多模态大模型学习笔记(二)——机器学习十大经典算法:一张表看懂分类 / 回归 / 聚类 / 降维
回归选线性回归/决策树系,看是否需要非线性拟合;分类按数据规模/维度选逻辑回归/朴素贝叶斯/KNN/SVM/决策树系;聚类优先K-means,降维优先PCA。后续我们将针对每类算法展开实战教程,包括代码实现、调参技巧和业务落地案例,帮你从“懂理论”到“能落地”。
机器学习十大经典算法:一张表看懂分类 / 回归 / 聚类 / 降维
在上一篇内容中,我们梳理了机器学习的核心任务体系(监督/无监督学习),以及回归、分类、聚类、降维四大核心任务的底层逻辑。本篇将聚焦机器学习十大经典算法,用“表格+可视化图解”的形式,拆解每类算法的适用场景、核心逻辑和关键特性,帮你快速匹配算法与业务需求。
1 先看核心:十大算法与四大任务的对应关系
机器学习算法的选择,第一步是“按任务定算法范围”。以下这张表清晰标注了十大经典算法分别对应回归、分类、聚类、降维四大核心任务,帮你快速定位:
| 回归 | 分类 | 聚类 | 降维 | |
|---|---|---|---|---|
| 监督学习 | 1. 线性回归 | |||
| 2. 逻辑回归 | ||||
| 3. 朴素贝叶斯 | ||||
| 4. KNN | ||||
| 5. SVM | ||||
| 6. 决策树回归 | 6. 决策树 | |||
| 7. 随机森林回归 | 7. 随机森林 | |||
| 8. GBDT 回归 | 8. GBDT | |||
| 非监督学习 | 9. K-means | |||
| 10. PCA |
2 回归任务:预测连续数值的核心算法
回归任务的核心是“预测连续型结果”(如房价、销量、温度),十大算法中聚焦回归的有4类,且均属于监督学习范畴:
2.1 线性回归:最基础的线性拟合工具
线性回归是回归任务的“基线算法”,核心是拟合输入特征与输出数值的线性关系(y = wx + b),权重系数可直接反映特征对结果的影响程度。
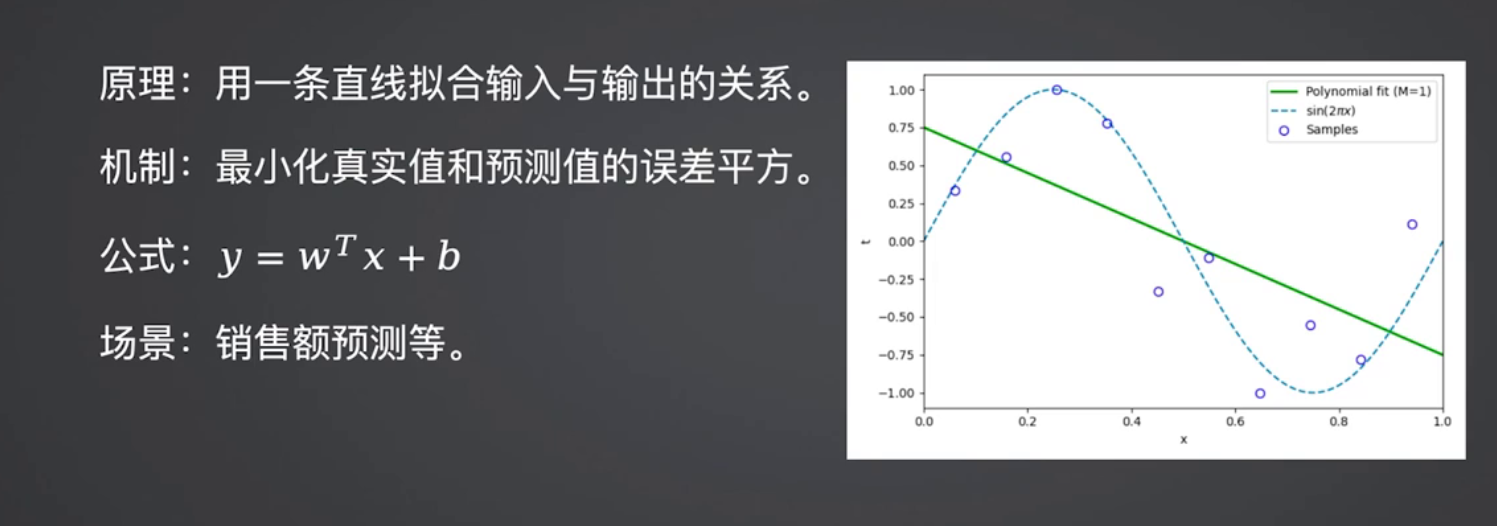
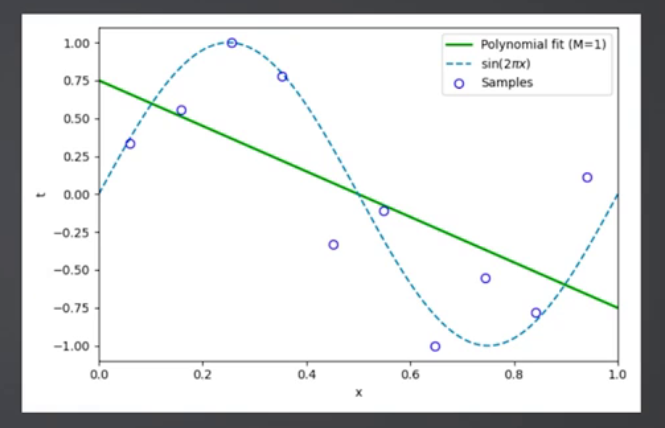
适用场景:房价初步预测、销量基线计算、风控中特征权重分析(如收入对还款能力的影响);
核心特点:可解释性极强、训练/预测速度快,但仅能拟合线性关系。
2.2 决策树回归/随机森林回归/GBDT回归:非线性回归的核心
这三类算法既支持分类也支持回归,是处理非线性回归任务的核心工具,三者的核心差异在于“模型构建逻辑”:
- 决策树回归:通过树状规则划分特征空间,直观但易过拟合;
- 随机森林回归:多棵决策树投票平均,鲁棒性强、抗过拟合;
- GBDT回归:串行修正误差,精度极高但训练速度慢。

