模型能不能训练出来是技术问题,敢不敢上线是评估问题
摘要:大模型工程中,训练失败容易察觉(如loss不收敛、显存爆炸),而评估失败往往隐蔽且危险。评估的本质是定义“成功标准”,比单纯优化模型更难达成共识。关键差异在于:训练有明确目标,评估需要混合判断;训练优化整体表现,评估关注极端情况;训练失败显性,评估失败隐性;训练是技术工作,评估涉及责任分配;训练可自动化,评估依赖人工判断。评估困境常表现为指标过多却决策困难,核心在于明确不可接受的风险类型而非
训练失败你能接受,评估失败你往往发现不了
在大模型工程里,有一个非常残酷但真实的现象:
- 训练失败,大家能迅速止损
- 评估失败,项目却可能一路冲到事故
原因很简单。
训练失败时:
- loss 不收敛
- 显存炸
- 模型输出明显不对
这些问题非常吵。
而评估失败时:
- 指标可能很好
- demo 看起来顺
- 样例大多“说得通”
但模型已经在某些你没看到的地方,
开始积累风险。
一个先摆在桌面上的结论(很重要)
在正式展开之前,我先把这篇文章最重要的一句话写出来:
训练是在优化模型,
评估是在定义“什么叫成功”。
而“什么叫成功”,
远比“怎么优化”更难达成共识。
第一层差异:训练有明确目标,评估没有
训练阶段,其实非常“单纯”。
你至少知道自己在干什么:
- 降 loss
- 提高 reward
- 让模型更像数据
不管这些目标对不对,
它们是清晰的。
而评估阶段,情况完全不同。
你需要回答的问题是:
- 这个模型算不算“够好”?
- 好到什么程度可以上线?
- 哪些错误可以接受?
- 哪些错误是红线?
注意:
这些问题,没有标准答案。
它们本质上是:
技术、业务、风险的混合判断。
第二层差异:训练面对的是“平均情况”,评估面对的是“坏情况”
训练过程本质上是在做一件事:
优化整体分布的期望表现。
无论是 SFT、LoRA 还是 PPO,
你关心的都是:
- 大多数样本
- 平均 loss
- 总体 reward
但评估关注的,恰恰相反。
评估真正关心的是:
- 极端输入
- 边缘场景
- 低频但高风险的 case
也就是说:
训练关心“整体变好”,
评估关心“最坏会多糟”。
而“最坏情况”,
天生就很难被穷举。
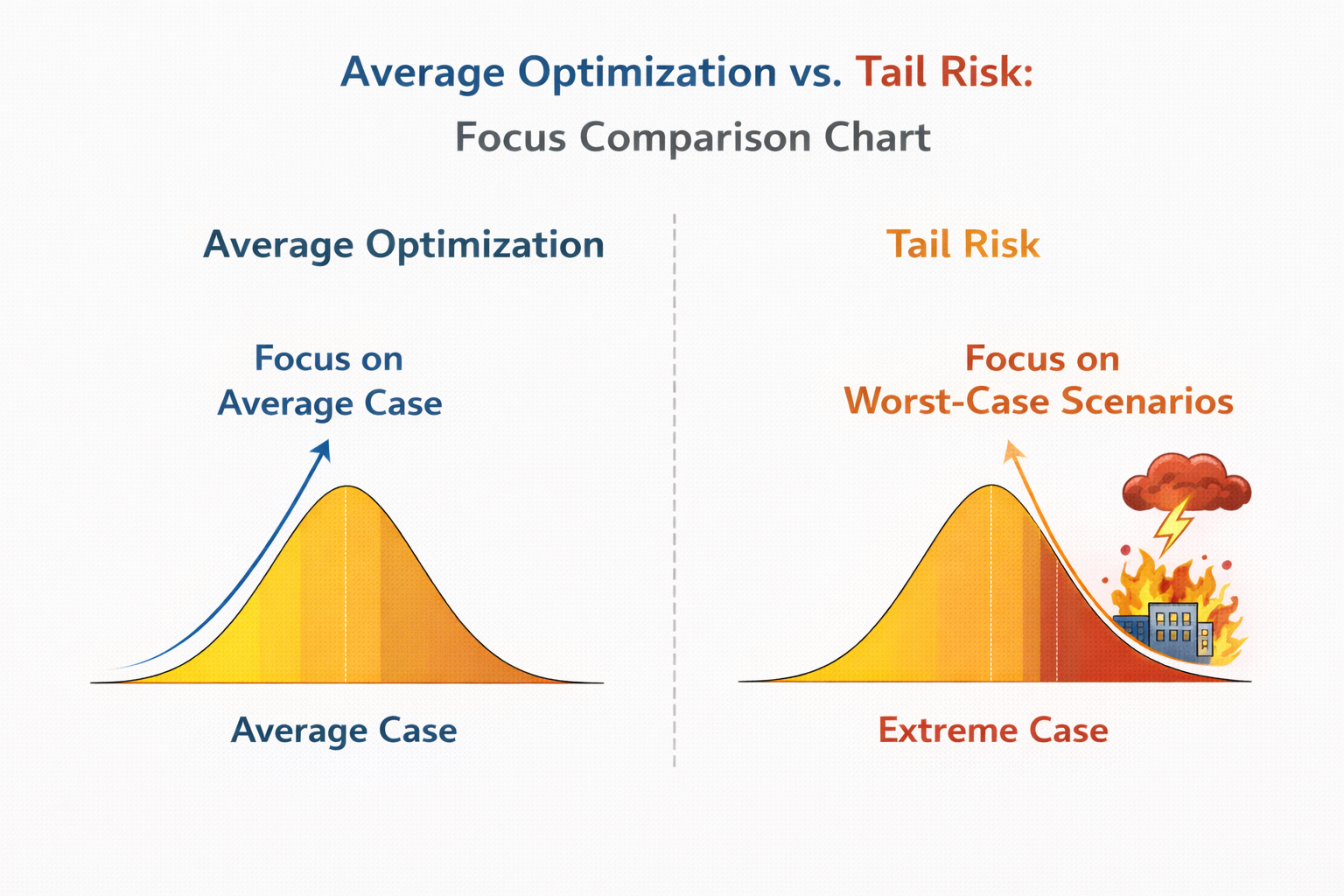
平均优化 vs 尾部风险 关注点对比
第三层差异:训练可以失败,评估一旦失败就很隐蔽
训练失败时,问题通常是显性的:
- loss 爆炸
- 模型崩坏
- 输出明显异常
但评估失败时,表现往往是:
- 指标“还不错”
- demo“能用”
- 少数 bad case 被解释成“偶发现象”
这正是评估难的地方:
评估失败,并不会大声告诉你它失败了。
它只是在默默地:
- 漏掉某些风险
- 放行某些不可接受行为
直到上线后,现实替你完成评估。
第四层差异:训练是技术工作,评估是责任工作
这是很多工程师最不适应的一点。
在训练阶段:
- 责任相对清晰
- 成败多半归因于技术方案
但评估阶段不一样。
评估意味着你在说:
“这个模型,我敢让真实用户用。”
这句话背后包含的,是:
- 风险承担
- 后果预期
- 谁来兜底
这已经不再是纯技术问题,
而是责任分配问题。
也正因为如此,
评估阶段的讨论,往往会变得非常艰难。
第五层差异:训练可以被“自动化”,评估几乎不行
训练是非常适合自动化的:
- pipeline 固定
- 指标明确
- 可重复性强
但评估,很难完全自动化。
原因很简单:
- 风险定义会变
- 业务关注点会变
- “不可接受”的标准会变
你可以自动算指标,
但你无法自动回答:
“这个错误,我们能不能接受?”
这也是为什么很多团队:
- 训练流程越来越成熟
- 评估流程却始终“靠人感觉”
而一旦评估过度依赖感觉,
系统稳定性就会变得非常脆弱。
一个非常真实的评估困境:你不知道该评估什么
在真实项目中,评估往往会陷入一个死循环:
- 指标太少 → 没安全感
- 指标太多 → 不知道该信哪个
- bad case 太多 → 看不过来
- bad case 太少 → 怀疑是不是没测出来
你会发现:
评估不是“有没有指标”,
而是“你到底在防什么”。
如果你自己都说不清风险优先级,
再精细的评估体系也只是在“制造安慰”。
为什么“评估越做越复杂”,反而越不敢上线
这是一个非常反直觉、但非常常见的现象。
很多团队在评估阶段,会不断追加:
- 更多测试集
- 更多指标
- 更多对照实验
但结果不是更安心,
而是:
信息越来越多,决策却越来越困难。
原因在于:
评估复杂度,已经超过了团队的理解能力。
当你无法解释:
- 某个指标变化意味着什么
- 某个 bad case 是否代表系统性问题
评估就会从“决策支持”,
变成“焦虑放大器”。
一个简单但非常残酷的事实
很多项目最终卡住,并不是因为模型不够好,而是因为:
没有任何一套评估结果,
能让团队“负责任地说:可以上线”。
不是没人努力,
而是评估本身承载了太多不确定性。
一个非常实用的评估自检问题(强烈建议)
在你继续“补评估”之前,可以先问自己一句话:
如果现在必须上线,
我们最担心模型会犯哪一类错误?
