五、服务端性能监控
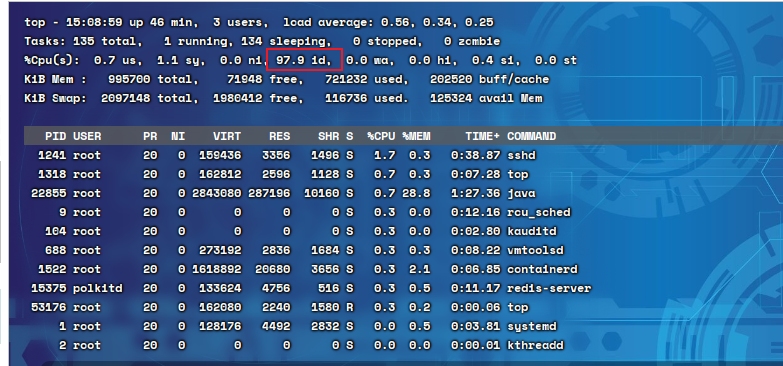
Top命令是Linux下一个实时的、交互式的,对操作系统整体监控的命令,可以对CPU、内存、进程监 控。:wait,在过去一段时间内,CPU等待磁盘的时间的占比,wa比较高的话,代表磁盘比较慢,CPU需要长时间等待磁盘。注意:top命令统计的id%和进程列表中每个进程占用的CPU使用率代表的含义不一样。监控磁盘的性能指标时,更关注util%,它代表了磁盘的繁忙度,上限是100%在top命令中,输入
前言:操作系统级别监控
- CPU使用率:反映系统的cpu繁忙程度
- 内存使用率:反映系统内存的使用空间
- 网络IO:反映系统网络流量
- 磁盘IO:反映系统磁盘的读写状态
一、CPU监控:top命令
释义:Top命令是Linux下一个实时的、交互式的,对操作系统整体监控的命令,可以对CPU、内存、进程监 控。是Linux下最常用的监控命令。
-
id%:CPU的空闲率,用100减去id%就是CPU的使用率
-
us%:user用户进程占用的CPU使用率
-
sy%:system系统进程占用的CPU使用率
-
wa%:wait,在过去一段时间内,CPU等待磁盘的时间的占比,wa比较高的话,代表磁盘比较慢,CPU需要长时间等待磁盘
CPU使用率=100-id%
在top命令中,输入数字1,则展示每个核的CPU使用情况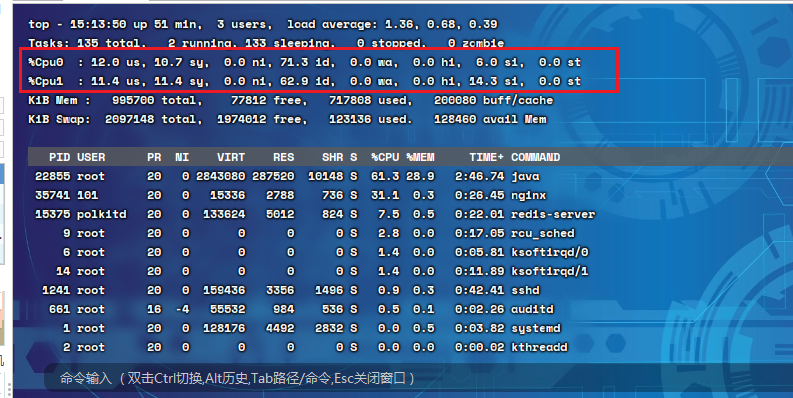
注意:top命令统计的id%和进程列表中每个进程占用的CPU使用率代表的含义不一样
区别:
1、100-id%: 代表CPU所有核心使用率的平均值
2、%CPU: 代表某个进程占用CPU所有核心的使用率之和
二、内存监控:free命令
释义:free命令可以查看当前系统内存的使用情况

free -m 以MB为单位显示系统内存的使用情况,同理,也可以使用-k、-g等其他的单位显示
- available: 代表当前操作系统可用的内存值
- buffer和cache:两者都是Linux下的缓存机制,其中buffer为写操作的缓存,cache为读操作的缓存
- swap:交换空间,磁盘上的一块空间,当系统内存不足时,会使用交换空间

三、磁盘监控:iostat 和 df
3.1磁盘IO监控:iostat命令
