黑马大模型RAG与Agent智能体实战教程LangChain提示词——4、提示词工程(Zero-Shot 零样本思想、Few-Shot 少样本思想、金融文本分类)Few Shot、Zero Shot
import os"""金融文本分类任务示例:1. 使用 FewShot 方式向模型展示文本分类任务的示例2. 对4段金融文本进行分类3. 分类类别:['新闻报道','公司公告','财务公告','分析师报告']"""# 1. 加载环境变量raise ValueError("未在环境变量或 .env 中找到 API_KEY,请先配置后再运行。")# 2. 初始化客户端# 3. 构建 FewShot
教程:https://www.bilibili.com/video/BV1yjz5BLEoY
代码:https://github.com/shangxiang0907/HeiMa-AI-LLM-RAG-Agent-Dev
文章目录
提示词工程-01、大模型prompt工程指南
介绍

技巧一:详细的描述

技巧二:让模型充当某个角色

技巧三:使用分隔符标明输入的不同部分

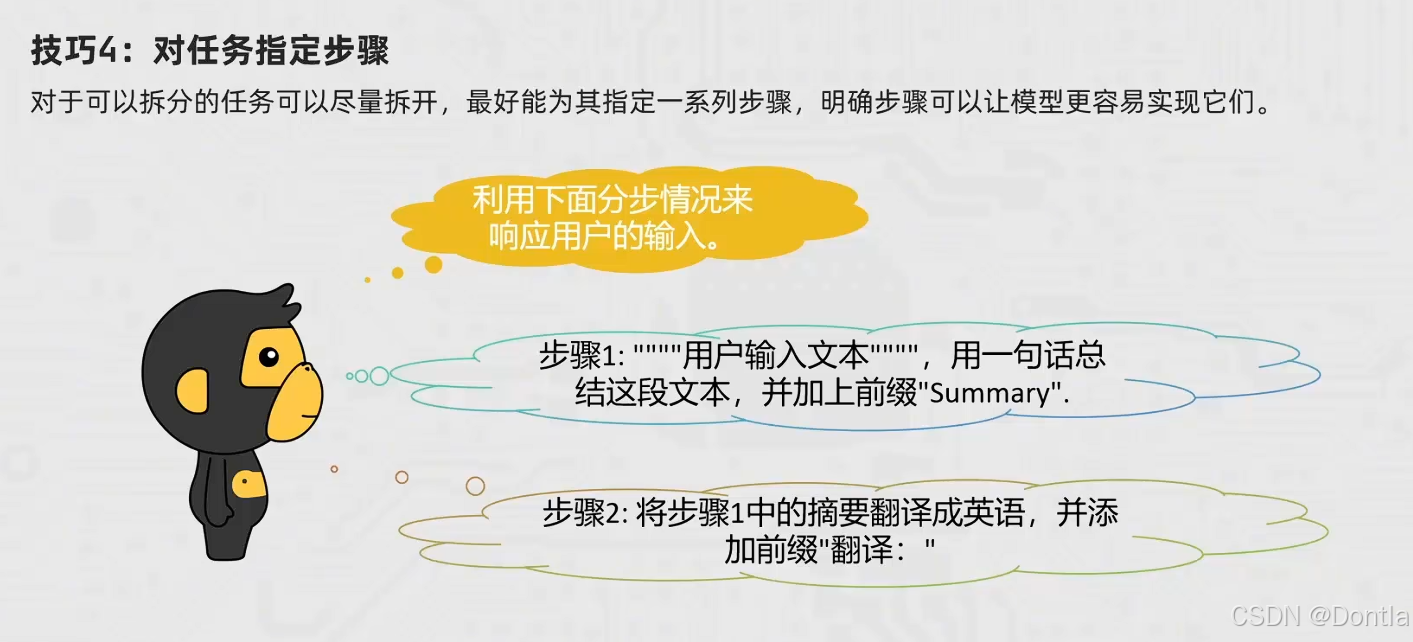
