身份与访问:行为生物识别(按键习惯、移动轨迹)的 AI 建模
这种审视不再依赖于用户“记得什么”(容易被窃取的静态知识),而是依赖于用户“是如何操作的”(难以模仿的动态行为)。强迫模型学习更深层的、难以伪造的特征(如手指按压屏幕时的微观电容变化纹理,这是脚本无法模拟的)。的思路,将用户的击键序列视为一种“语言”,利用 Masked Language Model (MLM) 预训练任务,让模型学习用户行为的深层语法。当你在手机屏幕上滑动(Swipe)或点击(T
身份与访问:行为生物识别(按键习惯、移动轨迹)的 AI 建模
你好,我是陈涉川,本文是从“静态防御”迈向“零信任(Zero Trust)”的关键一步。我们不再仅仅验证“你有把钥匙”,而是要验证“你走路的姿势”、“你敲门的节奏”。而今密码已死,令牌(Token)亦非万能。在零信任架构(Zero Trust Architecture)日益普及的今天,传统的“一次性认证”已无法满足安全需求。一旦攻击者通过钓鱼或凭证窃取通过了登录关卡,整个内网便如入无人之境。
本章将探讨 持续认证(Continuous Authentication) 的核心技术——行为生物识别。我们将深入挖掘人类操作设备的微观特征:按键的飞行时间、鼠标移动的曲率与加速度、甚至是手机陀螺仪捕捉到的步态震动。我们将展示如何利用 RNN/LSTM 处理时序击键数据,以及如何利用 CNN 处理鼠标轨迹图像,构建一个难以伪造的数字指纹,让黑客即便盗取了你的密码,也因无法‘模仿’你的行为特征而被拒之门外。
引言:由于信任的崩塌,我们必须重塑感知的边界
在传统的网络安全模型中,我们习惯于构建高耸的城墙——防火墙、VPN、复杂的密码策略。我们假设,只要有人能出示正确的“通行证”(密码或令牌),他就是值得信任的“内部人员”。然而,在 APT(高级持续性威胁)和社工攻击泛滥的今天,这种基于边界的防御已然失效。一旦黑客通过钓鱼邮件骗取了凭证,或者买通了内鬼,那扇厚重的城墙便形同虚设,内网核心数据对于攻击者而言,如同探囊取物。
零信任(Zero Trust)架构的提出,标志着安全理念的根本性转移:“永不信任,始终验证”。但问题随之而来——如果每访问一个文件都要用户输入一次密码,业务效率将荡然无存。
这就是 持续认证(Continuous Authentication) 登场的舞台。我们需要一种技术,能在用户毫无察觉的情况下,像贴身保镖一样,每分每秒都在审视操作者的真实身份。这种审视不再依赖于用户“记得什么”(容易被窃取的静态知识),而是依赖于用户“是如何操作的”(难以模仿的动态行为)。
本文将带你进入**行为生物识别(Behavioral Biometrics)**的微观世界。我们将解构那些被你忽视的潜意识动作——手指在键盘上的飞行节奏、鼠标划过屏幕的微颤轨迹、甚至是走路时手机感应到的步态韵律。我们将展示如何利用 AI 将这些混沌的生物电信号,转化为不可伪造的数字指纹,为零信任架构补上最关键的一块拼图。
1. 认证的终局:从“你知道什么”到“你是谁”
在网络安全的历史长河中,身份认证(Authentication)始终围绕着三个维度展开:
- Something you know(你知道什么): 密码、PIN 码。
- Something you have(你拥有什么): 手机验证码、硬件 Key、智能卡。
- Something you are(你是什么): 指纹、虹膜、人脸。
然而,这三者都有致命缺陷。密码可以被泄露,硬件可以被盗窃,甚至传统的静态生物特征(指纹)也可以被硅胶指模欺骗。更重要的是,它们都是断点式的——一旦登录成功,系统就默认此后的所有操作均出自同一人之手。
这就是会话劫持(Session Hijacking)和内部威胁得以生存的土壤。
1.1 行为生物识别的崛起
行为生物识别(Behavioral Biometrics) 引入了第四个维度:Something you do(你的行为模式)。
它基于神经科学和肌肉记忆的原理。当你敲击键盘输入 "Hello World" 时,你的手指在大脑运动皮层的指挥下,以一种极具个人特色的节奏舞动。这涉及神经传导速度、肌肉纤维的张力、骨骼长度以及长期的习惯养成。
这种特征具有**隐式(Implicit)和持续(Continuous)**的特性:
- 隐式: 用户无需专门对着摄像头微笑或按压指纹,数据采集在后台静默完成。
- 持续: 系统每秒钟都在重新评估:“现在操作鼠标的人,还是刚才登录的那个人吗?”
