②多模态联合训练-Kimi K2.5 技术报告解读
本文探讨了文本-视觉联合训练的优化策略。研究发现,早期以恒定比例融合视觉与文本token进行多模态预训练,能显著提升模型表现。通过"zero-vision SFT"方法,仅使用文本数据即可激活视觉能力,且视觉强化学习还能反哺文本性能。Kimi K2.5采用按能力而非模态组织的联合RL范式,实现了跨模态能力迁移。案例显示,模型能通过工具调用将复杂视觉任务转化为可编程操作,展现了强
文本-视觉 联合训练
原生多模态预训练
亮点: 相比于传统的先训练一个纯文本模型,后期才加入视觉能力变成VL的方法。K2.5 发现在视觉-文本总 token 数量固定的情况下,早期以较低比例融合视觉信息的效果更好。因此,K2.5在整个训练过程中始终以恒定比例混合文本与视觉token。
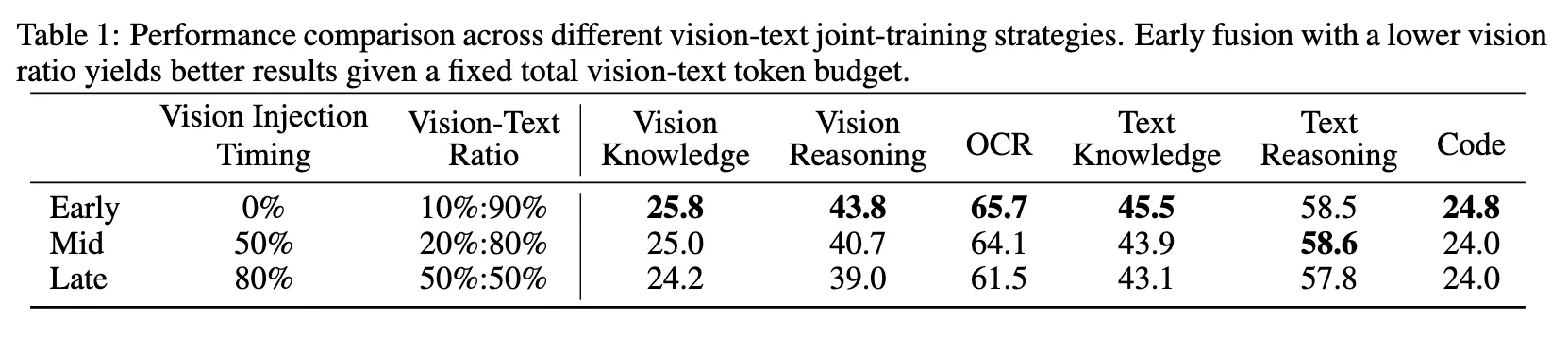
这张表展示了使用不同的多模态联合训练策略下,模型的表现对比。
- Vision Injection Timing: 在训练的哪个阶段开始介入视觉 token,0%是指在最开始训练时就是视觉-文本的混合训练,50%就是使用一半的数据训练后,才开始加入视觉 token。
- Vision-Text Ratio: 在 Vision Injection Timing 时刻加入了视觉 token 后,训练数据中视觉 token 和文本 token 所占的比例。