释义:iostat命令可以查看当前机器磁盘io的数据
如果没安装,需要先执行 yum install -y sysstat
命令:
iostat -x -k 1
释义:
-x:展示磁盘的扩展信息
-k:以k为单位展示磁盘数据
1:每1秒刷新一次
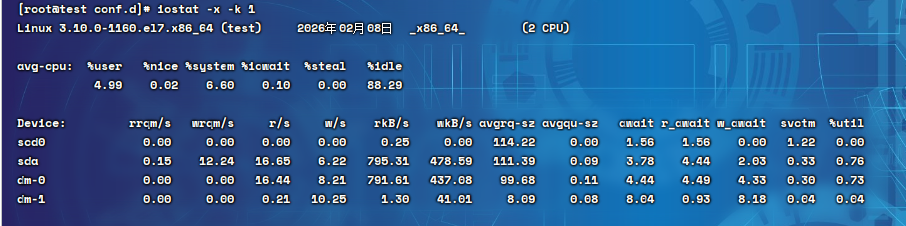
结果释义:
- util:磁盘IO使用率,单位%,反映磁盘的繁忙程度,上限100%
- rkb:每秒读磁盘字节数
- wkb:每秒写磁盘字节数
注意:
- 使用iostat命令时,重点关注sda(操作系统中的第一块磁盘)那一行的数据。如果是云服务器,一般磁盘的名字叫vda
-
监控磁盘的性能指标时,更关注util%,它代表了磁盘的繁忙度,上限是100%
3.2、磁盘空间监控:df命令
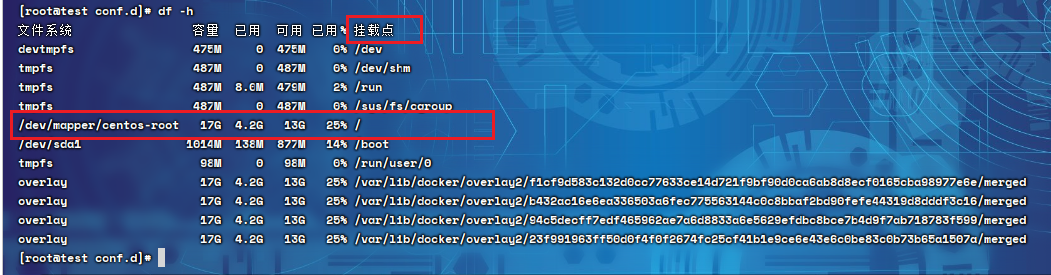
释义:df命令可以查看当前系统磁盘空间的使用情况
命令:df -h
注意:重点关注Mounted On为根目录/那行的数据
四、网络监控:sar
命令:
sar -n DEV 1 1000
其他:
DEV:统计网卡数据
1:每1秒刷新1次
1000:一共统计1000次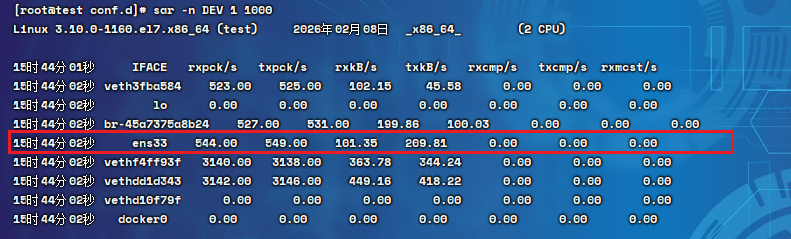
- ens33 代表的是网卡名称(一般的网卡名称都是eth或ens开头的),
- rxKB/s是服务器每秒接收的流量
- txKB/s是服务器每秒发送的流量
注意:网络速率不是一个瞬间值,也是一个区间值。本质是在过去一段时间内(1秒)服务器接收的流量总和(上行)和服务器传输的流量总和(下行)
五、如何判断某个指标是否达到瓶颈?
- CPU使用率:不超过80%
- 内存使用率:不超过80%
- 磁盘繁忙度:不超过90%
- 网络(发送/接受):结合网卡配置,一般的网卡都是千兆网卡(上行和下行均为千兆),千兆网卡吞吐量单位通常是1000Mbit /s ,流量监控工具统计单位是Mbyte/s(字节),1byte = 8bit,所以千兆网卡实际吞吐量=1000/8=125M byte/s。如果通过监控工具发现上行或者下行流量接近125Mb/s,说明当前的流量已经达到了网卡的上限,说明网络出现瓶颈。
六、综合监控工具
6.1vmstat
