【机器学习 01】别急着推公式,先搞懂我们到底在让机器“学”什么?
现在的 AI 很火,满大街都是 ChatGPT、DeepSeek。但作为开发者,当我们谈论“机器学习”时,我们到底在谈论什么?是高深的数学公式?还是复杂的神经网络? 其实,剥去华丽的外衣,机器学习在解决的问题非常朴素。今天作为这个系列的第一篇,我们不推导公式,先用“上帝视角”把机器学习的地图展开。
【机器学习 01】别急着推公式,先搞懂我们到底在让机器“学”什么?
前言
现在的 AI 很火,满大街都是 ChatGPT、DeepSeek。但作为开发者,当我们谈论“机器学习”时,我们到底在谈论什么?是高深的数学公式?还是复杂的神经网络?
其实,剥去华丽的外衣,机器学习在解决的问题非常朴素。今天作为这个系列的第一篇,我们不推导公式,先用“上帝视角”把机器学习的地图展开。
一、 什么是机器学习?
在传统的编程模式(比如你写 C++ 或 Python)中,我们扮演的是 “上帝” 的角色。我们制定规则,计算机会严格执行。
- 传统编程:
- 输入:规则(公式)+ 数据
- 输出:答案
- 例子:你写了一个
if (email.contains("中奖")) return "垃圾邮件";
但在现实生活中,很多规则太复杂了,人类写不出来。比如: 怎么定义一只“猫”? 是有圆耳朵?还是有胡须?这些规则有无数种例外,你无法用 if-else 穷尽。这时候,机器学习 (Machine Learning) 登场了。我们把角色互换:
-
机器学习:
- 输入:数据 + 答案(标签)
- 输出:规则(模型)
- 例子:你给机器看 1000 封垃圾邮件和 1000 封正常邮件,机器自己总结出:“哦,原来带有‘发票’且全是红字的通常是垃圾邮件”。
-
逻辑对比图
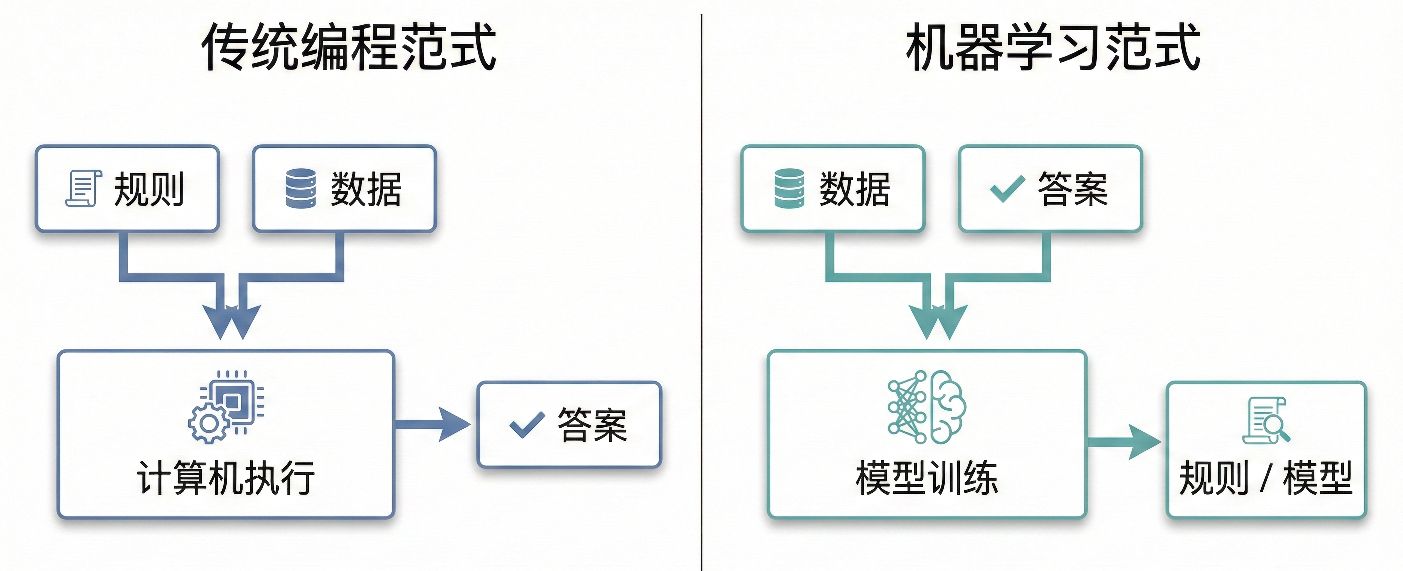
一句话定义:机器学习就是利用计算机,从历史数据中找规律,并把这个规律封装成“模型”用到新的数据上。
二、 机器学习的三大核心任务
如果我们把机器学习看作一个打工人,它的工作内容主要就三项:分类、回归、聚类。
1. 分类 (Classification) —— 是 A 还是 B?
