
大模型入门15:GraphRAG、LightRAG、AgenticRAG
传统RAG存在某些局限性,比如对于知识图谱支持准确性很差,同时还面临歧义查询或需要深入理解上下文的查询方面的困难。但是大模型私有化部署通常依赖于多个外部来源,这些来源可能具有不同的格式、标准和可靠性水平。我们需要更多的方案解决这些难题。为什么需要多类型RAG前文提到了,RAG是大模型定制化或者私有化部署时知识增强方法的最便捷、成本最低的方式,是一种新数据引入大模型的经济高效的方法,它大模型私有化部

“传统RAG存在某些局限性,比如对于知识图谱支持准确性很差,同时还面临歧义查询或需要深入理解上下文的查询方面的困难。但是大模型私有化部署通常依赖于多个外部来源,这些来源可能具有不同的格式、标准和可靠性水平。我们需要更多的方案解决这些难题。”
为什么需要多类型RAG
前文AI|大模型入门(四):检索增强生成(RAG)提到了,RAG是大模型定制化或者私有化部署时知识增强方法的最便捷、成本最低的方式,是一种新数据引入大模型的经济高效的方法,它大模型私有化部署必备的步骤。
前文AI | 大模型入门(九):RAG数据库提到了,我们为什么需要RAG,同时指出RAG数据库有多种,如向量数据库、图数据库、知识图谱等。
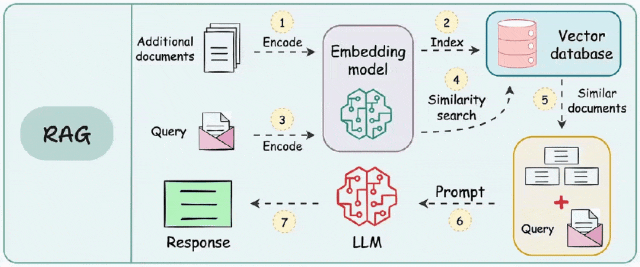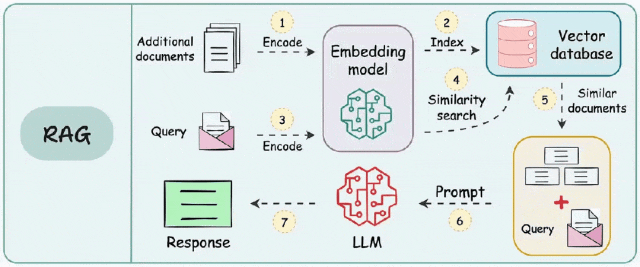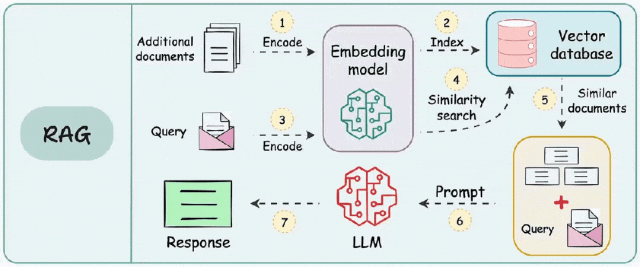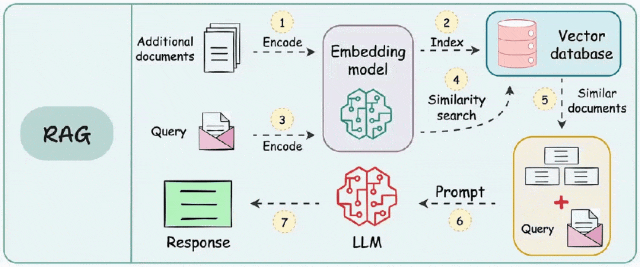
传统RAG工作流程图
但是,传统RAG在支持多类型数据源时存在一定的不足,比如:
一是大模型私有化部署过程中通常依赖于多种类型的外部数据源。这些数据源可能具有不同的格式、标准和可靠性水平,例如PDF、平面文件、Markdown、CSV、网页内容、拓扑图、思维导图等等;
二是传统RAG在实施过程中还面临歧义查询或需要深入理解上下文的查询方面的困难。传统RAG在设计上是将文档分块以便进行检索,然而这种方法忽略了这些块之间的上下文关系。如果意义或上下文跨越多个块,就很难准确回答复杂的问题。
这些问题是传统RAG技术设计天然短板,主要源于信息检索过程,但是该过程有时会忽略精确响应所需的细微差别。为了支持更广泛的外部数据,提升检索准确性,本文将继续探讨常用的其他RAG实现框架。
GraphRAG
1. 什么是GraphRAG
