如何从业务能力拆解AI Agent架构:以AI运动教练为例
FitMind SQL-Agent是一个数据驱动的AI运动分析系统,通过LangChain框架构建。该系统结合大型语言模型(LLM)与外部工具,解决传统模型知识静态性和缺乏行动能力的问题。核心功能包括:1)自然语言转SQL查询用户运动数据;2)基于知识库的运动专业问答;3)智能路由决策判断查询方式。系统采用五层能力建模方法,将复杂运动任务拆解为认知操作,通过"思考-行动-观察"
1️⃣ 项目背景与挑战
传统大型语言模型(LLM)的知识主要来源于预训练语料,其能力受限于两个核心问题:
-
知识静态性:模型知识截止于训练时间点,无法访问实时数据或用户私有数据。
-
缺乏行动能力:模型只能生成文本,无法主动调用外部系统完成任务,例如数据库查询、计算或信息检索。
在真实运动场景中,这些限制尤为明显。例如,一个传统 AI 运动助手只能基于通用运动知识提供建议,却无法回答如下关键问题:
-
我上个月跑步总里程是多少?
-
我的训练强度是否超过安全阈值?
-
根据我的历史训练记录,我下周应如何调整训练计划?
为了解决这一问题,近年来出现了 AI Agent 架构。Agent 通过赋予大模型调用工具的能力,使其能够与外部环境交互。
一个完整 Agent 系统通常包含三个核心组件:
-
基础语言模型(LLM)
-
外部工具系统(Tools)
-
任务编排与决策模块(Agent Orchestrator)
通过 Agent 框架,大模型可以在复杂任务中执行多步骤推理与行动循环,从而实现:
-
查询用户运动数据库
-
调用专业知识库
-
进行个性化训练规划
-
动态调整训练策略
因此,本文提出 FitMind SQL-Agent,探索如何通过 LangChain 构建一个数据驱动型 AI 运动分析系统。
2️⃣ 能力域建模方法论
1.明确业务能力边界——模型做什么
-
核心目标:定义模型的核心应用场景、解决的具体问题、用户意图对齐,避免泛化性过宽,确保业务聚焦
-
建立步骤:
-
拆解业务场景:将复杂场景拆分为 “知识密集型任务”(如问答、事实核查)和 “交互式决策任务”(如虚拟环境交互、真实场景操作)两类核心方向。
-
锁定任务基准:为每个业务场景匹配公开基准(如 QA 用 HotpotQA、决策用 ALFWorld),明确性能评估指标(如 EM 值、成功率)。
-
限定能力范围:明确模型 “能做” 与 “不能做”,例如 ReAct 限定 “不涉及危险环境操作”“不编辑外部知识库”,避免业务边界模糊。
-
2.拆解认知任务——模型怎么想
-
核心目标:将业务能力转化为模型可执行的底层认知操作,确保认知行为与业务目标对齐。
-
建立步骤:
-
提炼通用认知操作:将业务均拆解为 6 类核心认知任务 —— 目标分解、信息提取、常识 / 算术推理、进度跟踪、异常处理、结果合成。
-
绑定业务与认知:为具体业务场景分配核心认知操作,例如 “多跳问答” 侧重 “目标分解 + 信息提取”,“虚拟环境交互” 侧重 “进度跟踪 + 异常处理”。
-
定义认知输出格式:认知操作需以 “自然语言推理轨迹” 呈现(如 “我需要先搜索 X,再查找 Y”),确保可解释性。
-
反思与自我修正:例如当模型发现搜索结果为空时,不是直接报错,而是思考是否需要换个关键词搜索。
-
3.设计决策与推理流程——模型怎么排
-
核心目标:构建 “认知 - 行动 - 反馈” 的闭环流程,让模型能动态调整策略,避免静态推理或盲目行动。
-
建立步骤:
-
确定流程框架:采用 “思考(Thought)→行动(Action)→观察(Observation)” 三段式闭环,确保每一步行动都有认知支撑,每一次观察都能反哺思考。
-
灵活调整推理密度:知识密集型任务采用 “密集推理”(每步行动前均有思考),决策类任务采用 “稀疏推理”(关键节点插入思考),平衡效率与准确性。
-
设计切换机制:当模型内部知识不足(如 CoT-SC 多数答案不一致)时,切换至 “外部工具调用”;当外部工具无结果时,切换至 “内部推理”,实现内外部知识协同。
-
终止条件设计:在闭环中补充“终止机制”。模型容易陷入死循环(如反复搜索同一个词),需要设置最大步数(Max Steps)或重复检测机制来强制跳出。
-
4.搭载专用工具系统——模型怎么干
-
核心目标:为模型提供与外部环境交互的 “操作载体”,工具需贴合业务场景,避免功能冗余。
-
建立步骤:
-
工具类型匹配:根据业务场景设计工具,分为三类核心工具:
-
知识检索工具:如 Wikipedia API(支持 search/lookup/ finish),用于获取外部静态知识;
