自用trick清单:29个让GRPO「不翻车」的野路子技巧
本文总结了29个实战有效的GRPO算法调参技巧,涵盖策略探索、奖励设计、稳定性提升等七大类,强调其在大模型对齐中的工业级应用价值与场景适配性。
·
调参调到头秃?别急,GRPO(Generalized Reinforcement Learning for Preference Optimization)这个PPO的“升级版”,早就悄悄成了大模型对齐的工业标配。但你知道吗?除了那些被写进训练脚本的常规操作,还藏着一堆“野路子”技巧——它们可能没上过顶会,却在各大厂的训练集群里默默扛起了效果提升的大旗。今天咱们就来盘一盘这29个实用又带点巧思的GRPO优化tricks,按实战场景分门别类,帮你下次调参时多几把趁手的“瑞士军刀”。
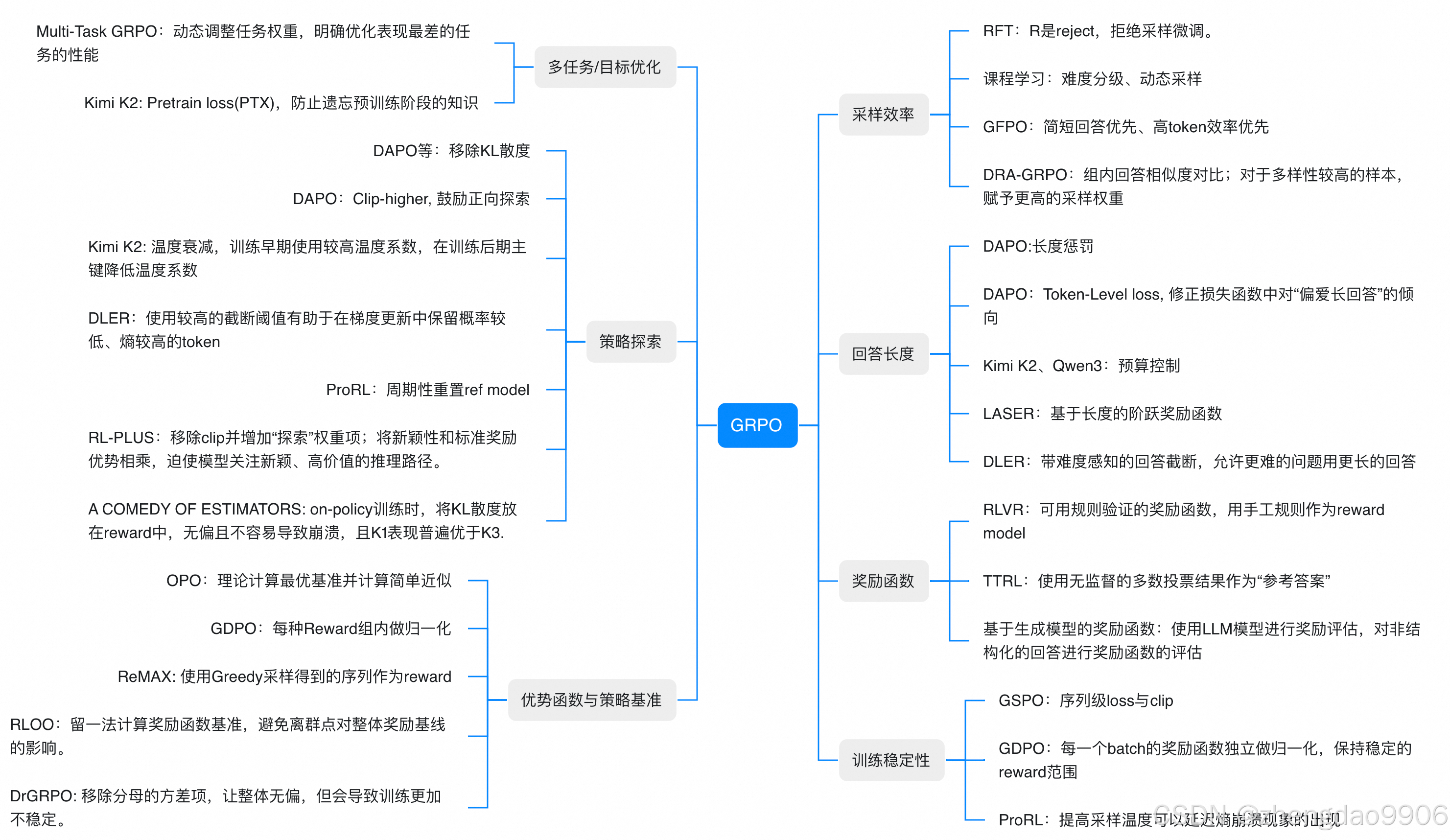
一、策略探索类优化
- DAPO移除KL散度
摒弃传统KL散度约束,让策略更新更加自由。这一方法源于早期RLHF实践中发现的KL散度可能导致策略过度保守的问题,在Llama系列模型的微调中被证实能显著提升探索效率,避免模型陷入局部最优。 - DAPO Clip-higher技术
通过扩大策略更新的clip范围,针对性强化对有益探索方向的梯度更新。这一技巧在Meta的LLaMA-2微调中得到验证,允许模型在安全边界内进行更大胆的探索,同时防止策略崩溃。 - Kimi K2温度衰减策略
训练初期采用高温策略鼓励广泛探索,后期逐步降温聚焦高质量策略。这种动态调整机制借鉴了模拟退火算法思想,在Qwen系列模型中表现出色,有效平衡了探索与利用的矛盾。 - DLER截断阈值调整
在梯度更新时设置更高截断阈值,保留低概率但高价值的token选择。这一技巧让模型在训练后期能更专注于高质量但稀有的策略路径,特别适用于需要深度推理的复杂任务。 - ProRL周期性重置参考模型
定期重置参考模型参数,打破长期依赖导致的策略偏差累积。这种"重启"机制类似于深度学习中的学习率预热策略,能有效防止策略在局部最优解附近震荡,保持探索活力。 - RL-PLUS移除clip并增加探索权重
移除策略更新的clip限制,同时叠加探索激励权重。这一方法在Anthropic的Constitutional AI研究中得到验证,能有效引导模型关注新颖且高价值的推理路径,避免过度保守的策略选择。 - A COMEDY OF ESTIMATORS
on-policy训练中将KL散度融入reward设计,既保持策略稳定性又避免优化方向偏差。这一创新方法通过K1变体进一步优化KL计算,在保持无偏性的同时显著提升模型性能。
二、优势函数与策略基准优化
- OPO理论最优基准近似
