Flume概述与基础
Flume概述
日志收集是大数据的基石。
许多公司的业务平台每天都会产生大量的日志数据。收集业务日志数据,供离线和在线的分析系统使用,正是日志收集系统的要做的事情。高可用性,高可靠性和可扩展性是日志收集系统所具有的基本特征。
目前常用的开源日志收集系统有Flume, Scribe等。 Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,目前已经是Apache的一个子项目。Scribe是Facebook开源的日志收集系统,它为日志的分布式收集,统一处理提供一个可扩展的,高容错的简单方案。
介绍
网址:
官方文档:https://flume.apache.org/FlumeUserGuide.html
下载地址:http://archive.apache.org/dist/flume/
官方介绍:
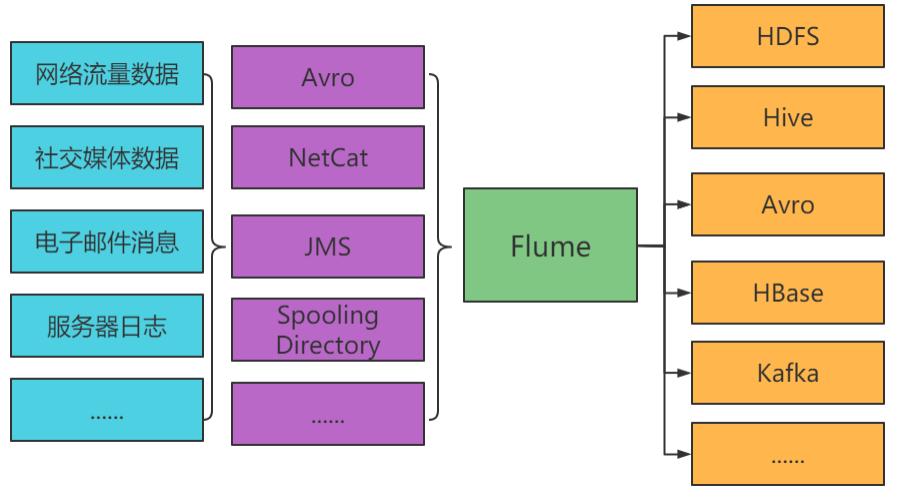
1.Apache Flume是一个分布式、可靠和可用的系统,用于有效地收集、聚合和将大量日志数据从许多不同的来源转移到集中式数据存储。
2.Apache Flume的使用不仅限于日志数据聚合。 由于数据源是可定制的, Flume可以用来传输大量的事件数据,包括但不限于网络流量数据、社交媒体生成的数据、电子邮件消息和几乎任何可能的数据源。
架构
-
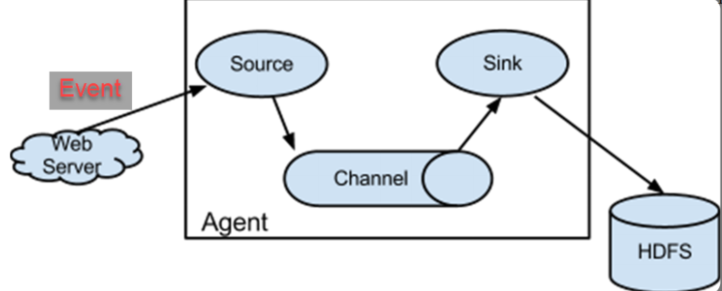
Agent Agent 是一个 JVM 进程,它以事件的形式将数据从源头送至目的。 Agent 主要有 3 个部分组成: Source 、 Channel 、Sink。
-
Source Source 是负责接收数据到 Flume Agent 的组件。Source组件可以处理各种类型、各种格式的日志数据,包括avro、 thrift 、 exec 、 jms 、 spooling directory 、 netcat、 taildir 、 sequence generator 、 syslog 、 http 、 legacy 。
-
Sink Sink 不断地轮询 Channel 中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个Flume Agent 。 Sink 组件目的地包括 hdfs 、 logger 、avro、 thrift 、 ipc 、 file 、 HBase 、 solr 、自定义。
-
Channel Channel是位于Source和Sink之间的缓冲区。因此,Channel允许Source和Sink运作在不同的速率上。Channel是线程安全的,可以同时处理几个Source的写入操作和几个Sink的读取操作。 Flume自带两种Channel:Memory Channel和File Channel。Memory Channel是内存中的队列。 Memory Channel在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么Memory Channel就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。 File Channel将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。
-
Event 传输单元, Flume数据传输的基本单元,以Event的形式将数据从源头送至目的地。 Event由Header和Body两部分组成, Header用来存放该event的一些属性,为K-V结构,Body用来存放该条数据,形式为字节数组。
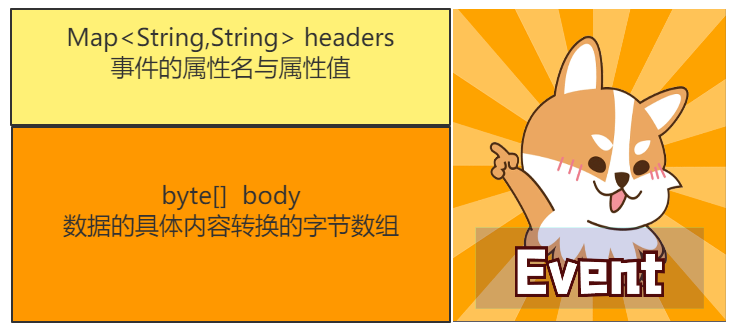
public interface Event { /**Returns a map of name-value pairs describing the data stored in the body.*/ public Map<String, String> getHeaders(); /**Set the event headers * @param headers Map of headers to replace the current headers.*/ public void setHeaders(Map<String,String> headers); /**Returns the raw byte array of the data contained in this event.*/ public byte[] getBody(); /**Sets the raw byte array of the data contained in this event. * @param body The data.*/ public void setBody(byte[] body); }
与Scribe区别
下面将对常见的开源日志收集系统Flume和Scribe的各方面进行对比。对比中Flume将主要采用Apache下的Flume-NG为参考对象。同时,我们将常用的日志收集系统分为三层(Agent层,Collector层和Store层)来进行对比。
|
对比项 |
Flume |
Scribe |
|
使用语言 |
Java |
c/c++ |
|
容错性 |
Agent和Collector间, Collector和Store间都有容错性,且提供三种级别的可靠性保证; |
Agent和Collector间, Collector和Store之间有容错性; |