-
交互操作工具:如 WebShop 的 “搜索 - 选择 - 购买”、ALFWorld 的 “导航 - 拾取 - 使用”,用于动态环境交互;
-
辅助工具:如解码策略(贪心解码、束搜索),用于优化行动输出。
-
-
简化工具接口:工具操作需结构化、低复杂度(如 “search [实体]”“click [选项]”),避免模型学习成本过高。
-
工具权限管控:限定工具的操作范围(如 “仅检索 Wikipedia,不编辑”“仅浏览商品,不真实支付”),降低风险。
-
5.整合数据资源底座——模型用什么
-
核心目标:构建 “内外部结合、可迭代更新” 的数据资源,为模型提供持续的知识与训练支撑。
-
建立步骤:
-
三层数据整合:
-
外部数据:静态知识库(如 Wikipedia)、真实场景数据(如 WebShop 的 1.18M 商品信息),确保数据的真实性与时效性;
-
内部数据:模型预训练的常识知识(如 “台灯通常在桌子上”),降低外部数据依赖;
-
人工标注数据:少量高质量 “推理 - 行动” 轨迹(ReAct 仅用 1-6 个示例),用于少样本提示或微调。
-
-
静态知识(Knowledge): Wikipedia、商品库、微调数据(SFT Data),这是模型“学到”或“查到”的。
-
动态记忆(Memory):这是模型“记住”的。需要补充:
-
短期记忆(Working Memory):当前的上下文窗口,保存推理轨迹。
-
长期记忆(Long-term Memory):通常使用 向量数据库(Vector DB) 存储历史对话或过往经验,让模型在处理新任务时能参考旧任务的经验(RAG 思想)。
-
-
6.如何运用五层模型构建AI运动教练
我们将上述五层能力建模方法应用于运动教练场景(这里仅仅是对于我想象中构建的AI运动教练,但是后续完成的是这个里面的一部分),将系统能力划分为四大核心业务模块:
-
用户建模能力
-
训练决策能力
-
健康与营养分析能力
-
运动知识顾问能力
通过能力域建模,可以将复杂运动指导任务拆解为可执行的认知流程,并进一步映射到 LangChain 的 Agent 与 Tool 体系中。
-
AI运动教练的目标功能需求分析:
-
收集用户信息,保存用于其他功能进行定制化
-
根据用户需求,定制训练计划
-
记录运动进展,记录卡路里消耗
-
记录每日三餐进行卡路里计算
-
对于常见的运动损伤的及时处理建议
-
对于常见运动的知识点掌握,对于用户提供相应建议
-
用户对于运动计划存在打断或者长时间没有完成时进行相关补充或者另行安排
-
-
功能需求转化为业务能力
① 业务能力(Business Capability):
-
用户建模能力
-
训练决策能力——交互式决策任务
-
健康与营养分析能力——知识密集型任务
-
运动知识顾问能力——知识密集型任务
② 认知任务(Cognitive Tasks) -
用户建模能力:目标分解(提取用户信息进行存储),信息提取(提取用户状态、以往训练计划、饮食情况
-
训练决策能力:
-
目标分解:将“我要减脂”分解为“每周 3 次有氧 + 2 次力量 + 热量缺口 500kcal”。
-
逻辑推理:根据用户“膝盖痛”的约束,推理出“排除深蹲/跳绳”的决策。
-
异常处理(Re-planning):关键点。检测到 Plan_Completion < 50% 或 Days_Missed > 3,触发“降低强度”或“合并训练量”的策略。
-
-
健康与营养分析能力:
-
信息提取:识别自然语言中的食物(“早上吃了一个煎饼果子” -> 煎饼果子, 1个)。
-
算术推理:调用热量库计算 Total_Intake,对比 Target_Burn,得出“还需要运动多久”或“晚餐建议摄入量”
-
结果合成:生成带数据的建议(“你今天超标 200 卡,建议晚餐少吃主食”)。
-
-
运动知识顾问能力:
-
意图识别:高优先级识别“疼痛”、“受伤”、“流血”等关键词。
-
安全检索:检索经过验证的急救知识库(非通用网络搜索,防止偏方)。
-
风控过滤:在输出前进行安全检查,确保话术包含就医引导。
-
③ 决策与推理流程(Reasoning Flow):如果用户最近没有运动,想要恢复运动
-
Observation(观察):
-
读取 User_DB,发现 Last_Active_Date 为 3 天前。
-
读取 Plan_Status,发现“周三、周四训练未完成”。
-
-
Thought(思考 - 稀疏推理):
-
思考 1:用户中断了训练,之前的计划堆积,不能直接让用户一天做三天的量(风险高)
-
思考 2:需要询问用户当前状态(是否生病?是否忙碌?)
