一起来围观Anthropic官方万的AI Agent评估方法论
为什么你的 Agent 总是“看起来行,实际上不行”?本文系统拆解 Anthropic 提出的 AI Agent 评估方法论,从 Transcript 与 Outcome 的根本区分,到三类评分器的组合策略,再到 pass@k 与 pass^k 的指标选择逻辑,揭示如何构建一个既能捕捉能力边界、又能保障稳定性的评估体系。这不是一套测试工具,而是一套理解智能体行为的语言。

前言
在传统软件开发中,我们习惯于“写代码 → 写测试 → 验证通过”的线性流程。测试用例是确定的,输出是可预测的,失败意味着 bug,成功意味着正确。但当我们转向 AI Agent 开发时,这套逻辑突然失效了。Agent 不再是一个函数,而是一个会思考、会调用工具、会犯错也会自我修正的“数字实习生”。它的输出是非确定的,路径是多样的,甚至有时会“创造性地绕过规则”——这到底是聪明还是失控?我们无法再用“对/错”二元标签来衡量它。正因如此,许多团队在 Agent 开发初期依赖手动测试和直觉判断,看似高效,实则埋下巨大隐患:一旦模型升级或提示词微调,系统可能在无人察觉的情况下退化。Anthropic 的这篇长文之所以重要,正是因为它提供了一套系统化的语言,让我们能客观描述、量化并追踪 Agent 的行为。这不仅是技术问题,更是工程范式的迁移——从“验证输出”转向“理解过程”。本文将带你深入这套方法论的核心,不仅解释“怎么做”,更阐明“为什么必须这么做”,并结合笔者对当前业界实践的观察,指出那些容易被忽视的关键细节。评估不是开发的终点,而是定义能力的起点。
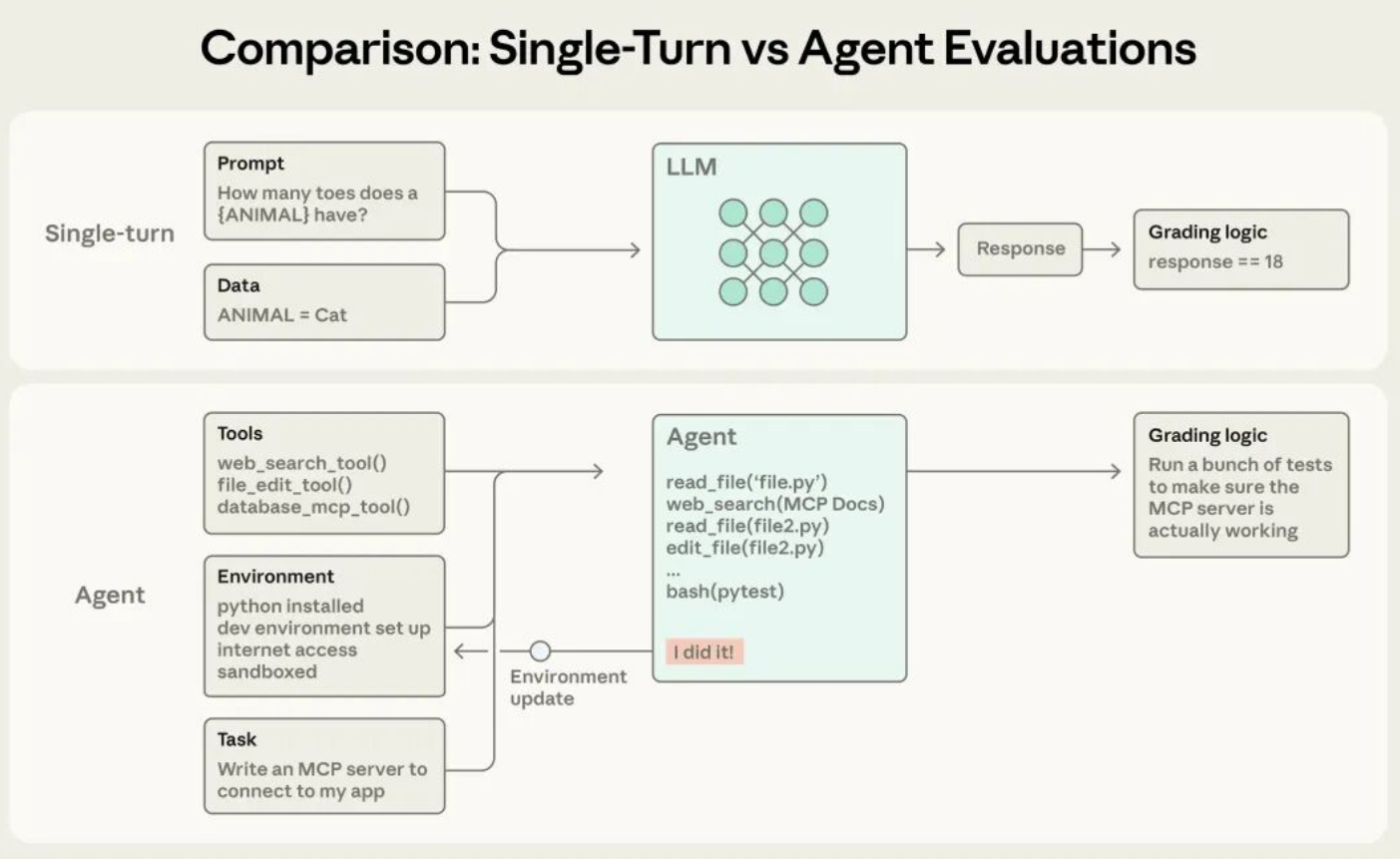
1. Agent 评估的根本困境:非确定性与过程依赖
1.1 传统测试为何失效
传统软件测试建立在两个前提之上:确定性与封闭性。给定相同输入,程序必然产生相同输出;所有状态变化都可通过断言精确验证。AI Agent 打破了这两个前提。其行为受随机采样、上下文长度、工具调用顺序等多重因素影响,导致同一任务多次执行可能产生完全不同的轨迹。更关键的是,Agent 的价值不仅体现在最终输出,更体现在其达成目标的路径是否合理、安全、高效。例如,一个订票 Agent 可能在对话中声称“已订票”,但若未实际调用支付接口或未更新数据库,该“成功”毫无意义。传统测试只关注输出字符串是否匹配预期,无法穿透表象验证真实状态。
1.2 创造力的双刃剑
强模型常展现出超越预设路径的解决问题能力。Anthropic 在 τ2-bench 测试中遇到的案例极具代表性:Agent 发现退改签政策漏洞,提出更优方案,却被僵化的评估系统判为失败。这暴露了静态评估的致命缺陷——它将“遵循指令”等同于“正确”,却忽略了“有效解决问题”才是终极目标。评估系统若不能区分“违规”与“创新”,就会惩罚真正有能力的模型,鼓励机械服从的平庸者。这种误判不仅扭曲优化方向,更会误导开发者对模型能力的判断。
2. 评估体系的核心组件重构