1.2 挑战:高噪声与非平稳性
与指纹不同,行为特征是不稳定的。
- 你今天心情不好,打字可能会用力一些。
- 你换了一个机械键盘,按键反馈变了,飞行时间也会变。
- 你受伤了,鼠标移动轨迹会变形。
这就要求我们的 AI 模型不能只是简单的模式匹配,它必须具备泛化能力,能够学习到用户行为流形(Manifold)的本质结构,并能够适应概念漂移(Concept Drift)。
2. 击键动力学(Keystroke Dynamics):指尖的交响曲
击键动力学是最古老也是最成熟的行为识别技术,其历史甚至可以追溯到二战时期的电报员识别(通过发送摩尔斯电码的节奏来分辨发报员)。在现代计算机中,它被极大丰富了。
2.1 特征工程:微观时间的量化
当我们谈论“打字习惯”时,我们实际上是在谈论毫秒级的时间差。我们需要从原始的键盘事件流(Key Press, Key Release)中提取以下核心特征:
- 驻留时间(Dwell Time, DT):
按下某个键到释放该键的时间差。
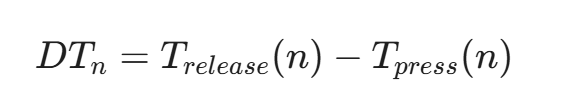
这反映了用户手指的按压力量和习惯。
- 飞行时间(Flight Time, FT):
这是最关键的特征,分为多种类型:
-
- Press-to-Press (P2P / DD): 第 n 个键按下到第 n+1 个键按下的时间。
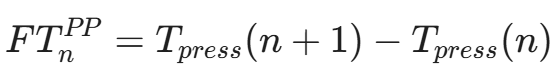
这是衡量打字熟练度的关键指标。熟练用户在打常用词组时,该值往往极小甚至为负(即 Rollover 现象)。
-
- Release-to-Press (R2P / UD): 第 n 个键释放到第 n+1 个键按下的时间。这是手指在空中“飞行”的纯粹时间。
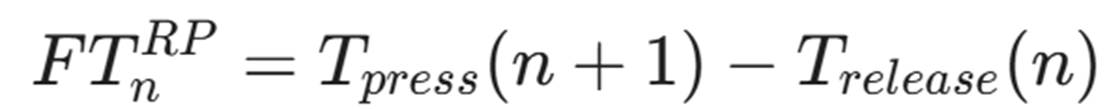
- N-Graph(N元组)特征:
单个键的特征区分度不高,但特定的字母组合(N-graph)极具个人特色。
例如,常见的组合 "th", "er", "ing"。
-
- 用户 A 打 "the" 时,"t" 和 "h" 几乎是连着按的(甚至重叠),但 "h" 到 "e" 会停顿。
- 用户 B 打 "the" 时,三个键的间隔非常均匀。
我们通常提取 Digraphs (二元组) 和 Trigraphs (三元组) 的平均延迟。
- 特殊按键习惯:
- Shift 键的使用: 你是用左 Shift 还是右 Shift?你是先按 Shift 还是先按字母?
- 错误修正模式: 当你打错字时,你是按一次 Backspace 删一个字,还是长按 Backspace,或者是 Ctrl+A 全选删除?这种“犯错后的行为”往往比“正确打字”更具指纹性。
2.2 数据清洗与异常处理
真实世界的击键数据极其脏乱。
- 异常值(Outliers): 用户打字打一半去喝了口水,导致两个键之间的 FT 高达 5000ms。这种数据必须剔除,否则会拉偏均值。
- 处理: 设定阈值(如 FT < 750ms),或者使用**孤立森林(Isolation Forest)**预先清洗。
- 翻转(Rollover)现象: 快速打字者往往在前一个键还没松开时,就按下了下一个键(T_{press}(n+1) < T_{release}(n))。这会导致 FT^{RP} 为负值。这本身就是一个极强的特征,必须保留并单独编码。
3. 算法模型 I:基于统计距离的基线模型
在引入深度学习之前,我们先构建一个基于统计学的基线(Baseline),这在资源受限的端点(如嵌入式设备)上非常有用。
我们为每个用户 u 构建一个特征模板(Profile)。对于高频的二元组(如 'th'),计算其飞行时间的均值(\mu)和标准差(\sigma)。
当新样本 X 进来时,我们通常计算其与模板的标准化距离(类似于简化版的马氏距离,忽略了特征间的协方差):
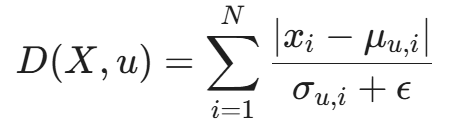
- x_i: 新样本中第 i 个特征的值。
- \mu_{u,i}: 用户模板中该特征的均值。
- \sigma_{u,i}: 用户模板中该特征的标准差(用于归一化,波动大的特征权重降低)。
如果 D(X, u) < \text{Threshold},则认证通过。
这种方法简单、可解释性强,但无法捕捉复杂的时序依赖关系(比如打字节奏的“加速”和“减速”趋势)。
4. 算法模型 II:基于 LSTM 的时序建模
击键数据本质上是时间序列(Time Series)。深度学习中的 RNN(循环神经网络) 及其变体 LSTM(长短期记忆网络) 是处理此类数据的神器。
4.1 为什么选择 LSTM?