|
负载均衡 |
Agent和Collector间, Collector和Store间有LoadBalance和Failover两种模式 |
无 |
|
可扩展性 |
好 |
好 |
|
Agent丰富程度 |
提供丰富的Agent,包括avro/thrift socket, text, tail等 |
主要是thrift端口 |
|
Store丰富程度 |
可以直接写hdfs, text, console, tcp;写hdfs时支持对text和sequence的压缩; |
提供buffer, network, file(hdfs, text)等 |
|
代码结构 |
系统框架好,模块分明,易于开发 |
代码简单 |
Flume基础
安装配置
这里演示flume-1.9.0版本的安装配置。https://download.csdn.net/download/m0_62491477/92650741
首先将apache-flume-1.9.0-bin.tar.gz上传到linux的/opt/apps目录下,然后解压apache-flume-1.9.0-bin.tar.gz到/opt/目录下
[root@node3 ~]# cd /opt/apps/
[root@node3 apps]# tar -zxvf apache-flume- 1.9.0-bin.tar.gz -C /opt/修改apache-flume-1.9.0-bin的名称为flume-1.9.0
[root@node3 apps]# cd /opt/
[root@node3 opt]# mv apache-flume-1.9.0- bin/ flume-1.9.0将lib文件夹下的guava-11.0.2.jar删除以兼容Hadoop 3.1.3
[root@node3 opt]# rm -f flume- 1.9.0/lib/guava-11.0.2.jar修改配置文件
[root@node3 opt]# cd flume-1.9.0/conf/
[root@node3 conf]# cp flume-env.sh.template flume-env.sh
[root@node3 conf]# vim flume-env.sh export JAVA_HOME=/usr/java/default配置环境变量
[root@node3 conf]# vim /etc/profile
# flume环境变量
export FLUME_HOME=/opt/flume-1.9.0
export PATH=$PATH:$FLUME_HOME/bin
[root@node3 conf]# source /etc/profile验证安装是否成功
[root@node3 conf]# cd
[root@node3 ~]# flume-ng version
Flume 1.9.0
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: d4fcab4f501d41597bc616921329a4339f73585e
Compiled by fszabo on Mon Dec 17 20:45:25 CET 2018
From source with checksum 35db629a3bda49d23e9b3690c80737f9
入门案例
四台虚拟机上安装netcat软件
yum install -y nc创建工作目录
[root@node3 ~]# cd /opt/flume-1.9.0/
[root@node3 flume-1.9.0]# mkdir jobs创建并添加配置文件
[root@node3 flume-1.9.0]# cd jobs/
[root@node3 jobs]# vim netcat-logger.conf
# Name the components on this agent
# a1:表示的agent的名称
# agent a1下的所有source
a1.sources = r1
# agent a1下的所有的sink
a1.sinks = k1
# agent a1下的所有的 channel
a1.channels = c1
# Describe/configure the source source的配置
# 指定sources.r1类型
a1.sources.r1.type = netcat
# 指定监听服务器的主机名或ip地址
a1.sources.r1.bind = node3
# 指定监听服务器的端口号
a1.sources.r1.port = 44444
# Describe the sink sink相关参数的配置
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
# channel相关参数的配置
# channel的类型
a1.channels.c1.type = memory
# channel的容量
a1.channels.c1.capacity = 1000
# 进入channel的event事件的事务容量
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
# 将具体的source-channel-sink进行绑定
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
查看命令的帮助
[root@node3 conf]# flume-ng help
Usage: /opt/flume/bin/flume-ng <command> [options]...
