PaperBanana:NeurIPS 级学术图自动生成 | 论文内附官方提示词

论文链接:https://arxiv.org/abs/2601.23265
发布时间:2026.01.30
先划重点:论文附录里有专业的绘图提示词可供参考。
相信很多搞科研的朋友都深有体会,写论文最痛苦的往往不是推公式或做实验,而是画那张能撑起整篇论文门面的方法框图。
以前咱们全靠手工在那儿拉框、连线、对齐,一坐就是大半天,手都要废了;后来生图大模型火了,大家觉得救星来了,不过总觉得差点意思,总没法一次性满足你的要求。
最近看到北大和谷歌合作的一篇论文,推出了一个叫 PaperBanana 的“数字绘画助手”,专门解决这个痛点。
最让我感到惊喜的是,这篇论文里所有带“🍌”标志的图,全是由 PaperBanana 它自己画出来的。
这就是用自己的产品写自己的论文呀。
目前,他们的代码和数据正在开源进程中,不过,论文附录里直接公开了各个智能体的完整提示词,咱们完全可以照着这些专家的“对话模板”去调教我们的绘图助手。
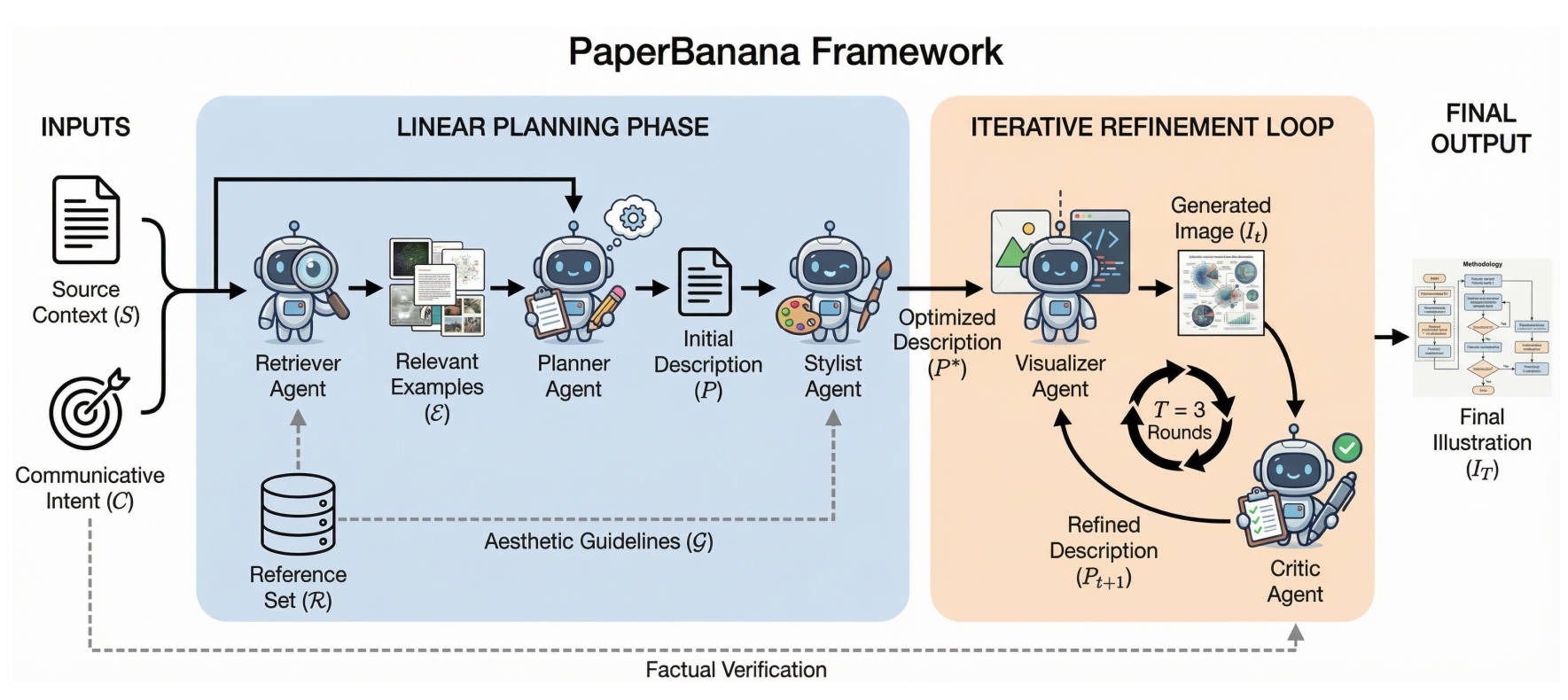
它是怎么画图的?“五人专家团”一起画图
PaperBanana 并不是简单地把一段指令直接丢给 AI 绘图,而是组建了一个多智能体团队,模拟了顶级设计师的工作流:
- Retriever(检索专家):它会先从 NeurIPS 2025 等顶会库里筛选出最相关的 10 个案例作为参考,保证画出来的东西有“顶会范儿”。
- Planner(策划专家):它是大脑,负责把晦涩的论文段落和你的绘图意图转化成一份极其详尽的文字蓝图。
- Stylist(造型师):这位专门负责审美,它会按照自动总结的“顶会审美指南”(比如低饱和度的柔和配色),把蓝图精修为高颜值说明书。
- Visualizer(插画师):它根据指令生成图像;如果是数据图,它还会写出 Python 的 Matplotlib 代码来绘制,确保数据绝对精准。
- Critic(审核员):像审稿人一样盯着看,发现逻辑错了或者字画糊了,就打回重画,通常会迭代 3 轮直到完美。
数据说话:真的比人工好吗?
