大模型应用:因果推理赋能大模型:从关联分析到因果决策的升级路径.80
大模型与因果推理的融合应用 摘要:当前大模型虽能识别数据相关性,却难以理解因果性,导致决策支持能力受限。本文探讨了大模型与因果推理的结合路径:通过因果图、do-演算和结构因果模型等工具,实现从关联分析到干预预测再到反事实推理的三层能力跃迁。这种融合既能利用大模型处理非结构化数据的优势,又能借助因果推理消除虚假关联,提升决策的可解释性和泛化性。实证分析表明,该方法能有效区分气温与冰淇淋销量、溺水人数
一、引言
在大模型快速普及的当下,我们早已习惯用它完成文本生成、数据分析、趋势预测等工作,但其原生能力始终绕不开一个核心局限,只懂“相关性”,不懂“因果性”。它能精准发现“打广告后销量上涨”、“降价后购买率提升”的关联,却无法回答“广告真的是销量上涨的原因吗?”、“如果不降价,销量会如何变化?”这类决策级问题;它能基于海量数据生成看似合理的结论,却也会因虚假关联产生“冰淇淋销量越高,溺水人数越多”的荒谬推理,这也是大模型幻觉、偏见问题的核心根源之一。
而因果推理,作为探索事物间“因”与“果”本质联系的方法论,恰好能弥补这一短板。当大模型的海量知识建模、非结构化数据理解、自然语言交互能力,与因果推理的逻辑推演、混杂因素控制、干预与反事实分析能力相结合,大模型便实现了从“知其然”到“知其所以然”的关键跨越,从单纯的预测工具升级为能支撑决策、解释逻辑、泛化跨场景的智能工具。今天我们好好拆解一下从“找相关”到“找因果”的技术本质,对其中的原理一探究竟。

二、基础知识
1. 核心概念
- 相关性:两个变量一起变化,但无法确定谁导致谁,比如“冰淇淋销量上升”和“溺水人数增加”同时发生,正相关,但两者没有直接因果关系。
- 因果性:一个变量的变化直接导致另一个变量的变化。比如“气温升高”的因素可以导致“冰淇淋销量上升”的结果,“气温升高”的因素也可以导致“游泳人数增加→溺水人数增加”的结果。
- 大模型 + 因果推理:用大模型的语言理解、知识建模能力,解决传统因果推理“依赖专家知识、难处理非结构化数据”的问题;同时用因果推理弥补大模型“只看相关性、易产生幻觉或偏见”的缺陷,实现从“知其然”到“知其所以然”的升级。
2. 因果关系的三层阶梯
因果推理并非单一技能,而是一个由浅入深、逐级跃迁的能力体系。分为三个逐级递进的层级。每一层都对应一类更深层次的问题,也对模型的因果理解能力提出更高要求。
第一层:关联:“看到什么?”, 此层是所有推理的基础,但仅停留在描述世界。
- 核心问题:变量之间是否存在统计上的共现关系?
- 典型例子:数据中显示“打广告”和“销量上涨”经常同时出现。
- 大模型原生能力:非常强。大模型擅长从海量观测数据中捕捉模式,完成分类、预测、聚类等任务。
- 局限性:无法区分相关与因果。例如,销量上涨可能源于季节性需求,而非广告本身。
- 引入因果推理后的提升:能够识别混杂因素,判断哪些关联是真实的因果信号,哪些是虚假相关,如由共同原因导致的伪相关。
第二层:干预:“如果我主动做某事,会怎样?”,此层使模型从“被动观察者”转变为“主动决策支持者”。
- 核心问题:在人为施加某种行动(干预)后,结果会如何变化?
- 典型例子:如果我们今天决定投放广告(而非自然发生),销量会提升多少?
- 大模型原生能力:薄弱。大模型基于历史观测数据训练,无法自然模拟“do 操作”(即干预)的效果。
- 关键挑战:干预会打破原有数据分布,而模型未学习过这种“非自然状态”。
- 引入因果推理后的提升:借助因果图和 do-演算,可估计干预下的期望结果,支持策略评估、A/B测试模拟、个性化推荐等决策场景。
第三层:反事实:“如果当初做了不同的选择,结果会怎样?”,此层代表真正的“因果理解”,使模型具备反思与想象的能力。
- 核心问题:在已经发生某一事实的前提下,设想一个与之相反的假设情境,并推断其结果。
- 典型例子:昨天我们打了广告,销量是1000;但如果昨天没打广告,销量会是多少?
