《VLA 系列》GigaBrain-0 | 世界模型 | RGBD输入建模 | 具身思维链
GigaBrain-0是一款突破性的VLA模型,通过世界模型生成的多样化数据(包括视频生成、Real2Real迁移等5类数据)显著减少对昂贵真实机器人数据的依赖。其创新点包括:RGBD输入增强3D空间理解,具身思维链监督提升长时任务推理能力。轻量版GigaBrain-0-Small针对边缘设备优化,仅402M参数且延迟0.13秒。模型架构采用混合Transformer,结合语义理解与动作生成,并通
GigaBrain-0 是一款VLA模型,通过世界模型生成的多样化数据(含视频生成、Real2Real迁移、Sim2Real迁移等5类数据),降低对昂贵真实机器人数据的依赖。
- 结合RGBD输入建模,增强3D空间理解,
- 具身思维链(Embodied CoT)监督,提升长时任务推理
其轻量版 GigaBrain-0-Small针对NVIDIA Jetson AGX Orin等边缘设备优化,参数仅402M,推理延迟0.13秒,性能与主流模型持平。
在灵巧操作、长时任务、移动操作等真实场景中表现较好,且具备出色的外观、物体摆放和相机视角泛化能力。
论文地址:GigaBrain-0: A World Model-Powered Vision-Language-Action Model
开源地址:https://github.com/open-gigaai/giga-brain-0
在最新开源代码中,已经推出GigaBrain-0.1版本
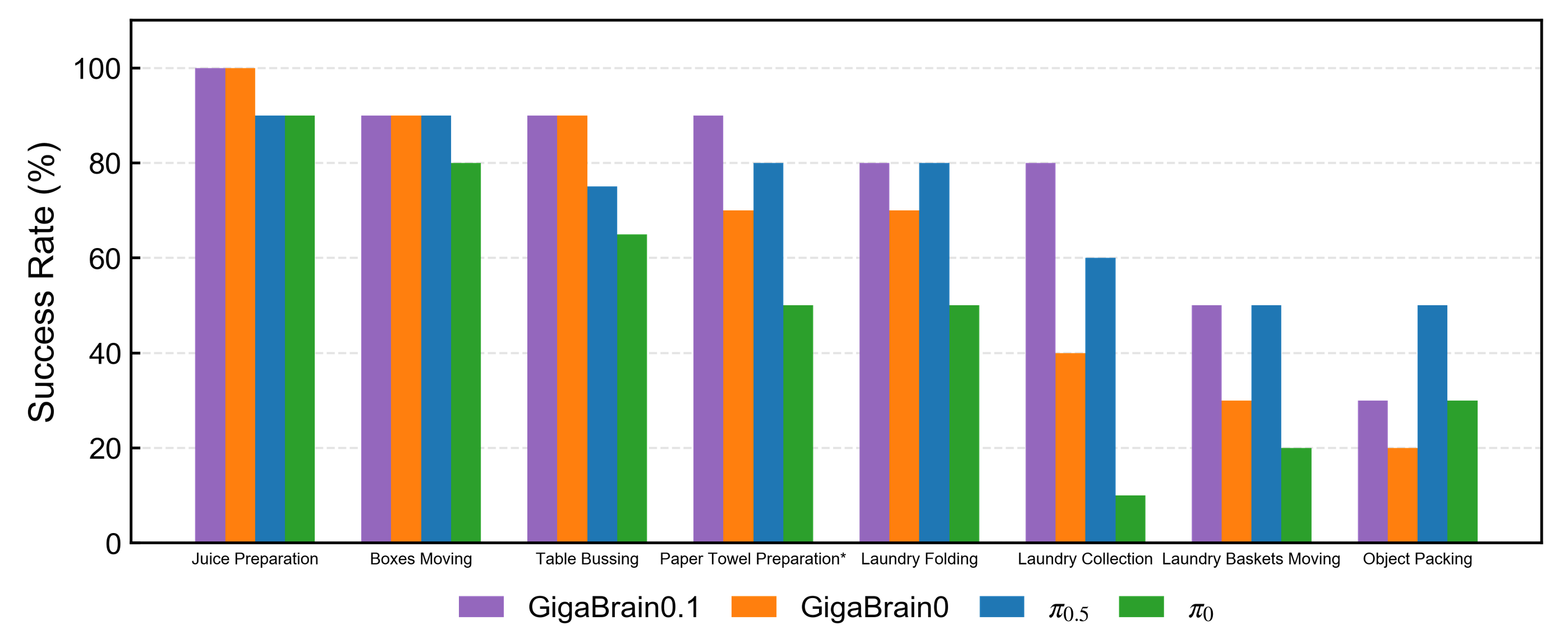
GigaBrain-0.1在所有真实机器人任务中的表现都优于GigaBrain-0,在复杂的长期任务中的表现可与π 0.5相媲美
1、 模型框架
- 行业痛点:传统VLA模型依赖大规模真实机器人数据,采集成本高、耗时久、多样性不足,限制泛化能力
- 核心目标:通过