释义:vmstat命令综合了CPU、进程、内存、磁盘IO等信息,其实主要用它实时监控swap
命令:
vmstat 1
其他:
1:代表每秒监控一次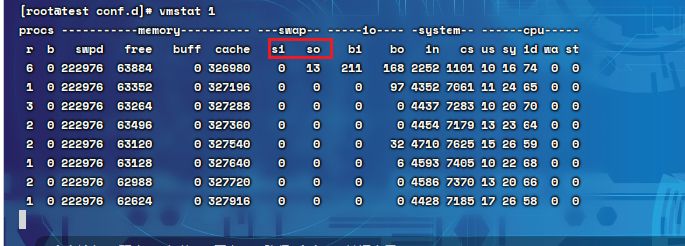
6.2超级监控工具:dstat
释义:dstat是一个全能监控工具,整合了CPU、内存、磁盘、网络等几乎所有的监控项,支持实时刷新,dstat需要先进行安装:yum install -y dstat
命令:
dstat -tcmnd --disk-util
其他:
t:time
c:CPU
m:内存
n:network,网络
d:disk,磁盘
--disk-util:监控磁盘的繁忙度
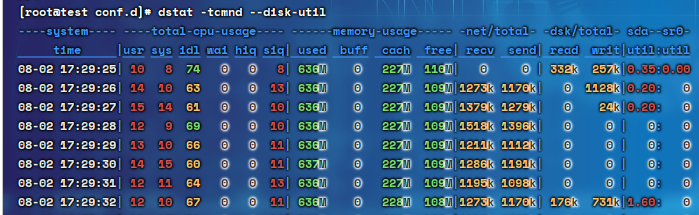
6.3监控工具:nmon
释义:nmon是IBM公司开发的Linux性能监控工具,可以实时展示系统性能情况,也可以将监控数据写入文 件中,并使用nmon分析器做数据展示
将“nmon”文件上传到Linux,在执行命令。
命令:
./nmon -ft -s 5 -c 1000
其他:
-f :表示生成数据文件名中有时间
-T :输出最消耗资源的进程
-s :每隔多少秒采集一次数据
-c :一共采集多少次数据Nmon文件需要关注的标签页:
1、cpu_all
2、diskbusy
3、net
4、mem
七、集群监控平台 普罗米修斯
释义:普罗米修斯监控平台可以对集群多台机器的系统资源进行监控,具体部署方法见文档
7.1Prometheus监控平台架构
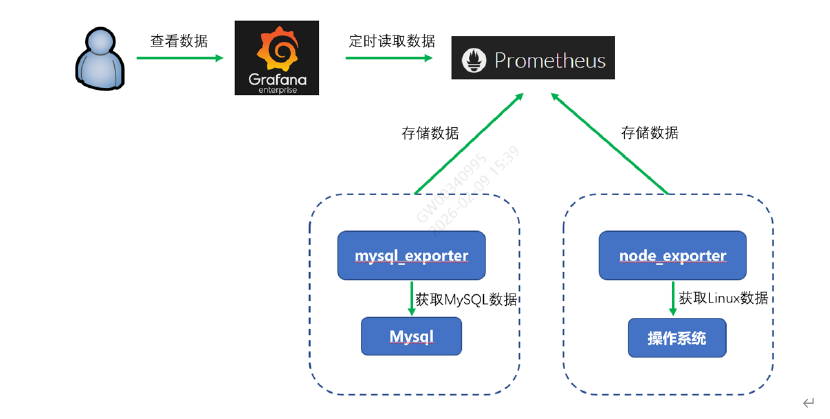
概念解释:
- Exporter:监控程序,负责收集数据。针对不同的监控目标,官方有不同的exporter程序
- Prometheus:时序数据库,负责存储数据
- Grafana:UI展示平台,负责展示数据
7.2部署前准备:
1、 关闭所有Linux机器的防火墙:systemctl stop firewalld
2、 保证所有Linux机器的时间是准确的,执行date命令检查;如果不准确,建议使用ntp同步最新网络时间
yum install -y ntp
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
