Agent架构解析与实战(九)--Tree of Thoughts
🌳 给 AI 装个“系统脑”:从线性直觉到树状博弈—— 还在迷信 CoT 的单向输出?你的 Agent 缺少关键的“自我纠错”与“全局推演”能力!
参考来源:all-agentic-architectures[1]
原始论文:Yao et al., "Tree of Thoughts: Deliberate Problem Solving with Large Language Models" (NeurIPS 2023)

目录
- 架构定义
- 宏观工作流
- 核心算法:BFS vs DFS
- ToT vs CoT 对比分析
- 应用场景
- 优缺点分析
- 代码实现详解
- 测试与验证
- 结论与核心要点
1. 架构定义
Tree-of-Thoughts (ToT) 是一种智能体推理框架,将问题解决过程建模为树形搜索。与 Chain-of-Thought (CoT) 的单一线性推理不同,ToT 代理同时探索多条推理路径(分支),在每一步生成多个候选"思维"或下一步操作,然后评估这些思维,剪枝无效或不可行的分支,并扩展最有希望的分支。
核心理念
| 特性 | 描述 |
|---|---|
| 多路径探索 | 同时探索多条推理路径,非顺序单一 |
| 自我评估 | 代理评估每个中间状态的可行性和进展 |
| 回溯能力 | 当一条路径失败时,可以回溯到其他分支 |
| 启发式剪枝 | 根据评估结果剪除无效或不理想的路径 |
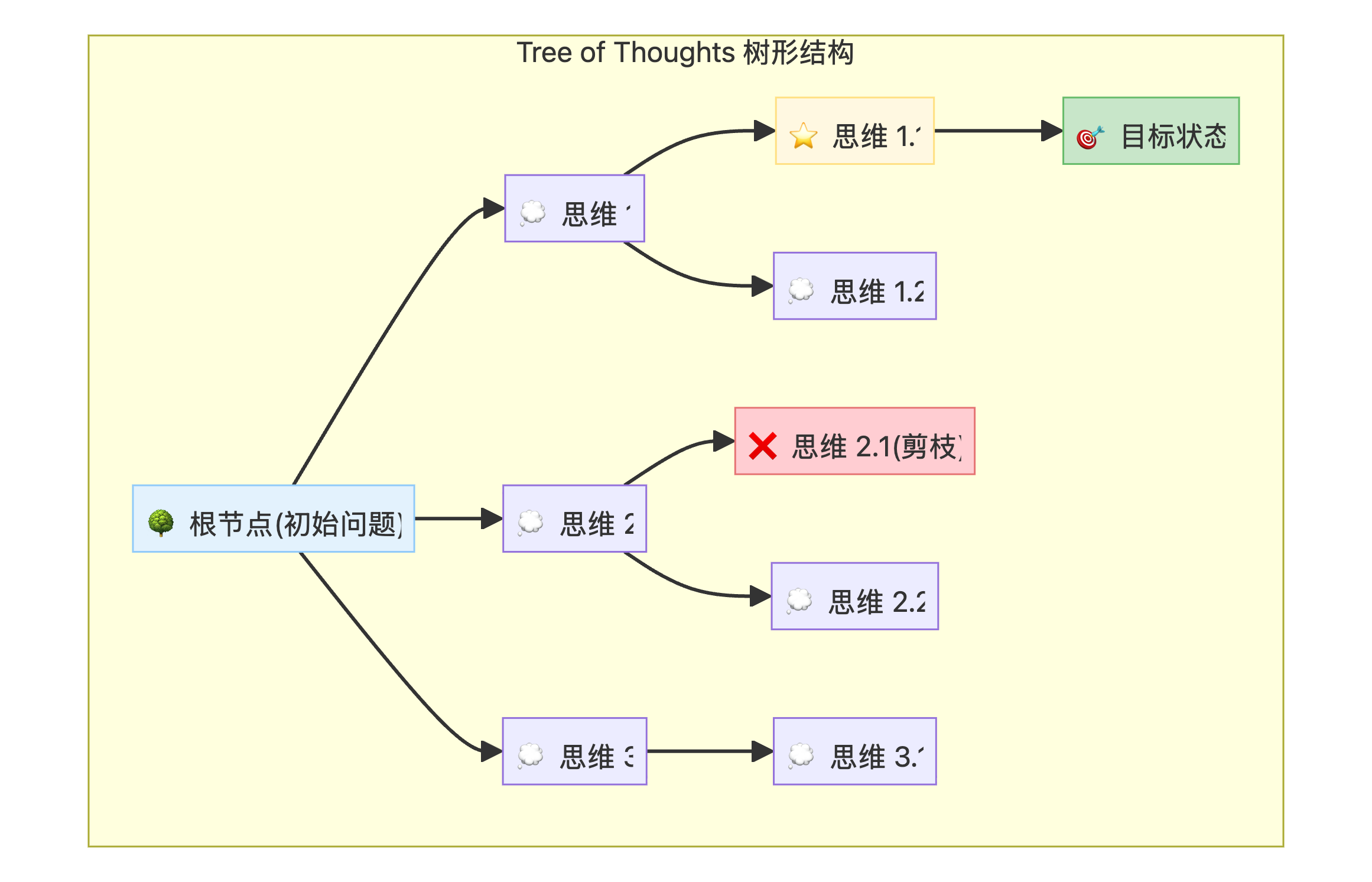
[!IMPORTANT]
🎯 核心创新ToT 将 LLM 的思维生成能力与传统 AI 的搜索算法(BFS、DFS)相结合,使 LLM 能够进行战略性前瞻、权衡不同选择、并在必要时回溯,大幅提升复杂问题的推理能力。
2. 宏观工作流
ToT 代理遵循**"分解 → 生成 → 评估 → 剪枝 → 扩展"**的迭代流程:
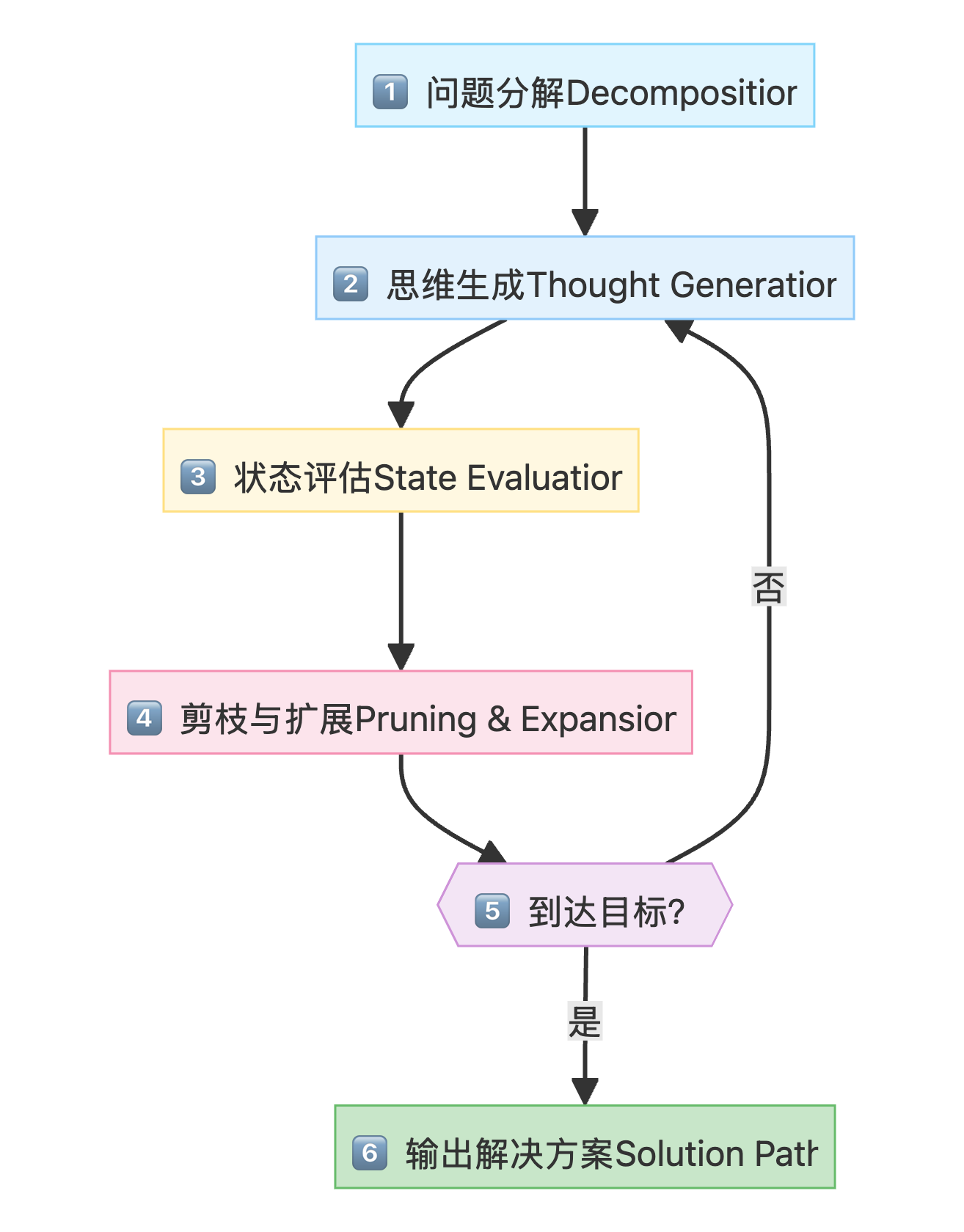
详细步骤说明
| 阶段 | 组件 | 描述 |
|---|---|---|
| 1 | 问题分解 | 将问题分解为一系列步骤或"思维" |
| 2 | 思维生成 | 对于当前问题状态,代理生成多个潜在的下一步操作,形成树的分支 |
| 3 | 状态评估 | 每个新思维(导致新状态)由评估函数评估其有效性、进展和启发式价值 |
| 4 | 剪枝与扩展 | 无效或不可行的分支被剪除,代理从最有希望的活跃分支继续扩展 |
| 5 | 目标检查 | 检查是否到达目标状态,若未到达则继续迭代 |
| 6 | 解决方案 | 输出从根节点到目标节点的思维路径 |