- 大模型原生能力:几乎为零。反事实需要对数据生成机制有结构性理解,而大模型缺乏显式的因果机制建模。
- 关键难点:反事实涉及对“未发生世界”的重构,必须依赖结构因果模型(SCM)等工具。
- 引入因果推理后的提升:通过 SCM 和噪声项回溯,可生成逻辑一致、符合因果律的反事实推断,用于归因分析、责任判定、经验复盘等高阶任务。
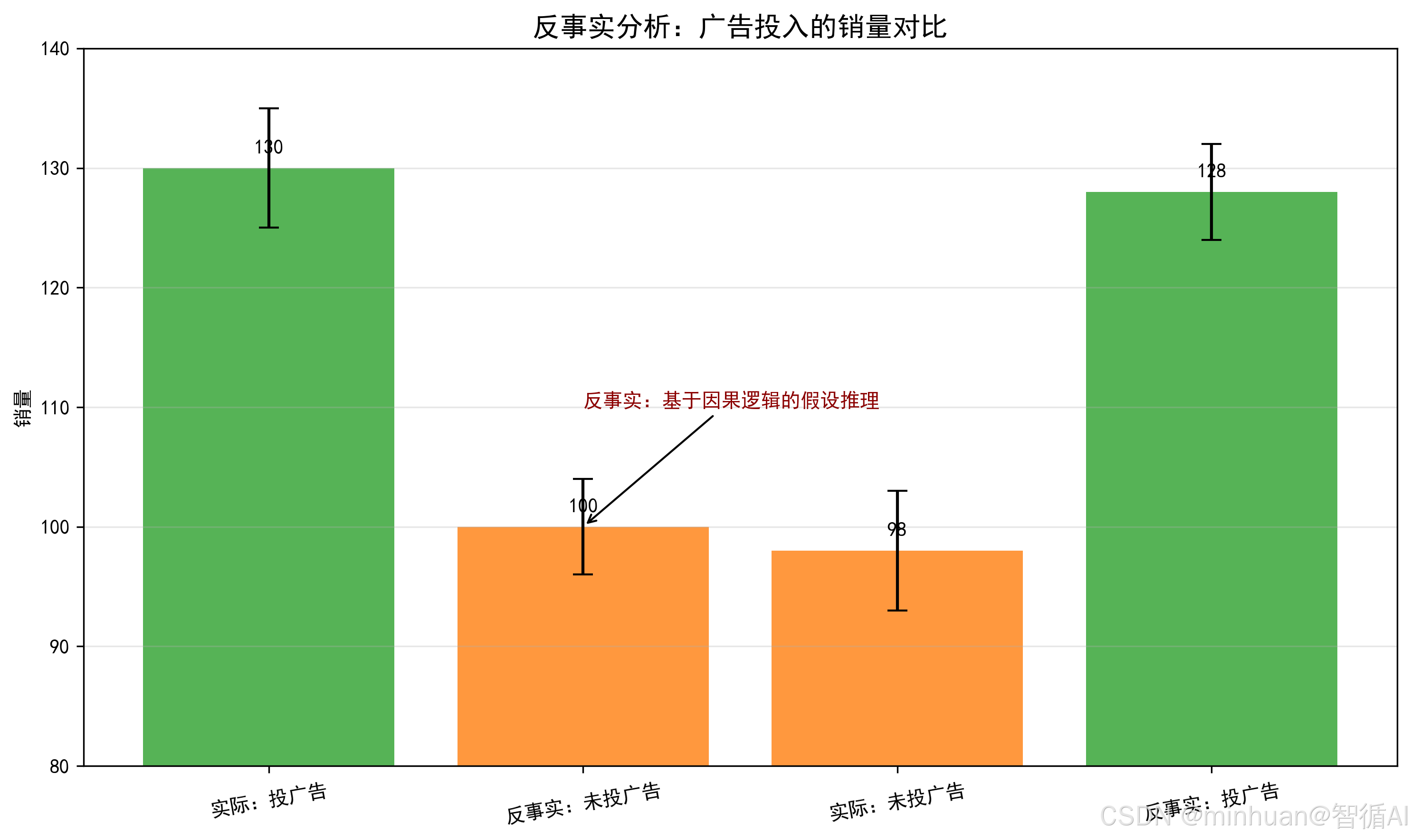
这条路径清晰地表明:仅有大数据和强大拟合能力,不足以实现真正的智能决策。只有将大模型与因果推理框架深度融合,才能让AI从“知道是什么”走向“理解为什么”和“设想如果……会怎样”。
3. 核心工具
- 1. 因果图(DAG,有向无环图):用“节点 = 变量、箭头 = 因果方向”画因果关系。比如:
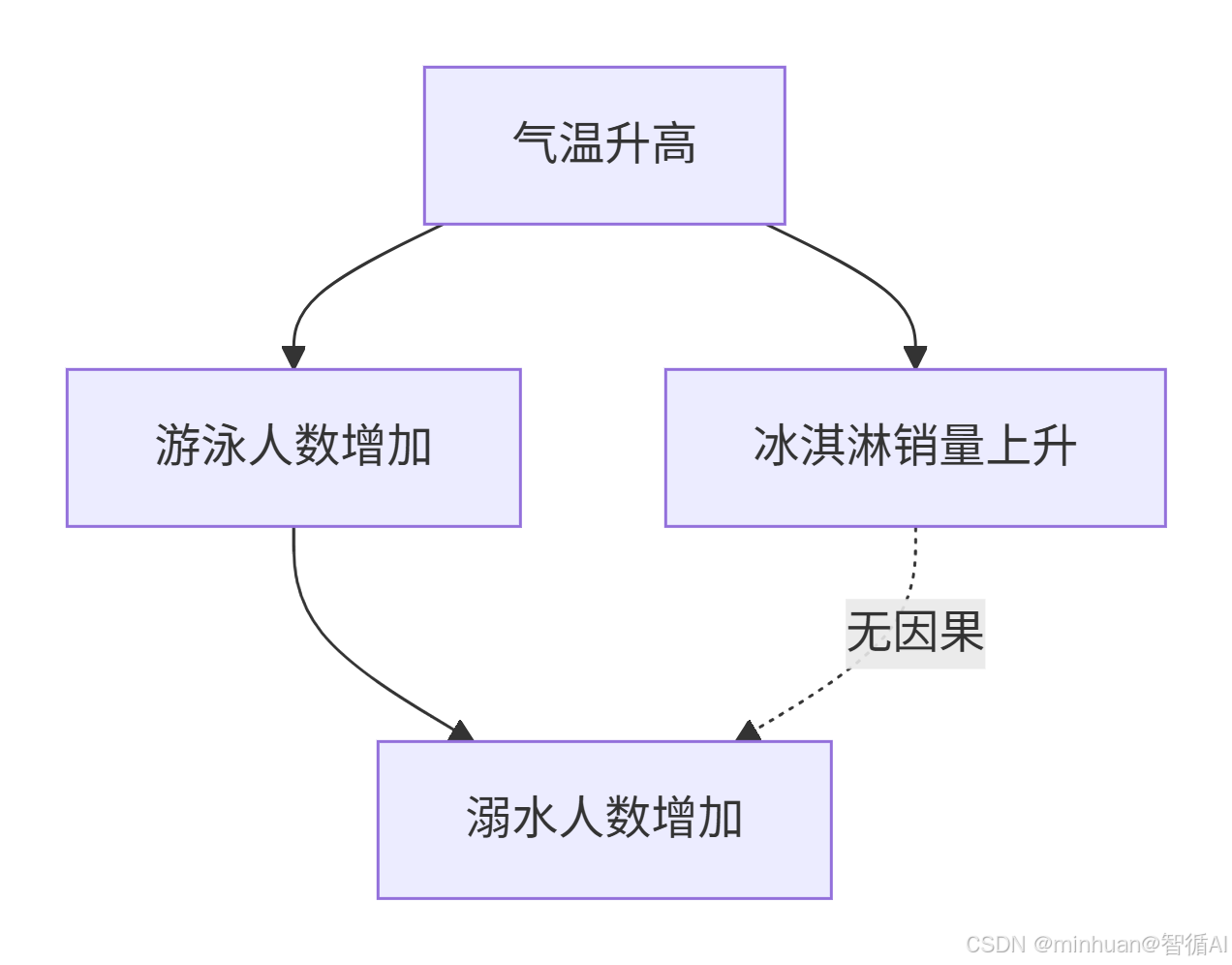
1.1 核心因果关系链:
- 气温升高 → 游泳人数增加(直接因果)
- 天气炎热促使更多人选择游泳降温
- 游泳人数增加 → 溺水人数增加(直接因果)
- 游泳人数增多导致溺水风险总体增加
- 气温升高 → 冰淇淋销量上升(直接因果)
- 天气炎热刺激冷饮消费需求
1.2 重要区分:
- 冰淇淋销量上升 ↔ 溺水人数增加(无直接因果关系)
- 两者都与气温升高有关,但彼此之间没有直接的因果联系
- 这是统计学上的"相关关系"而非"因果关系"
- 不能因为冰淇淋销量上升就推断溺水人数会增加
1.3 电商场景因果图(DAG):销量影响因素