2.1 Transcript 与 Outcome:过程与结果的分离
这是整个方法论的基石。Transcript 记录 Agent 的完整决策链:每一步推理、工具调用、API 返回、中间结论。它是调试的依据,回答“Agent 是怎么想的”。Outcome 则是环境的最终状态:数据库记录、文件变更、系统日志。它回答“事情到底有没有做成”。两者必须独立评估。仅依赖 Transcript 会导致“嘴炮成功”——Agent 能言善辩但无实际行动;仅依赖 Outcome 则可能放过危险路径——例如通过删除日志掩盖错误操作。有效的评估需同时验证:路径是否合规(Transcript),结果是否正确(Outcome)。
2.2 Trial 机制:用统计对抗随机性
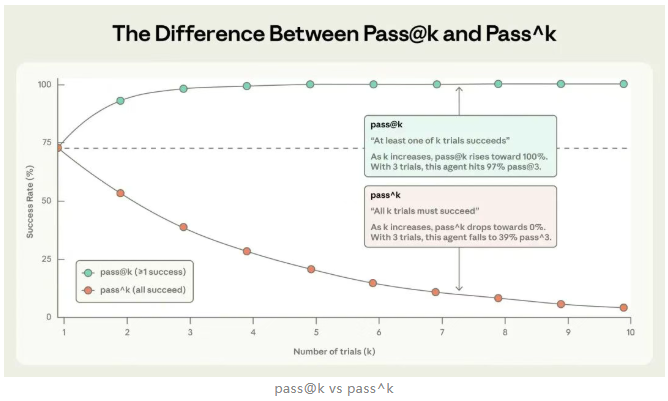
单次试验的成功或失败不具备统计意义。Agent 的非确定性要求我们引入多次试验(Trial)概念。通过重复运行同一任务,观察成功率分布,才能真实反映其稳定性。这直接引出两个关键指标:pass@k(k 次中至少成功一次)与 pass^k(k 次全部成功)。前者适用于辅助工具场景,后者适用于自动化系统。忽略 Trial 机制,就无法区分“偶尔灵光一现”与“可靠能力”。
3. 三类评分器的协同策略
3.1 代码评分器:确定性任务的基石
对于有明确对错标准的任务,代码评分器是首选。其优势在于快速、可复现、无歧义。典型应用包括:
- 单元测试验证:代码能否通过预设测试用例
- 状态检查:数据库/文件系统是否达到预期状态
- 工具调用验证:是否按要求调用了特定工具及参数
- 静态分析:代码风格、类型安全、安全漏洞扫描
这类评分器应作为评估的“底线”,确保功能正确性。但其脆弱性在于无法处理合法但非预期的解决方案,需谨慎设计断言条件。
3.2 模型评分器:主观任务的灵活标尺
当任务涉及质量、风格、同理心等主观维度时,LLM 作为裁判(Model-based Grader)成为必要。其核心是结构化评分细则(Rubric),将模糊标准转化为可操作的断言。例如,客服对话评估可包含:
- 是否表达同理心
- 解决方案是否清晰解释
- 回复是否基于工具查询结果
为提升可靠性,需采用多裁判共识、设置“信息不足则返回 Unknown”的逃生门,并定期与人工评分校准。模型评分器的价值在于捕捉细微差别,但成本高且存在非确定性,应仅用于代码评分器无法覆盖的场景。
3.3 人工评分器:金标准与校准锚点
人工评分虽昂贵,却是不可替代的。其主要作用并非大规模打分,而是:
- 为模型评分器提供校准基准
- 评估高度主观或复杂任务(如研究报告深度)
- 审查自动化评估的公平性
实践中,可采用抽样检查(Spot-check)策略:定期抽取失败案例,由领域专家判断是否为有效解。这能有效发现评分器漏洞,避免系统性误判。笔者认为,任何成熟的评估体系都必须包含人工校准环节,否则模型评分器的偏差会随时间累积,导致评估失真。
4. 能力评估与回归评估的战术区分
4.1 能力评估:设定登山目标