3. 核心算法:BFS vs DFS
ToT 框架明确集成搜索算法来导航思维树,最常用的两种策略是 BFS 和 DFS:
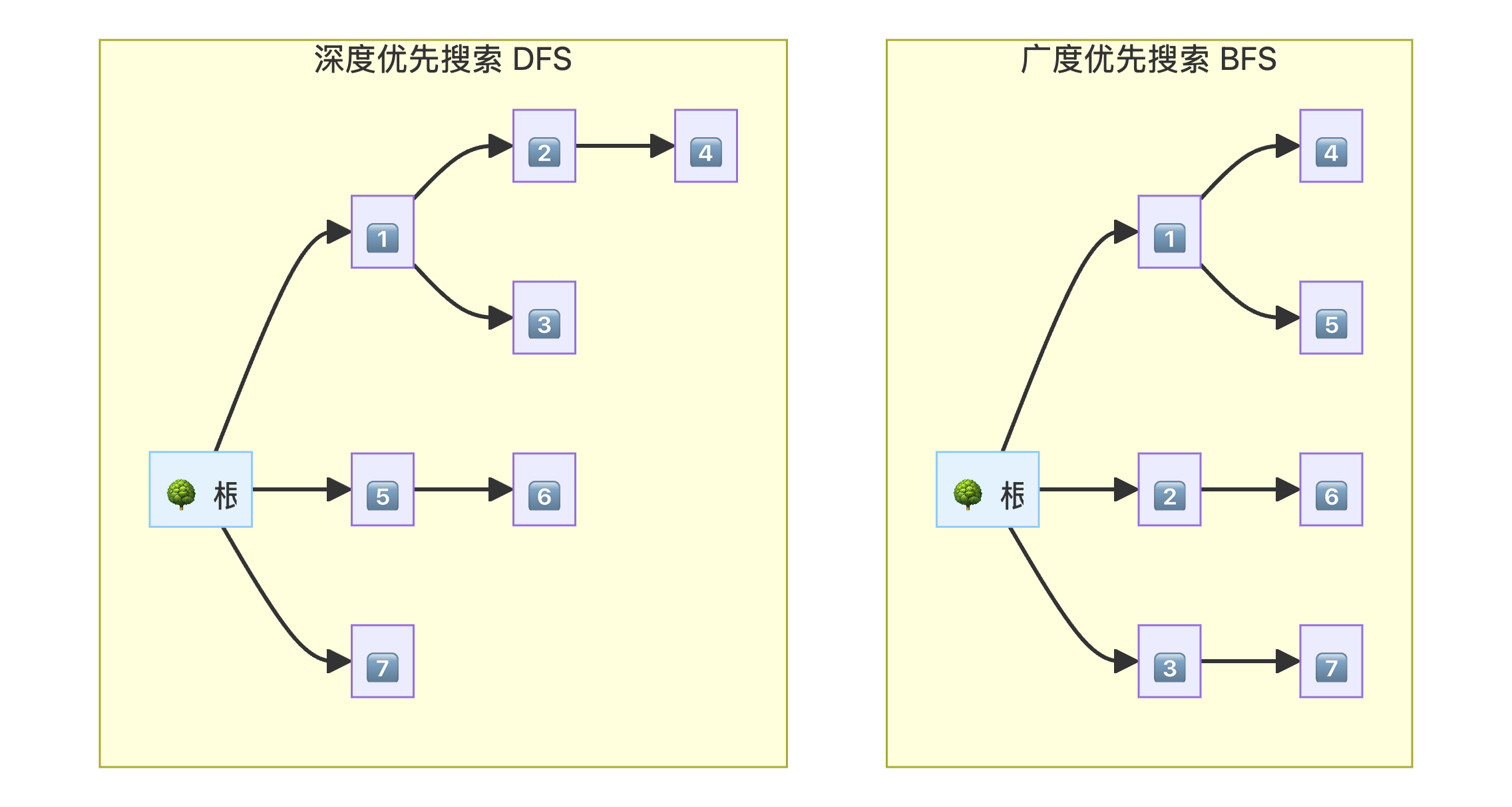
算法对比
| 特性 | BFS (广度优先) | DFS (深度优先) |
|---|---|---|
| 探索方式 | 先探索同一层的所有节点,再深入下一层 | 先深入探索一条分支到底,再回溯 |
| 适用场景 | 寻找最短路径或最浅解决方案 | 需要深入分析每个选项的问题 |
| 内存使用 | 较高(需存储所有同层节点) | 较低(只需存储当前路径) |
| 优点 | 保证找到最短解 | 可能更快找到深层解 |
| 缺点 | 可能探索过多无用分支 | 可能陷入无限深的分支 |
[!TIP]
💡 算法选择建议
- BFS:当问题的解接近根节点,或需要找最优(最短)解时使用
- DFS:当问题需要完整探索,或内存受限时使用
- Beam Search:保持固定数量最优分支,平衡探索广度和内存
4. ToT vs CoT 对比分析
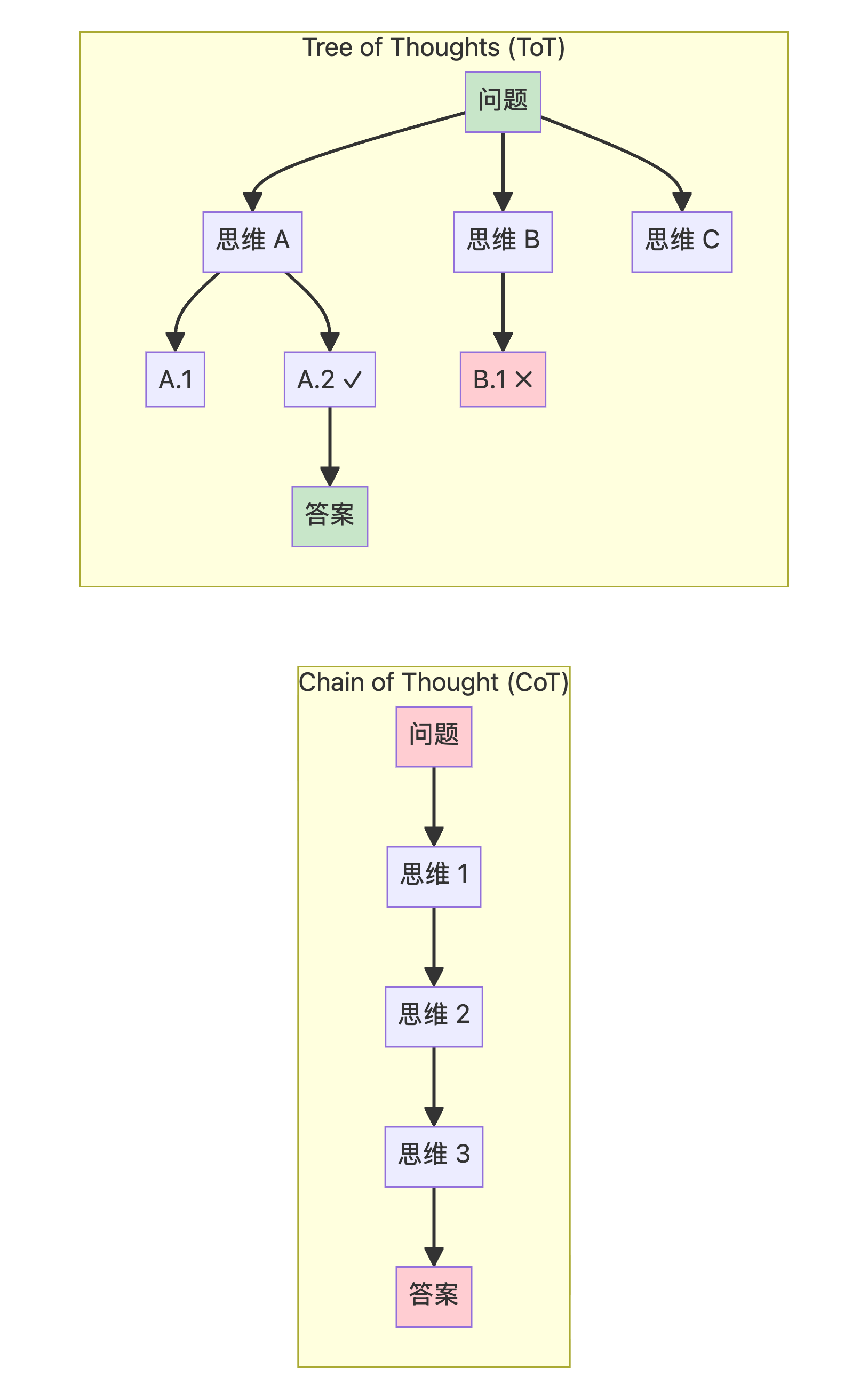
详细对比
| 维度 | Chain of Thought (CoT) | Tree of Thoughts (ToT) |
|---|---|---|
| 推理方式 | 线性、顺序推理 | 树形、多路径探索 |
| 思维表示 | 单一连续的文本序列 | 多个并行的"思维"分支 |
| 回溯能力 | ❌ 无法回溯 | ✅ 可以回溯和尝试替代路径 |
| 自我评估 | ❌ 无中间评估 | ✅ 每步都评估进展和可行性 |
| 错误容忍 | 单步错误导致整体失败 | 对错误有鲁棒性,可剪枝 |
| 计算成本 | 较低(单次推理) | 较高(多次生成+评估) |
| 适用场景 | 顺序、清晰路径的问题 | 复杂规划、探索性问题 |
[!WARNING]
⚠️ CoT 的局限性CoT 依赖 LLM 的预训练知识来"回忆"解决方案。对于经典、众所周知的问题可能有效,但:
- 单步错误无法自我纠正
- 对于新颖或复杂问题,失败概率较高
- 正确性基于"记忆"而非"可验证的推理"
5. 应用场景 (Use Cases)
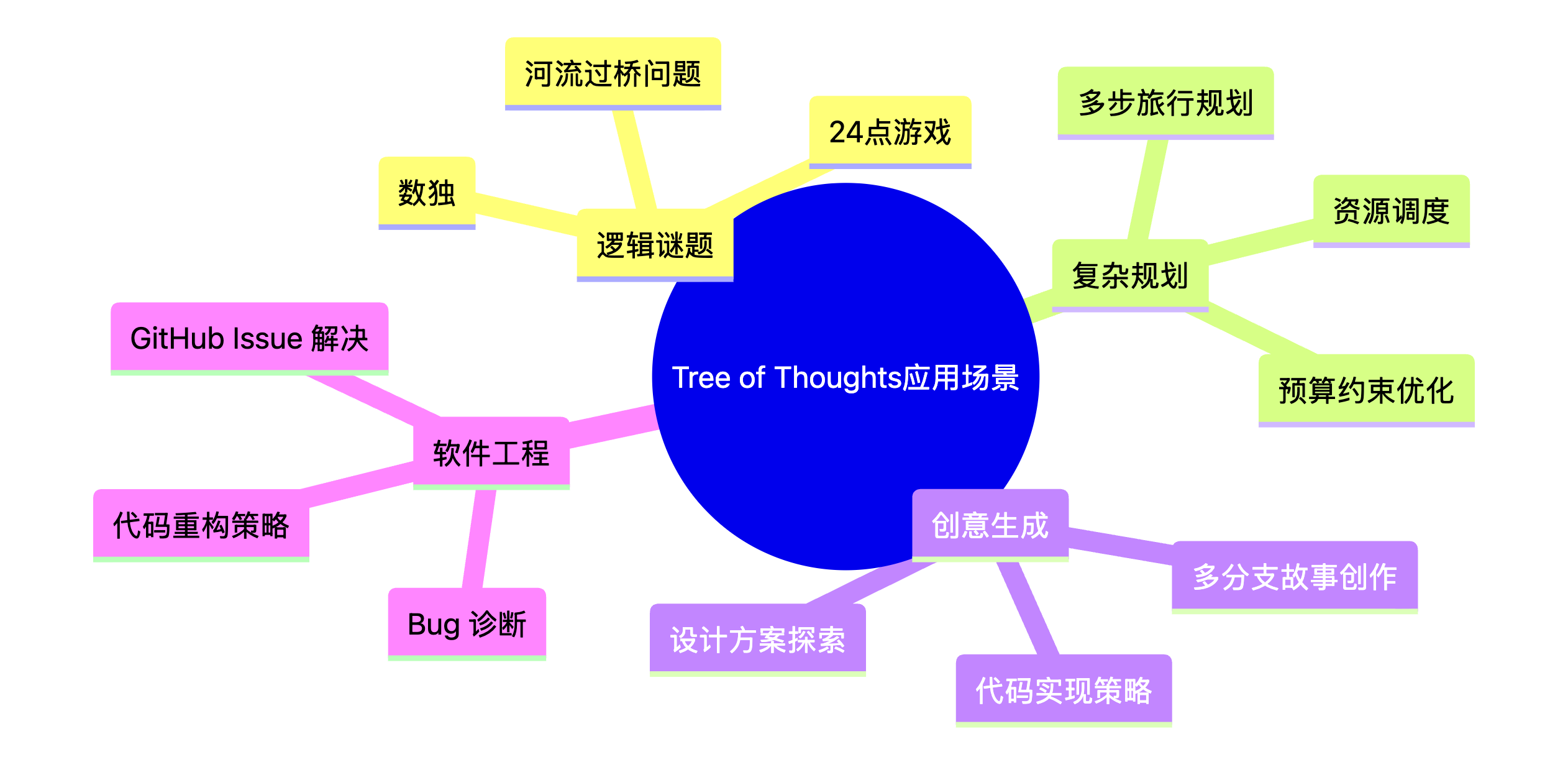
| 场景 | 描述 | 为何适用 ToT |
|---|---|---|
| 逻辑谜题 & 数学问题 | 具有明确规则和目标状态,需要多步、非线性推理的问题 | 需要探索和回溯 |
| 复杂规划 | 任务需要详细计划,操作顺序重要,必须遵守约束 | 多种可能路径需要评估 |
