2026年02月09日热门论文
本文总结了前沿论文围绕LLM应用的五大核心趋势:1)LLM Agent能力强化,聚焦可靠性、记忆管理与安全防御;2)多模态融合与推理,推动感知向协同推理演进;3)检索与深度推理联动,解决知识时效性与推理深度问题;4)优化算法与效率提升;5)构建真实场景评估体系。重点介绍了CAR-bench评估Agent一致性、Spider-Sense分层防御框架、MemSkill动态记忆优化等创新工作,以及多模态
论文趋势总结与分类
“工欲善其事,必先利其器;器欲尽其用,必先明其道。” 前沿论文,围绕LLM从“能力生成”到“价值落地”的关键转型,形成五大核心趋势与分类,深刻回应真实场景对模型可靠性、交互性、适配性的迫切需求:
- LLM Agent能力强化类:聚焦Agent在真实环境中的可靠性、记忆管理、长期规划与安全防御,破解“理想场景强、真实场景弱”的痛点,是LLM落地的核心支撑。
- 多模态融合与推理类:打破文本与视觉、音频的壁垒,推动多模态模型从“感知融合”走向“推理协同”,拓展模型应用边界。
- 检索与深度推理类:强化检索与推理的闭环联动,解决“知识时效性”与“推理深度”的双重难题,赋能深度研究、科学分析等复杂任务。
- 优化算法与效率提升类:针对模型训练与推理的效率瓶颈,优化优化器、解码策略等底层技术,实现“提质增效”的双重目标。
- 基准测试与评估体系类:构建更贴近真实场景的评估框架,填补现有基准在跨领域、复杂推理、社会交互等维度的空白,为模型迭代提供科学标尺。
一、LLM Agent能力强化类
-
★★★★★ CAR-bench: Evaluating the Consistency and Limit-Awareness of LLM Agents under Real-World Uncertainty
核心应用场景:车载语音助手等真实交互场景
创新点:“明者因时而变,知者随事而制”,针对现有基准忽视真实场景中用户输入模糊性的缺陷,构建含58个互联工具、LLM模拟用户的CAR-bench,引入幻觉任务与消歧任务,首次系统评估Agent的一致性、不确定性处理与能力认知,揭示前沿模型在消歧任务中通过率不足50%的核心痛点。
论文地址:https://huggingface.co/papers/2601.22027 -
★★★★☆ Spider-Sense: Intrinsic Risk Sensing for Efficient Agent Defense with Hierarchical Adaptive Screening
核心应用场景:自主Agent的安全防御
创新点:“防患于未然,未雨而绸缪”,突破传统强制检查的防御范式,提出基于内在风险感知(IRS)的事件驱动防御框架,通过轻量相似匹配与深度内部推理的分层机制,在降低8.3%延迟开销的同时,实现最低攻击成功率(ASR)与误报率(FPR),为Agent安全注入“蜘蛛感应”。
论文地址:https://huggingface.co/papers/2602.05386 -
★★★☆☆ MemSkill: Learning and Evolving Memory Skills for Self-Evolving Agents
核心应用场景:长历史交互场景下的Agent记忆管理
创新点:“学而不思则罔,思而不学则殆”,重构Agent静态记忆操作為可学习、可进化的记忆技能,通过控制器-执行器-设计者的闭环架构,动态选择记忆技能并迭代优化,解决传统记忆系统刚性强、效率低的问题,在多任务中实现性能与泛化性双提升。
论文地址:https://huggingface.co/papers/2602.02474 -
★★☆☆☆ Accurate Failure Prediction in Agents Does Not Imply Effective Failure Prevention
核心应用场景:Agent部署前的干预有效性评估
创新点:“差之毫厘,谬以千里”,揭示LLM评论模型的离线高准确率与部署时性能波动的矛盾,提出“破坏-恢复”权衡理论与含50个任务的预部署测试,可精准预判干预对高成功率任务的退化风险(最高达26个百分点)与高失败率任务的微弱提升,为Agent可靠部署提供科学依据。
论文地址:https://huggingface.co/papers/2602.03338 -
★★☆☆☆ ProAct: Agentic Lookahead in Interactive Environments
核心应用场景:交互式环境中的长horizon规划任务
创新点:“凡事预则立,不预则废”,通过接地前瞻蒸馏(GLAD)与蒙特卡洛评论器(MC-Critic)的两阶段训练,让Agent内化前瞻推理逻辑,压缩复杂搜索树为因果推理链,4B参数模型在随机与确定性环境中均超越开源基线,逼近闭源模型性能。
论文地址:https://huggingface.co/papers/2602.05327 -
