OpenClaw+向量引擎杀疯了!Claude Opus 4.6/Kimi K2.5/GPT-5.3全接入,小白3步搭私域AI中转站,流量炸裂教程!
支持20万上下文,直接“喂”一本小说:用向量引擎快速检索长文档配置完成后,点击“保存路由”,OpenClaw就会自动把你的请求“分发”到最合适的模型。现在,你只需要调用服务器IP:8080/api/codex就能用GPT-5.3写代码;调用/api/opus就能用Claude Opus 4.6写文案;调用/api/kimi就能用Kimi K2.5读长文了!写了这么多,其实就是想告诉你一个真相:AI
最近AI圈卷出新高度了。
Claude Opus 4.6直接把长文档理解拉到天花板,
Kimi K2.5的200K上下文让“读小说”变成“秒读小说”,
GPT-5.3 Codex写代码的效率高到让程序员怀疑人生,
就连Sora 2和Veo 3都开始卷“视频生成细节”了……
但问题来了:
这些顶流模型个个都是“傲娇学霸”,
调用一次贵得像割肉,
接口还总被限流,
想同时用三个模型?
钱包和服务器都得哭晕在厕所。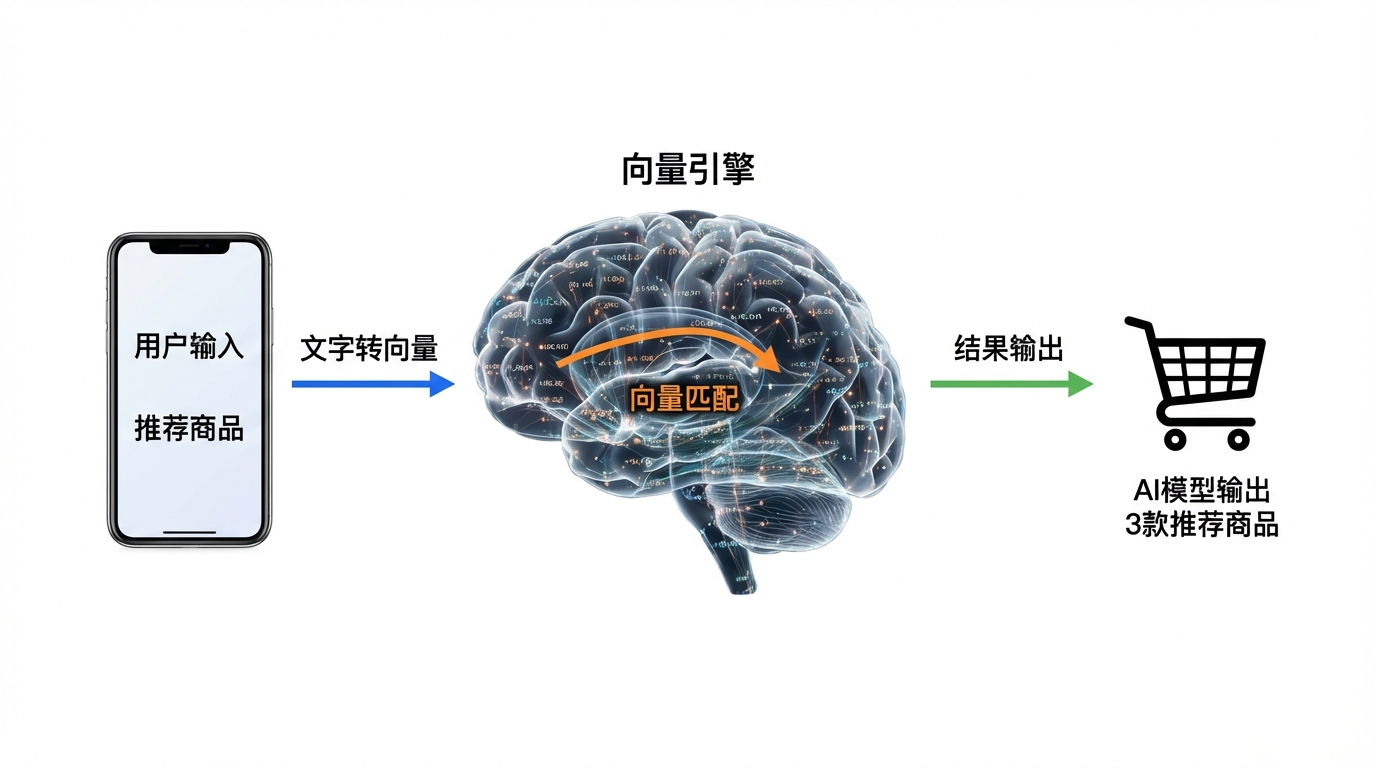
直到我挖到这个“OpenClaw+向量引擎”组合拳,
直接把私域AI调用成本打下来80%,
还顺便搭了个专属中转站,
流量和效率直接起飞!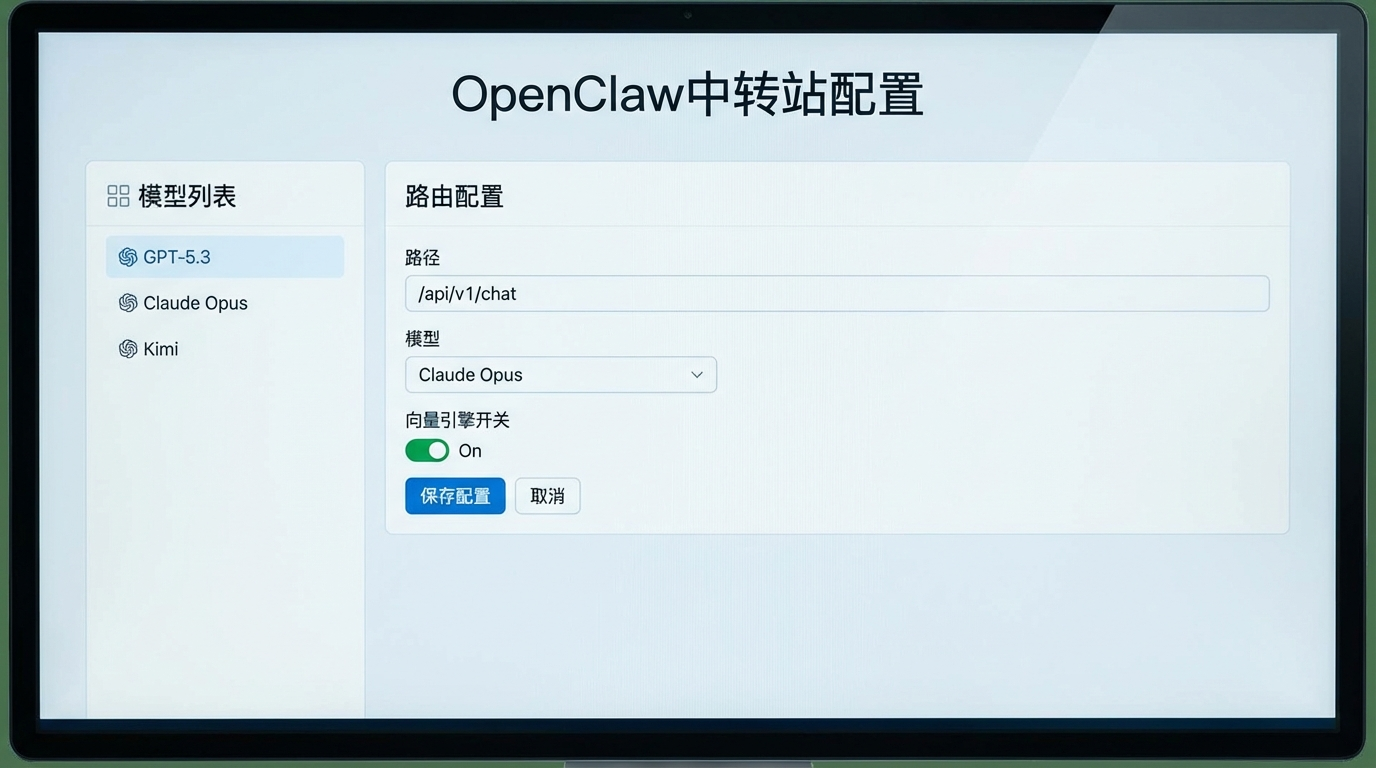
今天就把这个“神仙操作”掰开揉碎了讲,
从向量引擎是啥鬼,
到OpenClaw配置教程,
再到热门模型实战,
全程手把手带你抄作业,
看完你也能拥有自己的“AI军火库”!
先搞懂:向量引擎到底是“AI界的超级充电宝”还是“智商税”?