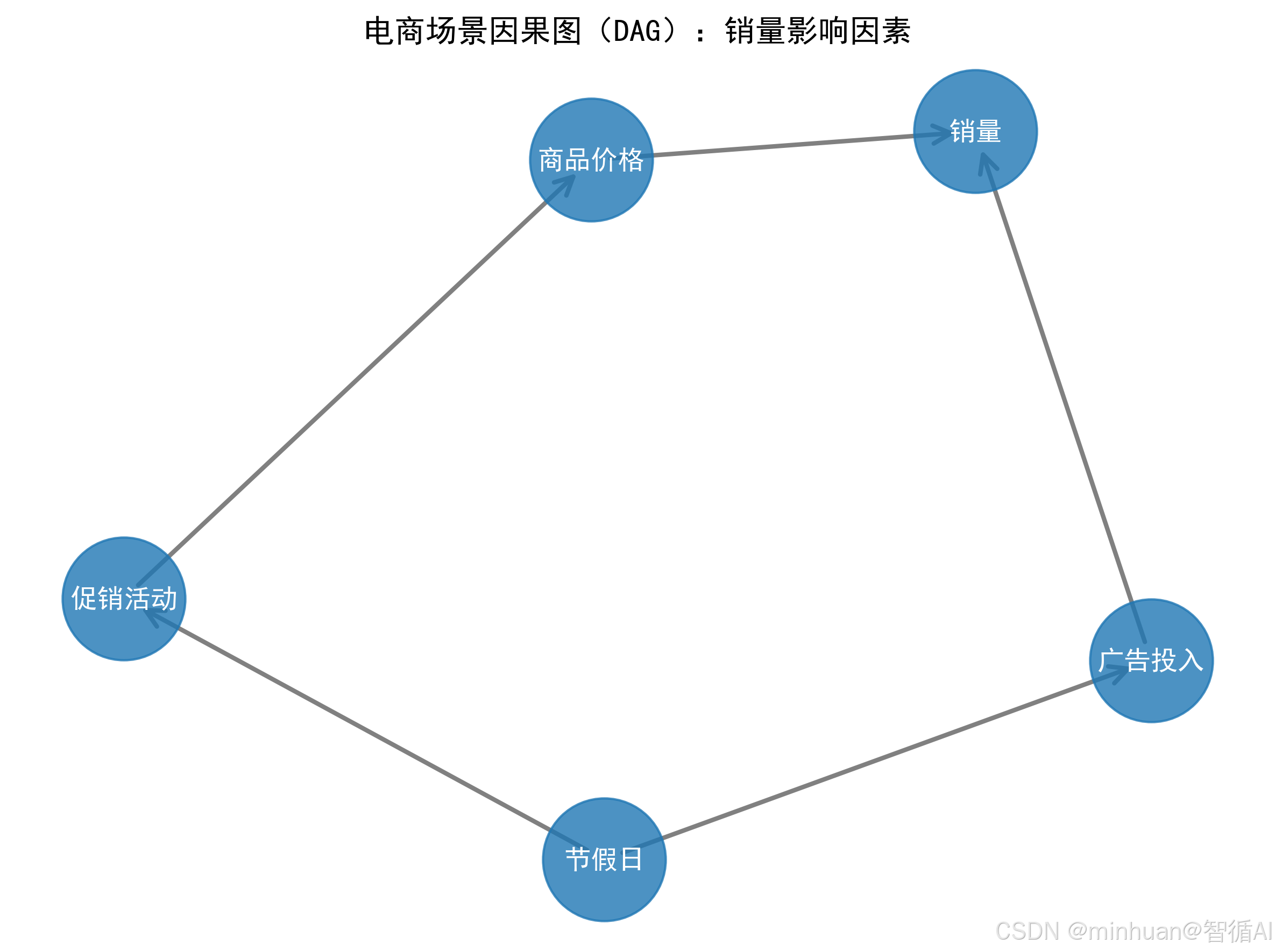
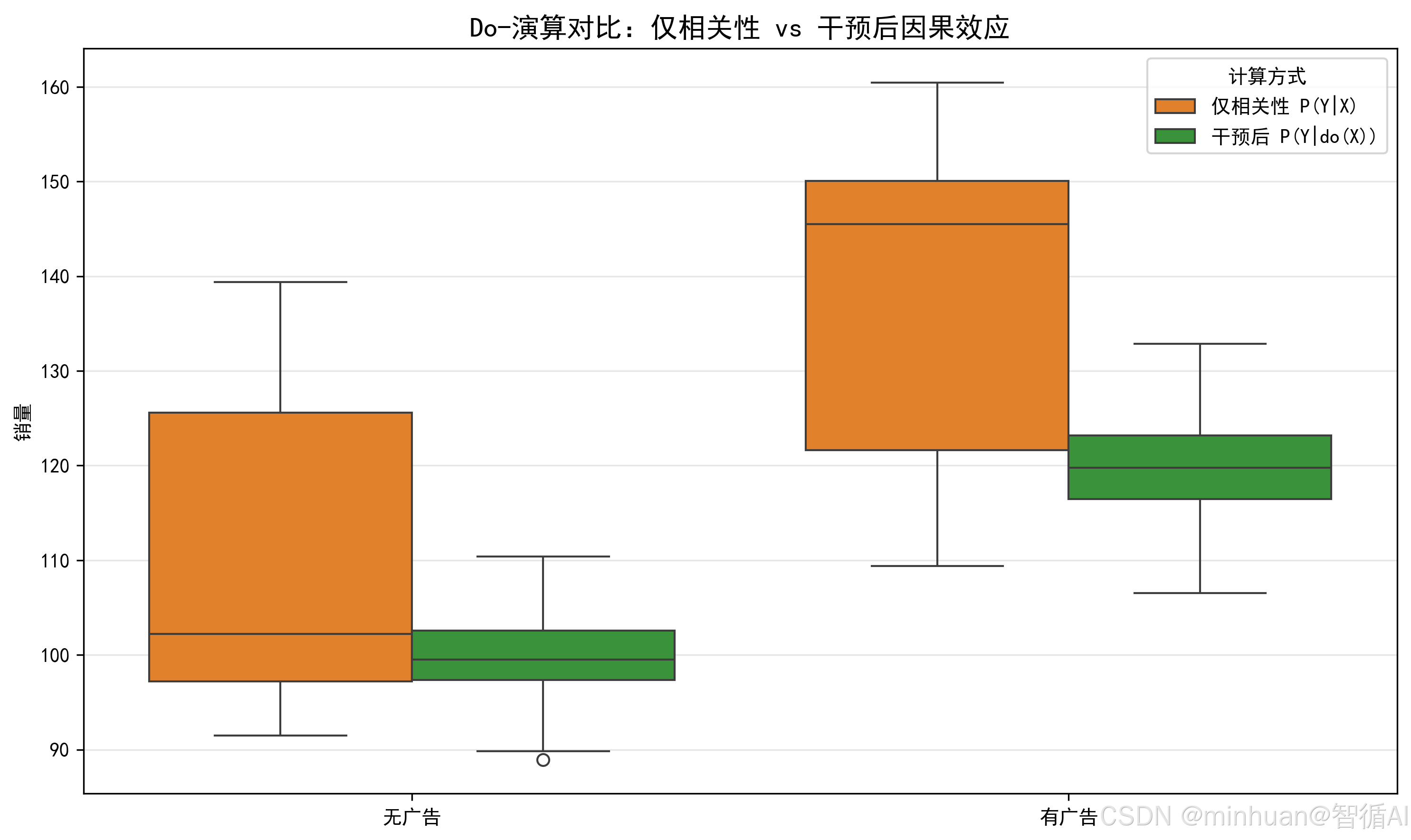
- 2. Do - 演算:区别于传统概率P(Y|X)(仅看 X 和 Y 的关联),Do - 演算计算P(Y|do(X))(主动干预 X 后 Y 的结果),是因果推理的核心算法。
- 3. 结构因果模型(SCM):用方程量化因果关系,比如销量 = α×广告投入 + β×促销活动 + U,U是未观测的混杂因素,如“节假日”。
三、基础原理
1. 传统因果推理的痛点
- 依赖专家手动构建因果图,成本高;
- 无法处理文本、语音等非结构化数据;
- 对隐藏的混杂因素敏感,易误把相关当因果。
2. 大模型赋能因果推理的原理
- 语义提取:从论文、用户评论、报告中自动提取因果关系,比如从“用户反馈‘降价后才买’”中提取“降价→购买”;
- 混杂因素识别:从非结构化文本中发现隐藏的混杂变量,比如从“618 期间广告 + 促销同时进行”中识别“促销”是广告和销量的混杂因素;
- 反事实生成:生成符合逻辑的反事实场景,比如“如果 618 没做促销,广告带来的销量增长是多少”。
3. 因果推理赋能大模型的原理
- 减少幻觉:基于因果逻辑生成内容,而非仅统计关联;
- 提升可解释性:回答 “为什么得出这个结论”,比如“推荐A商品是因为买过B,且B和A有因果关系”;
- 增强泛化能力:因果关系跨场景更稳定,比如A城市的“降价→销量涨”可迁移到B城市。
四、执行流程
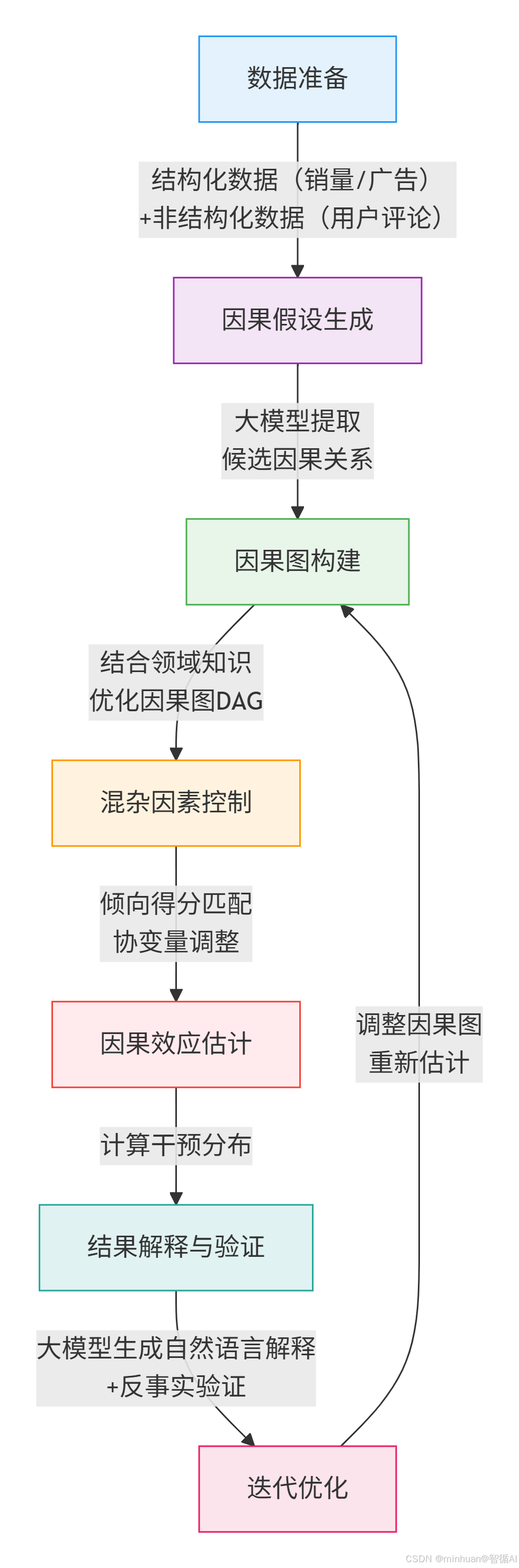
