ICLR 2026 | UIUC:一行代码,终结大模型“过度思考”!
令。
在训练人工智能做数学题或复杂推理时,我们通常只告诉它“答案对不对”。这就像老师只给学生打勾或打叉,却不告诉学生解题步骤是否太啰嗦,或者思路偏了没。这就导致AI为了凑出正确答案,往往会“想太多”,生成很多废话,既浪费算力又慢。现有的解决方法通常是简单粗暴地“惩罚长答案”,但这容易把必要的推理步骤也砍掉,导致变笨。
研究背景:
目前的强化学习(RL)主要依赖可验证奖励(即答案是否正确),这种信号太粗糙了。它无法区分“简洁的正确答案”和“啰嗦的正确答案”,也无法给“这就做对了一半”的答案加分。为了让模型更像人类的高效思考者,现有的方法(如长度惩罚)往往以牺牲准确率为代价,这是一个亟待解决的难题。
本论文提出的模型框架:
为了解决该问题,本论文提出了Self-Aligned Reward (SAR) 框架。它利用困惑度(Perplexity) 的相对差异作为奖励信号,鼓励模型生成既紧扣问题又简洁的答案。实验表明,该方法在保持甚至提高准确率(+4%)的同时,大幅减少了模型的废话和算力消耗(-30%)。
一、论文基本信息

- 论文标题:SELF-ALIGNED REWARD: TOWARDS EFFECTIVE AND EFFICIENT REASONERS
- 作者姓名与单位:Peixuan Han (UIUC), Adit Krishnan (Amazon AWS) 等
- 论文链接:arXiv:2509.05489v1
二、主要贡献与创新
- 提出了SAR奖励机制:利用答案在“有无问题”条件下的困惑度差异,量化答案的质量与相关性。
- 无需外部奖励模型:完全基于模型自身的概率分布计算奖励,避免了训练额外Reward Model的开销。
- 实现了帕累托最优:在准确率和效率(长度)的权衡上,表现优于现有的长度惩罚或熵最小化方法。
- 细粒度的质量评估:SAR能区分冗余答案、部分正确答案和完全错误答案,提供比二元对错更丰富的信号。
三、研究方法与原理
核心思路:
模型认为:好的回答应该是“看了问题后觉得很自然,但不看问题觉得很突兀”。SAR通过计算答案在给定问题下的困惑度与单独答案的困惑度之差,来奖励那些高度依赖问题信息且不废话的生成内容。
【模型原理与数学推导】
论文的核心在于如何设计这个Self-Aligned Reward (SAR)。作者结合了标准的可验证奖励(Verifiable Reward, VR) 和 SAR。
-
基础定义:
令 qqq 为问题,aaa 为答案。困惑度(Perplexity, ppl)反映了模型生成这段话的“惊讶程度”,数值越低表示模型越有信心。- 条件困惑度 ppl(a∣q)ppl(a|q)ppl(a∣q):看到问题后,生成答案的困惑度。
- 独立困惑度 ppl(a)ppl(a)ppl(a):不看问题,直接生成该答案的困惑度。
-
SAR计算公式:
论文提出的SAR奖励 RSAR_{SA}RSA 计算如下:
RSA=clip(ppl(a)−ppl(a∣q)ppl(a),−1,1) R_{SA} = \text{clip}\left( \frac{ppl(a) - ppl(a|q)}{ppl(a)}, -1, 1 \right) RSA=clip(ppl(a)ppl(a)−ppl(a∣q),−1,1)- 公式解读:这个公式测量的是“有了问题之后,答案的确定性提升了多少”。
- 如果答案紧扣问题(如引用了题目中的数字),ppl(a∣q)ppl(a|q)ppl(a∣q) 会很低,而 ppl(a)ppl(a)ppl(a) 相对较高(因为没有上下文,这些数字很突兀),分子大,奖励高。
- 如果答案是废话或通用套话(如“让我们一步步思考”),无论有没有问题,ppl(a∣q)ppl(a|q)ppl(a∣q) 和 ppl(a)ppl(a)ppl(a) 都差不多,分子接近0,奖励低。
- 公式解读:这个公式测量的是“有了问题之后,答案的确定性提升了多少”。
-
最终奖励函数:
在强化学习(如PPO或GRPO算法)中,最终的奖励函数由正确性和SAR共同决定:
Rtotal=RVR(q,a,gt)+α⋅RSA R_{total} = R_{VR}(q, a, gt) + \alpha \cdot R_{SA} Rtotal=RVR(q,a,gt)+α⋅RSA
其中,RVRR_{VR}RVR 是二值的正确性奖励(对得1,错得0),α\alphaα 是调节系数。 -
直观理解:
如下图(参考文中图2)所示,红色标记的Token表示对 RSAR_{SA}RSA 贡献大,蓝色表示贡献小。- 高分Token:首次利用题目信息的Token(如题目中的具体数字)。
- 低分Token:重复的信息或废话。

四、实验设计与结果分析
实验设置:
- 数据集:GSM8k, MATH, NuminaMath (训练集); GSM-symbolic, AIME (测试集,用于验证泛化性)。
- 基础模型:Qwen3-1.7B/4B, Phi-3.5-mini, Gemma3-1B。
- 评测指标:准确率 (Accuracy)、平均响应长度 (Average Response Length)。
- 对比基线:PPO, GRPO (标准RL), GRPO-O1 (O1-pruner, 长度惩罚), GRPO-ER (Efficient Reasoner)。
对比实验结果:
在多个数据集的平均表现上,SA-GRPO (Self-Aligned GRPO) 取得了最好的效果。
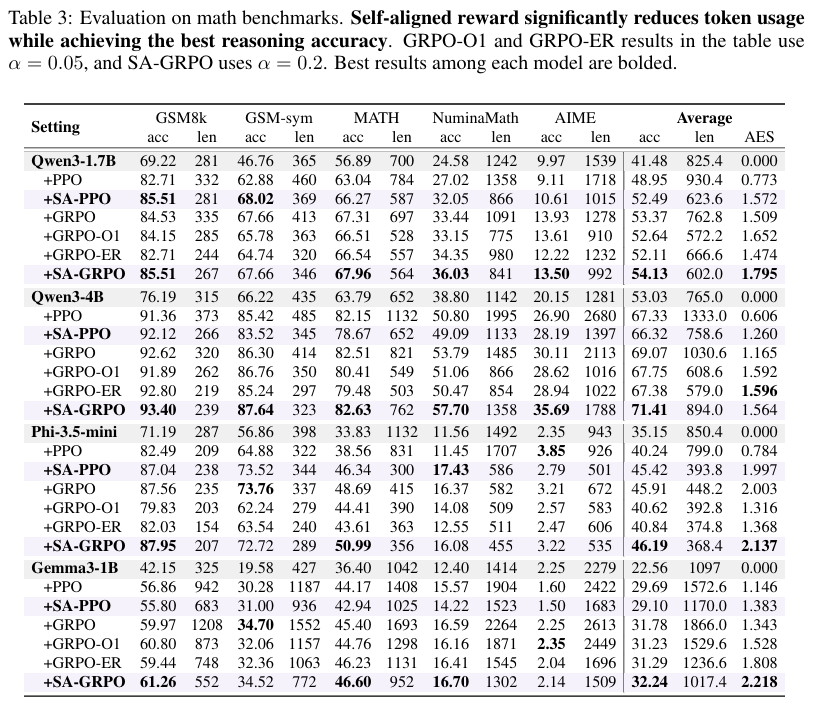
结果分析:
- 准确率与效率双赢:SA-GRPO在准确率上比标准GRPO高出约2-3个百分点,同时长度减少了约15%-30%。
- 优于长度惩罚:单纯惩罚长度(O1, ER)虽然能显著缩短答案,但往往会因为“少想了”而导致做错题。SAR通过奖励“有效信息”,在精简的同时保留了关键推理步骤。
可视化对比 (Pareto Frontier):
论文通过调整超参数 α\alphaα,绘制了准确率增益与长度减少的权衡图。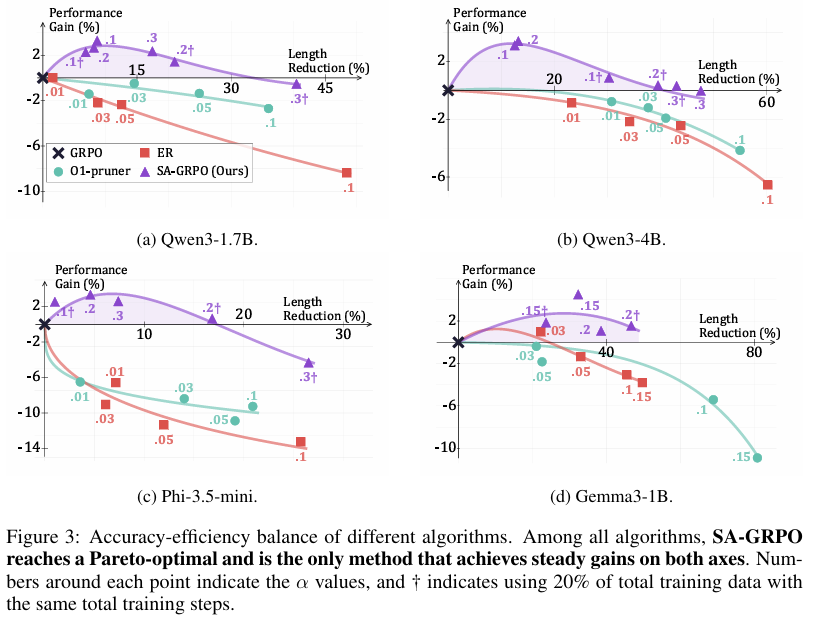