commands:
help display this help
text
agent run a Flume agent指定
agent的名称
global options:
--conf,-c <conf> use configs in <conf>
directory 配置文件目录
-Dproperty=value sets a Java system property value指定java的系统属性值
-Xproperty=value sets a Java -X option agent options:
--name,-n <name> the name of this
agent (required)指定agent的名称
--conf-file,-f <file> specify a config
file (required if -z missing)如果不指定-z选项,则必须指定配置文件
--zkConnString,-z <str> specify the ZooKeeper connection to use启动Flume并监听44444端口
[root@node3 jobs]# cd ../
[root@node3 jobs]# flume-ng agent -c jobs/ -n a1 -f jobs/netcat-logger.conf -Dflume.root.logger=INFO,console
在node2上使用netcat工具发送数据
[root@node2 ~]# nc node3 44444
hello
OK
nice to meet you!
OK
去node3的flume窗口查看:

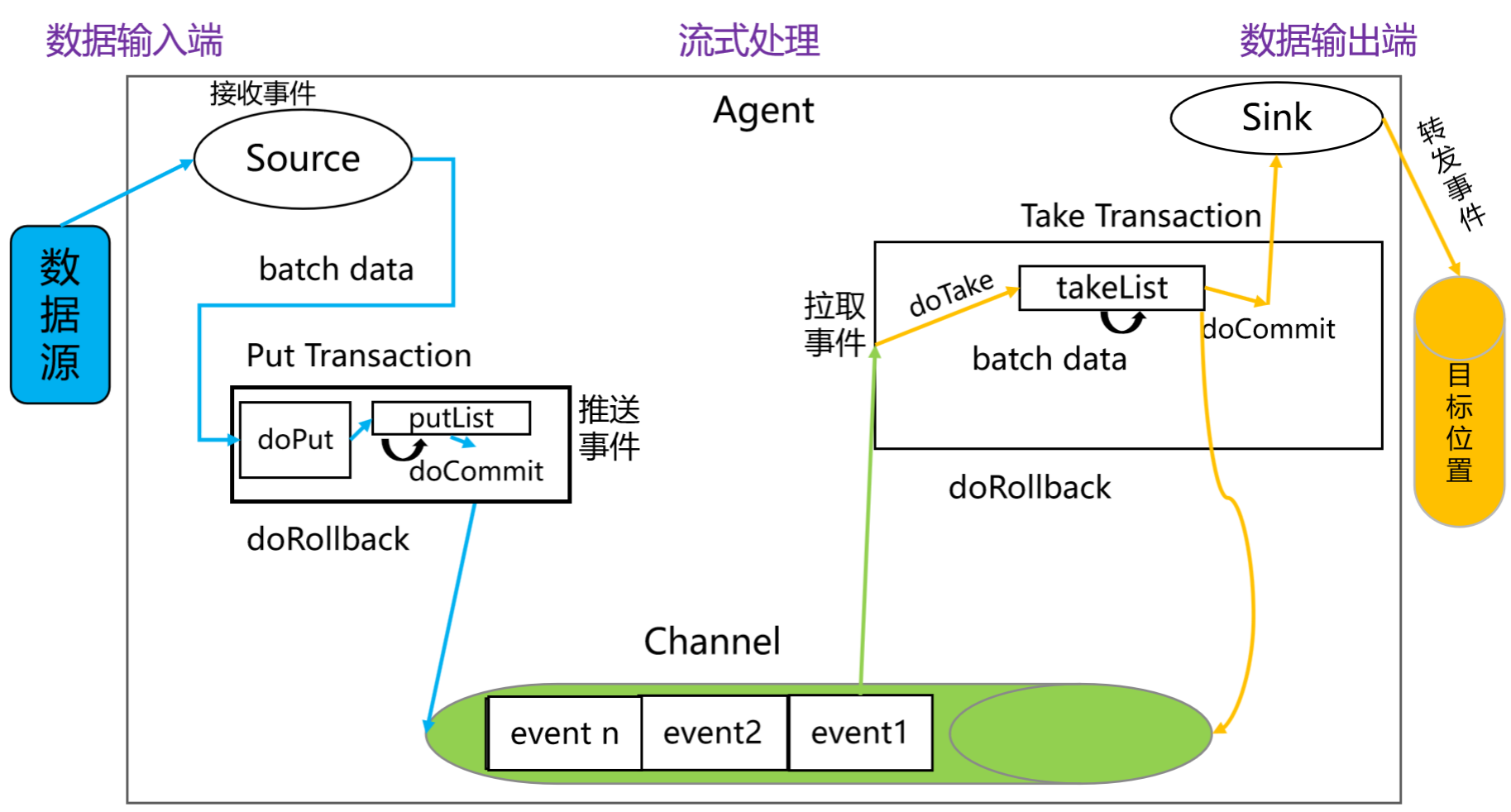
Flume事务剖析
-
doPut: 将批数据先写入临时缓冲区 putList
-
doCommit: 检查 channel 内存队列是否足够合并
-
doRollback:channel 内存队列空间不足,回滚数据,直接将数据丢弃。
-
doTake: 将数据取到临时缓冲区 takeList ,并将数据发送到目标位置(比如: HDFS 、 Hive 等)
-
doCommit: 如果数据全部发送成功,则清除临时缓冲区 takeList
-
doRollback: 数据发送过程中如果出现异常, rollback 将临时缓冲区 takeList 中的数据归还给channel 内存队列。
Source实战
Exec Source案例
tail -F、cat)来采集命令输出的日志数据,适合采集本地文件、系统日志、命令行输出等场景。

- 配置极简:只需指定命令即可,无需复杂的参数配置;
- 实时性强:
tail -F能做到秒级采集,适合实时日志监控; - 灵活性高:支持任意 Linux 命令 / 脚本,可自定义采集逻辑;
- 轻量无依赖:无需额外组件,直接基于 Linux 命令运行。
缺点(生产需避坑)
- 数据丢失风险:
- Flume Agent 崩溃 / 重启时,命令子进程会被杀死,重启期间的命令输出可能丢失;
- 若采集的文件被删除 / 重命名(如日志轮转),
tail -f会中断(需用tail -F规避)。
- 无断点续传:Agent 重启后,
tail -F会从文件末尾重新开始采集,无法恢复到崩溃前的位置,可能漏采数据。 - 命令阻塞风险:若配置的命令是 “一次性命令”(如
cat bigfile.log),命令执行完成后子进程退出,Source 会一直重启该命令,导致资源浪费。 - 不支持分布式:仅能采集 Agent 所在机器的本地数据,无法直接采集远程数据。
|
Property Name |
Default |
Description |
|
channels |
||
|
type |
– |
The component type name, needs to be exec |
|
command |
– |
The command to execute |
|
shell |
A shell invocation used to run the command. e.g. /bin/sh -c. Required only for commands relying on shell features like wildcards, back ticks, pipes etc. |
|
|
batchSize |
20 |
