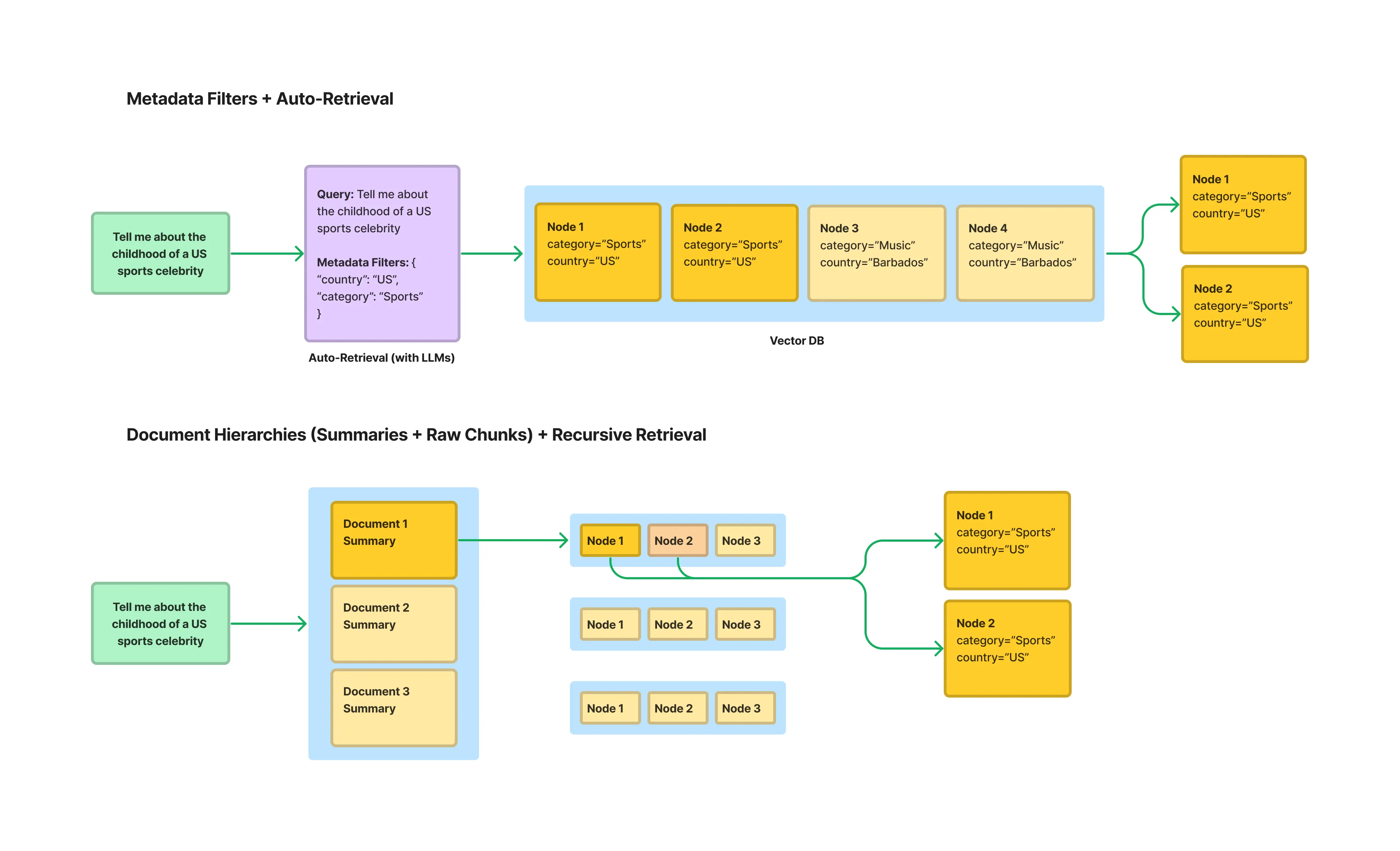
RAG 系统性能跃迁:LlamaIndex 索引优化实战指南
摘要:本文探讨了检索增强生成(RAG)系统中的索引优化策略。通过LlamaIndex工具,提出两种核心方法:1)句子窗口检索技术,在保证检索精度的同时扩展上下文,解决信息碎片化问题;2)结构化索引方案,提升大规模知识库的检索效率。实验表明,相比传统方法,优化后的索引策略能显著提高回答的准确性和完整性。文章包含具体代码实现和技术细节,为开发者提供生产级解决方案。
在构建检索增强生成(RAG)系统时,很多开发者会遇到这样的困境:明明用了最先进的大语言模型,检索结果却总是差强人意 —— 要么答非所问,要么遗漏关键信息。其实,RAG 的性能瓶颈往往不在 LLM 本身,而在索引环节。本文基于 LlamaIndex 的生产级方案,深入解析两种核心索引优化策略,帮你突破检索精度与生成质量的双重瓶颈。
一、上下文扩展:让检索既精准又全面
RAG 系统中存在一个经典矛盾:小块文本检索精准但上下文缺失,大块文本信息丰富却易引入噪音。比如用户问 “气候变化对大西洋环流的影响”,单个句子可能精准匹配 “大西洋经向翻转环流(AMOC)预计衰退”,但缺乏衰退的原因和影响;而大段文本虽包含完整信息,却可能混入无关的太平洋环流内容。
LlamaIndex 提出的句子窗口检索(Sentence Window Retrieval) 巧妙解决了这个问题,其核心思想是:用短句做检索保证精度,用扩展窗口补全上下文提升生成质量。
1.1 句子窗口检索的工作原理
这个策略的精妙之处在于将 “索引” 与 “生成” 两个阶段分离处理,具体流程可分为四步:
(1)索引阶段:拆分句子并存储上下文窗口
- 句子拆分:将文档按句子切割成最小单元(每个句子作为独立节点)
- 窗口存储:每个句子节点的元数据中,自动保存其前后各 N 个句子(默认 N=3)组成的上下文窗口
- 关键细节:仅用单个句子生成向量嵌入(确保检索精度),上下文窗口仅作为元数据备用
(2)检索阶段:精准定位相关句子
用户查询时,系统在所有单句节点中执行向量相似度搜索,快速锁定最相关的核心句子(比如与 “AMOC 变化” 最匹配的句子)。
(3)后处理阶段:扩展上下文窗口
通过MetadataReplacementPostProcessor工具,用节点元数据中存储的上下文窗口替换原始单句,相当于从孤立句子扩展为带前后文的段落。
(4)生成阶段:基于完整上下文回答
扩展后的文本包含足够背景信息,LLM 能生成更全面、逻辑更连贯的答案。
1.2 代码实战:句子窗口检索 vs 常规检索
以 IPCC 气候报告为例,我们对比两种检索方式的效果。核心代码如下:
import os
from llama_index.core.node_parser import SentenceWindowNodeParser, SentenceSplitter
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.llms.deepseek import DeepSeek