以理论最优策略为基准目标,通过简化计算实现高效策略优化。这种方法借鉴了"近似动态规划"思想,在保证理论保证的同时大幅降低计算复杂度,适用于资源受限场景。 - GDPO组内Reward归一化
对同一Reward类别内的样本进行归一化处理,消除不同Reward尺度差异。这一技巧受到标准化技术启发,能有效解决多目标优化中不同目标量纲不一致的问题,提升训练稳定性。 - ReMAX使用Greedy采样序列
利用Greedy采样得到的序列作为reward信号,简化奖励计算过程。这种方法在实践中被证明能有效降低计算复杂度,同时保持奖励信号的可靠性,特别适合大规模训练场景。 - RLOO留一法计算奖励基准
通过留一法计算奖励函数基准,避免离群点对整体奖励基线的影响。这一技术借鉴了统计学中的稳健估计思想,能有效提高奖励函数的鲁棒性。 - DrGRPO移除分母方差项
移除分母的方差项,让整体无偏,但会导致训练更加不稳定。这一方法展示了在GRPO优化中无偏性与稳定性的权衡,需要结合其他技术共同使用以获得最佳效果。
三、训练稳定性优化
- GSPO序列级loss与clip
结合序列级损失函数与梯度裁剪,从整体序列角度约束更新幅度。这种方法避免了传统token级优化中可能出现的局部优化问题,特别适用于长文本生成任务,防止模型在生成过程中偏离预期。 - GDPO批次内奖励归一化
每个batch内独立对奖励进行归一化,维持奖励信号的稳定分布。这一技术借鉴了BatchNorm的思想,能有效缓解训练过程中的奖励漂移问题,使训练过程更加平滑。 - ProRL提高采样温度
提升策略采样时的温度参数,增加策略多样性。这一技巧受到信息论中"熵"概念的启发,能延缓因策略过早收敛导致的熵崩溃现象,是稳定训练的关键参数,在实际应用中往往需要精细调整。
四、采样效率优化
- 课程学习难度分级
按任务难度分阶段设计训练样本,从易到难逐步提升难度。这一方法源自教育学中的"循序渐进"原则,在语言模型训练中被证明能显著加速收敛过程,减少训练时间。 - GFPO简短回答优先策略
优先选择简短且信息密度高的回答样本,提升单个token的训练价值。这一技巧受到"奥卡姆剃刀"原则启发,避免模型学习冗余表达,提高训练效率,特别适合对话系统优化。 - DRA-GRPO组内相似度对比
通过计算组内回答相似度筛选差异化样本,对多样性高的样本增加采样概率。这种方法借鉴了信息检索中的"多样性检索"思想,能有效提升训练样本的质量,避免模型过拟合常见模式。
五、回答长度控制优化
- DAPO长度惩罚机制
在损失函数中加入与生成长度相关的惩罚项,抑制模型生成过长回答。这一方法受到"简洁性原则"启发,避免模型陷入"长文本陷阱",在对话系统中尤为重要,能显著提升用户体验。 - DAPO Token-Level loss设计