为了测试它是不是真有两把刷子,作者搞了个 PaperBananaBench,用了 292 个 NeurIPS 2025 的高难度真实案例做测试。
自动评估的实验结果非常亮眼:
- 简洁度(Conciseness):比基准模型提升了 +37.2%,它非常擅长去掉废话,只留干货。
- 审美(Aesthetics):提升了 +6.6%。
- 综合得分:整体表现提升了 +17.0%。
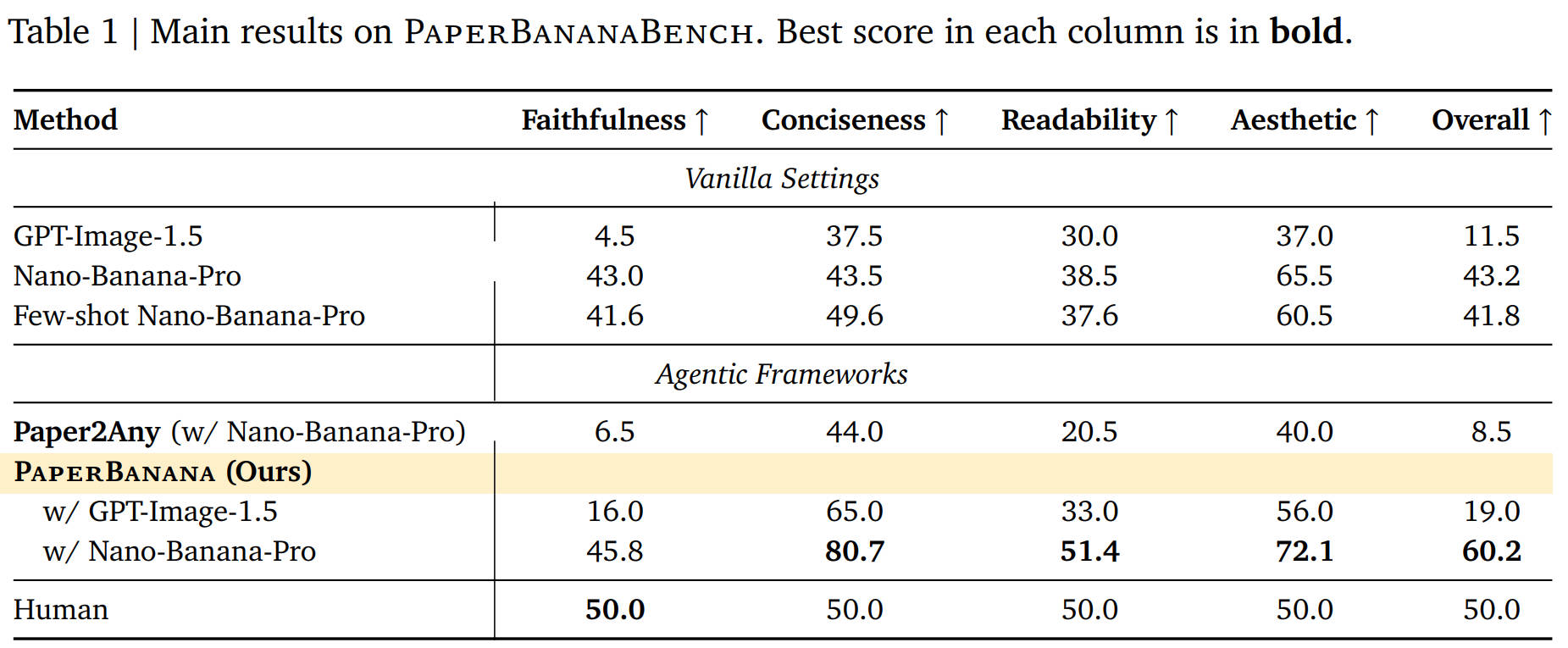
在人工评估中,人类评委给出的 胜/平/负比例为 72.7% / 20.7% / 6.6%,它画出来的图,绝大多数情况下比普通的 AI 生图模型要好得多。
不止是画图
除了从零开始画图,PaperBanana 还有两个让我们非常省心的应用:
-
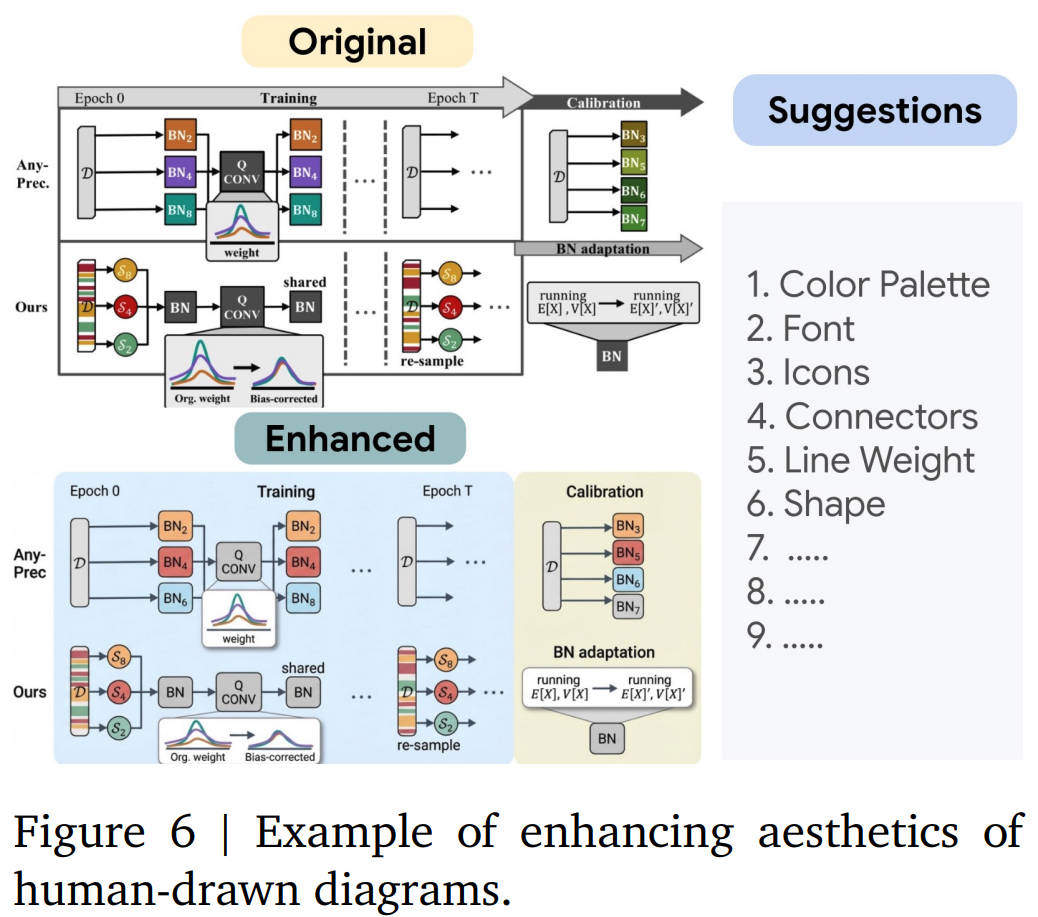
给旧图“整容”:如果你手里已经有一张画得比较简陋的框图,可以把它丢给模型。它能根据总结出的学术审美指南,帮你优化配色、字体和布局。
-
数据图的精准拿捏:在画统计图时,它是通过代码生成来完成的。相比直接生图,代码绘制能避免“数值幻觉”——即模型为了好看乱标数据点的问题。
不足之处
虽然它很强大,但论文也诚实地指出了一些局限。比如目前的输出主要是位图,不太好后期微调。而且在极其复杂的逻辑连线上,偶尔还是会出错。
不过,作者推荐了一种“生成并选择”(Generate-and-select)的工作流,即多生几个候选方案,我们选最好的那个,这样效率最高。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 15
15 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)