【ComfyUI】SD1.5 + ControlNet 姿态搭配线稿融合动漫转真人
本文介绍了一套基于ComfyUI的动漫转真人图像风格反推工作流,通过自动化提取动漫人物特征并生成关键词,结合大模型引导生成高真实感人像。核心流程包括图像加载、关键词反推(WD14Tagger模型)、姿态识别(ControlNet)、Prompt编码(CLIPTextEncode)及高清生成(KSampler+IterativeUpscale),支持稳定输出符合现实美学的图像。系统模块化设计涵盖语义
今天给大家演示一个动漫转真人图像风格反推工作流,通过ComfyUI实现从动漫人物图像中自动识别人物特征、反推关键词,并生成逼真人影像。
本工作流不仅支持对已有图像进行反向分析生成提示词,还结合了大模型进行条件引导,最后输出高质量、真实风格的人物图像。通过深度利用VAE、ControlNet与高效放大流程,用户可以轻松将二次元形象转化为符合现实美学的人像内容。整个流程自动化程度高,输出稳定,适用于创作者、Cos设计、角色建模等多种场景。

文章目录
工作流介绍
本工作流名为「动漫转真人 反推关键词人影像生成」,核心目的是将动漫人物图像进行反向关键词提取,并结合这些提示词,引导大模型生成具有真实感的人像。工作流起始于图片加载与分析,通过Tagger模型获取语义信息,配合图像处理(如姿态识别、边缘线提取、分割等),生成关键词,再利用Prompt和ControlNet进行图像引导。
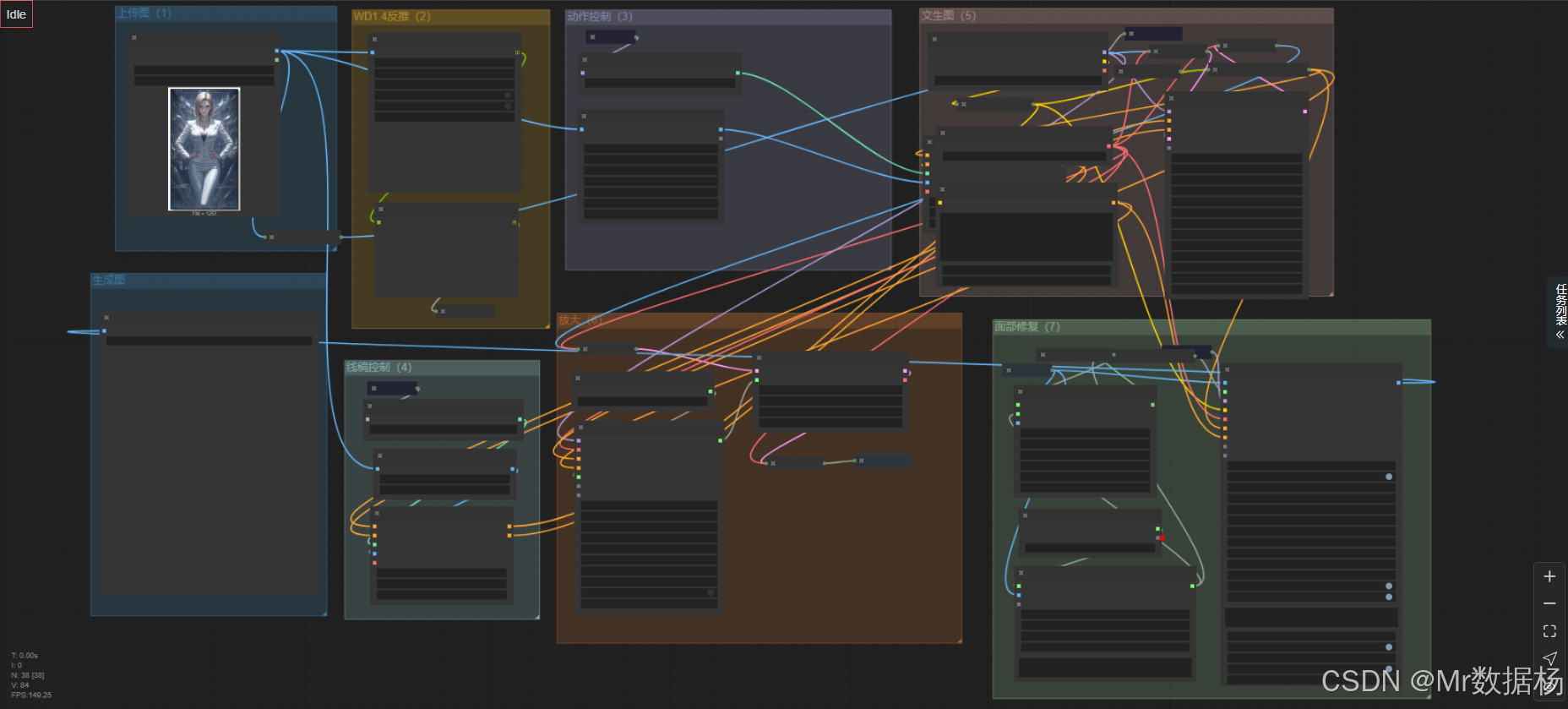
整个过程中融合了深度学习VAE模型进行图像解码与编码,同时搭配KSampler完成采样和细节渲染,实现动漫到真人的高质量风格迁移。
核心模型
本工作流依赖多个核心模型来实现从动漫图像中提取特征再到图像生成的全过程。首先使用 wd-v1-4-moat-tagger-v2 模型提取图像的语义标签作为关键词,再通过 control_v11p_sd15_openpose_fp16.safetensors 引导姿态识别。最终的图像生成依赖 Stable Diffusion 主模型以及可选的放大模型处理细节,还包括用于视觉感知的 CLIP 模型。所有模型协同工作,共同提升了输出图像的真实性与一致性。
| 模型名称 | 说明 |
|---|---|
| wd-v1-4-moat-tagger-v2 | 图像反推关键词识别模型,提取Prompt提示词 |
| control_v11p_sd15_openpose_fp16.safetensors | ControlNet的OpenPose模型,用于识别并引导人物姿态 |
| vae-ft-mse-840000-ema-pruned.safetensors | 图像VAE解码器,提升图像细节与稳定性 |
| Stable Diffusion 模型 | 文生图主力模型,用于生成最终图像 |
| sam_vit_b_01ec64.pth | SAM分割模型,用于图像区域精细分割辅助ControlNet控制 |
Node节点
工作流使用的节点多样,涵盖了图像加载、图像处理、Prompt生成、ControlNet控制、模型加载与采样、图像放大等多个环节。通过 Set/Get 系列节点对关键数据进行缓存与调用,使整个流程逻辑清晰,效率更高。重点节点如 WD14Tagger 用于关键词反推、BNK_CLIPTextEncodeAdvanced 负责文本编码、ControlNetApplyAdvanced 控制图像生成姿态,而 IterativeLatentUpscale 则用于高分辨率增强。
| 节点名称 | 说明 |
|---|---|
| LoadImage | 加载输入图像 |
| WD14Tagger | 动漫图像标签提取,生成关键词提示词 |
| BNK_CLIPTextEncodeAdvanced | 将文本关键词编码为正向/负向Prompt向量 |
| ControlNetApplyAdvanced | 应用姿态引导与ControlNet控制图像生成走向 |
| KSampler //Inspire | 采样器,负责生成图像的核心采样过程 |
| IterativeLatentUpscale | 对生成图像进行逐步高质量放大 |
| VAEEncode / VAEDecode | 负责图像与潜变量间的转换 |
