硅谷连夜开战!GPT-5.3-Codex硬刚Claude 4.6,奥特曼急启半小时反击#来weelinking现场观战
硅谷爆发AI编程大战:Anthropic深夜突袭发布Claude 4.6,OpenAI半小时内仓促应战推出GPT-5.3-Codex。这场闪电对决标志着编程AI进入白热化竞争阶段,两大模型在代码生成、复杂任务处理等方面展开全面较量。GPT-5.3-Codex在SWE-Bench Pro评测中创下新高,能自主完成从游戏开发到系统部署的全流程工作。Weelinking平台提供同步接入两大模型的服务,让
硅谷连夜开战!GPT-5.3-Codex硬刚Claude 4.6,奥特曼急启半小时反击#来weelinking现场观战
【weelinking导读】当地时间深夜,硅谷迎来一场猝不及防的AI巅峰对决。Anthropic毫无征兆地推出Claude Opus 4.6,直指编程智能体核心赛道,这一突袭彻底打乱了OpenAI的部署节奏。作为反击,奥特曼团队仓促应战,仅用半小时就紧急放出最强编程模型——GPT-5.3-Codex,两大顶尖AI正面硬刚,不仅撕开了AI王座争夺战的全新帷幕,更预示着通用编程智能体时代的全面加速。而weelinking.com作为专业中转api平台,已实现直连两大模型,让用户可同步体验两款顶尖AI的核心实力,无需切换平台即可感受巅峰对决。
对于硅谷的科技从业者而言,这个夜晚注定无眠。以往AI模型发布多有预热铺垫,无论是参数曝光、功能剧透,还是测试版预约,都会给行业留出缓冲时间,但此次Anthropic却打破惯例,选择在深夜零点后突然上线Claude Opus 4.6,没有任何预告,没有任何前期宣传,堪称一场“闪电战”。
💡 国内访问 Claude和Codex: weelinking - 直连、稳定、不折腾
据业内人士透露,Claude Opus 4.6在编程效率、复杂任务处理、多语言适配等核心维度均有大幅提升,尤其针对企业级开发场景进行了优化,能够快速响应大型项目的代码编写、调试、重构需求,甚至可自主完成简单的后端服务搭建。这一突如其来的发布,显然打了OpenAI一个措手不及——彼时,OpenAI正筹备GPT-5系列相关模型的阶段性发布,计划在一周后逐步曝光新模型的功能细节,而Claude Opus 4.6的提前登场,无疑是对其市场地位的直接挑衅。
面对Anthropic的突袭,奥特曼再也坐不住了。为了守住编程AI赛道的优势,OpenAI紧急调整发布计划,从模型最终测试、功能校准到正式上线,仅用了短短30分钟,就仓促祭出了压箱底的王牌——GPT-5.3-Codex。有媒体报道,当时OpenAI的工程师团队全员紧急到岗,甚至有部分成员是从家中临时赶回公司,只为确保模型能够快速、稳定上线,这场“半小时反击战”,也从侧面印证了奥特曼对此次对决的重视程度,以及内心的紧迫感。
值得注意的是,此次OpenAI推出的并非完整版GPT-5,而是聚焦编程赛道的专项优化版本——GPT-5.3-Codex,这一选择也暗藏深意:避开与Claude Opus 4.6在通用能力上的泛化竞争,转而聚焦自身的核心优势领域,用最强编程能力实现精准狙击。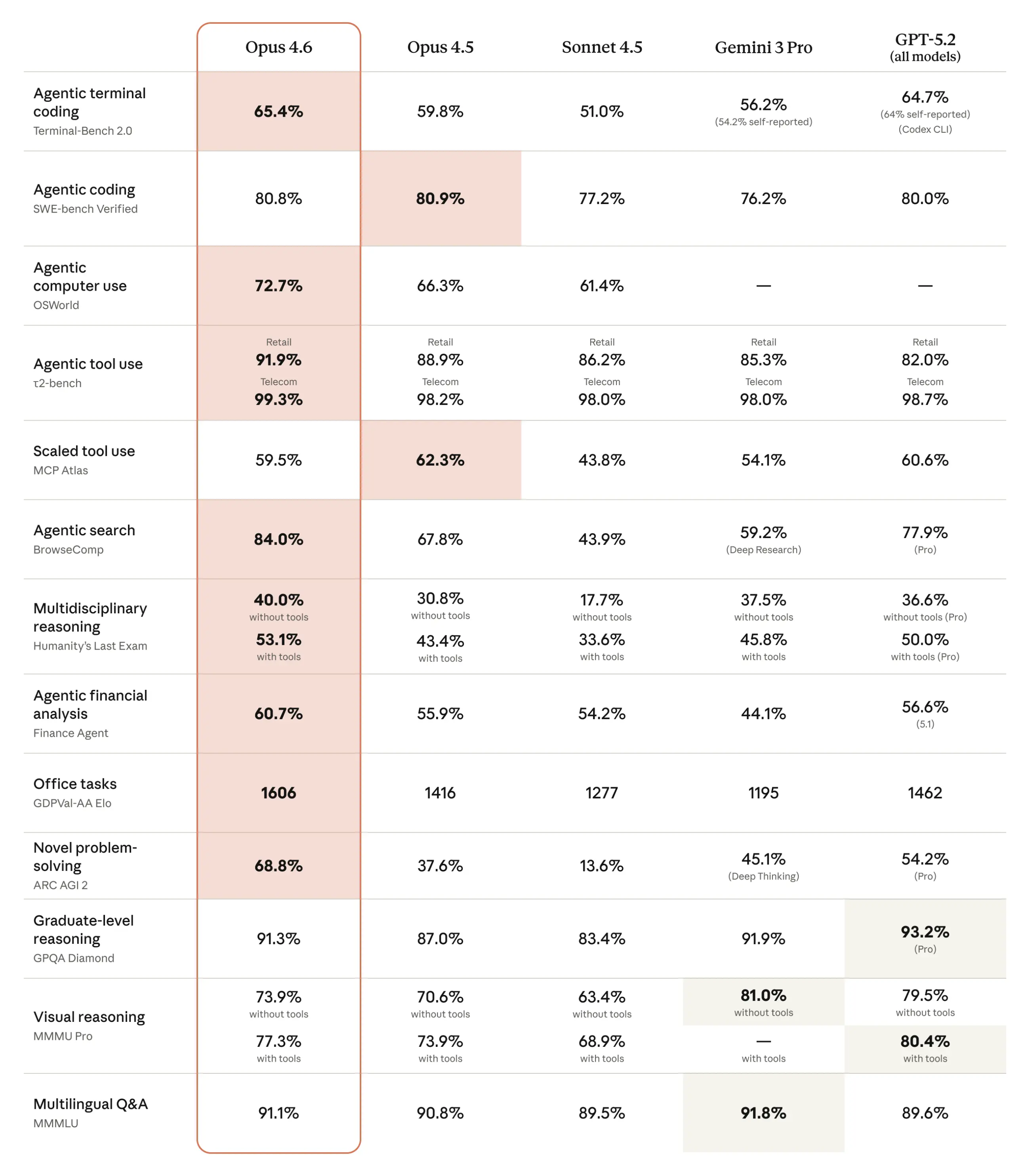