在token级别设计损失函数,针对性消除模型对长回答的隐式偏好。这种方法比传统序列级长度控制更精细,能有效解决模型"贪长"问题,使生成内容更加精炼。 - Kimi K2预算控制技术
预先设定生成长度预算阈值,严格限制模型输出长度。这一技术类似于"字数限制",在需要精确控制输出长度的场景(如API响应)中非常实用,确保输出符合业务需求。 - LASER阶梯式奖励函数
根据生成长度分段设置阶梯式奖励,对符合目标长度的回答给予更高激励。这一方法借鉴了"目标导向"思想,能有效引导模型生成理想长度的回答,适用于需要严格控制输出长度的场景。 - DLER难度感知截断
结合问题难度动态调整截断长度,对复杂问题允许更长回答。这种方法体现了"因材施教"的理念,让模型能根据问题复杂度自适应调整回答长度,提升回答质量。
六、奖励函数设计优化 - RFT拒绝采样微调
R是reject,拒绝采样微调,通过拒绝低质量样本提升模型性能。这一方法在实践中被证明能有效过滤低质量样本,提高训练数据的质量,特别适合处理噪声较大的数据集。 - RLVR规则验证奖励函数
可用规则验证的奖励函数,用手工规则作为reward model。这种方法结合了领域知识和机器学习,在特定领域任务中能提供更准确的奖励信号,如代码生成、数学推理等任务。 - TTRL多数投票参考答案
使用无监督的多数投票结果作为"参考答案",减少人工标注成本。这一技术在大规模训练中特别有价值,能有效降低对高质量人工标注数据的依赖,同时保持奖励信号的可靠性。 - 基于生成模型的奖励函数
使用LLM模型进行奖励评估,对非结构化的回答进行奖励函数评估。这一方法利用大模型的推理能力,能更准确地评估复杂任务的回答质量,特别适合开放式问题的回答评估。
七、多任务/目标优化
- Multi-Task GRPO动态任务权重
动态调整任务权重,明确优化表现最差的任务的性能。这种方法借鉴了"短板理论",通过关注最弱环节提升整体性能,在多任务学习中被证明能显著提高模型的泛化能力。 - Kimi K2预训练知识保留
Pretrain loss(PTX),防止遗忘预训练阶段的知识。这一技术在微调过程中保留预训练损失项,通过多目标优化防止模型遗忘预训练阶段学到的通用知识,特别适合在特定领域微调时保持通用能力。
结语
说到底,这些tricks就像老工程师抽屉里的“私藏工具”——未必光鲜亮丽,但关键时刻总能救场。从策略探索的“大胆试错”,到奖励函数的“精打细算”,每个技巧背后都是对训练动态的细腻观察。不过别忘了,再好的技巧也得“看菜吃饭”:风控场景要稳,创意生成要野,没有放之四海皆准的银弹。下次训练卡壳时,不妨翻翻这份清单,说不定某个冷门trick,就成了你模型突破瓶颈的那把钥匙。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)