from langchain_community.chat_models import ChatTongyi
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core.postprocessor import MetadataReplacementPostProcessor
# 1. 配置模型
Settings.llm = ChatTongyi(
model_name="qwen-turbo-2025-07-15",
temperature=0.7,
max_tokens=2048,
api_key=os.getenv("TONGYI_API_KEY")
)
Settings.embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-en")
# 2. 加载文档
documents = SimpleDirectoryReader(input_files=["IPCC_AR6_WGII_Chapter03.pdf"]).load_data()
# 3. 构建句子窗口索引
node_parser = SentenceWindowNodeParser.from_defaults(
window_size=3, # 前后各3个句子组成窗口
window_metadata_key="window", # 窗口文本存储的元数据键
original_text_metadata_key="original_text"
)
sentence_nodes = node_parser.get_nodes_from_documents(documents)
sentence_index = VectorStoreIndex(sentence_nodes)
# 4. 构建常规分块索引(对比基准)
base_parser = SentenceSplitter(chunk_size=512)
base_nodes = base_parser.get_nodes_from_documents(documents)
base_index = VectorStoreIndex(base_nodes)
# 5. 配置查询引擎(关键:添加后处理器)
sentence_query_engine = sentence_index.as_query_engine(
similarity_top_k=2,
node_postprocessors=[MetadataReplacementPostProcessor(target_metadata_key="window")]
)
base_query_engine = base_index.as_query_engine(similarity_top_k=2)
# 6. 执行查询并对比结果
query = "What are the concerns surrounding the AMOC?"