ntpdate cn.pool.ntp.org7.3Prometheus监控平台搭建流程
本套监控体系包括:
- 操作系统监控
- MySQL监控
- redis监控
- Nginx监控
- docker监控
注意:为了安装更方便,安装过程采用docker安装。
7.3.1安装node_exporter
释义:node_exporter是专用于监控操作系统的exporter,包括CPU、内存、磁盘、网络等监控信息,在被监控的机器上安装exporter。模板id:11074
启动容器:
docker run -d -p 9100:9100 -v /proc:/host/proc:ro -v /sys:/host/sys:ro -v /:/rootfs:ro prom/node-exporter7.3.2安装Prometheus
释义:Prometheus是一个时序数据库,是用来存储数据的,要在宿主机上安装
- 在宿主机创建一个prometheus目录,如:/root/prometheus
- 在/root/prometheus下创建一个配置文件prometheus.yml,内容如下
global:
scrape_interval: 15s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'node'
static_configs:
- targets: ['192.168.3.224:9100']
注意:job_name为node的配置节点,targets中配置的是node_exporter的IP和端口,如果有多个node_exporter,中间以逗号隔开:['192.168.2.158:9100','192.168.2.168:9100']
- 运行容器:
docker run -d -p 9090:9090 -v /root/prometheus:/etc/prometheus --privileged=true prom/prometheus- 浏览器访问:http://{宿主机IP}:9090 即可看到prometheus提供的UI操作界面,点击status-targets,查看node_exporter的链接状态,如果状态是绿色的up代表链接成功
7.3.3安装grafana
- 启动容器:
