多智能体进阶指南:如何让AI团队既聪明又省钱?
Arxiv论文解读:本文提出基于集体影响力估计网络(CIEN)的多智能体强化学习框架,通过仅估计智能体对公共对象的集体影响而非个体动作,显著降低了通信需求。CIEN网络输出维度固定,不随智能体数量增加,实现可扩展协作。实验验证该方法在通信受限环境下仍保持高效协作,为大规模机器人系统提供实用解决方案。
多智能体进阶指南:如何让AI团队既聪明又省钱?
Arxiv文章解读第2期
随着多智能体系统从实验室走向现实落地,“协作效率”正成为新的技术分水岭。面对智能体数量激增带来的通信爆炸与计算冗余,传统的“大鸣大放”式协作显得笨重且昂贵。本期解读的两篇论文,分别从强化学习与大语言模型两个前沿方向给出了极具启发性的答案:一篇提出基于“集体影响力”的无通信协作框架,打破智能体数量扩展的瓶颈;另一篇利用图神经网络动态“量体裁衣”,根据任务难度自动调整通信拓扑,在大幅降低Token消耗的同时保持高性能。如果你关注AI系统的工程落地与成本优化,这两篇研究不容错过。
- 论文1《Scalable Multiagent Reinforcement Learning with Collective Influence Estimation》:提出基于集体影响力估计网络(CIEN)的MARL框架,解决网络规模随智能体数量膨胀的瓶颈;无需频繁通信即可实现高效协作,降低了对通信基础设施的依赖;具备极强的可扩展性,新智能体加入无需修改现有网络结构;在真实三臂机器人平台上成功验证了鲁棒性与部署可行性。
- 论文2《G-Designer: Architecting Multi-agent Communication Topologies via Graph Neural Networks》:结合变分图自编码器(VGAE)动态设计通信拓扑,在MMLU上达到84.50%及HumanEval上89.90%的高精度,同时最高减少95.33%的Token消耗,且具备对抗攻击下的强鲁棒性。
论文1:Scalable Multiagent Reinforcement Learning with Collective Influence Estimation
基本信息
- 资讯条目:Scalable Multiagent Reinforcement Learning with Collective Influence Estimation
- 论文链接:https://arxiv.org/abs/2601.08210
- 作者:Zhenglong Luo,Zhiyong Chen,Aoxiang Liu,Ke Pan
- 发表时间:2026-01-13T04:24:11Z
- 发表来源:arXiv
这篇论文在解决什么难题
传统的MARL方法通常依赖智能体交换状态和动作信息来协调它们的行为。虽然这种方法在较小的环境中效果良好,但当智能体数量增加时,尤其是在通信基础设施有限的情况下,这种方法就变得难以管理。可扩展性,无论是系统规模还是计算复杂性,都是将MARL应用于大规模实际任务(如机器人技术和自动化系统)时面临的最关键挑战之一。
本文通过引入一种允许智能体在最小化通信的情况下进行操作的框架,解决了这些挑战。这消除了智能体之间不断共享信息所带来的瓶颈,尤其是在通信受限的环境中。CIEN框架通过依赖每个智能体从局部观测和任务特定状态中推断关键交互信息,减少了对显式通信的依赖。
它最有价值的创新点
本文的最大贡献是CIEN框架。该框架模拟了所有智能体对任务对象的集体影响,使得每个智能体可以根据其局部观测做出有根据的决策,而无需获取其他智能体的动作信息。这一转变显著减少了通信开销,改善了可扩展性和鲁棒性。CIEN模型是可扩展的,因为其网络规模不会随着智能体数量的增加而增长;无论增加多少智能体,系统结构保持不变。
在受控环境和现实世界的机器人平台上的实验结果验证了该框架,显示在通信受限的场景中,协调性和性能得到了提高。这表明CIEN有可能成为大规模现实应用的基石,尤其是在通信可能不可靠或成本高昂的情况下。
核心方法详解
这篇论文的核心方法是:在通信受限的多智能体强化学习中,不估计其他智能体的动作,而是估计它们对任务公共对象的「集体影响」(Collective Influence),并将其嵌入到 SAC 框架中,形成 CIEN‑SAC。
传统 MARL 在无通信时,要么把其他智能体当环境(不稳定),要么估计其他智能体的动作(维度爆炸)。本文改为:每个智能体只看自己 + 公共物体状态,预测其他所有智能体对物体的「总影响」,用一个小网络 CIEN 拟合,维度不随智能体数量增加,从而实现可扩展协作。
对第 iii 个智能体:
- 自身状态:sis^isi
- 其他智能体状态:s−is^{-i}s−i(不可观测)
- 公共任务对象状态:sos^oso(可观测,如圆盘位姿)
- 自身动作:aia^iai
- 其他智能体动作:a−ia^{-i}a−i(不可通信、不可观测)
传统方法试图估计 a−ia^{-i}a−i,但智能体变多则输出维度爆炸。
定义:其他所有智能体对公共对象状态变化的总效应,记为 c−ic^{-i}c−i,它是一个低维、固定维数的向量,与智能体数量无关。
