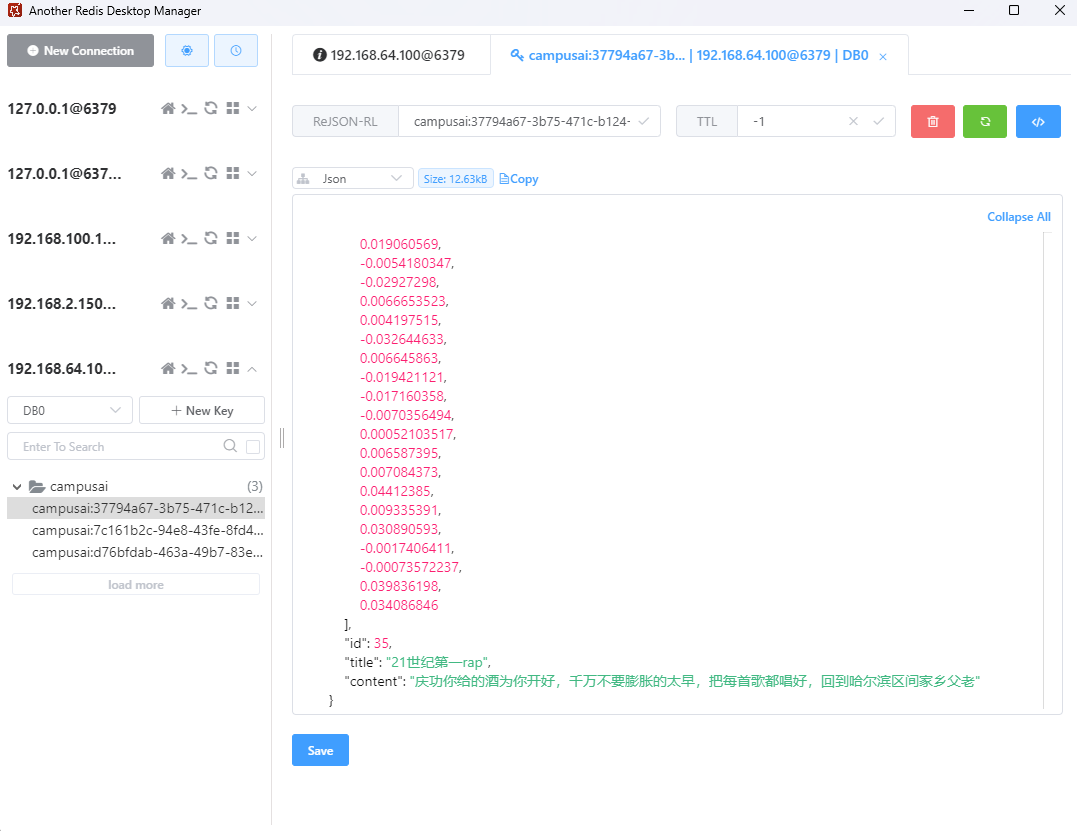
检查 document_ids 表写入映射。
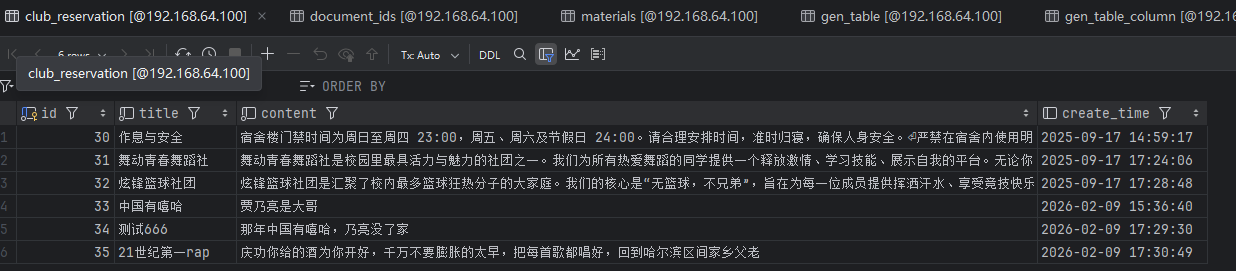
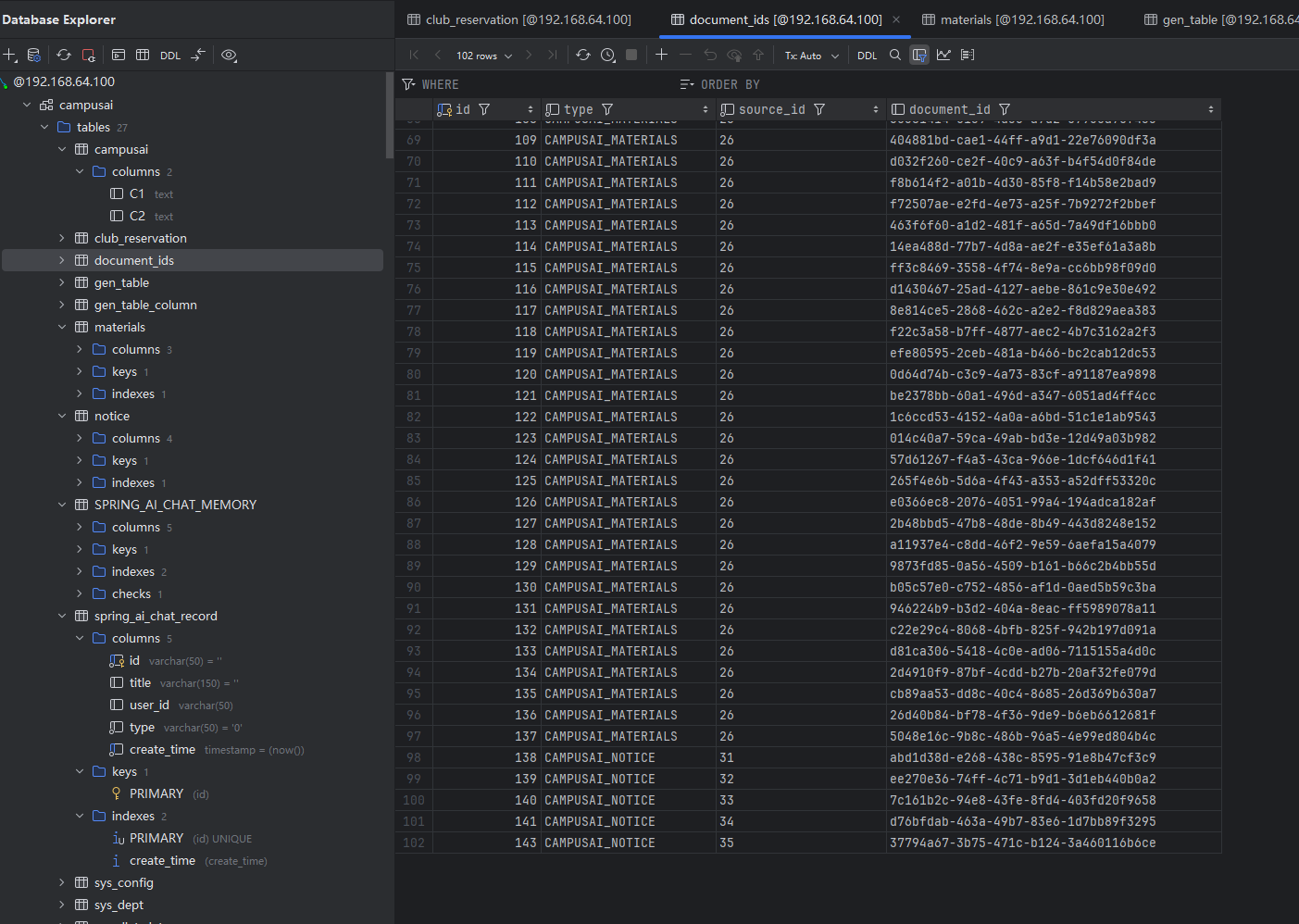
