
如何构建可靠的大模型评测系统?
基于算法的评估系统的研究是指导人工智能发展的前提,没有这个前提,人工智能只能是人工智障。在 20 世纪中期,AI 系统评估主要集中于评估特定任务中的算法性能,例如逻辑推理和数值计算。传统的机器学习任务如分类和回归通常使用可编程和统计指标,包括准确率、精确率和召回率。随着深度学习的出现,AI 系统的复杂性迅速增长,促使评估标准发生转变。AI 评估已从预定义的可编程机器指标扩展到更灵活、更鲁棒的评估器

基于算法的评估系统的研究是指导人工智能发展的前提,没有这个前提,人工智能只能是人工智障。在 20 世纪中期,AI 系统评估主要集中于评估特定任务中的算法性能,例如逻辑推理和数值计算。传统的机器学习任务如分类和回归通常使用可编程和统计指标,包括准确率、精确率和召回率。随着深度学习的出现,AI 系统的复杂性迅速增长,促使评估标准发生转变。AI 评估已从预定义的可编程机器指标扩展到更灵活、更鲁棒的评估器,用于解决复杂、现实的任务。一个典型的例子是图灵测试,它通过人类对话来确定 AI 模型是否能够表现出类似人类的智能行为。 图灵测试为评估人工智能模型提供了基本指导方针,特别是在评估人工智能模型在灵活和现实环境中的智能方面。
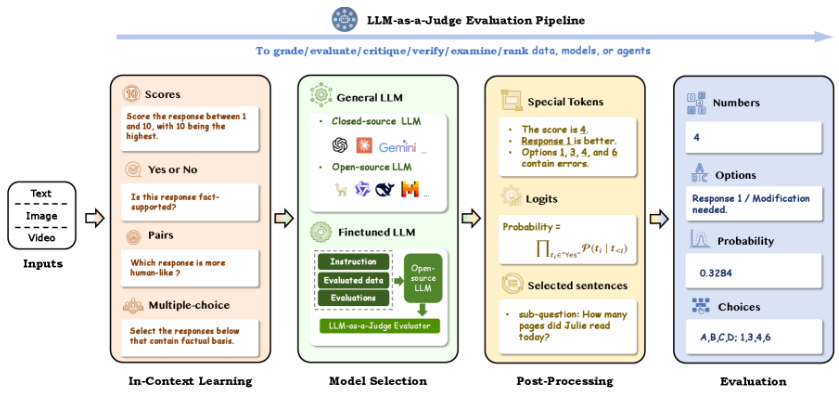
然而随着OpenAI的ChatGPT问世,大型语言模型(LLMs)的快速发展推动了它们在各个领域的应用扩展。其中最具前景的应用之一就是基于自然语言响应的评估系统,当然在这个契机下,一种新的范式已经出现,用 LLMs 取代人类代码和统计指标进行评估,LLM 作为评估的范式出现,克服了人工评估的可扩展性限制和传统指标的语义不敏感性。
LLM评估器系统
首先我们要知道什么是LLM as a Judge? 一般 judge模型只是用于评估其他神经网络输出的神经网络 ,并且在大多数情况下,他们评估的是文本生成。这些模型从小型专业分类器(类似“垃圾邮件过滤器”,但针对毒性分析)到大型语言模型(LLM),既有大型通用型,也有小型专属型。在后一种情况下,当你用 LLM 作为裁判时,你会给它一个提示词,因此,对于LLM作为judge的过程就是通过输入-输出-得分(得分这里主要是要关注分数怎么设定,是0-1,还是1-10,还是1-100?),而从对于LLM评估系统,大体可以分为:单LLM系统、多LLM系统、人机协作系统。
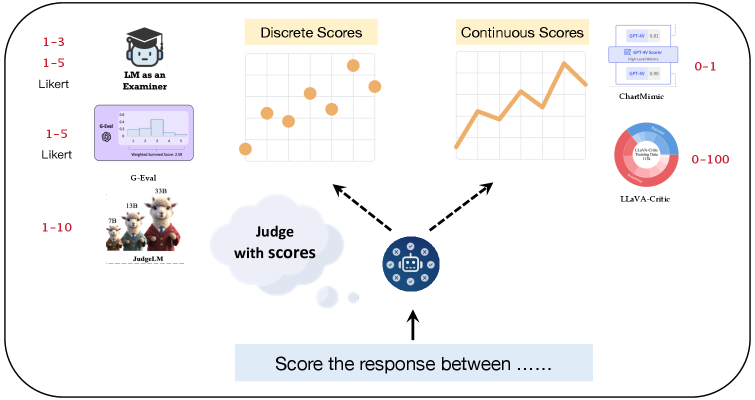
a. 单 LLM 系统
单LLM系统主要依赖于单个模型执行来进行任务判断,其有效性主要取决于LLM的能力以及处理输入数据的策略。这种方法通常可以分为三个基本组成部分:提示工程、微调和模型输出后处理。
提示工程) 涉及设计清晰且结构化的输入提示,以从LLM 裁判那里获得准确且符合上下文的响应。这种方法能够确保 LLM 理解特定复杂任务并能够提供与目标一致的判断。在许多情况下,精心设计的提示词能显著减少模型训练的必要性。
模型微调)微调涉及在特定数据集上训练一个已存在的 LLM,以使其适应特定的判断任务。当判断领域涉及高度专业化的知识或细微的决策时,它尤其有用。
模型输出后处理)后处理涉及进一步优化评估结果,以提取更精确和可靠的结果。这一步骤通常包括分析初始输出、结果不一致性或者是需要改进的地方,随后进行有针对性的调整和深入分析。通过解决这些问题,从而确保后处理评估结果不仅准确,而且与任务的特定目标和标准相一致。
对于企业而言,优先考虑提示词工程,其次是模型输出处理,最后是微调。
b.多LLM系统
多 LLM 评估利用多个 LLM 的集体智慧来增强评估的鲁棒性和可靠性。通过促进模型间通信或独立聚合其输出,这些系统可以有效地减少偏差,利用不同模型之间的互补优势,提高决策精度,并促进对复杂判断的更细致理解。
协作)指LLM之间动态的信息流动(评估过程的中间数据共享),这对于在判断过程中激发见解和分享理由至关重要。相关研究也表明LLM之间的通信可以通过它们的互动产生涌现能力,从而实现更一致的决定过程和更好的判断性能。多LLM 系统可以从 LLM 互动中受益于两种反馈方式:合作和竞争。
合作:多LLM可以通过交互共享信息和推理,共同实现一个共同目标,从而增强整体评估过程。
