医疗 AI 如何说“我不知道”?详解 CLEAR-Mamba 的不确定性量化机制
在狄利克雷分布中,全 1 代表“完全无知”(Zero Evidence),而全 0 在数学上是未定义的(非法值)。证据与参数的关系:在证据深度学习(EDL)中,狄利克雷分布的参数α\alphaα与模型输出的“证据”eeeαkek1αkek1eke_kek(Evidence):模型在特征图中找到的支持第kkk类的证据量,必须≥0\ge 0≥0。完全无知状态:意味着模型什么证据都没找到,即ek0
这篇论文由浙江大学(浙大二院眼科中心等机构)的研究团队提出,2026年1月26挂在arxiv上。旨在解决眼科血管造影(Angiography)图像分类中的几大痛点:时序信息利用不足、模型泛化能力弱以及预测可信度低的问题 。本文中几个模块实现很有想法,本文对其进行解读。由于论文未开源任何代码和数据集,本文对其中核心模块进行解读分析,并实现为可插拔模块方便感兴趣的读者测试。

1.核心背景与问题 (Introduction & Motivation)
眼科造影的特殊性: 眼底荧光血管造影 (FFA) 和吲哚菁绿血管造影 (ICGA) 是动态的序列图像,包含血流动力学(hemodynamics)和病变演变的时间信息 。
**现有方法的局限:**现有的多模态方法往往只关注不同模态间的融合,而将造影视为静态图像,丢失了时间维度的诊断价值 。 CNN 难以捕捉长距离依赖,ViT 计算开销大,不适合处理长序列造影 。现有模型常在分布外数据上表现出“过度自信”(Overconfidence),且难以适应复杂的临床场景(如多病种分类) 。
2.提出的解决方案:CLEAR-Mamba 框架
为了解决上述问题,作者提出了 CLEAR-Mamba 框架。这是一个基于 MedMamba 的增强型框架。CLEAR-Mamba 的工作流是:
- MedMamba 提取基础的时序特征。
- HaC 观察这些特征,动态调整网络参数,使特征更适配当前病例。
- RaP 接收调整后的特征,计算分类证据,并最终输出诊断结果 + 不确定性评分 。
包含三个核心组件 :
2.1 基座 (Backbone): MedMamba
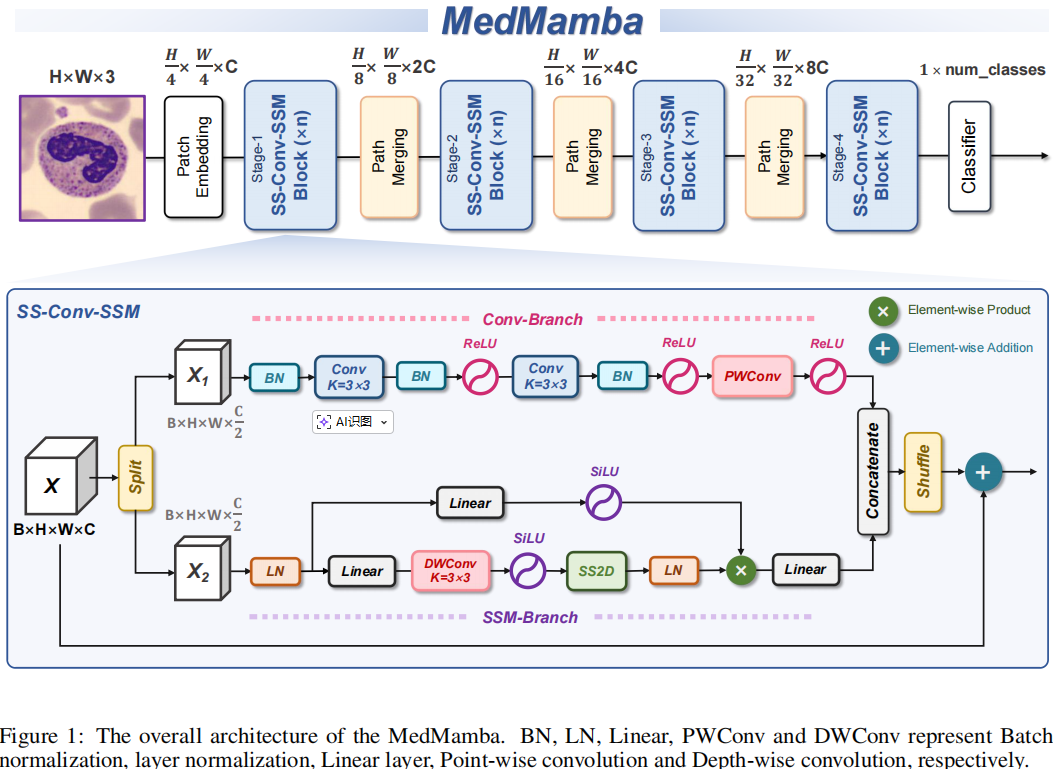
MedMamba(MEDMAMBA: VISION MAMBA FOR MEDICAL IMAGE CLASSIFICATION)是2024年提出的一个基于Mamba的医学图像分类模型,利用视觉状态空间模型 (VSSMs) 和 2D 选择性扫描 (SS2D) 技术,能够在保持线性计算复杂度的同时,高效捕捉造影序列中的长距离时序依赖和局部特征 。模型结构不复杂,我这里直接放上MedMamba中的插图,这篇论文代码已经开源,我之前也做过测评,感兴趣可以自行去下载代码调测,本文重点不在基座解读上,后面的2.2和2.3才是我们解读的重点。
2.2 HaC: 超适应调节模块 (Hyper-adaptive Conditioning)
设计初衷: 在眼科造影中,不同设备、不同造影阶段以及病灶的多样性会导致严重的“域偏移”(Domain Shift)。传统的静态模型参数一旦训练完成就固定了,难以应对这种个体间的巨大差异 。HaC 的目标是让模型具备“动态适应性”,即针对每一张输入图像,微调特征提取的方式。
原理: 引入超网络 (HyperNetwork),根据输入图像的特征动态生成模型参数 。
作用: 实现“病例级”的自适应。它能根据输入特征的分布调整网络,从而提高模型在不同个体和跨域场景下的泛化能力和适应性 。