| 创意写作 & 代码生成 | 探索多个故事分支或实现策略后再选择最佳 | 创意需要多路径探索 |
| 软件问题解决 | 解决 GitHub Issues、调试复杂 Bug | 问题诊断需要系统性搜索 |
6. 优缺点分析
✅ 优点
| 优点 | 说明 |
|---|---|
| 鲁棒性强 | 系统性地探索问题空间,比单遍方法更不容易陷入困境或产生错误答案 |
| 处理组合复杂性 | 非常适合可能序列数量庞大的问题 |
| 可验证性 | 解决方案是通过搜索构建的,而非仅依赖记忆 |
| 错误纠正 | 当一条路径失败时,可以通过回溯探索其他路径 |
❌ 缺点
| 缺点 | 说明 |
|---|---|
| 计算密集 | 需要比简单 CoT 更多的 LLM 调用和状态管理,更慢且更昂贵 |
| 依赖评估质量 | 搜索效果严重依赖状态评估逻辑的质量 |
| 实现复杂度 | 需要定义状态表示、验证规则、目标状态等 |
| 可能过度探索 | 没有好的剪枝策略会导致不必要的分支探索 |
7. 代码实现详解
7.1 环境配置
依赖库安装
pip install -q -U langchain-openai langchain langgraph python-dotenv rich pydantic langchain-core langchain_community7.2 导入库并设置密钥
import os
import re
from typing import List, Dict, Any, Optional
from dotenv import load_dotenv
from collections import defaultdict
# pydantic数据模型
from pydantic import BaseModel, Field
# langchain组件
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
# langgraph组件
from langgraph.graph import StateGraph, END
from typing_extensions import TypedDict
# For pretty printing
from rich.console import Console
from rich.markdown import Markdown
from rich.tree import Tree
# --- API Key and Tracing Setup ---
load_dotenv()
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = "Agentic Architecture - Tree-of-Thoughts (OpenAI)"