论文通过一个网络直接从公共对象状态估计它:
c−i=eψ(so)(1)\boxed{c^{-i} = e_\psi(s^o)} \tag{1}c−i=eψ(so)(1)
- eψe_\psieψ:Collective Influence Estimation Network (CIEN)
- 输入:仅公共对象 sos^oso
- 输出:低维集体影响 c−ic^{-i}c−i
这是整篇文章最核心公式。
策略以 自身状态 + 对象状态 + 集体影响 为输入:
πϕ(ai∣si,so,c−i)\pi_\phi(a^i \mid s^i, s^o, c^{-i})πϕ(ai∣si,so,c−i)
实际建模为高斯分布:
ai=tanh(μϕ(si,so,c−i)+σϕ(⋅)⊙ϵ),ϵ∼N(0,I)(2)a^i = \tanh\big(\mu_\phi(s^i,s^o,c^{-i}) + \sigma_\phi(\cdot)\odot\epsilon\big),\quad \epsilon\sim\mathcal{N}(0,I) \tag{2}ai=tanh(μϕ(si,so,c−i)+σϕ(⋅)⊙ϵ),ϵ∼N(0,I)(2)
使用双 Critic 减少过估计:
Qθ1(si,so,ai,c−i),Qθ2(si,so,ai,c−i)Q_{\theta_1}(s^i,s^o,a^i,c^{-i}),\quad Q_{\theta_2}(s^i,s^o,a^i,c^{-i})Qθ1(si,so,ai,c−i),Qθ2(si,so,ai,c−i)
关键:不再输入其他智能体状态/动作,只输入集体影响。
TD 目标(带熵正则):
y=r+γminj=1,2Qθj′(snexti,snexto,anexti,cnext−i)+αlogπϕ(anexti∣snexti,snexto,cnext−i)(3)\boxed{y = r + \gamma\min_{j=1,2}Q_{\theta'_j}(s^i_{\text{next}},s^o_{\text{next}},a^i_{\text{next}},c^{-i}_{\text{next}}) + \alpha\log\pi_\phi(a^i_{\text{next}}\mid s^i_{\text{next}},s^o_{\text{next}},c^{-i}_{\text{next}})} \tag{3}y=r+γj=1,2minQθj′(snexti,snexto,anexti,cnext−i)+αlogπϕ(anexti∣snexti,snexto,cnext−i)(3)
其中:
- anexti=πϕ(snexti,snexto,cnext−i)a^i_{\text{next}} = \pi_\phi(s^i_{\text{next}},s^o_{\text{next}},c^{-i}_{\text{next}})anexti=πϕ(snexti,snexto,cnext−i)
- cnext−i=eψ′(snexto)c^{-i}_{\text{next}} = e_{\psi'}(s^o_{\text{next}})cnext−i=eψ′(snexto)(目标 CIEN)
Critic 损失:
L(θj)=E[(Qθj(si,so,ai,c−i)−y)2],j=1,2(4)\boxed{L(\theta_j) = \mathbb{E}\left[\big(Q_{\theta_j}(s^i,s^o,a^i,c^{-i}) - y\big)^2\right]},\quad j=1,2 \tag{4}L(θj)=E[(Qθj(si,so,ai,c−i)−y)2],j=1,2(4)
Actor 梯度(最大化 Q + 熵):
∇ϕJ(ϕ)=E[∇ϕ(αlogπϕ−Qθ1)](5)\boxed{\nabla_\phi J(\phi) = \mathbb{E}\left[\nabla_\phi\big(\alpha\log\pi_\phi - Q_{\theta_1}\big)\right]} \tag{5}∇ϕJ(ϕ)=E[∇ϕ(αlogπϕ−Qθ1)](5)
CIEN 网络更新(关键!):
CIEN 本质是在拟合其他智能体的联合策略效应,因此训练方式类似策略网络,也要带熵:
∇ψJ(ψ)=E[∇ψ(αlogπψ(⋅∣si,so,c−i)−Qθ1)](6)\boxed{\nabla_\psi J(\psi) = \mathbb{E}\left[\nabla_\psi\big(\alpha\log\pi_\psi(\cdot\mid s^i,s^o,c^{-i}) - Q_{\theta_1}\big)\right]} \tag{6}∇ψJ(ψ)=E[∇ψ(αlogπψ(⋅∣si,so,c−i)−Qθ1)](6)
这是论文最关键的训练设计:CIEN 不是简单回归,而是和 Actor 同风格优化,保证能拟合动态协作效应。
软更新目标网络:
θj′←τθj+(1−τ)θj′,j=1,2\theta'_j \leftarrow \tau\theta_j + (1-\tau)\theta'_j,\quad j=1,2θj′←τθj+(1−τ)θj′,j=1,2