核心机制:HyperNetwork (超网络) HaC 采用了一种轻量级的超网络架构,其核心思想是:“由一个网络为另一个网络生成参数”。
step1:特征压缩 (Global Descriptor Extraction):
首先,从 MedMamba 主干网络 (Backbone) 的输出层 X(L)X^{(L)}X(L) 中,通过全局平均池化 (GAP) 提取出一个全局特征向量 zzz 。
这个 zzz 包含了当前病例的整体语义信息(例如:这是一张造影早期的图,还是晚期的图;是模糊的,还是清晰的)。
step2:动态参数生成 (Parameter Generation):
HaC 将这个全局特征 zzz 输入到一个超网络 HψH_{\psi}Hψ 中。超网络不输出分类结果,而是输出一组调节参数 θ\thetaθ 。
公式表达为:θ=Hψ(z)\theta = H_{\psi}(z)θ=Hψ(z)。
step3:特征调制 (Feature Modulation - FiLM & Gating):
生成的参数 θ\thetaθ 被用来对原始特征进行仿射变换(Affine Transformation)。论文借鉴了 FiLM (Feature-wise Linear Modulation) 的思想,生成缩放因子 γ\gammaγ 和平移因子 β\betaβ 。调制公式:
X~=γ⊙X+β\tilde{X} = \gamma \odot X + \betaX~=γ⊙X+β
为了保持训练稳定,作者还引入了一个门控机制 (Gated Mechanism)。超网络同时生成一个门控系数 α\alphaα(通过 Sigmoid 激活),用于控制调节的力度 。最终输出:
Xout=X+α⊙(X~−X)X_{out} = X + \alpha \odot (\tilde{X} - X)Xout=X+α⊙(X~−X)
这意味着模型会根据当前图像的特征,自适应地决定保留多少原始特征,以及融入多少动态调整后的特征 。
HaC 它让 CLEAR-Mamba 变成了一个“千人千面”的模型。遇到模糊的图像,它可能会自动增强边缘特征的权重;遇到不同设备的图像,它会动态调整分布,从而极大提升了跨域适应能力 。
2.3 RaP: 可靠性感知预测 (Reliability-aware Prediction)
设计初衷: 传统的深度学习分类器使用 Softmax 输出概率。然而,Softmax 有一个致命缺陷:即使模型完全在“瞎猜”,它也可能给出一个很高的置信度(例如 99% 的概率归为某一类),这被称为“过度自信” 。在医疗诊断中,这种“不懂装懂”是极度危险的。RaP 旨在让模型能够说“我不知道”。
原理: 基于证据深度学习 (Evidential Deep Learning, EDL) 构建的分类头。它不直接输出概率,而是参数化一个狄利克雷分布 (Dirichlet distribution) 。
作用: 模型不仅输出预测结果,还输出“不确定性” (Uncertainty)。当证据不足或样本模糊时,模型会给出高不确定性,避免盲目自信,支持临床中的风险感知决策(如转交人工复核) 。
核心机制:证据深度学习 (Evidential Deep Learning, EDL) RaP 不再将输出视为单纯的概率,而是视为支持某一类别的“证据” (Evidence),并基于狄利克雷分布 (Dirichlet Distribution) 对不确定性进行建模 。
step1:证据生成 (Evidence Generation):
模型的最后一层不使用 Softmax,而是使用 Softplus 激活函数,确保输出非负的证据向量 eee 。