for key in ["OPENAI_API_KEY", "LANGCHAIN_API_KEY"]:
if not os.environ.get(key):
print(f"{key} 未找到. 请创建.env文件并配置对应密钥.")
print("环境变量和LangTrace配置完成.")运行结果:
环境变量和LangTrace配置完成.7.3 创建问题环境(狼、羊、白菜问题)
console = Console()
class PuzzleState(BaseModel):
"""
Represents the state of the Wolf, Goat, and Cabbage puzzle.
"""
# Using sets for unordered collections of items on each bank
left_bank: set[str] = Field(default_factory=lambda: {"wolf", "goat", "cabbage"})
right_bank: set[str] = Field(default_factory=set)
boat_location: str = "left"
move_description: str = "Initial state."
def is_valid(self):
"""
检查当前状态是否正常(没有任何东西被吃掉)
"""
# 检查左岸
if self.boat_location == "right":
if "wolf" in self.left_bank and "goat" in self.left_bank:
return False
if "goat" in self.left_bank and "cabbage" in self.left_bank:
return False
# 检查右岸
if self.boat_location == "left":
if "wolf" in self.right_bank and "goat" in self.right_bank:
return False
if "goat" in self.right_bank and "cabbage" in self.right_bank:
return False
return True
def is_goal(self):
"""检查是否到了预期终态"""
return self.right_bank == {"wolf", "goat", "cabbage"}
def __hash__(self):