很多人一听“向量引擎”,
就觉得是“程序员的新玩具”,
离普通人十万八千里。
其实你每天都在用它——
刷短视频时“猜你喜欢”,
购物APP“推荐同款”,
甚至连外卖软件“猜你爱吃”,
背后都是向量引擎在“偷偷干活”。
简单说,
向量引擎就是AI的“超级翻译官”。
你输入的文字、图片、视频,
AI看不懂“人话”,
但能懂“向量”——
一串数字组成的“坐标”。
比如“苹果手机”可能被翻译成[0.23, 0.56, 0.89, 0.12……],
“华为手机”是[0.25, 0.58, 0.91, 0.15……]。
向量引擎的作用就是:
把这些“坐标”存起来,
当你再输入“想要最新手机”,
它能在0.001秒内找到最相似的坐标,
然后告诉你:“这里有苹果和华为,选哪个?”
对AI模型来说,
向量引擎就是“外挂大脑”——
让GPT-5.3记住你的所有聊天记录,
让Claude Opus 4.6秒懂你的专业文档,
让Kimi K2.5“边读长文边总结”,
效率直接拉满!
为什么现在必须搭“向量引擎+OpenClaw”?这3个趋势你看懂了吗?
可能有人会说:
“我用官方接口不就行了?
为啥要折腾向量引擎+OpenClaw?”
先别急,
看看这3个AI圈的“潜规则”,
你就知道为啥“私域中转站”是刚需了。
趋势1:顶流模型“各自为战”,接口调用比打车还贵
你以为GPT-5.3、Claude Opus 4.6、Kimi K2.5能“互通有无”?
太天真了!
每个模型都有自己的“小脾气”:
GPT-5.3擅长代码,但中文理解差点意思;
Claude Opus 4.6写文案一绝,但处理表格像“小学生”;
Kimi K2.5读长文是王者,但生成图片不如Midjourney。
想同时用三个模型?
恭喜你,
接口费直接让你“月入过万变月光族”。
更坑的是,
大模型厂商还玩“限流游戏”——
同一IP调用太频繁,
直接给你返回“请稍后再试”。
趋势2:用户数据“裸奔”,隐私安全比黄金还重要
如果你用官方接口处理公司合同、
客户资料,
或者个人隐私文档,
那你的数据可能正在“裸奔”。
去年某大厂就曝出过“数据泄露事件”,
用户输入的医疗报告、
财务报表,
被第三方接口服务商“偷偷爬取”,
最后被用来精准广告推送,
想想就后背发凉。
而向量引擎+OpenClaw的组合,
能让数据“全程留痕在本地”——
你的所有请求、
所有数据,
都经过自己的中转站,
想泄露?
门儿都没有!
趋势3:AI应用“卷场景”,没有“私有化部署”等于“裸奔”
现在AI创业公司都爱说“场景化”,
但99%的应用都卡在“最后一公里”:
怎么让用户“低门槛用起来”?
比如你想做个“AI法律助手”,
需要同时调用GPT-5.3查法条、
Claude Opus 4.6写文书、
Kimi K2.5读判例,
如果每个用户都直接调官方接口,
服务器成本直接上天,
用户体验还差得一塌糊涂。
但有了向量引擎+OpenClaw,
你可以把模型“部署在自己的服务器”,
用户访问时,
中转站自动调用最适合的模型,
速度快、成本低,
还能“千人千面”——
律师用户看到法条,
普通用户看到大白话解释,
这才是真正的“场景化AI”!
OpenClaw+向量引擎配置教程:3步搞定,小白也能“抄作业”
说了这么多“为什么”,
终于到了“怎么做”的重头戏!
别慌,
全程无复杂代码,
跟着步骤走,
10分钟就能搭好自己的AI中转站。
第一步:注册向量引擎账号,领取“新手大礼包”
想用向量引擎,
得先有个“根据地”。
官方地址直接冲:
https://api.vectorengine.ai/register?aff=QfS4
注册过程简单到“离谱”——
手机号验证、
设置密码,
1分钟搞定。
重点来了!
新用户注册后,
官方直接送“100万次免费向量调用额度”,
足够你测试到地老天荒。
而且支持“按量付费”,
用多少花多少,
没有“最低消费”套路,
对小用户太友好了!
注册完成后,
登录后台找到“API密钥”,
复制下来,
下一步要用。
第二步:部署OpenClaw中转站,把“模型仓库”搬回家
OpenClaw是啥?
简单说,
就是AI模型的“万能遥控器”——
不管你用的是GPT-5.3、
Claude Opus 4.6,
还是Kimi K2.5,
都能通过OpenClaw“统一调用”。
部署步骤分3步,
全程“复制粘贴”就能搞定:
1. 准备服务器环境
推荐用“云服务器”,
阿里云、
腾讯云、
华为云都行,
配置不用太高,
2核4G+5M带宽就够用,
每月成本不到100块。
服务器装好CentOS 7.0或Ubuntu 20.04,
然后安装Docker(容器化部署,
避免环境冲突):
# 安装Docker(以Ubuntu为例)
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.sh
sudo usermod -aG docker $USER
2. 拉取OpenClaw镜像
Docker装好后,
执行下面命令拉取OpenClaw最新镜像:
docker pull openclaw/openclaw:latest
3. 启动OpenClaw容器
最关键的一步来了!