GraphRAG(Graph-based Retrieval Augmented Generation,图检索增强生成)是由微软于2024年7月2日开源的图检索增强生成框架,其目标是要提升大模型在处理私有数据时的理解和推理能力,是一种结合了知识图谱和检索增强生成(RAG)技术的新方法。
传统的RAG技术通过从外部知识库中检索相关信息,增强生成模型的输出质量。而GraphRAG则进一步引入了知识图谱,将信息以节点和边的形式存储,提供更丰富的上下文和关系信息,从而提升生成效果。
2. 工作原理
其工作原理是将知识图谱中的结构化数据整合到大语言模型的处理过程中,为模型的响应提供更细致、更全面的信息基础。知识图谱是对现实世界中的实体及其关系的结构化表示。它主要由两个部分组成:节点和边。节点代表单个实体,如人、地点、物体或概念。而边则表示这些节点之间的关系,表明它们是如何相互连接的。
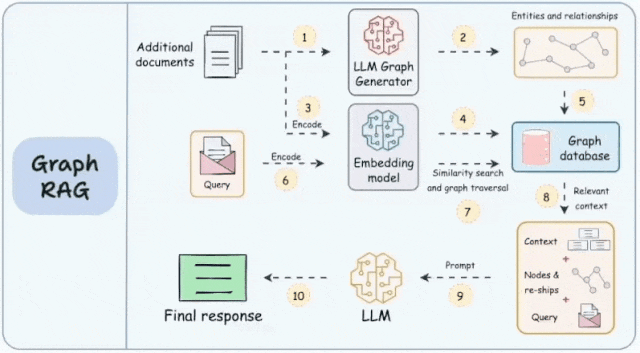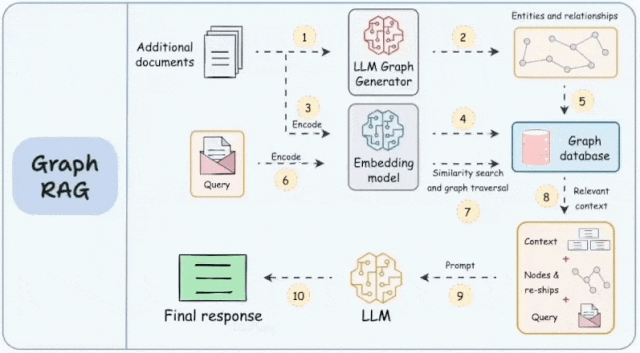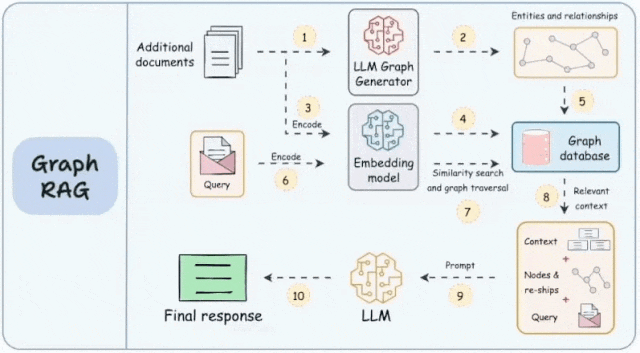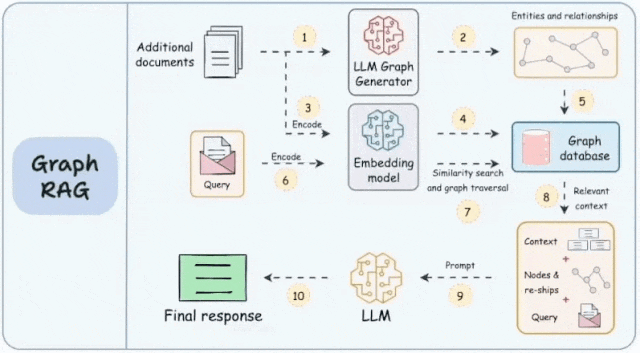
知识图谱构建:GraphRAG的核心在于其能够将非结构化的文本数据转换为结构化的图谱形式。在这个过程中,文本中的每个实体和概念都被视为图中的节点,而它们之间的关系则构成了节点之间的边。这种方法不仅增强了模型对数据的理解能力,也为模型提供了更丰富的信息检索和推理路径。
图机器学习:利用图神经网络(GNN)等图机器学习技术,GraphRAG能够进一步挖掘知识图谱中的深层信息和复杂关系,从而提升模型在问答、摘要和推理任务中的表现。
3. 技术优势
多维度问答能力:GraphRAG能够理解并回答涉及复杂关系和多步骤推理的问题,提供全面且准确的答案。
自动知识图谱更新:随着新数据的输入,GraphRAG能够自动更新知识图谱,保持信息的时效性和准确性。
跨领域信息整合:能够处理跨领域的数据集,整合不同来源和类型的信息,提供全面的视角和深入的分析。
高效的信息检索:通过社区检测算法和图检索技术,GraphRAG能够快速定位到相关信息,提高检索效率。
定制化摘要生成:根据不同的查询需求,GraphRAG能够生成定制化的信息摘要,提供个性化的信息服务。
但是,GraphRAG构建成本高、扩展性差,不支持知识图谱的增量更新,限制了它的应用场景,尤其是对于要求灵活多变的中小企业助手类、专家类应用场景不够友好。