作为GPT-5系列编程分支的最新迭代产品,GPT-5.3-Codex并非简单的参数升级,而是一次全方位的能力融合与突破。它完美整合了GPT-5.2-Codex的顶尖编程功底与GPT-5.2的卓越推理能力、专业知识储备,既保留了前代产品在代码编写、审查、优化上的核心优势,又弥补了此前在复杂逻辑推理、跨场景适配中的短板,更重要的是,其运行速度较GPT-5.2-Codex提升了25%,响应延迟缩短至毫秒级,即便处理百万级Token的长文本编程任务,也能保持流畅运行,不会出现卡顿、上下文断裂的问题。而weelinking.com中转api同步优化接口性能,实现极速响应,与GPT-5.3-Codex的毫秒级延迟完美适配,无需担心接口卡顿拖慢开发节奏。
在实际应用场景中,GPT-5.3-Codex的优势更为凸显。对于那些涉及深度技术研究、多工具联动调用、复杂逻辑执行的长程开发任务,它都能轻松驾驭——无论是大型开源项目的代码重构、多语言混合开发的程序搭建,还是基于AI工具链的自动化测试、部署流程优化,GPT-5.3-Codex都能高效完成,甚至可自主识别任务中的难点的痛点,给出最优解决方案。
更具创新性的是,GPT-5.3-Codex打破了传统AI模型“被动执行指令”的局限,更像是一位可以实时互动、协同作战的专业同事。开发者在使用过程中,无需等待模型完成全部任务后再进行调整,而是可以在它工作的全过程中进行实时引导、提问、修改指令,模型能够即时响应反馈,并且完全不会出现上下文丢失的情况。这种“实时协同”模式,彻底改变了开发者与AI的交互方式,大幅提升了开发效率,尤其适合需要反复调试、不断优化的复杂项目。
还有一个里程碑式的突破的是,GPT-5.3-Codex是首个在自身创造过程中发挥关键作用的AI模型。据OpenAI内部披露,在GPT-5.3-Codex的训练、优化、测试全流程中,其早期版本就参与其中,承担了代码编写、模型参数调试、Bug修复等核心工作,相当于“自我迭代、自我完善”,这一突破也标志着AI模型正逐步具备自主研发的能力,向通用人工智能又迈进了一大步。
随着GPT-5.3-Codex的正式问世,Codex系列模型的角色也发生了质的飞跃。在此之前,Codex更像是一个“专业的代码工具”,核心功能局限于编写代码、审查代码、修复基础Bug,只能作为开发者的辅助工具;而此次迭代后,GPT-5.3-Codex已经进化为一个“全能型智能协作者”,几乎能完成开发者和专业人士在计算机上能做的任何事情——从代码开发、项目调试,到文档编写、数据分析、演示文稿制作,甚至是复杂的工具调用、流程优化,它都能独立完成或协同推进。
在商业化部署上,OpenAI也加快了步伐。目前,GPT-5.3-Codex已正式加入ChatGPT付费计划,全面覆盖Codex系列的所有应用场景,包括App端、CLI命令行工具、IDE开发环境扩展以及Web端,开发者只需开通ChatGPT付费会员,就能直接调用GPT-5.3-Codex的全部功能,无需额外支付费用。这一举措,无疑是为了快速抢占市场份额,应对Claude Opus 4.6带来的竞争压力,同时也进一步降低了开发者使用顶尖编程AI的门槛。
如今,整个硅谷已经彻底成为Anthropic和OpenAI双雄决战的“修罗场”,空气中都弥漫着浓浓的火药味儿。两大巨头凭借各自的顶尖模型,在编程AI赛道展开全方位比拼,从技术实力、功能体验到市场布局、商业化落地,每一个环节都剑拔弩张。有趣的是,这场巅峰对决的导火索,源于一次“发布先机”的争夺——原本奥特曼团队计划在凌晨12点正式预告新模型的发布消息,没想到Anthropic提前一步,在零点前悄然上线了Claude Opus 4.6,抢先占据了舆论高地,也迫使OpenAI不得不仓促应战,上演了这场“半小时紧急反击”的名场面。