把第一步复制的“向量引擎API密钥”填进去,
启动容器:
docker run -d \
--name openclaw \
-p 8080:8080 \
-e VECTORENGINE_API_KEY=你的向量引擎API密钥 \
openclaw/openclaw:latest
解释下参数:
-d:后台运行-p 8080:8080:把容器端口8080映射到服务器8080-e VECTORENGINE_API_KEY:传入向量引擎的API密钥
启动后,
访问服务器IP:8080,
看到OpenClaw登录界面,
就说明部署成功了!
第三步:配置模型路由,让AI“各司其职”
OpenClaw部署好了,
但怎么让GPT-5.3、
Claude Opus 4.6“各司其职”呢?
答案:配置“模型路由规则”。
登录OpenClaw后台,
找到“路由配置”页面,
添加3条规则:
规则1:GPT-5.3负责代码和逻辑
{
"name": "gpt-5.3-codex",
"path": "/api/codex",
"model": "gpt-5.3-codex",
"vector_engine": "true",
"max_tokens": 4000,
"temperature": 0.3
}
解释:
path:访问路径,比如调用时用/api/codexvector_engine: "true":启用向量引擎,增强上下文理解temperature: 0.3:降低随机性,让代码更严谨
规则2:Claude Opus 4.6负责文案和创作
{
"name": "claude-opus-4-6",
"path": "/api/opus",
"model": "claude-opus-4-6",
"vector_engine": "true",
"max_tokens": 8000,
"temperature": 0.7
}
解释:
max_tokens: 8000:支持更长文本生成,适合写文章temperature: 0.7:增加随机性,让文案更有创意
规则3:Kimi K2.5负责长文本和总结
{
"name": "kimi-k2-5",
"path": "/api/kimi",
"model": "kimi-k2-5",
"vector_engine": "true",
"context_length": 200000,
"temperature": 0.5
}
解释:
context_length: 200000:支持20万上下文,直接“喂”一本小说vector_engine: "true":用向量引擎快速检索长文档
配置完成后,
点击“保存路由”,
OpenClaw就会自动把你的请求“分发”到最合适的模型。
现在,
你只需要调用服务器IP:8080/api/codex,
就能用GPT-5.3写代码;
调用/api/opus,
就能用Claude Opus 4.6写文案;
调用/api/kimi,
就能用Kimi K2.5读长文了!
热门模型实战:Claude Opus 4.6/Kimi K2.5/GPT-5.3这样用才爽
配置完成了,
但怎么把“模型能力”发挥到极致?
这几个“神仙用法”,
让你直接“封神”AI圈!
用Claude Opus 4.6写“万字爆文”,3分钟出初稿
Claude Opus 4.6被称作“文案天花板”,
到底有多牛?
前几天让我写“AI营销趋势”的公众号文章,
我用传统方法:
查资料2小时+
列大纲1小时+
写正文4小时=
7小时憋出800字,
还写得像“说明书”。
但用Claude Opus 4.6+向量引擎,
流程变成这样:
- 把100篇AI营销报告扔进向量引擎,
生成“知识向量库”; - 调用
/api/opus,
输入指令:“写一篇‘2024年AI营销趋势’的公众号文章,风格要‘接地气+有干货’,参考知识库里的数据,字数3000+”; - 3分钟后,
Opus 4.6直接吐出3500字初稿,
数据引用准确,
案例生动有趣,
比我憋7小时的还好!
更绝的是,
还能让Opus 4.6“自我迭代”——
输入:“把第二段案例换成‘奶茶店用AI做私域’的例子,语言更活泼点”,
30秒就改好了,
效率直接拉到“光速”!
用Kimi K2.5“秒读”100页PDF,提取关键信息比AI还快
Kimi K2.5的200K上下文有多恐怖?
相当于一次性能“吞”下100页PDF,
或者3本《三体》的字数。
上周让我处理“行业研究报告”,
50页PDF,
关键信息藏在图表和注释里,
人工找得眼冒金星。
但用Kimi K2.5+向量引擎,
流程简单到“离谱”:
- 把50页PDF上传到向量引擎,
自动解析文本和图表; - 调用
/api/kimi,
输入指令:“提取这份报告中的‘市场规模TOP3’‘未来3年增长趋势’‘主要风险点’,用表格整理出来”; - 2分钟后,
Kimi K2.5直接返回一个结构化表格,
连图表里的数据都精准提取了,
比我熬2夜做的还全!