LightRAG
1. 什么是LightRAG
LightRAG 是香港大学和北京邮电大学联合科研团队开发和开源的一款新型的图检索增强生成框架,其主要目标是通过使用知识图谱和嵌入来检索相关知识块以生成响应。传统的 RAG 系统通常将文档拆分成孤立的块,但 LightRAG 更进一步——它通过构建实体关系对的形式将文本中的单个概念连接起来。
LightRAG是一种基于GraphRAG的创新方法,它将知识图谱的属性与基于嵌入的检索系统相结合,使其既快速又高效,达到了最先进的结果。它在各种基准测试中都优于简单的RAG和GraphRAG。
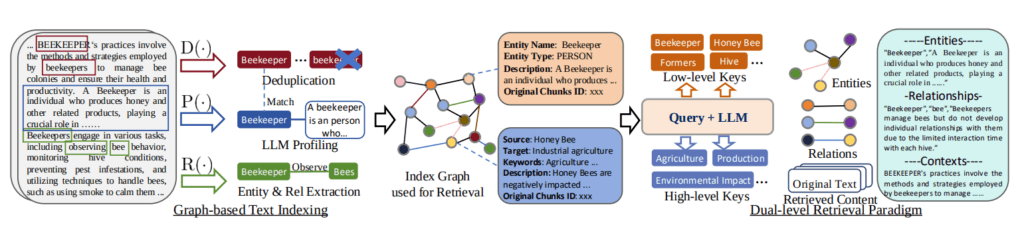
LightRAG架构图
2. LightRAG相比于GraphRAG的优势
虽然GraphRAG是开创性技术,但是它资源消耗太大。每一次运行往往需要数百次大模型API调用,通常用于像DeepSeek-R1这样昂贵的大型模型,这显然不适用于本地部署私有大模型的大多数场景。另外,每次更新外部数据源时GraphRAG都必须重建整个图谱,从而增加了成本。而LightRAG则不同:
-
使用更少的API调用,可以适用于更加轻量级的模型,如QwQ-32B。据测试,LightRAG的Token消耗仅为微软GraphRAG的1/6000,API调用次数减少约 90%。
-
允许对图形进行增量更新,而无需完全重新生成。
-
支持双层检索,如局部检索和全局检索,增强了检索信息的能力。它能够从低级别(具体细节)和高级别(宏观主题)两个层次全面检索信息,充分利用基于图的文本索引,捕获查询的完整上下文,从而生成更为丰富的回答。

一句话,LightRAG更快、更经济,并且允许对图进行增量更新,无需完全重新生成整个图谱。
AgenticRAG
1. 什么是AgenticRAG
AgenticRAG的核心思想是在每个阶段引入自主智能体Agent。
其工作的主要步骤有:
第一步:查询重写。智能体对用户查询输入信息进行重写,例如修正拼写错误。
第二步:额外信息获取。智能体判断是否需要额外的信息,比如通过搜索引擎或者调用工具获取必要的数据。
第三步:内容检查。在生成内容后,智能体会检查答案的相关性和有效性。如果不符合要求,系统会返回第一步,修改查询并继续迭代,直到找到相关内容或告知用户问题无法回答。
下图为AgenticRAG的工作流程图。