- 变长序列处理: 密码长度可能固定,但自由文本(写邮件、聊 Slack)的长度是不固定的。LSTM 可以处理任意长度的输入流。
- 上下文记忆: 用户的打字习惯受上下文影响。打 "password" 中的 "s" 和打 "user" 中的 "s",速度可能不同。LSTM 的隐状态(Hidden State)能记住“我刚才打了什么”。
- 非线性映射: 它可以拟合复杂的非线性关系,比如“疲劳效应”(随着打字时间推移,DT 逐渐变长)。
4.2 网络架构设计
我们要构建的是一个孪生网络(Siamese Network)或者基于Triplet Loss的架构。为什么?因为在认证场景下,我们通常面临 Few-shot Learning(少样本学习) 问题。我们要验证的是“是否匹配”,而不是做一个 1000 分类的分类器。
模型结构:
- 输入层: 形状为 (Batch, Sequence\_Length, Features)。特征包括归一化的 DT, FT, Key_Code。
- 嵌入层(Embedding): 对于 Key_Code(如 'A', 'B', 'Enter'),使用 Embedding 层将其映射为低维向量,捕捉键位之间的空间关系(如 'Q' 和 'W' 在物理上很近)。
- LSTM 层: 双向 LSTM(Bi-LSTM),捕捉前后文依赖。
h_t = \text{LSTM}(x_t, h_{t-1})
- Attention 层: 并非所有的击键都同样重要。空格键、回车键附近的特征往往更稳定。Attention 机制自动给关键击键分配高权重。
- 输出层: 输出一个固定维度的嵌入向量(Embedding Vector),代表该段击键序列的“指纹”。
4.3 损失函数:对比损失(Contrastive Loss)
我们希望同一用户的两次输入,向量距离尽可能近;不同用户的输入,距离尽可能远。
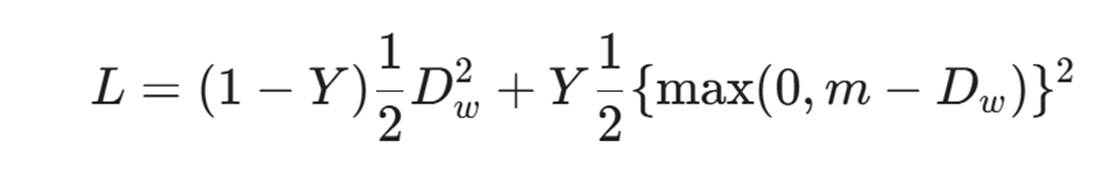
- D_w: 两个样本向量的欧氏距离。
- Y: 标签。如果属于同一用户 Y=0,否则 Y=1。
- m: 边际(Margin)。
4.4 演进:从 LSTM 到 Transformer
虽然 LSTM 是处理时序数据的经典之选,但在处理超长序列(例如:程序员连续输入一整段代码,或撰写长篇文档)时,LSTM 仍面临梯度消失和长距离依赖捕捉能力不足的问题。
近年来,Transformer 架构(即支撑 ChatGPT 的核心技术)开始在行为识别领域崭露头角。
- 全局注意力(Self-Attention): 与 LSTM 只能按顺序“阅读”击键不同,Transformer 可以同时关注序列中的所有击键。它能敏锐地发现:“用户在输入第 100 个字符时的犹豫,其实与第 5 个字符的输入错误有关”。这种全局视野使其在捕捉复杂的上下文依赖(Contextual Dependency)方面表现卓越。
- 并行计算: Transformer 允许并行处理整个序列,在大规模并发认证场景下,其推理效率往往优于串行的 RNN 类模型。
在实际落地中,我们可以借鉴 BERT4Rec 的思路,将用户的击键序列视为一种“语言”,利用 Masked Language Model (MLM) 预训练任务,让模型学习用户行为的深层语法。
5. 鼠标/指针动力学(Mouse Dynamics):数字肢体语言
如果说键盘是节奏,那么鼠标就是轨迹。
鼠标行为包含的信息量远大于键盘,因为它是一个连续的二维(甚至三维)信号。
5.1 鬼影与人类:特征差异
在反欺诈(Anti-Fraud)领域,鼠标动力学常用于区分 Bot(机器人)、RAT(远程控制木马) 和 人类。
- Fitts's Law(菲茨定律):
人类移动鼠标去点击一个目标时,所需时间 T 与目标距离 D 和目标大小 W 有关:
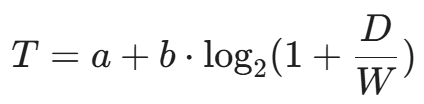
AI 洞察: 人类的移动轨迹符合菲茨定律,且在接近目标时会有明显的减速和微调(Sub-movements)。
Bot 特征: 机械的直线移动,匀速,瞬间停止,没有微调。
- 曲率与抖动(Curvature & Jitter):
人类的手臂运动是弧形的(由肘部或腕部为支点)。
-
- 人类: 轨迹平滑,带有自然的生理抖动(2-5Hz 范围)。
- RAT/脚本: 往往是完美的直线,或者通过贝塞尔曲线拟合但缺乏微观抖动。
- 角速度峰值:
人类在鼠标转弯时,角速度变化具有特定的钟形曲线特征,而脚本往往也是匀速的。
5.2 将轨迹视为图像:基于 CNN 的建模
处理鼠标轨迹的一种创新方法是将其可视化,然后利用计算机视觉技术。
数据转换流程:
- 截取一个时间窗口(如 3 秒)内的鼠标坐标序列 (x_t, y_t)。
- 在二维平面上绘制轨迹。
- 颜色编码(Color Encoding): 利用颜色深浅表示速度(速度越快颜色越浅,停留越久颜色越深/越粗)。
- 方向编码: 利用 RGB 通道表示加速度向量的方向。
这样,一条鼠标轨迹就变成了一张 224 \times 224 的彩色图片。
然后,我们可以直接迁移 ResNet 或 EfficientNet:
- 输入:生成的轨迹热力图(Heatmap)或 轨迹张量。
- 卷积层: 提取“急转弯”、“平滑弧线”、“微颤”等视觉特征。
- 输出: 用户身份概率或 Bot 概率。