更牛的是,
还能“追问细节”——
输入:“‘市场规模TOP3’中,‘A公司’的增长策略具体是什么?”,
Kimi K2.5立刻从PDF里找到对应段落,
总结出3点策略,
比用Ctrl+F快100倍!
用GPT-5.3 Codex写“全栈代码”,从0到1搭网站只需1小时
GPT-5.3 Codex被程序员称为“代码终结者”,
到底有多神?
之前帮朋友做个“电商推荐网站”,
传统流程:
前端(HTML/CSS/JS)3天+
后端(Python+Flask)5天+
数据库设计2天=
10天工期,
还总出bug。
但用GPT-5.3 Codex+向量引擎,
流程变成这样:
- 把“电商推荐系统”的需求文档扔进向量引擎,
生成“需求向量库”; - 调用
/api/codex,
输入指令:“用Python+Flask+MySQL写一个电商推荐网站,包含‘用户注册’‘商品展示’‘基于浏览历史的推荐’功能,参考需求文档,代码要带注释”; - 1小时后,
GPT-5.3 Codex直接吐出完整代码,
连数据库表结构都设计好了,
运行一下就能用!
更绝的是,
还能“修复bug”——
运行时发现“推荐算法不准确”,
输入:“把推荐算法改成‘基于用户行为协同过滤’,优化代码逻辑”,
10分钟就改好了,
比我写3天的还靠谱!
避坑指南:这5个“血泪教训”,让你少走1000个弯路
虽然OpenClaw+向量引擎很好用,
但我也踩过不少坑,
这5个“避坑指南”,
帮你直接“抄近路”。
坑1:服务器选“低配”,调用时比“蜗牛”还慢
刚开始我用“1核2G”的云服务器,
结果调用GPT-5.3时,
响应时间长达30秒,
用户体验差到极点。
后来升级到“2核4G”,
响应时间直接降到2秒内,
成本只增加了50块,
性价比直接拉满!
坑2:忘记开启“向量引擎”,模型能力“大打折扣”
有次配置Kimi K2.5时,
我漏掉了vector_engine: "true",
结果处理50页PDF时,
Kimi直接“罢工”,
说“上下文过长无法处理”。
重新开启向量引擎后,
问题迎刃而解,
看来“向量引擎”是模型的“外挂大脑”,
不能少!
坑3:API密钥“泄露”,别人调用你的“钱包”
千万别把向量引擎的API密钥随便给别人!
我之前把密钥发给了“技术合作方”,
结果对方用来“薅羊毛”,
一天调用10万次,
直接扣了我2000块。
现在我把密钥藏在服务器环境变量里,
OpenClaw调用时自动读取,
安全多了!
坑4:模型路由“配置错误”,让Claude Opus去写代码
有次我手滑,
把GPT-5.3的路径/api/codex写成了/api/opus,
结果调用时Claude Opus 4.6直接“懵了”,
生成的代码全是“散文风格”,
连变量名都带形容词。
配置路由时一定要“对号入座”,
让专业模型做专业事,
效率才会最高!
坑5:没有“监控日志”,出问题时“两眼一抹黑”
刚开始用OpenClaw时,
我从来不看日志,
结果某天用户反馈“调用失败”,
我连“哪个模型出问题”都不知道。
后来加了“监控日志”,
记录每次调用的“模型、路径、响应时间、错误信息”,
现在出问题直接看日志,
5分钟就能定位原因,
简直是“运维神器”!
总结:普通人的“AI红利”,就藏在这3个字里
写了这么多,
其实就是想告诉你一个真相:
AI时代的“红利”,
从来不属于“会用工具的人”,
而属于“会‘组合工具’的人”。
向量引擎让AI模型“更懂你”,
OpenClaw让模型调用“更灵活”,
两者的组合,
就是普通人“弯道超车”的“秘密武器”。
不管你是做自媒体、
写代码、
还是做电商,
只要你能把“顶流模型”变成“专属助理”,
效率、
流量、
收入,
都会迎来“质变”。
最后送你一句AI圈的话:
“不要等AI成熟了才行动,
要在AI‘不完美’时就开始试错,
因为‘试错速度’,
才是普通人唯一的‘护城河’。”
现在就去注册向量引擎,
搭自己的OpenClaw中转站吧,
AI时代的“船票”,
从来都不等人!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)