竞争:多LLMs系统也可以从竞争性或对抗性通信中受益,即 LLMs 相互辩论或争论以评估彼此的输出,从而不断优化。
投票选举)在LLM之间无交互的多 LLM 系统中,多个模型独立生成结果,随后通过多数投票、加权平均和优先考虑最高置信度预测等技术,多种聚合策略将它们综合为最终决策。这些方法允许每个模型不受干扰地评估,并最终从每个模型的响应中提取和结合最有效的元素。
c.人机协作系统
人机协作系统弥合了自动 LLM 判断与人类监督的必要需求之间的差距,特别是在法律、医疗保健和教育等高风险领域。人类评估者要么作为最终决策者,要么作为验证和改进模型输出的中介。通过融入人类见解,混合系统可以确保最终判断更加可靠,并与伦理考量保持一致,能够通过反馈循环赋能模型的持续改进。
Agent评估器系统
随着评估对象从简单的文本响应发展到跨专业领域的复杂多步任务,传统的 LLM 作为裁判的方式日益不足,它只关注最终输出而未能验证中间步骤或满足专业领域的严格标准。为了弥补这一差距,范式正在转向采用去中心化审议、可执行验证和细粒度评估的 Agent 作为裁判,以缓解这些局限性。
a. 单智能体评估器
Agent-as-a-Judge 代表了一个快速发展的领域,其已经开始渗透评测系统,然而目前单Agent评估系统跟LLM一样存在一个非常重要的问题-自我偏见。这种单智能体带有很强主观性意识,对于系统而言存在严重问题。

多智能体协作
多智能体协作利用集体推理来减轻 Agent-as-a-Judge 系统中的单LLM 偏见。早期系统遵循固定协议的程序范式,而近期研究则朝着基于反馈自适应选择智能体的反应式方法发展。
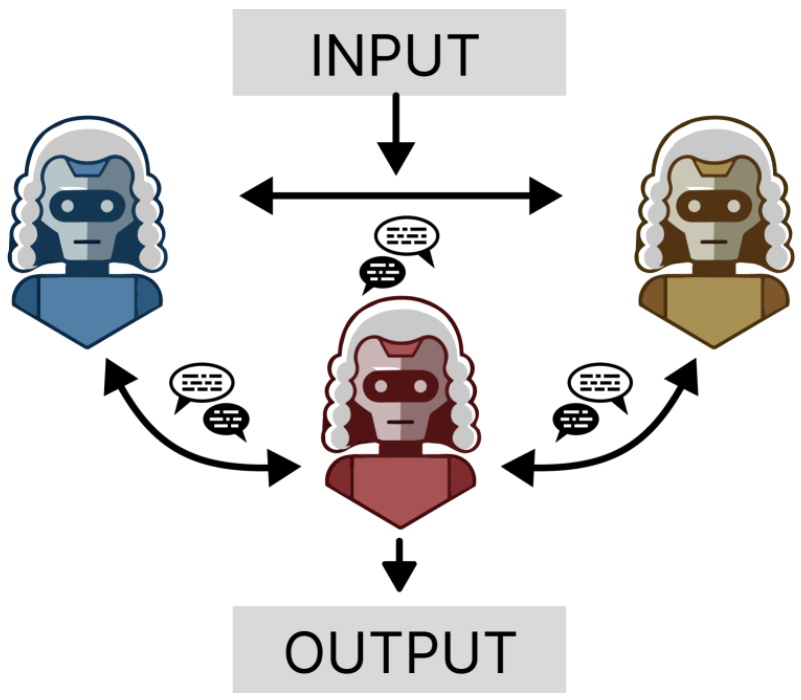
投票选举 or 聚合)多智能体跟多LLM一样,通过选举投票和信息共享来解决单Agent的偏见问题。
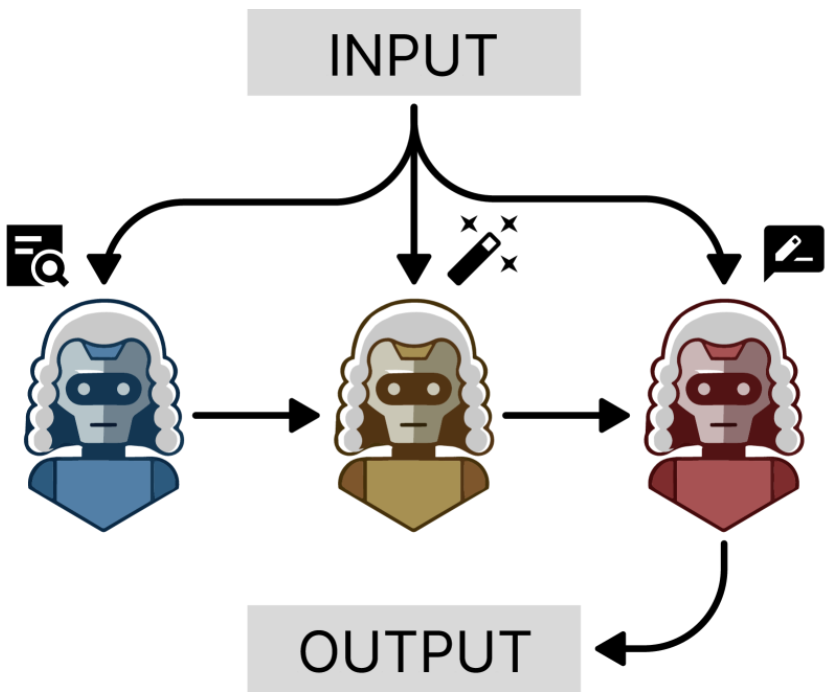
多任务分解)除此之外,Agent比多LLM好的一个策略是:多任务分解。这是 Agent-as-a-Judge 范式中的一项核心能力,它能够将高级评估目标分解为可执行的子任务,并根据中间分析动态调整评估轨迹,拆解后的任务采用"分而治之"策略,将不同的子任务分配给专门的代理进行系统评估。
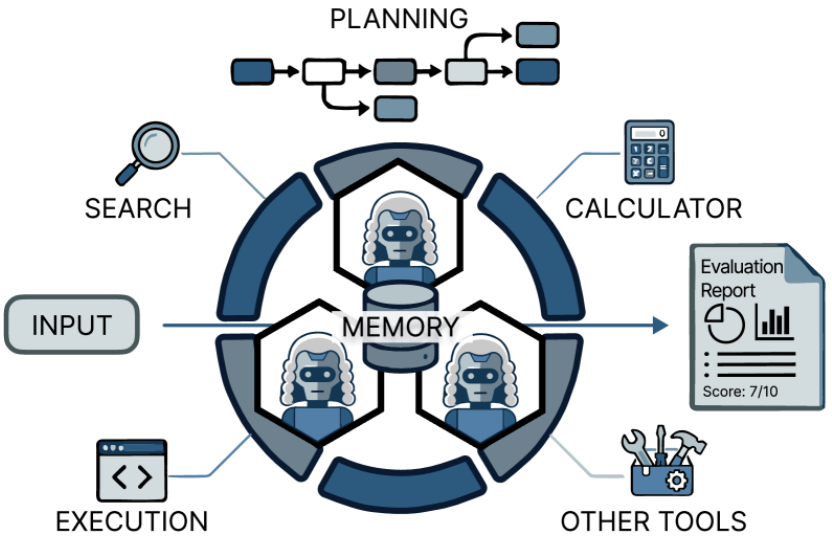
工具集成与记忆
工具集成是 Agent-as-a-Judge 框架的核心能力,使评估器能够基于外部证据和明确检查来进行评估。
在 Agent-as-a-Judge 框架中,工具的一个常见用途是收集支持评估的额外证据。这类证据包括中间产物、执行结果和感知信号,这些信号无法通过基于文本的推理可靠地获取。例如在代码相关任务中,Agent-as-a-Judge允许评估器检查执行产物或运行自动检查,以用于评估的执行反馈【反馈】。
当然我们还可以使用工具来验证被评估者的输出或中间推理步骤是否满足明确的正确性约束,例如逻辑有效性、数学严谨性或事实一致性。在这些框架中,评估器Agent识别需要验证的声明或步骤,并调用适当的工具进行检查。然后,Agent在上下文中解释这些验证信号,以指导最终评估【指导】。
对于记忆,一般使 Agent-as-a-Judge 框架能够在评估步骤之间保留信息,支持多步推理、一致判断和重用先前结果。根据记忆的作用对先前工作分类,包括中间状态跟踪和个性化上下文保留。在后期需要调用使用的时候,可以根据不同的类别、领域、任务进行使用。
多LLM评估器案例
Python实现
数据用例
[{"instruction": "Calculate the hypotenuse of a right triangle with legs of 6 cm and 8 cm.","input": "","output": "The hypotenuse of the triangle is 10 cm.","model 1 response": "\nThe hypotenuse of the triangle is 3 cm.","model 2 response": "\nThe hypotenuse of the triangle is 12 cm."},{"instruction": "Name 3 different animals that are active during the day.","input": "","output": "1. Squirrel\n2. Eagle\n3. Tiger","model 1 response": "\n1. Squirrel\n2. Tiger\n3. Eagle\n4. Cobra\n5. Tiger\n6. Cobra","model 2 response": "\n1. Squirrel\n2. Eagle\n3. Tiger"}]