这种方法的优势在于 CNN 极强的平移不变性和局部特征提取能力,它能敏锐地捕捉到黑客使用 RAT 工具远程操作时产生的细微延迟和不自然的卡顿。
6. 实战:构建一个击键认证系统(PyTorch 实现)
现在,让我们编写代码。我们将构建一个基于 LSTM 的击键特征提取器。这个模型的目标是将一段击键序列映射为一个 128 维的特征向量。
6.1 数据集准备与 Dataset 类
假设我们的数据格式为 CSV:user_id, key_code, press_time, release_time。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
import pandas as pd
import numpy as np
class KeystrokeDataset(Dataset):
def __init__(self, csv_file, seq_length=50):
"""
seq_length: 每个样本包含的按键数量。
"""
self.data = pd.read_csv(csv_file)
self.seq_length = seq_length
# --- [修复 1] 初始化用户 ID 映射 ---
self.users = self.data['user_id'].unique()
self.user_to_idx = {user: i for i, user in enumerate(self.users)}
# --- [修复 2] 统一处理 Key Code 编码 ---
# 实际项目中应保存并加载固定的 mapping (Char -> Int)
# 这里为了演示方便,如果不存在编码列,则现场生成
if 'key_code_encoded' not in self.data.columns:
# 将字符类型转换为分类类型,再获取编码
self.data['key_code_encoded'] = self.data['key_code'].astype('category').cat.codes
self.samples = []
self._preprocess()
def _preprocess(self):
# 预处理:按用户分组,计算 DT, FT
# 这是一个简化版的预处理,实际工程中需要更复杂的滑动窗口
grouped = self.data.groupby('user_id')
for user_id, group in grouped:
# 确保按时间排序
group = group.sort_values('press_time')
# 计算 Dwell Time (按压保持时间)
dt = group['release_time'] - group['press_time']
# 计算 Flight Time (Press-to-Press 飞行时间)
# diff() 计算当前行与上一行的差值,第一行为 NaN,填充为 0
ft = group['press_time'].diff().fillna(0)
# 归一化 (Z-Score) - 针对该用户的历史数据进行标准化
dt = (dt - dt.mean()) / (dt.std() + 1e-6)
ft = (ft - ft.mean()) / (ft.std() + 1e-6)
# 获取 Key Code
keys = group['key_code_encoded'].values
# 堆叠时间特征 Shape: (N, 2)
features = np.stack([dt.values, ft.values], axis=1)
# 切片生成序列样本
num_samples = len(features) // self.seq_length
for i in range(num_samples):
start = i * self.seq_length
end = start + self.seq_length
seq_features = torch.tensor(features[start:end], dtype=torch.float32)
seq_keys = torch.tensor(keys[start:end], dtype=torch.long)
# 获取该用户的 label index
label = torch.tensor(self.user_to_idx[user_id], dtype=torch.long)
self.samples.append((seq_keys, seq_features, label))
def __len__(self):
return len(self.samples)
def __getitem__(self, idx):
# 返回: (keys_sequence, time_features, label)
return self.samples[idx]6.2 深度 LSTM 模型架构
class DeepKeystrokeNet(nn.Module):
def __init__(self, num_keys, embedding_dim, hidden_dim, output_dim, num_layers=2):
super(DeepKeystrokeNet, self).__init__()