★★☆☆☆ Reinforcement World Model Learning for LLM-based Agents
核心应用场景:文本状态下的Agent环境适应
创新点:“知行合一,笃行致远”,提出自监督的强化世界模型学习(RWML),通过模拟与真实状态的嵌入空间对齐,解决Agent难以预判动作后果的问题,相比直接任务奖励RL,在ALFWorld与τ² Bench分别提升6.9与5.7个百分点,且抗奖励攻击能力更强。
论文地址:https://huggingface.co/papers/2602.05842 -
★★☆☆☆ LatentMem: Customizing Latent Memory for Multi-Agent Systems
核心应用场景:多Agent协作系统的记忆定制
创新点:“和而不同,各展其长”,针对多Agent记忆同质化与信息过载问题,设计含经验库与记忆合成器的LatentMem框架,通过潜记忆策略优化(LMPO)生成Agent专属紧凑记忆,在主流框架中实现最高19.36%的性能提升,且无需修改底层架构。
论文地址:https://huggingface.co/papers/2602.03036 -
★☆☆☆☆ Towards Reducible Uncertainty Modeling for Reliable Large Language Model Agents
核心应用场景:Agent不确定性量化与安全管控
创新点:“知其然,更知其所以然”,突破单轮问答的不确定性量化局限,提出Agent的条件不确定性降低框架,将不确定性建模从“累积过程”重构为“交互降低过程”,为LLM Agent的可靠部署提供首个通用理论范式与设计指南。
论文地址:https://huggingface.co/papers/2602.05073
二、多模态融合与推理类
-
★★☆☆☆ Context Forcing: Consistent Autoregressive Video Generation with Long Context
核心应用场景:长时视频生成的时序一致性保障
创新点:“承前启后,一脉相承”,破解学生-教师失配导致的长视频生成瓶颈,通过长上下文教师模型引导学生训练,结合快慢记忆架构减少视觉冗余,实现超20秒有效上下文长度(较现有方法提升2-10倍),保障2分钟长视频的时序一致性。
论文地址:https://huggingface.co/papers/2602.06028 -
★★☆☆☆ RISE-Video: Can Video Generators Decode Implicit World Rules?
核心应用场景:文本-图像到视频(TI2V)生成的推理能力评估
创新点:“形而上者谓之道,形而下者谓之器”,跳出视觉保真度评估的局限,构建含467个人工标注样本的RISE-Video基准,从推理对齐、时序一致性、物理合理性、视觉质量四维度,揭示现有TI2V模型在隐含世界规则理解上的普遍缺陷。
论文地址:https://huggingface.co/papers/2602.05986 -
★★☆☆☆ Thinking in Frames: How Visual Context and Test-Time Scaling Empower Video Reasoning
核心应用场景:视觉推理任务(迷宫导航、七巧板拼图)
创新点:“见微知著,由表及里”,将视频生成模型重构为视觉推理范式,通过生成帧作为中间推理步骤,验证模型在零样本泛化、视觉上下文利用与测试时缩放的三大核心能力,揭示增加视频长度可提升复杂路径推理的规律。
论文地址:https://huggingface.co/papers/2601.21037 -
★★☆☆☆ SwimBird: Eliciting Switchable Reasoning Mode in Hybrid Autoregressive MLLMs
核心应用场景:多模态场景下的自适应推理
创新点:“因材施教,因地制宜”,突破多模态模型固定推理模式的局限,提出可切换推理模式的MLLM,支持文本仅推理、视觉仅推理、交织推理三种模式,通过混合自回归公式与92K监督微调数据集,在文本逻辑与视觉密集任务中实现双向优化。
论文地址:https://huggingface.co/papers/2602.06040 -
★☆☆☆☆ V-Retrver: Evidence-Driven Agentic Reasoning for Universal Multimodal Retrieval
核心应用场景:通用多模态检索
创新点:“实事求是,循证而行”,重构多模态检索为基于视觉检查的Agent推理过程,通过外部视觉工具主动获取证据,结合课程学习与强化学习,实现假设生成与视觉验证的交替推理,平均提升检索准确率23.0%,增强感知驱动推理的可靠性。
论文地址:https://huggingface.co/papers/2602.06034 -
★★☆☆☆ Reinforced Attention Learning