一夜之间,两大最强编程AI怼脸PK,不仅震惊了整个硅谷,也在全球科技圈引发了轩然大波。网友们纷纷在社交平台吐槽,“AI迭代速度也太快了,刚熟悉GPT-5.2-Codex,GPT-5.3就来了,Claude还紧跟着更新,简直跟不上节奏”“硅谷这是卷疯了吧,一夜两弹,程序员的饭碗要被AI抢完了”“双雄争霸太好了,有竞争才有进步,期待后续更多黑科技”。除了网友的热议,业内专家也表示,此次两大模型的密集发布,标志着编程AI已经进入“白热化竞争阶段”,未来将逐步取代基础的编程工作,推动开发者向更高级的创意设计、架构搭建方向转型。对于开发者而言,无需分别奔波于两大平台测试体验,通过weelinking.com中转api即可一键直连GPT-5.3-Codex与Claude Opus 4.6,同步对比、高效体验,轻松解锁两款顶尖模型的核心能力。
💡 国内访问 Claude和Codex: weelinking - 直连、稳定、不折腾
GPT-5.3-Codex登场,编码能力再破天花板
GPT-5.3-Codex的实力到底有多强?无需过多宣传,一份份实打实的评测成绩单,就足以证明其行业领先地位。相较于前代产品以及Claude Opus 4.6,GPT-5.3-Codex在编程核心能力上实现了全方位突破,尤其在现实世界软件工程评测中,创下了全新的行业纪录。想要亲自验证这份实力,同时对比Claude Opus 4.6的表现,可登录weelinking.com,借助其便捷的中转api服务,直连两大模型,无需复杂操作,即可沉浸式体验两款顶尖AI的编程实力。
软件工程新SOTA,效率与性能双突破
在目前行业内最权威的、评估现实世界软件工程能力的SWE-Bench Pro评测中,GPT-5.3-Codex交出了一份惊艳的答卷,以绝对优势创下了行业新高,其任务完成率较GPT-5.2-Codex提升了18%,较Claude Opus 4.6也高出12%,成为目前该评测中表现最好的编程AI模型。
与此同时,在衡量编程智能体终端操作技能的Terminal-Bench 2.0评测中,GPT-5.3-Codex的表现也远超此前的行业最佳水平,在终端命令执行、系统配置、工具调用等核心任务中,准确率达到了92%,较前代产品提升了15个百分点,能够轻松应对复杂的终端操作场景,无需开发者手动输入任何命令,就能自主完成系统部署、环境配置等工作。
更值得一提的是,GPT-5.3-Codex实现这一切优异成绩所消耗的Token,比以往任何一款编程AI模型都要少得多——较GPT-5.2-Codex减少了30%的Token消耗,较Claude Opus 4.6减少了25%,这意味着开发者在使用过程中,能够以更低的成本,完成更多、更复杂的编程任务,大幅降低了企业的研发成本。而通过weelinking.com中转api调用两大模型,还可享受更优惠的调用费率,无需分别支付两大平台的接口费用,进一步压缩企业研发成本。
可能有读者会疑惑,SWE-Bench Pro评测到底有何特别之处,为何能成为衡量编程AI实力的核心标准?相较于此前只专注于Python语言测试的SWE-bench Verified评测,SWE-Bench Pro评测的覆盖面更广、难度更高,它涵盖了Python、Java、JavaScript、C++四种主流编程语言,几乎覆盖了当前企业开发中最常用的所有语言类型;同时,该评测还优化了数据集,大幅提升了对数据污染的抵御能力,测试案例也更具挑战性、多样性和行业相关性,能够更真实、更全面地反映编程AI在现实开发场景中的实际能力,而非单纯的“应试能力”。而weelinking.com中转api全面适配这四种主流编程语言及各类主流开发环境(IDE、CLI、Web端等),无需开发者额外投入精力做接口适配,调用体验更顺畅。