ψ′←τψ+(1−τ)ψ′(7)\psi' \leftarrow \tau\psi + (1-\tau)\psi' \tag{7}ψ′←τψ+(1−τ)ψ′(7)
传统动作估计:
a^−i∈Rd⋅(N−1)\hat{a}^{-i} \in \mathbb{R}^{d\cdot (N-1)}a^−i∈Rd⋅(N−1)
维度随智能体数 NNN 线性增长。
本文集体影响:
c−i=eψ(so)∈Rkc^{-i} = e_\psi(s^o) \in \mathbb{R}^{k}c−i=eψ(so)∈Rk
kkk 是固定小常数(如实验中 k=2),与 N 无关。
因此:
- 网络结构不随智能体数量变化
- 增加智能体不需要改网络、不改输入输出维度
- 计算复杂度不爆炸
这就是论文标题 Scalable 的数学根源。
整体算法流程:
- 每个智能体观测 si,sos^i, s^osi,so
- CIEN 计算集体影响:c−i=eψ(so)c^{-i}=e_\psi(s^o)c−i=eψ(so)
- Actor 输出动作:ai∼πϕ(⋅∣si,so,c−i)a^i\sim\pi_\phi(\cdot\mid s^i,s^o,c^{-i})ai∼πϕ(⋅∣si,so,c−i)
- 存入经验池:(si,so,ai,c−i,r,s′i,s′o)(s^i,s^o,a^i,c^{-i},r,s'^i,s'^o)(si,so,ai,c−i,r,s′i,s′o)
- 采样批次,用式 (3)(4) 更新 Critic
- 用式 (5) 更新 Actor
- 用式 (6) 更新 CIEN
- 软更新目标网络(式7)
这篇文章的数学与结构核心只有三点:
-
放弃估计其他智能体动作 a−ia^{-i}a−i,转而估计低维、与智能体数量无关的 集体影响 c−ic^{-i}c−i。
-
用 CIEN 网络拟合:
c−i=eψ(so)c^{-i} = e_\psi(s^o)c−i=eψ(so) -
将 c−ic^{-i}c−i 作为额外输入嵌入 SAC,Actor/Critic/CIEN 三者联合端到端训练,保持网络结构固定,实现通信受限、可扩展、稳定的多智能体协作。

- 图1:三臂协作机器人系统
- 图1解读:这展示了实验使用的真实物理平台。读者应关注三个机械臂如何共同操作一个物体。这验证了所提方法在现实机器人系统中的可行性,证明了在无需频繁通信的情况下,多智能体能够有效协作并完成搬运任务。
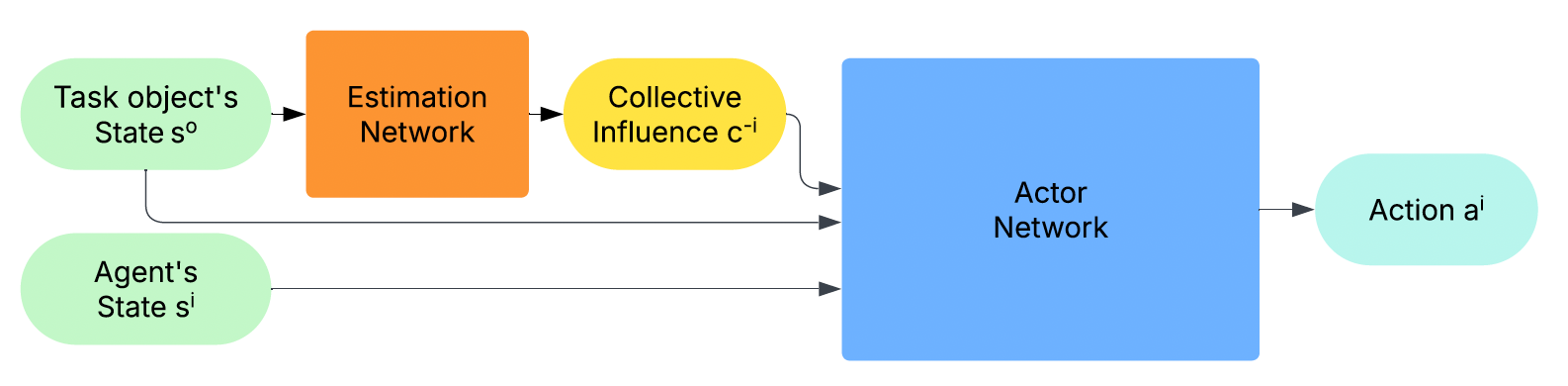
- 图2:集成集体影响估计网络(CIEN)的Actor网络流程图
- 图2解读:此图展示了算法的核心架构。读者需关注CIEN如何利用局部观测和任务物体状态来估计集体影响,从而生成动作。该设计避免了网络随智能体数量增加而膨胀,有效解决了大规模多智能体系统的扩展性问题。
实验与应用价值
在基于Soft Actor-Critic (SAC)算法的多智能体协作仿真任务中进行了测试,评估了通信受限环境下的协调性能;将训练好的策略部署到真实的三臂协作机器人平台上,验证了方法的实际部署效果和鲁棒性。
| 观察维度 | 设置/指标 | 结果/结论 |
|---|---|---|
| 实验设计 | 多任务+多团队配置 | 围绕协作有效性进行多条件对比 |
| 对比基线 | 单专家 vs 多智能体团队 | 观察团队是否真正超过最优个体 |
| 结果趋势 | 性能与鲁棒性指标 | 在基于Soft Actor-Critic (SAC)算法的多智能体协作仿… |
| 价值维度 | 解读 |
|---|---|
| 领域贡献 | 为解决大规模多智能体强化学习中的通信瓶颈和计算扩展性问题提供了新思路;证明了通过建模环境对象状态变化可以替代昂贵的显式通信和个体行为建模;推动了MARL算法从仿真环境向实际物理系统的落地应用。 |
| 通俗理解 | 以前大家合作需要不停发消息或者算清每个人具体在干什么,人一多就算不过来了。现在的方法是:大家只关注共同操作的那个物体(比如一个门),通过看门怎么动,就能推测出大家合起来的力是多少,然后自己配合调整。这样不用说话,也不用管有多少队友,算起来很快。 |
| 与日常生活关系 | 就像几个人一起抬一张重桌子,你不需要旁边的人一直告诉你“我现在用了10斤力”或者“我要往左转”,你只需要感觉桌子的倾斜度和移动速度,就能知道大家合力的效果,从而自然地调整自己的姿势,这种配合既省事又高效。 |
论文2:G-Designer: Architecting Multi-agent Communication Topologies via Graph Neural Networks
基本信息
- 资讯条目:G-Designer: Architecting Multi-agent Communication Topologies via Graph Neural Networks
- 论文链接:https://arxiv.org/abs/2410.11782