流程说明:
- 1. 数据准备:收集结构化的销量、广告投入以及非结构化的用户评论、行业报告;
- 2. 因果假设生成:用大模型从文本中提取“广告→销量”、“促销→销量”等候选因果关系;
- 3. 因果图构建:结合大模型输出和行业知识,画出最终因果图;
- 4. 混杂因素控制:排除“节假日”、“竞品价格”等干扰因素;
- 5. 因果效应估计:计算“主动增加1000元广告投入后,销量能涨多少”;
- 6. 结果解释:大模型生成“销量增长 80% 来自广告,20% 来自促销”的自然语言解释;
- 7. 迭代优化:验证反事实场景,如果没投广告,销量会降多少,调整因果图。
五、示例分析
1. 对比因果分析
示例代码通过“冰淇淋销量与溺水人数”模拟案例,展示了相关性不等于因果性(Correlation ≠ Causation)这一因果推理中的核心误区,主要说明了即使两个变量高度相关,也不代表一个导致另一个。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 1. 生成模拟数据(气温、冰淇淋销量、溺水人数)
np.random.seed(42)
n = 100
temperature = np.random.uniform(20, 40, n) # 气温20-40℃
ice_cream = 0.8 * temperature + np.random.normal(0, 2, n) # 气温→冰淇淋销量
