谈谈为什么现在大模型转向Decoder-only架构
Transformer架构自2017年提出以来,推动了NLP领域的技术革命。研究显示,大模型发展经历了从Encoder-Decoder架构(如BERT)向Decoder-Only架构(如GPT系列)的转变。这种转变源于Decoder架构在多方面的优势:更符合语言生成规律、更适合大规模扩展、训练效率更高,并能展现"涌现"能力。当前主流大模型普遍采用Decoder-Only架构,其
引言
自2017年Google Brain团队提出Transformer架构以来,自然语言处理(NLP)领域经历了一场前所未有的技术革命。这个基于自注意力机制的创新架构,彻底改变了传统序列建模的方式。在随后的发展历程中,我们可以清晰地观察到两个主要的技术演进阶段:
第一阶段(2018-2020年)以Encoder-Decoder架构为主导,代表模型包括:
- BERT(2018年):首个基于Transformer的双向编码器模型
- RoBERTa(2019年):BERT的优化版本
- ALBERT(2019年):参数效率更高的BERT变体
第二阶段(2020年至今)则转向了Decoder-Only架构,典型代表有:
- GPT-3(2020年):1750亿参数的突破性模型
- GPT-4(2023年):多模态能力的飞跃
- Claude系列(2021-2023年):注重安全性的对话模型
- Gemini(2023年):Google的多模态大模型
这种架构选择的转变背后,反映了AI研究者对语言模型本质认知的深化。Decoder-Only架构之所以占据主导地位,主要基于以下几个关键发现:
- 自回归特性更符合人类语言生成的自然过程
- 单向注意力机制在长文本建模中表现更优
- 简化架构有利于模型规模的指数级扩展
- 预训练-微调范式向零样本/少样本学习转变
目前,这些大型语言模型已展现出惊人的通用人工智能(AGI)特性,在代码生成、创意写作、知识问答等多个领域都达到了接近人类的水平。这一发展不仅改变了自然语言处理领域的技术路线,更重新定义了人机交互的可能性边界。
本文将深入探讨为什么在当前通用大模型的发展中,解码器(Decoder)的作用已经超越了编码器(Encoder),成为主导性的架构选择。我们将从技术原理、训练范式、应用场景等多个维度进行分析,并通过对比表格直观展示两种架构的差异。
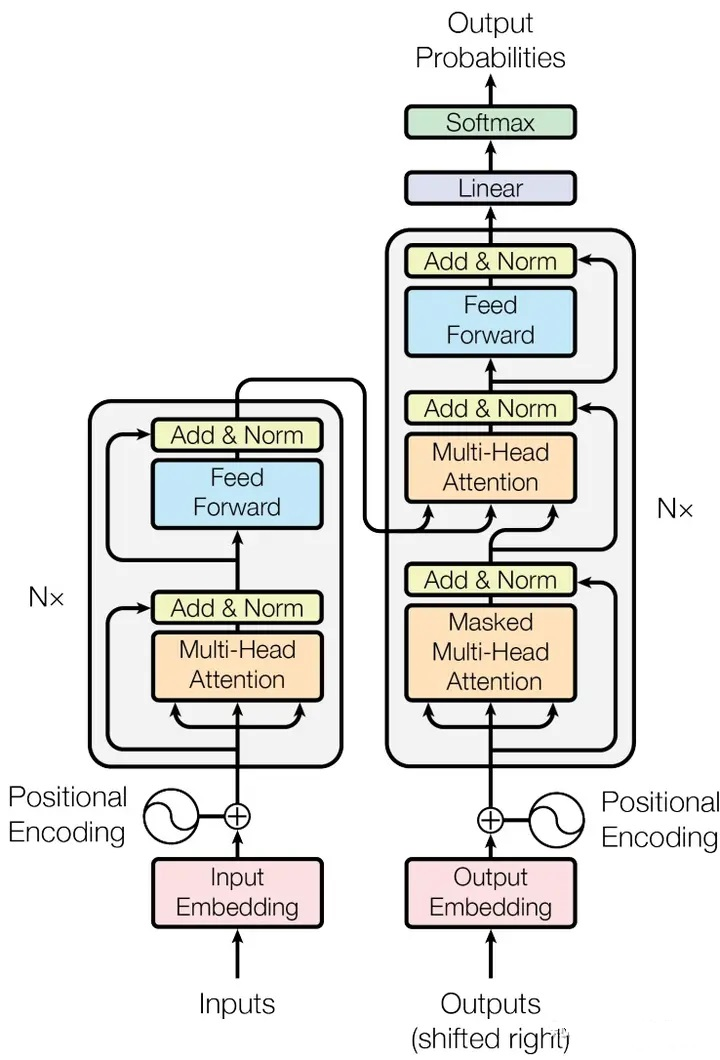
编码器与解码器的基本概念
Transformer架构回顾
Transformer架构由Vaswani等人在2017年的论文《Attention Is All You Need》中提出,彻底改变了自然语言处理领域。该架构由两部分组成:编码器(Encoder)和解码器(Decoder)。
编码器(Encoder)
编码器负责将输入序列转换为连续的语义表示(Contextualized Embeddings)。它通过多头自注意力机制和前馈神经网络,捕捉输入序列中的上下文信息。典型的编码器模型包括BERT、RoBERTa、ALBERT等,它们主要用于理解任务,如文本分类、命名实体识别等。
解码器(Decoder)