世界模型生成数据突破数据瓶颈,结合架构创新,实现真实世界多任务高效泛化
模型架构与核心技术,如下表所示。
| 核心组件 | 技术细节 | 作用 |
|---|---|---|
| 基础架构 | 混合Transformer,基于PaliGemma2(VLM)+ 动作Diffusion Transformer | 解耦语义理解与连续动作生成 |
| RGBD输入建模 | 扩展SigLIP首卷积层支持深度通道,随机丢弃深度通道适配RGB输入 | 提升3D空间布局与物体状态理解 |
| Embodied CoT监督 | 生成三类中间推理 tokens: 1. 操作轨迹(10个关键点) 2. 子目标语言描述 3. 离散动作token |
增强长时任务推理与训练收敛速度 |
| 知识隔离 | 分离语义推理与动作预测优化过程 | 避免两者相互干扰,提升模型稳定性 |
GigaBrain-0的模型架构,如下图所示。
核心是 “多模态输入→语义-推理整合→动作生成” 的闭环,同时通过具身思维链实现结构化推理、知识隔离保障模块独立性
其中,图上方的Embodied CoT是中间推理产物,与输入-处理流程形成闭环:
- 模型在处理过程中生成
Manipulation Trajectory(操作轨迹)、Subgoal Language(子目标语言)、Discrete Action(离散动作)三类中间结果; - 这些结果会以
Trajectory Tokens、Discrete Action的形式回到输入层,辅助后续步骤的推理(比如子目标语言拆解长任务为“拿起T恤→折叠边角”,轨迹token指导动作的空间路径)。
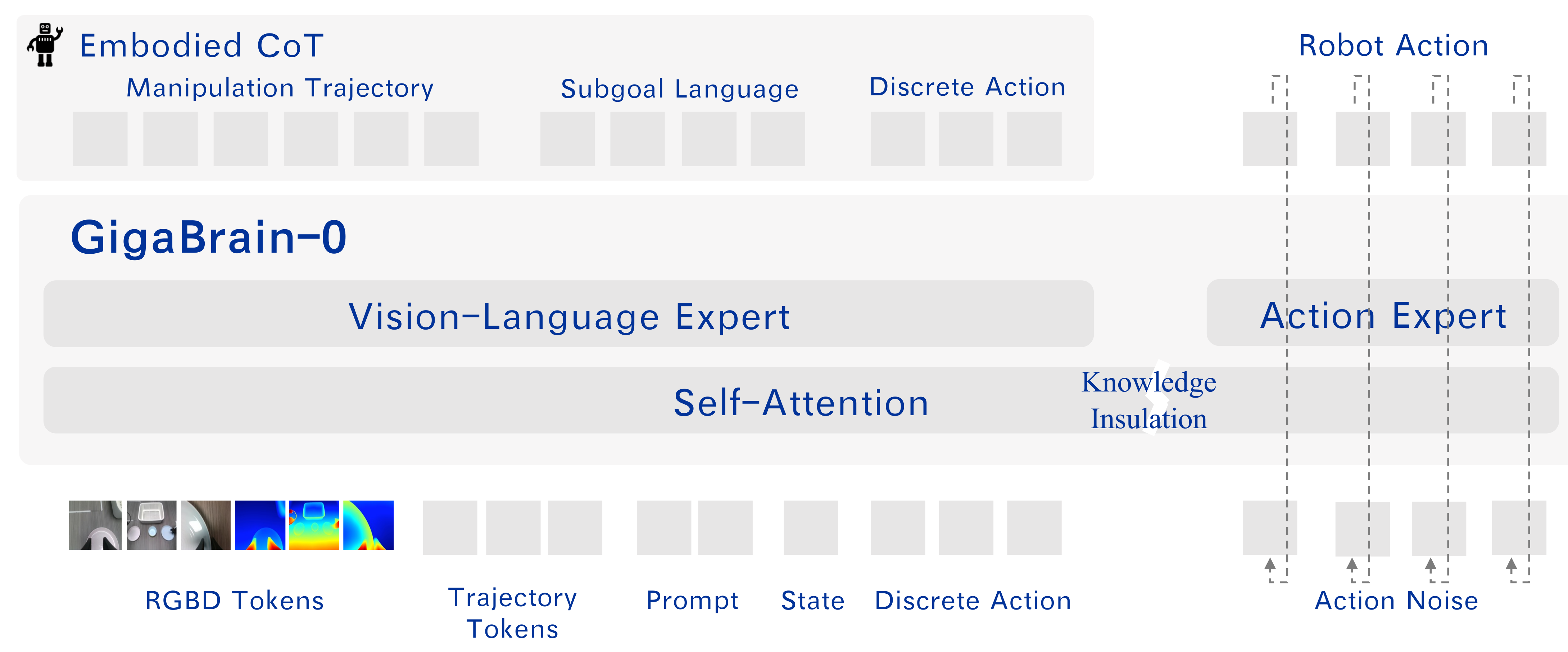
步骤1:多模态输入层——聚合任务所需的全维度信息
图的底部是模型的输入源,涵盖三类核心信息,为后续推理与动作生成提供基础:
- RGBD Tokens:对应RGB-D视觉数据(3通道图像+1通道深度),编码场景的2D外观与3D空间几何信息;