评估代码
from pathlib import Pathimport jsonfrom openai import OpenAIfrom tqdm import tqdmwith open("config.json", "r") as config_file:config = json.load(config_file)api_key = config["OPENAI_API_KEY"]client = OpenAI(api_key=api_key)def run_chatgpt(prompt, client, model="gpt-4-turbo"):response = client.chat.completions.create(model=model,messages=[{"role": "user", "content": prompt}],temperature=0.0,seed=123,)return response.choices[0].message.contentdef load_evaluation_data():json_file = "eval-example-data.json"with open(json_file, "r") as file:json_data = json.load(file)def format_input(entry):instruction_text = (f"Below is an instruction that describes a task. Write a response that "f"appropriately completes the request."f"\n\n### Instruction:\n{entry['instruction']}")input_text = f"\n\n### Input:\n{entry['input']}" if entry["input"] else ""instruction_text + input_textreturn instruction_text + input_textdef generate_model_scores(json_data, json_key, client):scores = []for entry in tqdm(json_data, desc="Scoring entries"):prompt = (f"Given the input `{format_input(entry)}` "f"and correct output `{entry['output']}`, "f"score the model response `{entry[json_key]}`"f" on a scale from 0 to 100, where 100 is the best score. "f"Respond with the number only.")score = run_chatgpt(prompt, client)try:scores.append(int(score))except ValueError:continuereturn scoresif __name__ == '__main__':json_data = load_evaluation_data()# for entry in json_data[:5]:# prompt = (f"Given the input `{format_input(entry)}` "# f"and correct output `{entry['output']}`, "# f"score