| SAMDetectorCombined / ImpactSegsAndMask | 结合分割模型对图像区域进行精细控制 |
工作流程
整个动漫转真人工作流由多个阶段组成,从图像载入、特征分析、关键词反推、姿态识别,到最终的图像生成与高分辨率放大,构成了一个闭环的、高度自动化的人像转换系统。
首先,输入图像通过 LoadImage 节点读取,进入 WD14Tagger 模型反推出提示关键词。这些关键词随后传入文本编码器 BNK_CLIPTextEncodeAdvanced,构建正向和负向的Prompt条件。同时,图像本身还被送入 DWPreprocessor、LineArtPreprocessor、SAMDetectorCombined 等节点处理,以提取姿态、边缘线稿和语义分割区域,为后续ControlNet控制打基础。
生成阶段由 ControlNetApplyAdvanced 节点结合图像控制条件和Prompt共同驱动 KSampler 生成潜变量图像,随后通过 VAEDecode 解码成最终图像。若需要提升输出质量,则接入 IterativeLatentUpscale 实现高清放大。
整套流程自动衔接,最大程度减少人工干预,且每一步均以模块化方式组织,可按需调整替换。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 图像输入 | 载入用户上传的动漫人物图像 | LoadImage |
| 2 | 特征提取 | 使用 Tagger 模型分析图像内容,提取关键词 | WD14Tagger |
| 3 | 姿态与区域识别 | 提取人物姿态、边缘、面部、手等语义信息 | DWPreprocessor、LineArtPreprocessor、SAMDetectorCombined |
| 4 | Prompt构建 | 利用关键词构造文本向量,用于生成控制 | BNK_CLIPTextEncodeAdvanced |
| 5 | ControlNet控制 | 应用姿态、区域引导,融合Prompt条件进行图像引导生成 | ControlNetApplyAdvanced |
| 6 | 图像采样 | 结合模型、Prompt与条件,完成初始图像采样 | KSampler //Inspire |
| 7 | 图像解码 | 将潜变量解码为清晰图像 | VAEDecode |
| 8 | 高清放大 | 对生成图像进行多轮次高分辨率放大 | IterativeLatentUpscale |
大模型应用
BNK_CLIPTextEncodeAdvanced 反推关键词语义编码
该节点接收由识别器反推得到的关键词文本,并将其编码为完整的语义向量。它不负责图像结构推理,只专注于将自动生成的关键词转成模型可理解的语义条件。反推关键词提供了对原图内容的再描述,因此 Prompt 会直接影响生成时的风格、主体范围与细节走向。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| BNK_CLIPTextEncodeAdvanced | Prompt 文本: 由 WD14Tagger 反推出的关键词串,通过 ShowText → SetNode → GetNode 输入(例如:1girl, long hair, smile, …) Negative 配置: weight_interpretation: A1111 token_normalization: none |
将反推出的关键词编码为主语义,用于还原原图内容并指导真实风格生成。 |
CLIPTextEncodeA1111(负向广域语义) 错误结构压制核心
该节点用于输入极长的负向 Prompt 清单。这些文字的全部作用是帮助模型压制错误肢体、扭曲结构、错误遮挡、低质量瑕疵,确保写实生成稳定干净。它不参与正向风格,只负责把负向提示转成语义向量,强力影响生成质量。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| CLIPTextEncodeA1111 | Negative Prompt: 包含完整极长负向串,如: lowres,bad anatomy,bad hands,text,error,(missing fingers:1.1),extra digit,fewer digits, …(共数百条) |