The max number of lines to read and send to the channel at a time |
|
batchTimeout |
3000 |
Amount of time (in milliseconds) to wait, if the buffer size was not reached, before data is pushed downstream |
具体操作如下:
将node3上netcat-logger.conf拷贝exec-logger.conf,并修改:
[root@node3 jobs]# cp netcat-logger.conf exec-logger.conf
[root@node3 jobs]# vim exec-logger.conf
# Describe/configure the source source的配置
# 指定sources.r1类型
a1.sources.r1.type = exec
# 指定对应的命令
a1.sources.r1.command = tail -F /root/log.txt
# 指定解释上面命令的命令解释器是谁
a1.sources.r1.shell = /bin/bash -c
# 一批数据的数量:从Source到putList
a1.sources.r1.batchSize = 3
# 批的实效时间 单位为毫秒
a1.sources.r1.batchTimeout = 5000启动flume
[root@node3 jobs]# flume-ng agent --conf ./ --name a1 --conf-file exec-logger.conf -Dflume.root.logger=INFO,console在node3的另外的一个连接窗口向/root/log.txt文件中不断添加文本,观察flume日志的变化


spooldir Source案例
spooldir Source是 Flume 中专门针对「本地文件批量采集」设计的数据源,核心解决了 Exec Source 易丢数据、无断点续传的问题,是生产环境采集本地文件(如日志文件、业务数据文件)的首选方案。

核心逻辑
- 监控你指定的本地目录(Spool 目录);
- 自动检测目录中新增的文件,按规则读取文件内容;
- 读取完成后,对文件做「标记 / 删除 / 重命名」,避免重复采集;
- 将文件内容封装为 Flume Event,传递给 Channel 和 Sink。
优点
- 无数据丢失 + 防重复采集:
- 基于事务机制,Event 写入 Channel 成功后才标记文件为已处理;
- 读取完成的文件会被重命名 / 删除,绝对避免重复采集(Exec Source 无此机制)。
- 断点续传:
- 若 Flume Agent 崩溃重启,未读取完成的文件会从断点继续读取(依赖 File Channel),不会漏采 / 重采。
- 适合大文件采集:
- 按行读取文件,无需一次性加载整个文件到内存,支持 GB 级大文件采集(Exec Source 用 cat 读取大文件易占满内存)。
- 配置灵活:
- 支持文件前缀 / 后缀过滤、递归监控子目录、自定义重命名规则,适配各种文件采集场景。
缺点
- 不支持实时追加采集:
- SpoolDir Source 仅读取文件的 “静态内容”,文件放入 spool 目录后,若有新内容追加,Flume 不会读取新增部分(这是核心限制!)。
- 文件不可修改:
- 放入 spool 目录的文件不能被修改 / 移动 / 删除(直到 Flume 处理完成),否则会导致采集异常(如文件内容不完整、重复采集)。
- 目录监控有延迟:
- 基于定时扫描(默认 500ms),新文件放入目录后,最快 500ms 才会被检测到,实时性略低于 Exec Source。
具体步骤如下:
将node3上netcat-logger.conf拷贝spooldir-logger.conf,并修改:
[root@node3 jobs]# cp netcat-logger.conf spooldir-logger.conf
[root@node3 jobs]# vim spooldir-logger.conf
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /root/log
#采集后的文件,在原名称的后面添加的后缀
a1.sources.r1.fileSuffix = .wusen
#忽略所有以.tmp结尾的文件