-
思考 3:根据用户反馈调整。如果用户说“太忙”,则压缩今日训练时间;如果说“太累”,则切换为恢复性训练。
-
-
Action(行动):
-
调用询问用户状态工具询问原因。
-
根据反馈调用计划规划工具。
-
-
Feedback(反馈):
-
用户确认新计划。
-
系统更新数据库。
-
④ 工具系统(Tools)
-
数据读写工具 (CRUD)
-
知识检索工具 (Retrieval)
-
计算工具 (Calculation)
⑤ 数据资源(Memory & DB)
-
静态专业知识库 (External Knowledge):
-
动作库:包含动作名称、肌群、难度、禁忌(如:腰突禁做硬拉)。
-
食物库:常见食物的热量、GI 值、三大营养素占比。
-
急救知识库:RICE 原则、常见运动损伤处理流程(来源需权威,如红十字会)。
-
-
动态用户数据库 (User DB):
-
基础档案:年龄、性别、BMI、目标。
-
日志流 (Logs):每日摄入热量、每日运动消耗、打卡时间戳。
-
当前计划 (Active Plan):JSON 格式的日程表。
-
向量记忆 (Vector Memory):存储用户过去的反馈(如“我不喜欢吃西兰花”、“我做波比跳会头晕”),用于 Prompt 上下文增强,避免重复询问。
-
3️⃣ 我的系统设计——FitMind SQL-Agent
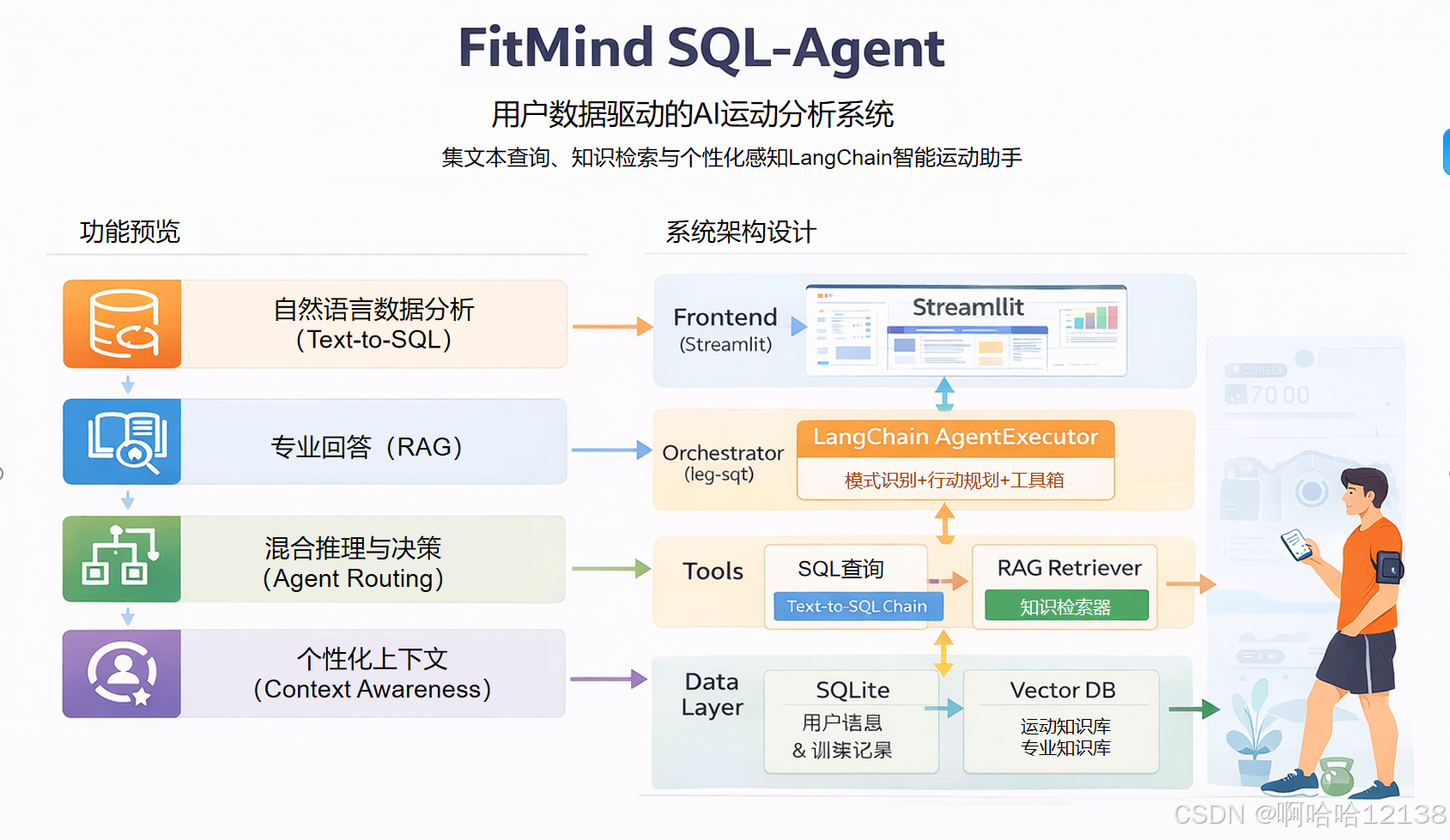
1.功能预览:
-
自然语言数据分析 (Text-to-SQL):用户使用自然语言进行提问,系统将问题转化为SQL语句,从数据库查询并且回答。
-
基于知识库的专业问答 (RAG):针对通用的运动科学问题,检索预备文档进行回答。
-
混合推理与决策 (Agent Routing):系统根据用户意图来自动判断是该”查数据库“还是”查文档“,并且相应去执行。
-
个性化用户上下文 (Context Awareness):系统”认识“用户,记住基本的画像,在对话中隐式使用这些信息。
2.系统架构设计
- 用户交互层 (Frontend)
-
工具:Streamlit (最快出图表和对话框)
-