ek=Softplus(Wz+b)e_k = \text{Softplus}(Wz + b)ek=Softplus(Wz+b)
这里 eke_kek 表示第 kkk 类疾病被观测到的证据量。
step2:狄利克雷参数化 (Dirichlet Parameterization):
将证据转换为狄利克雷分布的参数 α\alphaα:
αk=ek+1\alpha_k = e_k + 1αk=ek+1
狄利克雷分布是“概率的概率分布”。通过它,我们可以算出预期的类别概率 p^k=αk/S\hat{p}_k = \alpha_k / Sp^k=αk/S,其中 S=∑αkS = \sum \alpha_kS=∑αk 是总证据量 。
step3:不确定性量化 (Uncertainty Quantification):
RaP 的核心优势在于它能量化认知不确定性 (Epistemic Uncertainty)。如果不确定性高(即总证据量 SSS 很小),说明模型没见过这类样本,此时预测结果不可信。在推理阶段,模型通过计算预测熵 H(p^)H(\hat{p})H(p^) 来衡量不确定性 。
step4:损失函数 (Objective Function):
训练时使用特殊的损失函数:负对数似然 (NLL) + KL 散度正则项 。
L=LNLL(α;y)+λ⋅KL[Dir(α)∣∣Dir(1)]\mathcal{L} = \mathcal{L}_{NLL}(\alpha; y) + \lambda \cdot KL[Dir(\alpha) || Dir(1)]L=LNLL(α;y)+λ⋅KL[Dir(α)∣∣Dir(1)]
KL 正则项的作用: 强迫模型在没有证据支持时,回归到均匀分布(即“我什么都不知道”的状态),防止模型在分布外数据上产生高置信度 。
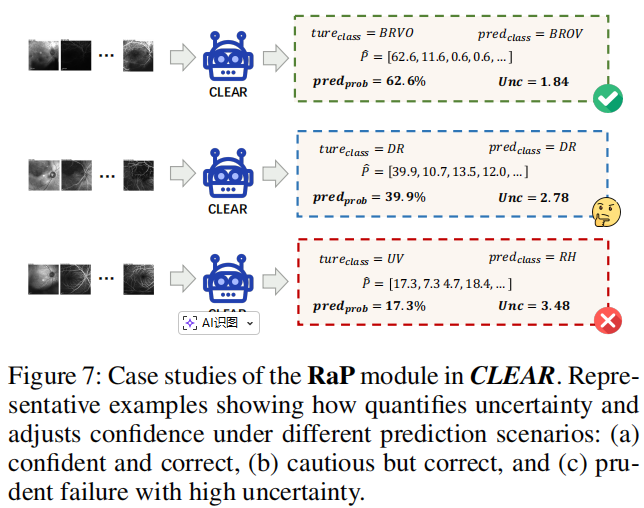
RaP 将传统的“黑盒预测”转变为“可信预测”。论文图 7 展示了一个被误分类为“视网膜出血”的葡萄膜炎样本。如果是普通模型,可能会以 90% 的置信度误判;但 RaP 给出了极高的不确定性 (Unc≈3.48Unc \approx 3.48Unc≈3.48),提示医生:“这里我很困惑,请人工复核” 。
2.4 数据集构建:多智能体数据引擎 (Multi-Agent Data Engine)
由于公开数据集稀缺且多为单病种,作者构建了一个大规模的内部数据集。为了处理原始 PDF 报告,开发了一套自动化的多智能体处理流程 :
处理流程 (Pipeline):
1.提取器 (Extractor): 从 PDF 中定位并提取高分辨率图像 。
2.分析器 (Analyzer): 利用 OCR 和 NLP 解析报告文本,提取左右眼 (OS/OD) 和模态 (FFA/ICGA) 等元数据 。
3.处理器 (Processor): 自动检测并擦除图像上的隐私信息(如名字、ID),同时保留视网膜区域 。
4.匹配器 (Matcher): 解决双眼并在同一张图上的问题,进行左右眼分割和病灶匹配,减少标签噪声 。
5.审查员 (Reviewer): 引入眼科医生进行人工质量控制,确保障据质量 。
**数据集统计:**包含 15,524 张有效图像 。覆盖 43 种眼科疾病类别(长尾分布,糖尿病视网膜病变 DR 占比最高) 。包含完整的 FFA (87.7%) 和 ICGA (12.3%) 时序序列 。
3.几个问题的思考
以下几个问题是可能非研究领域的读者看论文会有疑问的点,这里试图澄清一下
3.1 问题1: 为什么用Softplus,softmax输出的概率大小不是也可以从一定程度上代表确信度吗?