a1.sources.r1.ignorePattern = ([^ ]*\.tmp)
#fileHeader值为true表示显示信息从哪个文件中读取的,false不显示
a1.sources.r1.fileHeader = true创建目录并启动
[root@node3 jobs]# mkdir /root/log
[root@node3 jobs]# flume-ng agent --conf ./ --name a1 --conf-file spooldir-logger.conf -Dflume.root.logger=INFO,console复制一个node3连接的xshell终端,/root/log目录下拷贝文本文件
[root@node3 ~]# cp log.txt log/查看flume输出日志:

查看/root/log目录

Taildir Source案例
Exec source适用于监控一个实时追加的文件,不能实现断点续传;Spooldir Source适合用于同步新文件,但不适合对实时追加日志的文件进行监听并同步;而Taildir Source是为解决「实时采集本地文件新增内容 + 高可靠性」而设计的数据源,相当于 Exec Source(实时) + SpoolDir Source(可靠)的 “合体升级版” —— 既支持实时监控文件追加内容,又能断点续传、避免数据丢失,是生产环境采集实时日志的最优选择(替代 Exec Source 的缺陷)。
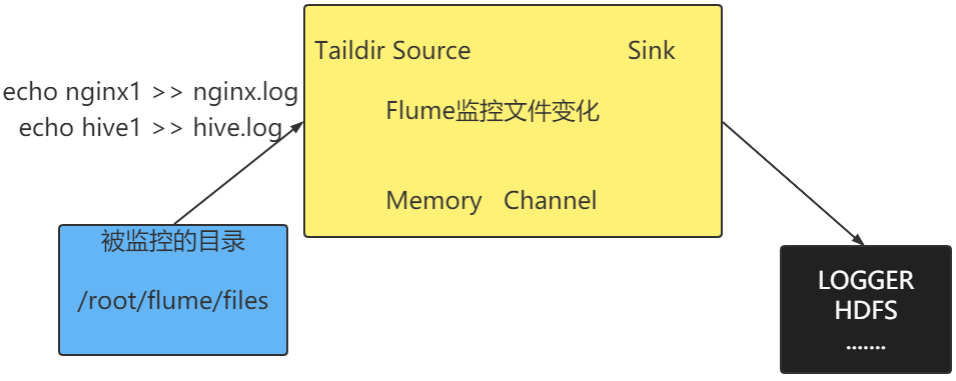
核心逻辑
- 监控指定的一个 / 多个本地文件(支持通配符);
- 实时跟踪文件的新增内容(类似
tail -F,但更可靠); - 记录每个文件的「读取偏移量」(即读到了哪一行 / 哪个字节),并持久化到本地文件;
- Agent 重启后,从上次的偏移量继续读取,实现断点续传;
- 将读取的内容封装为 Flume Event,传递给 Channel/Sink。
案例需求:使用Flume监听整个目录的实时追加文件,采集到新增的内容通过console输出。
具体步骤:
拷贝一份配置文件
[root@node3 jobs]# cp exec-logger.conf taildir-logger.conf创建目录
[root@node3 jobs]# mkdir -p /root/flume/files编辑taildir-logger.conf
[root@node3 jobs]# vim taildir-logger.conf
# 指定sources.r1类型
a1.sources.r1.type = TAILDIR
# 定义两个文件组
a1.sources.r1.filegroups = fg1 fg2
# 分别介绍fg1 fg2监控的文件集
a1.sources.r1.filegroups.fg1 = /root/flume/files/.*\.txt
a1.sources.r1.filegroups.fg2 = /root/flume/files/.*\.log
# 需要断点续传,添加如下配置
a1.sources.r1.positionFile = /root/flume/taildir.json启动flume
[root@node3 jobs]# flume-ng agent --name a1 --conf-file taildir-logger.conf -Dflume.root.logger=INFO,console测试:
[root@node3 files]# echo hive1 >> hive.log
[root@node3 files]# echo hive2 >> hive.log
[root@node3 files]# echo it1 >> it.txt
[root@node3 files]# echo it2 >> it.txt
停止flume,再执行如下追加
[root@node3 files]# echo it3 >> it.txt
[root@node3 files]# echo hive3 >> hive.log再启动flume,看是否有it3和hive3内容。有则表示断点续传成功

查看/root/flume/taildir.json
![]()
Sink实战
HDFS Sink
|
别名 |
描述 |
|
%t |
Unix时间戳,毫秒 |
|
%{host} |
替换名为"host"的事件header的值。支持任意标题名称。 |