功能:用户输入自然语言,展示 AI 回复 + SQL 查询结果(可视化图表)。
- 编排与路由层 (Orchestrator - LangChain Agent)
使用 LangChain Agent (OpenAI Tools Agent / ReAct Agent)。
-
核心组件:
AgentExecutor -
功能:接收用户指令,判断意图:
-
如果是“查数据”(如:我上周消耗了多少卡路里?):调用 SQL Tool。
-
如果是“问知识”(如:膝盖疼怎么跑步?):调用 RAG Tool。
-
如果是“闲聊”:直接 LLM 回复。
-
- 工具层 (Tools Layer)
主要实现两个核心工具(Tools):SQL 数据查询器 (Text-to-SQL Chain)、知识检索器 (RAG Retriever)
-
数据资源层 (Data Layer)
-
Structured Data (SQLite):用户基础信息
-
Unstructured Data (Vector DB):运动科学文档。
-
3.基本阶段预览:
-
阶段一:数据构建与基础环境搭建
- 阶段目标:完整 SQLite 数据库设计、初始运动知识向量库、可运行 LangChain 基础 Demo
-
阶段二:Text-to-SQL 数据分析能力实现
- 阶段目标:使 AI 能够理解自然语言并查询用户运动数据,实现数据驱动分析能力。
-
阶段三:Agent 多工具智能决策系统
- 阶段目标:智能任务规划能力、多工具协同执行能力、上下文对话理解能力
-
阶段四:系统产品化与交互展示
- 阶段目标:构建前端交互系统、完善项目文档和部署
参考资料:
1.Superpower LLMs with Conversational Agents | Pinecone
2.ReAct: Synergizing Reasoning and Acting in Language Models

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 27
27 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)