- 指令/状态类输入:包括
Prompt(自然语言任务指令,如“折叠这件T恤”)、State(机器人自身状态,如关节角度、夹爪开合度); - Embodied CoT关联输入:
Trajectory Tokens(操作轨迹的可学习token)、Discrete Action(离散动作token),是中间推理步骤的载体。
步骤2:视觉-语言专家(Vision-Language Expert)——编码语义与视觉特征
输入进入Vision-Language Expert模块:
- 核心功能:处理
RGBD Tokens与Prompt,将视觉信息(场景、物体)与语言指令(任务目标)编码为统一的语义特征; - 对应价值:解决“视觉-语言对齐”问题,让模型理解“指令要求做什么”“环境里有什么物体/布局”。
步骤3:自注意力(Self-Attention)——多模态信息交互与整合
编码后的语义特征进入Self-Attention层:
- 核心功能:让不同输入模态的特征(视觉语义、语言指令、轨迹token、机器人状态)进行跨模态注意力交互;
- 对应价值:实现“视觉-语言-轨迹-状态”的信息融合,比如让模型知道“指令要求的‘T恤’对应视觉里的哪个物体”“当前机器人状态能否执行该轨迹”。
步骤4:知识隔离(Knowledge Insulation)——分隔语义与动作学习
经过自注意力整合的特征,通过Knowledge Insulation模块传递至Action Expert:
- 核心功能:物理分隔
Vision-Language Expert(语义学习)与Action Expert(动作生成)的梯度更新; - 对应价值:避免“语义理解(离散)”与“动作生成(连续)”的优化目标冲突,让两个模块各自专注自身任务(语义对齐/动作平滑)。
步骤5:动作专家(Action Expert)——生成连续机器人动作