drowning = 0.7 * temperature + np.random.normal(0, 2, n) # 气温→溺水人数
# 2. 计算相关性
df = pd.DataFrame({
'temperature': temperature,
'ice_cream': ice_cream,
'drowning': drowning
})
# 相关性矩阵
corr_matrix = df.corr()
print("相关性矩阵:")
print(corr_matrix)
# 3. 可视化(相关性陷阱)
plt.figure(figsize=(12, 4))
# 子图1:气温vs冰淇淋销量
plt.subplot(1, 3, 1)
plt.scatter(df['temperature'], df['ice_cream'])
plt.xlabel('气温')
plt.ylabel('冰淇淋销量')
plt.title('气温→冰淇淋销量(因果)')
# 子图2:气温vs溺水人数
plt.subplot(1, 3, 2)
plt.scatter(df['temperature'], df['drowning'])
plt.xlabel('气温')
plt.ylabel('溺水人数')
plt.title('气温→溺水人数(因果)')
# 子图3:冰淇淋销量vs溺水人数
plt.subplot(1, 3, 3)
plt.scatter(df['ice_cream'], df['drowning'])
plt.xlabel('冰淇淋销量')
plt.ylabel('溺水人数')
plt.title('冰淇淋vs溺水(仅相关)')
plt.tight_layout()
plt.savefig('correlation_vs_causality.png')
plt.show()输出结果:
相关性矩阵:
temperature ice_cream drowning
temperature 1.000000 0.927709 0.884954
ice_cream 0.927709 1.000000 0.817093
drowning 0.884954 0.817093 1.000000
结果图示:
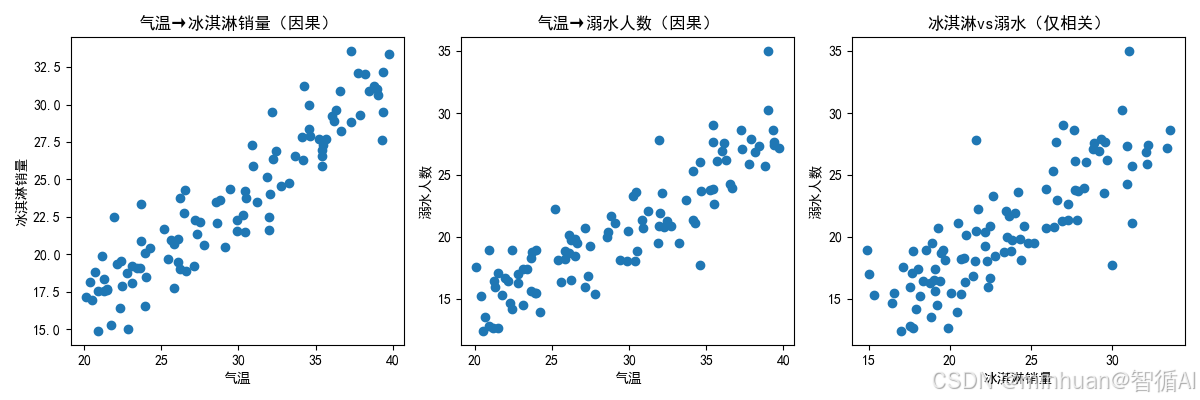
输出结果说明:
- 冰淇淋销量和溺水人数的相关系数≈0.8,高度相关,但无直接因果,核心原因是气温
2. 大模型辅助生成因果假设
代码示例说明了如何利用本地部署的大模型从非结构化用户评论中自动提取因果关系,体现将本地大模型能力与因果推理初步结合,实现了利用大模型强大的语言理解能力,从非结构化文本中初步识别潜在因果线索;
from transformers import AutoTokenizer, AutoModelForCausalLM
from modelscope import snapshot_download
import torch
# 下载模型到本地缓存
model_name = "qwen/Qwen1.5-1.8B-Chat"
cache_dir = "D:\\modelscope\\hub"
print("正在下载/校验模型缓存...")