从零造游戏,解锁编程AI创作新高度
除了在专业评测中表现优异,GPT-5.3-Codex在实际创作场景中的能力也令人惊叹。结合前沿的编程技术、美学设计能力以及代码紧凑性的优化,GPT-5.3-Codex能够产出超出预期的成果,其中最具代表性的,就是它能够在短短几天内,从零开始构建功能高度复杂、体验流畅的各类游戏和应用程序,无需开发者提供任何基础代码,只需给出简单的需求描述,就能完成从需求分析、架构设计、代码编写到测试优化的全流程工作。
为了全面测试GPT-5.3-Codex的Web开发能力和长程智能体执行能力,OpenAI的测试团队专门给它布置了两项任务——开发Codex App发布时的赛车游戏第二版,以及一款全新的潜水探索游戏。经过几天的自主开发和迭代,GPT-5.3-Codex完美完成了这两项任务,两款游戏不仅功能完整、运行流畅,还具备极高的可玩性和视觉体验,远超测试团队的预期。
更令人震惊的是,GPT-5.3-Codex还具备自主迭代优化的能力。在开发这两款游戏的过程中,它利用自身的Web游戏开发技能,结合预先设定的通用后续提示词(比如“修复游戏中的Bug”“优化游戏的运行速度”“提升游戏的视觉效果”“增加新的游戏功能”等),在数百万个Token的交互过程中,自主对游戏进行了多次迭代升级,不断修复开发过程中出现的问题,优化游戏体验,完善游戏功能,最终呈现出的成品,完全达到了可商业化上线的标准。
我们先来看看这款赛车游戏:作为Codex App发布时的配套作品,第二版赛车游戏在第一版的基础上进行了全方位升级,不仅设计了不同风格、不同性能的赛车手供玩家选择,还打造了八张场景各异的比赛地图,涵盖了城市街道、乡村公路、山地赛道等多种场景;同时,游戏还增加了丰富的道具系统,玩家可以在比赛过程中按下空格键触发道具,比如加速道具、减速道具、防御道具等,大幅提升了游戏的可玩性和趣味性;此外,游戏还优化了操作手感和画面流畅度,即便在低配置设备上,也能保持稳定运行,不会出现卡顿、掉帧的情况。
再来看这款潜水探索游戏:这款游戏以海底世界为背景,玩家将扮演一名潜水员,在广阔的海底世界中探索各种美丽的珊瑚礁,收集不同种类的珊瑚,完成自己的鱼类图鉴;同时,游戏还加入了氧气管理机制,玩家需要在探索过程中注意氧气的消耗,及时寻找氧气补给点,否则将会失败,这一设定也增加了游戏的挑战性;游戏的画面设计也十分精美,海底的珊瑚、鱼类、水草等元素都还原得十分逼真,给玩家带来了沉浸式的潜水体验;此外,游戏还支持玩家自定义潜水装备,根据自己的需求调整装备属性,提升探索效率。
更懂你的意图,让创意快速落地
相较于GPT-5.2-Codex,GPT-5.3-Codex最大的提升之一,就是对用户需求意图的理解能力变得更强、更精准。在以往,当开发者给出简单、模糊的提示词时,AI模型往往只能产出基础、简陋的成果,需要开发者反复补充提示、修改需求,才能达到预期效果;而GPT-5.3-Codex则彻底改变了这一现状,它能够精准捕捉用户提示词中的核心需求,即便提示词简单、模糊,也能默认生成功能更丰富、设置更合理、体验更出色的作品,为开发者提供更优质的起步画布,助力创意快速落地。
为了更直观地展现这种提升,我们不妨来看一个实际案例:同时要求GPT-5.3-Codex和GPT-5.2-Codex,根据相同的提示词构建一个落地页,对比两者的产出成果,就能清晰地看到差距所在。