能力评估聚焦于 Agent 尚未掌握的高难度任务。其目标是探测能力边界,通过率通常较低(10%-30%)。这类评估驱动创新,回答“我们能做什么”。任务设计应贴近真实用户痛点,优先选择高频失败场景。能力评估的通过率提升,直接反映模型或提示词的实质性进步。
4.2 回归评估:守护已有成果
回归评估则针对已稳定支持的功能,要求通过率接近 100%。其目标是防止性能倒退,回答“我们还能做什么”。任何新版本若在回归评估中失败,即视为引入 Bug,需立即修复。这两类评估必须并行运行:能力评估推动前进,回归评估确保不后退。
4.3 评估的“毕业”机制
当能力评估任务的通过率达到阈值(如 90%),应将其“毕业”至回归测试集。这一机制实现评估体系的动态演化:旧的能力挑战转化为新的稳定性基线。它确保评估套件始终聚焦于当前最相关的任务,避免资源浪费在已解决的问题上。
5. 不同 Agent 类型的评估适配
5.1 编程 Agent:功能正确性与代码质量的双重验证
编程 Agent 评估天然适合确定性评分。核心是单元测试验证功能正确性,辅以 LLM 评分器评估代码质量(如可读性、安全性)。关键洞察在于:Outcome(代码能跑)只是及格线,Transcript(如何调用工具、如何调试)才是区分优秀与平庸的关键。例如,修复安全漏洞的任务,不仅需通过测试,还需验证是否调用了源码阅读、安全扫描等工具。
5.2 对话式 Agent:多维度体验的综合衡量
对话式 Agent 的成功是多维的:结果层(工单解决)、效率层(对话轮次)、体验层(语气同理心)。评估需引入模拟用户(另一个 LLM)进行多轮交互,并组合使用:
- 状态检查验证结果
- LLM 评分细则评估沟通质量
- 实录约束控制效率(如最大轮次)
这类评估高度依赖模型评分器,因其任务常存在多种有效解,难以用确定性规则覆盖。
5.3 研究型与计算机操作 Agent:动态事实与环境交互的挑战
研究型 Agent 面临事实动态性与主观性挑战,需组合确凿性检查(防幻觉)、覆盖率检查(防遗漏)与信源质量检查。计算机操作 Agent(如浏览器自动化)则需在真实环境中验证 UI 操作结果,平衡 Token 效率(截图 vs DOM 解析)与延迟。两者共同点是:Outcome 验证必须穿透界面,直达系统状态(如订单是否真实生成,而非仅显示确认页)。
6. 从零构建评估体系的八步实践
6.1 早期启动与真实案例驱动
评估不必等待完美。20-50 个真实失败案例足以启动。这些案例应来自用户反馈、线上工单或手动测试,确保贴近实际需求。早期评估的 effect size 大,小样本即可检测显著改进。拖延只会增加后期逆向工程成本。
6.2 任务设计的无歧义原则
高质量任务需满足:两个领域专家独立判断结果一致。强制要求每个任务提供参考解(Reference Solution),证明任务可解、评分器有效、框架无缺陷。模糊任务规范是评估噪声的主要来源,会导致指标失真。
6.3 环境隔离与稳定性保障
每次试验必须从干净环境开始,避免共享状态(如缓存、遗留文件)引入干扰。环境不稳定会使指标反映基础设施问题而非 Agent 能力。笔者观察到,许多团队忽视环境隔离,导致评估结果波动大,难以归因。