- 如果答不出来 → 评估方向是错的
- 如果答得很清楚 → 才值得围绕它补评估
评估不是穷举,
而是选择。
一段极简的“评估思维”示意代码(概念性)
# 评估的核心,不是统计“对了多少”
# 而是显式标注“哪些错是不可接受的”
def is_blocking_error(output):
return (
violates_policy(output)
or makes_strong_commitment(output)
or encourages_user_risk(output)
)
注意这里的重点:
- 没有复杂指标
- 只有明确红线
这类判断,
比精细打分更重要。
很多团队在评估阶段越做越焦虑,并不是因为模型太差,而是缺乏一个能把“训练变化、评估结果、风险类型”放在同一视角下对照的方式。用 LLaMA-Factory online 对不同版本模型进行并行评估,更容易判断:模型是真的在变好,还是只是在绕开你现有的评估方式。
总结:训练决定模型能走多远,评估决定你敢不敢走
我用一句话,把这篇文章彻底收住:
训练是在问:模型还能不能更强;
评估是在问:我们愿不愿意为它的错误负责。
这也是为什么:
- 训练可以不断重来
- 评估却必须一次次慎重
真正成熟的团队,不是训练得最猛的,
而是最清楚自己在评估什么、又在放弃什么的团队。
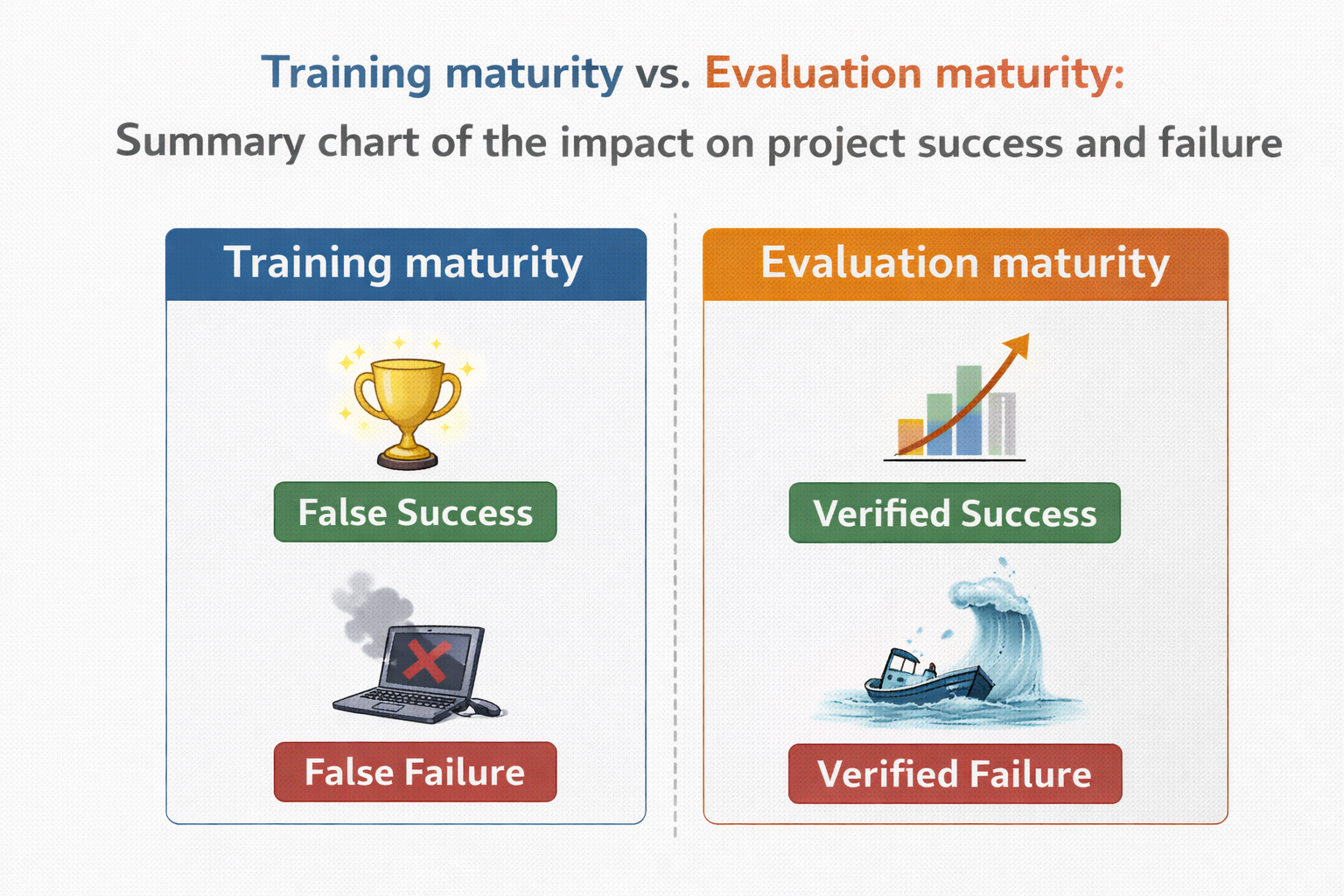
训练成熟度 vs 评估成熟度 对项目成败影响总结图

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 26
26 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)