SkyWalking 消费积压 6 亿条:一次 Kafka 分区倾斜的深度复盘
摘要 当SkyWalking的Kafka消费积压6亿条消息时,紧急扩容分区无效,排查发现数据倾斜严重,少数分区承担了绝大部分流量。深入源码发现,Agent上报数据时固定以实例名作为Kafka消息的Key,导致相同实例的数据始终路由到同一分区。解决方案包括:1)紧急降低采样率减少数据量;2)修改源码将Key设为null,使Kafka均匀分配数据。最终通过优化配置和源码修复解决了积压问题,保障了系统稳
当你发现 SkyWalking 的 Kafka 消费积压了 6 亿条消息,你的第一反应是什么?
A. 扩容机器 B. 加分区 C. 提桶跑路 D. 深呼吸,打开源码
如果你选了 C,说明你很有生活智慧。但作为一个有职业素养的工程师,我选了 B,然后发现不管用,最后被迫选了 D。
这篇文章,就是从 6 亿积压到源码级定位根因的完整复盘。
一、问题现象
1. 告警发现
某天早上打开监控大盘,发现 SkyWalking 对应的 Kafka 消费组积压量直线飙升,查看近 7 天和近 16 天的趋势图,积压量已经突破了 6 亿条。


此时的心情可以用四个字形容:大事不妙。
2. 直观感受
- 日志查询严重延迟,研发同学反馈"查不到最新日志"
- 链路追踪页面数据滞后严重,几乎等于"瞎了"
- 积压量还在持续增长,完全没有收敛的趋势
6 亿条消息是什么概念?如果把每条消息当成一粒米,大概可以铺满 3 个篮球场。当然这个比喻没什么用,但至少说明——量很大。
二、排查现场
1. 第一反应:扩 Kafka 分区
既然消费不过来,最直觉的想法就是——加分区,提升并行消费能力。
docker exec -it kafka-broker bash
# 进入容器后,先 unset JVM 参数,避免干扰命令行工具
unset JAVA_TOOL_OPTIONS
# 查看当前分区情况
kafka-topics.sh \
--bootstrap-server 10.0.0.1:9092 --describe \
--topic skywalking-segments
# 批量扩容所有 SkyWalking 相关 topic 到 12 分区
for t in skywalking-segments skywalking-logs skywalking-metrics \
skywalking-meters skywalking-profilings skywalking-logs-json \
skywalking-managements; do
echo "Expanding topic: $t"
kafka-topics.sh \
--bootstrap-server 10.0.0.1:9092 \
--alter \
--topic "$t" \
--partitions 12
done
扩完分区,满怀期待地等了一会儿……
2. 扩分区后:积压依旧,而且更扎心了
扩分区后继续观察,积压不仅没缓解,还暴露了一个更深层的问题——分区数据严重倾斜:
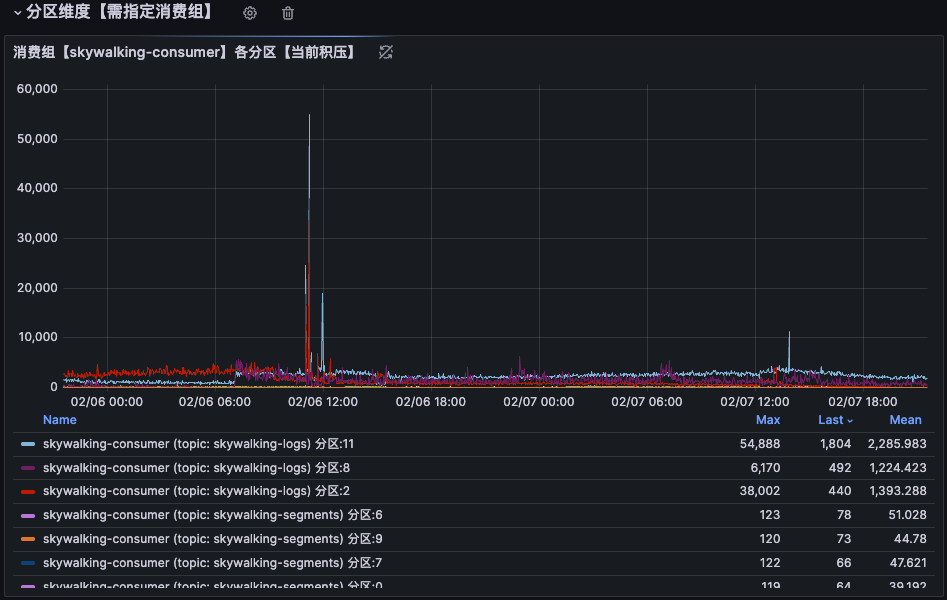
12 个分区中,Partition-2、Partition-8、Partition-11 三个分区的数据量远远大于其他分区。其他分区基本在"摸鱼",这三个分区在"996"。
加分区就像给高速公路加车道,但如果所有车都只走最左边三条道,加再多车道也是白搭。
3. 查看 ES 写入情况