# 让对象变得可哈希(hashable),用于快速查找和去重
return hash((frozenset(self.left_bank), frozenset(self.right_bank), self.boat_location))
def __eq__(self, other):
return self.__hash__() == other.__hash__()
def get_possible_moves(state: PuzzleState) -> List[PuzzleState]:
"""生成所有可能的、有效的当前状态的下一步状态"""
moves = []
current_bank = state.left_bank if state.boat_location == "left" else state.right_bank
# 把一个东西放到船上再移动
for item in current_bank:
new_state = state.model_copy(deep=True)
if state.boat_location == "left":
new_state.left_bank.remove(item)
new_state.right_bank.add(item)
new_state.boat_location = "right"
new_state.move_description = f"Moved {item} to the right bank."
else:
new_state.right_bank.remove(item)
new_state.left_bank.add(item)
new_state.boat_location = "left"
new_state.move_description = f"Moved {item} to the left bank."
if new_state.is_valid():
moves.append(new_state)
# 移动空船
empty_move_state = state.model_copy(deep=True)
if state.boat_location == "left":
empty_move_state.boat_location = "right"
empty_move_state.move_description = "Moved the boat to the right bank."
else:
empty_move_state.boat_location = "left"
empty_move_state.move_description = "Moved the boat to the left bank."