- SA-GRPO的曲线始终位于右上方:这意味着在相同的长度缩减下,SAR的方法能保持更高的准确率;或者在相同的准确率下,SAR生成的答案更短。这证明了其达到了帕累托最优。
消融实验:
论文验证了SAR中各个组件的重要性: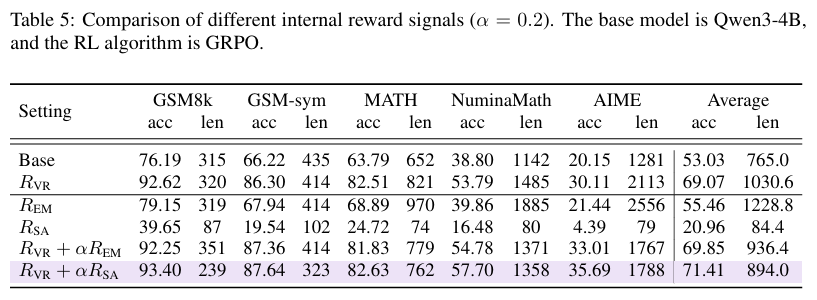
- 仅使用 RSAR_{SA}RSA (无正确性奖励):模型崩溃,生成极短且无意义的文本。说明可验证奖励(VR) 是基础。
- 使用熵最小化 (Entropy Min) 代替 SAR:准确率下降,且容易导致模型过度自信。说明相对困惑度差异比单纯的自信度更有效。
五、论文结论与评价
总结与结论:
本文提出了一种新颖的自对齐奖励(SAR),通过计算条件概率与非条件概率的差异,为大模型推理提供了一个细粒度、内容感知的内部反馈信号。理论和实验证明,SAR能够有效抑制模型生成冗余的“废话”,同时鼓励模型深度利用题目信息。这种方法成功地在强化学习训练中平衡了推理能力与计算效率,打破了以往“越聪明越啰嗦”的魔咒。
实际影响与启示:
- 降低推理成本:对于大规模部署的推理模型(如DeepSeek-R1类),减少30%的Token生成量意味着巨大的成本节约和更低的延迟。
- 新的RL范式:证明了除了外部Reward Model和Ground Truth之外,模型自身的统计特征(困惑度差异)可以作为高质量的监督信号,这为Self-Evolving(自我进化) 提供了新思路。
优缺点分析:
- 优点:
- 零额外训练成本:不需要训练额外的Reward Model,计算只涉及前向传播。
- 通用性强:适用于PPO、GRPO等多种RL算法,且在不同尺寸的模型上均有效。
- 抗Hack:相比于简单的长度惩罚,SAR更难被模型“钻空子”(例如输出极短的错误答案)。
- 缺点:
- 依赖基础能力:SAR是基于概率差的,如果基座模型本身对问题的理解很差(ppl分布混乱),该奖励可能失效。
- 计算开销:虽然不需要额外模型,但需要计算两次困惑度(有Condition和无Condition),在训练时的Forward阶段会有少量的计算增加。
对“记忆”的惩罚:SAR的一个有趣特性是它天然惩罚“死记硬背”。如果模型背下了一个答案,那么无论有没有问题,它的生成概率都很高,导致 RSAR_{SA}RSA 很低。这在数学推理中是好事,但在某些需要精确背诵知识的任务(如法条引用)中可能会有负面影响。逻辑推理的泛化:虽然在逻辑任务上表现不错,但SAR的核心假设是“答案紧密依赖于问题”。对于那些开放式创意写作或闲聊任务,这种强依赖假设可能不适用,因此该方法主要局限于强逻辑推理场景。超参数敏感性:文中展示了 α\alphaα 的调节对结果影响较大,实际应用中如何自动平衡 RVRR_{VR}RVR 和 RSAR_{SA}RSA 的权重是一个值得进一步研究的工程问题。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)