local_model_path = snapshot_download(model_name, cache_dir=cache_dir)
print(f"模型本地路径:{local_model_path}")
# 设置设备
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"使用设备:{device}")
# 加载分词器和模型
tokenizer = AutoTokenizer.from_pretrained(local_model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
local_model_path,
trust_remote_code=True,
torch_dtype=torch.float16 if device == "cuda" else torch.float32,
device_map="auto"
).eval()
# 2. 准备非结构化文本(用户评论示例)
user_reviews = """
用户1:"618期间这款商品降价了,我才买的,之前价格太高一直没下手。"
用户2:"看到了广告才知道这款商品,加上有促销,直接下单了。"
用户3:"不管有没有广告,这款商品本身质量好,我都会买。"
用户4:"节假日期间商品销量明显涨,广告反而没什么用。"
"""
# 3. 调用本地大模型提取因果关系
def extract_causal_relations(text):
prompt = f"""
请从以下用户评论中提取所有因果关系,格式为"因→果":
{text}
要求:
1. 只提取直接因果关系;
2. 排除仅相关的关系;
3. 列出所有候选因果关系。
"""
# 构造消息格式(Chat格式)
messages = [
{"role": "user", "content": prompt}
]
# 使用Chat模板
text_input = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
# 分词并移至设备
model_inputs = tokenizer([text_input], return_tensors="pt").to(device)
# 生成回答
with torch.no_grad():
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512,
temperature=0.1,
do_sample=False,
pad_token_id=tokenizer.eos_token_id
)
# 解码输出
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
return response
# 4. 执行并输出结果
causal_relations = extract_causal_relations(user_reviews)
print("\n大模型提取的因果关系:")
print(causal_relations)输出结果:
正在下载/校验模型缓存...
模型本地路径:D:\modelscope\hub\qwen\Qwen1___5-1___8B-Chat
使用设备:cpu
大模型提取的因果关系:
1. "618期间这款商品降价了,我才买的,之前价格太高一直没下手。"- 因果关系:因为商品在618期间降价,导致用户才买了该商品,因此是由于价格因素引起的购买行为。
2. "看到了广告才知道这款商品,加上有促销,直接下单了。"
- 因果关系:看到广告和促销信息促使用户下单购买,因此是由于广告或促销信息引起的购买行为。
3. "不管有没有广告,这款商品本身质量好,我都会买。"
- 因果关系:用户认为商品本身质量好是其决定是否购买的主要原因,因此是由于产品质量因素引起的购买行为。
4. "节假日期间商品销量明显涨,广告反而没什么用。"