the model response `{entry['model 1 response']}`"# f" on a scale from 0 to 100, where 100 is the best score. "# )for model in ("model 1 response", "model 2 response"):scores = generate_model_scores(json_data, model, client)print(f"\n{model}")print(f"Number of scores: {len(scores)} of {len(json_data)}")print(f"Average score: {sum(scores) / len(scores):.2f}\n")# Optionally save the scoressave_path = Path("scores") / f"model-{model.replace(' ', '-')}.json"with open(save_path, "w") as file:json.dump(scores, file)
Java实现
java实现可以看下spring ai的实现,这里是通过模型结果和标准结果进行评估。
依赖添加
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-openai-spring-boot-starter</artifactId><version>1.0.0-M3</version></dependency>
实现自己的一个评估器(官方给的很少,就1-2个)
package com.ywj.aidemo.evaluate;import com.ywj.aidemo.bean.EvaluateResult;import org.springframework.ai.chat.client.ChatClient;import org.springframework.ai.evaluation.EvaluationRequest;import org.springframework.ai.evaluation.EvaluationResponse;import org.springframework.ai.evaluation.Evaluator;import java.util.Collections;public class AnswerConparisonEvaluator implements Evaluator {private static final String DEFAULT_EVALUATION_PROMPT_TEXT = " Your task is to evaluate if the response for the query\n is in line with the context information provided.\\n\n You have two options to answer. Either YES/ NO.\\n\n Answer - YES, if the response for the query\n is in line with context information otherwise NO.\\n\n Query: \\n {query}\\n\n Response: \\n {response}\\n\n Context: \\n {context}\\n\n Answer: \"\n";private final ChatClient.Builder chatClientBuilder;private static final String Agent_EVALUATION_PROMPT_TEXT = """任务描述:你需要对agent输出的结果与标准答案进行详细的对比分析,并给出一个分数。分数范围为0到100分,其中100分表示agent输出结果与标准答案完全一致且准确无误,0分表示agent输出结果与标准答案完全不符或存在严重错误。对比维度:1、内容准确性:检查agent输出结果中的关键信息是否与标准答案一致,包括事实、数据、结论等。