当单模态走到尽头,多模态正在重塑医学图像 AI
多模态医学影像智能处理研究进展 随着单模态医学影像性能接近极限,多模态融合成为突破关键。近期研究围绕模态融合、缺失模态应对和临床适用性展开:1)BrainMVP框架通过跨模态重建和对比学习实现缺失模态下的高效预训练;2)半监督分割方法利用多阶段融合和对比互学习提升标签稀缺时的性能;3)改进的模态丢弃策略结合可学习token增强缺失模态的泛化能力;4)区域文本一致性增强技术(RBTCA)通过文本-图
当单一模态的医学影像逐渐逼近性能天花板,多模态,正在成为打开下一阶段医学影像智能的关键钥匙。在真实临床场景中,医生从来不是只“看一张图”做决策:CT、MRI、PET、超声、病理切片,甚至影像报告与电子病历,共同构成对疾病的完整认知。然而,长期以来,算法却往往只能处理“单一模态、单一任务”的理想化输入。
近三年,随着 多模态表示学习、跨模态对齐、医学大模型与生成式 AI 的快速发展,多模态医学图像处理迎来了真正的爆发期。从 CVPR、MICCAI 到 Nature 等顶级会议与期刊,一系列工作正在系统性地回答三个核心问题:不同模态如何高效融合?模态缺失如何应对?模型如何走向真实临床?本文系统梳理多模态医学图像处理的发展脉络、关键技术路线与未来趋势,帮助你快速把握这一方向的研究全貌。
1.Multi-modal Vision Pre-training for Medical Image Analysis
【创新点】
-
提出首个针对 大规模缺失模态 医学图像的多模态视觉预训练框架,弥补现有自监督仅针对单模态训练的不足。
-
设计三个预训练代理任务:跨模态图像重构、模态感知对比学习与模态数据蒸馏,提升跨模态表征质量。
-
在 10 个下游医学图像分割和分类任务中相比现有预训练方法显著提高 Dice 与准确率。
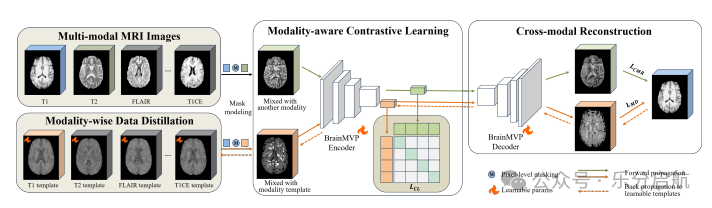
【方法】研究采用了一种新颖的多模态MRI数据预训练范式,利用跨模态重建学习独特的脑影像嵌入和高效的模态融合能力,并引入了模态感知对比学习模块和模态-wise数据蒸馏模块。。
【实验】作者收集了来自不同中心和设备的16,022个脑MRI扫描(超过240万张图像),涵盖八种MRI模态。实验结果显示,BrainMVP在下游任务中的表现优于现有最先进的预训练方法,Dice Score提高了0.28。
2.Semi-Supervised Multi-Modal Medical Image Segmentation for Complex Situations
【创新点】
-
提出多阶段多模态融合策略以最大化各模态互补信息利用。
-
引入对比互学习(Contrastive Mutual Learning)以约束各模态预测一致性。
-
显著提升了标签稀缺条件下的分割性能,证明其鲁棒性。
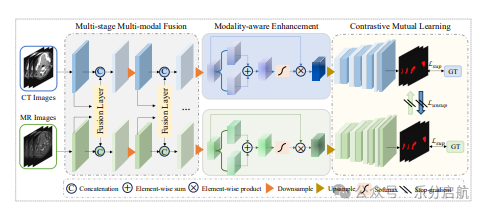
【方法】 采用多阶段多模态融合和增强策略,结合对比互学习方法,以充分利用多模态信息的互补性,减少特征差异,增强特征共享与对齐。
【实验】在两个多模态数据集(具体数据集名称未在摘要中给出)上进行实验,结果表明所提出框架在半监督任务中具有优越的性能和鲁棒性。
3.Learning Contrastive Multimodal Fusion with Improved Modality Dropout
【创新点】
-
提出 模态丢弃 + 对比学习 框架改善现实场景下模态缺失问题。
-
设计可学习的模态 token 提升缺失模态下的表征一致性。
-
泛化性好,可与 CT 基础模型联合用于疾病预测任务。
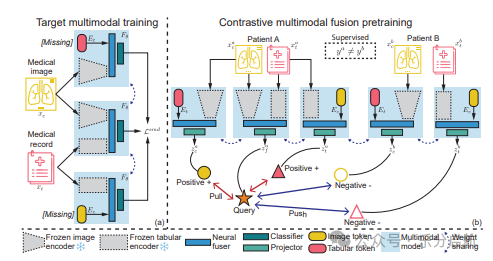
【方法】论文提出了一种新的多模态学习框架,该框架集成了增强模态dropout和对比学习,通过引入可学习的模态标记来提高对缺失模态的融合能力,并增强传统的单模态对比目标,以融合多模态表示。
【实验】 在大型临床数据集上进行的疾病检测和预测任务实验表明,该方法在只有单一模态可用等具有挑战性和实际应用场景中实现了最先进的性能。此外,通过成功集成到最近的CT基础模型中,展示了其适应性。研究结果表明,该方法在多模态学习方面具有有效性、效率和泛化能力,为现实世界的临床应用提供了一个可扩展、低成本解决方案。
4.Region-Based Text-Consistent Augmentation for Multimodal Medical Segmentation
【创新点】
-
针对 医学图像+文本 语义增强提出区域一致性增强策略。
-
利用图像区域提取文本提示集成增强,更好保持多模态一致性。
-
可插件集成到现有分割模型中提升 Dice 指标。
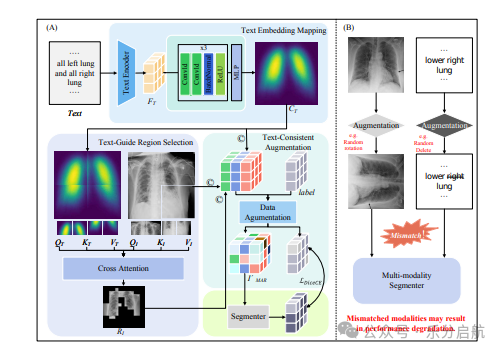
【方法】 提出基于区域的文本一致性增强(RBTCA),通过识别文本报告中描述的图像区域、提取区域文本线索、将线索整合到图像模态感知表示中,再进行区域级增强,确保文本-图像一致性,并支持即插即用集成。
【实验】 在QaTa-Covid19和自建的Lung Tumor CT Segmentation(LTCT)数据集上,将RBTCA集成到基线分割模型后,Dice系数最高提升7.24%,验证了其有效性。实验通过将RBTCA作为即插即用模块嵌入现有分割流程,在多模态数据上评估分割性能改进。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)