docker run -d -p 3000:3000 grafana/grafana- 浏览器访问:http://{宿主机ip}:3000, 输入用户名/密码:admin/admin
- 配置prometheus数据源
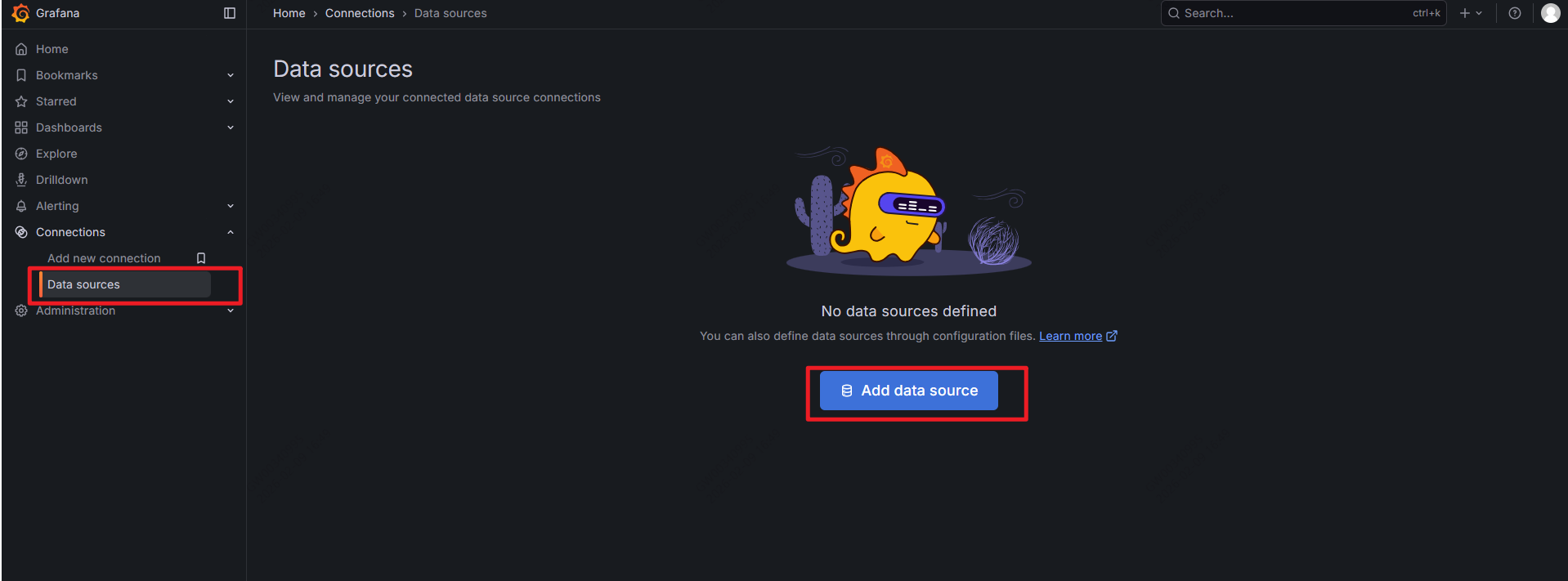
- 在URL处,填写prometheus的IP和端口号,其他保持默认,点击最下方Save & test
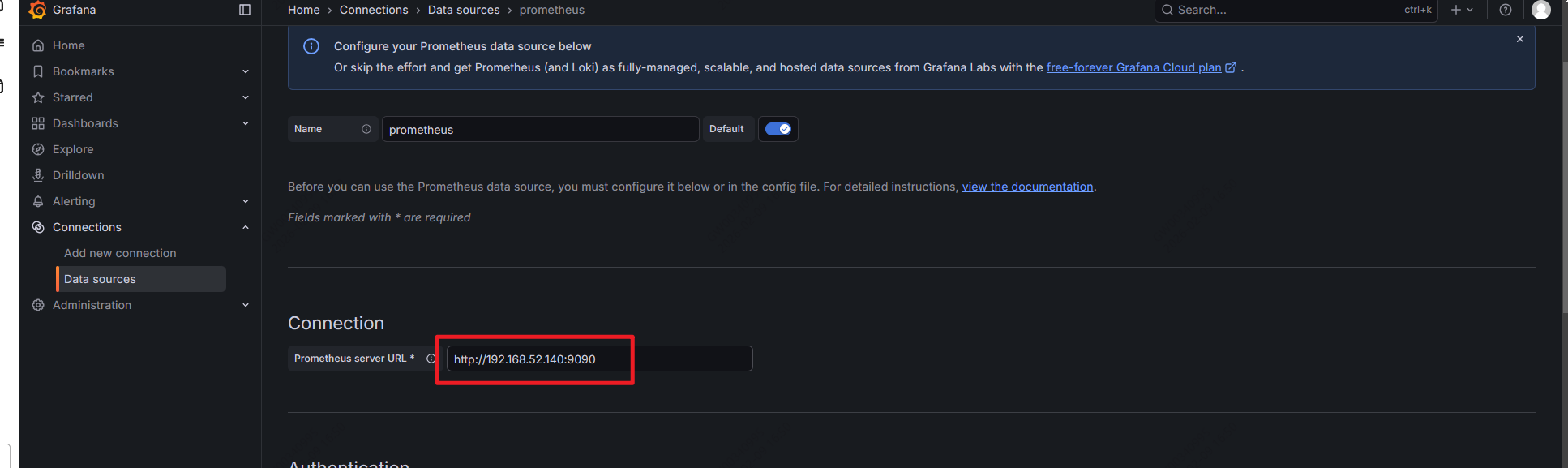
- 导入模板:输入模板id:11074,点击load,然后再次选择数据源
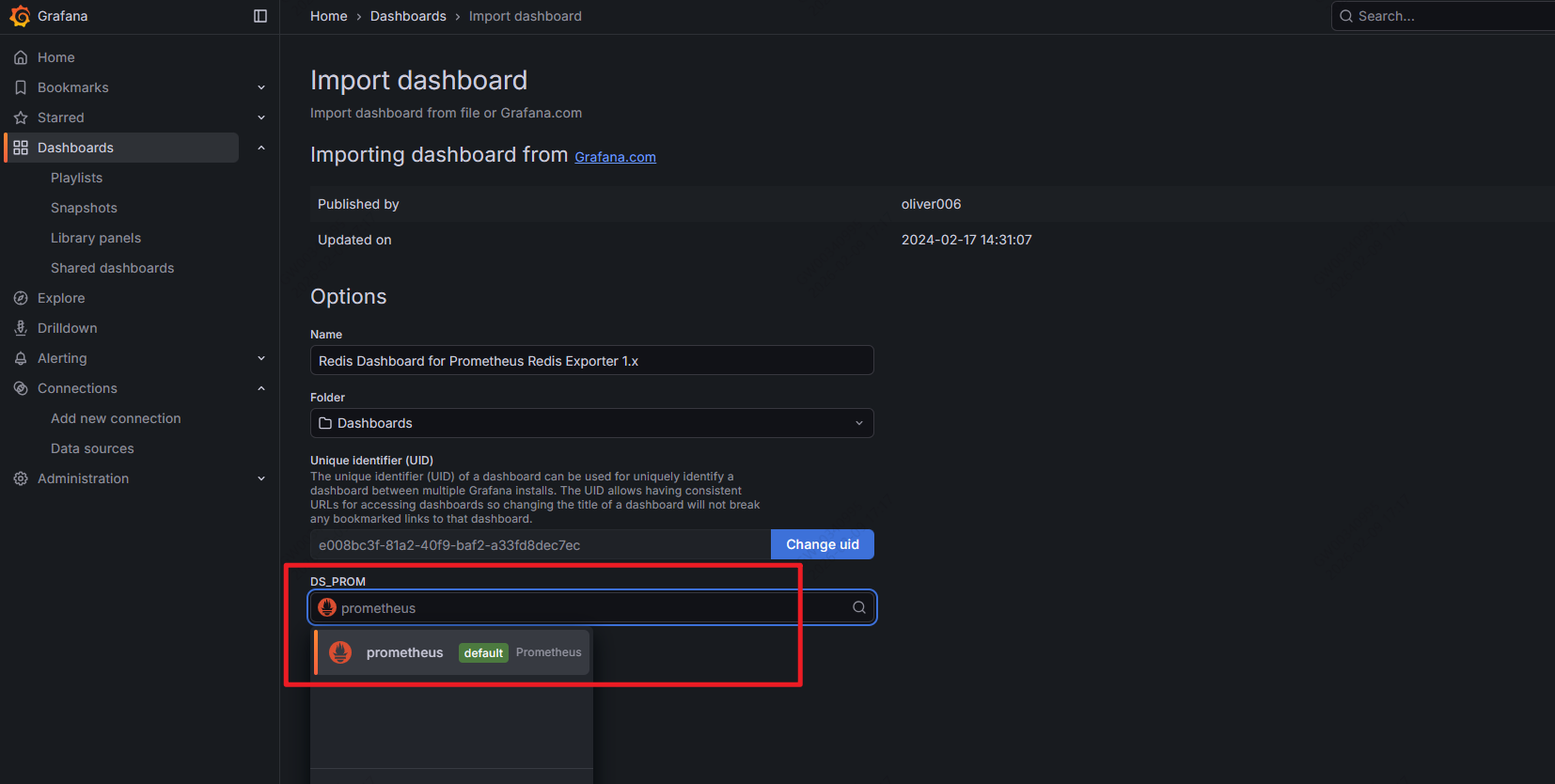
- 展示监控报表
- 注意:如果导入后的模板报错,如图:
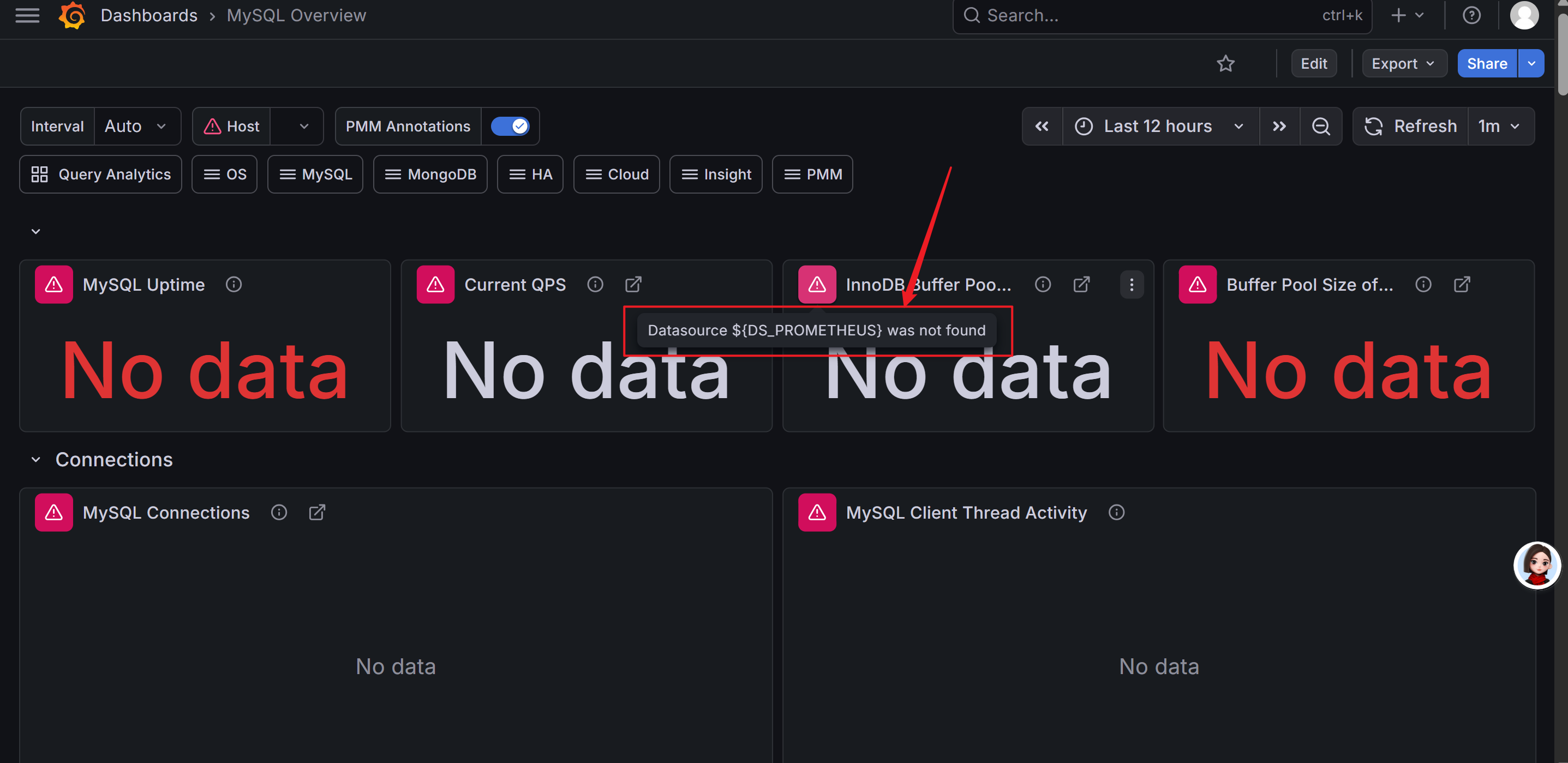
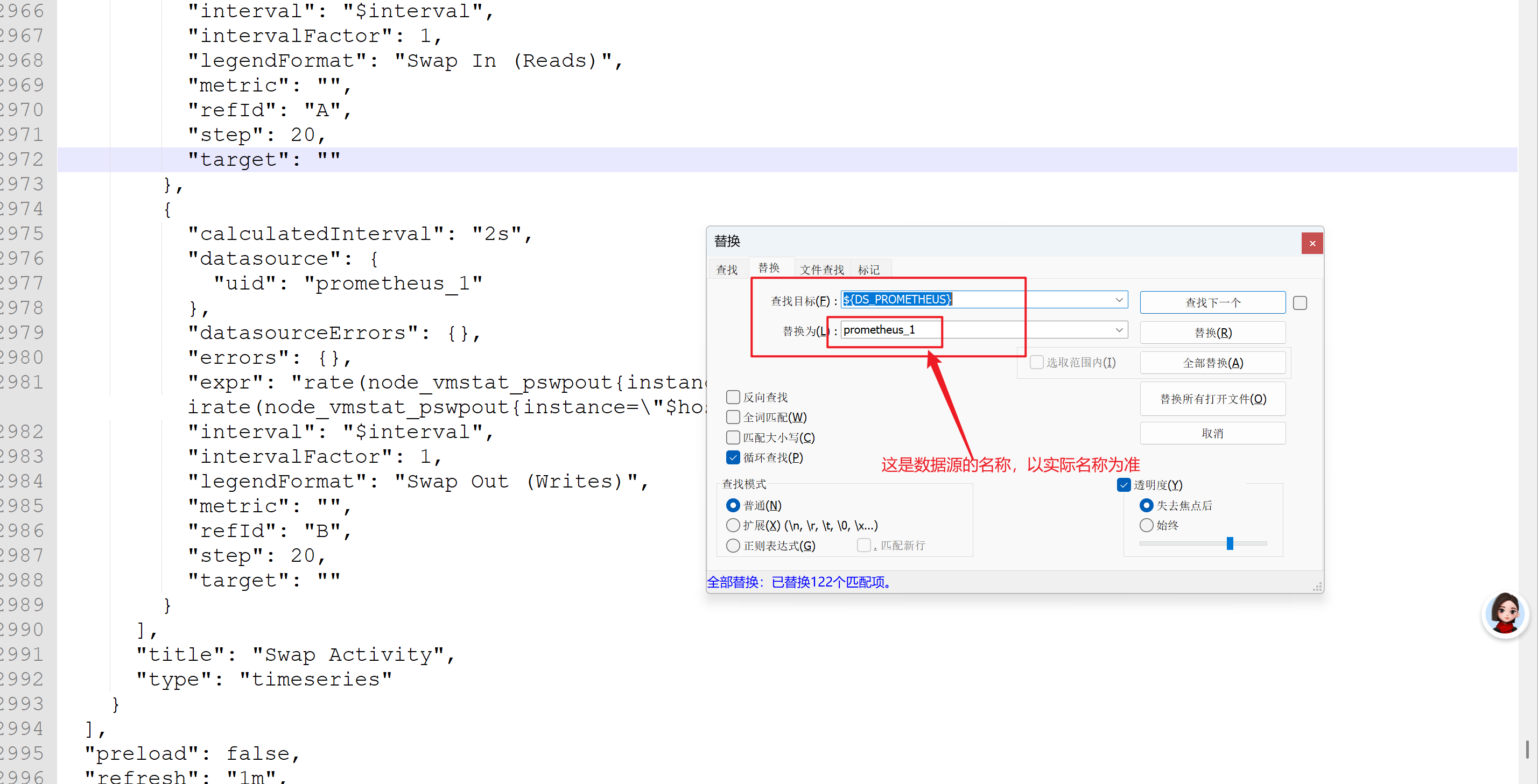
则需要将json代码复制到notepad上,将“${DS_PROMETHEUS}”整体替换成数据源的名称,比如“prometheus”
7.3.4安装mysql_exporter
- 启动容器:将数据中的ip、端口号写成自己的,DATA_SOURCE_NAME是一个环境变量,配置的是数据库的用户名、密码、数据库IP、端口号,根据实际情况进行修改
docker run -d -p 9104:9104 -e DATA_SOURCE_NAME="root:Testfan#123@(192.168.2.41:3306)/" prom/mysqld-exporter:v0.14.0- 在prometheus.yml中添加mysql_exporter信息,mysql_exporter的默认端口号为9104
- job_name: 'mysql'
static_configs:
- targets: ['192.168.2.41:9104']- 重启prometheus容器
- 在grafana中导入mysql监控模板,模板id:7362,操作方法同node_exporter
7.3.5安装redis_exporter
- 启动容器
docker run -d -p 9121:9121 oliver006/redis_exporter \ --redis.addr redis://192.168.2.41:6379 \ --redis.password 'Testfan#123'注意:
1、根据实际情况修改redis的IP和端口号
2、如果Redis有密码,需要添加--redis.password,没有密码不需要配
- 在prometheus.yml中添加redis_exporter信息,redis_exporter的默认端口号为9121
- job_name: 'redis'
static_configs:
- targets: ['192.168.2.41:9121']- 重启prometheus容器
- 在grafana中导入redis监控模板,模板id:763
7.3.6安装nginx_exporter
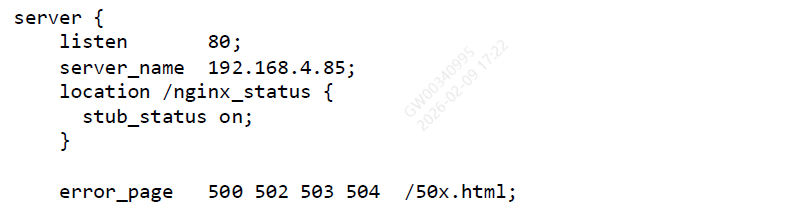
- 进入Nginx服务器的/etc/nginx/conf.d目录下,创建一个监控项目配置文件sub_status.conf,内容如下:
- 注意:server_name改成Nginx的本机IP
- 启动或重启Nginx
- 启动nginx_exporter容器,命令中的IP替换为Nginx的IP
docker run -d -p 9113:9113 nginx/nginx-prometheus-exporter -nginx.scrape-uri \ http://192.168.4.85/nginx_status- 在prometheus.yml中添加nginx_exporter信息,nginx_exporter的默认端口号为9113
- 重启prometheus容器
- 在grafana中导入nginx监控模板,模板id:12708
7.3.7安装cadvisor
释义:如果想监控容器的资源占用,如CPU、内存、磁盘等信息,而不是监控物理机,就需要使用cadvisor来监控
- 执行命令,设置目录权限,并建立软连接
mount -o remount,rw '/sys/fs/cgroup'
ln -s /sys/fs/cgroup/cpu,cpuacct /sys/fs/cgroup/cpuacct,cpu- 启动cadvisor容器
docker run -d -p 18080:8080 \
-v /:/rootfs:ro \
-v /var/run:/var/run:rw \