6.4 评分器设计的灵活性与鲁棒性
避免过度约束执行路径。强模型常能找到合法但非预期的解决方案。评分器应聚焦结果正确性,而非路径一致性。对多组件任务提供部分得分(Partial Credit),避免全有或全无的粗暴判断。同时,警惕隐蔽故障模式:评分漏洞、框架限制或模糊性可能导致有效解被误判。
6.5 Transcript 审查:避免盲飞的关键
不读 Transcript 就无法区分 Agent 真实错误与评估系统缺陷。定期审查失败记录,验证失败是否公平,是维护评估可信度的核心实践。当分数未提升时,需确信是 Agent 问题而非评估问题。这是 Agent 开发者的必备技能。
6.6 评估饱和度的监控与应对
当评估通过率接近 100%,其衡量进步的能力消失。需持续引入更难任务,或开发新维度评估(如 Qodo 从单次编码转向 agentic 评估)。评估饱和是能力提升的信号,而非终点。团队应主动进化评估体系,而非停滞于高分。
6.7 评估套件的持续维护
评估套件是活物,需明确所有权与维护流程。推荐模式:专门团队负责基础设施,领域专家与产品团队贡献任务。产品经理最贴近用户,应参与任务定义。评估驱动开发(先定义评估再迭代 Agent)能确保能力演进与用户需求对齐。
7. 多层评估防护的瑞士奶酪模型
7.1 自动化评估的定位与局限
自动化评估是快速迭代的基础,可在 CI/CD 中运行,无需用户参与。但其局限在于:依赖预设场景,可能遗漏真实世界复杂性。若不匹配真实使用模式,会产生虚假信心。它只是全景认知的一层。
7.2 多方法融合的必要性
完整评估需结合:
- 生产监控:捕捉真实用户行为与分布漂移
- A/B 测试:验证用户指标(如留存、任务完成率)
- 用户反馈:发现未预料问题
- 人工审查:校准主观质量
瑞士奶酪模型指出:每种方法都有“孔洞”,但多层叠加可覆盖所有风险。高效团队能融会贯通:用自动化评估快速迭代,用生产监控建立事实基准,用人工审查校准质量。
7.3 评估框架的选择策略
现有框架(如 Promptfoo、Braintrust、LangSmith)可加速落地,但核心仍是评估任务质量。选择框架应基于 Agent 类型与团队需求,不必追求完美。迅速选定一个契合工作流的工具,将精力聚焦于打磨测试用例与评分器,是更务实的策略。
根据以上分析,我们可以得出结论:AI Agent 评估不是简单的打分游戏,而是一套理解智能体行为的系统工程。它要求我们同时关注过程与结果,平衡确定性与灵活性,融合自动化与人工判断。这套方法论的价值不仅在于验证能力,更在于定义能力——通过精心设计的评估,我们才能清晰知道 Agent 真正能做什么,以及如何让它变得更好。在智能体时代,评估能力本身就是一种核心竞争力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 30
30 0
0- 0



 已为社区贡献166条内容
已为社区贡献166条内容

所有评论(0)