飞腾平台使用AMD ROCm的流程 (PhyBin 二进制翻译版)
摘要: 本文介绍了在飞腾D3000 ARM架构CPU上通过PhyBin二进制翻译引擎适配ROCm平台的实践方案。飞腾CPU作为国产ARM代表,面临AI算力需求增长但缺乏成熟GPGPU生态的挑战。实验采用Ubuntu 22.04系统,通过PhyBin模拟x86环境安装AMD GPU驱动和ROCm 6.3,成功在RX 7800XT显卡上运行llama.cpp项目,实现了Qwen3-8B模型的推理(64
1. 背景简介
飞腾CPU采用ARMv8指令集架构,在外部技术管制持续收紧、国内智能算力需求爆发的背景下,在飞腾ARM架构平台上探索适配ROCm(Radeon Open Compute Platform),是构建全国产异构算力栈的一项关键且富有挑战性的战略举措。飞腾CPU作为国产ARM路线的领军者,在政务、金融、电力等国计民生领域已实现规模化应用,但其生态主要围绕通用计算,面对大模型训练与推理等智能算力需求,亟需引入成熟的GPGPU生态以降低AI应用向国产平台迁移的成本。虽然ROCm开源了代码,但AMD官方并未提供ROCm和AMD驱动对Linux ARM架构的支持,当前技术路径采用飞腾的“九译”引擎(Phybin)进行二进制翻译适配,作为一种过渡方案以实现基础功能的验证与运行。后续计划利用ROCm的开源特性,进行更深层次的源码编译与原生移植,旨在最终实现性能优化与生态融合。
1.1 硬件和操作系统
| CPU | 飞腾 D3000 |
|---|---|
| 操作系统 | Ubuntu 22.04 |
| 内存 | 32G DDR5 |
| Linux内核版本 | 6.8.0-90-generic |
| AMD显卡型号 | RX 7800XT 16GB |
1.2 软件依赖
| PhyBin(九译引擎) | 2.1.0 |
|---|---|
| x86镜像 | Ubuntu 22.04 |
2. 下载PhyBin(九译引擎)
2.1 PhyBin 介绍
PhyBin 是一款运行在Arm64机器上的二进制翻译软件。通过Linux的binfmt机制,它能将自身注册为x86 程序的执行器,翻译x86程序的指令,并将其转换为Arm64架构下可执行的指令,从而使得大多数x86应用无需重新编译即可在Arm64服务器上运行,实现低成本的应用迁移。
PhyBin 主要包含两个组件: 1. PhyBin二进制翻译引擎 2. Guest x86镜像运行环境

2.2 PhyBin 安装
(1) 在Phytium PhyBin 产品页对应软件包下载
https://www.phytium.com.cn/developer/independent_software/detail/51/49/
(2) 安装Phybin引擎
sudo dpkg -i cn.com.phytium.phybin-<phybin-version>.aarch64.deb
(3) 安装Guest x86镜像deb安装包
sudo dpkg -i cn.com.phytium.phybin-ubuntu_20.04-<os-version>.aarch64.deb
(4) 下载ubuntu22.04镜像
wget https://oss-nc-beijing-2.cecloudcs.com/appstore/ubuntu_22.04.tar.gz
tar xf ubuntu_22.04.tar.gz -C /opt/phybin/os/
(5) 修改conf文件
vim /etc/phybin/phybin.conf
guest_os_image=/opt/phybin/os/ubuntu_22.04
2.3 运行PhyBin
(1)运行以下命令进入拥有root权限的x86环境
sudo phybin
(2)在拥有root权限的x86环境中执行以下命令安装wget
apt-get update
apt instal wget
3. 安装ROCm
(1)安装AMD GPU驱动