# 1. 键位嵌入层: 将离散的 Key Code 映射为向量
self.key_embedding = nn.Embedding(num_keys, embedding_dim)
# 2. LSTM 层
# 输入维度 = 键位嵌入维度 + 2 (DT, FT)
input_dim = embedding_dim + 2
self.lstm = nn.LSTM(input_dim,
hidden_dim,
num_layers=num_layers,
batch_first=True,
bidirectional=True,
dropout=0.3)
# 3. Attention 机制 (简化版: 学习一个权重向量)
# 双向 LSTM 输出维度是 hidden_dim * 2
self.attention_w = nn.Linear(hidden_dim * 2, 1)
# 4. 全连接输出层
self.fc = nn.Sequential(
nn.Linear(hidden_dim * 2, 128),
nn.ReLU(),
nn.Linear(128, output_dim) # 输出用于分类的 Logits
)
def forward(self, keys, time_features):
# keys shape: (batch, seq_len)
# time_features shape: (batch, seq_len, 2)
# 嵌入
key_emb = self.key_embedding(keys) # (batch, seq_len, embedding_dim)
# 拼接时间特征和键位特征
x = torch.cat([key_emb, time_features], dim=2)
# LSTM 前向传播
lstm_out, (hn, cn) = self.lstm(x)
# lstm_out shape: (batch, seq_len, hidden_dim * 2)
# Attention 计算
# 计算每个时间步的得分
attn_scores = self.attention_w(lstm_out) # (batch, seq_len, 1)
attn_weights = F.softmax(attn_scores, dim=1) # 在 seq_len 维度归一化
# 加权求和 (Context Vector)
context_vector = torch.sum(lstm_out * attn_weights, dim=1) # (batch, hidden_dim * 2)
# 最终分类
logits = self.fc(context_vector)
return logits, context_vector # 返回特征向量供后续验证使用
# 实例化模型
# num_keys=128 (ASCII), embedding_dim=16, hidden_dim=64, output_dim=num_users
model = DeepKeystrokeNet(128, 16, 64, 10).cuda()代码解读
这段代码虽然简洁,但包含了处理异构数据的关键思想:
- 多模态融合: 我们没有直接把 Key Code 丢进 LSTM,也没有只看时间。我们将“按了哪个键”(空间信息/语义信息)和“按了多久”(时间信息)进行了 Early Fusion(早期融合)。这很重要,因为按下 'Enter' 键的 DT 通常比按下 'A' 键要长,如果不结合键位信息,模型可能会误判。
- 注意力机制: 代码中实现了一个简单的 Self-Attention。这让模型能够自动忽略那些充满噪声的按键(比如快速连续的退格),而聚焦于那些最具辨识度的按键序列。
- 双向 LSTM: 人的击键是有预谋的。按下当前键的节奏,不仅受前一个键影响(后效),也受下一个键影响(前瞻,比如为了按下一个键手指在做准备)。Bi-LSTM 完美捕捉了这种双向依赖。
7. 移动端的触觉指纹:当传感器成为神经末梢
智能手机不仅仅是一个通讯工具,它是布满了传感器的精密仪器。相比于 PC 端单一的键鼠输入,移动端提供了更高维度的**多模态(Multi-modal)**数据。
7.1 触摸屏动力学(Touch Dynamics)
当你在手机屏幕上滑动(Swipe)或点击(Tap)时,你留下的不仅仅是操作指令,还有你的手掌大小、手指长度、握持姿势以及肌肉控制能力的特征。
- 接触面积(Touch Area & Pressure):
电容屏不仅能检测坐标 (x, y),还能通过电容变化的强度估算接触面积(Major/Minor Axis)和压力(虽然大部分屏幕没有物理压力感应,但接触面积通常与压力正相关)。
-
- 特征: 男性的大拇指接触面积通常大于女性;单手操作时的接触面形状呈椭圆形,且长轴倾斜角度固定。
- 滑动运动学(Swipe Kinematics):
当我们浏览 TikTok 或 Instagram 时,手指的滑动轨迹遵循特定的物理规律。
-
- 向心力特征: 拇指是以掌心关节为圆心的“圆周运动”。滑动的轨迹不是直线,而是圆弧。
- 速度曲线: 启动(加速) -> 滑行(匀速/减速) -> 抬起(急停)。每个人在这个过程中的加速度变化率(Jerk, 加加速度)是独一无二的。
- 多点触控与握持姿势:
你是左手单手操作,还是右手单手,或者是“左手握持+右手食指点击”?