分类任务要做的事情很简单:给定一堆数据,让机器画一条“分界线”,把它们区分开来。这条“线”可以是直线,也可以是曲线,甚至是高维空间里的复杂边界。
-
核心特征:输出结果是离散的、有限的类别。
-
典型场景:垃圾邮件识别(是/否)、手写数字识别(0~9)。
2. 回归 (Regression) —— 具体是多少?
和分类不同,回归任务并不是要“划清界限”,而是希望模型学到数据背后的变化趋势,从而给出一个具体数值。可以把回归理解为:在一堆散点中,拟合出一条最合理的曲线。
- 核心特征:输出结果是连续的数值。
- 典型场景:房价预测、股票走势、气温预测。
3. 聚类 (Clustering) —— 物以类聚
聚类和前面两种任务最大的不同在于:它属于无监督学习,没有标准答案。机器不会提前知道“哪一类是什么”,只能根据数据之间的相似程度,自动把相近的样本聚到一起。
- 核心特征:数据没有标签(无监督),让机器自己找规律。
- 典型场景: 用户画像分群、异常检测。
三、 误区粉碎:深度学习 ≠ 神经网络 ≠ 机器学习 ≠ 人工智能
很多新手入门时,容易被网上狂轰滥炸的名词搞晕:ChatGPT 是人工智能吗?它是机器学习吗?它是神经网络吗?
- 答案是:都是,但层级不同。
新手最常见的误区是这样一种想法:
“现在都在讲 AI,那我直接学深度学习(Deep Learning)就好了,前面的不用管。”
这就好比认为:
既然已经有了法拉利,就没必要了解轮子和发动机的原理。
要真正走稳这条路,我们至少需要先建立下面两个核心认知。
1. 理清层级关系
这四个概念并不是平行的,而是一个层层包含的包含关系。
人工智能 (AI) ⊃ 机器学习 (ML) ⊃ 神经网络 (NN) ⊃ 深度学习 (DL) \text{人工智能 (AI)} \supset \text{机器学习 (ML)} \supset \text{神经网络 (NN)} \supset \text{深度学习 (DL)} 人工智能 (AI)⊃机器学习 (ML)⊃神经网络 (NN)⊃深度学习 (DL)
- 人工智能 (Artificial Intelligence):这是最外层的大圈,是我们的终极目标——让机器展现出智慧。
- 机器学习 (Machine Learning):这是实现 AI 的一种手段/方法。除了机器学习,AI 还可以通过“规则引擎”(if-else)来实现。
- 神经网络 (Neural Networks):这是机器学习中的一个流派。它受人脑神经元启发,用数学公式模拟神经元的连接。
- 深度学习 (Deep Learning):这是神经网络的进阶版。特指层数很深(Deep)的神经网络。
一句话总结:深度学习是用“深层神经网络”去实现“机器学习”,最终达到“人工智能”的技术。
2. 场景为王:杀鸡焉用牛刀?
深度学习虽然处于最核心、最前沿的位置,但它并不是万能钥匙。在算法工程师的工具箱里,深度学习就像是一把威力巨大的重型电锤。
- 优点:力大无穷,能处理图像、声音、自然语言这些复杂的非结构化数据。
- 缺点:笨重、需要海量数据喂养、计算成本高、且是“黑盒”(不可解释)。
而传统机器学习算法(如逻辑回归、SVM、XGBoost),就像是精密螺丝刀。
- 优点:轻便、训练快、对小数据友好、逻辑清晰(可解释)。
实战建议:
- 如果你处理的是 Excel 表格数据(如银行风控、用户分类、房价预测),XGBoost / LightGBM 等传统算法往往比神经网络更高效,且更容易向老板解释为什么。
- 如果你处理的是 图片、视频、语音(如人脸识别、自动驾驶),那么请毫不犹豫地使用 深度学习。
不要因为深度学习的火热,而忽略了传统机器学习算法的基石作用。
四、 总结
今天我们剥离了数学公式,从应用场景的角度重新审视了机器学习。对于开发者来说,“判断你在解决什么问题”往往比“写出模型代码”更重要。当你拿到一个实际需求时,请按以下逻辑进行快速判断:
-
数据有标签吗?
- 有 → \rightarrow → 监督学习(Supervised Learning)
- 无 → \rightarrow → 无监督学习(Unsupervised Learning)
-
(如果是监督学习)你要预测的目标是什么?
- 是类别(如:好/坏) → \rightarrow → 分类问题(Classification)
- 是数值(如:价格/温度) → \rightarrow → 回归问题(Regression)
核心算法速查表:
| 任务类型 | 学习方式 | 标签 (Label) | 输出类型 | 典型算法 |
|---|---|---|---|---|
| 分类 | 监督学习 | 有 | 离散类别 | KNN, SVM, 决策树 |
| 回归 | 监督学习 | 有 | 连续数值 | 线性回归, GBDT |
| 聚类 | 无监督学习 | 无 | 簇 (Cluster) | K-Means |
记住:没有最好的算法,只有最匹配场景的算法。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)