[Minimind]Pytorch手敲大模型学习笔记[未完结]
这是一篇学习笔记,主要记录的是手敲大模型过程中遇到的问题与解决方案,同时记录和整理学习心得。
这是一篇学习笔记,主要记录的是手敲大模型过程中遇到的问题与解决方案,同时记录和整理学习的心得体会。
零、前置知识
1.Attention:
Attention实现的功能就是把原来用来表示token的嵌入向量更加精细化、使这个嵌入向量具有更多的上下文语义修饰信息,从而实现整个文本的语义关联。

原理就是:
一段句子被分割成多个token后,每个token被映射成一个多维嵌入向量,这些嵌入向量
不包括上下文的语义信息,但包括这个token的位置信息,位置信息就是这个token在一个句子中所处哪个位置。为了让每个嵌入向量
更加精细化,这里为每个token的嵌入向量
定义了一个查询向量
和一个键向量
,查询向量
和键向量
都是维度比嵌入向量
小很多的向量(维度较小是为了把原来的嵌入向量投射到更加低纬度的空间),最后通过
的操作,得到每个token经过精细化修饰后的嵌入向量
。这里为每个token嵌入向量附加的向量
,就相当于是附加了上下文的语义信息。其中,
,
表示值矩阵,值矩阵
与嵌入向量
的点积得到值向量
,值矩阵
需要模型从数据中学习训练来获得。代表修饰修饰信息的查询向量
则通过
(同理,
)获得,这里的
是每个token的查询矩阵,查询矩阵中的每一个数值都代表这未知权重,这些权重都需要通过模型从数据中学习训练来获得。
每个token对应嵌入向量的查询矩阵,相当于是嵌入向量向原始句子中的其他token释放的查询信号,这个查询信号包含了原token所需要的修饰信息,当句子中其他token的键
所携带的修饰信息,与token释放的查询矩阵
所需要的修饰信息方向很像时,则实现了语义查找功能,那么原句中键
所对应的token就是查询矩阵
对应token的修饰成分,衡量键
与查询矩阵
相似度则是用二者点积来实现的,即n个token的n个键
与n个token的n个查询矩阵
分别两两点积,形成n
n的点积矩阵
,然后每列再经过softmax得到归一化的权重。
2. 注意力掩码:
让键与查询
点积矩阵
(注意力矩阵)为上三角矩阵,即键
与查询
点积矩阵三角下方的点积数值在进行softmax之前设置为无穷,目的是为了不让句子后面预测出来的词对句子前面的预测结果产生影响,防止模型看后面的答案。自注意力机制下使用,互注意力机制下不使用。
3. 上下文长度:
上下文长度和注意力矩阵大小有关,注意力矩阵与token数量的平方呈正比,占用大量内存空间,所以上下文长度很难扩展。
4. 值向量矩阵 的参数量:
的参数量:
如果token的嵌入向量是n维度的向量,那么值向量矩阵的维度是nn,非常大,通常情况下值向量矩阵参数量的大小等于查询矩阵
参数量的大小+值矩阵参数量的大小
(m的值小于n的值)。这时,为了将低值向量矩阵
n
n的参数量,可以采用大矩阵的低秩分解办法:
=
,其中
是降值矩阵,
是升值矩阵。在多头注意力机制中,多个自注意力机制的
升值矩阵会被合并成为一个输出矩阵,而这时候单个注意力机制的值矩阵往往指的是他们的降值矩阵
。
5. 多头注意力机制
多头注意力机制,就是每个自注意力机制单独计算,然后再将结果加权求和,一起改变token嵌入向量的精确度,目的是为了让嵌入向量进一步获得更加精确的嵌入向量。具体而言就是,在单个注意力网络下,
是单个注意力网络计算的结果,现在假设有
个注意力,则此时的
,即多个自注意力头叠加的结果,每个自注意力头都运行一边上面的运算,再相加即可。
6. 现代化python指南
这部分主页python专栏有更新,不赘述。
7. ResNet残差网络
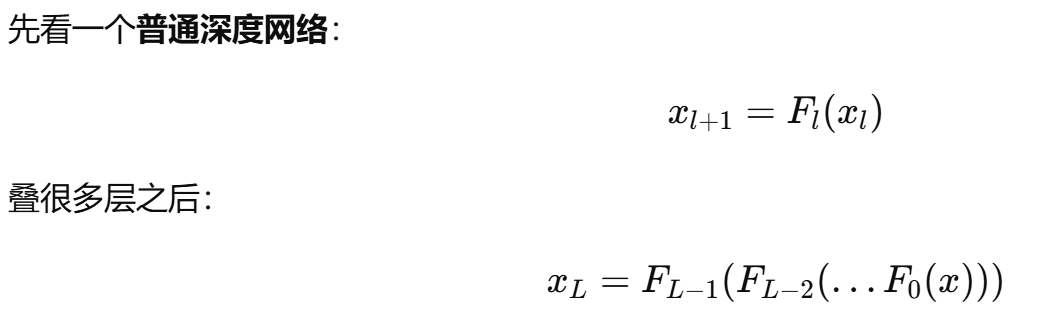
普通网络经过很多层后,在反向传播中,容易出现梯度爆炸或者梯度消失的问题。
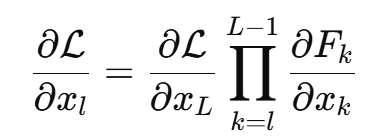
ResNet的思想是学习的不是完整的函数隐射关系 ,而是将其转化为学习映射关系与自变量之间的偏移量
,那么该问题就转化为
![]()

是单位矩阵

原始信息可以不经过任何中间权重矩阵变换直接传播到最低层,一定程度上可以缓解梯度消失的问题。
8. 文本编码 和 tokenizer
[学完代码再学这个]
① ASCII、Unicode 和 UTF- 8
② BPE算法原理和训练实现
③ 完整 tokenizer 类的封装
9. embedding模块
[学完代码再学这个]
一、Minimind架构图
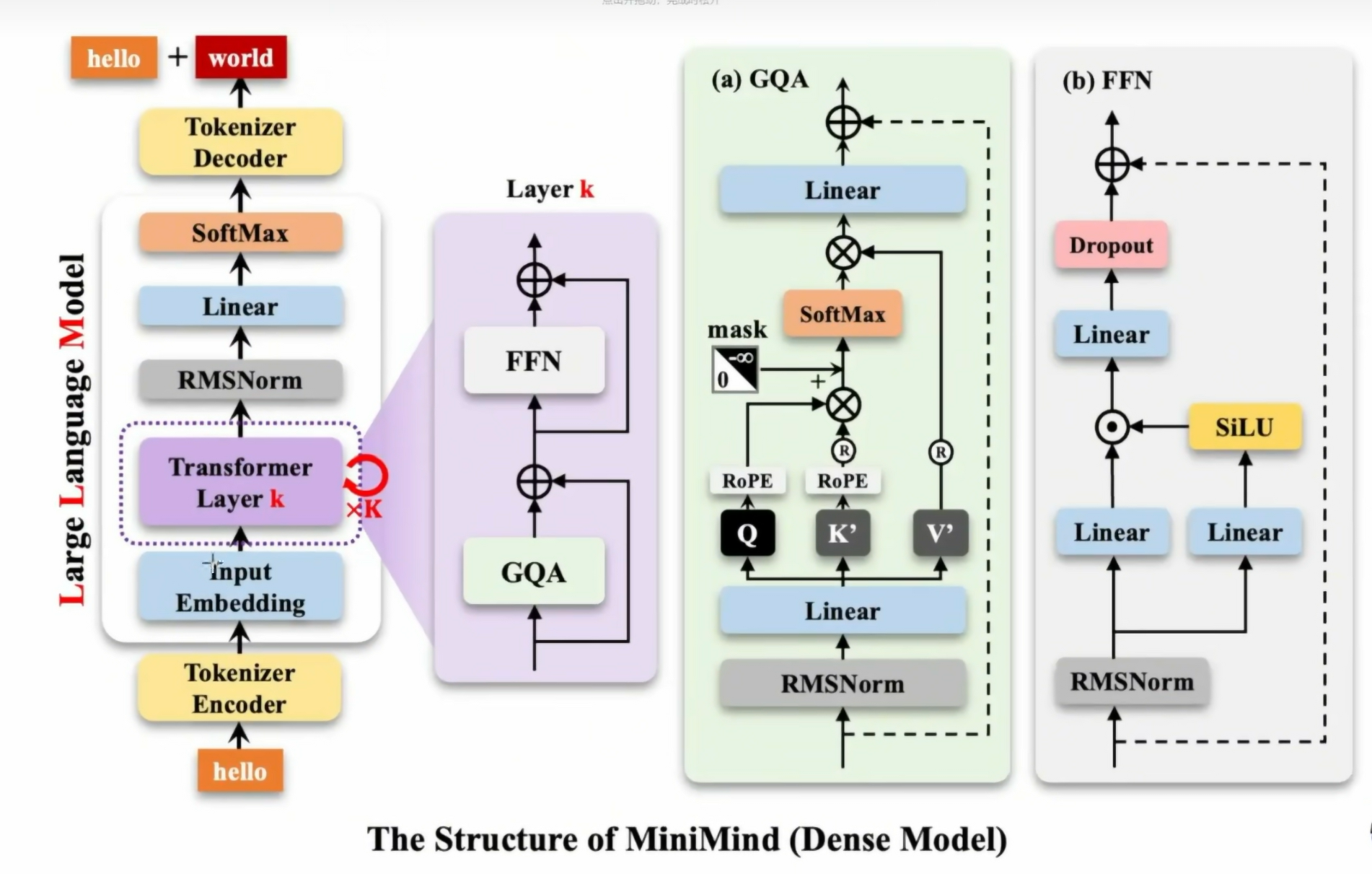
二、RMSNorm
RMSNorm & layerNorm 二者都是为了避免在对权重求梯度下降时,网络因输入的数或按或小,而产生的梯度下降或梯度消失问题。
layerNorm:对token的特征向量每个特征维度的数值进行归一化
![]()
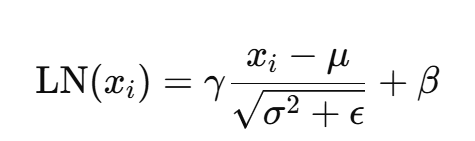
其中,
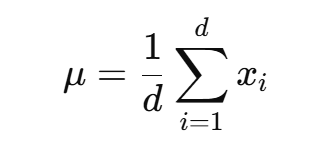
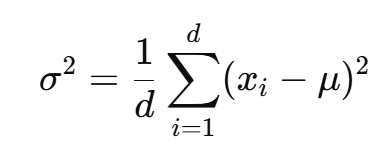
γ,β是可学习参数,ϵ 是极小的数,作为数值稳定项
RMSNorm:与layerNorm功能类似,核心思想是不减均值,只用均方根来缩放,导致归一化的公式不一样:
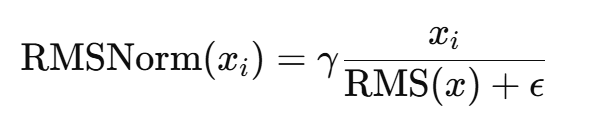 ,其中
,其中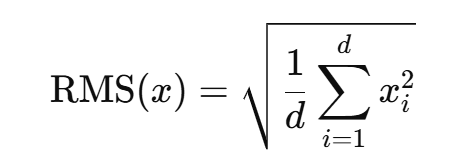
通常没有 β(均值偏置) ,只有一个缩放参数 γ(方差偏置),ϵ 是极小的数,作为数值稳定项
可以这样做的理由是:
-
在深层 Transformer 中:激活的 均值偏移并不是主要问题,幅值(scale)不稳定 才是训练的核心难点
-
RMSNorm:只控制向量的 整体能量(L2 范数),已经足够稳定训练
-
去掉均值和 β:参数更少,计算更快,推理更友好
代码:
import torch
import torch.nn as nn