决策树核心结构(回归/分类通用)

随机森林多树集成逻辑

GBDT误差修正逻辑
适用场景:
- 决策树回归:信贷额度预测(需明确决策规则);
- 随机森林回归:电商销量预测(抗噪、稳定性优先);
- GBDT回归:推荐系统评分预测(精度优先)。
3 分类任务:判断离散类别的7大核心算法
分类任务是监督学习中最常用的场景(如垃圾邮件识别、用户标签分类),十大算法中有7类聚焦分类,覆盖不同数据规模、维度和可解释性需求:

分类任务核心逻辑框架
3.1 逻辑回归:二分类的“基线王者”
逻辑回归基于线性回归扩展,通过Sigmoid函数将输出映射到0~1区间,实现二分类概率预测,是高维稀疏数据分类的首选基线算法。
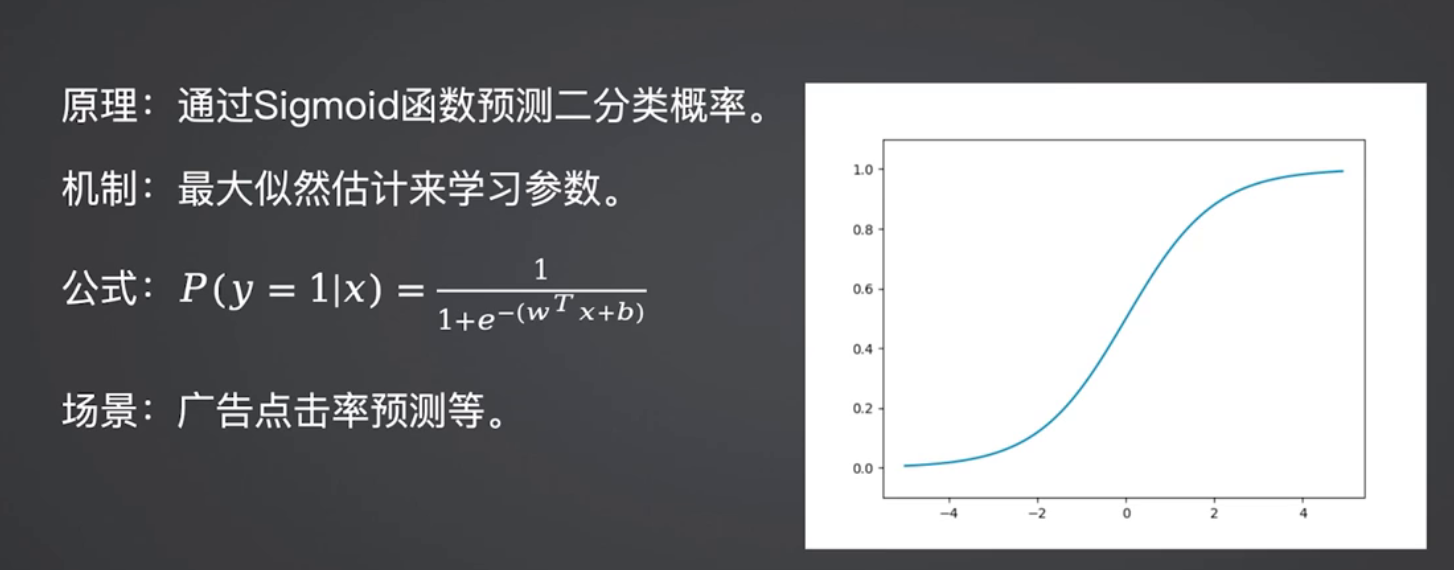