负责将长负向文本变成语义编码,用来压制畸形、错误肢体、低质量、结构混乱等问题,是画面稳定的关键语义来源。 |
WD14Tagger 自动标签语义来源
虽然它不是文本编码器,但它负责生成“反推关键词”的文本来源,并通过后续节点输送到 BNK_CLIPTextEncodeAdvanced。它的文本不是用户输入,而是模型自动分析图像后得到的语义标签,由 Prompt 编码器最终转成可控语义。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| WD14Tagger | 自动生成标签: 例如:1girl, black hair, jacket, outdoors, smile … (实际标签由原图特征决定) |
作为大模型语义的源头,自动生成关键词,通过编码节点影响最终生成方向。 |
使用方法
整个工作流通过“反推关键词”方式,把用户输入的动漫图自动解析为文本标签,再将这些标签编码成语义,用来生成写实人像。用户替换图片后,系统会自动完成加载图像、提取标签、关键词展示、关键词编码、姿态提取、线稿生成、深度分析与最终图像生成。
角色图是主体来源,反推关键词是语义核心,Prompt 控制生成的写实方向与细节,ControlNet 则保持结构稳定。用户不需要自己写 Prompt,只需上传图像即可自动生成人物的写实影像。
| 注意点 | 说明 |
|---|---|
| 反推标签由 WD14 决定 | 图片越清晰,关键词越准确 |
| 负向 Prompt 不要删减 | 该清单用于稳定结构与防畸形 |
| 输入图尽量主体明确 | 自动反推的标签会更聚焦 |
| 姿态、线稿、深度会自动生成 | 只要给图,系统即可推理结构 |
| 不需要手写正向 Prompt | 反推关键词会自动作为语义来源 |
| 替换图片即可重新生成 | 工作流自动执行无需手动调整 |
应用场景
该工作流广泛适用于动漫角色风格迁移、真人拟像设计、二次元Cos设定图生成、IP人物原画拟真等多个领域。尤其适合内容创作者、概念设定师、AI图像工作者、社交媒体运营等需要从“设定形象”向“写实展示”转化的场景。
例如,创作者可上传一张风格独特的动漫人物图,通过系统自动提取关键词并反向生成真人形象图像。也可将该流程嵌入到Cosplay选角辅助系统中,用于评估哪位真人最适合扮演某个动漫角色,或者进行AI造型推荐。
在社交媒体场景下,用户可将自己的角色设定头像通过本工作流生成对应的真实形象图,用作头像、封面或角色衍生内容,增强粉丝互动与视觉冲击力。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 动漫拟人化生成 | 将动漫角色图像转换为真实人类形象 | 插画师、原画师 | 动漫角色 + 真人形象对比图 | 快速拟真 + 提取关键词提示词 |
| Cosplay辅助 | 根据角色图像反推出关键词,筛选适配演员 | 选角导演、Cos博主 | 人设关键词 + 真人拟像图 | 自动关键词匹配 + 可视化输出 |
| 社交头像生成 | 用于社交媒体、短视频平台角色头像生成 | 虚拟主播、社媒用户 | 个性设定图像 + 真实头像图 | AI建模与写实风格合成 |
| AIGC创作辅助 | 为AI图像创作提供Prompt关键词参考与视觉基准 | AIGC从业者 | Prompt反推结果 + 成品对照图 | 快速生成素材 + 图文结合 |
| 设定写实化 | 将2D设定转化为可视化写实形象参考 | 编剧、策划、美术 | 设定图 + 写实图像 | 写实风格美术参考图自动生成 |
开发与应用
更多 AIGC 与 ComfyUI工作流 相关研究学习内容请查阅:
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境开发,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和使用

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 1
1 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)