2、逻辑连贯性:评估agent输出结果的逻辑结构是否清晰,是否与标准答案的逻辑框架相符。3、完整性:判断agent输出结果是否涵盖了标准答案中的所有重要方面,是否存在遗漏。4、语言表达:分析agent输出结果的语言是否流畅、清晰,是否存在语法错误或表达不清的地方。5、细节处理:对比agent输出结果和标准答案在细节方面的差异,如具体例子、引用等。打分规则:90-100分:agent输出结果在所有维度上与标准答案高度一致,几乎没有错误或偏差。80-89分:agent输出结果在大部分维度上与标准答案相符,存在少量细节错误或表达不够精准。70-79分:agent输出结果在主要方面与标准答案相符,但在某些维度上存在明显不足,如逻辑不够清晰或内容有部分遗漏。60-69分:agent输出结果与标准答案有一定相似性,但在多个维度上存在较多问题,如内容不完整、逻辑混乱等。0-59分:agent输出结果与标准答案不符,存在严重错误或偏差,无法满足任务要求具体步骤:阅读标准答案:仔细阅读并理解标准答案的内容和要求。分析agent输出结果:逐一对比agent输出结果与标准答案在上述维度上的表现。记录差异和问题:将发现的差异和问题详细记录下来,以便在打分时作为参考。给出分数:根据agent输出结果的整体表现,按照打分规则给出一个合理的分数。提供反馈:简要说明打分的理由,指出agent输出结果的优点和不足之处,提出改进建议。用户问题:%sAgent回答:%s标准答案:%sJson输出评估结果:""";public AnswerConparisonEvaluator(ChatClient.Builder chatClientBuilder) {this.chatClientBuilder = chatClientBuilder;}public EvaluationResponse evaluate(EvaluationRequest evaluationRequest) {String response = evaluationRequest.getResponseContent();String context = this.doGetSupportingData(evaluationRequest);EvaluateResult evaluationResponse = this.chatClientBuilder.build().prompt().user((userSpec) -> userSpec.text(" " +"任务描述:\\n" +"你需要对agent输出的结果与标准答案进行详细的对比分析,并给出一个分数。分数范围为0到100分,其中100分表示agent输出结果与标准答案完全一致且准确无误,0分表示agent输出结果与标准答案完全不符或存在严重错误。\\n 分数范围为0到100分,其中100分表示agent输出结果与标准答案完全一致且准确无误,0分表示agent输出结果与标准答案完全不符或存在严重错误\\n\n " +// "对比维度:\\n" +// "1、内容准确性:检查agent输出结果中的关键信息是否与标准答案一致,包括事实、数据、结论等。\\n" +// "2、逻辑连贯性:评估agent输出结果的逻辑结构是否清晰,是否与标准答案的逻辑框架相符。\\n" +// "3、完整性:判断agent输出结果是否涵盖了标准答案中的所有重要方面,是否存在遗漏。\\n" +// "4、语言表达:分析agent输出结果的语言是否流畅、清晰,是否存在语法错误或表达不清的地方。\\n" +// "5、细节处理:对比agent输出结果和标准答案在细节方面的差异,如具体例子、引用等。\\n\n" +// "打分规则:\\n" +// "90-100分:agent输出结果在所有维度上与标准答案高度一致,几乎没有错误或偏差。\\n" +// "80-89分:agent输出结果在大部分维度上与标准答案相符,存在少量细节错误或表达不够精准。\\n" +// "70-79分:agent输出结果在主要方面与标准答案相符,但在某些维度上存在明显不足,如逻辑不够清晰或内容有部分遗漏。\\n" +// "60-69分:agent输出结果与标准答案有一定相似性,但在多个维度上存在较多问题,如内容不完整、逻辑混乱等。