- 因果关系:节假日期间商品销量的上涨与广告没有直接关联,但可能是因为消费者对节日促销活动的关注度提高,从而推动了销量的增长,而广告的作用可能是通过吸引消费者的注意力来促进销售,因此是由于促销活动和消费者关注度之间的间接因果关系。
3. 简单因果效应估计
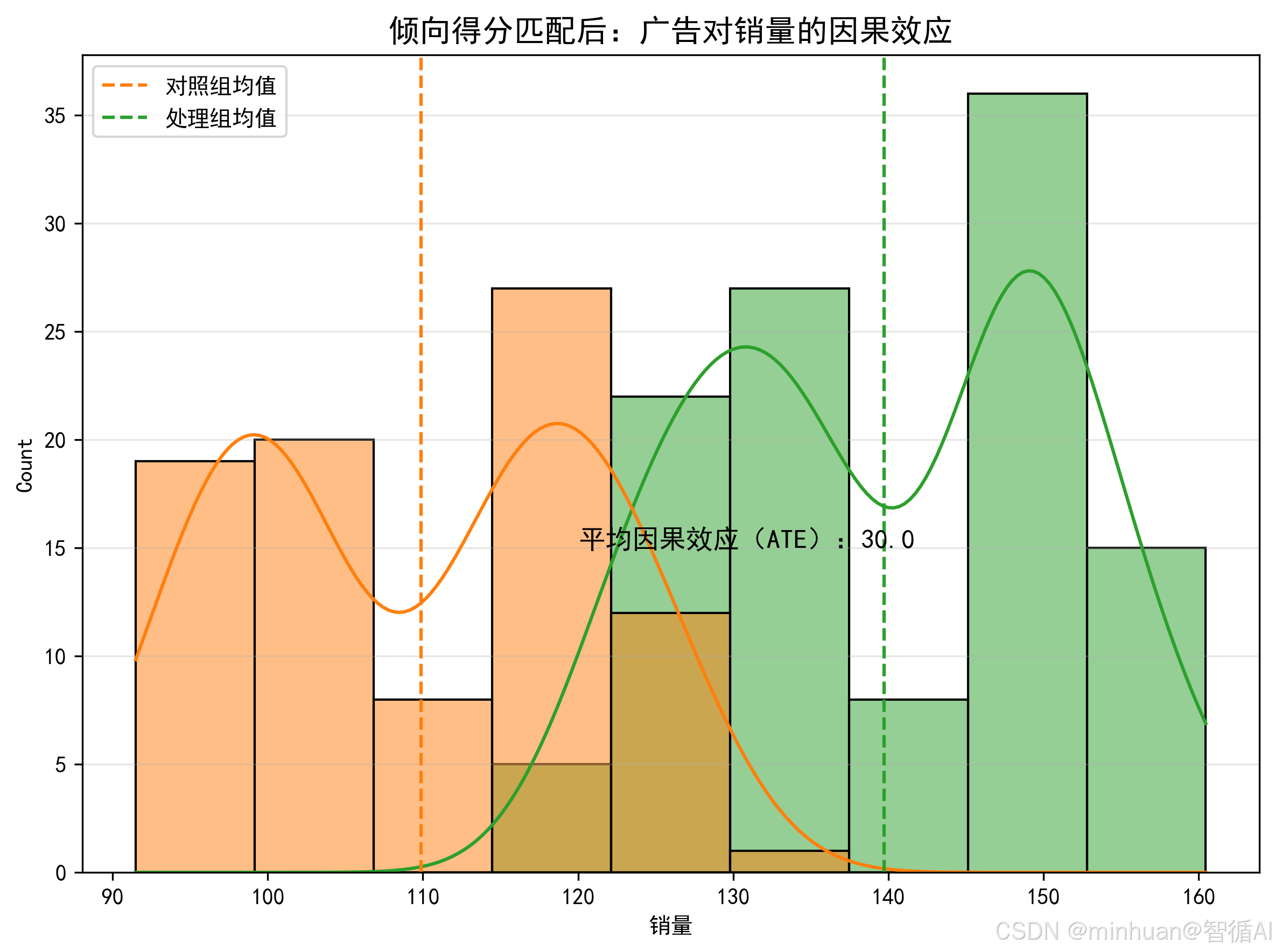
通过倾向得分匹配(PSM)方法,从观测数据中估计广告投入对销量的因果效应,同时控制混杂因素(促销活动)的影响。这是示例,用于在无法进行随机对照试验(RCT)时,尽可能逼近真实的因果关系。
from causalinference import CausalModel
import pandas as pd
import numpy as np
# 1. 生成模拟数据(广告投入=干预变量,销量=结果变量,促销=混杂因素)
np.random.seed(42)
n = 200
# 混杂因素:促销活动(0=无,1=有)
promotion = np.random.binomial(1, 0.5, n)
# 干预变量:广告投入(0=无广告,1=有广告)
ad = np.random.binomial(1, 0.6, n)
# 结果变量:销量(受广告、促销影响)
sales = 100 + 30*ad + 20*promotion + np.random.normal(0, 5, n)
# 2. 构建因果模型
cm = CausalModel(
Y=sales, # 结果变量
D=ad, # 干预变量(0/1)
X=promotion # 混杂因素
)
# 3. 倾向得分匹配
cm.est_propensity_s() # 估计倾向得分
cm.est_via_matching(matches=1) # 1:1匹配
# 4. 输出因果效应
print("\n因果效应估计结果:")
print(f"平均处理效应(ATE):{cm.estimates['matching']['ate']:.2f}")
print(f"处理组平均效应(ATT):{cm.estimates['matching']['att']:.2f}")输出结果:
因果效应估计结果:
平均处理效应(ATE):30.00
处理组平均效应(ATT):30.00
结果说明:
- ATE(平均处理效应):投广告相比不投广告,销量平均增长≈30,和我们设定的30一致
- 这说明我们成功控制了促销的混杂因素,得到了真实的因果效应
六、大模型 + 因果推理的意义
- 能力升级:大模型从预测工具升级为决策工具,不仅能预测“销量会涨”,还能回答“怎么让销量涨”;
- 减少缺陷:解决大模型的幻觉、偏见问题,比如不再推荐“买冰淇淋防溺水”这种错误关联;
- 提升可解释性:让大模型从黑箱变白箱,比如AI推荐商品时能解释推荐原因是什么;
- 增强泛化性:因果关系跨场景更稳定,大模型在新行业或新场景的表现更好。
七、总结
通过对大模型与因果推理融合应用的进一步了解,我们对大模型的能力边界和升级逻辑有了更清晰的认知。此前总觉得大模型的数据分析能力足够强大,能找关联、做预测就够用,却忽略了相关非因果的核心问题,这也是模型会出幻觉、给不出靠谱决策建议的关键。接触后才发现,因果推理不是简单的补充,而是让大模型从凭数据统计说话到靠逻辑因果判断的核心支撑。大模型和因果推理的双向赋能也很有启发,前者解决了传统因果推理处理非结构化数据、构建假设难的问题,后者则补上了大模型可解释性、泛化性的短板,二者结合才是更贴合实际应用的智能。
因果分析不是空中楼阁,从识别混杂因素到用倾向得分匹配计算因果效应,每一步都能落地。其实我们学大模型技术不能只停留在用模型,更要理解背后的逻辑,只有抓准事物的因果本质,才能让模型的输出真正服务于实际决策。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献54条内容
已为社区贡献54条内容

所有评论(0)