- 作者:Guibin Zhang,Yanwei Yue,Xiangguo Sun,Guancheng Wan,Miao Yu,Junfeng Fang 等9位
- 发表时间:2024-10-15T17:01:21Z
- 发表来源:arXiv
这篇论文在解决什么难题
当前基于大语言模型(LLM)的智能体系统虽然在集体智能方面表现出潜力,但在实际部署中面临一个核心痛点:如何针对特定任务选择最优的通信拓扑结构?现有的多智能体设计往往采用静态预设的拓扑(如全连接、链式或固定的Swarm结构),缺乏灵活性。这种“一刀切”的静态方法难以适应任务的复杂度和多样性。对于简单任务,复杂的拓扑(如GPTSwarm)会产生大量冗余的通信Token,造成计算资源浪费和成本增加;而对于复杂任务,过于简单的拓扑(如链式结构)又无法提供足够的信息交互深度,导致求解质量下降。因此,设计一个能够根据任务难度自动调整连接方式,在保证高性能的同时最大限度降低通信开销的自适应架构,是极具挑战性的技术难题。
它最有价值的创新点
创新类型:架构与算法融合创新。论文首次引入变分图自编码器(VGAE)来自动化生成多智能体系统的通信拓扑,而非依赖人工设计的静态结构。它创新性地在图中引入“任务特定虚拟节点”,将任务特征融入图结构的生成过程中。
通俗解释:这就像不再给一群协作的专家(智能体)规定固定的开会流程,而是请一位超级调度官(VGAE模型),这位调度官手里拿着任务的具体需求(虚拟节点),实时判断哪些专家之间需要对话,哪些不需要。对于简单的问题,调度官就让大家排成一队挨个说(链式),少费口舌(省Token);对于难的问题,调度官就让大家频繁讨论,形成复杂的网状结构(Swarm),确保问题解决。这种方法打破了传统固定流程的僵化,实现了“量体裁衣”式的智能协作。
核心方法详解
这篇论文提出的G-Designer是一套为大语言模型(LLM)多智能体系统动态设计任务感知型通信拓扑的方法,核心解决了"不同任务该选哪种智能体通信结构,才能兼顾性能、效率和鲁棒性"的问题。其本质是用变分图自编码器(VGAE) 对多智能体网络和任务信息进行编码-解码,再通过正则化和策略梯度优化,生成适配具体任务难度的稀疏通信拓扑,全程遵循作者提出的MACP多智能体通信协议。
作者先定义了Multi-agent Communication Protocol (MACP),这是G-Designer的设计准则,要求最优的多智能体通信拓扑必须满足有效性、任务自适应性、对抗鲁棒性三大要求,并用数学公式量化了这个优化目标:
minG∈G[−u(G(Q))+β1⋅∥G∥+β2⋅∣G^(Q^)−G(Q)∣]\min _{\mathcal{G} \in G}\left[-u(\mathcal{G}(\mathcal{Q}))+\beta_{1} \cdot\| \mathcal{G}\| +\beta_{2} \cdot|\hat{\mathcal{G}}(\hat{\mathcal{Q}})-\mathcal{G}(\mathcal{Q})|\right]G∈Gmin[−u(G(Q))+β1⋅∥G∥+β2⋅∣G^(Q^)−G(Q)∣]
公式通俗解读:
- G\mathcal{G}G:代表多智能体的通信拓扑(图结构),Q\mathcal{Q}Q是输入任务/查询;
- −u(G(Q))-u(\mathcal{G}(\mathcal{Q}))−u(G(Q)):有效性项,u(⋅)u(·)u(⋅)是拓扑的性能效用(比如任务准确率),加负号表示最大化性能;
- β1⋅∥G∥\beta_{1} \cdot\| \mathcal{G}\|β1⋅∥G∥:自适应性项,∥G∥\| \mathcal{G}\|∥G∥衡量拓扑的计算/通信开销(比如token消耗),这一项要求最小化开销,β1\beta_1β1是权重系数;
- β2⋅∣G^(Q^)−G(Q)∣\beta_{2} \cdot|\hat{\mathcal{G}}(\hat{\mathcal{Q}})-\mathcal{G}(\mathcal{Q})|β2⋅∣G^(Q^)−G(Q)∣:鲁棒性项,G^\hat{\mathcal{G}}G^是受对抗攻击后的拓扑,Q^\hat{\mathcal{Q}}Q^是受攻击的任务,这一项要求攻击前后的拓扑性能偏差尽可能小,β2\beta_2β2是权重系数。
简单说:MACP要求G-Designer找的拓扑,要准确率高、花钱(token)少、抗攻击强。
G-Designer把多智能体系统建模成有向图,再通过构建(Construct)-设计(Design)-优化(Optimize) 三步,为每个具体任务生成定制化通信拓扑,全程是任务驱动的端到端流程:
- 构建:把智能体和任务分别建模成图的节点(含智能体的能力/角色特征),生成一个带任务虚拟节点的初始多智能体网络;
- 设计:用变分图自编码器(VGAE)对初始网络编码,得到低维隐空间表示,再解码生成初步的通信图,最后通过正则化得到稀疏、高效的最终通信拓扑Gcom\mathcal{G}_{com}Gcom;
- 优化:用生成的Gcom\mathcal{G}_{com}Gcom指导智能体协作完成任务,通过策略梯度优化编码器/解码器的参数,让拓扑持续适配任务。