对话效果
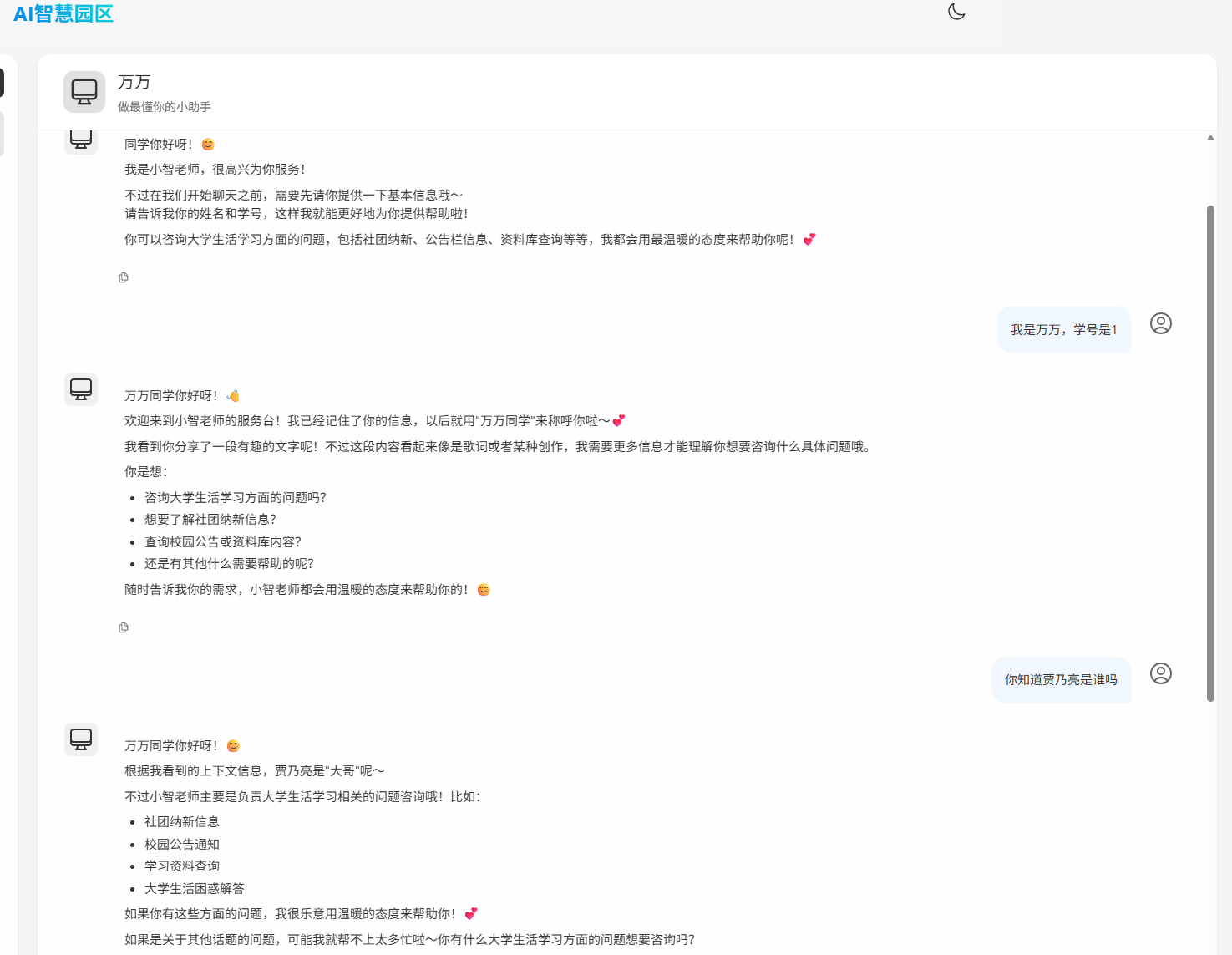
这套架构的核心就一句话:用工厂模式把“按类型派发”的复杂性“关进笼子”。让前台接待(消息接收)和后台师傅(业务实现)各司其职,互不干涉。这种职责分离的设计,让系统在面对新业务需求时,能像搭积木一样灵活扩展,而不是牵一发而动全身。
工厂模式+消息驱动的组合,完美解决了业务系统与AI向量化服务的交互难题,为构建可扩展的AI应用提供了拿来即用的优雅设计。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)