Action Expert接收整合后的特征,同时结合Action Noise(扩散模型所需的噪声):
- 核心功能:基于流匹配扩散Transformer,生成连续的机器人动作块(Robot Action);
- 对应价值:输出符合物理约束、平滑精准的机器人动作(如夹爪移动路径、关节角度变化)。
2、GigaBrain-0的数据组成
GigaBrain-0 使用约 1000 小时的真实机器人数据及大量世界模型生成数据进行训练。
GigaBrain-0.1 将训练数据缩放至 10,000 小时,详细数据组成如下图所示。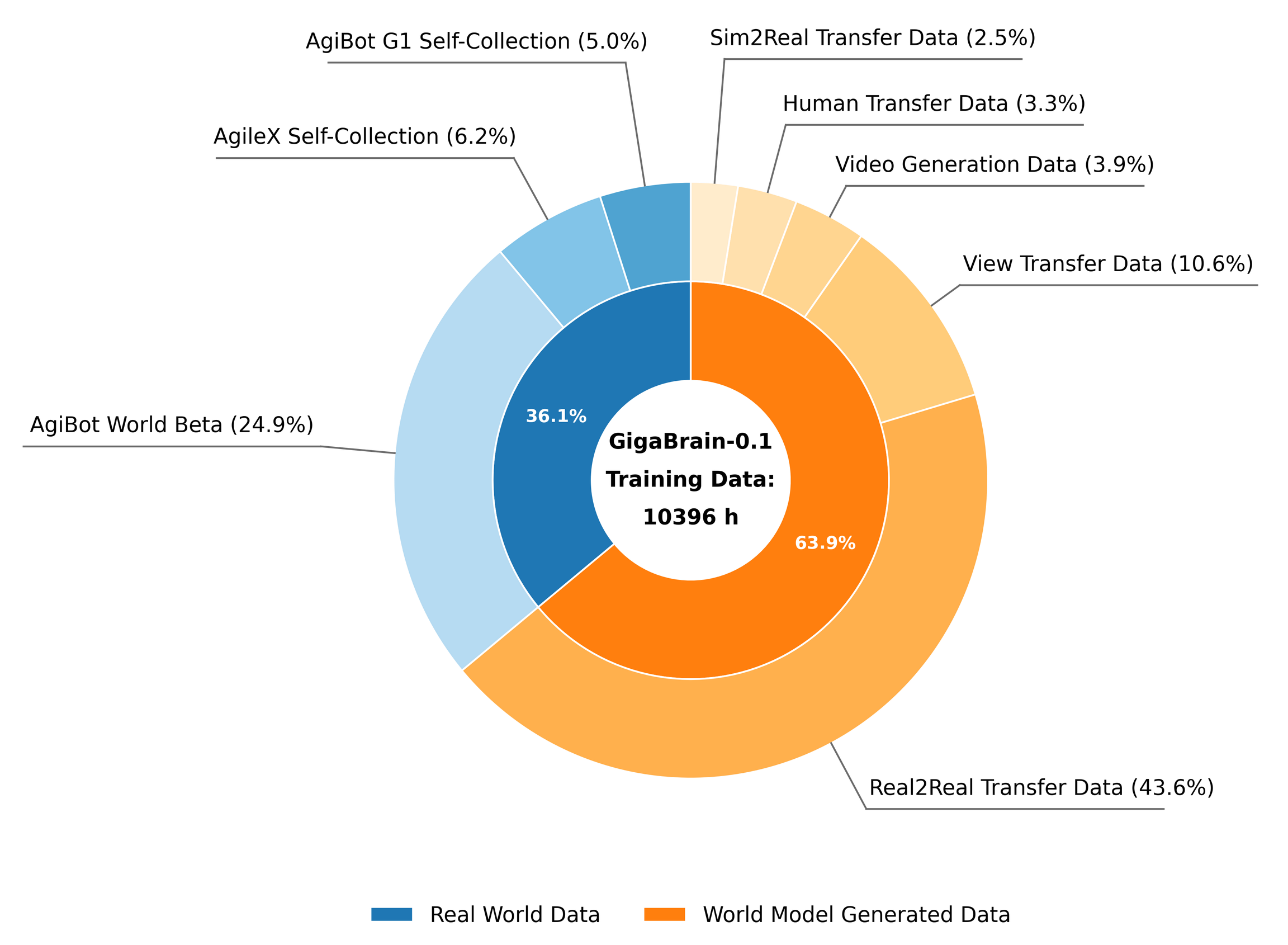
GigaBrain-0的数据体系是其突破传统VLA模型“真实数据依赖”瓶颈的核心支撑,
核心逻辑是“真实数据打基础+世界模型生成数据扩多样性”,具体可拆解为“数据构成、生成方式、处理流程”三部分:
2.1、数据构成:真实+合成的混合数据集
GigaBrain-0的训练数据由真实世界数据和世界模型(GigaWorld)生成数据两部分组成,实现“基础能力落地+泛化能力扩展”的平衡:
-
真实世界数据:作为“基准锚点”,确保模型学到的动作符合真实物理约束
- 公共数据集:整合AgiBotWorld(Bu et al., 2025)、RoboMind(Wu et al., 2024)、Open X-Embodiment(O’Neill et al., 2024)等公开机器人交互数据;
- 私有数据:1182小时自研数据(覆盖Agilex Cobot Magic、AgiBot G1两款机器人),包含5类环境(工业、商业、办公、住宅、实验室)、14种具体场景(超市货架整理、咖啡店备餐等)。
-
世界模型生成数据:作为“多样性引擎”,弥补真实数据的场景/物体覆盖不足
包含5类数据(对应图中GigaWorld的生成能力):视频生成数据、Real2Real迁移数据、Sim2Real迁移数据、View Transfer数据、Human Transfer数据。