技巧四:对任务指定步骤
技巧五:提供例子

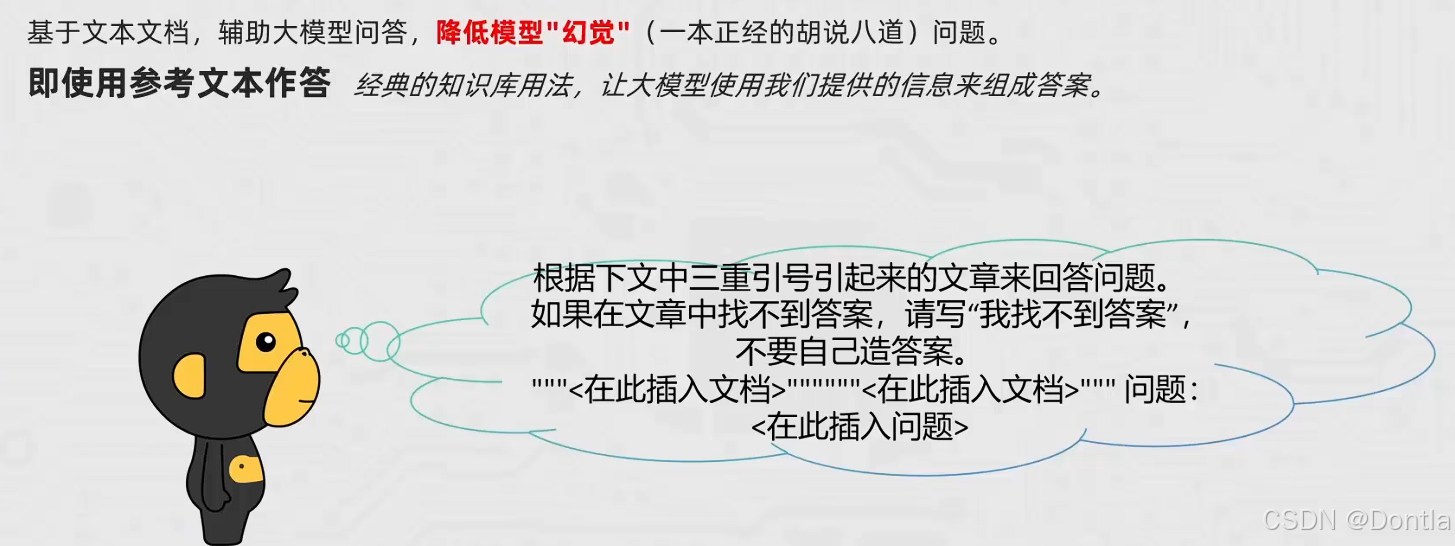
技巧六:使用参考文本作答
总结

提示词工程-02、提示词优化案例介绍和零样本少样本思想
案例介绍


Zero-Shot 零样本思想
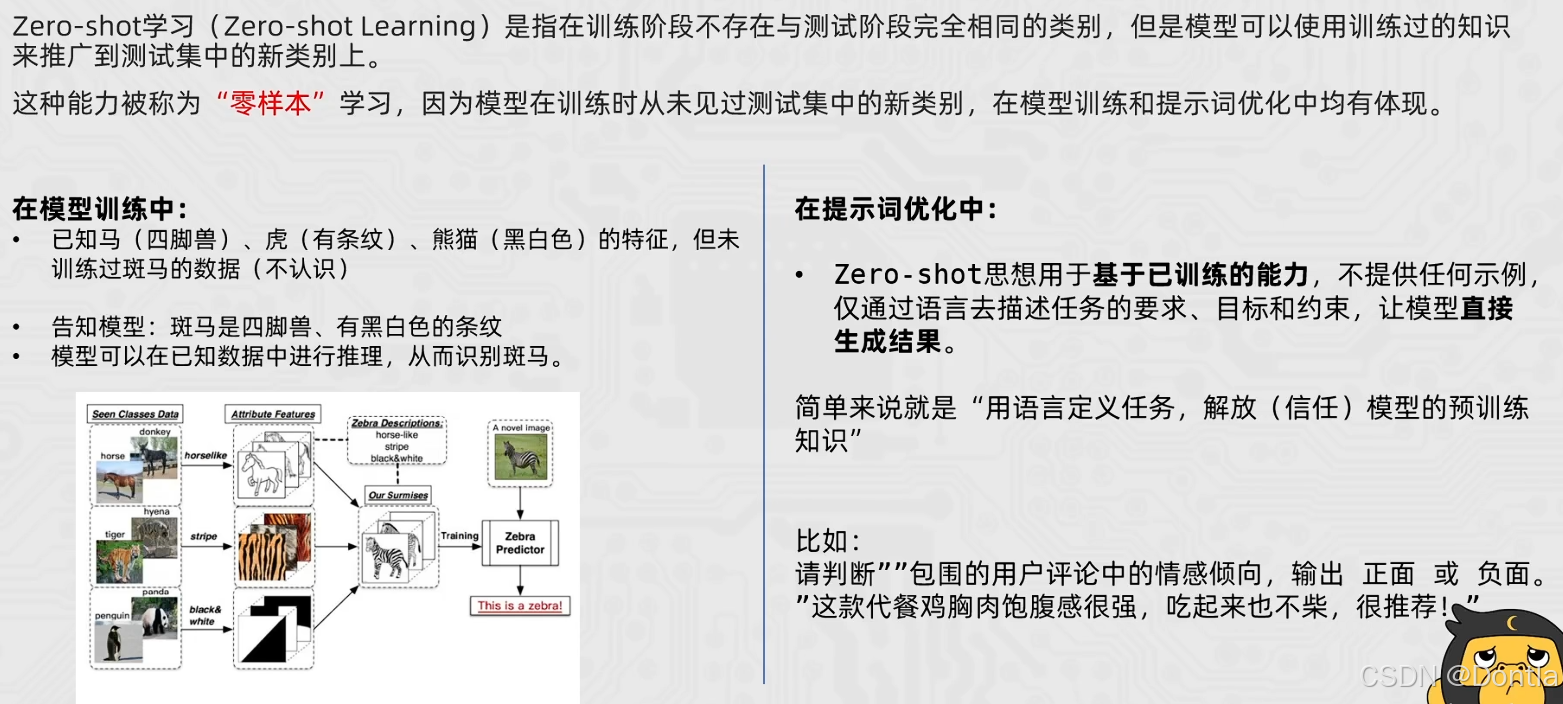
Zero-Shot 少样本思想
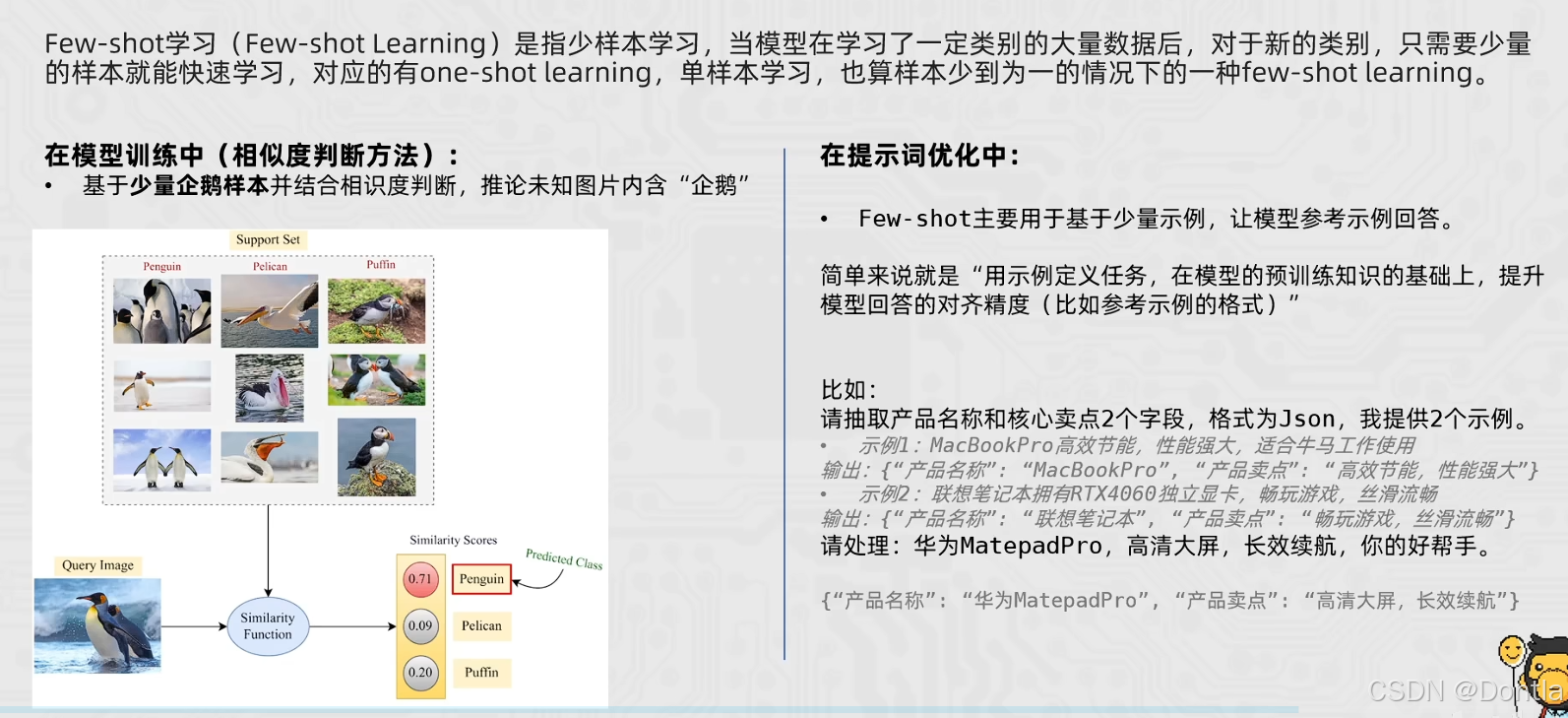
总结

提示词工程-03、提示词优化案例_金融文本分类任务
→提示词:帮我新建代码05,代码要完成一个金融文本分类任务,具体如图,帮我编写代码


←AI回复
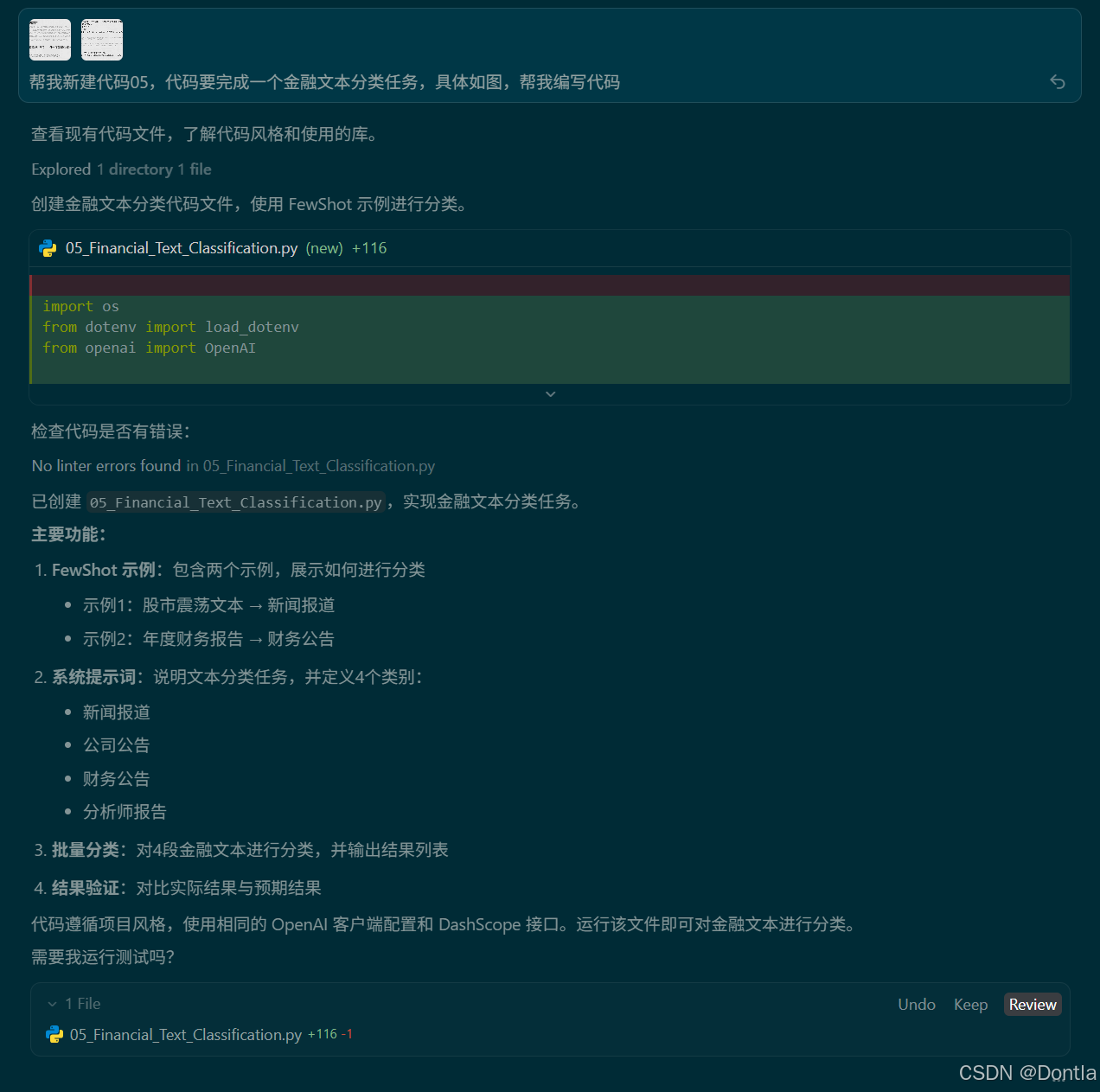
05_Financial_Text_Classification.py
import os
from dotenv import load_dotenv
from openai import OpenAI
def main():
"""
金融文本分类任务示例:
1. 使用 FewShot 方式向模型展示文本分类任务的示例
