对于模拟实现C++vector类的详细解析—上
开篇介绍:
hello 大家,nice to meet you,哈哈,不知道大家经过上一篇的对于C嘎嘎中vector的详细介绍,对vector了解的怎么样了,哈哈,相信大家肯定是有所收获的。
大家也可以通过这个链接,去了解C++中的vector:
vector - C++ Reference![]() https://legacy.cplusplus.com/reference/vector/vector/?kw=vector那么和string一样,我们不能只会用而不会写,所以呀,在接下来,我们就要一起去探索,对C++vector类的模拟实现,值得一提的是,大家可能会觉得,vector本质上也是个数组,那不就是个顺序表吗?哈哈,肯定不是的大家,vector可比顺序表高级以及复杂多了,实现方式也有所不同。
https://legacy.cplusplus.com/reference/vector/vector/?kw=vector那么和string一样,我们不能只会用而不会写,所以呀,在接下来,我们就要一起去探索,对C++vector类的模拟实现,值得一提的是,大家可能会觉得,vector本质上也是个数组,那不就是个顺序表吗?哈哈,肯定不是的大家,vector可比顺序表高级以及复杂多了,实现方式也有所不同。
那么究竟,我们要如何去模拟实现vector呢?我们且看下文。
注意点:
需要注意的是,vector 和 string 本质相近,都属于顺序表,也就是数组。但 vector 可以存储的类型更多种,无论是 int、double、string 等,都能支持。因此,我们无法直接使用 int * 这类成员变量。为了实现强大的兼容性,显然需要使用类模板,通过用户的显式实例化来指定要存储的数据类型,原理便是如此。另外,由于使用了类模板,vector 这个类必须在头文件中完整实现,不能将其成员函数分离到源文件中,这是 C++ 的规定。
就像下面这样子
namespace win
{
//使用类模版
template <typename type1>
class vector//不包含vector头文件,我们就可以直接写vector,不难不行,编译器会报错
{
……
}
}
vector的成员变量:
说到 vector 和 string 最大的不同,其实核心就体现在成员变量的设计上。
和 string 类以及之前实现的顺序表不一样,我们在模拟实现 vector 时,不会直接用size和capacity这样的整型成员变量,而是采用了更 “灵活” 的三个指针(在模拟实现里,迭代器可简单等效为对应数据类型的指针)来管理空间与元素:
- 第一个指针(可理解为
_start),指向数组的第一个元素,同时也是指向着整块数组空间,作用类似于 string 里的字符数组指针、或是之前顺序表的arr,标记存储数据的数组起始位置; - 第二个指针(可理解为
_finish),指向数组中最后一个有效数据的下一个位置;结合_start来看,_finish - _start的结果就等同于之前的 “元素个数(size)”; - 第三个指针(可理解为
_endOfStorage),指向数组存储空间的最后一个位置(注意是整个分配空间的末尾,而非有效数据的末尾);此时_endOfStorage - _start的结果就等同于之前的 “容量(capacity)”。
之所以不用整型的size和capacity,是因为 vector 需要适配迭代器的设计(后续迭代器操作更依赖指针运算)。这三个指针必须满足关系:_start <= _finish <= _endOfStorage—— 当_finish == _start时,容器为空(元素个数为 0);当_finish == _endOfStorage时,容器已满(元素个数等于容量),此时若插入新元素,就需要扩容(重新分配更大空间,并更新这三个指针的指向)。

那么其实就是,我们在vector的模拟实现中,要使用迭代器的模式去实现,不再是之前的char*等等,这是更加高级的方法。
那么我们又知道,迭代器的类型是比较复杂的,不是我们现阶段要去了解的,但是呢,也没事,在我们的模拟实现中,是可以使用指针去表示迭代器的。
那么其实就是所传入的数据的类型的指针,这个类型可能是string,可能是int,可能是float等等,所以呢,我们上面也是说了,我们要用类模版,并且是命名为type1,所以我们就可以直接创建type1的指针,同时为了我们平时迭代器的名字,我们就将type1的指针重命名为iterator来使用,同时也可以创建只读的迭代器,具体代码如下:
typedef type1* iterator;//直接定义迭代器,因为后面的容器基本都是用迭代器
//在我们的模拟实现中,其实迭代器就相当于是数据类型的指针
typedef const type1* const_iterator;//定义不可变的迭代器
接下来就是我们的三个成员变量了:
private:
iterator mstart = nullptr; //指向数组第一个元素的迭代器(数据起始位置)
iterator mfinish = nullptr; //指向最后一个有效数据的下一个位置的迭代器(mfinish - mstart 为元素个数 size)
iterator mend_of_storage = nullptr; //指向数组存储空间末尾的迭代器(mend_of_storage - mstart 为容量 capacity)确实和我们之前实现的都不同一样,但是呢,等大家习惯了这个方式之后,就会轻松很多了,也能逐渐意识到这么使用的好处。
对于vector的迭代器begin、end、size、capacity函数的实现:
begin和end函数的实现:
那么,在实现了迭代器之后,我们就要实现begin和end函数了,这个是迭代器的关键,那么具体是如何实现,其实就是和string类的实现一样,包括注意事项,const修饰等等,都是一样的,唯一不同的只是说不是直接返回msize和mcapacity,而是返回两个指针(迭代器)相减,原理就是迭代器相减结果相当于整型。