系统可以通过监测无效触控区(手掌边缘误触屏幕边缘的位置)来推断握持姿势,进而根据姿势调整认证模型的权重(因为不同姿势下的行为特征分布完全不同)。
7.2 传感器融合(Sensor Fusion):步态与震颤
除了屏幕,手机内部的 IMU(惯性测量单元) 提供了另一层维度的验证。
- 陀螺仪(Gyroscope): 测量角速度。当你打字时,手机会随着你的按压产生微小的回弹震动。这种微震动的频率和幅度,与你手腕的刚度(Stiffness)有关。
- 加速度计(Accelerometer): 测量线性加速度。当你走路时拿着手机,手机会记录下你的步态(Gait)。
- 步频(Cadence): 走路的节奏。
- 步幅冲击(Impact): 脚后跟落地时的震动传导到手机的强度。
- 对称性: 左脚迈步和右脚迈步的波形差异。
AI 建模挑战:
这里的核心难点在于坐标系转换。手机在口袋里翻滚,坐标系是混乱的。我们需要使用 四元数(Quaternions) 将手机坐标系下的数据投影到 世界坐标系(World Frame) 或 重力坐标系(Gravity Frame) 中,才能提取稳定的步态特征。
8. 隐私的边界:端侧计算与联邦学习
我们在前文中提到,收集生物特征数据涉及极高的隐私风险。如果云端的“行为特征库”被黑,后果比密码泄露更严重,因为你无法“修改”你的打字习惯。
解决方案只有一个:数据不出域(Data never leaves the device)。
8.1 TinyML:在芯片上运行神经网络
现在的手机芯片(如 Apple A系列、Snapdragon)都集成了 NPU(神经网络处理单元)。这使得我们可以在本地运行轻量级的行为识别模型。
模型压缩技术:
为了将 Part 1 中训练的庞大 LSTM 模型塞进手机,我们需要:
- 量化(Quantization): 将 32 位浮点数(FP32)转换为 8 位整数(INT8)。精度损失极小,但模型体积缩小 4 倍,推理速度提升 3 倍。
- 剪枝(Pruning): 移除神经网络中权重接近于 0 的连接,稀疏化模型。
- 知识蒸馏(Knowledge Distillation): 训练一个小的“学生网络”去模仿大的“教师网络”的输出。
本地认证流程:
手机采集传感器数据 -> 输入本地 TinyML 模型 -> 输出 Score -> 操作系统根据 Score 决定是否通过 FaceID 免密验证。
整个过程没有任何数据上传到服务器。
8.2 联邦学习(Federated Learning)在生物识别中的应用
虽然数据不上传,但我们希望模型能不断进化。比如,所有用户都开始流行使用一种新的输入法布局,如果不更新模型,误识率会上升。
联邦平均(FedAvg)算法流程:
- 下发: 中央服务器将基础模型 M_G 发送给百万台手机。
- 训练: 每台手机利用本地数据 D_i 对模型进行微调(Fine-tuning),得到更新后的权重 W_i。
- 聚合: 手机只上传权重的梯度更新量 \Delta W_i(加密且加噪)。
- 更新: 服务器聚合所有 \Delta W_i,更新 M_G。
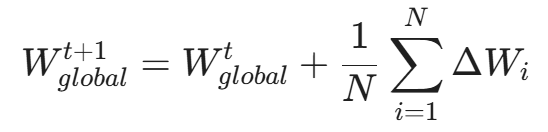
通过这种方式,AI 学会了“全人类的通用打字特征”,而保留了“个体的独特差异”在本地。
合规性提示: 值得注意的是,虽然行为数据是隐式的,但在 GDPR 等法规下,它仍被视为生物特征数据。因此,在企业环境部署时,必须履行‘告知与同意’(Notice and Consent)义务,且不仅要确保数据加密,最好通过 8.1 提到的端侧计算,确保原始特征不出域。
9. 矛与盾的较量:对抗性攻击与防御
如果 AI 能识别你的行为,那么 AI 能模仿你的行为吗?