核心应用场景:多模态LLM的注意力优化
创新点:“提纲挈领,纲举目张”,突破传统强化学习优化输出序列的局限,提出直接优化内部注意力分布的RAL框架,通过策略梯度方法提升信息分配与跨模态对齐,结合在线注意力蒸馏,在图像与视频基准中持续超越GRPO等基线。
论文地址:https://huggingface.co/papers/2602.04884
三、检索与深度推理类
-
★★☆☆☆ Semantic Search over 9 Million Mathematical Theorems
核心应用场景:数学定理检索与定理证明辅助
创新点:“博观而约取,厚积而薄发”,构建含920万条人类撰写定理的大规模语料库,以自然语言描述为检索表示,系统分析表示上下文、模型选择等关键因素,在专业数学家查询集上,定理级与论文级检索性能显著超越Google搜索与前沿LLM, latency仅4秒。
论文地址:https://huggingface.co/papers/2602.05216 -
★★☆☆☆ Retrieval-Infused Reasoning Sandbox: A Benchmark for Decoupling Retrieval and Reasoning Capabilities
核心应用场景:深度研究场景的文档接地推理评估
创新点:“抽丝剥茧,去伪存真”,提出DeR2基准,通过四种证据访问机制(仅指令、仅概念、仅相关文档、全量文档)分离检索损失与推理损失,结合两阶段验证避免参数泄露,揭示部分模型在干扰文档存在时性能退化的“模式切换脆弱性”。
论文地址:https://huggingface.co/papers/2601.21937 -
★★☆☆☆ SAGE: Benchmarking and Improving Retrieval for Deep Research Agents
核心应用场景:深度研究Agent的文献检索优化
创新点:“工欲善其事,必先利其器”,构建含1200个跨四领域查询、20万篇论文的SAGE基准,发现传统BM25检索在研究Agent场景中比LLM基检索器优30%,提出语料级测试时缩放框架,通过LLM增强文档元数据与关键词,在短问题与开放问题中分别提升8%与2%检索性能。
论文地址:https://huggingface.co/papers/2602.05975
四、优化算法与效率提升类
-
★★☆☆☆ Length-Unbiased Sequence Policy Optimization: Revealing and Controlling Response Length Variation in RLVR
核心应用场景:LLM与VLM的RLVR训练优化
创新点:“衡外情,量己力,察时势”,揭示RLVR算法中响应长度偏差导致的性能波动问题,提出长度无偏序列策略优化(LUSPO),修正GSPO的长度偏差,解决响应长度崩溃问题,在数学推理与多模态推理场景中持续超越GRPO、GSPO等方法。
论文地址:https://huggingface.co/papers/2602.05261 -
★★☆☆☆ DFlash: Block Diffusion for Flash Speculative Decoding
核心应用场景:LLM的推理效率提升
创新点:“兵贵神速,效率为先”,突破投机解码中自回归草稿生成的局限,提出基于轻量块扩散模型的并行草稿生成框架,通过目标模型上下文特征条件化,实现6倍无损加速,较EAGLE-3提升2.5倍速度,兼顾生成质量与GPU利用率。
论文地址:https://huggingface.co/papers/2602.06036 -
★★☆☆☆ Dr. Kernel: Reinforcement Learning Done Right for Triton Kernel Generations
核心应用场景:Triton内核生成的RL训练优化
创新点:“对症下药,有的放矢”,针对内核生成中奖励攻击与懒惰优化问题,设计KernelGYM分布式GPU环境,提出轮次级强化留一法(TRLOO)解决GRPO的偏置策略梯度问题,结合性能分析奖励(PR)与拒绝采样(PRS),14B模型生成内核在KernelBench中1.2倍加速率达47.8%,超越Claude-4.5-Sonnet与GPT-5。
论文地址:https://huggingface.co/papers/2602.05885 -
★☆☆☆☆ DASH: Faster Shampoo via Batched Block Preconditioning and Efficient Inverse-Root Solvers
核心应用场景:神经网络训练的优化器加速
创新点:“工欲速则不达,欲速而得者,必以其道”,针对Shampoo优化器计算开销大的痛点,将预条件块堆叠为3D张量提升GPU利用率,引入Newton-DB迭代与切比雪夫多项式近似加速逆矩阵根计算,实现4.83倍优化器步骤加速,同时降低验证困惑度。