\\n" +// "0-59分:agent输出结果与标准答案不符,存在严重错误或偏差,无法满足任务要求\\n\n" +// "具体步骤:\\n" +// "阅读标准答案:仔细阅读并理解标准答案的内容和要求。\\n" +// "分析agent输出结果:逐一对比agent输出结果与标准答案在上述维度上的表现。\\n" +// "记录差异和问题:将发现的差异和问题详细记录下来,以便在打分时作为参考。\\n" +// "给出分数:根据agent输出结果的整体表现,按照打分规则给出一个合理的分数。\\n" +// "提供反馈:简要说明打分的理由,指出agent输出结果的优点和不足之处,提出改进建议。\\n\n" +"输出要求:\\n" +"必须包含:score 和 feedback字段 \\n\n" +"用户问题: \\n {query}\\n\n 模型回答: \\n {response}\\n\n 标准答案: \\n {context}\\n\n Answer: \"\n").param("query", evaluationRequest.getUserText()).param("response", response).param("context", context)).call().entity(EvaluateResult.class);boolean passing = false;float score = 0.0F;if (evaluationResponse.score >= 60) {passing = true;score = evaluationResponse.score;}return new EvaluationResponse(passing, score, evaluationResponse.feedBack, Collections.emptyMap());}}
可以看到上面有两个,一个是比较全面的prompt,一个是比较简单的prompt,这个就取决你对评估器的要求,如果要求比较严格,可以使用约束比较强的prompt。由于官方给的评估器很简单,这里也是为什么我要自己去实现一个评估器的原因。
评估结果
@Data@AllArgsConstructor@NoArgsConstructorpublic class EvaluateResult {public Integer score;public String feedBack;}
controller实现
package com.ywj.aidemo.controller;import com.ywj.aidemo.evaluate.AnswerConparisonEvaluator;import org.springframework.ai.chat.client.ChatClient;import org.springframework.ai.chat.prompt.Prompt;import org.springframework.ai.evaluation.EvaluationRequest;import org.springframework.ai.evaluation.EvaluationResponse;import org.springframework.ai.evaluation.FactCheckingEvaluator;import org.springframework.ai.evaluation.RelevancyEvaluator;import org.springframework.ai.model.Content;import org.springframework.ai.openai.OpenAiChatModel;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.web.bind.annotation.GetMapping;import org.springframework.web.bind.annotation.RequestParam;import org.springframework.web.bind.annotation.RestController;import