if empty_move_state.is_valid():
moves.append(empty_move_state)
return moves
print("Puzzle environment defined successfully.")运行结果:
Puzzle environment defined successfully.[!TIP]
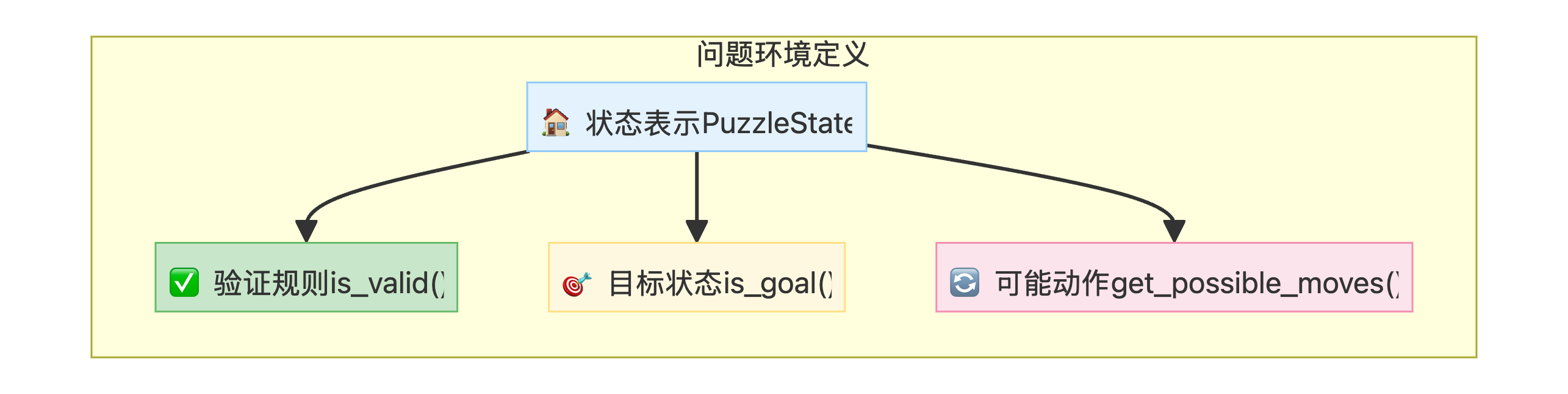
💡 设计要点
- 状态表示:使用
set存储每岸的物品__hash__方法:使状态可哈希,便于检测循环- 验证规则:检查狼与羊、羊与白菜是否在无人看管时独处
7.4 通过 LangGraph 实现 ToT Agent
状态定义和节点实现
llm = ChatOpenAI(
model="gpt-5-mini",
temperature=0.2,
api_key=os.environ["OPENAI_API_KEY"],
base_url="https://api.openai.com/v1"
)
# pydantic模型
class MoveChoice(BaseModel):
base_move_index: int = Field(description="The index of the best move from the provided list of possible moves.")
reasoning: str = Field(description="Brief reasoning for why this is the most promising move.")
# LangGraph状态
class ToTState(TypedDict):
problem_description: str
# 每一条路径都是PuzzleState的列表
active_paths: List[List[PuzzleState]]
solution: Optional[List[PuzzleState]]
# 节点
def initial_search(state: ToTState) -> Dict[str, Any]:
"""Node to set up the initial state of the search."""
initial_puzzle_state = PuzzleState()
return {"active_paths": [[initial_puzzle_state]]}
def expand_paths(state: ToTState) -> Dict[str, Any]:
"""The 'Thought Generator'. Expands each active path with a promising next move."""
console.print("Expanding paths...")
new_paths = []
# 为了演示ToT的搜索特性,这里穷举所有有效移动
# 如果问题规模很大,才需要 LLM 来做启发式剪枝(Heuristic Pruning)
for path in state["active_paths"]:
last_state = path[-1]
possible_next_states = get_possible_moves(last_state)
if not possible_next_states:
continue
for next_state in possible_next_states:
new_paths.append(path + [next_state])
console.print(f"[cyan]Expanded to {len(new_paths)} new paths. [/cyan]")
return {"active_paths": new_paths}
def prune_paths(state: ToTState) -> Dict[str, Any]:
"""The 'State Evaluator'. Removes invalid states and cycles. Also checks for solution."""
console.print("Pruning paths...")
pruned_paths = []
found_solution = None
for path in state["active_paths"]:
# 1. 检查是否找到解 (Check for Solution)
if path[-1].is_goal():
console.print("[green]Found a solution! [/green]")
found_solution = path
break
# 2. 检查循环 (Cycle Check)
if path[-1] in path[:-1]:
continue
pruned_paths.append(path)
console.print(f"[cyan]Pruned to {len(pruned_paths)} paths. [/cyan]")
if found_solution:
return {"active_paths": pruned_paths, "solution": found_solution}
return {"active_paths": pruned_paths}
# 条件节点
def check_for_solution(state: ToTState) -> str:
"""Checks if a solution has been found and routes execution."""