-v /sys:/sys:ro \
-v /var/lib/docker/:/var/lib/docker:ro \
-v /dev/disk/:/dev/disk:ro \
--privileged=true google/cadvisor- 在prometheus.yml中添加cadvisor信息
- job_name: 'cadvisor'
static_configs:
- targets: ['192.168.2.41:18080']- 重启prometheus容器
- 在grafana中导入容器监控模板,模板id:193
八、Java线程监控
8.1线程的5中状态
- 新建:new
- 运行:runnable
- 等待:waitting(无限期等待)、timed waitting(限期等待)
- 阻塞:blocked
- 结束:terminated
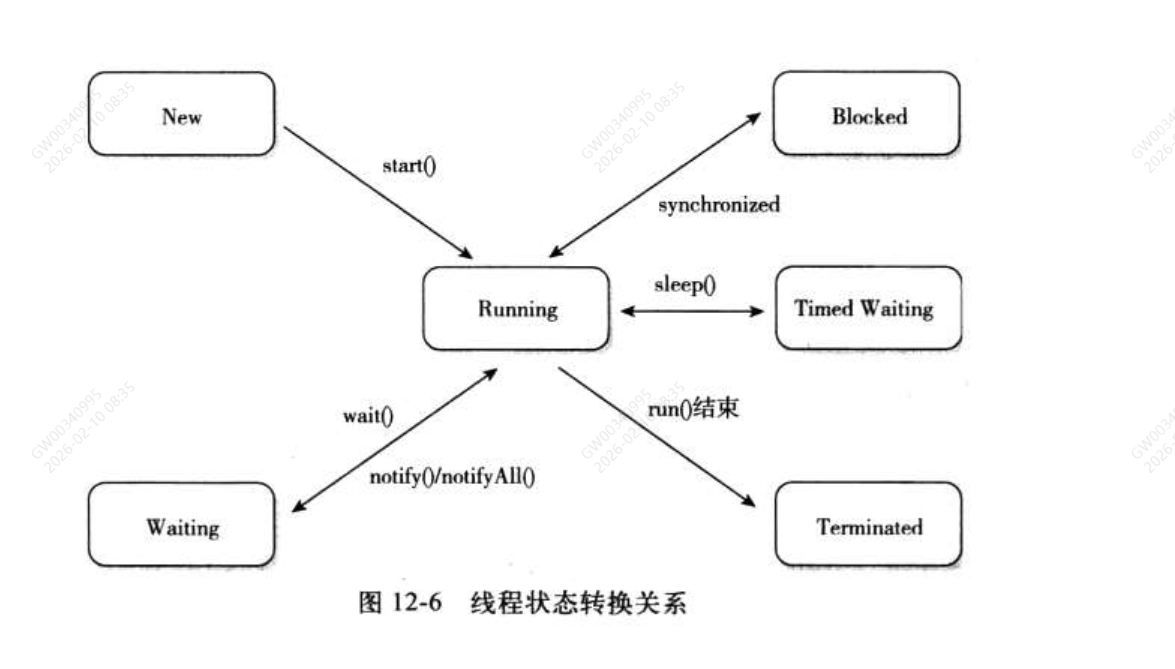
8.2Jvisualvm
释义:图形界面工具,监控之前先对jvm 加监控参数
Java程序监控
方法一:项目使用tomcat启动
- 在tomcat 的bin 目录下,catalina.sh 文件中,第二行添加:
JAVA_OPTS="-Djava.rmi.server.hostname=192.168.52.129 -Dcom.sun.management.jmxremote.port=10086 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.rmi.port=10086"
注意:
1、改port:改成本地空闲的port
2、将hostname为本机ip- 重启tomcat,使用jvisualvm建立链接
方法二:通过脚本启动
- 编辑启动脚本,找到项目jar包的启动命令,在java命令的后面,-jar的前面,添加:
-Djava.rmi.server.hostname=192.168.4.44 -Dcom.sun.management.jmxremote.port=10086 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=fals -Dcom.sun.management.jmxremote.rmi.port=10086- 重启程序,使用jvisualvm建立链接