论文地址:https://huggingface.co/papers/2602.02016 -
★★☆☆☆ Privileged Information Distillation for Language Models
核心应用场景:多轮Agent环境的模型蒸馏
创新点:“他山之石,可以攻玉”,解决特权信息(PI)训练与无PI推理的迁移难题,提出π-Distill联合师生目标与OPSD自蒸馏方法,仅通过动作轨迹蒸馏前沿Agent,在多Agent基准中超越监督微调+RL的行业标准,为闭源模型能力迁移提供新路径。
论文地址:https://huggingface.co/papers/2602.04942
五、基准测试与评估体系类
-
★★☆☆☆ BABE: Biology Arena BEnchmark
核心应用场景:生物领域AI的实验推理能力评估
创新点:“格物致知,知行合一”,基于同行评审论文与真实生物研究构建BABE基准,聚焦实验推理、因果推理与跨尺度推理,填补现有生物基准对“科学家级推理”评估的空白,为AI赋能生物研究提供精准度量工具。
论文地址:https://huggingface.co/papers/2602.05857 -
★★☆☆☆ SocialVeil: Probing Social Intelligence of Language Agents under Communication Barriers
核心应用场景:语言Agent的社会智能评估
创新点:“言为心声,沟通为桥”,模拟语义模糊、社会文化失配、情绪干扰三大真实沟通障碍,构建含720个场景的SocialVeil环境,提出未解决困惑与相互理解两大评估指标,揭示前沿LLM在障碍下相互理解度下降45%的现状,为Agent社会交互能力优化提供依据。
论文地址:https://huggingface.co/papers/2602.05115 -
★★☆☆☆ Grounding and Enhancing Informativeness and Utility in Dataset Distillation
核心应用场景:数据集蒸馏的质量优化与评估
创新点:“去粗取精,化繁为简”,从理论上定义数据集蒸馏的信息量与效用性,提出InfoUtil框架,通过沙普利值归因最大化信息量、梯度范数选择最大化效用性,在ImageNet-1K上用ResNet-18实现6.1%性能提升,为紧凑数据集构建提供科学方法。
论文地址:https://huggingface.co/papers/2601.21296
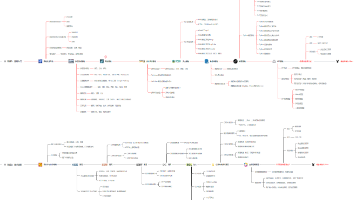
思维导向图(结构化呈现)
核心主题:2026年初LLM从“能力生成”到“价值落地”的关键转型
│
├─ 趋势核心:可靠性、交互性、多模态适配、效率提升、科学评估
│
├─ 五大分类分支
│ ├─ 1. LLM Agent能力强化(落地核心支撑)
│ │ ├─ 可靠性评估:CAR-bench(车载场景不确定性)
│ │ ├─ 安全防御:Spider-Sense(内在风险感知)
│ │ ├─ 记忆管理:MemSkill(可进化记忆技能)
│ │ ├─ 规划能力:ProAct(前瞻推理蒸馏)
│ │ └─ 部署评估:Accurate Failure Prediction(干预有效性测试)
│ │
│ ├─ 2. 多模态融合与推理(边界拓展)
│ │ ├─ 视频生成:Context Forcing(长时序一致性)
│ │ ├─ 推理评估:RISE-Video(隐含规则理解)
│ │ ├─ 视觉推理:Thinking in Frames(帧级推理范式)
│ │ └─ 自适应推理:SwimBird(多模式切换)
│ │
│ ├─ 3. 检索与深度推理(复杂任务赋能)
│ │ ├─ 专业检索:Semantic Search(数学定理)
│ │ ├─ 推理分离:DeR2(检索-推理损失 decoupling)
│ │ └─ 研究检索:SAGE(深度研究Agent优化)
│ │
│ ├─ 4. 优化算法与效率提升(底层赋能)
│ │ ├─ RL优化:LUSPO(长度无偏)、Dr.Kernel(内核生成)
│ │ ├─ 推理加速:DFlash(块扩散投机解码)
│ │ └─ 优化器加速:DASH(Shampoo改进)
│ │
│ └─ 5. 基准测试与评估体系(科学度量)
│ ├─ 领域基准:BABE(生物实验推理)
│ ├─ 社会智能:SocialVeil(沟通障碍场景)
│ └─ 数据蒸馏:InfoUtil(信息量-效用性平衡)
│
└─ 终极目标:构建可靠、高效、泛化的实用化LLM系统
更多内容关注公众号"快乐王子AI说"

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 31
31 0
0- 0



 已为社区贡献113条内容
已为社区贡献113条内容

所有评论(0)