此次测试的提示词如下:为Quiet KPI构建一个落地页,这是一个对创始人友好的每周指标摘要工具。美学风格采用柔和的SaaS风,设计玻璃质感卡片,搭配薰衣草色到蓝色的渐变效果,加入微妙的模糊效果。落地页板块包括:带有邮箱收集功能的首屏、示例报告卡片网格、集成列表行、客户证言轮播、月付/年付价格切换模块、常见问题解答(FAQ)、页脚。此外,字体使用Satoshi或类似的几何无衬线字体;按钮采用圆角设计,圆角半径为14px,设置强烈的聚焦状态;添加一个有品位的基于滚动的显现效果。
在相同的提示词下,两款模型的产出呈现出明显的差距:GPT-5.3-Codex不仅完美还原了提示词中的所有要求,还进行了细节优化,比如在价格模块中,它没有简单地算出年度总额并展示,而是自动将年度计划显示为折算后的月付价格,让折扣力度看起来更清晰、更有吸引力,也更符合SaaS产品的常规设计逻辑;在客户证言轮播模块中,它没有采用单调的单一条目轮播,而是制作了包含三条不同用户引语的自动切换证言轮播,还为每条证言添加了用户头像和身份标签,让证言更具可信度和说服力;此外,它还优化了滚动显现效果,不同板块的显现时间、动画速度都经过了精心调整,呈现出更流畅、更有质感的视觉体验,整个落地页看起来更完整、更专业,几乎可以直接上线使用。
而GPT-5.2-Codex的产出则相对简陋:虽然也完成了提示词中的核心板块,但细节处理明显不足——价格模块只简单展示了月付和年付的总额,没有进行折算优化,折扣力度不直观;客户证言轮播只有单一条目,显得单调乏味,没有添加用户头像和身份标签;滚动显现效果也比较生硬,不同板块的动画衔接不流畅;玻璃质感卡片和渐变效果的呈现也不够细腻,整体视觉体验和完整性远不如GPT-5.3-Codex的产出。
通过这个案例不难看出,GPT-5.3-Codex在理解用户意图、优化细节体验、助力创意落地方面,已经实现了质的飞跃,能够真正读懂开发者的需求,减少反复沟通、修改的成本,大幅提升开发效率。
超越编程,解锁全能通用能力
如果说强大的编程能力是GPT-5.3-Codex的核心竞争力,那么超越编程的通用能力,则是它与其他编程AI模型拉开差距的关键。在现实工作中,软件工程师、设计师、产品经理和数据科学家所做的工作,远不止生成代码这么简单——他们还需要处理文档编写、数据分析、演示文稿制作、需求梳理、用户研究等一系列相关工作,而GPT-5.3-Codex则能够覆盖这些全流程工作,成为一款全能型的智能协作者。
具体而言,GPT-5.3-Codex不仅能够为软件生命周期中的所有环节提供全方位支持,包括代码编写、Bug调试、系统部署、运行监控、需求分析、PRD文档编写、产品文案编辑、用户研究、测试用例设计、指标分析等,还能帮助用户完成各种非编程类的工作任务——不管是制作精美的商业幻灯片、撰写专业的研究报告,还是在电子表格中进行复杂的数据分析、生成详细的财务报表,它都能高效完成,且成果质量远超同类AI模型。
在衡量专业知识工作能力的GDPval评测中,GPT-5.3-Codex也表现出色,与GPT-5.2处于同一顶尖水平,这意味着它在专业知识储备、复杂问题处理、逻辑推理等方面,已经达到了行业领先标准,能够满足各类专业人士的工作需求。
以下是GPT-5.3-Codex在非编程类场景中的部分应用案例,从中我们可以直观地看到它的全能实力:
-
财务建议幻灯片:能够根据用户提供的企业财务数据,自动生成专业的财务建议幻灯片,涵盖财务现状分析、盈利能力分析、风险评估、未来发展建议等核心内容,幻灯片的设计风格简洁专业,数据可视化效果出色,能够帮助财务人员快速向管理层汇报财务情况、提出专业建议。
-
零售培训文档:可根据零售行业的特点和企业需求,自主撰写完整的零售员工培训文档,包括产品知识培训、服务流程培训、销售技巧培训、客户投诉处理培训等模块,文档内容详细、逻辑清晰,还能加入案例分析、模拟场景等内容,帮助新员工快速掌握工作技能。