8.3线程堆栈信息分析
- 线程名称:Mytesting
- 优先级: prio =10 ,默认是5
- tid =0xb7545800 :jvm 线程idid,jvm 内部线程的唯一标识
- nid =0x15cf 0x15cf:对应系统线程idid(NativeThread IDID),和top 命令查看的线程pid 对应,不过一个是10 进制,一个是16 进制。(通过命令:top H p pidpid,可以查看该进程的所有线程信息)
- 线程状态:java.lang.Thread.State : BLOCKED (on object monitor)
- 线程此时正在执行的方法,以及调用链:
-
at ThreadStatusTest.blocked (ThreadStatusTest.java: - waiting to lock <0x8bd6a238> (a java.lang.Object at BlockedStatus.run (ThreadStatusTest.java: at java.lang.Thread.run (Thread.java:
-
九、各个应用监控指标
9.1Mysql监控
- 连接数:客户端和服务端的某个软件同时建立的tcp链接数。
- Mysql最大链接数:150
- 通过监控工具可以看到当前连接数,用当前连接数和最大连接数作对比,判断连接数是否存在瓶颈
9.2redis监控
- 最大连接数:默认是10000,可以通过maxclients修改
- 通过监控工具可以看到当前连接数(connected),用当前连接数和最大连接数作对比,判断连接数是否存在瓶颈
9.3Nginx监控
- worker_processes:工作进程的数量,Nginx在启动的时候,会启动一个主进程 + n个工作进程(默认情况下,n是CPU的核数)
- 每个工作进程,默认最大的连接数为 1024,一般会改成65535
- Nginx最大连接数 = 当前CPU的核数 * 1024
- 通过监控工具可以看到当前连接数(connected),用当前连接数和最大连接数作对比,判断连接数是否存在瓶颈

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)