# 继承nn.Module类
class RMSNorm(nn.Module):
# __init__方法,初始化参数
def __init__(self, dim: int, eps: float = 1e-8):
super().__init__()
self.dim = dim
self.eps = eps
self.scale = nn.Parameter(torch.ones(dim))
# normalize方法,进行归一化计算
def _norm(self, x ):
return x * torch.rsqrt(x.pow(2).norm(2, dim=-1, keepdim=True) + self.eps)
# forward方法,定义前向传播逻辑
def forward(self, x):
return self.scale * self._norm(x.float()).type_as(x)三、RoPE&YaRN
RoPE
为什么需要位置信息?
简单来说,在注意力机制中,如果计算一个token与另一个token的点积的话,即计算二者之间的注意力分数,那么当这两个token的特征向量一旦确定,那它们的点积结果,是不随这个两个token在句子中的位置变化而发生改变,其实这个现象也叫做自注意力的置换不变性。
但是不同token在句子中的未知不同,会表现出不同的语义,如果只用上面那种自注意力机制的话,就会因为无法获取位置信息,而丢失对句子的部分理解,所以这个时候位置编码的出现就是为了解决无法获取位置信息的问题。
2D旋转矩阵
引入坐标旋转方法来表示位置信息,(这里介绍完原理之后,回答为什么旋转位置编码的方法,能够表征位置信息),先从最简单的2D旋转矩阵开始说起:
已知原始向量,给定幅值 A ,方向角 θ :
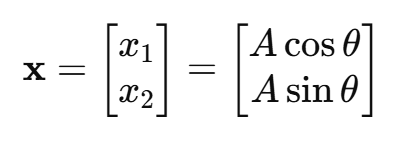
逆时针旋转 θ′ 后的方向角变为:
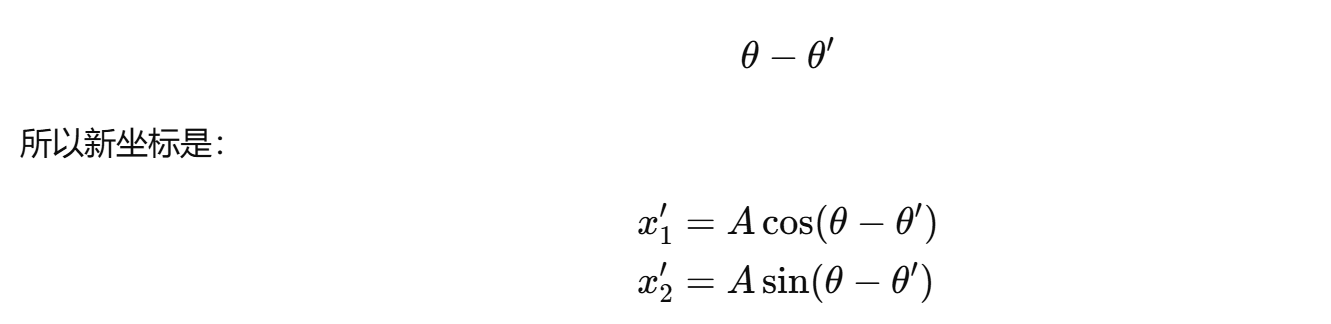
代入正余弦差角公式得:
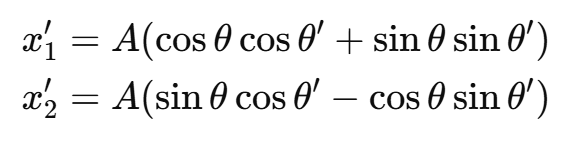
把原坐标![]() 换回得:
换回得:
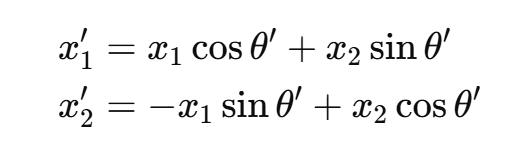
把上面两行合并成一个矩阵乘法:
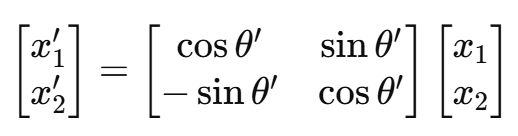
所以综上所述,一个2维向量 ,其在平面内旋转角度
的矩阵是:
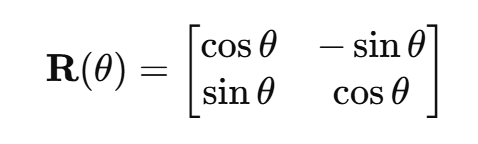
旋转后的向量是:
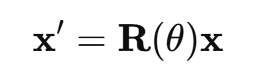
n阶RoPE旋转矩阵
由于token的特征向量往往是高纬度的,所以在2D旋转矩阵的基础上,拓展出n阶旋转矩阵。这个n阶的旋转矩阵只对查询向量Q和键向量K作用,而不对值向量V作用,就相当于只对查询矩阵Q和键矩阵K进行坐标变换。
关于为什么旋转矩阵只对查询向量Q和键向量K作用,而不对值向量V作用,这里笔者有自己的理解:我的想法是,V是与原始token特征向量维度相同的向量,V完全保留了原始token的语义信息,然后Q和K的点积得到的权重,相当于是对原始token的语义影响,(理解为影响是觉得后面还有加权求和的操作),然后这个影响,就Q和K点积的权重,是由两部分组成语义信息和位置信息,这两个都是其他token对原来token的影响,所以不包括在V中。然后,位置信息修饰其实就是对语义信息的修正。语义信息和位置信息是捆绑在一块的,就(甲打乙)和(乙打甲),就是因为位置变了所以语义变了,所以从某种意义上说,位置信息是对原来语义信息的修正。那么当K和Q在进行位置编码时,其实就相当于在原有的语义信息上,完成了这种修正,即在原来语义信息基础上,加上了另一种特殊的语义信息——位置信息。
所以用RoPE 对 Query / Key 的作用可以用公式表示为(以Query 向量 为例):

其中,定义每个子空间定义旋转角度是这样的,以第 i 个 token,在第 k 个二维子空间的旋转角度为例:
![]()
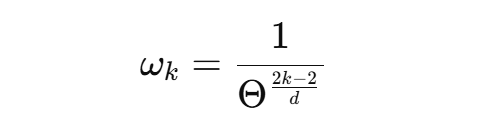
d 表示 Query / Key 向量的维数,i 表示 token在序列中所属的序号,Θ 是一个常数,通常取 10000 , 表示不同维度对应的旋转频率,k表示划分后的第k个2阶数旋转矩阵的序号,k=1,2,…,d/2,可以看到随着 k 的增加,
的数值不断减小,即旋转角度 θ 增加速度变慢,向量在二维平面上沿圆周旋转速度变慢。这时,旋转角度 θ变化快的叫高频,变化慢的叫低频,可以看见 k 值越小时,频率越高, k 值越大时,频率越低。由于这个特性,赋予了旋转位置编码(RoPE)的多尺度感知能力,即低频子空间只有距离较大时才能感知,属于慢变化,高频子空间距离较小便能感知,但容易出现周期幻觉。相同维度k下,相邻token间相差角度是
。
为什么旋转位置编码的方法,能够表征位置信息:
因为经过相对位置编码后的Query / Key向量再进行点积时,可以得到
![]()
该点积自然包含了Query / Key向量间的相对角度 ,因此,通过旋转位置编码让自注意力权重隐式编码了 token 相对位置,无需显式增加位置信息向量。
旋转位置编码(RoPE)随距离衰减:RoPE 的“随距离衰减”的这个特质是符合直觉的,因为远距离的文本对token的影响很小,文本与token越近时,影响越大。当Q与K是全为一的向量,他们的注意力分数可以简化为下面公式,
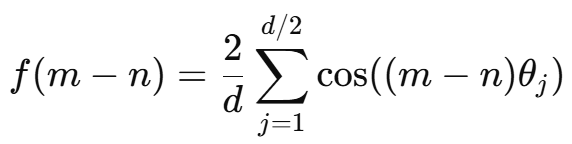
公式只依赖 相对位置 ,
时,表示相对位置为零,即自己,所以所有维度方向一样,相当于没有角度差,注意力分数
达到峰值
很大时,表示相对位置很远,距离很远的文本信息,这时注意力分数函数
处在高频,快速振荡,高频子空间点积对长距离有自然抵消的现象,注意力分数较小,从而达到远距离的文本对token的影响很小,文本与token越近时,影响越大。
旋转位置编码(RoPE)的外推性:

![]()