print(f"查询: {query}\n")
print("--- 句子窗口检索结果 ---")
window_response = sentence_query_engine.query(query)
print(f"回答: {window_response}\n")
print("--- 常规检索结果 ---")
base_response = base_query_engine.query(query)
print(f"回答: {base_response}\n")
— 句子窗口检索结果 —
回答: The primary concern surrounding the Atlantic Meridional Overturning Circulation (AMOC) is that it will very likely decline over the 21st century under all scenarios, though there is low confidence in the exact magnitude of this decline. While an abrupt collapse before 2100 is considered unlikely, the ongoing decline poses significant risks to global climate systems, including changes in weather patterns, ocean heat distribution, and marine ecosystems. Additionally, there is low confidence in quantifying historical AMOC changes due to limited agreement in reconstructed and simulated trends, and short observational records since the mid-2000s make it difficult to distinguish between natural variability and human-induced changes.— 常规检索结果 —
回答: The primary concern surrounding the Atlantic Meridional Overturning Circulation (AMOC) is that it will very likely decline over the 21st century under all scenarios, though it is unlikely to experience an abrupt collapse before 2100. This decline is linked to anthropogenic forcing, but direct observational records since the mid-2000s are too short to determine the exact contributions of internal variability, natural forcing, and human-induced factors. The projected weakening of AMOC has significant implications for global climate systems, including changes in temperature, precipitation patterns, and marine ecosystems.
当查询 “关于 AMOC 的主要担忧是什么” 时,结果差异显著:
- 句子窗口检索:不仅指出 AMOC 预计衰退,还补充了 “定量预测置信度低”、“观测记录时间短”、“20 世纪数据可靠性不足” 等细节,答案更像专业综述。
- 常规检索:仅概括了衰退趋势和不确定性,结论较笼统。
这种差异的核心原因是:句子窗口检索既精准定位了 “AMOC 衰退” 这个核心句,又通过上下文窗口补充了相关背景,而常规检索的 512 字块可能混入冗余信息,或漏掉关键细节。
1.3 技术细节:节点解析器的底层逻辑
SentenceWindowNodeParser的源码实现包含三个关键步骤,理解这些能帮你更好地调优:
- 句子切分:用
split_by_sentence_tokenizer将文档拆分为句子列表,确保语义完整。 - 窗口构建:对第
i个句子,取[i-3, i+3]范围内的句子组成窗口(自动处理边界情况),拼接后存入元数据。 - 嵌入过滤:通过
excluded_embed_metadata_keys设置,确保嵌入模型只处理单句文本(窗口文本不参与向量生成)。
通过这种设计,既保证了检索阶段的精准性,又为生成阶段预留了充足的上下文。
二、结构化索引:让大规模知识库检索更高效
当知识库规模扩大到数百个文档时,传统的全库向量搜索会效率骤降。比如用户问"2023 年 Q2 财报中的 AI 投入",在包含产品手册、技术文档、历年财报的全库中搜索,不仅慢,还可能被 2022 年的财报内容干扰。
结构化索引通过给文本块附加元数据(如文档类型、日期、章节等),实现先过滤再检索,大幅提升效率和精度。
2.1 元数据的核心价值
元数据就像给文本块贴的标签,常见的有效标签包括:
- 文档属性:文件名、创建日期、作者、类型(如财报、手册)
- 内容结构:章节标题、层级(如 第 3 章 3.1 节)
- 自定义标签:业务领域(如 AI、销售)、重要程度等
这些标签能将检索范围从全库缩小到相关子集。例如上述财报查询,可先通过document_type="财报"和date="2023Q2"过滤,再在结果中搜索AI 投入,精度自然更高。
2.2 递归检索:跨多源数据的智能路由
在更复杂的场景(如多表格 Excel 文件),需要更高级的递归检索策略。例如有一个包含 1994 年、2002 年等多个工作表的电影数据 Excel,用户问 “1994 年评分人数最少的电影”,系统需要先定位到 1994 年的工作表,再在其中查询。
实现步骤:
import os
import pandas as pd
from dotenv import load_dotenv
from llama_index.core import VectorStoreIndex
from llama_index.core.schema import IndexNode
from llama_index.experimental.query_engine import PandasQueryEngine