2. 对4段金融文本进行分类
3. 分类类别:['新闻报道','公司公告','财务公告','分析师报告']
"""
# 1. 加载环境变量
load_dotenv()
api_key = os.getenv("API_KEY")
if not api_key:
raise ValueError("未在环境变量或 .env 中找到 API_KEY,请先配置后再运行。")
# 2. 初始化客户端
client = OpenAI(
api_key=api_key,
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
# 3. 构建 FewShot 示例和任务说明
system_prompt = """你是一个专业的金融文本分类助手。你的任务是对给定的金融文本进行分类。
文本分类任务是指:根据文本的内容和特征,将文本归类到预定义的类别中。
你需要将文本分类到以下4个类别之一:
- 新闻报道:描述金融市场动态、政策变化、市场波动等新闻性内容
- 公司公告:公司发布的关于业务活动、收购、合作等公告信息
- 财务公告:涉及公司财务状况、资产负债表、现金流等财务数据的内容
- 分析师报告:分析行业趋势、投资机会、市场预测等分析性内容
请严格按照以下格式输出:只输出类别名称,不要输出其他内容。
下面是一些示例:"""
# FewShot 示例
fewshot_examples = [
{
"role": "user",
"content": "\"今日,股市经历了一轮震荡,受到宏观经济数据和全球贸易紧张局势的影响。投资者密切关注美联储可能的政策调整,以适应市场的不确定性。\"是['新闻报道','公司公告','财务公告','分析师报告']里的什么类别?"
},
{
"role": "assistant",
"content": "新闻报道"
},
{
"role": "user",
"content": "\"本公司年度财务报告显示,去年公司实现了稳步增长的盈利,同时资产负债表呈现强劲的状况。经济环境的稳定和管理层的有效战略执行为公司的健康发展奠定了基础。\"是['新闻报道','公司公告','财务公告','分析师报告']里的什么类别?"
},
{
"role": "assistant",
"content": "财务公告"
}
]
# 4. 待分类的文本
texts_to_classify = [
"今日,央行发布公告宣布降低利率,以刺激经济增长。这一降息举措将影响贷款利率,并在未来几个季度内对金融市场产生影响。",
"ABC公司今日发布公告称,已成功完成对XYZ公司股权的收购交易。本次交易是ABC公司在扩大业务范围、加强市场竞争力方面的重要举措。据悉,此次收购将进一步巩固ABC公司在行业中的地位,并为未来业务发展提供更广阔的发展空间。详情请见公司官方网站公告栏",
"公司资产负债表显示,公司偿债能力强劲,现金流充足,为未来投资和扩张提供了坚实的财务基础。",
"最新的分析报告指出,可再生能源行业预计将在未来几年经历持续增长,投资者应该关注这一领域的投资机会"
]
# 5. 对每段文本进行分类
results = []
for text in texts_to_classify:
# 构建消息列表
messages = [
{"role": "system", "content": system_prompt},
*fewshot_examples, # 添加 FewShot 示例
{
"role": "user",
"content": f"\"{text}\"是['新闻报道','公司公告','财务公告','分析师报告']里的什么类别?"