因为旋转位置编码的注意力分数计算只依赖token间的相对位置,而不是绝对位置,所以只要旋转公式可以计算,注意力分数依旧正确,训练长度限制不会影响公式本身的计算。

稀疏旋转矩阵的代码表示:
在数学推导中,RoPE 的旋转矩阵常被写成:
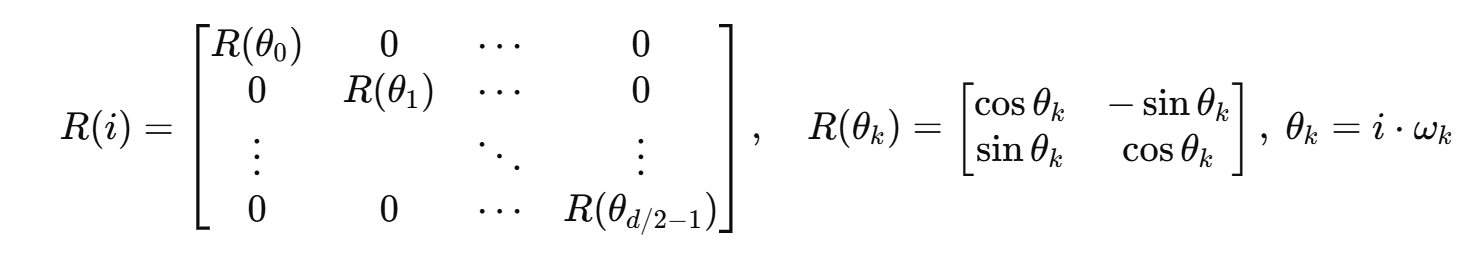
这是一个 的块对角矩阵,这个旋转矩阵是高度稀疏的矩阵,在计算和存储时需要占用大量空间,在工程中是不会使用的,计算
![]()
时,时间复杂度为 ,即
,
是
维向量,为了得到一个维度的数值,每个维度计算时,都需要计算
次乘法和
次加法,一共有
个维度,则共需计算
次。
工程实现 (写代码的时候) 则把“矩阵乘法”展开成逐元素公式:
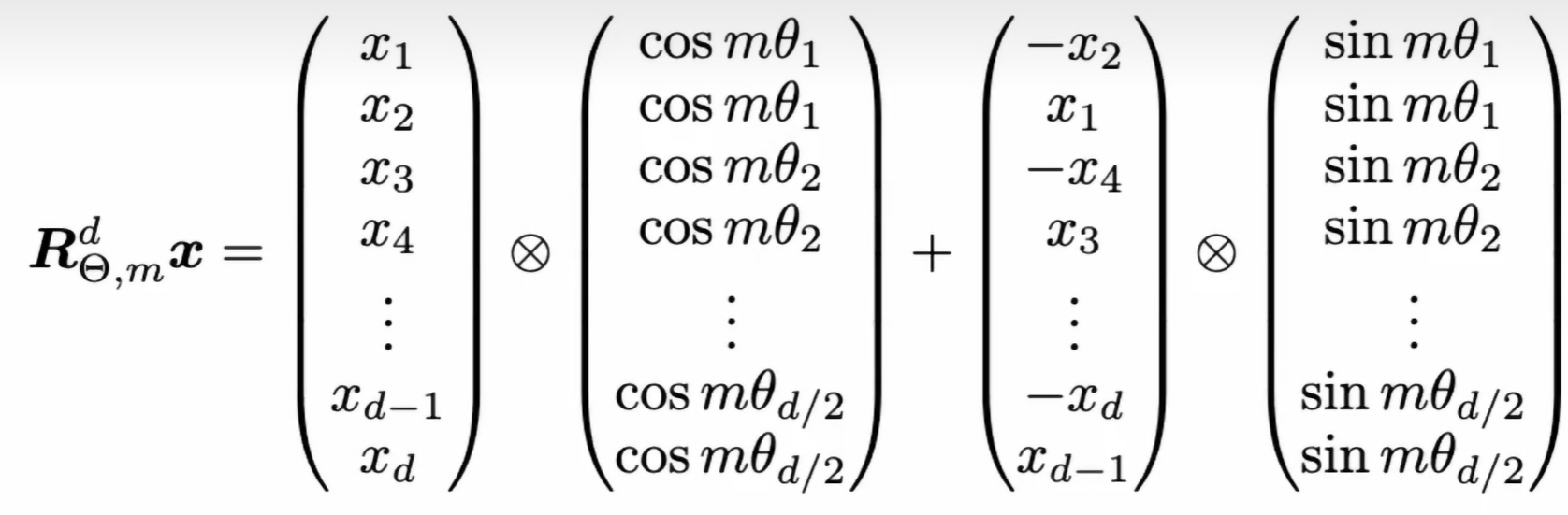
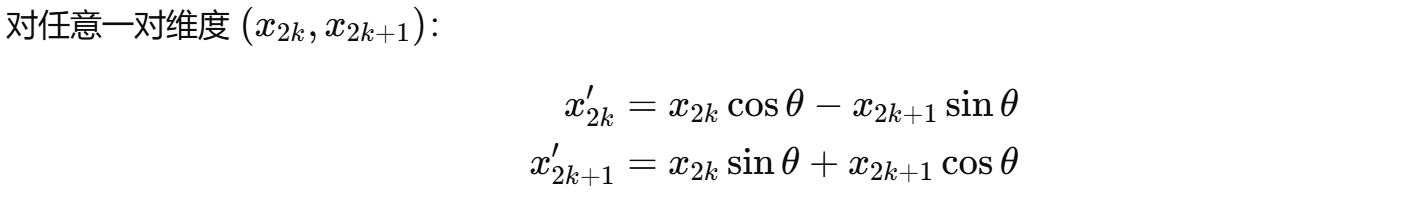
整理后,偶数维: ,奇数维:
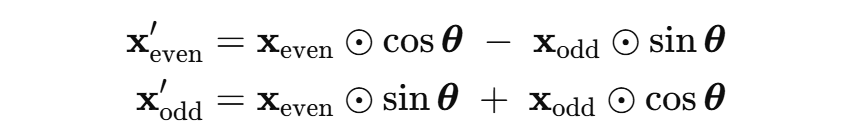
计算的时间复杂度为 ,
次乘法,
次加法,时间复杂度是
级别。
YaRN
对下面公式中的 做了如下改进,改进其实就是完成对
的放缩操作:
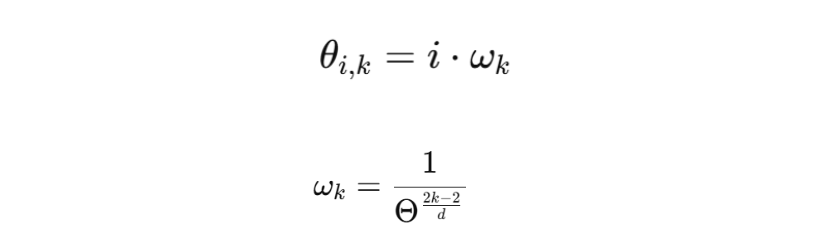
minimind中的YaRN改进:
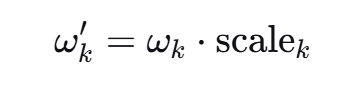
根据上面公式,对 进行放缩操作,缩放因子如下,

其中, 和
可通过如下计算得到:
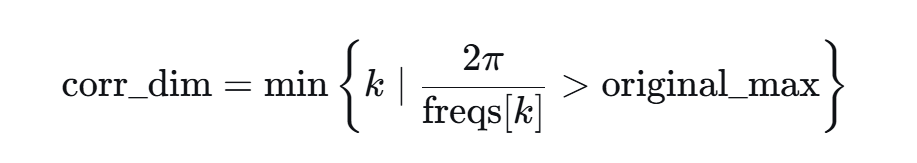
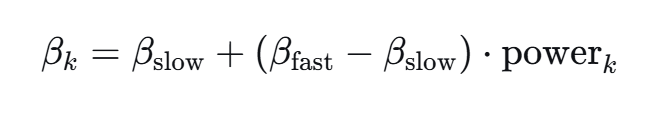
中的
则通过下面式子得到:
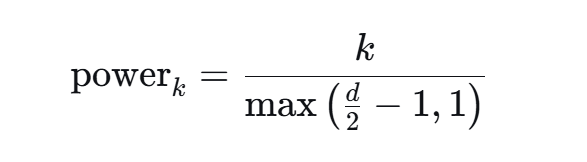
式子中的 、
、
、
(代码中的 factor 变量),在代码中均由rope_scaling统一配置,他们都是在modle.py文件下面的class MokioMindConfig(PretrainedConfig)类里面定义的,用的参数是按照Hugging Face Transformers 库中的模型配置类来确定的,用的时候直接通过下面代码获取就好了。
if rope_scaling is not None:
orig_max,factor,beta_fast,beta_slow=(
rope_scaling.get("original_max_position_embeddings",2048),
rope_scaling.get("factor",4),
rope_scaling.get("beta_fast",4),
rope_scaling.get("beta_slow",1),
)
代码:
def precompute_freqs_cis(dim:int,
end:int=int(32*1024),
rope_base:float=1e6,
rope_scaling:Optional[dict] = None,
):
# 写出最初RoPE式子
freqs = 1.0 / (rope_base ** (torch.arange(0, dim, 2)[: dim // 2].float() / dim))
if rope_scaling is not None:
orig_max,factor,beta_fast,beta_slow=(
rope_scaling.get("original_max_position_embeddings",2048),
rope_scaling.get("factor",4),
rope_scaling.get("beta_fast",4),
rope_scaling.get("beta_slow",1),
)
if end / orig_max < 1.0:
# 计算corr_dim
corr_dim = next((i for i in range(dim // 2) if 2 * math.pi / freqs[i] > orig_max), dim // 2)
# 计算power
power = torch.arange(0,dim//2,device=freqs.device).float()/(max(dim//2 -1,1))
# 计算计算beta
beta = beta_slow + (beta_fast - beta_slow) * power
# 计算scale
scale = torch.where(
torch.arange(dim//2,device=freqs.device) < corr_dim,
(beta * factor - beta + 1) / (beta * factor),
1.0 / factor
)
# 应用scale
freqs = freqs * scale
#生成位置索引
t = torch.arange(end, device=freqs.device)
freqs = torch.outer(t, freqs).float()
# 返回一个cos和sin
freqs_cos = torch.cos(freqs).repeat_interleave(2, dim=-1)
freqs_sin = torch.sin(freqs).repeat_interleave(2, dim=-1)
return freqs_cos, freqs_sin
def apply_rotary_pos_emb(q,k,cos,sin,unsqueeze_dim = 1):
def rotate_half(x):
x1,x2 = x[...,::2], x[...,1::2]
return torch.stack((-x2,x1),dim=-1).flatten(-2)
q_embed = (q * cos.unsqueeze(unsqueeze_dim)) + (rotate_half(q) * sin.unsqueeze(unsqueeze_dim))
k_embed = (k * cos.unsqueeze(unsqueeze_dim)) + (rotate_half(k) * sin.unsqueeze(unsqueeze_dim))