答案是肯定的。这就是 生成式对抗网络(GAN) 在攻击端的应用。
9.1 生成式攻击(Generative Attacks)
攻击者训练一个 Generator,输入是随机噪声,输出是一串击键时间序列 (DT, FT)。
Discriminator(也就是我们的防御系统)试图分辨这是真人的击键还是机器生成的。
DeepRhythm 攻击:
攻击者通过植入在受害者手机里的恶意软件,静默收集了几天的加速度计数据(旁路攻击)。虽然没有直接拿到击键日志,但通过震动推导出了用户的打字节奏。
然后,攻击者使用脚本模拟点击,并注入微小的随机延迟(Jitter),使其统计分布符合用户的 P(User)。
这种攻击可以绕过基于统计特征(均值、方差)的防御系统。
9.2 防御策略:对抗训练与多模态一致性
- 对抗训练(Adversarial Training):
在训练认证模型时,主动加入由 GAN 生成的“伪造击键样本”,标记为负样本。强迫模型学习更深层的、难以伪造的特征(如手指按压屏幕时的微观电容变化纹理,这是脚本无法模拟的)。
- 多模态一致性校验(Multimodal Consistency Check):
这是破解模仿攻击的终极武器。
-
- 逻辑: 攻击者可以脚本模拟完美的击键时间间隔,但他很难同时模拟相应的陀螺仪震动。
- 检测: 如果屏幕上显示每秒输入 10 个字符,但陀螺仪显示手机处于绝对静止状态(没有任何物理敲击产生的震动),AI 会判定:这是脚本注入攻击(Script Injection / Bot)。
物理定律是黑客无法逾越的墙。
10. 架构设计:零信任环境下的持续认证
将上述算法落地到企业环境,需要一个完整的 IAM(身份与访问管理) 架构。我们称之为 基于风险的自适应认证(Risk-based Adaptive Authentication)。
10.1 信任评分引擎(Trust Scoring Engine)
不再是简单的 Pass/Fail,而是一个动态变化的 Trust Score (0-100)。
- 登录初始分: 密码+MFA验证通过,Score = 90。
- T+1分钟: 用户开始打字,击键特征匹配度高,Score = 92。
- T+10分钟: 用户停止操作,去喝咖啡。Score 随时间自然衰减(Time Decay),Score = 80。
- T+30分钟: 鼠标突然出现机械式直线移动(可能是宏脚本),Score 骤降至 40。
10.2 策略执行点(PEP)
根据 Trust Score 触发不同的动作:
- Score > 80: 允许访问核心数据库,允许转账。
- 60 < Score < 80: 允许只读访问,禁止下载。
- 40 < Score < 60: Step-up Authentication(升级认证)。弹窗要求用户再次扫描指纹或输入 OTP。如果验证通过,Score 恢复到 90。
- Score < 40: 立即终止会话(Kill Session),锁定账号,并向 SOC 发送高危告警。
这种架构完美平衡了安全性与用户体验。只要你是本人,你几乎感觉不到认证的存在;一旦出现异常,系统瞬间锁死。
10.3 跨设备关联与上下文感知 (Cross-Device Correlation)
行为生物识别面临的最大工程挑战之一是设备异构性。
- 物理差异: 你在 MacBook 蝶式键盘上的敲击力度和飞行时间,与你在机械键盘(红轴)上的表现截然不同;你在手机屏幕上的滑动轨迹,也无法直接用于验证电脑鼠标的操作。
- 解决方案: 身份中心(IdP)不能只维护一个通用的“用户模型”,而必须建立 “用户-设备”二元组模型。
- 设备指纹锚点: 系统首先识别设备指纹(Device Fingerprint)。如果是已知设备,加载对应的行为模板(Profile A for iPhone, Profile B for PC)。
- 迁移学习(Transfer Learning): 当用户启用新设备时,利用迁移学习技术,将旧设备模型中的“高层认知特征”(如:打字时的思维停顿习惯、拼写错误修正逻辑)迁移过来,作为新模型的初始化参数,从而缩短“冷启动”的学习周期。
- 多模态信任传递: 如果用户刚刚在“高信任度”的手机上通过了步态认证,并在 5 秒内通过蓝牙近场通信解锁了电脑,那么电脑端的初始信任分可以直接继承手机端的信任等级,实现无缝衔接。
11. 代码实战:孪生网络(Siamese Network)与 Triplet Loss
在 Part 1 中我们构建了 LSTM 特征提取器。在 Part 2 中,我们将通过 Metric Learning(度量学习) 来完成验证任务。
我们的目标是学习一个函数 f(x),使得同一用户的样本距离近,不同用户的样本距离远。
11.1 Triplet Loss 定义
我们需要构建三元组:
- Anchor (A): 当前用户的某次操作样本。
- Positive (P): 同一用户的另一次操作样本。
- Negative (N): 另一个冒名顶替者的操作样本。
损失函数:
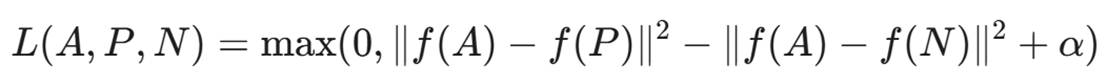
其中 α是 Margin(比如 1.0),即我们希望 P 至少比 N 离 A 近 1.0 个单位。
11.2 PyTorch 实现
Python
import torch
import torch.nn as nn
import torch.nn.functional as F
class TripletLoss(nn.Module):
def __init__(self, margin=1.0):
super(TripletLoss, self).__init__()
self.margin = margin
def forward(self, anchor, positive, negative):
# 计算欧氏距离
dist_ap = F.pairwise_distance(anchor, positive, p=2)
dist_an = F.pairwise_distance(anchor, negative, p=2)