- 举一个栗子🌰: 假设所有的训练数据中有10w的视觉token,90w文本token。那么 Early 策略就是一直使用1:9的比例去训练;Mid策略就是先用50w文本token训练,再用10w视觉token+10w文本token训练;Late 策略就是先用80w文本token训练,再用10w视觉token+10w文本token训练。
由此得出,在多模态模型训练的的开始阶段就加入视觉 token,不仅可以提升多模态的融合效果,也可以提升每个单模态的能力。这启发了原生多模态预训练策略:不再将大量视觉训练集中在后期,而是在训练早期就以适中视觉比例融入,使模型在延长双模态协同优化的同时,自然发展出均衡的多模态表征。
Zero-Vision SFT
在经过上述预训练后的VLM只能理解视觉信息,但并不具备基于视觉的工具调用能力,这为多模态 RL 带来了冷启动问题。传统的方式使用人工标注或基于 Prompt 生成的 CoT 数据,但这类方法在多样性上受限,通常将视觉推理局限于简单图表和基础工具操作(裁剪、旋转、翻转)。
Kimi 发现,高质量的文本 SFT 数据相对丰富且多样,提出了zero-vision SFT,仅使用文本SFT数据在后训练阶段不仅激活 Agent 能力,也激活视觉能力。在该方法中,所有图像操作均通过 IPython 中的程序化操作完成,有效泛化了传统的视觉工具使用。这种“zero-vision”激活支持多种推理行为,包括通过二值化与计数实现的像素级操作(如物体尺寸估计),并可泛化至视觉定位、计数及 OCR 等视觉基础任务。