return q_embed, k_embed
四、GQA
理解了上面的Attention机制,这部分比较好懂,Multi-head (MHA) 相当于是Queries、Keys、Values这三这的权重参数矩阵,即 、
、
这三者权重参数矩阵的数量是相同的,且权重信息不共享,Multi-query (MQA) 就是多个
之间参数信息不共享,但是
和
之间的多个参数矩阵是共享权重的,所以就可以等效的看成是只用了一个权重参数矩阵。由此类推,看图可知,GQA是一种介于 MHA 和 MQA 之间的状态。
那么,为什么Keys和Values之间的参数矩阵可以共享参数,而Queries的参数矩阵不可以共享参数?Keys 和 Values 可以共享,因为它们只是被 Query 加权的“静态表征”,共享不会破坏多样性。Queries 不可以共享,因为每个 Query 决定了注意力模式,多头/多组需要独立的 Query 来捕捉不同模式。
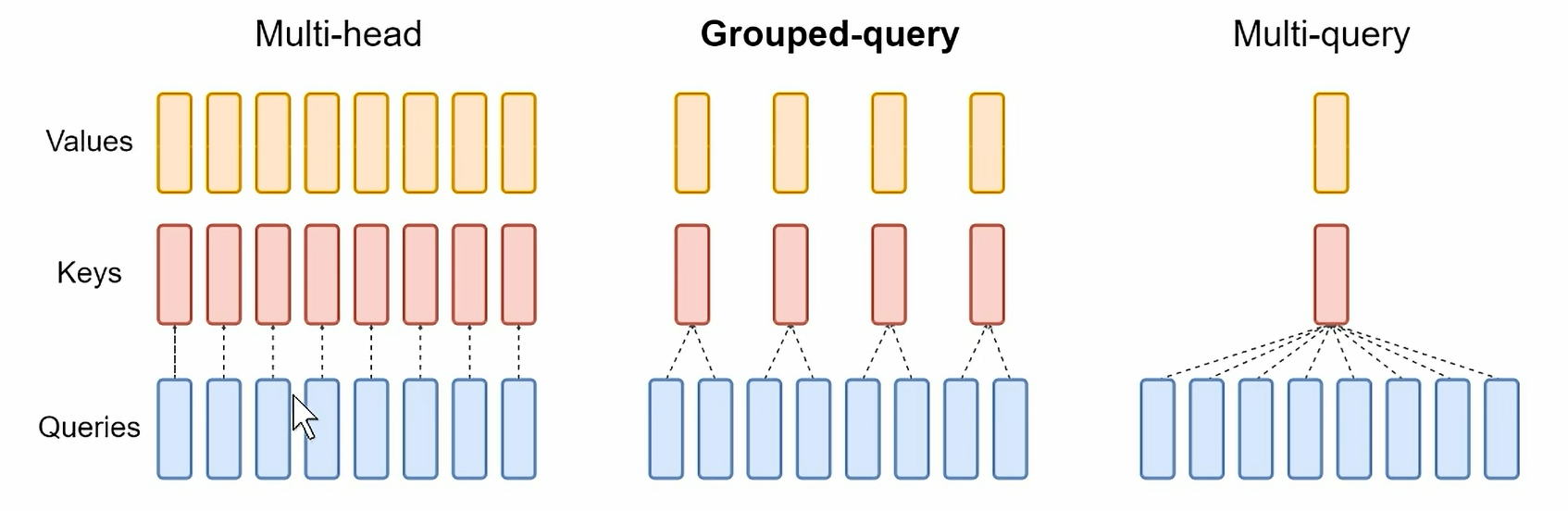
而在Minimind中使用到的就是GQA的方法,采用4个Q共用一个K和V,代码如下:
代码1:
def repeat_kv(x:torch.Tensor,n_rep:int)->torch.Tensor:
bs,slen,num_key_value_heads,head_dim = x.shape
if n_rep == 1:
return x
return (
x[:,:,:,None,:]
.expand(bs,slen,num_key_value_heads,n_rep,head_dim)
.reshape(bs,slen,num_key_value_heads * n_rep, head_dim)
)
class Attention(nn.Module):
def __init__(self,args:MokioMindConfig):
super().__init__()
self.num_key_value_heads = (args.num_attention_heads
if args.num_key_value_heads is None
else args.num_key_value_heads
)
assert args.num_attention_heads % self.num_key_value_heads == 0,(
"num_attention_heads must be divisible by num_key_value_heads")
self.n_local_heads = args.num_attention_heads
self.num_key_value_heads = args.num_key_value_heads
self.n_rep = self.n_local_heads // self.num_key_value_heads
self.head_dim = args.hidden_size // args.num_attention_heads # 计算每个头的维度
self.q_proj = nn.Linear(args.hidden_size,args.num_attention_heads * self.head_dim,bias=False)
self.k_proj = nn.Linear(args.hidden_size,self.num_key_value_heads * self.head_dim,bias=False)
self.v_proj = nn.Linear(args.hidden_size,self.num_key_value_heads * self.head_dim,bias=False)
self.o_proj = nn.Linear(args.num_attention_heads * self.head_dim,args.hidden_size,bias=False)
self.attn_dropout = nn.Dropout(args.dropout)
self.resid_dropout = nn.Dropout(args.dropout)
self.dropout = args.dropout
self.flash = hasattr(torch.nn.functional, "scaled_dot_product_attention") and args.flash_attention
上面这段代码中涉及到的两个类分别实现:重复的方法 和 Attention机制的参数定义,其中

nn里面的方法:
(1)dropout:使用的dropout方法防止过拟合,只在训练过程中使得部分神经元失活,在测试和验证时,所有神经元均处于激活状态。

(2)linear:完成一次维度的线性变换(eg :三维到五维),w 和 b 均是可调参数
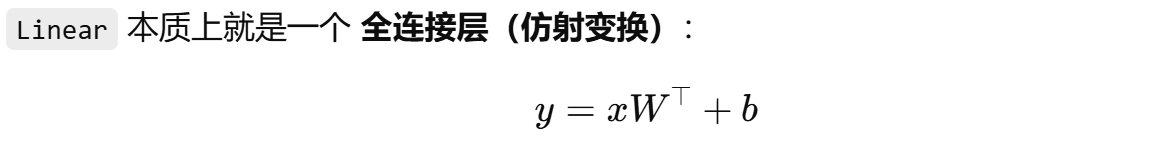
代码2:
def forward(
self,
x: torch.Tensor,
position_embeddings:Tuple[torch.Tensor,torch.Tensor],
past_key_value:Optional[Tuple[torch.Tensor,torch.Tensor]]=None,
use_cache =False,
attention_mask:Optional[torch.Tensor]=None,
) ->torch.Tensor:
# 投影,计算q,k,v
bsz,seq_len,_ = x.shape
xq,xk,xv = self.q_proj(x), self.k_proj(x), self.v_proj(x)
# 把输入拆分成多个头,用view
xq = xq.view(bsz,seq_len,self.n_local_heads,self.head_dim)
xk = xk.view(bsz,seq_len,self.num_key_value_heads,self.head_dim)