wget https://repo.radeon.com/amdgpu-install/7.1.1/ubuntu/jammy/amdgpu-install_7.1.1.70101-1_all.deb
sudo apt install ./amdgpu-install_7.1.1.70101-1_all.deb
sudo apt update
sudo apt install "linux-headers-$(uname -r)" "linux-modules-extra-$(uname -r)"
sudo apt install amdgpu-dkms
amdgpu-install_6.3.60302-1_all.deb
(2)安装ROCm
wget https://repo.radeon.com/amdgpu-install/6.3.2/ubuntu/jammy/amdgpu-install_6.3.60302-1_all.deb
sudo apt install ./amdgpu-install_6.3.60302-1_all.deb
sudo apt update
sudo apt install python3-setuptools python3-wheel
sudo usermod -a -G render,video $LOGNAME # Add the current user to the render and video groups
sudo amdgpu-install --usecase=rocm,hip --no-dkms
(3) 运行ROCm 查看是否安装成功
rocm-smi
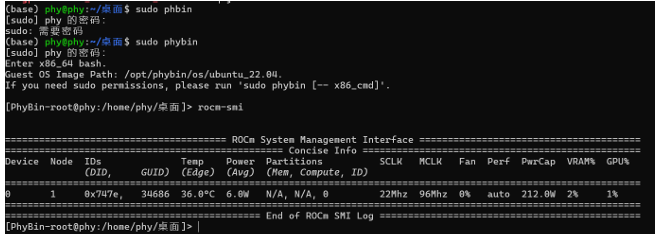
注:安装过程比较漫长,请耐心等候
4. Llama.cpp 推理
4.1 Llama.cpp 介绍
Llama.cpp 是一个开源项目,通过纯 C/C++ 实现高效运行大型语言模型(LLM),专注于在本地设备上提供轻量级、高性能的推理解决方案。该项目通过优化算法和最小化依赖项,支持在多种 CPU 和 GPU 架构上高效运行,既能在普通 CPU 上流畅执行模型推理,也能利用 GPU 加速提升性能。核心特点包括广泛的硬件兼容性、多种量化技术(如 1.5 位到 8 位整数量化)以显著降低模型大小和内存占用,并支持多种操作系统(Windows、Linux、macOS 等)。此外,Llama.cpp 提供简洁的 API 和命令行工具,便于开发者集成到自有应用或进行本地测试,其开源特性也吸引了社区持续贡献,成为本地化部署大模型的重要工具之一(Ollama 和 LM Studio 均基于 Llama.cpp)。
4.2 Llama.cpp 项目编译
(1)克隆项目到本地
git clone https://github.com/ggml-org/llama.cpp
(2)进入项目目录
cd llama.cpp
(3)cmake构建build目录并执行编译(基于ROCm构建)
HIPCXX="$(hipconfig -l)/clang" \
HIP_PATH="$(hipconfig -R)" \
-DCMAKE_BUILD_TYPE=Release \
cmake -S . -B build -DGGML_HIP=ON \
&& cmake --build build --config Release -- -j 8
4.3 Llama.cpp 运行LLM
(1)使用命令行直接运行模型
llama-cli -m Qwen3-8B-Q4_k_M-GGUF
(2)使用API服务的方式运行模型
llama-server -m Qwen3-8B-Q4_k_M-GGUF
(2)测试模型性能
llama-bench -m Qwen3-8B-Q4_k_M-GGUF
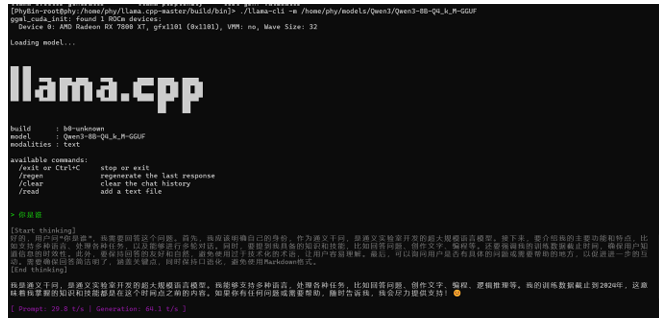
8B模型推理速度为64.3 tokens/s,性能相当不错了!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)