在很多常规任务中,Softmax 输出的最大概率值(Maximum Probability)确实常被用作置信度。但是,在医疗诊断等高风险领域,Softmax 有一个致命的“过度自信”(Overconfidence)缺陷,而这正是这篇论文引入 Softplus 和证据深度学习(Evidential Deep Learning, EDL)要解决的核心问题。
先说 Softmax 的“致命缺陷”-强迫选择 (Forced Choice)。
Softmax 的数学本质是归一化。无论输入是什么,它都强制把所有类别的概率之和变为 1。我举一个分布外数据(OOD)的例子。假设你训练了一个识别“猫”和“狗”的模型,现在输入 一张“飞机”的照片。Softmax 的反应: 模型在特征空间里可能觉得“飞机”稍微有点像“猫”(比如都有耳朵形状的突起)。假设模型给出的原始分数(Logits)都很低,比如 猫=0.002,狗=0.001。Softmax 会放大微小的差异,最后输出:猫 52%,狗 48%(甚至更高)。这样的后果是看到 52% 的概率,可能以为模型有一半把握。但实际上模型根本没见过飞机,它是在“瞎猜”。Softmax 掩盖了“模型其实对所有类别都不熟”这一事实 。
Softplus + EDL 的逻辑是基于“证据”的绝对量。这篇论文中的 RaP 模块使用 Softplus 激活函数,是为了输出非负的“证据量” (Evidence),而不是概率。Softplus 公式是 y=ln(1+ex)y = \ln(1 + e^x)y=ln(1+ex)。它的作用是把神经元的输出变成一个大于 0 的数 ,这代表模型在图像中发现了多少“证据”支持这一类。还是上面的场景,模型在图里找不到猫的特征(胡须),也找不到狗的特征(鼻子)。Softplus 输出的证据量:猫的证据 ecat≈0e_{cat} \approx 0ecat≈0,狗的证据 edog≈0e_{dog} \approx 0edog≈0。总证据量 SSS: S=∑(ek+1)S = \sum (e_k + 1)S=∑(ek+1)。不确定性 uuu: u=K/Su = K / Su=K/S(K是类别数)。因为证据很少,分母 SSS 很小,导致不确定性 uuu 极大。模型会告诉你:“我认为是猫的概率是 50%,但是我的不确定性是 100%。”
我们可以对比两组 Logits(模型原始输出):
情况 A(很有把握): Logits = [100, 100]
情况 B(完全瞎猜): Logits = [0.01, 0.01]
| 方法 | 情况 A (高分) | 情况 B (低分) | 结论 |
|---|---|---|---|
| Softmax | 概率:[0.5, 0.5] |
概率:[0.5, 0.5] |
Softmax 无法区分它是“懂”还是“不懂”,输出一模一样。 |
| Softplus (RaP) | 证据:[High, High] 不确定性:极低 |
证据:[Low, Low] 不确定性:极高 |
RaP 能区分出情况 B 是不可信的。 |
论文在图 4(b) 中通过实验证明了这一点:
不加 RaP (使用 Softmax): 即使是分类错误的样本,模型给出的置信度中位数也高达 0.870 。这意味着模型经常自信满满地胡说八道。
加上 RaP (使用 Softplus+EDL): 分类错误的样本,置信度中位数骤降至 0.274 。这说明模型知道自己可能错了,变得更加“谦虚”和谨慎。
3.2 损失函数为什么这样设计
简单来说,负对数似然 (NLL) 负责让模型**“学得准”(尽可能把正确类别的证据找出来)。KL 散度正则项 负责让模型“守规矩”**(如果没有十足的把握,就默认自己什么都不知道,保持高不确定性)。两者结合,才能让模型既能准确诊断疾病,又敢于承认自己看不懂某些疑难杂症。
接下来通俗解释一下:
负对数似然 (NLL) —— “努力考高分”:NLL (Negative Log-Likelihood) 的作用是拟合数据。这和普通的交叉熵损失很像,但它是基于“证据”的。对于一张标注为“糖尿病视网膜病变(DR)”的图片,NLL 会强迫模型去挖掘属于 DR 的特征(比如出血点、渗出物)。模型找到特征 -> DR 类的证据量 eDRe_{DR}eDR 增加。DR 类的狄利克雷参数 αDR\alpha_{DR}αDR 增加。NLL 损失变小。如果单独使用NLL,为了让损失最小化,模型可能会拼命增加证据量,甚至产生幻觉。比如看到一张模糊的图,为了迎合 NLL,它可能会强行说“我觉得这有 99% 是 DR”,以此来降低损失。这就导致了过度自信。
KL 散度正则项 —— “默认归零”:KL 散度 (Kullback-Leibler Divergence) 用来衡量两个分布有多不同。在这里,我们衡量的是:“模型当前的预测分布” 和 “完全无知的均匀分布” 之间的差距。 我们预设一个“先验分布”,即 Dir(1,1,...,1)Dir(1, 1, ..., 1)Dir(1,1,...,1),这意味着每一类的证据都是 0。代表**“我什么证据都没看到,所以我对每个类别的概率都是均等的(完全不确定)。”KL 项会产生一个惩罚力,试图把模型的预测拉回到这个“完全无知”的状态**。它在对模型说:“除非你真的在图里看到了确凿的证据,否则你就给我保持沉默(输出均匀分布,不确定性最大化)。”
Loss=LNLL⏟想让证据越多越好+λ⋅KL[Dir(α)∣∣Dir(1)]⏟想让证据越少越好Loss = \underbrace{\mathcal{L}_{NLL}}_{\text{想让证据越多越好}} + \lambda \cdot \underbrace{KL[Dir(\alpha) || Dir(1)]}_{\text{想让证据越少越好}}Loss=想让证据越多越好 LNLL+λ⋅想让证据越少越好 KL[Dir(α)∣∣Dir(1)]
加在一起是个博弈的过程。
场景 A:清晰的典型病例(比如明显的 DR)
NLL 说: “快看!这里有出血点!快把 DR 的证据加到 100!” -> 这一项会急剧下降,收益很高。
KL 说: “不行,你要保持无知,证据要归零!” -> 这一项会上升(因为偏离了均匀分布)。
结果: 因为 NLL 降低带来的收益远远大于 KL 增加带来的惩罚(因为证据是真实存在的),所以模型最终会输出:高证据,低不确定性。
场景 B:奇怪的脏数据(比如全是噪点的图,或者一张飞机的图)
NLL 说: “额…我看不到什么出血点,但我得瞎猜一个类来降低损失…” -> 即使瞎猜,NLL 下降得也很勉强,收益不高。
KL 说: “别瞎猜!既然没看清,就给我退回到均匀分布!”