适用场景:垃圾邮件识别、贷款风险判断、广告点击率预测(十万级数据+几百维特征)。
3.2 朴素贝叶斯:高维稀疏数据的“极速工具”
基于贝叶斯定理,假设特征独立,训练/预测速度极快,对文本类高维稀疏数据友好。


适用场景:新闻分类、垃圾短信识别、百万级用户行为标签分类。
3.3 KNN:小样本数据的“惰性分类器”
核心是“物以类聚”,无需训练,新样本类别由最近K个邻居决定,适合小样本、低维数据。

适用场景:小型数据集图像识别(小于1万样本+几十维特征)。
3.4 SVM:高维小样本的“高精度选择”
寻找最优超平面最大化类别间隔,通过核函数处理非线性数据,高维小样本下精度突出。
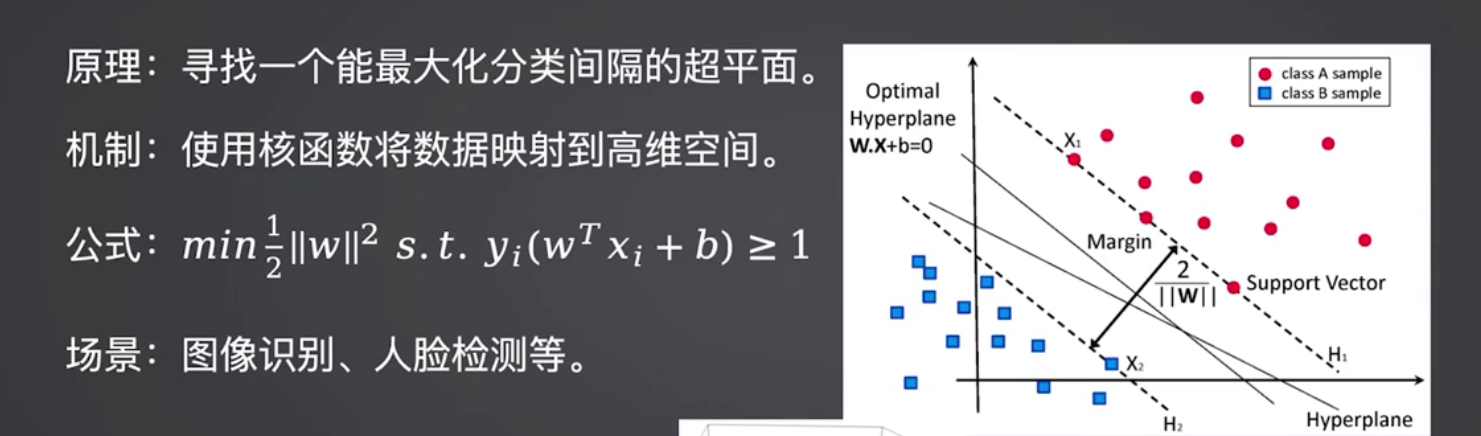
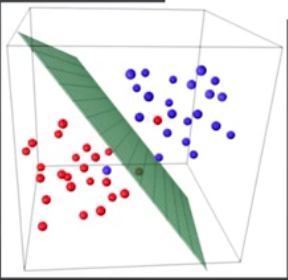