xv = xv.view(bsz,seq_len,self.num_key_value_heads,self.head_dim)
# q和k,使用 roPE
cos,sin = position_embeddings
xq,xk = apply_rotary_pos_emb(xq,xk,cos[:seq_len],sin[:seq_len])
# 对于 k 和 v ,使用repeat(注意kv cache)
if past_key_value is not None:
xk = torch.cat([past_key_value[0],xk],dim=1)
xv = torch.cat([past_key_value[1],xv],dim=1)
past_kv = (xk,xv) if use_cache else None
xq,xk,xv =(
xq.transpose(1,2),
# bsz, n_heads, seq_len, head_dim
repeat_kv(xk,self.n_rep).transpose(1,2),
repeat_kv(xv,self.n_rep).transpose(1,2),
)
# 进行attention计算,q@k^T / sqrt(d)
if self.flash and seq_len > 1 and (attention_mask is None or torch.all
(attention_mask == 1)):
attn_mask =(
None
if attention_mask is None
else attention_mask.view(bsz,1,1,-1).expand(bsz,self.n_local_heads,
seq_len,-1).bool()
)
output = F.scaled_dot_product_attention(xq,xk,xv,attn_mask=attn_mask,
dropout_p = self.dropout if self.training else 0.0,is_causal=True)
else:
scores = (xq @ xk.transpose(-2,-1)) / math.sqrt(self.head_dim)
scores = scores + torch.triu(
torch.full((seq_len,seq_len),float("-inf"),device = scores.device),
diagonal=1
).unsqueeze(0).unsqueeze(0)
# 最后拼接头,输出投影,返回
if attention_mask is not None:
extended_attention_mask = attention_mask.unsqueeze(1).unsqueeze(2)
extended_attention_mask = (1.0 - extended_attention_mask) * -1e9
scores = scores + extended_attention_mask
scores = F.softmax(scores.float(),dim=-1).type_as(xq)
scores = self.attn_dropout(scores)
output = scores @ xv
# [bsz, n_heads, seq_len, head_dim]
output = output.transpose(1,2).reshape(bsz,seq_len,-1)
output = self.resid_dropout(self.o_proj(output))
return output, past_kv这段代码是接着代码1的,实现的是 forward 向前传播
xq,xk,xv =(
xq.transpose(1,2),
# bsz, n_heads, seq_len, head_dim
repeat_kv(xk,self.n_rep).transpose(1,2),
repeat_kv(xv,self.n_rep).transpose(1,2),
)
上面代码实现原来维度中的 n_heads 和 seq_len 的位置交换,因为pytorch中,前两个维度代表次数,后两个维度代表计算。

Attention 这部分终于看完了/(ㄒoㄒ)/~~
五、FFN
之前写的忘记保存了,我哭死。。。
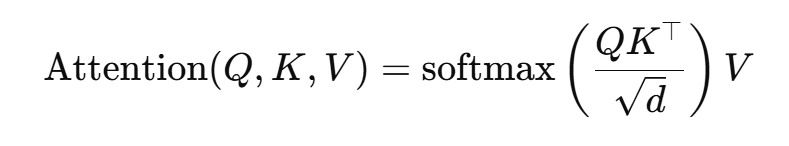
为什么需要FFN,FFN 与 attention 有什么区别?attention 是 V 的线性组合,只是把已有 token 的表示 按权重混合,不会创造新特征,使得模型的表达能力极弱。FFN 则通过引入激活函数和门控单元等机制,使得模型选择和过滤特征,具有更强表现力。
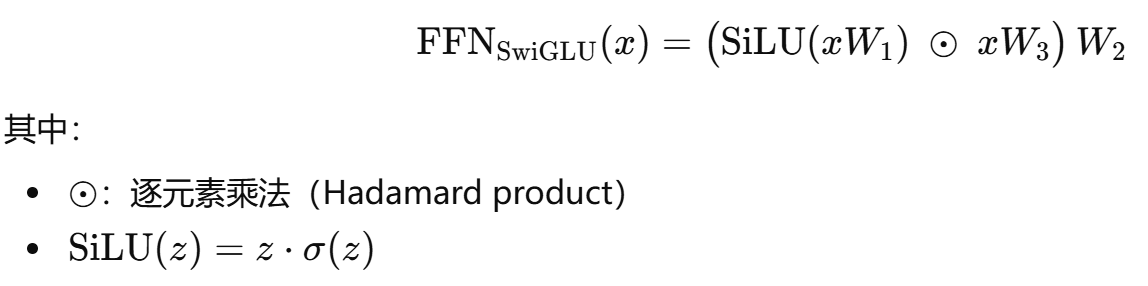
SwiGLU FFN 与传统的FFN不同,传统FFN的表达如下所示,是由两个Linear 层,中间夹一个激活函数组成:
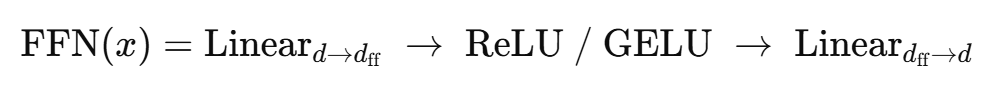
前一个Linear层的作用是升纬,将维度升至原来的4倍,后一个Linear层的作用是降维,将维度降到与原来相同的维度。因此,传统FFN的参数量可计算为
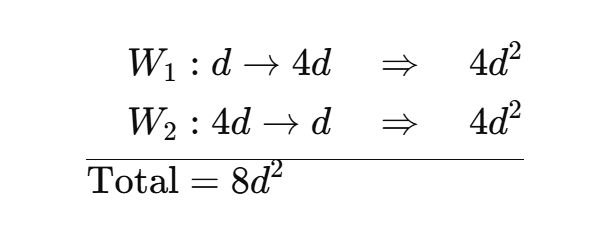
SwiGLU FFN 改进了这种升维,再降维的机制,有一种说法是将其与 attention 机制对比理解的,比较有意思,内容大致如下:
SwiGLU FFN和attetion 机制本质上是相似的, 部分类似于 attention 中求的注意力分数,
则代表 attention 中的 V,意味着保留了原始 token 的特征,而
本质上也是一种线性叠加,只不过这种线性叠加,受到 门控机制
激活函数的影响。其中,
和
是升维矩阵,将维度升为原来token维度的
倍,
是降维矩阵,将维度降到与原来token 相同的维度。
为什么将维度升为原来token维度的 倍?