SkyWalking OAP 最终会将数据写入 Elasticsearch,看一下 ES 的写入线程池状态:
GET /_cat/thread_pool/write?v
| 节点 | active | queue | rejected |
|---|---|---|---|
| node-03 | 8 | 118 | 0 |
| node-02 | 8 | 15 | 0 |
| node-01 | 0 | 0 | 0 |
ES 写入同样极度不均衡:node-03 的写入队列堆积了 118 个任务,node-01 完全空闲。同时发现 node-03 的 CPU 使用率也明显偏高。
整个 ES 集群是 3 节点、8C16G 的配置。三个节点的工作状态可以形象地概括为:一个在拼命、一个在划水、一个在睡觉。
来看一眼 ES 机器的监控大盘,画面感更直接:

CPU、负载、写入压力全部集中在少数节点上,和 Kafka 分区倾斜的表现完全吻合——数据从源头就歪了,下游自然跟着歪。
4. 紧急止血:清理积压消息
排查当天上午,积压已超过 6 亿条。先删除了积压最严重的 skywalking-segments topic 数据,但积压仍在持续增长。
下午,决定清理全部积压消息,清理后日志查询恢复正常。

但这只是"止血",不是"治病"。核心问题仍然存在——为什么数据会倾斜到少数几个分区?
三、原因分析
1. 定位瓶颈:segments 才是大头
从多张监控图中可以明确看到:积压主要集中在 skywalking-segments 这个 topic 上。
这里要科普一下:skywalking-segments 存储的是链路追踪数据(Trace Segments),并不是日志(Logs)。链路数据的量级通常远大于日志,因为每一次 RPC 调用、每一个 SQL 执行、每一次 HTTP 请求都会产生 Span。
2. 深入源码:真凶浮出水面
虽然通过降低采样率临时解决了问题(详见下方方案一),但工程师的"强迫症"不允许我就这样放过它。抽空翻了一下 SkyWalking Agent 的源码,直接定位了根因。
Agent 上报数据到 Kafka 依赖的是 kafka-reporter-plugin 这个插件,项目结构如下:
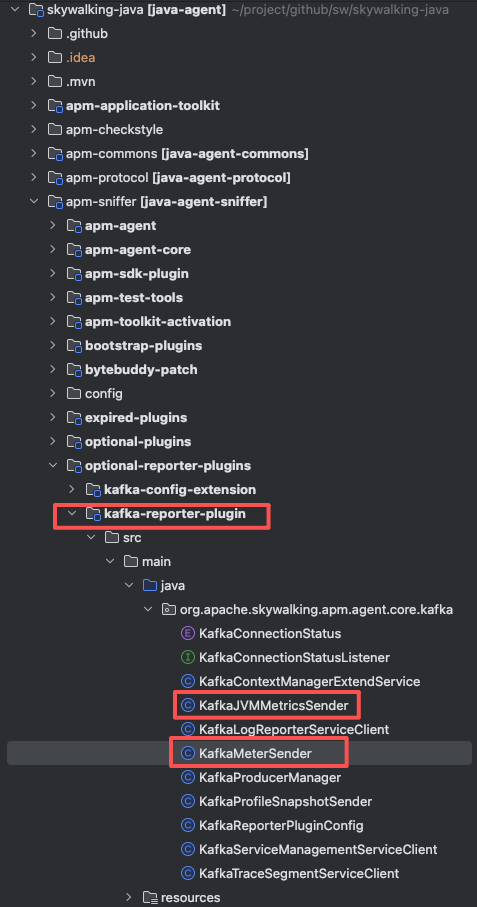
代码量不多,关键的发送类一眼就能锁定。我们看其中 KafkaMeterSender 的核心发送逻辑:
@OverrideImplementor(MeterSender.class)
public class KafkaMeterSender extends MeterSender
implements KafkaConnectionStatusListener {
private String topic;
private KafkaProducer<String, Bytes> producer;
@Override
public void send(Map<MeterId, BaseMeter> meterMap,
MeterService meterService) {
if (producer == null) {
return;
}
MeterDataCollection.Builder builder =
MeterDataCollection.newBuilder();
transform(meterMap, meterData -> {
builder.addMeterData(meterData);
});
// 注意看这里:key 固定为实例名称!