|
%a |
星期几的短名,即Mon, Tue, ... |
|
%A |
星期几的全名,即Monday, Tuesday, ... |
|
%b |
月份短名,即Jan, Feb, ... |
|
%B |
月份全名,即January, February, ... |
|
%c |
时间和日期,即Thu Mar 3 23:05:25 2030 |
|
%d |
day of month (01) |
|
%e |
day of month without padding (1) |
|
%D |
date; same as %m/%d/%y |
|
%H |
hour (00..23) |
|
%I |
hour (01..12) |
|
%j |
day of year (001..366) |
|
%k |
小时 ( 0..23) |
|
%m |
月份 (01..12) |
|
%n |
不加前缀的月份 (1..12) |
|
%M |
分钟(00..59) |
|
%p |
locale’s equivalent of am or pm |
|
%s |
seconds since 1970-01-01 00:00:00 UTC |
|
%S |
second (00..59) |
|
%y |
年份最后两位 (00..99) |
|
%Y |
year (2030) |
|
%z |
+hhmm数字时区 (for example, -0400) |
参数介绍:
|
属性名称 |
默认值 |
说明 |
|---|---|---|
|
channel |
- |
|
| type |
- |
组件类型名称 ,必须是hdfs |
|
hdfs.path |
- |
HDFS路径 ,如hdfs://mycluster/flume/mydata |
|
hdfs.filePrefix |
FlumeData |
flume在hdfs 目录中创建文件的前缀 |
|
hdfs.fileSuffix |
- |
flume在hdfs 目录中创建文件的后缀。 |
|
hdfs.inUsePrefix |
- |
flume正在写入的临时文件的前缀 |
|
hdfs.inUseSuffix |
.tmp |
flume正在写入的临时文件的后缀 |
|
hdfs.rollInterval |
30 |
多长时间写一个新的文件 (0 = 不写新的文件) ,单位秒 |
|
hdfs.rollSize |
1024 |
文件多大写新文件单位字节(0: 不基于文件大小写新文件) |
|
hdfs.rollCount |
10 |
当写一个新的文件之前要求当前文件写入多少事件(0 = 不基于事件数写新文件) |
|
hdfs.idleTimeout |
0 |
多长时间没有新增事件则关闭文件(0 = 不自动关闭文件)单位为秒 |
|
hdfs.batchSize |
100 |
写多少个事件开始向HDFS刷数据 |
|
hdfs.codeC |
- |
压缩格式 :gzip, bzip2, lzo, lzop, snappy |
|
hdfs.fileType |
SequenceFile |
当前支持三个值 :SequenceFile ,DataStream ,CompressedStream。(1)DataStream不压缩输出文件 ,不要设置codeC (2)CompressedStream 必须设置codeC |
|
hdfs.maxOpenFiles |
5000 |
最大打开多少个文件。如果数量超了则关闭最旧的文件 |
|
hdfs.minBlockReplicas |
- |
对每个hdfs的block设置最小副本数。如果不指定 ,则使用hadoop的配置的值。1 |
|
hdfs.writeFormat |
- |
对于sequence file记录的类型。Text或者Writable(默认值) |
| hdfs.callTimeout |
10000 |
为HDFS操作如open、write、flush、close准备的时间。如果HDFS操作很慢 ,则可以设置这个值大一点儿。单位毫秒 |
|
hdfs.threadsPoolSize |
10 |
每个HDFS sink的用于HDFS io操作的线程数 (open, write, etc.) |
|
hdfs.rollTimerPoolSize |
1 |
每个HDFS sink使用几个线程用于调度计时文件滚动。 |