结果: 既然 NLL 赚不到什么便宜,KL 的惩罚就占了上风。模型会倾向于不产生任何证据。
最终输出: 所有类别的证据都接近 0 -> 极高的不确定性。
论文中对于 KL 散度正则项的系数 λ\lambdaλ(在文中也称为 KL Coef 或 adaptive evidence coefficient λe\lambda_eλe),主要取值为 5×10−35 \times 10^{-3}5×10−3(即 0.005)。
3.3 目标分布 Beta 时,为什么是全 1 而不是全 0?
在狄利克雷分布中,全 1 代表“完全无知”(Zero Evidence),而全 0 在数学上是未定义的(非法值)。
证据与参数的关系:在证据深度学习(EDL)中,狄利克雷分布的参数 α\alphaα 与模型输出的“证据” eee 的关系是:
αk=ek+1\alpha_k = e_k + 1αk=ek+1
eke_kek (Evidence):模型在特征图中找到的支持第 kkk 类的证据量,必须 ≥0\ge 0≥0。
完全无知状态:意味着模型什么证据都没找到,即 ek=0e_k = 0ek=0。代入公式 αk=0+1=1\alpha_k = 0 + 1 = 1αk=0+1=1。所以,目标分布(代表完全不确定)的参数应该是 α=[1,1,...,1]\alpha = [1, 1, ..., 1]α=[1,1,...,1]。
全 1 的几何意义(均匀分布):
狄利克雷分布 Dir(α)Dir(\alpha)Dir(α) 描述的是“概率分布的分布”。当 α=[1,1,...,1]\alpha = [1, 1, ..., 1]α=[1,1,...,1] 时,它是一个单纯形上的均匀分布 (Uniform Distribution)。这意味着“它是第1类的概率”、“它是第2类的概率”…这种可能性是均等的。这正是我们想要的“正则化目标”:如果没证据,就不要偏向任何一类。
全 0 的数学禁区:狄利克雷分布的概率密度函数包含 Γ(αk)\Gamma(\alpha_k)Γ(αk)(伽马函数)。Γ(n)=(n−1)!\Gamma(n) = (n-1)!Γ(n)=(n−1)!。如果设为全 0,即 αk=0\alpha_k = 0αk=0,那么需要计算 Γ(0)\Gamma(0)Γ(0)。Γ(0)\Gamma(0)Γ(0) 是趋于无穷大的(未定义)。 因此,狄利克雷分布的参数必须严格大于 0。
3.4 HaCModule 和残差块 (Residual Block) 有什么区别和联系?
想说个人理解:HaCModule 可以被看作是一个“动态的、自适应的”残差块。
它们的数学形式非常相似,都使用了 跳跃连接 (Skip Connection):
普通残差块 (ResNet): y=x+F(x)y = x + F(x)y=x+F(x),这里的 F(x)F(x)F(x) 通常是卷积层。
HaCModule:y=x+α⊙(Fadapt(x)−x)y = x + \alpha \odot (F_{adapt}(x) - x)y=x+α⊙(Fadapt(x)−x),或者简化看做y=x+Residual_Termy = x + \text{Residual\_Term}y=x+Residual_Term
它们的共同点在于都允许原始信息无损通过,只学习“需要调整的部分”(残差),这有助于梯度传播和深层网络训练。核心区别在于**“静态 vs 动态”** 以及 “变换 vs 调制”。我用个表格对比一下:
| 特性 | 普通残差块 (ResNet Block) | HaCModule (超适应调节) |
|---|---|---|
| 权重性质 | 静态 (Static) | 动态 (Dynamic) |
| 权重来源 | 训练好的固定参数(卷积核 WWW)。无论输入什么图片,卷积核 WWW 都是不变的。 | 由超网络生成。输入图片不同 -> 生成的 γ,β\gamma, \betaγ,β 就不同。它是“看人下菜碟”。 |
| 操作类型 | 卷积 (Convolution)。主要关注空间上的特征提取。 | 调制 (Modulation / FiLM)。对特征通道进行缩放和平移(Scale & Shift)。 |
| 作用域 | 局部感受野。 | 全局上下文(利用 Global Pooling 得到的 zzz 来控制)。 |
| 目的 | 提取更深层的特征。 | 校准/适应特征。解决域偏移问题(比如针对模糊图片,自动放大某些边缘特征的权重)。 |
| 公式对比 | y=x+Conv(x)y = x + \text{Conv}(x)y=x+Conv(x) | y=x+Gate(x)⋅(γ(x)⋅x+β(x)−x)y = x + \text{Gate}(x) \cdot (\gamma(x) \cdot x + \beta(x) - x)y=x+Gate(x)⋅(γ(x)⋅x+β(x)−x) |
通俗的说:残差块 就像一副 “近视眼镜”。镜片的度数(权重)是配好固定的,不管你看书还是看电影,镜片度数不会变。HaCModule 就像人眼的 “晶状体”(或者相机的自动对焦)。当你看到不同的东西(输入 zzz 变化),肌肉会推动晶状体改变形状(生成 γ,β\gamma, \betaγ,β 参数),实时调整焦距,让你看得更清楚。
3.5 为什么选择狄利克雷分布?