那么我就直接给出详细代码了,大家有什么不懂的,可以去看了string类的模拟实现的那一篇博客中的关于迭代器的解析,大家也就能懂了,这二者是有很强的相通性的。
//再设置一下begin、end函数
iterator begin()
{
//不能设置为const成员函数,因为是可读可写的迭代器
//可能外部会通过返回值去修改
//而const成员函数要求是既不能在成员函数内部修改成员变量
//也不能通过返回值等在外部进行修改成员变量
return mstart;
}
iterator end()
{
return mfinish;
}
//不可修改迭代器
const_iterator cbegin() const
{
//不会在函数内改变类的成员变量
//且无法在外部通过该函数的返回值去修改成员变量
//所以要为const成员函数
//同时将返回类型设置为const迭代器
//确保不会被修改,
return mstart;
}
const_iterator cend() const
{
//不会在函数内改变类的成员变量
//且无法在外部通过该函数的返回值去修改成员变量
//所以要为const成员函数
//同时将返回类型设置为const迭代器
//确保不会被修改,
//为什么设置了为const成员函数之后,返回类型还要设置为const
//这是为了双重保证 const 语义的完整性——const 成员函数和
//const 迭代器(const_iterator)分别从 “函数内部行为” 和 “外部访问权限” 两个维度,
//确保 const 对象的 “只读性” 不被破坏,二者缺一不可。
//具体原因拆解:
//1. const 成员函数的作用:限制 “函数内部” 的修改行为
//cend() const 中的 const 修饰,是向编译器承诺:
//函数内部不会直接修改类的非 mutable 成员变量(如 mstart、mfinish 等);
//函数内部不会调用非 const 成员函数(避免间接修改对象)。
//但这只能约束 “函数内部的操作”,无法限制 “外部通过函数返回值进行的修改”。
//2. const_iterator 的作用:限制 “外部通过返回值” 的修改行为
//const_iterator 是 “只读迭代器”,它的核心特性是:通过它只能读取元素,
//无法修改元素(例如 * it = 10; 会编译报错)。
//const 成员函数 + const_iterator 的组合,才能彻底保证:
//函数内部:不修改对象(const 成员函数的约束);
//外部访问:无法通过返回的迭代器修改对象(const_iterator 的约束)。
//这就像给 const 对象加了 “双重锁”:既防止内部 “自毁”,也防止外部 “入侵”
//那么总结一下其实就是,我们设置为了const成员函数之后
//只能限定函数内部不能对成员变量进行修改
//const 成员函数并没有 “主动限定外界通过返回值修改”,
//它的约束是 “间接的、依赖返回类型配合” 的。
//如果返回类型是 “可写的”(比如普通 iterator、非 const 引用),
//外界依然能绕过 const 成员函数的约束,修改对象成员变量。
//简单说:const 成员函数管的是 “函数内部不能改”,不管 “外部拿到返回值后能不能改”。
//所以就需要将返回类型设置为const去打匹配,
//这样子才能确保外部不能通过返回值等去修改成员变量
return mfinish;
}
希望大家仔细理解。
size和capacity函数的实现:
那么这个就简单的多得多了,我们直接看代码:
// 返回当前有效元素的个数(mfinish与mstart的差值)
// 声明为const成员函数,确保不会修改类的成员变量
size_t size() const
{
return mfinish - mstart;
}
// 返回当前已分配空间的总容量(mend_of_storage与mstart的差值)
// 声明为const成员函数,确保不会修改类的成员变量
size_t capacity() const
{
return mend_of_storage - mstart;
}相信大家对这个肯定是轻车熟路,手拿把掐了吧,ps:这两个函数也是写代码时最轻松的时候。
对vector[]的运算符重载函数:
那么我们知道,vector本质上也是个数组,只是存储的数据类型不固定罢了,但是呢,vector又不是完全等价于数组,所以我们是不能像对待数组一样去直接使用[]访问指定下标的元素。
所以呢为了能够完美的贴近我们平时的使用,我们就要使用[]的运算符重载函数去实现能够通过[]去直接访问vector中指定下标的数据。
那么具体要怎么实现呢,其实是和string类的[]的运算符重载函数一模一样的,我们知道,vector的成员变量中mstart其实就是指向存储数据的那一个数组空间,就等价于string里面的mstr。
所以我们通过[]去访问vector的指定下标的元素,其实就是访问mstart中指定下标的数据,说到这里,大家就应该很清楚了吧,我们下面直接就看代码:
// 对[]的运算符重载函数
// 可读可写版本:返回指定位置元素的引用,允许外部修改
type1& operator[](const size_t pos)
{
// 不声明为const成员函数:虽然函数内部不直接修改成员变量,
// 但返回的引用允许外部通过该函数修改元素,不符合const成员函数的语义
return mstart[pos];
}
// 只读版本:返回指定位置元素的const引用,禁止外部修改
const type1& operator[](const size_t pos) const
{
// 声明为const成员函数:函数内部不修改成员变量,且返回const引用限制外部修改
return mstart[pos];
}即如上。
对vector的clear、尾删、empty函数的实现:
OK大家,这也是个so easy的部分,
1. empty() 函数(判断 vector 是否为空)
实现步骤:
- 明确判断核心依据:结合 vector 的指针管理逻辑,有效元素个数由
mfinish - mstart决定,当mfinish与mstart指向同一位置时,代表无有效元素; - 对比两个指针:判断
mfinish是否等于mstart; - 返回结果:若相等,返回
true(容器为空);若不相等,返回false(容器非空)。
2. clear() 函数(清空 vector 有效元素)
实现步骤:
- 明确清空核心目标:仅删除有效元素,不释放已分配的空间(即不改变
mstart和mend_of_storage的指向); - 调整指针位置:直接将
mfinish赋值为mstart,让有效元素的结束位置与起始位置重合,此时mfinish - mstart = 0,有效元素个数变为 0,达到清空效果。
3. pop_back() 函数(尾删 vector 最后一个有效元素)
实现步骤:
- 前置检查:为避免空容器执行尾删导致异常,先通过
empty()函数判断容器是否为空,若为空则触发断言(assert)报错; - 实现尾删逻辑:由于
mfinish指向最后一个有效元素的下一个位置,只需将mfinish向前移动一位(自减 1),即可让最后一个有效元素脱离 “有效范围”,等价于删除该元素(不改变存储空间,仅调整有效元素计数)。
下面我就给上详细代码:
// 判断vector是否为空
// 核心依据:当mfinish与mstart指向同一位置时,无有效元素
bool empty() const
{
if (mfinish == mstart)
{
return true;
}
return false;
}
// 清空vector中的有效元素(不释放已分配空间)
// 实现逻辑:将mfinish指向mstart,使有效元素个数变为0
void clear()
{
mfinish = mstart; // 仅调整有效元素结束位置,不改变容量
}
// 尾删vector的最后一个有效元素
void pop_back()
{
// 前置检查:确保容器非空,为空则触发断言
assert(!empty());
// 实现逻辑:mfinish向前移动一位,最后一个有效元素脱离有效范围
--mfinish; // 等价于有效元素个数减1
}大家可以发现,其实是和顺序表的尾删差不多的哦。
实现vector的析构函数:
理论上来说,我们应该先写构造函数,但 vector 的构造函数实际上需要用到尾插(push_back)。因为 vector 要存储的数据类型不确定,所以创建新 vector 进行赋值、交换,或是直接赋值,都不现实。因此,最好的方式是通过循环逐个尾插数据。前面实现 string 类时用的方法,在 vector 中并不适用,本质原因是 string 类中存储的数据类型已知,而 vector 中存储的数据类型未知。
所以嘞,我们可以先写个析构函数,那么其实也很简单,就是释放空间呗,那么vector中哪个成员变量有指向空间呢?很明显,就是mstart。
所以我们只要释放mstart,然后再去将成员变量都置为空就行,即赋值为nullptr,具体代码如下:
// 析构函数:释放动态分配的内存并重置指针
~vector()
{
if (mstart)
{
delete[] mstart; // 释放mstart指向的数组空间
mstart = nullptr; // 指针置空,避免野指针
mfinish = nullptr;
mend_of_storage = nullptr;
}
}so easy。
实现vector的reserve函数:
在实现尾插函数之前,需要先实现 reserve 函数。说白了就是空间不足时进行扩容,或开辟指定大小的空间,更直白地说,它就是扩容函数。也是和string类的reserve函数一样的功能,大家可以先去string类那里去复习一下,这里就不进行详细解释了。
reserve 函数的核心目的是确保 vector 的容量至少为指定大小 n,当现有容量不足时进行扩容,实现思路和步骤如下:
一、判断是否需要扩容
首先计算当前容量(通过mend_of_storage - mstart得到),只有当指定的 n 大于当前容量时,才需要执行扩容操作(若 n 小于等于当前容量,无需处理,保持原空间不变)。
二、保存原有元素个数
扩容后需要保留原有元素,因此先记录当前有效元素的个数(old_size,即size()的结果,也就是mfinish - mstart)。
三、分配新的内存空间
用new动态分配一块能容纳 n 个type1类型元素的空间,并用临时指针temp指向这块新空间。这里选择new是因为 vector 存储的类型是模板参数type1(可能是任意类型,包括自定义类型),new能正确为该类型分配对齐的内存。
四、复制原有元素到新空间
将旧空间中的old_size个元素复制到新空间。这里不使用memcpy(字节级浅拷贝),而是用std::copy:
- 原因是
type1可能是自定义类型(如string),这类类型往往涉及资源管理(如动态内存)。memcpy只会浅拷贝字节,导致新、旧元素的资源指针指向同一块内存,后续释放旧空间时会让新元素的资源指针变成野指针,引发错误; std::copy会调用元素的赋值运算符,对自定义类型实现正确的拷贝(如string的赋值会进行深拷贝,重新分配资源),避免资源管理问题。
五、释放旧空间
用delete[]释放mstart指向的旧空间,避免内存泄漏。
六、更新三个核心指针
旧空间释放后,原mstart、mfinish、mend_of_storage均变为野指针,需重新指向新空间的对应位置:
mstart指向新空间的起始位置(即temp);mend_of_storage指向新空间的末尾(mstart + n,因为新容量是 n);mfinish指向新空间中原有元素的结束位置(mstart + old_size,确保有效元素个数不变)。
为什么要这样设计?