整体流程可概括为:任务→智能体图建模→VGAE编码解码→稀疏拓扑→智能体协作→性能反馈优化。
G-Designer首先将多智能体系统形式化为有向图G=(V,E)\mathcal{G}=(V, E)G=(V,E),这是所有后续操作的基础,核心是定义节点(智能体)、边(通信关系)、任务虚拟节点三个核心元素。
每个智能体对应图的一个节点vi∈Vv_i \in Vvi∈V,节点包含智能体的核心属性,公式定义为:
vi={Basei,Rolei,Statei,Plugini}v_{i}=\{Base _{i}, Role _{i}, State _{i}, Plugin _{i}\}vi={Basei,Rolei,Statei,Plugini}
- BaseiBase_iBasei:智能体的基础LLM(比如GPT-4、Llama3);
- RoleiRole_iRolei:智能体的角色(比如数学分析师、程序员、测试工程师);
- StateiState_iStatei:智能体的历史交互/知识积累;
- PluginiPlugin_iPlugini:智能体的外部工具(比如Python编译器、数学计算器、网页搜索)。
每个智能体接收提示P\mathcal{P}P,生成响应Ri\mathcal{R}_iRi,公式为:
Ri=vi(P)=vi(Psys,Pusr)\mathcal{R}_{i}=v_{i}(\mathcal{P})=v_{i}\left(\mathcal{P}_{sys}, \mathcal{P}_{usr}\right)Ri=vi(P)=vi(Psys,Pusr)
其中Psys\mathcal{P}_{sys}Psys是系统提示(含角色/状态),Pusr\mathcal{P}_{usr}Pusr是用户/其他智能体的提示(含任务、其他智能体的回复)。
智能体之间的通信关系用**邻接矩阵A∈{0,1}N×NA \in \{0,1\}^{N×N}A∈{0,1}N×N**表示(NNN是智能体数量):
A[i,j]=1⇔智能体i向智能体j传递信息,否则A[i,j]=0A[i, j]=1 \Leftrightarrow \text{智能体}i\text{向智能体}j\text{传递信息,否则}A[i,j]=0A[i,j]=1⇔智能体i向智能体j传递信息,否则A[i,j]=0
边的物理意义就是信息流向(比如程序员→测试工程师,代表程序员把代码传给测试工程师)。
为了让拓扑感知任务特征,作者加入了任务专属虚拟节点vtaskv_{task}vtask,这个节点和所有智能体节点双向连接,作用是:
- 作为任务信息的全局载体,把任务Q\mathcal{Q}Q的特征传递给所有智能体;
- 让智能体之间的信息流动更顺畅,避免"信息孤岛"。
任务虚拟节点的特征由节点编码器生成:xtask=NodeEncoder(Q)x_{task} = \text{NodeEncoder}(\mathcal{Q})xtask=NodeEncoder(Q),其中NodeEncoder是轻量文本嵌入模型(比如all-MiniLM-L6-v2),把任务文本转成固定维度的向量。
结合智能体节点、任务虚拟节点和锚定拓扑AanchorA_{anchor}Aanchor(初始简单拓扑,比如链式结构,作为设计起点),最终得到带任务信息的初始多智能体网络Gˉ\bar{\mathcal{G}}Gˉ,公式为:
G‾=([Xagentxtask⊤],A~anchor)\overline{\mathcal{G}} = \left(\left[\begin{array}{c} X_{agent } \\ x_{task }^{\top} \end{array}\right], \tilde{A}_{anchor }\right)G=([Xagentxtask⊤],A~anchor)
- XagentX_{agent}Xagent:所有智能体节点的特征矩阵(每行是一个智能体的嵌入向量);
- A~anchor\tilde{A}_{anchor}A~anchor:融合了任务虚拟节点的锚定邻接矩阵(在原AanchorA_{anchor}Aanchor基础上,加虚拟节点和所有智能体的双向边)。
通俗理解:这一步相当于把"5个不同角色的GPT-4智能体+1个数学题任务",变成了一个带任务信息的初始图,图里有6个节点,初始边是简单的链式结构。
这是G-Designer的核心算法模块,用变分图自编码器(VGAE) 对初始网络Gˉ\bar{\mathcal{G}}Gˉ进行编码(降维提取特征)和解码(生成通信拓扑),最终得到稀疏、高效的通信拓扑Gcom\mathcal{G}_{com}Gcom。
编码器的作用是将初始网络Gˉ\bar{\mathcal{G}}Gˉ的节点特征和拓扑结构,编码成低维隐向量HagentH_{agent}Hagent(保留核心特征,降低计算量),公式基于变分推断,定义为:
q(Hagent∣X~,A~anchor)=∏i=1Nq(hi∣X~,A~anchor)=∏i=1NN(hi∣μi,diag(σi2))q\left(H_{agent } | \tilde{X}, \tilde{A}_{anchor }\right) = \prod_{i=1}^{N} q\left(h_{i} | \tilde{X}, \tilde{A}_{anchor }\right) = \prod_{i=1}^{N} \mathcal{N}\left(h_{i} | \mu_{i}, diag\left(\sigma_{i}^{2}\right)\right)q(Hagent∣X~,A~anchor)=i=1∏Nq(hi∣X~,A~anchor)=i=1∏NN(hi∣μi,diag(σi2))
公式通俗解读:
- q(⋅)q(·)q(⋅):VGAE的后验分布编码器,作者用两层图卷积网络(GCN) 实现;
- hih_ihi:第iii个智能体的低维隐向量,服从正态分布N\mathcal{N}N;
- μi\mu_iμi和σi\sigma_iσi:正态分布的均值和方差,由GCN对初始图Gˉ\bar{\mathcal{G}}Gˉ的特征X~\tilde{X}X~和邻接矩阵A~anchor\tilde{A}_{anchor}A~anchor计算得到:μ=GNNμ(X~,A~anchor)\mu=GNN_{\mu}(\tilde{X}, \tilde{A}_{anchor})μ=GNNμ(X~,A~anchor),log(σ)=GNNσ(X~,A~anchor)log(\sigma)=GNN_{\sigma}(\tilde{X}, \tilde{A}_{anchor})log(σ)=GNNσ(X~,A~anchor);
- 乘积形式表示每个智能体的隐向量相互独立,便于计算。
通俗理解:编码阶段就像把"一张复杂的初始图"压缩成"一组简洁的特征向量",每个智能体对应一个向量,保留了"智能体角色+任务特征+初始通信关系"的核心信息。
解码器分草图生成和稀疏精炼两步,从隐向量HagentH_{agent}Hagent生成最终的通信拓扑Gcom\mathcal{G}_{com}Gcom,核心是先粗后精,既保证拓扑适配任务,又保证稀疏高效。
先通过隐向量生成稠密的通信草图邻接矩阵S∈[0,1]N×NS \in [0,1]^{N×N}S∈[0,1]N×N,SijS_{ij}Sij表示"智能体iii向jjj通信的概率",公式为:
ps(Sij=1∣hi,hj,htask)=Sigmoid((log(ϵ)−log(1−ϵ)+ϖij)/τ)p_{s}\left(S_{ij}=1| h_{i},h_{j},h_{task}\right) = \text{Sigmoid}\left((log (\epsilon )-log (1-\epsilon )+\varpi _{ij})/\tau \right)ps(Sij=1∣hi,hj,htask)=Sigmoid((log(ϵ)−log(1−ϵ)+ϖij)/τ)
其中ϖij=FFNd([hi,hj,htask])\varpi_{ij}=FFN_{d}([h_{i}, h_{j}, h_{task}])ϖij=FFNd([hi,hj,htask])(前馈网络融合两个智能体和任务的隐向量),ϵ∼Uniform(0,1)\epsilon \sim Uniform(0,1)ϵ∼Uniform(0,1)是随机数,τ\tauτ是温度系数(控制概率的平滑度)。
通俗理解:这一步生成的是"概率版"通信拓扑,每个位置是0~1的概率值,比如S12=0.9S_{12}=0.9S12=0.9表示"智能体1向2通信的概率90%",但这个拓扑是稠密的(很多非0值),通信开销大,需要进一步精炼。
通过正则化目标对稠密草图SSS进行精炼,得到稀疏的邻接矩阵S~\tilde{S}S~,再基于S~\tilde{S}S~定义最终的通信拓扑Gcom\mathcal{G}_{com}Gcom,核心公式为:
S~=argmaxS~∈S[12∥S−ZWZ⊤∥F2+ζ∥W∥∗]\tilde{S} = \underset{\tilde{S} \in \mathbb{S}}{arg max } \left[ \frac{1}{2}\left\| S-Z W Z^{\top}\right\| _{F}^{2}+\zeta\| W\| _{*} \right]S~=S~∈Sargmax[21 S−ZWZ⊤ F2+ζ∥W∥∗]
Gcom=(V,Ecom),Ecom={(i,j)∣S~ij≠0∧(i,j)∈E}\mathcal{G}_{com }=\left(\mathcal{V}, \mathcal{E}_{com }\right), \mathcal{E}_{com }=\left\{(i, j) | \tilde{S}_{i j} \neq 0 \land(i, j) \in \mathcal{E}\right\}Gcom=(V,Ecom),Ecom={(i,j)∣S~ij=0∧(i,j)∈E}
公式通俗解读:
- 锚定正则化项12∥S−ZWZ⊤∥F2\frac{1}{2}\left\| S-Z W Z^{\top}\right\| _{F}^{2}21 S−ZWZ⊤ F2:让精炼后的S~\tilde{S}S~和原始草图SSS、锚定拓扑AanchorA_{anchor}Aanchor保持相似,保证拓扑的合理性(不偏离基本的通信逻辑);