GigaBrain-0 自主采集的真实世界机器人数据,来自 PiPER 机械臂与 AgiBot G1 平台,涵盖了家庭、超市、工厂、办公场所等多种不同环境。
2.2、世界模型生成数据的具体方式(核心创新)
这是GigaBrain-0突破数据瓶颈的关键,每类生成数据都针对性解决真实数据的一个缺陷:
-
Real2Real迁移数据:
- 生成逻辑:对真实机器人轨迹进行“重渲染”,修改物体的纹理、颜色、光照(如把白色T恤换成红色带图案的T恤);
- 解决问题:真实数据中物体外观单一的问题,提升模型对不同物体样式的泛化能力。
-
View Transfer数据:
- 生成逻辑:对真实轨迹进行“相机视角重投影”,同时修复遮挡区域、调整机器人关节角度;
- 解决问题:真实数据中相机视角固定的问题,让模型适应不同观测角度下的任务。
-
Sim2Real迁移数据:
- 生成逻辑:在Isaac Sim仿真环境中生成轨迹,再通过扩散模型增强画面真实感;
- 解决问题:真实数据中危险/复杂场景(如易碎品操作)难以采集的问题,扩展场景覆盖范围。
-
Human Transfer数据:
- 生成逻辑:将人类第一视角操作视频(如EgoDex数据集),通过逆动力学模型转换为机器人可执行的轨迹;
- 解决问题:真实机器人数据量少的问题,复用大规模人类动作数据。
-
视频生成数据:
- 生成逻辑:输入单张物体图+文本指令(如“折叠T恤”),用视频生成模型生成操作视频,再提取动作序列;
- 解决问题:真实数据中“未见过的物体/任务”覆盖不足的问题,实现“零真实数据”的任务迁移。
GigaWorld 通过获取真实世界采集的数据,生成纹理、颜色、光照及材质属性的泛化变体,以此实现 Real2Real 外观迁移。
2.3、数据处理流程:提升数据质量与利用效率
为了让混合数据更适配模型训练,GigaBrain-0做了3项关键处理:
- 深度补全:用MoGe模型(Wang et al., 2025)为无深度的RGB帧生成深度图,统一输入格式;
- 自动子目标标注:通过Qwen-VL2.5模型,基于夹爪状态分割轨迹,并生成标准化子目标描述(如“拿起T恤→对齐领口”);
- 数据去重:每个任务最多保留50条多样化轨迹,避免重复数据降低训练效率。
GigaWorld 能够在不同文本提示下,基于同一初始帧生成多样化的未来轨迹,从而为数据集扩充了新颖的操作序列。
3、核心技术分析
3.1、RGB-D输入建模:强化空间感知能力
传统VLA模型多依赖纯RGB输入,难以精准理解3D空间几何与物体深度关系,精密操作(衣物折叠、物体对齐)性能受限。
GigaBrain-0优化设计如下:
- 输入适配:接收 (B × H × W × 4) 张量(3通道RGB + 1通道深度),先归一化处理,再通过
SigLIP(Zhai et al., 2023)提取视觉特征; - 模型扩展:为SigLIP第一层卷积层添加零初始化
深度通道核,保留预训练RGB特征提取能力,同时学习深度感知表征; - 兼容性优化:训练时随机丢弃深度通道(零填充替代),推理阶段可适配纯RGB输入,提升部署灵活性;
- 训练特性:SigLIP全程全量可训练,自适应微调适配具身场景RGB-D感知,强化3D空间布局与物体状态理解。
3.2、Embodied CoT:模拟人类认知的结构化推理
受LLM思维链(CoT)推理(Wei et al., 2022)启发,模型引入具身思维链,生成中间推理token而非直接输出动作,解决长时任务时序规划与细粒度决策难题:
三类中间推理token及功能
- 操作轨迹(manipulation trajectories):机器人末端执行器路径投影至图像平面,以10个均匀采样关键点表示,通过双向自注意力与视觉上下文交互,实现全局空间推理;
- 子目标语言(subgoal language):自然语言描述中间目标(如“拿起纸巾”“折叠边角”),拆解长时任务为原子步骤,降低时序依赖复杂度;