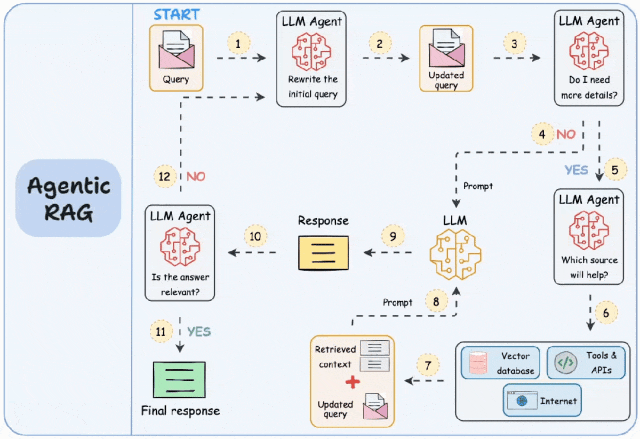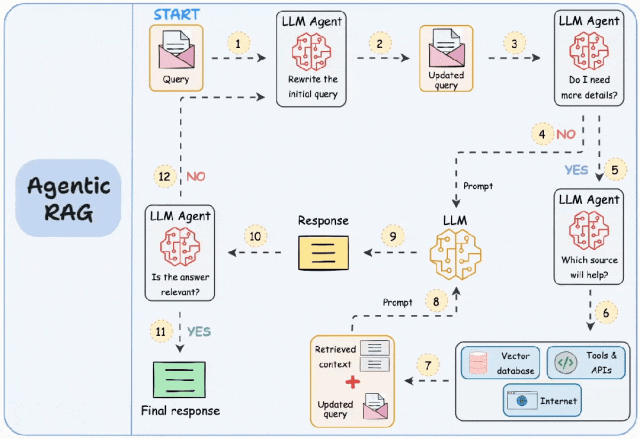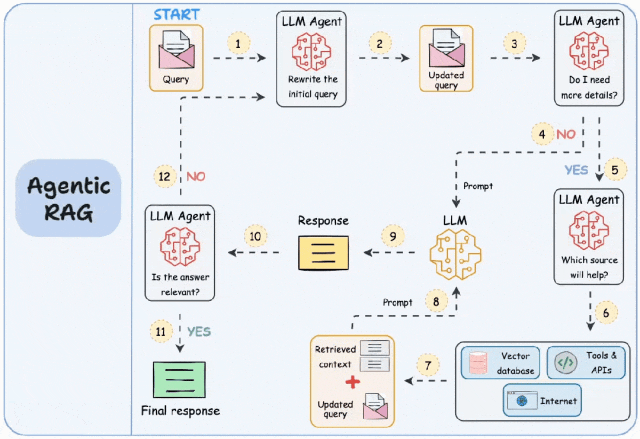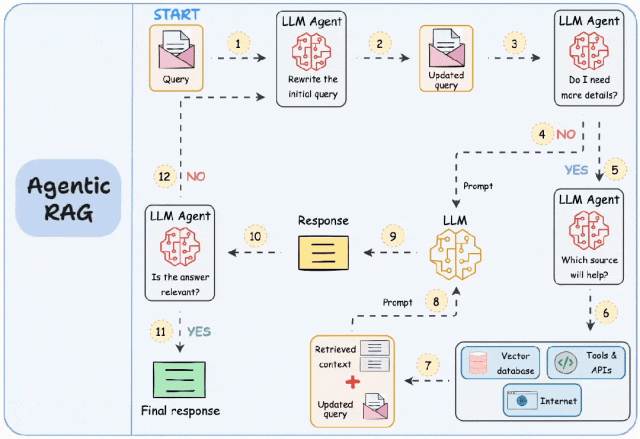
Agentic RAG工作流程图
2. 技术优势
AgenticRAG在传统RAG的基础上引入了AI Agent(智能体),强调自主决策和动态交互能力。能够处理复杂的对话、多轮交互和动态调整检索策略,适应用户复杂需求。Agentic也是未来智能体开发的一个重要基础型技术思路。
但是相较于传统RAG,它的成本更高,处理时间更长,更适合用于复杂对话系统、虚拟助手等场景,能够有效处理多轮对话和复杂查询。
随着大模型技术的逐步成熟,生态逐步完善,人们对大模型需求的进一步提高,AgenticRAG将会有更大的发展空间,有望成为基础设施级别的技术需求,比如AgenticRAG功能直接融入基础大模型,成为大模型功能必备的能力之一。
技术选型
前文AI | 大模型入门(十):RAG vs. KAG我们也提到过阿里推出的知识图谱解决方案KAG。因此对于知识图谱的检索增强生成场景,我们有众多的解决方案可以选择。在技术选型时建议选择合适的解决方案:
1. 如果是搭建简单的企业内部办公问答助手客服机器人,外部数据源是表格、word文本等纯文本类型,可以选择传统RAG。
2. 如果是用于专业领域的知识关联分析的行业专家机器人,外部数据源非常庞大,并且是逻辑关系极高的知识图谱等内容,且不会轻易更新,比如医疗诊断图谱、法律条款关联分析等,可以选择GraphRAG或者KAG。
3. 如果是用于专业领域的知识关联分析的行业专家机器人,外部数据源不会太大,而且是逻辑关系极高的知识图谱等内容,并且具有实时更新需求,比如医疗案例分析、审判案件分析等,可以选择LightRAG。
4. 如果是用于解决复杂的开放型问题,需要主动检索外部数据、多轮交互,推理过程等功能,可以选择AgenticRAG。
总结:简单问答直接用传统RAG(简单好用),有知识图谱需求用LightRAG(便宜轻便好用),更加复杂的需求用AgenticRAG(复杂但功能强大)。
注:目前,大模型技术还处于初始发展阶段,各种思路、技术架构野蛮生长,不断推陈出新,各种应用、框架还处于还在快速迭代过程中。今天选择了一种技术,明天可能就会有更好的解决方案。今天遇到无法逾越的障碍,明天解决方案可能就已经集成到大模型中。
如何学习AGI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取