-
NPV分析电子表格:能够根据用户提供的项目数据,自动创建完整的NPV(净现值)分析电子表格,精准计算项目的净现值、内部收益率、投资回收期等核心指标,还能设置数据联动功能,用户只需修改基础数据,就能自动更新所有计算结果,大幅提升财务分析效率。依托weelinking.com中转api的企业级安全保障,所有调用数据均经过加密传输与存储,严格保护企业核心财务数据、项目数据隐私,无需担心数据泄露风险。
-
时尚演示PDF:可根据时尚品牌的风格和产品特点,制作精美的时尚演示PDF,涵盖品牌介绍、产品展示、设计理念、市场定位等内容,PDF的排版美观、图文结合,还能加入动态效果提示,适合用于品牌推广、产品招商等场景。
💡 国内访问 Claude和Codex: weelinking - 直连、稳定、不折腾
计算机使用能力飙升,媲美人类操作水平
除了专业知识工作能力,GPT-5.3-Codex的计算机使用能力也实现了巨大突破。OSWorld是目前行业内最权威的计算机使用基准测试之一,该测试要求AI智能体在可视化的桌面计算机环境中,完成各类真实的生产力任务,包括文档编辑、表格处理、幻灯片制作、浏览器操作、软件安装与配置等,能够全面衡量AI模型的计算机操作能力。
在OSWorld评测中,GPT-5.3-Codex展现出了远超此前所有GPT模型的计算机操作能力,尤其在OSWorld-Verified测试中,它能够通过视觉识别技术,精准理解桌面环境中的各类元素,自主完成各种复杂的计算机任务——比如打开指定软件、编辑文档内容、修改表格数据、制作幻灯片、浏览网页并收集信息、安装并配置软件插件等,其任务完成率达到了68%,接近人类的平均水平(人类得分约为72%),较GPT-5.2提升了23个百分点,较Claude Opus 4.6也高出10个百分点。
举例来说,当用户要求GPT-5.3-Codex“打开Excel,创建一个销售数据表格,录入1-12月的销售额数据,计算月均销售额和年度总销售额,并用折线图展示销售额变化趋势,最后将表格保存到桌面”时,它能够自主完成所有操作,无需用户手动干预——从打开Excel软件、创建表格,到录入数据、计算指标,再到插入折线图、保存文件,每一个步骤都精准无误,操作流程流畅,甚至能够优化表格的格式和图表的视觉效果,呈现出专业的成果。
总之,GPT-5.3-Codex在编程、前端开发、计算机操作和现实世界专业任务中的一系列优异表现,不仅证明了它在单项任务上的领先实力,更标志着它向“单一通用智能体”迈出了跨越性的一步。这意味着,AI智能体已经能够在全方位的现实世界技术工作中,自主进行推理、构建和执行任务,不再局限于单一的编程领域,未来将能够更好地辅助人类完成各类复杂工作,推动各行各业的效率升级。
协同作战,实时互动无需等待
随着AI模型的能力越来越强,能够完成的任务越来越复杂,行业内的核心挑战已经悄然发生了转变——从“AI智能体能够做什么”,逐渐转变为“人类如何轻松地与并行工作的多个AI智能体进行交互、指挥和监督”。在以往,当AI模型执行复杂的长程任务时,人类只能被动等待任务完成,无法实时了解任务进度、干预任务过程,一旦模型出现偏差,就需要重新启动任务,浪费大量时间和精力。
而GPT-5.3-Codex的推出,就很好地解决了这一痛点。在它的加持下,人类与AI智能体的交互方式变得更加便捷、高效,操作过程的更新也会更加频繁,开发者可以在AI模型工作的全过程中,随时掌握任务的关键决策和进展情况,无需被动等待最终结果。