先解释一下什么是狄利克雷分布 (Dirichlet Distribution)?你可以把它理解为 “概率的概率”。对于普通分类器 (Softmax)会输出一个固定的概率向量,例如 [0.8, 0.2]。它告诉你“我认为是 A 的概率是 80%”。对于狄利克雷分类器 (EDL) 输出的是一个分布。它可能会说:“我认为概率向量可能是 [0.8, 0.2],也可能是 [0.7, 0.3],但肯定不是 [0.1, 0.9]”。
如果分布很尖锐(集中),说明模型很确定。
如果分布很平坦(铺开),说明模型很不确定。
为什么要选择它? 因为它与多分类分布 (Categorical Distribution) 是共轭先验(Conjugate Prior)关系。这使得我们可以直接将神经网络输出的“证据”映射到概率空间的密度上,非常适合用来建模认知不确定性 (Epistemic Uncertainty)。
4.代码实现
下面的代码我实现了HaC和RAP,由于论文未开源代码,这里仅供学习探讨,不确保与作者原始意图完全对齐。
import torch
import torch.nn as nn
import torch.nn.functional as F
# 超适应调节模块 (HaC)
class HaCModule(nn.Module):
"""
HaC: Hyper-adaptive Conditioning Module
对应论文中的公式 (4)-(7) 和 (10) [cite: 13, 203, 246]
"""
# in_channels为输入特征通道数,hidden_dim为超网络隐藏层维度
def __init__(self, in_channels, reduction_ratio=4, hidden_dim=64):
super(HaCModule, self).__init__()
# 保存输入通道数
self.in_channels = in_channels
# 1. 全局描述符提取 (Global Descriptor)
# 对应论文中的 z = GAP(X),使用自适应平均池化将特征图空间维度变为 1x1
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# 2. 超网络 (HyperNetwork)
# 用于生成参数 gamma (scale), beta (shift), alpha (gate)
# 结构设计参考了 FiLM 和 SE-Block 的轻量化设计思路
# 共享的特征提取层 (MLP),用于从全局特征 z 中提取高层语义信息
self.shared_mlp = nn.Sequential(
# 线性层:将维度映射到 hidden_dim
nn.Linear(in_channels, hidden_dim),
# 层归一化:稳定训练
nn.LayerNorm(hidden_dim),
# GELU激活函数
nn.GELU(),
# 第二层线性变换
nn.Linear(hidden_dim, hidden_dim),
# 层归一化
nn.LayerNorm(hidden_dim),
# GELU激活函数
nn.GELU()
)
# 分支 1: 生成 Gamma (Scale) 和 Beta (Shift)
# 输出维度为 2倍输入通道数,之后会被拆分
self.gamma_beta_head = nn.Linear(hidden_dim, in_channels * 2)
# 分支 2: 生成 Alpha (Gate)
self.alpha_head = nn.Sequential(
# 线性映射回原通道数
nn.Linear(hidden_dim, in_channels),
# Sigmoid 函数确保门控系数 alpha 在 [0, 1] 之间
nn.Sigmoid() # 门控系数需要在 [0, 1] 之间
)
# 前向传播逻辑
def forward(self, x):
"""
Input: x [B, C, H, W]
Output: out [B, C, H, W]
"""
# 获取输入张量的 batch, channel, height, width
b, c, h, w = x.size()
# 1. 提取全局特征 z: [B, C]
# 先池化得到 [B, C, 1, 1],再 view 成 [B, C]
z = self.avg_pool(x).view(b, c)
# 2. 通过超网络生成参数
# 得到共享特征表示
features = self.shared_mlp(z)
# 生成 gamma 和 beta: [B, 2*C] -> [B, C], [B, C]
# 通过分支1网络
params = self.gamma_beta_head(features)
# 将结果沿通道维度切分为 gamma 和 beta
gamma, beta = torch.split(params, self.in_channels, dim=1)
# 生成 alpha (Gate): [B, C]
# 通过分支2网络
alpha = self.alpha_head(features)
# 3. 调整维度以便进行广播 (Broadcasting)
# 将参数形状调整为 [B, C, 1, 1] 以匹配特征图 x 的形状
gamma = gamma.view(b, c, 1, 1)
beta = beta.view(b, c, 1, 1)
alpha = alpha.view(b, c, 1, 1)
# 4. 特征调制 (Feature Modulation)
# Formula (10/15): X_out = X + alpha * ((gamma * X + beta) - X) [cite: 233, 247]
# 注意:这里模拟了论文中提到的残差与门控结合的机制
# 对输入特征 x 进行仿射变换 (FiLM 操作)
x_modulated = x * (1 + gamma) + beta # 或者是 x * gamma + beta,取决于具体实现,通常 gamma 初始化为 0 或 1
# 最终融合:原始特征 + 门控系数 * (调制特征 - 原始特征)
# 这种残差连接方式能保证训练初期的稳定性
out = x + alpha * (x_modulated - x)
# 返回调节后的特征图
return out
# 定义可靠性感知预测头 (RaP)
class RaPHead(nn.Module):
"""
RaP: Reliability-aware Prediction Head
基于证据深度学习 (Evidential Deep Learning)
对应论文公式 (8) 和 (11)
"""
# 初始化,in_features为输入特征维度,num_classes为分类类别数
def __init__(self, in_features, num_classes):