- 按需扩容:仅当 n 大于当前容量时操作,避免不必要的内存分配,节省资源;
- 保留原有元素:复制旧元素到新空间,确保扩容后原有数据不丢失;
- 兼容自定义类型:用
std::copy而非memcpy,适配自定义类型的资源管理逻辑,避免浅拷贝引发的错误; - 更新指针避免野指针:旧空间释放后,及时更新三个指针指向新空间,保证 vector 状态的正确性。
我在这边对为什么不能用memcpy函数再进行详细的解析一下:
- memcpy是内存的二进制格式拷贝,将一段内存空间中内容原封不动的拷贝到另外一段内存空间中
- 如果拷贝的是自定义类型的元素,memcpy既高效又不会出错,但如果拷贝的是自定义类型元素,并且自定义类型元素中涉及到资源管理时,就会出错,因为memcpy的拷贝实际是浅拷贝。
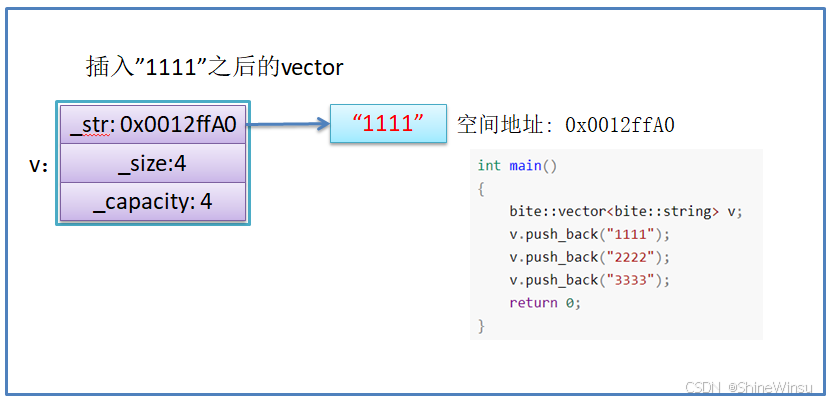
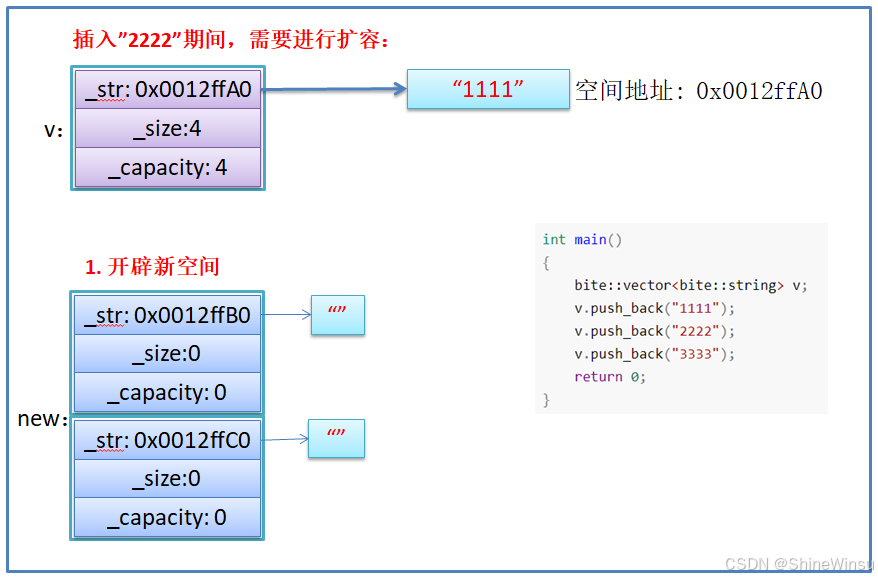
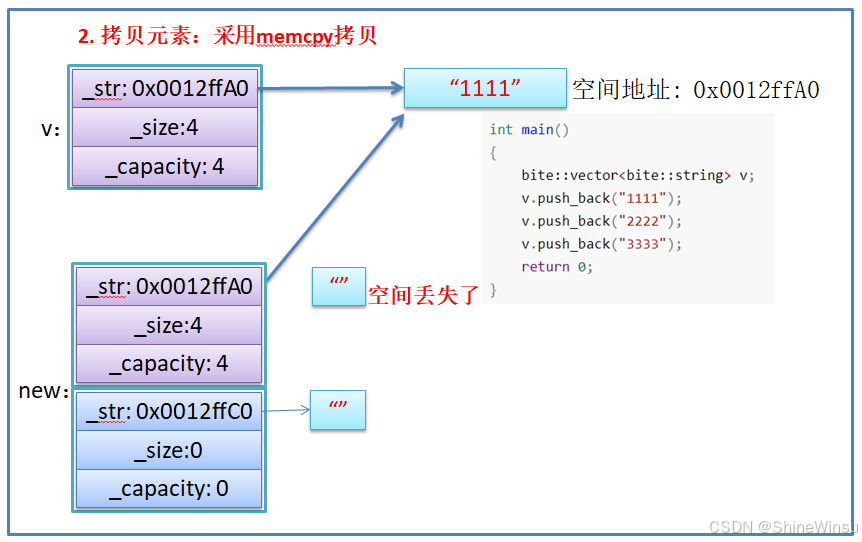
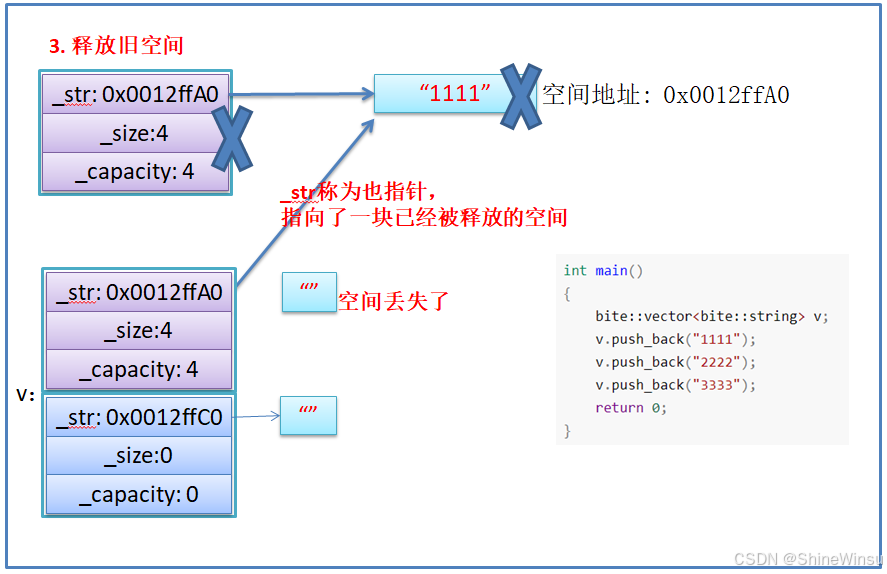
希望大家注意,是不能用memcpy函数的
下面就给出完整代码:
// 那么在写尾插函数之前,还得先去实现reserve函数
// 说白了就是去空间不够就扩容或者开辟指定空间的函数
// 再直白点就是扩容函数
void reserve(size_t n)
{
// 如果指定空间大小大于原本的空间大小,才去开辟
size_t capacity = mend_of_storage - mstart;
if (n > capacity)
{
size_t old_size = size();
// 直接开n个空间大小
iterator temp = new type1[n];
// 将原本的msart的数据都丢给temp
// for (size_t i = 0; i < old_size; i++)//其实是相当于*this.size(),也可以直接用old_size
// {
// temp[i] = mstart[i];//一个一个丢进去
// }
// 除了使用循环,也可以使用C++中std里面的copy函数
// 它的语法为 std::copy(源起始迭代器, 源结束迭代器, 目标起始迭代器),
// 作用是:把从「源起始迭代器」到「源结束迭代器前一个位置」的元素,
// 复制到以「目标起始迭代器」为起点的内存区域。
std::copy(begin(), begin() + old_size, temp);
// 它的作用是:把 “从容器的 begin()(起始位置)开始、
// 连续 old_size 个元素”,
// 复制到 “以指针 temp 为起始位置” 的内存区域中。
// 不要忘记了,temp是指向整个数组,但是一般是指向数组的头元素的
// 接下来就是要把原本的mstart所指向的空间给释放掉
delete[] mstart;
// 将temp赋值给mstart,此时二者都指向前面给temp开辟的空间
mstart = temp;
// 更新成员变量