适用场景:基因数据分类、图像特征分类(十万级高维小样本)。
3.5 决策树/随机森林/GBDT:分类任务的“进阶组合”
三类算法在分类场景的特性与回归场景一致,核心差异在于输出为离散类别:
- 决策树:可解释性强,适合生成信贷审批规则;
- 随机森林:鲁棒性强,适合电商用户分层;
- GBDT:精度最高,适合精准风控分类。
3.6 分类算法选型速查表
| 数据规模 | 维度数量 | 可解释性要求 | 算力和时间需求 | 分类算法 |
|---|---|---|---|---|
| 十万级 | 几百维 | 强(权重系数可解释) | 训练快,预测快,适合 baseline | 逻辑回归 |
| 百万级 | 高维稀疏 | 中(概率结果可解释) | 极快,训练和预测开销都低 | 朴素贝叶斯 |
| 小于一万 | 几十维 | 弱(黑箱投票) | 无训练,大样本时非常缓慢 | KNN |
| 十万级 | 高维小样本 | 中(支持向量可解释) | 训练慢,预测速度中 | SVM |
| 十万级 | 几百维 | 强(树结构直观) | 训练快,预测速度快,易过拟合 | 决策树 |
| 百万级 | 高维稀疏 | 中(可看特征重要性) | 训练慢,预测速度中,鲁棒性好 | 随机森林 |
| 百万级以上 | 高维稀疏 | 弱(黑箱,难解释) | 训练慢,预测比 RF 慢,精度最高 | GBDT |
4 无监督学习:聚类与降维的2大核心算法
无监督学习无需标签,核心是挖掘数据内在规律,十大算法中K-means(聚类)和PCA(降维)是最经典的代表:
4.1 K-means:数据分组的“基础工具”
K-means通过迭代更新聚类中心,将数据按相似性分组,是用户分群、商品聚类的首选。

聚类任务核心逻辑

K-means迭代过程
适用场景:电商用户消费习惯分群、异常交易识别前置聚类。
4.2 PCA:高维数据的“压缩神器”
PCA通过线性变换将高维数据映射到低维空间,保留核心信息,是图像、文本数据降维的核心工具。
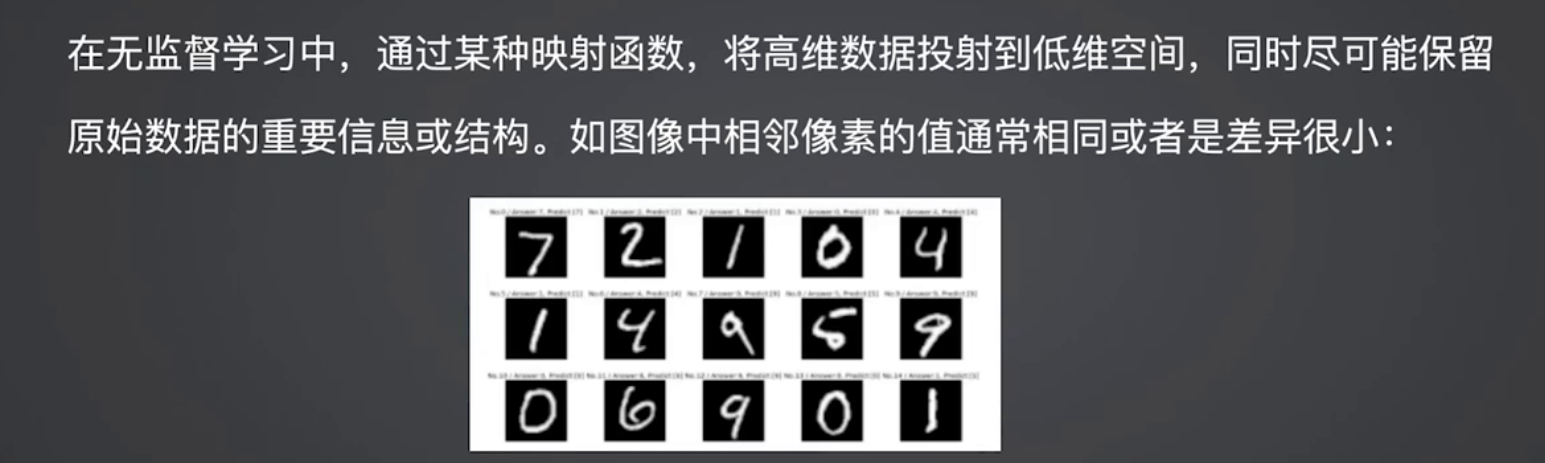
降维任务核心逻辑

PCA维度压缩逻辑
适用场景:高维图像特征降维、用户行为数据维度压缩。
5 算法落地:从选型到训练的核心逻辑
掌握十大算法的分类与特性后,落地机器学习任务需遵循“任务定义→算法选型→训练调优→评估迭代”的流程,其中训练调优的核心是“损失函数+正则化”,避免过拟合、提升泛化能力:

机器学习任务的一般步骤

过拟合问题与正则化解决思路
6 总结
机器学习十大经典算法的核心是“匹配场景”:
- 回归选线性回归/决策树系,看是否需要非线性拟合;
- 分类按数据规模/维度选逻辑回归/朴素贝叶斯/KNN/SVM/决策树系;
- 聚类优先K-means,降维优先PCA。
后续我们将针对每类算法展开实战教程,包括代码实现、调参技巧和业务落地案例,帮你从“懂理论”到“能落地”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 5
5 0
0- 0



 已为社区贡献62条内容
已为社区贡献62条内容

所有评论(0)