if state.get("solution"):
return "solution_found"
return "continue_search"构建工作流图
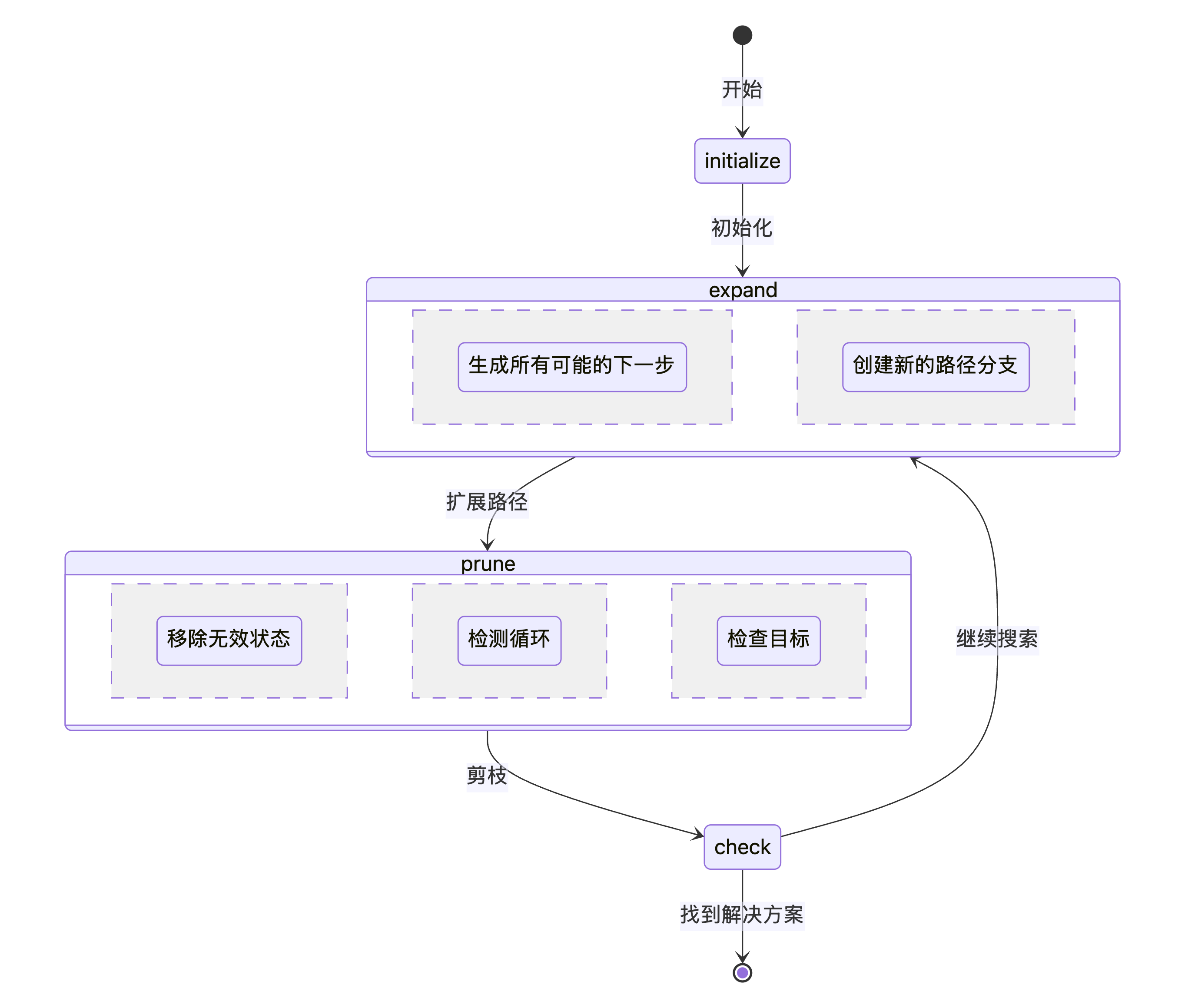
# 构建图
workflow = StateGraph(ToTState)
workflow.add_node("initialize", initial_search)
workflow.add_node("expand", expand_paths)
workflow.add_node("prune", prune_paths)
workflow.set_entry_point("initialize")
workflow.add_edge("initialize", "expand")
workflow.add_edge("expand", "prune")
workflow.add_conditional_edges(
"prune",
check_for_solution,
{
"solution_found": END,
"continue_search": "expand"
}
)
tot_agent = workflow.compile()
print("ToT Agent创建成功.")运行结果:
ToT Agent创建成功.8. 测试与验证
8.1 运行 ToT Agent 解决狼羊白菜问题
problem = "A farmer wants to cross a river with a wolf, a goat, and a cabbage..."
console.print("--- 🌳 Running Tree-of-Thoughts Agent ---")
config = {"recursion_limit": 50}
final_state = tot_agent.invoke({"problem_description": problem}, config=config)
console.print("\n--- ✅ ToT Agent Solution ---")
if final_state.get('solution'):
solution_path = final_state['solution']
tree = Tree("[bold magenta]Wolf, Goat, and Cabbage Solution Path[/bold magenta]")
for i, state in enumerate(solution_path):
tree.add(f"[bold blue]Step {i+1}: {state.move_description}[/bold blue]")
console.print(tree)运行结果:
--- 🌳 Running Tree-of-Thoughts Agent ---
Expanding paths...
Expanded to 1 new paths.
Pruning paths...
Pruned to 1 paths.
Expanding paths...
Expanded to 2 new paths.
Pruning paths...
Pruned to 1 paths.
...
Found a solution!
Pruned to 1 paths.
--- ✅ ToT Agent Solution ---
Wolf, Goat, and Cabbage Solution Path
├── Step 1: Initial state.
├── Step 2: Moved goat to the right bank.
├── Step 3: Moved the boat to the left bank.
├── Step 4: Moved cabbage to the right bank.
├── Step 5: Moved goat to the left bank.
├── Step 6: Moved wolf to the right bank.
├── Step 7: Moved the boat to the left bank.