super(RaPHead, self).__init__()
# 定义最后的线性分类层
self.linear = nn.Linear(in_features, num_classes)
# 前向传播
def forward(self, x):
# 假设输入 x 已经是展平后的向量 [B, in_features]
# 计算 Logits
logits = self.linear(x)
# 核心:使用 Softplus 替代 Softmax
# 确保输出的证据量 (Evidence e) 是非负数
evidence = F.softplus(logits)
# Dirichlet parameters alpha = e + 1
# 计算狄利克雷分布的参数 alpha
alpha = evidence + 1
# 返回 alpha 用于后续计算损失或推理
return alpha
# 定义证据深度学习损失函数
class EDLLoss(nn.Module):
"""
证据深度学习损失函数 (Evidential Deep Learning Loss)
Loss = L_NLL + lambda * L_KL
对应论文公式 (9)
"""
# 初始化,annealing_step 用于控制 KL 散度权重的退火过程
def __init__(self, num_classes, annealing_step=10):
super(EDLLoss, self).__init__()
self.num_classes = num_classes
self.annealing_step = annealing_step # KL 散度退火步数
# 计算 KL 散度的辅助函数
def kl_divergence(self, alpha):
# 计算 Dirichlet(alpha) 与 Uniform Dirichlet(1) 之间的 KL 散度
# 构造目标分布 Beta (即全为1的均匀分布)
beta = torch.ones([1, self.num_classes], dtype=torch.float32, device=alpha.device)
# 计算 alpha 的和
S_alpha = torch.sum(alpha, dim=1, keepdim=True)
# 计算 beta 的和
S_beta = torch.sum(beta, dim=1, keepdim=True)
# 下面是狄利克雷分布间 KL 散度的数学公式实现
lnB = torch.lgamma(S_alpha) - torch.sum(torch.lgamma(alpha), dim=1, keepdim=True)
lnB_uni = torch.sum(torch.lgamma(beta), dim=1, keepdim=True) - torch.lgamma(S_beta)
dg0 = torch.digamma(S_alpha)
dg1 = torch.digamma(alpha)
kl = lnB + lnB_uni + torch.sum((alpha - beta) * (dg1 - dg0), dim=1, keepdim=True)
return kl
# 损失计算前向传播
def forward(self, alpha, target, epoch_num=None):
"""
alpha: [B, K] - 模型输出的狄利克雷参数
target: [B] - 真实标签 (LongTensor)
epoch_num: 当前 epoch 数,用于调节 KL 权重 (annealing)
"""
# 将 target 转为 One-hot 编码: [B, K]
y = F.one_hot(target, num_classes=self.num_classes).float()
# 计算总证据强度 S (S = sum(alpha_k))
S = torch.sum(alpha, dim=1, keepdim=True)
# 1. 负对数似然损失 (Type 2 Maximum Likelihood / Bayes Risk)
# L_NLL = sum( y_k * (log(S) - log(alpha_k)) ),让模型尽可能拟合正确标签的证据
nll_loss = torch.sum(y * (torch.log(S) - torch.log(alpha)), dim=1, keepdim=True)
# 2. KL 散度正则化
# 强迫那些没见过样本的分布趋向于均匀分布 (即不确定性最大化)
kl_loss = self.kl_divergence(alpha)
# 3. 动态调整 KL 权重 (Annealing)
# 避免训练初期模型就过度关注不确定性而无法收敛
if epoch_num is not None:
# 随着 epoch 增加,系数从 0 逐渐增加到 1
annealing_coef = min(1.0, epoch_num / self.annealing_step)
else:
annealing_coef = 1.0 # 默认全权重
# 论文中提到 lambda_e 在 [1e-4, 1e-2] 之间,这里我们可以作为外部参数传入
# 为了演示,我们直接返回加权和:NLL损失 + 退火系数 * KL正则项
total_loss = torch.mean(nll_loss + annealing_coef * kl_loss)
return total_loss
这里为方便快速测试,我集成到restnet上:
# 集成了 CLEAR 框架 (HaC + RaP) 的 ResNet 模型
class CLEAR_ResNet(nn.Module):
def __init__(self, num_classes=43):
super(CLEAR_ResNet, self).__init__()
# 1. 假设我们用一个 ResNet 作为 Backbone
from torchvision.models import resnet18
# 加载 ResNet18,不使用预训练权重
backbone = resnet18(pretrained=False)
# 去掉原始的全连接层和最后两层 (Pooling 和 FC)
self.features = nn.Sequential(*list(backbone.children())[:-2])
# ResNet18最后输出 512 通道
# [cite_start]2. 插入 HaC 模块 [cite: 244]
# 放置在特征提取器之后,参数聚合之前
self.hac = HaCModule(in_channels=512, hidden_dim=64)
# 全局池化 (HaC输出后还需要池化才能进全连接,或者在HaC内部处理)
# 论文中 HaC 是插在 Backbone 最后的特征图上的
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