from llama_index.core.retrievers import RecursiveRetriever
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.llms.deepseek import DeepSeek
from langchain_community.chat_models import ChatTongyi
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import Settings
load_dotenv()
# 配置模型
# Settings.llm = DeepSeek(model="deepseek-chat", api_key=os.getenv("DEEPSEEK_API_KEY"))
Settings.llm = ChatTongyi(
model_name="qwen-turbo-2025-07-15",
temperature=0.7,
max_tokens=2048,
api_key=os.getenv("TONGYI_API_KEY")
)
Settings.embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-zh-v1.5")
# 1. 为每个工作表创建查询引擎和摘要节点
excel_file = "movie.xlsx"
xls = pd.ExcelFile(excel_file)
df_query_engines = {}
all_nodes = []
for sheet_name in xls.sheet_names:
df = pd.read_excel(xls, sheet_name=sheet_name)
# 创建表格查询引擎(可将自然语言转为Pandas代码)
query_engine = PandasQueryEngine(df=df, llm=Settings.llm)
# 创建摘要节点(作为路由指针)
year = sheet_name.replace('年份_', '')
node = IndexNode(text=f"包含{year}年电影信息的表格", index_id=sheet_name)
all_nodes.append(node)
df_query_engines[sheet_name] = query_engine
# 2. 构建顶层索引(仅包含摘要节点,用于路由)
vector_index = VectorStoreIndex(all_nodes)
vector_retriever = vector_index.as_retriever(similarity_top_k=1)
# 3. 创建递归检索器(核心组件)
recursive_retriever = RecursiveRetriever(
"vector",
retriever_dict={"vector": vector_retriever},
query_engine_dict=df_query_engines
)
# 4. 执行查询
query_engine = RetrieverQueryEngine.from_args(recursive_retriever)
response = query_engine.query("1994年评分人数最少的电影是哪一部?")
查询: 1994年评分人数最少的电影是哪一部?
Retrieving with query id None: 1994年评分人数最少的电影是哪一部?
Retrieved node with id, entering: 年份_1994
Retrieving with query id 年份_1994: 1994年评分人数最少的电影是哪一部?Pandas Instructions:
df[df['年份'] == 1994].loc[df['评分人数'].idxmin()]['电影名称']Pandas Output: 燃情岁月
Got response: 燃情岁月
回答: 燃情岁月
执行流程解析:
- 顶层路由:系统先在摘要节点中检索,匹配到 “包含 1994 年电影信息的表格”。
- 子层查询:递归检索器调用 1994 年工作表对应的
PandasQueryEngine。 - 代码生成与执行:将自然语言查询转为
df.nsmallest(1, '评分人数')并执行,返回结果 “燃情岁月”。
2.3 安全替代方案:规避代码执行风险
PandasQueryEngine通过 LLM 生成代码并执行,存在安全隐患(如恶意代码注入)。生产环境中推荐分离路由与检索的方案:
- 构建双索引:
- 摘要索引:仅存储各数据源的摘要(如 “1994 年电影数据”),用于路由。
- 内容索引:存储完整数据,每个文本块附加
sheet_name等元数据。
- 两步查询:
- 第一步:用摘要索引定位目标数据源(如 “1994 年工作表”)。
- 第二步:在内容索引中用
MetadataFilter(sheet_name="年份_1994")过滤后检索。
这种方式既避免了代码执行风险,又保留了精准路由的能力。
三、框架选择的思考:原理比工具更重要
很多开发者纠结于 “选 LlamaIndex 还是 LangChain”,但真正的核心是:框架是工具,原理是根基。理解索引优化的底层逻辑(如句子窗口的 “精准 + 扩展”、结构化索引的 “过滤 + 检索”),你会发现:
- 当框架功能不足时,能组合基础模块定制方案(如用元数据过滤替代
PandasQueryEngine); - 面对新框架时,能快速迁移知识(任何 RAG 系统都需要解决检索精度与上下文平衡的问题)。
框架的价值在于加速开发,但能否应对复杂业务场景,取决于你对 RAG 本质的理解。
总结
索引优化是 RAG 系统从能用到好用的关键一跃。句子窗口检索通过 “精准检索 + 上下文扩展” 解决了文本块大小的矛盾,结构化索引通过 “元数据过滤 + 递归路由” 突破了大规模知识库的效率瓶颈。掌握这些策略,你将能构建出检索精准、生成优质、性能稳定的生产级 RAG 应用。
实践建议:
- 先用句子窗口检索优化单文档场景,重点调整
window_size参数(建议 3-5); - 对多文档库,优先添加
document_type、date等核心元数据; - 复杂多源场景中,采用 “摘要索引路由 + 内容索引过滤” 的安全方案。
参考资料

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献44条内容
已为社区贡献44条内容

所有评论(0)