mend_of_storage = mstart + n;//其实就是最开始的元素加上开辟的空间数
mfinish = mstart + old_size;
// 那么最后一个有效数据的下一个位置其实就是和原本的mfinish一样的
// 但是嘞,我们是要重新指定的,那么是为什么呢?
// 其实就是因为我们设置的成员变量是迭代器类型的
// 换句话说就是指针类型的,
// 那么在开辟temp之前,
// mfinish和mend_of_storage都是指向原本的mstart所指向的那一块空间的对应的位置
// 但是我们后面是把原本的mstart所指向的空间给释放掉
// 所以就导致,mfinish和mend_of_storage所指向的位置,没了
// 就是相当于mfinish和mend_of_storage成了野指针了
// 不要想着说在将temp赋值给mstart之后,mfinish和mend_of_storage可以自动转移
// 这是不可能的,所以呢,是需要我们自己去手动指定指向的
// 也就是我们也要对mfinish和mend_of_storage进行赋值
// 这样子才能将mfinish和mend_of_storage改为指向新的空间的对应的位置
// 那么怎么赋值呢,其实就是按照上面的
// 因为我们是开辟了n个空间,那么自然mend_of_storage 就是等于 mstart + n;
// 而mfinish其实就是和原本的离mstart的距离一样
// 但是由于我们对mstart重新赋值,所以我们要去保留之前的mfinish离mstart的距离
// 即old_size,那么后面加上这个变量,就是和原本的mfinsh指向的位置一样了
// 指向的空间不一样哦
// 最后将temp指针赋值为空,也可以不,毕竟是个局部变量
temp = nullptr;
// 那么在string类中,其实是使用strcpy函数来进行的
// 但是为什么在vector里面,我们不用memcpy函数呢?
// 其实这是因为vector里面存储的数据类型可能是string类等这一些自定义类型
// 那么这个时候,使用memcpy就不行了
// 因为memcpy的本质是浅拷贝,即一个一个字节的拷贝过去,那么针对内置类型还行
// 但是对自定义类型这一些可能会有申请空间的类型,就不行了
// 因为它只是把字节拷贝过去,但是并没有去开辟新空间
// 拿string类的mstr来说,它也是指针,它指向着存储字符数据的空间
// 那么当使用memcpy来进行拷贝的话,编译器就会让temp里面的string的mstr
// 值与原本的mstart的一样,但是,它们两个指向的空间也还是一样的
// 说白了就是没有进行深拷贝,只是把表面的数据给拷贝过去
// 但是两个指向的空间还是同一块,即都指向原本的mstart的mstr指向空间
// 再直白一点就是,使用memcpy函数之后
// temp里面的mstr和原本的mstart的mstr指向的是同一块空间
// 那么当mstart释放了之后,temp里面的mstr就成为了野指针
// 结论:如果对象中涉及资源管理(如动态内存、文件句柄、网络连接、数据库连接、锁资源等),
// 千万不能使用memcpy进行对象之间的拷贝!