- 离散动作token(discrete action tokens):为DiT连续动作预测提供离散先验,加速训练收敛(Pertsch et al., 2025)。
生成方式差异
- 操作轨迹:放弃自回归解码,引入10个可学习轨迹token作为VLM辅助输入,通过轻量GRU解码器回归2D像素坐标,兼顾推理效率与空间精度;
- 子目标语言与离散动作token:采用自回归生成,通过标准下一个token预测监督,保证推理步骤时序连贯性。
3.3、知识隔离:避免语义与动作学习的干扰
VLA模型核心矛盾为语义理解(离散)与动作生成(连续)优化目标冲突,前者侧重视觉-语言对齐,后者侧重动作平滑性与物理可行性。GigaBrain-0引入知识隔离(Knowledge Insulation, Driess et al., 2025)机制:
- 核心作用:训练中隔离语义推理(VLM)与动作预测(DiT)的优化过程,避免梯度更新相互干扰,模块各司其职;
- 核心优势:无需手动调整语言与动作预测损失权重,模型自动平衡学习进度,提升训练稳定性与最终性能。
4、训练目标函数与优化逻辑
模型采用联合优化目标,整合Embodied CoT中间推理与连续动作块生成损失,公式如下:
L = E D , τ , ϵ [ − ∑ j = 1 n − 1 M C o T , j l o g p θ ( x j + 1 ∣ x 1 : j ) + ∥ ϵ − a c h u n k − f θ ( a c h u n k τ , ϵ ) ∥ 2 + λ ∥ G R U ( t ^ 1 : 10 ) − t 1 : 10 ∥ 2 ] \mathcal{L}=\mathbb{E}_{\mathcal{D}, \tau, \epsilon}\left[-\sum_{j=1}^{n-1} M_{CoT, j} log p_{\theta}\left(x_{j+1} | x_{1: j}\right)+\left\| \epsilon-a_{chunk }-f_{\theta}\left(a_{chunk }^{\tau, \epsilon}\right)\right\| ^{2}+\lambda\left\| GRU\left(\hat{t}_{1: 10}\right)-t_{1: 10}\right\| ^{2}\right] L=ED,τ,ϵ[−j=1∑n−1MCoT,jlogpθ(xj+1∣x1:j)+∥ϵ−achunk−fθ(achunkτ,ϵ)∥2+λ
GRU(t^1:10)−t1:10
2]
损失项解析
- CoT推理损失:监督子目标语言与离散动作token自回归生成,(M_{CoT, j}) 为掩码标识,仅对CoT推理流token计算损失;
- 动作生成损失:基于流匹配的连续动作块预测损失,(a_{chunk}^{\tau, \epsilon}) 为加高斯噪声的动作块,保障动作平滑性与物理可行性;
- 轨迹回归损失:监督操作轨迹2D关键点预测精度,(\lambda=1) 为平衡权重,保证空间推理准确性。
通过联合损失函数,将“语义理解-中间推理-动作生成”绑定为统一优化目标,使模型同步学习任务目标、规划逻辑与执行动作,实现端到端具身智能。
5、模型效果
当前开源有下面这些权重:
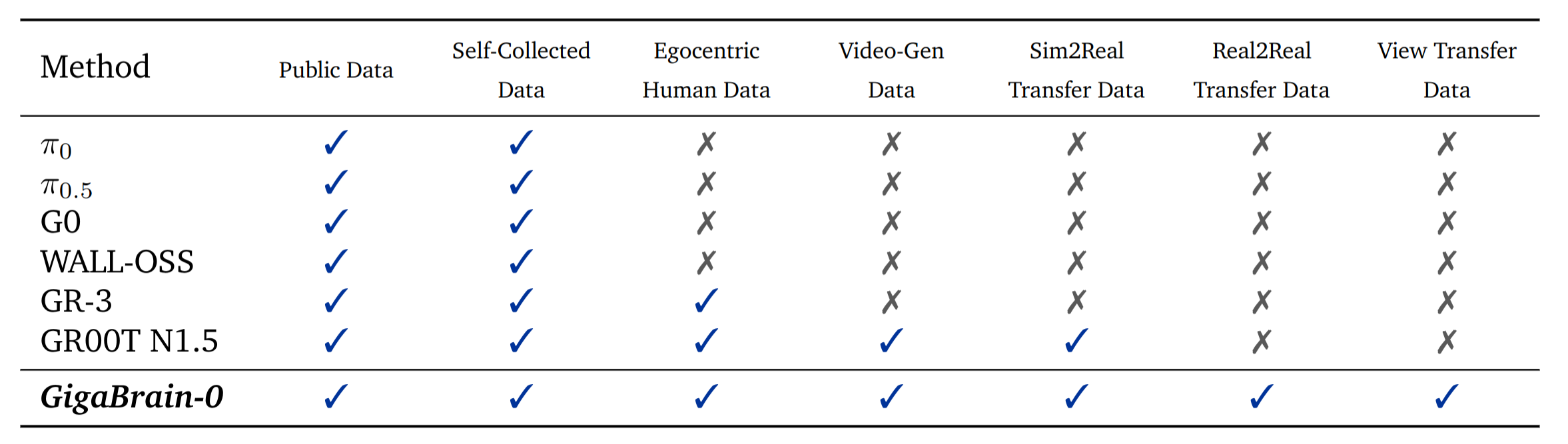
不同VLA模型的训练数据使用情况对比:
GigaBrain-0 利用多样化的数据源,以提升泛化能力并减少对真实世界机器人数据的依赖
下面是不同模型的指标对比: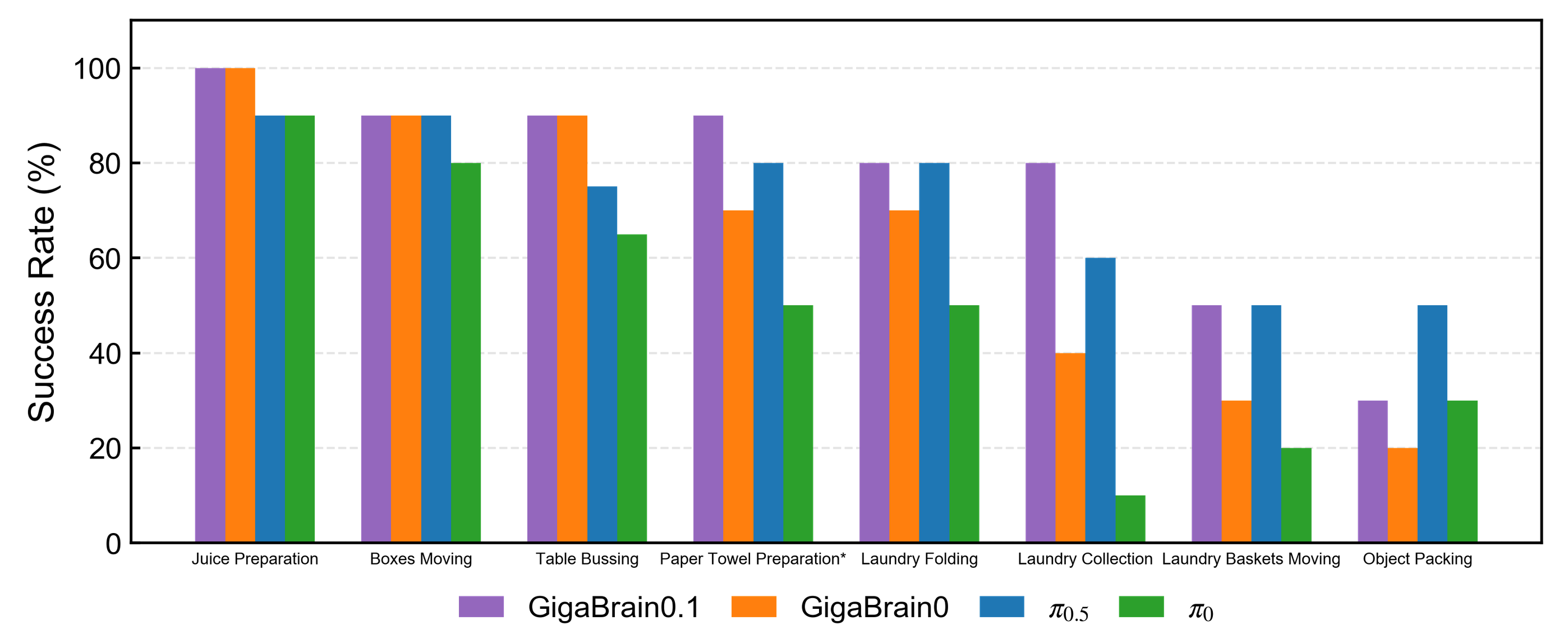
分享完成~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 13
13 0
0- 0



 已为社区贡献58条内容
已为社区贡献58条内容

所有评论(0)