| hdfs.round |
false |
支持文件夹滚动的属性。是否需要新建文件夹。如果设置为true ,则会影响所有的基于时间的逃逸字符 ,除了%t。 |
|
hdfs.roundValue |
1 |
该值与roundUnit一起指定文件夹滚动的时长 ,会四舍五入 |
|
hdfs.roundUnit |
second |
控制文件夹个数。多长时间生成新文件夹。可以设置为- second, minute 或者 hour. |
|
hdfs.timeZone |
Local Time |
Name of the timezone that should be used for resolving the directory path, e.g. America/Los_Angeles. |
| hdfs.useLocalTimeStamp |
false |
一般设置为true ,使用本地时间。如果不使用本地时间 ,要求flume发送的事件header中带有时间戳。该时间用于替换逃逸字符 |
案例1:监控指定路径,采集新增的文件,每5秒在hdfs上创建一个新的文件夹
具体步骤:
启动hadoop集群
[root@node1 ~]# startha.sh复制配置文件
[root@node3 jobs]# cp spooldir-logger.conf spooldir-hdfs1.conf修改文件spooldir-hdfs1.conf
[root@node3 jobs]# vim spooldir-hdfs1.conf # Describe the sink sink相关参数的配置
a1.sinks.k1.type = hdfs
# 指定在hdfs上的保持路径 时间会四舍五入
a1.sinks.k1.hdfs.path = /flume/events/%m- %d/%H%M/%S
# 指定在hdfs上的文件前缀
a1.sinks.k1.hdfs.filePrefix = events-
# 设置目录的生成策略
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 5
a1.sinks.k1.hdfs.roundUnit = second
# 配置使用本地时间戳
a1.sinks.k1.hdfs.useLocalTimeStamp = true删除文件
[root@node3 jobs]# rm -f /root/log/log.txt.wusen启动flume
[root@node3 jobs]# flume-ng agent --conf ./ --name a1 --conf-file spooldir-hdfs1.conf -Dflume.root.logger=INFO,console拷贝文件到/root/log目录下
[root@node3 ~]# cp hello.txt log/
[root@node3 ~]# cp log.txt log/查看hdfs文件系统
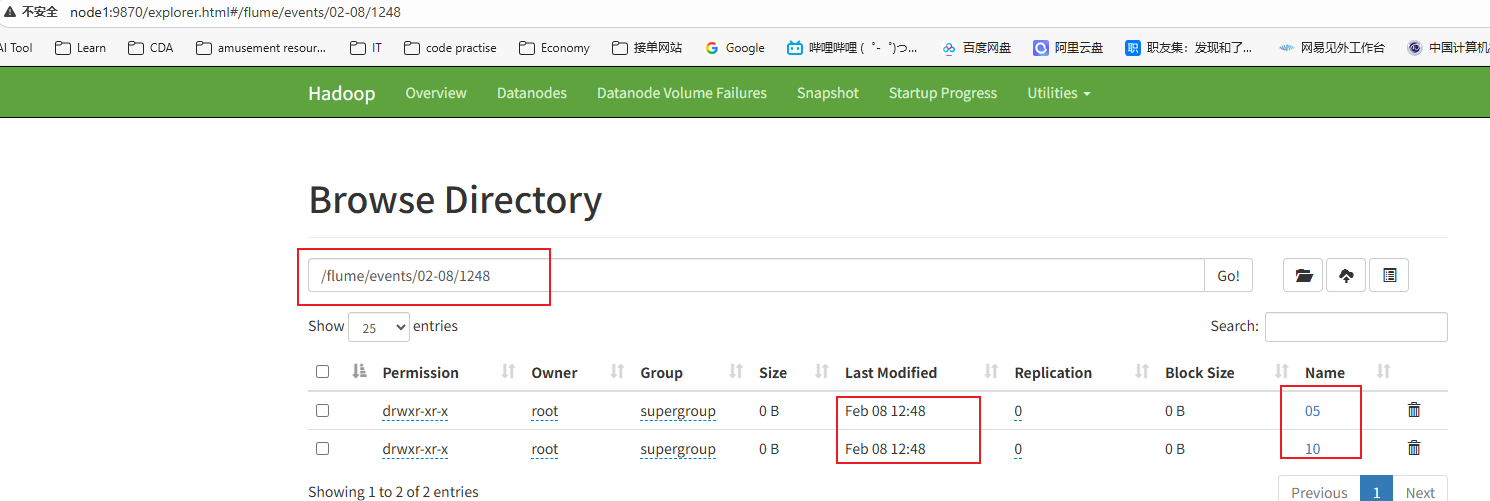
案例2:监控指定路径,采集新增的文件,每10条记录写到一个文件中
具体步骤:
复制配置文件
[root@node3 jobs]# cp spooldir-hdfs1.conf spooldir-hdfs2.conf修改文件spooldir-hdfs2.conf
[root@node3 jobs]# vim spooldir-hdfs2.conf # Describe the sink sink相关参数的配置
a1.sinks.k1.type = hdfs
# 指定在hdfs上的保持路径 时间会四舍五入
a1.sinks.k1.hdfs.path = /flume/events/%m- %d/%H%M
# 指定在hdfs上的文件前缀
a1.sinks.k1.hdfs.filePrefix = events-
# 设置目录的生成策略
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 1
a1.sinks.k1.hdfs.roundUnit = hour
# 配置文件的生成策略 10条event一个文件
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 10
# 配置使用本地时间戳
a1.sinks.k1.hdfs.useLocalTimeStamp = true