因为 SwiGLU 的中间维度取 倍时,在参数量不变的情况下,能够获得更强的表达能力。

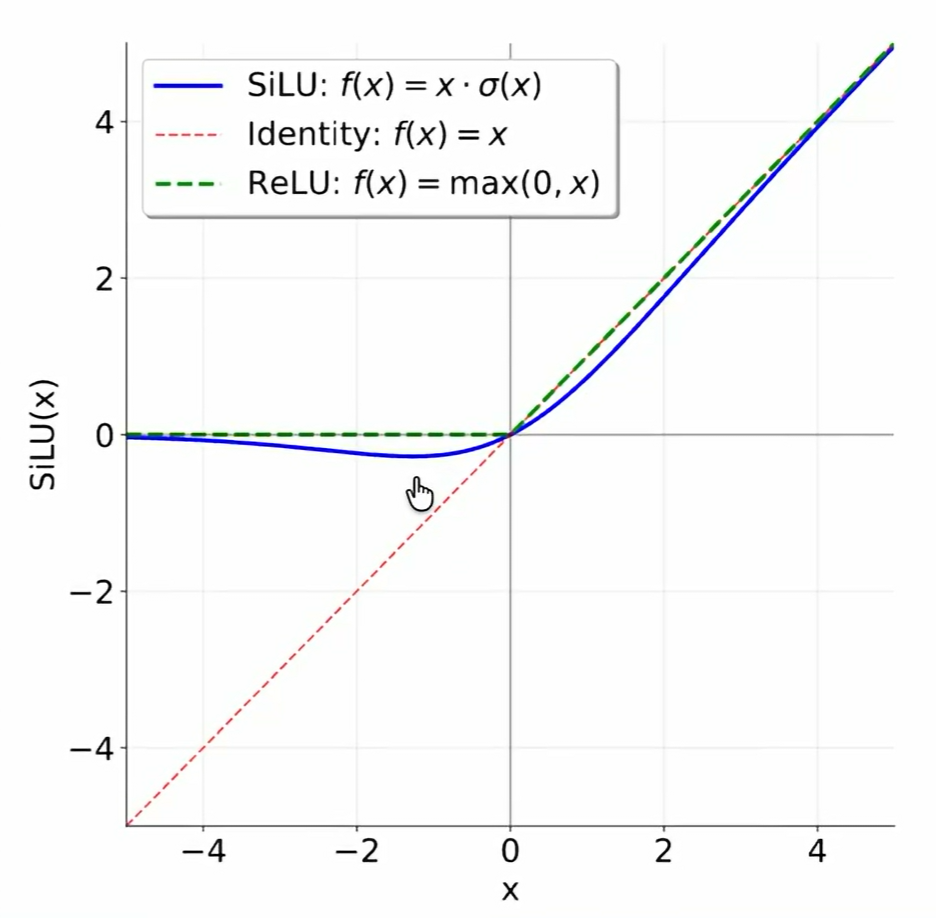
SiLU
与传统的FFN不同,SwiGLU FFN使用的激活函数是SiLU,而不是ReLU,原因如下:
在传统 FFN 中常用 ReLU 作为激活函数,但 ReLU 在 x<0 时输出恒为 0,梯度也为 0,容易导致部分神经元在训练过程中“死亡”(dying ReLU),从而影响模型的表达能力和梯度传播。而 SwiGLU 中使用的 SiLU,在 x<0 时,输出为接近 0 但不恒等于 0,梯度连续且非零。因此,梯度传播更稳定,门控信号更平滑,有利于深层 Transformer 的训练 。
代码:
class FeedEorward(nn.Module):
# 初始化
# 升维
# 降维
# 门控
# dropout
# 激活函数
def __init__(self,args:MokioMindConfig):
super().__init__()
if args.intermediate_size is None:
intermediate_size = int(args.hidden_size * 4)
args.intermediate_size = 64 * ((intermediate_size + 64 -1)//64)
self.up_proj = nn.Linear(args.hidden_size,args.intermediate_size,bias=False)
self.down_proj = nn.Linear(args.intermediate_size,args.hidden_size,bias=False)
self.gate_proj = nn.Linear(args.hidden_size,args.intermediate_size,bias=False)
self.dropout = nn.Dropout(args.dropout)
self.act_fn = ACT2FN[args.hidden_act]
def forward(self,x):
gated = self.act_fn(self.gate_proj(x))*self.up_proj(x)
return self.dropout(self.down_proj(gated))
六、拼接:Block
这部分没有理论知识,理解代码就行了,代码是把 attention 和 FFN 部分封装在了一起。
代码:
class MokioMindBlock(nn.Module):
def __init__(self,layer_id:int,config:MokioMindConfig):
super().__init__()
self.config = config
self.num_attention_heads = config.num_attention_heads
self.hidden_size = config.hidden_size
self.head_dim = self.hidden_size // self.num_attention_heads
self.self_attn = Attention(config)
self.layer_id = layer_id
self.input_layernorm = RMSNorm(config.hidden_size,eps=config.rms_norm_eps)
self.post_attention_layernorm = RMSNorm(config.hidden_size,eps=config.rms_norm_eps)
self.mlp = FeedEorward(config)
def forward(
self,
hidden_states,
position_embeddings,
past_key_value=None,
use_cache=False,
attention_mask=None):
residual = hidden_states
hidden_states,present_key_value = self.self_attn(
self.input_layernorm(hidden_states),
position_embeddings,
past_key_value,
use_cache,
attention_mask,
)
hidden_states = residual + hidden_states
hidden_states = hidden_states + self.mlp(
self.input_layernorm(hidden_states)
)
return hidden_states, present_key_value七、组装:Model
无理论,Model 封装到 RMSNorm ,理解代码就行。
代码:
class MokioMindModel(nn.Module):
def __init__(self,config:MokioMindConfig):
super().__init__()
self.vocab_size,self.num_hidden_layers = (
config.vocab_size,
config.num_hidden_layers,
)
self.embed_tokens = nn.Embedding(
config.vocab_size,config.hidden_size
)
self.dropout = nn.Dropout(config.dropout)
self.layers = nn.ModuleList(
[MokioMindBlock(i,config) for i in range(config.num_hidden_layers)]
)
self.norm = RMSNorm(config.hidden_size,eps=config.rms_norm_eps)
# RoPE 预计算
freqs_cos, freqs_sin = precompute_freqs_cis(
dim = config.hidden_size // config.num_attention_heads,
end = config.max_position_embeddings,
rope_base = config.rope_theta,
rope_scaling = config.rope_scaling,
)
self.register_buffer("freqs_cos",freqs_cos, persistent = False)
self.register_buffer("freqs_sin",freqs_sin, persistent = False)
def forward(
self,
input_ids:Optional[torch.Tensor]=None,
attention_mask:Optional[torch.Tensor]=None,
past_key_values:Optional[Tuple[Tuple[torch.Tensor]]]=None,
use_cache:bool=False,
**kwargs,
):
batch_size,seq_len = input_ids.shape
if hasattr(past_key_values,"layers"):
past_key_values = None
past_key_values = past_key_values or [None] * len(self.layers)
start_pos=(
past_key_values[0][0].shape[1] if past_key_values[0] is not None else 0
)
hidden_states = self.dropout(self.embed_tokens(input_ids))
position_embeddings = (
self.freqs_cos[start_pos : start_pos + seq_len],
self.freqs_sin[start_pos : start_pos + seq_len],
)
Presents = []
for layer_idx,(layer,past_key_value) in enumerate(
zip(self.layers,past_key_values)
):
hidden_states, present = layer(
hidden_states,
position_embeddings,
past_key_value=past_key_value,
use_cache=use_cache,
attention_mask=attention_mask,
)
Presents.append(present)
hidden_states = self.norm(hidden_states)
return hidden_states,Presents
八、组装:CausalLM
代码:
class MokioMindForCausalLM(PreTrainedModel,GenerationMixin):
config_class = MokioMindConfig
def __init__(self,config:MokioMindConfig):
self.config = config
super().__init__(config)
self.model = MokioMindModel(config)
self.lm_head = nn.Linear(
self.config.hidden_size,self.config.vocab_size,bias=False
)
# 权重共享
# 输出层权重与输入嵌入层权重共享
self.model.embed_tokens.weight = self.lm_head.weight
def forward(
self,
input_ids:Optional[torch.Tensor]=None,
attention_mask:Optional[torch.Tensor]=None,
past_key_values:Optional[Tuple[Tuple[torch.Tensor]]]=None,
use_cache:bool = False,
logits_to_keep:Union[int,torch.Tensor]=0,
**args
):
hidden_states, past_key_values = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
past_key_values=past_key_values,
use_cache=use_cache,
**args,
)
# logits_to_keep 是整数,那就保留最后n个位置
# 生成的时候只需要最后的logits来预测下一个token
slice_indices = (
slice(-logits_to_keep, None)
if isinstance(logits_to_keep, int)
else logits_to_keep
)
# hidden_states: [bsz, seq_len, hidden_size]
logits = self.lm_head(hidden_states[:, slice_indices, :])
return CausalLMOutputWithPast(
logits=logits,
past_key_values=past_key_values,
hidden_states=hidden_states,
)九、张量变换全流程

十、Dataset
自回归:基于之前的 token 和之前预测出来的 token 预测下一个 token
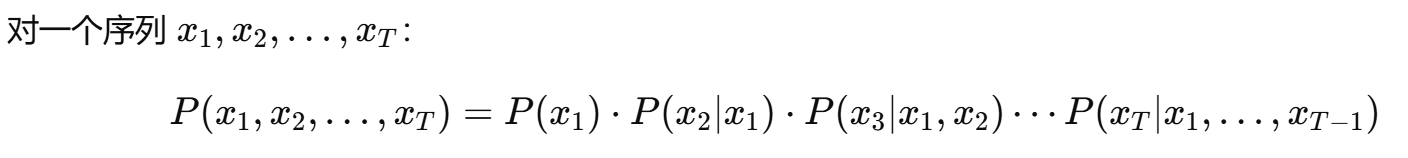
损失掩码:padding 为了让不同长度的数据“对齐”,人为补一些“没意义的占位符”,像 <pad> 。
“损失掩码(loss mask)”就是告诉模型“哪些位置的 loss 要算(标记为1),哪些不用算(标记为0)”,占位符” <pad> 处标记为0。
padding 示例
输入:
句子1:我 爱 NLP
句子2:我 爱padding 后:
句子1:我 爱 NLP
句子2:我 爱 <pad>loss mask:
句子1:1 1 1
句子2:1 1 0
注:<pad> 位置 不参与 loss 计算。
代码:
import json
from torch.utils.data import Dataset
import torch
import os
# 设置 okenizer 不并行加速,避免报错
os.environ["TOKENIZERS_PARALLELISM"] = "false"
# 先写dataset类
class PretrainDataset(Dataset):
def __init__(self, data_path, tokenizer, max_length=512):
super().__init__()
self.tokenizer = tokenizer
self.max_length = max_length
self.samples = self.load_data(data_path)
# 实现dataset内定的方法
def load_data(self, path):
samples = []
with open(path, 'r', encoding='utf-8') as f:
for line_num, line in enumerate(f,1):
data = json.loads(line.strip())
samples.append(data)
return samples
# _len_
def __len__(self):
return len(self.samples)
# __getitem_
def __getitem__(self, index):
sample = self.samples[index]
encoding = self.tokenizer(
str(sample['text']),
max_length=self.max_length,