- 稀疏正则化项ζ∥W∥∗\zeta\| W\| _{*}ζ∥W∥∗:∥W∥∗\|W\|_*∥W∥∗是矩阵WWW的核范数,最小化核范数会让S~\tilde{S}S~变得稀疏(大部分元素为0),从而减少通信开销,ζ\zetaζ是权重系数;
- Ecom\mathcal{E}_{com}Ecom:最终的通信边集合,只保留S~\tilde{S}S~中非0的元素,即"智能体iii和jjj有通信关系当且仅当S~ij≠0\tilde{S}_{ij}≠0S~ij=0"。
通俗理解:这一步相当于把"稠密的概率版拓扑"剪枝成"稀疏的确定版拓扑",比如删掉概率低于0.5的通信边,最终只保留核心的通信关系(比如数学分析师→程序员,程序员→测试工程师),既适配任务,又大幅减少token消耗。
生成通信拓扑Gcom\mathcal{G}_{com}Gcom后,用它指导多智能体协作完成任务,再通过性能反馈优化G-Designer的编码器/解码器参数,让拓扑的性能持续提升,核心是策略梯度(解决LLM性能效用u(⋅)u(·)u(⋅)不可微的问题)。
基于Gcom\mathcal{G}_{com}Gcom的通信关系,智能体进行KKK轮协作,每轮按**执行顺序σ\sigmaσ**生成响应,最后聚合得到任务解a(K)a^{(K)}a(K),核心公式为:
Ri(t)=vi(Psys(t),Pusr(t)),Pusr(t)={Q,∪vj∈Nin(vi)Rj(t)}\mathcal{R}_{i}^{(t)}=v_{i}\left(\mathcal{P}_{sys }^{(t)}, \mathcal{P}_{usr }^{(t)}\right), \quad \mathcal{P}_{usr }^{(t)}=\left\{\mathcal{Q}, \cup_{v_{j} \in \mathcal{N}_{in }\left(v_{i}\right)} \mathcal{R}_{j}^{(t)}\right\}Ri(t)=vi(Psys(t),Pusr(t)),Pusr(t)={Q,∪vj∈Nin(vi)Rj(t)}
a(t)=Aggregate(R1(t),R2(t),⋯ ,RN(t))a^{(t)} = \text{Aggregate}\left(\mathcal{R}_{1}^{(t)}, \mathcal{R}_{2}^{(t)}, \cdots, \mathcal{R}_{N}^{(t)}\right)a(t)=Aggregate(R1(t),R2(t),⋯,RN(t))
公式通俗解读:
- Ri(t)\mathcal{R}_{i}^{(t)}Ri(t):第ttt轮智能体iii的响应,仅基于自身角色和入度邻居的响应(Nin(vi)\mathcal{N}_{in}(v_i)Nin(vi)是向iii传递信息的智能体),符合Gcom\mathcal{G}_{com}Gcom的通信拓扑;
- Aggregate(⋅)\text{Aggregate}(·)Aggregate(⋅):结果聚合函数(比如多数投票、指定核心智能体总结),生成第ttt轮的中间解a(t)a^{(t)}a(t);
- 经过KKK轮迭代后,得到最终解a(K)=Gcom(Q)a^{(K)} = \mathcal{G}_{com}(\mathcal{Q})a(K)=Gcom(Q)。
LLM的性能效用u(⋅)u(·)u(⋅)(比如准确率)是不可微的(无法直接用反向传播),作者用策略梯度近似优化编码器/解码器的参数Θ={Θe,Θd}\Theta=\{\Theta_e, \Theta_d\}Θ={Θe,Θd},核心公式为:
∇ΘEΘ∼Ω[u(Gcom(Q))]≈1M∑k=1Mu(am(K))∇Θ(P(Gk))\nabla_{\Theta} \mathbb{E}_{\Theta \sim \Omega}\left[u\left(\mathcal{G}_{com }(\mathcal{Q})\right)\right] \approx \frac{1}{M} \sum_{k=1}^{M} u\left(a_{m}^{(K)}\right) \nabla_{\Theta}\left(P\left(\mathcal{G}_{k}\right)\right)∇ΘEΘ∼Ω[u(Gcom(Q))]≈M1k=1∑Mu(am(K))∇Θ(P(Gk))
公式通俗解读:
- 目标:最大化任务性能的数学期望E[u(⋅)]\mathbb{E}[u(·)]E[u(⋅)];
- P(Gk)P(\mathcal{G}_k)P(Gk):采样得到拓扑Gk\mathcal{G}_kGk的概率,由S~\tilde{S}S~的元素乘积得到:P(Gk)=∏i=1N∏j=1NS~ijP(\mathcal{G}_{k})=\prod_{i=1}^{N} \prod_{j=1}^{N} \tilde{S}_{i j}P(Gk)=∏i=1N∏j=1NS~ij;
- 用MMM个采样的拓扑Gk\mathcal{G}_kGk的性能u(am(K))u(a_m^{(K)})u(am(K))近似梯度,解决不可微问题。