// 因为memcpy是纯粹的字节级浅拷贝,仅复制对象的内存二进制数据,
// 不会调用对象的拷贝构造函数或赋值运算符,
// 完全无视对象的资源管理逻辑,最终必然引发严重问题
}
}怎么样大家,其实还是挺简单的,就是要注意保留原本的mfinish离mstart的距离,然后就是我们不能使用memcpy去浅拷贝,而是用循环或者copy函数去将原本的mstart数组里面的数据都转移到temp里面,其余的和string类中的实现reserve函数差不多的,正所谓一法通万法通。
实现vector的push_back函数:
OK大家,在我们前面铺垫了那么多之后,终于是迎来了模拟实现vector中最最重要的一个函数——push_back函数,那么其实实现它,也是和实现string类的push_back函数差不多的,只不过我们是不用下标来进行的,而是使用迭代器来直接解引用赋值,毕竟我们知道,其实成员变量mfinish这个迭代器(指针)就是指向数组的最后一个有效数据的下一个位置,所以我们可以直接解引用mfinish去将传入的值赋值给它,然后再去++mfinish去让mfinish这个指针往后移动一位,下面是详细步骤:
push_back函数的核心功能是在 vector 的尾部插入一个新元素,实现过程需兼顾空间检查、扩容处理和元素插入的安全性,详细步骤如下:
1. 检查当前空间是否足以容纳新元素
vector 的有效元素范围由mstart(起始)和mfinish(最后一个有效元素的下一个位置)标记,而总容量范围由mstart和mend_of_storage(存储空间末尾)标记。当size() == capacity()(即mfinish == mend_of_storage)时,说明当前已无剩余空间,若直接插入新元素会导致越界,因此必须先进行扩容。
2. 若空间不足,计算新容量并调用 reserve 扩容
-
计算新容量:为了平衡空间利用率和扩容效率,采用 “翻倍扩容” 策略:
- 若原容量(
oldcapacity)为 0(容器为空,初始状态),则新容量设为 2(避免初始容量为 0 时无法插入元素); - 若原容量大于 0,则新容量设为原容量的 2 倍(
2 * oldcapacity),减少频繁扩容的开销。
- 若原容量(
-
调用 reserve 函数:将计算出的
newcapacity传入reserve函数,由reserve负责开辟新空间、复制原有元素、释放旧空间并更新三个核心指针(mstart、mfinish、mend_of_storage),确保容器有足够空间容纳新元素。
3. 插入新元素到尾部
空间充足后(无论是否经过扩容),mfinish指针此时指向 “最后一个有效元素的下一个位置”,这个位置正是新元素的插入点。通过解引用mfinish指针(*mfinish = val),将新元素val赋值到该位置,完成元素的物理存储。
4. 更新有效元素的结束位置
插入元素后,mfinish指针需要向后移动一位(++mfinish),使其重新指向 “新的最后一个有效元素的下一个位置”,保证size()(mfinish - mstart)能正确反映当前有效元素的个数。
设计逻辑的核心考量
- 兼容性:由于 vector 存储的
type1可能是自定义类型(如string),插入时通过*mfinish = val调用元素的赋值运算符,确保自定义类型的资源管理逻辑(如深拷贝)被正确执行,避免浅拷贝问题。 - 效率:通过 “先检查空间再插入” 的逻辑,避免越界访问;翻倍扩容策略减少了扩容次数,降低了频繁申请内存和复制元素的开销。
- 状态一致性:每次操作后,
mstart <= mfinish <= mend_of_storage的关系始终成立,保证 vector 的内部状态正确。
下面是完整代码:
// 实现尾插函数
void push_back(const type1& val)
{
// 先检查剩余空间是否充足
if (size() == capacity()) // 等价于 mfinish == mend_of_storage
{
int oldcapacity = capacity();
size_t newcapacity = oldcapacity == 0 ? 2 : 2 * oldcapacity; // 修正原逻辑:初始容量为0时设为2,否则翻倍
reserve(newcapacity); // 扩容
}
// 成员变量为迭代器(指针类型),直接解引用赋值
*mfinish = val;
// 更新有效元素结束位置
++mfinish;
}还是很简单的大家。
实现vector的resize函数:
OK大家,我们知道,resize在vector中,还是比较重要的一个函数,比如我们在开辟二维数组的时候,它就排上了很大的用处,那么,我们又要怎么去实现出resize函数呢,首先resize函数的功能,大家应该是一清二楚的,那么我下面就直接讲实现步骤:
resize 函数的核心功能是调整 vector 的有效元素个数(size)为 n:若 n 小于当前 size,截断多余元素;若 n 大于当前 size,用指定值val填充新增的元素位置,同时按需扩容(保证容量足够容纳 n 个元素)。详细步骤如下:
一、明确函数核心参数与目标
void resize(const size_t& n, const type1& val = type1())
- 第一个参数
n:目标有效元素个数(最终size()需等于 n); - 第二个参数
val:新增元素的默认填充值,缺省值为type1()(即type1类型的默认构造对象,适配内置类型和自定义类型),大家注意,这个是我要着重强调的一个点:
type1& val:表示 val 是引用,引用 type1 类型的对象。引用的本质是 “对象的别名”,传递引用可以避免对象的拷贝开销 —— 如果直接传 type1 val,会生成对象的副本,既耗时又耗内存。而 const 修饰后,const type1& val 表示 “val 是对 type1 对象的只读引用”,函数内部不能通过 val 修改它所引用的对象,从而保证了 “初始值不会被函数意外篡改” 的语义。