padding='max_length',
truncation=True,
return_tensors='pt'
)
# (max_length,)
input_ids = encoding['input_ids'].squeeze()
# 损失掩码
loss_mask = input_ids != self.tokenizer.pad_token_id
# 自回归
X = torch.tensor(input_ids[:-1], dtype=torch.long)
Y = torch.tensor(input_ids[1:], dtype=torch.long)
loss_mask = torch.tensor(loss_mask[1:], dtype=torch.long)
return X, Y, loss_mask十一、Pretrain
预训练:指模型在大规模通用数据上,从随机初始化开始,通过完整的前向与反向传播过程学习通用表示;预训练之后的训练,像微调,是在预训练参数的基础上,继续进行完整的反向传播和参数更新,以适配具体下游任务。
预训练过程使用到的动态学习率公式为:
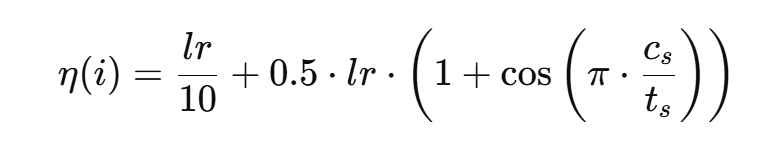

当模型训练时,分为多个 batch 时,loss 的计算,如下所示:
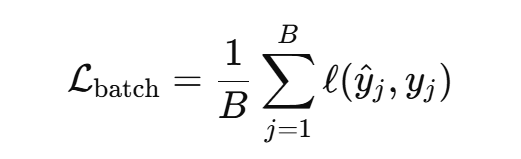
Batch 表征每次喂给模型的数据集大小,Epoch 用来表征整个训练集被完整喂给模型的次数。
代码:
import os
import sys
__package__ = "trainer"
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
import argparse # 命令行参数解析
import time # 时间统计
import warnings # 警告控制
import torch
import torch.distributed as dist # 分布式训练支持
from contextlib import nullcontext # 上下文管理器
from torch import optim, nn # 优化器和神经网络模块
from torch.nn.parallel import DistributedDataParallel # 分布式数据并行
from torch.utils.data import DataLoader, DistributedSampler # 数据加载器
from model.MokioModel import MokioMindConfig
from dataset.lm_dataset import PretrainDataset
from trainer.trainer_utils import ( # 训练工具函数
get_lr,
Logger,
is_main_process,
lm_checkpoint,
init_distributed_mode,
setup_seed,
init_model,
SkipBatchSampler,
)
# 忽略警告信息,保持输出清洁
warnings.filterwarnings("ignore")代码主体部分,日志打印后面可以不用怎么看:
# epoch:当前训练轮数
#batch:批次
def train_epoch(epoch,loader,iters,start_step=0,wandb=None):
loss_fct = nn.CrossEntropyLoss(reduction='none')
start_time = time.time()
for step,(X,Y,loss_mask) in enumerate(loader,start = start_step + 1):
X = X.to(args.device)
Y = Y.to(args.device)
loss_mask = loss_mask.to(args.device)
lr = get_lr(epoch * iters + step, iters*args.epochs,args.learning_rate)
for param_group in optimizer.param_groups:
param_group['lr'] = lr
# 混合精度上下文训练
# float16、float32等
with autocast_ctx:
# 前向传播
res = model(X)
# 计算loss
# [batch,seq,vocab_size] -> [batch*seq,vocab_size]
loss = loss_fct(res.logits.view(-1, res.logits.size(-1)), Y.view(-1)).view(Y.size())
loss = (loss * loss_mask).sum() / loss_mask.sum()
loss = loss / args.accumulation_steps
# 反向传播
scaler.scale(loss).backward()
# 梯度下降,优化参数
if (step + 1 ) % args.accumulation_steps == 0:
scaler.unscale_(optimizer)
# 梯度裁剪
torch.nn.utils.clip_grad_norm_(model.parameters(), args.grad_clip)
scaler.step(optimizer)
scaler.update()
# 梯度为0,避免累积,节省内存
optimizer.zero_grad(set_to_none=True)
# 日志打印
if step % args.log_interval == 0 or step == iters - 1:
spend_time = time.time() - start_time
current_loss = loss.item() * args.accumulation_steps # 恢复真实损失值
current_lr = optimizer.param_groups[-1]["lr"] # 当前学习率
eta_min = spend_time / (step + 1) * iters // 60 - spend_time // 60
Logger(
f"Epoch:[{epoch + 1}/{args.epochs}]({step}/{iters}) loss:{current_loss:.6f} lr:{current_lr:.12f} epoch_Time:{eta_min}min:"
)
# 记录到实验跟踪系统
if wandb:
wandb.log(
{"loss": current_loss, "lr": current_lr, "epoch_Time": eta_min}
)
if (step % args.save_interval == 0 or step == iters - 1) and is_main_process():
model.eval() # 切换到评估模式
# 构建保存路径
moe_suffix = (
"_moe" if hasattr(lm_config, "use_moe") and lm_config.use_moe else ""
)
ckp = f"{args.save_dir}/{args.save_weight}_{lm_config.hidden_size}{moe_suffix}.pth"
# 📚 分布式模型保存知识点
# DDP模型需要通过.module访问真正的模型
if isinstance(model, torch.nn.parallel.DistributedDataParallel):
state_dict = model.module.state_dict()
else:
state_dict = model.state_dict()
# 📚 半精度保存知识点
# 将float32参数转为float16,减少存储空间
state_dict = {k: v.half() for k, v in state_dict.items()}
torch.save(state_dict, ckp)
# 保存完整训练状态
lm_checkpoint(
lm_config,
weight=args.save_weight,
model=model,
optimizer=optimizer,
scaler=scaler,
epoch=epoch,
step=step,
wandb=wandb,
save_dir="checkpoints",
)
model.train() # 恢复训练模式后面就是主函数,涉及到一些工具的使用可以直接复制粘贴。
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="MiniMind Pretraining")
# ========== 基础训练参数 ==========
parser.add_argument("--save_dir", type=str, default="out", help="模型保存目录")
parser.add_argument(
"--save_weight", default="pretrain", type=str, help="保存权重的前缀名"
)
parser.add_argument(
"--epochs", type=int, default=1, help="训练轮数(建议1轮zero或2-6轮充分训练)"
)
parser.add_argument("--batch_size", type=int, default=32, help="batch size")
parser.add_argument("--learning_rate", type=float, default=5e-4, help="初始学习率")
# ========== 硬件和性能参数 ==========
parser.add_argument(
"--device",
type=str,
default="cuda:0" if torch.cuda.is_available() else "cpu",
help="训练设备",
)
parser.add_argument("--dtype", type=str, default="bfloat16", help="混合精度类型")
parser.add_argument("--num_workers", type=int, default=1, help="数据加载线程数")
# ========== 训练策略参数 ==========
parser.add_argument(
"--accumulation_steps", type=int, default=8, help="梯度累积步数"
)
parser.add_argument("--grad_clip", type=float, default=1.0, help="梯度裁剪阈值")
parser.add_argument("--log_interval", type=int, default=100, help="日志打印间隔")
parser.add_argument("--save_interval", type=int, default=100, help="模型保存间隔")
# ========== 模型架构参数 ==========
parser.add_argument("--hidden_size", default=512, type=int, help="隐藏层维度")
parser.add_argument("--num_hidden_layers", default=8, type=int, help="隐藏层数量")
parser.add_argument(
"--max_seq_len", default=512, type=int, help="训练的最大截断长度"
)
parser.add_argument(
"--use_moe",
default=0,
type=int,
choices=[0, 1],
help="是否使用MoE架构(0=否,1=是)",
)
# ========== 数据和恢复参数 ==========
parser.add_argument(
"--data_path",
type=str,
default="dataset/pretrain_hq.jsonl",
help="预训练数据路径",
)
parser.add_argument(
"--from_weight",
default="none",
type=str,
help="基于哪个权重训练,为none则从头开始",
)
parser.add_argument(
"--from_resume",
default=0,
type=int,
choices=[0, 1],
help="是否自动检测&续训(0=否,1=是)",
)
# ========== 实验跟踪参数 ==========
parser.add_argument("--use_wandb", action="store_true", help="是否使用wandb")
parser.add_argument(
"--wandb_project", type=str, default="MiniMind-Pretrain", help="wandb项目名"
)
# 解析命令行参数
args = parser.parse_args()
# ========== 1. 初始化环境和随机种子 ==========
"""
📚 分布式训练初始化知识点:
- local_rank: 当前进程在本机上的GPU编号
- 随机种子: 确保不同进程有不同但可复现的随机序列
- 这样既保证了随机性,又保证了可复现性
"""
local_rank = init_distributed_mode()
if dist.is_initialized():
args.device = f"cuda:{local_rank}" # 分布式训练时使用对应的GPU
# 📚 随机种子设置知识点
# 不同进程使用不同的种子,避免数据采样完全相同
# 42是基础种子,每个进程加上自己的rank保证不同
setup_seed(42 + (dist.get_rank() if dist.is_initialized() else 0))