producer.send(new ProducerRecord<>(
topic,
Config.Agent.INSTANCE_NAME, // <-- 关键:key = 实例名
Bytes.wrap(builder.build().toByteArray())
));
producer.flush();
}
}
看到问题了吗? ProducerRecord 的第二个参数是 key,而这里 key 被固定设置为 Config.Agent.INSTANCE_NAME(即服务实例名称)。
3. 根因:Kafka 分区策略 + 固定 Key = 数据倾斜
Kafka 的分区路由机制是这样的:
| 场景 | 分区策略 | 结果 |
|---|---|---|
| key = null | 轮询(Round Robin) | 数据均匀分布 ✅ |
| key != null | hash(key) % partitionCount | 相同 key 始终路由到同一分区 |
由于 key = INSTANCE_NAME,同一个服务实例的所有数据会始终被路由到同一个分区。
而在实际生产环境中,各服务实例的流量差异巨大——流量大的实例疯狂往同一个分区灌数据,流量小的实例对应的分区却很清闲。最终导致:
- 少数分区承担了绝大部分数据 → 消费速度跟不上生产速度 → 积压
- 大部分分区基本空闲 → 消费者线程在"带薪摸鱼"
这就好比食堂打饭,12 个窗口只有 3 个窗口排满了人,其他 9 个窗口的阿姨在聊天。你加再多窗口,排队的人还是往那 3 个窗口挤。
四、解决方案
方案一:降低 Agent 采样率(紧急止血)
研发同学最关心的是日志的实时性,链路追踪数据的优先级相对较低。在不扩容机器的前提下,先从采集端"做减法":
# 每 3 秒最多采样 100 条链路(默认值 -1,表示全量采集)
agent.sample_n_per_3_secs=${SW_AGENT_SAMPLE:100}
# 单个 Span 中最大 TraceSegmentRef 数量(默认 500 → 调整为 50)
agent.trace_segment_ref_limit_per_span=${SW_TRACE_SEGMENT_LIMIT:50}
# 单个 Segment 中最大 Span 数量(默认 300 → 调整为 30)
agent.span_limit_per_segment=${SW_AGENT_SPAN_LIMIT:30}
三个参数一调,链路数据的写入量直接降低了 90% 以上。简单粗暴,但有效。
调整后观察近 6 天的消费情况:
- 消费积压趋势平稳,无新增积压
- 分区间的数据分布也趋于均匀(因为整体量下来了)
截止 2 月份持续观察,未再出现新的积压。
方案二:修改 Agent 源码,修复分区倾斜(根治方案)
既然知道了根因是 key = INSTANCE_NAME 导致的 hash 倾斜,解决思路就很清晰了:
- 方案 A:将 key 设为
null,让 Kafka 使用轮询策略均匀分配 - 方案 B:使用随机 key 或自定义分区器,实现更灵活的负载均衡
具体做法:Fork skywalking-java 仓库,修改 kafka-reporter-plugin 中的 ProducerRecord 构造逻辑,将 key 置为 null 或使用随机值,然后自行打包部署验证。
改动量其实很小,核心就是把
Config.Agent.INSTANCE_NAME换成null,一行代码的事儿。但从发现问题到定位根因,这个过程才是最有价值的。
五、总结与反思
1. 时间线回顾
| 时间 | 动作 | 效果 |
|---|---|---|
| D+0 上午 | 发现 6 亿积压,尝试扩 Kafka 分区 | 无效 ❌ |
| D+0 下午 | 清理全部积压消息 | 临时恢复 ✅ |
| D+5 | 调整 Agent 采样率,降低 90% 写入量 | 积压消除 ✅ |
| D+30 | 分析源码定位根因:固定 key 导致分区倾斜 | 找到根因 ✅ |
| 后续 | 修改源码打包验证(进行中,后续会补充结论) | 根治方案 🔧 |
2. 经验教训
- 扩分区不是万能药:如果数据本身存在倾斜,扩分区只是增加了空闲分区的数量,对缓解热点分区毫无帮助
- Kafka 的 key 设计至关重要:key 决定了分区路由,不恰当的 key 选择会直接导致数据倾斜。除非有明确的顺序性需求,否则优先考虑
nullkey(轮询) - 先止血,再治病:线上问题首先保证业务可用,然后再从容地追根溯源
- 源码面前,了无秘密:当文档和经验都解释不了问题时,打开源码往往能在几分钟内找到答案
3. 举一反三
这个问题不仅限于 SkyWalking,所有使用 Kafka 的场景都可能遇到类似的分区倾斜问题。建议大家对自己项目中的 Kafka Producer 做一次 key 策略审查:
key是否固定?是否会导致数据集中到少数分区?- 是否真的需要按 key 保证顺序?如果不需要,考虑使用
nullkey - 分区数是否与消费者数量匹配?
如果这篇文章对你有帮助,或者你也踩过类似的坑,欢迎点赞、收藏,方便下次遇到 Kafka 积压时快速翻出来 “抄作业”。
毕竟,能从 6 亿积压里翻出一个 one-line fix 的文章,值得你一个小小的点赞 👍

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)