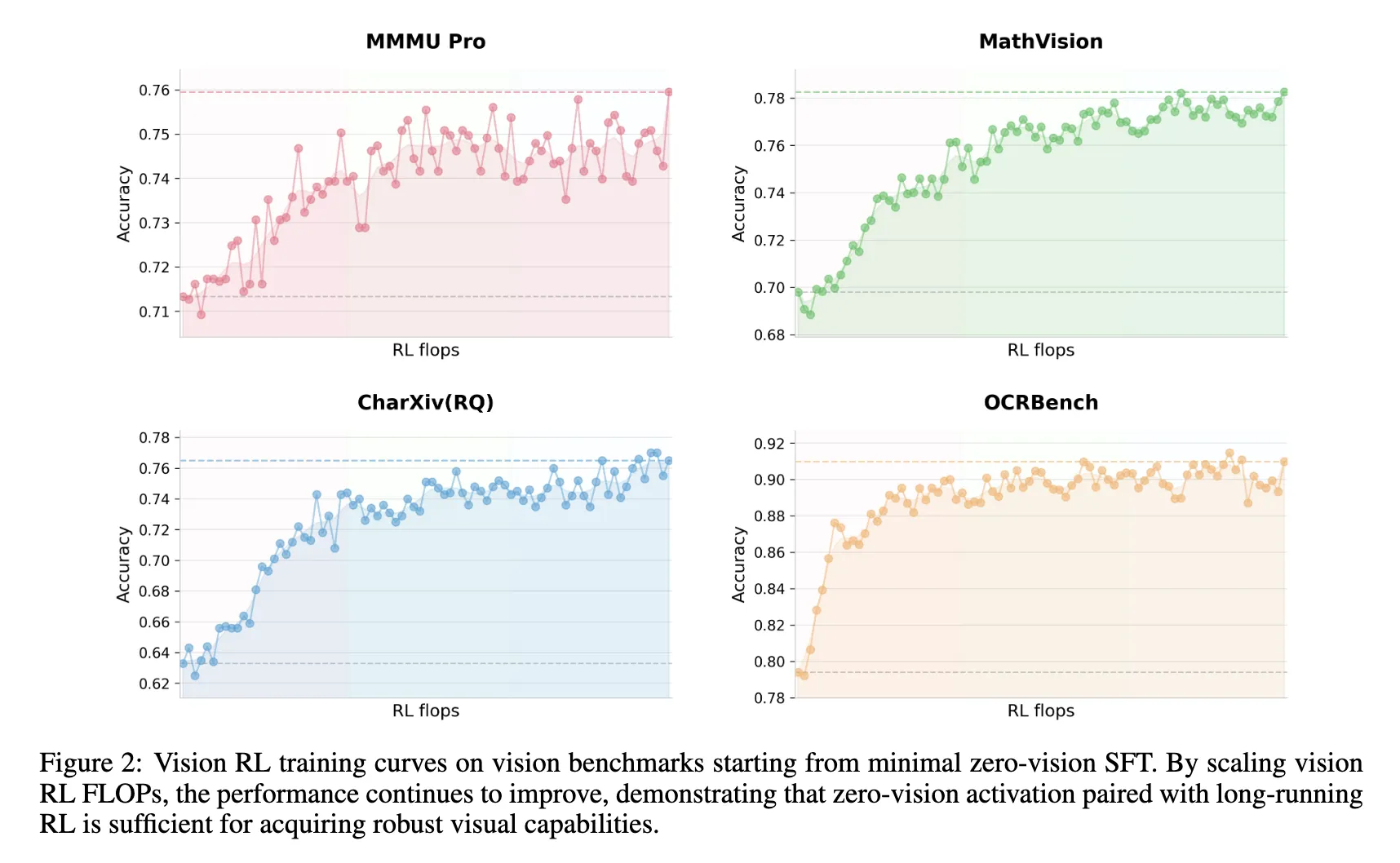
- 图中展示了模型性能随 RL 训练的曲线,由 zero-vision SFT 后的模型进行 RL 训练而来。
- 结果表明,zero-vision SFT足以激活视觉能力,同时确保跨模态泛化。
- 这一现象可能源于上述的文本与视觉数据联合预训练。
- 与zero-shot SFT相比,文本-视觉 SFT 在视觉、智能体任务上表现更差,可能由于缺乏高质量视觉数据。(但是在技术报告中并未找到相关的对比数据)

- 视觉强化学习提升文本性能:
- 为探究视觉与文本性能之间可能存在的权衡,我们在视觉 RL 训练的前后评估了纯文本的 benchmark。基于结果的视觉强化学习在文本任务上居然也带来了可量化的提升,
- 视觉强化学习增强了需要结构化信息提取领域的校准能力,降低了对类似视觉基础推理查询(如计数、OCR)的不确定性。这些发现表明,视觉强化学习可促进跨模态泛化,在不显著削弱语言能力的前提下改善文本推理。
- 多模态联合强化学习:
- 鉴于“zero-visioin SFT” 与视觉 RL 可涌现鲁棒视觉的能力,并进一步提升通用文本能力”的发现。在 Kimi K2.5 的后训练中采用联合多模态 RL 范式。