默认参数 = type1 ():type1 () 的作用是调用 type1 类的默认构造函数,创建一个 type1 类型的临时对象 —— 如果 type1 是 int,int () 会生成值为 0 的临时 int;如果是自定义类,就会调用其无参构造。=type1 () 则是给参数 val 指定默认值:如果调用函数时没有传入第二个参数,val 会自动引用这个 “默认构造的临时对象”。之所以不直接给缺省值为 0,是因为我们无法预知存储进 vector 的数据类型 —— 万一传入的是 float、字符串或自定义类型,0 就不再适用。因此,将缺省值设为传入数据类型的默认构造函数(即 type1 ()),就能让编译器自动适配类型:对于 int、double、char等内置类型,虽然它们没有类那样的 “成员函数形式的默认构造函数”,但 C++ 标准规定,使用 T ()(T 为内置类型,比如 int ()、double ())时会进行 “值初始化”,结果会初始化为零值等价形式:int ()→0、double ()→0.0、指针类型(如 int())→nullptr(空指针)。所以直接给缺省值为对应数据类型的构造函数调用(type1 ()),就能适配所有类型,无需手动指定具体缺省值。
这一个是大家之前闻所未闻的,但是却是一个很实用的东西,希望大家能够掌握,再强调一下,格式就是 :
数据类型()- 核心目标:只改变 “有效元素个数”,不强制缩小容量(仅当 n 大于当前容量时才扩容)。
二、分两种情况处理:n ≤ 当前 size(截断元素)
当目标个数 n 小于或等于当前有效元素个数(size())时,无需新增元素,只需 “舍弃” 超出 n 的元素:
- 直接调整
mfinish指针的位置:将mfinish指向mstart + n; - 原理:
size()的计算逻辑是mfinish - mstart,调整后size()直接变为 n,超出 n 的元素不再被视为 “有效元素”(但内存未释放,容量capacity()不变); - 示例:若当前
size=5、n=3,则mfinish = mstart + 3,原第 4、5 个元素虽仍在内存中,但不再被 vector 管理,后续操作不会访问。
三、分两种情况处理:n > 当前 size(新增并填充元素)
当目标个数 n 大于当前size()时,需要新增n - size()个元素,且填充为val,步骤如下:
1. 先确保容量足够容纳 n 个元素(按需扩容)
- 调用
reserve(n):reserve函数会自动判断当前容量是否小于 n,若小于则扩容到 n(或更大,取决于reserve的扩容逻辑),若已大于等于 n 则不操作; - 目的:避免新增元素时出现空间不足的情况,为后续插入元素提供足够内存。
2. 记录当前初始有效元素个数(避免循环中逻辑错乱)
- 定义
old_size变量,存储当前size()(即mfinish - mstart); - 关键原因:后续插入元素会调用
push_back,而push_back会修改mfinish,导致size()动态变化。若直接在循环中用size()作为起始条件,会出现起始值不断变大、循环次数异常的问题,因此必须用初始old_size固定起始位置。
3. 循环插入新增元素(从old_size到 n-1)
- 循环条件:
i从old_size开始,到i < n结束(共循环n - old_size次,对应需要新增的元素个数),这个大家可以画图举例子理解:
假设现在有一个 vector,它存储的是 int 类型数据,当前的情况如下:
- 当前有效元素个数(old_size):假设
old_size = 3,也就是说vector里已经有 3 个元素,比如是[1, 2, 3]。 - 目标有效元素个数(n):假设
n = 5,我们需要把vector的有效元素个数调整为 5 个。
按照循环条件 i 从 old_size(也就是 3)开始,到 i < n(也就是 5)结束。那么循环的过程是:
- 第一次循环:
i = 3,此时执行push_back(val)(假设val = 0,即新增的元素值为 0),vector变为[1, 2, 3, 0]。 - 第二次循环:
i = 4,再次执行push_back(val),vector变为[1, 2, 3, 0, 0]。
此时 i = 5,不满足 i < n(5 < 5 不成立),循环结束。可以看到,循环一共执行了 n - old_size = 5 - 3 = 2 次,正好新增了 2 个元素,使得 vector 的有效元素个数从 3 变成了 5,和我们的目标一致。
- 插入逻辑:每次循环调用
push_back(val),将val作为新元素插入尾部; - 原理:
push_back会自动处理 “赋值元素 + 移动mfinish指针” 的逻辑,无需手动操作mfinish; - 示例:当前
size=3、n=5,则循环 2 次(i=3、i=4),新增 2 个val元素,最终size=5。
4. 无需手动更新mfinish
- 因为每次
push_back都会自动将mfinish向后移动一位,循环结束后mfinish恰好指向第 n 个元素的下一个位置,size()自然等于 n,无需额外调整。
四、核心设计逻辑与注意点
- 区分 “size” 和 “capacity”:
resize改变的是 “有效元素个数”(size),而reserve改变的是 “容量”(capacity);resize可能触发扩容(当 n>capacity 时),但不会主动缩小容量; - 兼容所有数据类型:填充值
val的缺省值为type1(),内置类型(如 int)的默认构造为 0,自定义类型(如 string)会调用其默认构造函数,保证适配性; - 避免循环逻辑错误:用
old_size记录初始size(),防止循环中size()动态变化导致的起始位置错乱; - 复用已有函数:新增元素时直接调用
push_back,无需重复写 “赋值 + 移动指针” 的逻辑,减少代码冗余,且保证逻辑一致性(如push_back已处理的类型兼容、空间检查等)。
总结
resize函数通过 “分情况处理(截断 / 新增)+ 复用reserve扩容 + 复用push_back插入” 的逻辑,高效、安全地将有效元素个数调整为 n,同时兼顾了类型兼容性和代码简洁性,核心是通过调整mfinish指针(截断场景)或新增元素(填充场景),最终让size()等于目标 n。