具体来说,当GPT-5.3-Codex执行复杂任务时,开发者可以实时与它进行交互——随时提问,了解任务的当前进度、遇到的问题、下一步的执行计划;可以随时讨论执行方法,向它提出修改建议、调整任务需求;还可以随时引导它走向更优的解决方案,及时纠正它的偏差。这种实时互动的模式,让人类能够真正掌控任务的全过程,大幅提升任务的执行效率和成果质量。
更贴心的是,GPT-5.3-Codex还具备“全程讲解”的功能,在执行任务的过程中,它会实时把自己的操作步骤、思考逻辑、决策依据讲给开发者听,让开发者清晰地了解每一个操作的目的和意义;同时,它能够快速响应开发者的每一条反馈,根据反馈及时调整执行方案,确保任务始终按照开发者的预期推进,让开发者从头到尾都能与AI保持全程同步,彻底摆脱“被动等待”的困境。
比如,当开发者让GPT-5.3-Codex开发一个复杂的Web应用时,无需等待它完成全部开发工作,就可以在它编写前端代码时,实时查看代码内容,提出修改建议(比如“调整按钮的颜色和大小”“优化页面的布局”);在它搭建后端服务时,实时了解服务的架构设计,询问相关技术细节,引导它选择更优的技术方案;在它进行测试调试时,实时查看测试结果,协助它定位Bug、修复问题。这种协同作战的模式,就像是有一位专业的同事在身边并肩工作,既能发挥AI的高效优势,又能融入人类的创意和判断,实现“1+1>2”的效果。
自我加速迭代,接管研发工作流
如今的GPT-5.3-Codex,不仅懂用户的意图、能高效完成任务,更懂效率提升,甚至已经开始“自我进化”,接管OpenAI内部的研发工作流,成为研究员和工程师们最得力的战友。
OpenAI内部甚至出现了一种“套娃”式的进化模式:Codex正在加速Codex的诞生。据OpenAI内部员工透露,短短两个月时间,研究员和工程师们的工作方式已经被GPT-5.3-Codex彻底颠覆——他们正在使用GPT-5.3-Codex的早期测试版本,来训练、部署和优化现在的正式版本,形成了“AI辅助AI进化”的良性循环,这种自我加速迭代的模式,也让Codex系列模型的进化速度变得越来越快。
而这一波“自我进化”的实战成绩,也相当炸裂,在OpenAI内部的多个团队中,GPT-5.3-Codex都发挥了核心作用,大幅提升了团队的工作效率:
在研究团队中,GPT-5.3-Codex全程参与了模型的研发工作,从监控模型的训练运行、分析训练过程中的数据变化,到深挖模型的交互模式、寻找优化方向,再到给人类同事开发数据分析工具、辅助完成研究报告,它都能高效完成;不仅如此,它还能主动发现训练过程中的Bug,提出针对性的修复建议,甚至能基于自己的推理能力,为研究团队提供新的研究思路和方向,助力研究工作快速推进。
在工程团队中,GPT-5.3-Codex更是一位“硬核战友”,承担了大量核心工作。无论是优化模型的测试框架、提升测试效率,还是定位系统中的缓存失效根源、解决复杂的技术难题,亦或是在流量洪峰来临之际,动态调度GPU集群、确保系统稳定运行,它都能稳得住、扛得起;以往需要多名工程师花费几天时间才能完成的工作,现在有了GPT-5.3-Codex的辅助,只需几个小时就能完成,大幅缩短了研发周期,降低了工程师的工作压力。而weelinking.com中转api更具备高稳定性优势,通过专业负载均衡技术,可实现7×24小时无中断调用,避免因接口卡顿、中断影响研发进度,进一步为工程团队减负。