- 区别于传统的按输入模态划分专家的做法,Kimi K2.5 不再按模态、而是按能力——知识、推理、编程、智能体等——来组织 RL 领域。这些领域专家同时从纯文本和多模态查询中联合学习,生成式奖励模型(GRM)也在异构轨迹上跨模态无壁垒地优化。
- 该范式确保通过文本或视觉输入获得的能力提升,能够自然地泛化到另一模态的相关能力,从而最大化跨模态能力迁移。
这个视觉 tool call 能力具体指做什么?我从Kimi技术报告Blog中找到了答案:
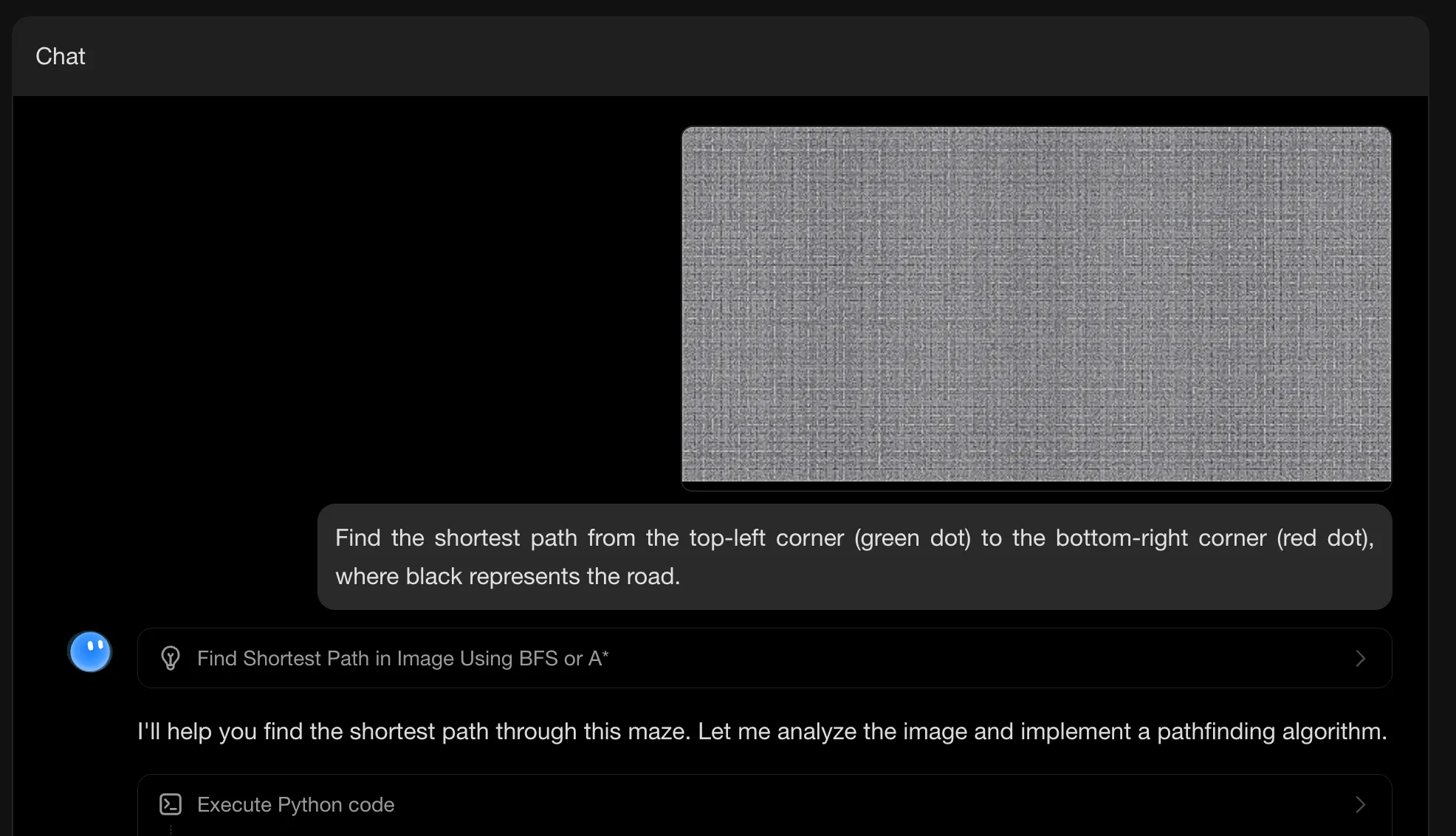
用户给 Agent 发送了一个类似马赛克的图片,其实这是一个非常复杂的迷宫,单凭模型的视觉能力+推理是很难完成的。
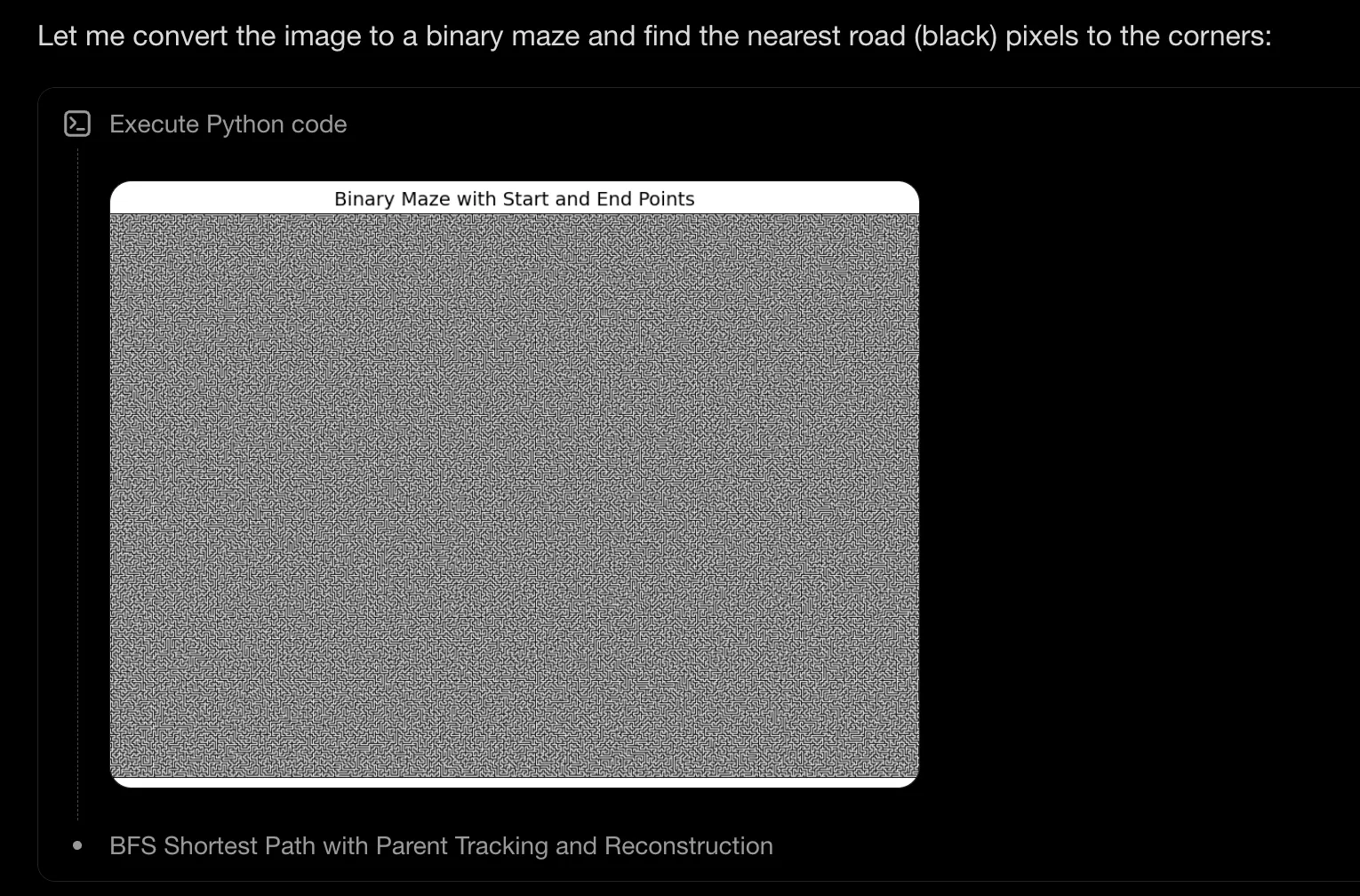

于是模型很聪明地想到了,先使用工具,把对这个图进行二值化处理,变成一个代码可操作的矩阵。然后继续使用 Python 调用相关的走迷宫算法即可完成这个看似复杂的任务了。这或许就是 vision agent 能力的独特魅力了,这种对图片进行 review 然后再调用工具的能力,特别适合网页前端设计和 vidio agent,这可能也是 Kimi K2.5 的前端设计能力特别强的原因,估计 kimi 的下一步可能就是 video agent 了!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)