}
]
# 发送请求
completion = client.chat.completions.create(
model="qwen3-max",
messages=messages,
stream=False,
)
# 获取分类结果
classification = completion.choices[0].message.content.strip()
results.append(classification)
print(f"文本: {text[:50]}...")
print(f"分类结果: {classification}\n")
# 6. 输出最终结果列表
print("=" * 60)
print("最终分类结果:")
print(f"{results}")
print("=" * 60)
# 7. 验证结果是否符合预期
expected_results = ['新闻报道', '公司公告', '财务公告', '分析师报告']
print("\n预期结果:", expected_results)
print("实际结果:", results)
if results == expected_results:
print("✓ 分类结果与预期一致!")
else:
print("⚠ 分类结果与预期不完全一致")
if __name__ == "__main__":
main()
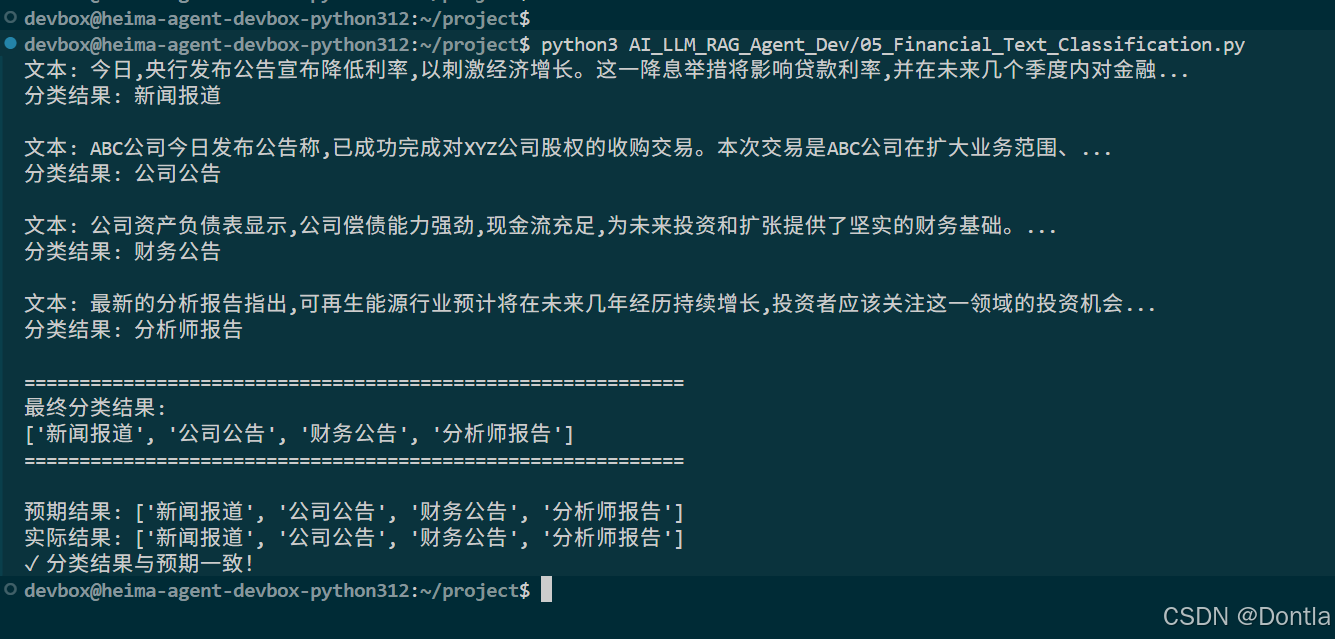
运行代码
python3 AI_LLM_RAG_Agent_Dev/05_Financial_Text_Classification.py
ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ
ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献427条内容
已为社区贡献427条内容

所有评论(0)