└── Step 8: Moved goat to the right bank.8.2 对比简单 Chain-of-Thought Agent
console.print("\n--- 📝 Running Simple Chain-of-Thought Agent ---")
cot_prompt = ChatPromptTemplate.from_messages([
("system", "You are a world-class logic puzzle solver. Provide a step by step solution in Chinese,"),
("human", "{problem}")
])
cot_chain = cot_prompt | llm
cot_result = cot_chain.invoke({"problem": problem}).content
console.print(Markdown(cot_result))CoT 运行结果:
下面给出一种能使农夫、狼、山羊、卷心菜都安全过河的步骤:
初始状态: 左岸:农夫、狼、山羊、卷心菜; 右岸:无
步骤:
1 农夫带山羊过河。
左岸:狼、卷心菜; 右岸:农夫、山羊。
说明:左岸剩狼与卷心菜,不会发生吃的问题。
2 农夫独自回到左岸。
左岸:农夫、狼、卷心菜; 右岸:山羊。
3 农夫带狼过河。
左岸:卷心菜; 右岸:农夫、狼、山羊。
说明:此时山羊在右岸有农夫在场,狼与山羊不单独相处。
4 农夫把山羊带回左岸。
左岸:农夫、山羊、卷心菜; 右岸:狼。
说明:把山羊带回避免狼和山羊单独留在右岸。
5 农夫带卷心菜过河。
左岸:山羊; 右岸:农夫、狼、卷心菜。
6 农夫独自回到左岸。
左岸:农夫、山羊; 右岸:狼、卷心菜。
7 农夫带山羊过河。
左岸:无; 右岸:农夫、狼、山羊、卷心菜 —— 全部安全到达。8.3 结果分析
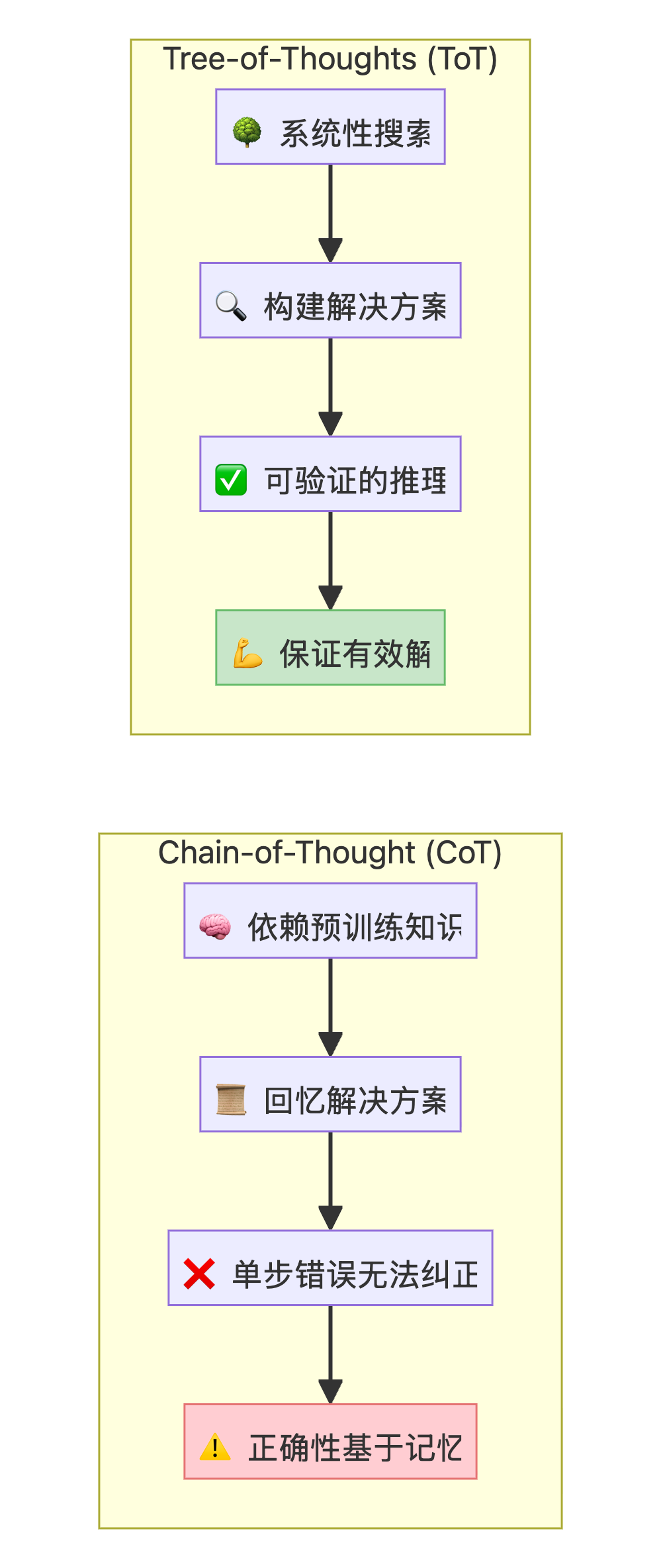
| 方法 | 机制 | 可靠性 | 适用场景 |
|---|---|---|---|
| CoT | 依赖预训练知识"回忆"解决方案 | 对经典问题有效,但无法自我纠正 | 顺序清晰的常见问题 |
| ToT | 通过系统性搜索"构建"解决方案 | 高度可靠,解的正确性可验证 | 复杂规划和探索性问题 |
[!IMPORTANT]
🎯 关键洞察ToT 代理的成功不是基于运气或记忆,而是基于其搜索算法的健壮性。这使其成为需要高可靠性和规划的任务的首选架构。
9. 结论与核心要点
🎓 核心成果
| 成果 | 说明 |
|---|---|
| 状态空间搜索 | 通过将问题转换为状态空间并系统性搜索,实现高鲁棒性推理 |
| 思维生成与评估 | LLM 生成候选思维,评估函数剪枝无效路径 |
| 可验证解决方案 | 解决方案通过搜索构建,正确性可保证 |
| LangGraph 实现 | 使用 LangGraph 构建清晰的状态机工作流 |
🌟 关键洞察
| 洞察 | 描述 |
|---|---|
| 搜索 + LLM | ToT 将传统 AI 搜索算法与 LLM 生成能力结合 |
| 计算换可靠性 | 更高的计算成本换取显著的可靠性提升 |
| 问题环境设计 | 成功的 ToT 需要良好定义的状态、验证规则和目标 |
| vs CoT | ToT 是 CoT 的泛化,适用于更复杂的问题 |
ToT 系统三核心组件

关键代码速查表
| 组件 | 代码 |
|---|---|
| 定义状态 | class PuzzleState(BaseModel) |
| 状态验证 | def is_valid(self) |
| 生成可能动作 | def get_possible_moves(state) |
| 扩展路径 | def expand_paths(state) |
| 剪枝评估 | def prune_paths(state) |
| 条件路由 | workflow.add_conditional_edges(...) |
| 编译图 | tot_agent = workflow.compile() |
参考链接
[1] all-agentic-architectures: https://github.com/FareedKhan-dev/all-agentic-architectures/tree/main

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)