java.util.List;import java.util.Map;@RestControllerpublic class EvaluationController {/*** 方式一: FactCheckingEvaluator (Spring AI 1.0.0-M5 API)* spring ai 文档: https://docs.spring.io/spring-ai/reference/api/testing.html*/private final OpenAiChatModel chatModel;@Autowiredpublic EvaluationController(OpenAiChatModel chatModel) {this.chatModel = chatModel;}/*** 标准答案和模型输出结果对比* curl验证: curl --location 'http://localhost:8089/ai/agent/evaluateResponse?message="springboot ai 是什么?"'* */@GetMapping("/ai/agent/evaluateResponse")public Map<String, Object> evaluateResponse(@RequestParam(defaultValue = "Tell me a joke") String message,@RequestParam(required = true) String standardResponse){String response = chatModel.call(new Prompt(message)).getResult().getOutput().getContent();// 方式一:自定义评估方法AnswerConparisonEvaluator factCheckingEvaluator = new AnswerConparisonEvaluator(ChatClient.builder(chatModel));// 方式二: 使用官方提供的// RelevancyEvaluator factCheckingEvaluator = new RelevancyEvaluator(ChatClient.builder(chatModel)); // 需要使用 FactCheckingEvaluator (Spring AI 1.0.0-M5 API)EvaluationRequest evaluationRequest = new EvaluationRequest(message, List.of(new Content() {@Overridepublic String getContent() {return standardResponse; // 标准答案}@Overridepublic Map<String, Object> getMetadata() {return Map.of();}}), response); // response 为模型回答EvaluationResponse evaluationResponse = factCheckingEvaluator.evaluate(evaluationRequest);return Map.of("score", evaluationResponse.getScore(),"isPass",evaluationResponse.isPass(),"modelResponse",response,"standardResponse",standardResponse,"userQuery",message,"feedback",evaluationResponse.getFeedback());}}
调用结果
我的问题是:地球是距离太阳第几近的行星?
标准答案是:地球是距离太阳第3近的行星
模型输出答案是:地球是距离太阳第三近的行星。按距离太阳由近及远的顺序,地球排 在第三位,前面是水星和金星
评估得分:95.0
如何学习AGI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取