通俗理解:这一步是"反馈学习"——如果生成的拓扑让任务准确率高,就保留对应的编码器/解码器参数;如果准确率低,就调整参数,让后续生成的拓扑更优。
G-Designer的核心亮点:
- 任务感知的动态拓扑:通过任务虚拟节点将任务特征融入图建模,让拓扑随任务难度动态变化(简单任务用稀疏拓扑,复杂任务用复杂拓扑);
- 稀疏高效:通过核范数稀疏正则化剪枝冗余通信边,最高可减少95.33%的token消耗;
- 对抗鲁棒性:编码阶段能识别恶意智能体的特征,解码阶段可剪枝受攻击智能体的通信边,攻击后准确率仅下降0.3%;
- 端到端可优化:基于VGAE和策略梯度,实现从"任务输入"到"拓扑生成"再到"性能优化"的端到端流程,无需人工干预。
G-Designer将LLM多智能体系统建模为带任务虚拟节点的有向图,以MACP协议为优化准则,通过变分图自编码器(VGAE) 对初始图进行编码-解码,生成稀疏的任务感知型通信拓扑,再通过策略梯度基于任务性能反馈优化模型参数,最终实现性能高、开销低、抗攻击强的多智能体协作,解决了传统静态拓扑"一刀切"的问题。
方法流程图与图解: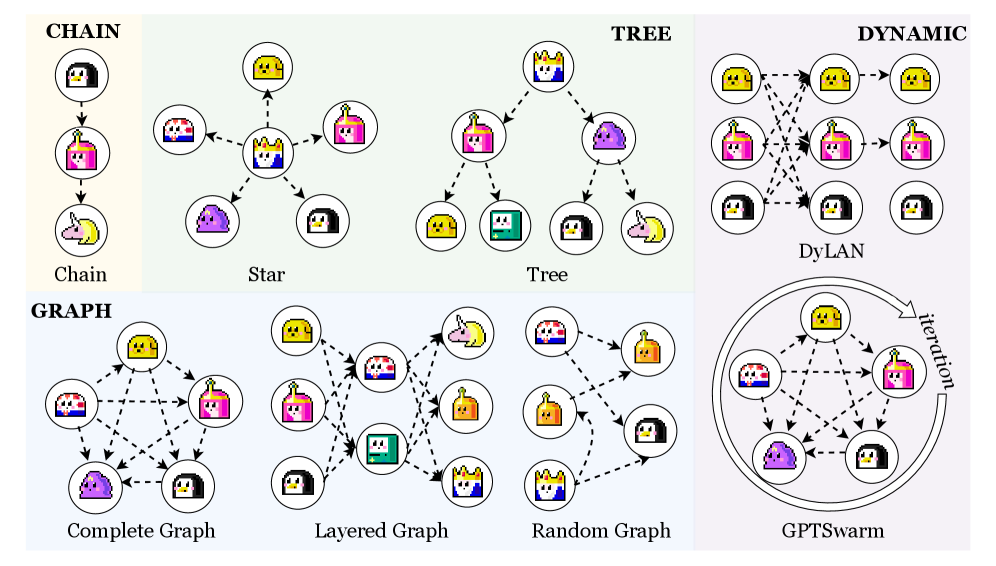
- 图1. 现有的大语言模型多智能体通信拓扑设计实践。
- 图1解读:该图展示了当前多智能体系统中常见的几种通信拓扑结构。读者应重点关注节点(智能体)之间连接方式的差异,例如全连接或环形结构。这揭示了现有设计通常是固定的,缺乏针对任务的适应性,从而引出了需要动态设计最优拓扑的研究动机。
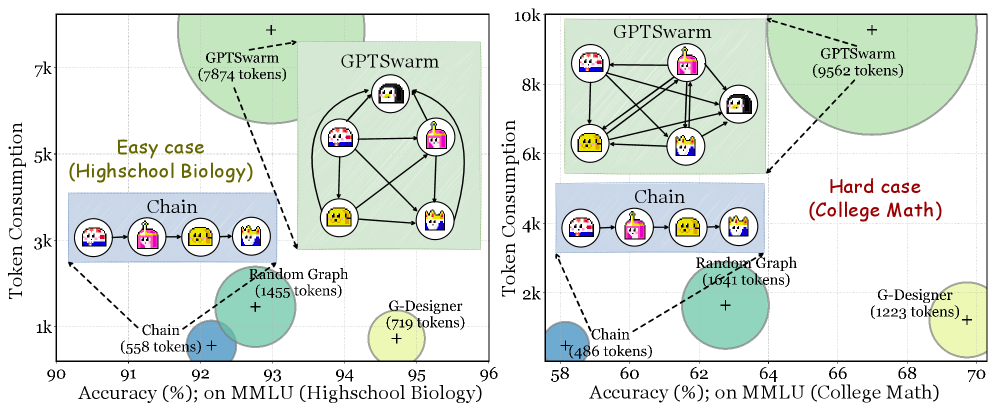
- 图2. 在MMLU数据集子集上,不同多智能体协议的Token消耗量与准确率对比。
- 图2解读:此图对比了不同协议在特定任务上的表现。读者需观察准确率与Token消耗之间的权衡关系,特别是在“高中生物”与“大学数学”难度不同任务下的表现差异。结论是现有方法难以同时实现低消耗与高准确,凸显了G-Designer设计自适应拓扑的优势。
实验与应用价值
实验在MMLU、HumanEval等6个基准数据集上进行,使用4个基于GPT-4的智能体。对比对象包括链式结构、星型结构及复杂的GPTSwarm等静态拓扑。结果显示,G-Designer在性能上显著优于传统静态方法,在MMLU上达到84.50%准确率,在HumanEval上达到89.90%通过率。趋势上表现出极强的任务适应性:在简单任务(如高中生物)上,其设计的拓扑接近链式结构,Token消耗降低94%;在困难任务(如大学数学)上,其自动演化为类似Swarm的复杂结构,准确率比链式结构提升8.75%。此外,对抗实验表明该方法在遭遇恶意攻击时准确率仅下降0.3%。
| 观察维度 | 设置/指标 | 结果/结论 |
|---|---|---|
| 综合性能 | MMLU准确率及HumanEval通过率 | 分别为84.50%和89.90%,均优于静态拓扑; 效率优化 |
| 对比基线 | 单专家 vs 多智能体团队 | 观察团队是否真正超过最优个体 |
| 结果趋势 | 性能与鲁棒性指标 | 实验在MMLU、HumanEval等6个基准数据集上进行,使用4个基于G… |
| 价值维度 | 解读 |
|---|---|
| 领域贡献 | 该研究首次将图神经网络(GNN)技术应用于多智能体系统的通信拓扑自动设计,提出了一种端到端的优化框架G-Designer,解决了从静态手工设计到动态自适应设计的跨越,显著提升了多智能体系统的效率、性能与安全性。 |
| 通俗理解 | 这篇文章做了一个“智能组织架构师”,它能根据任务的难易程度,自动决定一群AI助手该怎么聊天。任务简单就让它们排成队传话,省事省钱;任务难就让它们打成团热烈讨论,保证质量。这样既解决了大模型跑起来太贵的问题,又保证了能把题做对。 |
| 与日常生活关系 | 就像公司开会,讨论“中午吃什么”这种小事(简单任务),没必要把全公司几十号人都叫到会议室里,组长打个电话问问大家(链式)就行,省时间;但如果是“公司上市计划”这种大事(困难任务),就得各个部门负责人一起开会讨论,甚至还要反复沟通(网状结构),才能做出最好的决策。这个系统就是自动帮你决定该怎么开会的那个人。 |
总结
这两项研究共同揭示了多智能体技术从“野蛮生长”向“精细化运营”演进的趋势。无论是CIEN通过感知环境状态来替代繁琐的显式通信,还是G-Designer根据任务难度动态重构沟通网络,本质上都在追求“用最少的信息交换换取最优的团队决策”。这不仅显著降低了AI系统的部署门槛与硬件成本,也为构建具备鲁棒性的工业级AI集群提供了关键范式。对于普通读者而言,这或许也是一种职场智慧:高效的团队协作并非简单的消息互通,而是基于对目标(任务)深刻理解的结构化配合。在AI日益普及的今天,学会“聪明地协作”比“拼命地说话”更重要。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 26
26 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)