# 为HDFS操作如open、write、flush、close准备的时间
a1.sinks.k1.hdfs.callTimeout = 60000删除文件
[root@node3 ~]# rm -f /root/log/*启动flume
[root@node3 jobs]# flume-ng agent --conf ./ --name a1 --conf-file spooldir-hdfs2.conf -Dflume.root.logger=INFO,console拷贝文件到/root/log目录下

查看文件系统
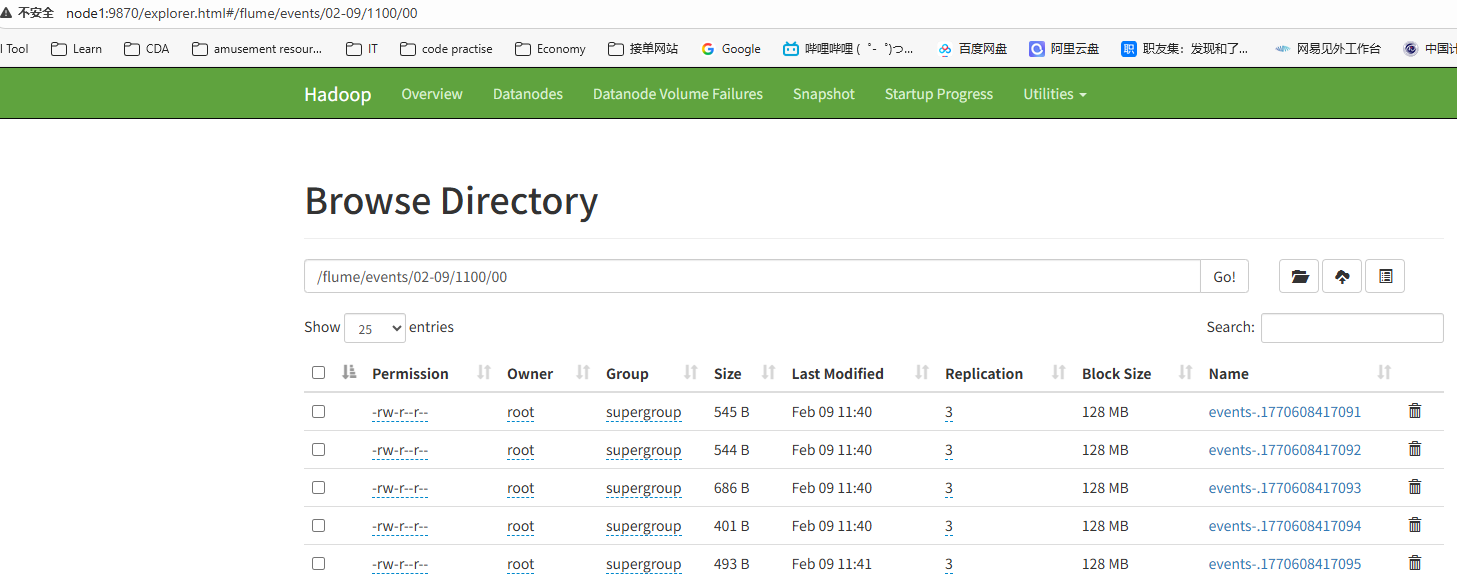
案例3:监控指定路径,采集新增的文件,五秒写入到一个文件中
具体步骤:
复制配置文件并修改
[root@node3 jobs]# cp spooldir-hdfs2.conf spooldir-hdfs3.conf
[root@node3 jobs]# vim spooldir-hdfs3.conf # Describe the sink sink相关参数的配置
a1.sinks.k1.type = hdfs
# 指定在hdfs上的保持路径 时间会四舍五入
a1.sinks.k1.hdfs.path = /flume/events/%m- %d/%H%M
# 指定在hdfs上的文件前缀
a1.sinks.k1.hdfs.filePrefix = events-
# 设置目录的生成策略
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 1
a1.sinks.k1.hdfs.roundUnit = hour
# 配置文件的生成策略 每隔5秒生成一个文件
a1.sinks.k1.hdfs.rollInterval = 5
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 0
# 配置使用本地时间戳
a1.sinks.k1.hdfs.useLocalTimeStamp = true
# 为HDFS操作如open、write、flush、close准备的时间
a1.sinks.k1.hdfs.callTimeout = 60000后面步骤和之前的一样,这里不赘述
Hive Sink
|
属性名 |
默认值 |
说明 |
|
type |
- |
组件类型名称,必须是hive |
|
hive.metastore |
- |
元数据仓库地址,如thrift://node3:9083 |
|
hive.database |
- |
数据库名称 |
|
hive.table |
- |
表名 |
|
hive.partition |
- |
逗号分割的分区值,标识写到哪个分区可以包含逃逸字符如果表分区字段为: (continent: string, country :string, time : string) 则"Asia,India,2030-05-26-01-21"表示continent为Asiacountry为India ,time是2030-05-26-01-21 |
|
callTimeout |
10000 |
Hive和HDFS的IO操作超时时间,比如openTxn ,write, commit ,abort等操作。单位毫秒 |
|
batchSize |
15000 |
一个hive的事务允许写的事件最大数量。 |
|
roundValue |
1 |
控制多长时间生成一个文件夹的时间的值 |
|
roundUnit |
minute |
控制多长时间生成一个文件夹的单位: second , minute , hour |
HBase Sink
|
属性名称 |
默 认 值 |
描述 |
|
type |
- |
组件类型名称 ,必须是hbase |
|
table |
- |
hbase的表名 |
|
columnFamily |
- |
列族的名称 |
|
zookeeperQuorum |
- |
对应于hbase-site.xml中hbase.zookeeper.quorum的值 ,指定zookeeper集群地址列表。 |
更多参数请参考:
https://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#hbasesinks

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)