解码器的主要功能是根据编码器提供的语义信息生成目标序列。它采用掩码自注意力机制(Masked Self-Attention),在预测当前token时仅能获取先前位置的信息,这种设计实现了序列的自回归生成。以GPT系列为代表的模型就是典型的解码器架构。
解码器主导的技术原因
1. 生成式AI的崛起
2022年末ChatGPT的问世标志着生成式AI正式进入主流视野。相较于早期的理解型任务(如分类、标注等),生成任务(如对话、写作、编程等)展现出更显著的商业价值和技术潜力。解码器架构特别适合生成任务,其采用的自回归方式能够逐token生成输出,这与人类的语言表达机制高度吻合。
2. 统一架构的优势
Decoder-Only架构可以用统一的方式处理各种任务。通过“提示工程”(Prompt Engineering),同一个模型可以完成问答、摘要、翻译、代码生成等多种任务,无需为每个任务单独训练模型。这种“一个模型解决所有问题”的范式大大降低了部署和维护成本。
3. 规模效应的释放(涌现)
研究发现,Decoder-Only架构模型在扩大规模时会展现出显著的涌现能力。当模型参数量突破100亿这个关键阈值后,会突然获得小模型所不具备的多种能力,包括上下文学习和思维链推理等特性。值得注意的是,这种规模效应在Decoder架构中表现得特别突出。
4. 训练效率的提升
Decoder-Only模型在训练时具有更高的计算效率。由于采用因果掩码(Causal Masking),模型可以并行处理整个序列,同时每个token的预测只依赖于前面的token,这使得训练过程更加高效。相比之下,Encoder-Decoder架构需要分别训练编码器和解码器,复杂度更高。
5. 预训练范式的演进
从BERT的掩码语言建模(MLM)到GPT的自回归语言建模,预训练范式发生了根本性转变。自回归预训练让模型学习“预测下一个token”的能力,这种能力可以直接迁移到各种下游生成任务。而MLM虽然适合理解任务,但在生成任务上表现欠佳。
架构对比分析
下表从多个维度对比了Encoder、Decoder和Encoder-Decoder三种架构的特点:
|
对比维度 |
Encoder |
Decoder |
Encoder-Decoder |
|
注意力机制 |
双向注意力 |
因果(单向)注意力 |
编码器双向+解码器因果 |
|
代表模型 |
BERT, RoBERTa |
GPT, LLaMA, Claude |
T5, BART |
|
主要任务 |
理解任务(分类、NER) |
生成任务(对话、写作) |
翻译、摘要 |
|
预训练目标 |
掩码语言建模(MLM) |
自回归语言建模 |
Span Corruption |
|
上下文利用 |
完整上下文 |
仅左侧上下文 |
编码器完整+解码器左侧 |
|
训练效率 |
中等 |
高 |
较低 |
|
推理效率 |
一次性编码 |
自回归生成 |
编码一次+解码多次 |
|
任务通用性 |
需针对任务微调 |
统一提示处理 |
统一文本到文本 |
|
涌现能力 |
较弱 |
强(100B+参数) |
中等 |
|
当前地位 |
逐渐被替代 |
主流选择 |
特定场景使用 |
关键差异解析
注意力机制
Encoder使用双向注意力,可以同时关注输入序列的所有位置;Decoder使用因果(单向)注意力,只能关注当前位置之前的信息。这种差异决定了Encoder更适合理解任务,Decoder更适合生成任务。