# 3. 替换为 RaP Head
# 替换原有的普通线性层,输出 alpha 而不是 logits
self.rap_head = RaPHead(in_features=512, num_classes=num_classes)
# 模型前向传播
def forward(self, x):
# Backbone 特征提取,输出 [B, 512, H, W]
x = self.features(x) # [B, 512, H, W]
# HaC 自适应调节,输出 [B, 512, H, W]
x = self.hac(x) # [B, 512, H, W]
# 池化操作,输出 [B, 512, 1, 1]
x = self.avgpool(x) # [B, 512, 1, 1]
# 展平为向量 [B, 512]
x = torch.flatten(x, 1)
# RaP 预测,输出狄利克雷参数 alpha [B, num_classes]
alpha = self.rap_head(x) # 输出狄利克雷参数 alpha
return alpha
if __name__ == "__main__":
# 初始化模型,假设有 10 个类别
model = CLEAR_ResNet(num_classes=10)
# 初始化损失函数,设置退火步数为 10
criterion = EDLLoss(num_classes=10, annealing_step=10)
# 模拟输入数据:Batch size=4, 3通道, 224x224
inputs = torch.randn(4, 3, 224, 224)
# 模拟真实标签
targets = torch.tensor([1, 0, 9, 2]) # 真实标签
# 前向传播,获取 alpha
alpha = model(inputs)
# 打印模型输出
print(f"Model Output (Alpha): \n{alpha.detach().numpy()}")
# 计算预测概率和不确定性
# 计算总证据 S
S = torch.sum(alpha, dim=1, keepdim=True)
# 预测概率 = alpha / S
probs = alpha / S # 预测概率
# 粗略的不确定性 = K / S
uncertainty = 10 / S # 粗略的不确定性 (K/S)
# 打印预测结果
print(f"Predicted Probs: \n{probs.detach().numpy()}")
print(f"Uncertainty: \n{uncertainty.detach().numpy()}")
# 计算损失,假设当前是第 1 个 epoch
loss = criterion(alpha, targets, epoch_num=1)
# 打印损失值
print(f"Loss: {loss.item()}")
上面需要解释的是KL 散度代码实现了什么公式,可能会有人困惑。代码实现的是 两个狄利克雷分布之间的 KL 散度解析解(Closed-form solution)。
我们要计算模型预测分布 Dir(α)Dir(\alpha)Dir(α) 和目标均匀分布 Dir(β)Dir(\beta)Dir(β)(其中 β=[1,1...1]\beta=[1,1...1]β=[1,1...1])之间的距离:
KL(Dir(α)∣∣Dir(β))=lnB(β)B(α)⏟Log Beta Function项+∑k=1K(αk−βk)(ψ(αk)−ψ(∑j=1Kαj))⏟Digamma项KL(Dir(\alpha) || Dir(\beta)) = \underbrace{\ln \frac{B(\beta)}{B(\alpha)}}_{\text{Log Beta Function项}} + \underbrace{\sum_{k=1}^K (\alpha_k - \beta_k) (\psi(\alpha_k) - \psi(\sum_{j=1}^K \alpha_j))}_{\text{Digamma项}}KL(Dir(α)∣∣Dir(β))=Log Beta Function项 lnB(α)B(β)+Digamma项 k=1∑K(αk−βk)(ψ(αk)−ψ(j=1∑Kαj))
其中:
- B(α)B(\alpha)B(α) 是多元 Beta 函数:B(α)=∏Γ(αk)Γ(∑αk)B(\alpha) = \frac{\prod \Gamma(\alpha_k)}{\Gamma(\sum \alpha_k)}B(α)=Γ(∑αk)∏Γ(αk)
- ψ(⋅)\psi(\cdot)ψ(⋅) 是 Digamma 函数(代码中的
torch.digamma)。
上面的代码我再摘出来详细注释一下:
# S_alpha 是 sum(alpha), S_beta 是 sum(beta)
# 1. 计算 -ln(B(alpha))
# ln(B(alpha)) = sum(lgamma(alpha_k)) - lgamma(S_alpha)
# 所以下面的代码其实计算的是 -ln(B(alpha)) 的一部分
lnB = torch.lgamma(S_alpha) - torch.sum(torch.lgamma(alpha), dim=1, keepdim=True)
# 2. 计算 ln(B(beta))
# 对应公式中的第一项分子部分
lnB_uni = torch.sum(torch.lgamma(beta), dim=1, keepdim=True) - torch.lgamma(S_beta)
# 3. 计算 Digamma 项
# formula: sum( (alpha - beta) * (digamma(alpha) - digamma(S_alpha)) )
dg0 = torch.digamma(S_alpha) # psi(sum(alpha))
dg1 = torch.digamma(alpha) # psi(alpha_k)
# 4. 组合所有项
# KL = ln(B(beta)) - ln(B(alpha)) + sum(...)
# 注意:代码中的 lnB 变量其实存的是 -ln(B(alpha)),所以这里直接相加
kl = lnB + lnB_uni + torch.sum((alpha - beta) * (dg1 - dg0), dim=1, keepdim=True)
这段代码不是近似计算,而是精确地写出了两个分布差异的代数表达式。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 16
16 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)