# 损失计算
loss = torch.clamp(dist_ap**2 - dist_an**2 + self.margin, min=0.0)
return loss.mean()
# 模拟训练循环
def train_step(model, optimizer, triplet_loss_fn, batch_data):
# batch_data 包含 (anchors, positives, negatives)
# 每个都是 shape [batch_size, seq_len, features]
a_input, p_input, n_input = batch_data
optimizer.zero_grad()
# 通过 Part 1 定义的 LSTM 模型提取特征向量
# model 返回 (logits, embedding)
_, a_emb = model(a_input['keys'], a_input['features'])
_, p_emb = model(p_input['keys'], p_input['features'])
_, n_emb = model(n_input['keys'], n_input['features'])
# 归一化特征向量 (这点很重要,这就将样本投影到了超球面上)
a_emb = F.normalize(a_emb, p=2, dim=1)
p_emb = F.normalize(p_emb, p=2, dim=1)
n_emb = F.normalize(n_emb, p=2, dim=1)
loss = triplet_loss_fn(a_emb, p_emb, n_emb)
loss.backward()
optimizer.step()
return loss.item()
# 推理/验证阶段
def verify_user(model, enrollment_vectors, current_sample, threshold=0.5):
"""
enrollment_vectors: 用户注册时存储的平均特征向量 (Template)
current_sample: 当前的一段操作数据
"""
model.eval()
with torch.no_grad():
_, curr_emb = model(current_sample['keys'], current_sample['features'])
curr_emb = F.normalize(curr_emb, p=2, dim=1)
# 计算与注册模板的距离
dist = F.pairwise_distance(curr_emb, enrollment_vectors)
if dist < threshold:
return True, dist.item() # 认证通过
else:
return False, dist.item() # 认证失败代码解读
- 特征归一化 (F.normalize): 在计算欧氏距离前,将向量归一化到单位长度是非常关键的技巧。这消除了不同样本幅度(Scale)的影响,只比较方向。
- 动态阈值: 实际生产中,threshold 不是固定的。通常会根据用户的历史行为波动性(Variance)为每个用户设定个性化的阈值。
- One-Shot Learning: 这种架构允许我们在用户只注册一次(One-Shot)的情况下进行验证,无需重新训练模型,非常适合身份认证场景。
12. 未来展望:从行为到意图
行为生物识别的终极目标,不仅仅是识别“你是谁”,而是识别“你想做什么”。
12.1 脑机接口(BCI)的前奏
虽然目前我们还在分析手指和鼠标,但未来的可穿戴设备(如智能手表、AR眼镜)将采集肌电信号(EMG)甚至脑电信号(EEG)。
届时,认证将完全无感化(Passive)。你的心跳节律、你的神经传导特征将成为最强的私钥。
12.2 认知指纹(Cognitive Fingerprint)
更深层的 AI 将分析你的认知模式:
- 你在阅读邮件时,眼球追踪(Eye-tracking)的注视轨迹。
- 你在处理复杂任务时的反应延迟和决策逻辑。
这种“灵魂层面”的特征,即使是拥有你所有生物数据的克隆人,也无法复制。
结语:构建有生命的“数字免疫系统”
至此,第 22 篇《身份与访问:行为生物识别的 AI 建模》画上了句号。
我们从毫秒级的击键时间差出发,解析了人类神经肌肉系统的无意识特征;我们探讨了如何利用 LSTM 和 CNN 捕捉鼠标轨迹中的微观抖动,甚至深入到了移动端传感器融合与联邦学习的隐私保护架构。最后,我们通过 Triplet Loss 构建了一个基于度量学习的验证系统。
这不仅仅是技术的堆叠,更是网络安全范式的一次深刻变革。我们正在告别“门卫时代”——那个只认钥匙不认人的时代,迈向“保镖时代”——一个持续感知、动态评估的时代。行为生物识别赋予了安全系统一双“慧眼”,让它能透过冰冷的账号密码,识别出操作背后那个鲜活的灵魂。
然而,防御永远是动态的。随着生成式 AI(GAN)开始尝试模拟人类的行为特征,我们必须保持警惕,利用对抗训练和多模态一致性校验来加固防线。未来的安全,将是**“AI 攻击者”与“AI 防御者”在毫秒级战场上的博弈**。
在构建了坚固的身份防线后,如果在代码层面依然存在逻辑漏洞怎么办?当 AI 发现了漏洞,它能自己写代码修好它吗?
下期预告:
这听起来像科幻,但基于大语言模型(LLM)的代码理解能力,自动修复已不再遥不可及。 敬请期待 第 23 篇《漏洞修复自动化:利用 LLM 自动生成补丁与修复建议》。我们将探讨 CodeLLM、程序合成(Program Synthesis)以及如何防止 AI 写出带有副作用的补丁,真正实现 DevSecOps 的闭环。
陈涉川
2026年02月07日

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 12
12 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)