训练目标
Encoder通常采用掩码语言建模(MLM),即随机掩码部分token让模型预测;Decoder采用自回归语言建模,预测下一个token。后者与生成任务的目标更加一致,因此迁移效果更好。
计算复杂度
对于长度为n的序列,自注意力的计算复杂度为O(n²)。Decoder-only架构由于采用因果掩码,可以通过优化将计算量减半。此外,Decoder-only架构在推理时可以复用之前的计算结果(KV Cache),大幅提升生成速度。
典型模型演进历程
大模型的发展历程清晰地展示了从Encoder主导到Decoder主导的转变轨迹:
Encoder时代(2018-2019)
以BERT(2018)为代表,这一时期的研究重点是如何通过预训练提升模型的理解能力。BERT在GLUE等理解任务基准上取得了突破性进展,催生了RoBERTa、ALBERT、ELECTRA等改进模型。这一阶段的模型主要用于文本分类、命名实体识别、问答等理解型任务。
Encoder-Decoder时代(2019-2021)
T5(2019)和BART(2019)代表了这一时期的主流架构。它们将各种NLP任务统一为“文本到文本”的转换问题,使用Encoder-Decoder架构处理理解和生成任务。这一思路在机器翻译、文本摘要等任务上取得了很好的效果。
Decoder时代(2020-至今)
GPT-3(2020)的发布标志着Decoder-Only架构的崛起。1750亿参数的规模展现出了惊人的少样本学习能力。此后,GPT-4、Claude、Gemini、LLaMA等模型均采用Decoder-Only架构,参数规模从数十亿到数千亿不等,展现出强大的通用能力。
未来趋势与展望
多模态融合
未来的大模型将不仅限于文本,而是融合图像、音频、视频等多种模态。GPT-4V、Gemini等模型已经展示了多模态理解的能力。Decoder-Only架构在多模态任务上同样展现出优势,通过将各种模态统一为token序列进行处理。
推理能力的增强
OpenAI的o1模型展示了通过强化学习提升推理能力的新方向。模型在回答前进行“思考”,生成中间推理步骤,最终得出答案。这种“慢思考”能力与Decoder的自回归生成特性高度契合,预示着Decoder架构在复杂推理任务上的巨大潜力。
效率优化
尽管Decoder-Only架构展现出强大的能力,但其计算成本仍然很高。未来的研究将聚焦于提升效率,包括模型压缩、量化、蒸馏、稀疏化等技术。同时,新的注意力机制(如线性注意力、状态空间模型)也在探索中,有望在保证性能的同时降低计算复杂度。
结论
Decoder-Only架构之所以成为当前通用大模型的主流选择,根本原因在于它完美契合了生成式AI的发展趋势。从统一任务处理、规模效应释放、训练效率提升到涌现能力的展现,Decoder架构在多个维度上都展现出独特优势。随着技术的不断进步,我们可以期待Decoder-Only模型在更多领域展现出惊人的能力,推动人工智能向通用智能(AGI)迈进。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 21
21 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)