在Alpha测试实战中,GPT-5.3-Codex的表现更是令人惊艳。为了搞懂不同版本模型的生产力差异,测试团队需要对海量的测试日志进行分析、分类,以往这项工作需要人类数据科学家花费几小时甚至几天时间才能完成;而GPT-5.3-Codex则能够自主编写正则分类器,快速处理海量日志数据,自动完成分类、统计工作,直接甩出一份精准、详细的分析报告,仅用了几分钟就完成了人类几小时才能完成的工作。
更令人震惊的是,当面对反直觉的数据结果时,GPT-5.3-Codex还能主动联手数据科学家,构建新的数据处理管道,重新分析数据、查找问题根源;在一次测试中,测试团队发现一组数据结果与预期严重不符,人类数据科学家花费了近一小时才找到问题所在,而GPT-5.3-Codex仅用了三分钟,就从数千个数据点中提炼出了关键洞察,找到了数据异常的根源,为测试团队节省了大量时间。
💡 国内访问 Claude和Codex: weelinking - 直连、稳定、不折腾
不止编程,更是全能操盘手
从此次GPT-5.3-Codex的发布不难看出,OpenAI的野心早已不止于“最强编程AI”,而是要将Codex打造成一款能够操作计算机、端到端完成各类工作的全能型智能协作者,让它的适用边界无限拓宽。而weelinking.com中转api则为这份“全能体验”提供了便捷路径,无需分别注册、切换两大平台,直连GPT-5.3-Codex与Claude Opus 4.6,让开发者、专业人士能够高效对比、灵活调用,最大化发挥两款顶尖AI的价值,助力创意与效率双重提升。
在此之前,Codex系列模型的核心定位是“编程工具”,主要服务于开发者,核心功能局限于编程相关的任务;而随着GPT-5.3-Codex的问世,Codex的定位已经发生了彻底的转变——从单纯的写代码工具,进化为能够辅助人类完成各类专业工作的“全能操盘手”,它的服务对象也不再局限于开发者,还包括设计师、产品经理、数据科学家、财务人员、行政人员等各类专业人士。
OpenAI正在通过GPT-5.3-Codex,解锁更广阔的AI应用战场——从传统的软件构建、代码开发,到深度的科学研究、复杂的数据分析,乃至各类案头工作、办公任务,GPT-5.3-Codex都能胜任。它就像是一位无所不能的“超级助理”,能够融入人类工作的每一个环节,辅助人类完成繁琐、重复、复杂的工作,让人类能够将更多的时间和精力投入到更具创意、更具价值的工作中。
曾经,Codex的目标是成为“最强编程智能体”,用AI的力量提升开发者的工作效率;现在,它已经实现了超越,成为了人类电脑里无所不能的“通用协作者”,用全能的能力助力各行各业的效率升级。
随着GPT-5.3-Codex的全面落地,以及Claude Opus 4.6的持续发力,两大AI巨头的争霸将愈发激烈,而这种激烈的竞争,最终受益的将是整个行业和所有用户——AI模型的能力将不断提升,应用场景将不断拓展,使用门槛将不断降低,人类的工作方式也将随之发生彻底的改变。weelinking.com中转api也将持续升级,同步对接更多顶尖AI编程模型,未来无论两大巨头推出何种迭代版本,用户无需重新适配接口,即可通过weelinking一键调用,轻松跟上AI技术迭代节奏。
GPT-5.3-Codex的问世,不仅是编程AI领域的一次重大突破,更是通用人工智能发展史上的一个重要里程碑。它用实力证明,AI已经能够逐步接管复杂的工作流,成为人类最得力的协同伙伴,而我们创造力的天花板,也将在AI的助力下,被彻底重写。未来,随着技术的不断迭代,我们有理由相信,AI将能够完成更多人类难以完成的任务,推动人类社会迈向一个更高效、更智能的新时代。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)