下面是完整代码:
// 实现 resize 函数
void resize(const size_t& n, const type1& val = type1())
{
if (n <= size())
{
// 如果小于的话,就保留前 n 个数据
mfinish = mstart + n;
}
else
{
// 如果大于原本的数据个数的话,就进行扩大数据个数
// 多余的数据全部初始化为传入的 val
// 不管怎么样,先开辟出大小为 n 的空间
// 至于要不要扩容,reserve 里面自然会去判断
reserve(n);
// 使用尾插去插入数据
// 其实就是从原本的 mfinish 位置开始,去尾插数据
// 直到插到第 n 个数据结束
// 也就是下标为 n 的前面一个位置结束
size_t old_size = size();
for (size_t i = old_size; i < n; ++i) // 举例得出
{
// 要注意不能将 i 初始化为 size(),
// 因为随着尾插,其实 size() 是会发生改变的,因为 mfinish 被改变了
// 所以就会导致 i 的起始值变来变去的
// 不符合 for 循环
// 所以我们要用一个变量去接收最开始的 size()
push_back(val);
}
// mfinish 自然会在尾插里面被更新
}
}其实大家仔细感受,还是挺简单的说实话,大家能理解三个成员变量就能很好的理解如何实现成员函数功能了。
OK大家,那么到了这里,字数也不少了,我们可以暂做休息,将剩下的内容放在下一篇博客中进行讲解,那才是模拟实现vector类的关键函数,比如构造函数、拷贝构造函数、insert函数和erase函数。
结语:
亲爱的朋友们,当敲下这行字时,仿佛能看到屏幕前的你正对着代码若有所思的模样。回顾这篇关于 vector 模拟实现的内容,从三个核心指针的设计到 reserve 的扩容逻辑,从 push_back 的尾插细节到 resize 的灵活调整,我们一步步拆解了这个看似复杂的容器背后的运作原理。或许此刻的你,心中既有对知识点串联的豁然,也有对细节处理的审慎 —— 这正是编程学习中最珍贵的状态:既见森林,也见草木。
还记得最初看到 vector 时,我们或许会觉得它不过是个 “万能数组”,可当亲手实现时才发现,每一个成员函数的背后都藏着对 “效率” 与 “安全” 的权衡。为什么要用三个指针而非 size 和 capacity?因为迭代器的设计需要指针运算的天然支持;为什么 reserve 要用 std::copy 而非 memcpy?因为自定义类型的资源管理容不得半点浅拷贝的马虎;为什么 push_back 要先检查容量?因为越界访问的代价可能是整个程序的崩溃。这些细节,就像容器的 “毛细血管”,看似微小,却决定了整个结构的健壮性。
尤其在实现 resize 函数时,那个 “type1 ()” 的默认参数设计,是不是让你对 C++ 的类型适配有了新的认识?它像一把万能钥匙,既能让 int 默认初始化为 0,也能让自定义类型调用自己的构造函数,这种 “以不变应万变” 的智慧,正是模板编程的魅力所在。而循环中用 old_size 固定初始大小的细节,更提醒我们:写代码不仅要实现功能,更要预判每一步操作可能引发的连锁反应 —— 就像下棋,多看一步,少踩一坑。
或许你会说,这些函数 STL 早就为我们写好了,何必自己再实现一遍?可正是在这一遍遍的 “重复造轮子” 中,我们才能触摸到抽象语法背后的逻辑骨架。当你亲手计算 mfinish - mstart 得到 size 时,就会明白 vector 的 size () 为何能做到 O (1) 的时间复杂度;当你在 reserve 中处理旧空间释放与新指针更新时,就会理解为什么扩容会导致迭代器失效;当你用 push_back 复用已有逻辑时,就会体会到 “代码复用” 不是一句空话,而是实实在在的工程智慧。
编程的学习,从来不是对 API 的死记硬背,而是对 “为什么这样设计” 的追问。就像我们在实现中反复对比 vector 与 string 的异同:它们同为顺序表,却因存储类型的灵活性而在细节上大相径庭。这种对比与思考,会让我们逐渐建立起对 “数据结构设计” 的全局认知 —— 什么时候该用指针管理内存?什么时候该用模板适配多类型?什么时候该牺牲一点空间换取效率?这些问题的答案,都藏在我们敲下的每一行代码里。
写到这里,突然想起初学数据结构时的自己,也曾对着 “顺序表扩容” 的逻辑犯愁:为什么要翻倍扩容而不是按需扩容?后来才明白,这是为了平衡时间复杂度 —— 就像我们生活中备东西,一次多买些,能减少频繁采购的麻烦。编程与生活,在 “权衡” 这一点上,竟是如此相似。
接下来的篇章里,我们还要攻克构造函数、拷贝构造、insert 与 erase 这些更具挑战性的内容。它们会涉及到深拷贝的陷阱、迭代器失效的场景、元素插入时的内存移动…… 这些都是 vector 实现中的 “硬骨头”,但也正是提升我们编程功底的关键。别怕难,就像这篇文章里的内容,初看复杂,拆解后便会发现:所谓难点,不过是一个个简单逻辑的叠加。
最后,想对你说:学习编程就像搭建积木,每一个知识点都是一块积木。今天我们搭好了 vector 的 “地基”—— 成员变量与基础函数,明天就能在此之上搭建更复杂的 “楼层”。或许过程中会有疏漏,会有调试时的挫败,但请相信,每一次对 bug 的追查,都是对逻辑的再梳理;每一次对细节的打磨,都是对思维的再锤炼。
愿你在接下来的学习中,依然保持这份拆解问题的耐心与勇气。当有一天,你能从容地写出一个完整的 vector,甚至能根据需求设计出更贴合场景的数据结构时,定会感谢此刻愿意沉下心来 “造轮子” 的自己。我们下一篇博客再见,那时的你,一定比现在更靠近 “知其然,更知其所以然” 的境界。加油,编程路上的同行者!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 51
51 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)