# ========== 2. 配置目录、模型参数、检查点 ==========
"""
📚 模型配置和检查点管理:
- 创建保存目录
- 构建模型配置对象
- 尝试加载断点续训数据
"""
os.makedirs(args.save_dir, exist_ok=True) # 确保保存目录存在
# 创建MiniMind模型配置
lm_config = MokioMindConfig(
hidden_size=args.hidden_size, num_hidden_layers=args.num_hidden_layers,use_moe=bool(args.use_moe)
)
# 📚 断点续训知识点
# 如果开启了断点续训,尝试加载之前的训练状态
ckp_data = (
lm_checkpoint(lm_config, weight=args.save_weight, save_dir="checkpoints")
if args.from_resume == 1
else None
)
# ========== 3. 设置混合精度 ==========
"""
📚 混合精度训练知识点:
- bfloat16: Google开发,数值范围大,更稳定
- float16: 标准半精度,节省内存但可能溢出
- autocast: 自动选择精度,关键运算用float32
"""
device_type = "cuda" if "cuda" in args.device else "cpu"
dtype = torch.bfloat16 if args.dtype == "bfloat16" else torch.float16
# 📚 上下文管理器知识点
# CPU不支持autocast,使用nullcontext作为空操作
autocast_ctx = (
nullcontext() if device_type == "cpu" else torch.cuda.amp.autocast(dtype=dtype)
)
# ========== 4. 配置WandB实验跟踪 ==========
"""
📚 实验跟踪系统知识点:
- WandB: 实验管理平台,记录训练过程
- SwanLab: 国产替代方案
- 支持断点续训时恢复到同一个实验
"""
wandb = None
if args.use_wandb and is_main_process():
# 使用SwanLab作为WandB的替代
import swanlab as wandb
# 📚 实验恢复知识点
# 如果有检查点数据,获取之前的wandb_id来恢复实验
wandb_id = ckp_data.get("wandb_id") if ckp_data else None
resume = "must" if wandb_id else None # 必须恢复到指定实验
# 构建实验名称,包含关键超参数
wandb_run_name = f"MiniMind-Pretrain-Epoch-{args.epochs}-BatchSize-{args.batch_size}-LearningRate-{args.learning_rate}"
wandb.init(
project=args.wandb_project, name=wandb_run_name, id=wandb_id, resume=resume
)
# ========== 5. 定义模型、数据、优化器 ==========
"""
📚 训练组件初始化:
- 模型: 根据配置创建MiniMind模型
- 数据集: 加载预训练数据
- 采样器: 分布式训练的数据分配
- 优化器: AdamW优化器
- 缩放器: 混合精度训练的梯度缩放
"""
# 初始化模型和分词器
model, tokenizer = init_model(lm_config, args.from_weight, device=args.device)
train_ds = PretrainDataset(args.data_path, tokenizer, max_length=args.max_seq_len)
train_sampler = DistributedSampler(train_ds) if dist.is_initialized() else None
scaler = torch.cuda.amp.GradScaler(enabled=(args.dtype == "float16"))
optimizer = optim.AdamW(model.parameters(), lr=args.learning_rate)
start_epoch, start_step = 0, 0
if ckp_data:
# 恢复模型参数
model.load_state_dict(ckp_data["model"])
# 恢复优化器状态(动量、方差估计等)
optimizer.load_state_dict(ckp_data["optimizer"])
# 恢复梯度缩放器状态
scaler.load_state_dict(ckp_data["scaler"])
# 恢复训练进度
start_epoch = ckp_data["epoch"]
start_step = ckp_data.get("step", 0)
if dist.is_initialized():
# 📚 RoPE位置编码特殊处理
# freqs_cos, freqs_sin是位置编码缓存,不需要梯度同步
model._ddp_params_and_buffers_to_ignore = {"freqs_cos", "freqs_sin"}
model = DistributedDataParallel(model, device_ids=[local_rank])
for epoch in range(start_epoch, args.epochs):
# 📚 分布式采样器epoch设置
# 每个epoch设置不同的随机种子,确保数据顺序随机化
if train_sampler:
train_sampler.set_epoch(epoch)
# 📚 断点续训逻辑
if epoch == start_epoch and start_step > 0: # 第一个epoch且存在检查点
# 使用跳批采样器,跳过已训练的数据
batch_sampler = SkipBatchSampler(
train_sampler or range(len(train_ds)), args.batch_size, start_step + 1
)
loader = DataLoader(
train_ds,
batch_sampler=batch_sampler,
num_workers=args.num_workers,
pin_memory=True,
)
Logger(
f"Epoch [{epoch + 1}/{args.epochs}]: 跳过前{start_step}个step,从step {start_step + 1}开始"
)
train_epoch(epoch, loader, len(loader) + start_step + 1, start_step, wandb)
else: # 默认从头开始
loader = DataLoader(
train_ds,
batch_size=args.batch_size,
shuffle=(train_sampler is None),
sampler=train_sampler,
num_workers=args.num_workers,
pin_memory=True,
)
train_epoch(epoch, loader, len(loader), 0, wandb)十二、训练
十三、eval
加载初始模型——注入权重——切换 eval 模式——生成结果
还有MOE部分没学。。。。。这部分先放一放吧(黄豆汗)
十四、Colab
将项目文件上传到Google Drive,colab 登录Google Drive,出现下图表示成功登录,且文件夹目录下出现 gdrive 。

后记[不懂的点]
1. model.py文件下面复制粘贴了这段代码,不懂它的作用
from transformers import PretrainedConfig
class MokioMindConfig(PretrainedConfig):
model_type = "mokiomind"
def __init__(
self,
dropout: float = 0.0,
bos_token_id: int = 1,
eos_token_id: int = 2,
hidden_act: str = "silu",
hidden_size: int = 512,
intermediate_size: int = None,
max_position_embeddings: int = 32768,
num_attention_heads: int = 8,
num_hidden_layers: int = 8,
num_key_value_heads: int = 2,
vocab_size: int = 6400,
rms_norm_eps: float = 1e-05,
rope_theta: int = 1000000,
inference_rope_scaling: bool = False,
flash_attention: bool = True,
############ MoE ############
use_moe:bool=False,
num_experts_per_tok:int=2,
n_routed_experts:int=4,
n_shared_experts:int=1,
scoring_func:str='softmax',
aux_loss_alpha:float=0.1,
seq_aux:bool=True,
norm_topk_prob:bool=True,
**kwargs,
):
super().__init__(**kwargs)
self.dropout = dropout
self.bos_token_id = bos_token_id
self.eos_token_id = eos_token_id
self.hidden_act = hidden_act
self.hidden_size = hidden_size
self.intermediate_size = intermediate_size
self.max_position_embeddings = max_position_embeddings
self.num_attention_heads = num_attention_heads
self.num_hidden_layers = num_hidden_layers
self.num_key_value_heads = num_key_value_heads
self.vocab_size = vocab_size
self.rms_norm_eps = rms_norm_eps
self.rope_theta = rope_theta
self.inference_rope_scaling = inference_rope_scaling
self.flash_attention = flash_attention
self.use_moe=use_moe
self.num_experts_per_tok=num_experts_per_tok
self.n_routed_experts=n_routed_experts
self.n_shared_experts=n_shared_experts
self.seq_aux=seq_aux
self.norm_topk_prob=norm_topk_prob
self.aux_loss_alpha=aux_loss_alpha
self.scoring_func=scoring_func
self.rope_scaling = (
{
"beta_fast": 4,
"beta_slow": 1,
"factor": 4,
"original_max_position_embeddings": 2048,
"type": "yarn",
}
if self.inference_rope_scaling
else None
)
2. 用VSCode提交代码到github不会
这个学一下Git 怎么使用就能解决,这个也可以出一篇笔记,emm....又给自己挖坑。。。
思考
做这个的时候,会遇到很多困难,做着做着,发现这些与项目本身无关紧要的困难,如果没有解决,会觉得如鲠在喉,特别是没有及时解决的时候,更加难受,然后烦躁,但是解决这样一个问题往往需要额外花很多时间,相当于在完成项目主线任务的时候,需要单开一个时间线解决这个问题,导致项目进程被搁置。这个时候最好的方法是:在不影响项目进程的情况下,先将这些无关紧要的任务记录下来,搁置在一边,再过完项目主线任务之后逐个解决。
原因如下:项目主线过完之后,完成任务之后的成就感,多少会让人更有信心,有信心就会更加积极地寻找,之前残留下小问题的解决方案,加之,项目主体已经完成,之后做的工作只不过是完善和补充罢了。
还有就是在看一个学习视频的时候,第一遍看主要侧重作者的思路,努力把视频逻辑理清,不要边看边记笔记,不然只会成为视频的文案翻译,没什么自己的思考,而且因为没有看完作者完整的推理链条,也很难形成自己的思维和直觉。在看完整个视频后,一定要做笔记整理!一定要做笔记整理!一定要做笔记整理!重要的事情说三遍,这个整理笔记的过程,就是整理自己的思维链条的过程,思路可以参考ai,但是文字一定要用自己的话写,这样印象会更加深刻,以后忘记了,需要复习这个知识点,拾起来也会很快。
学习YaRN的知识点时,由于网上关于这部分的学习视频很少,在一开始看公式的时候,感觉很痛苦。但其实,不用特别关注这些杂乱无章的公式,因为看到后面写代码的视频的时候,自然而然地公式之间的关系就串联起来了,思路就顺畅了,所以有时候明白大概原理就差不多了,最重要的是关注公式之间的逻辑,捋清思路。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)