AI世纪对决!Claude Opus 4.6 与 GPT-5.3 Codex 同日狙击,开发者该选谁?Weelinking帮你一键解锁双王炸!
关注公众号:weelinking | 访问官网:weelinking.com一场没有硝烟的战争在凌晨打响,两个顶级AI模型同时亮剑,而胜负关键或许藏在了一个不起眼的中转平台里。2026年2月6日凌晨2点,AI圈熬夜党们再次迎来了血脉贲张的时刻——Anthropic毫无预兆地扔出了 Claude Opus 4.6 这枚深水炸弹。就当所有人还在消化其恐怖的跑分数据时,20分钟后,OpenAI 的 GP
关注公众号:weelinking | 访问官网:weelinking.com
一场没有硝烟的战争在凌晨打响,两个顶级AI模型同时亮剑,而胜负关键或许藏在了一个不起眼的中转平台里。
2026年2月6日凌晨2点,AI圈熬夜党们再次迎来了血脉贲张的时刻——Anthropic毫无预兆地扔出了 Claude Opus 4.6 这枚深水炸弹。
就当所有人还在消化其恐怖的跑分数据时,20分钟后,OpenAI 的 GPT-5.3 Codex 官宣登场,直接上演了一场“中门对狙”的年度大戏。
两大巨头在同一个凌晨亮剑,这不仅是技术的对决,更是生态的较量。而作为开发者和普通用户,我们该如何同时驾驭这两头性能怪兽?答案或许就藏在本文末尾那个神秘的中转平台里。
AI世纪对决!Claude Opus 4.6 与 GPT-5.3 Codex 同日狙击,开发者该选谁?我们帮你一键解锁双王炸!
01 跑分大战,数据背后的真相
每次新模型发布,跑分总是第一战场。Claude Opu 4.6 这次交出的成绩单堪称华丽:
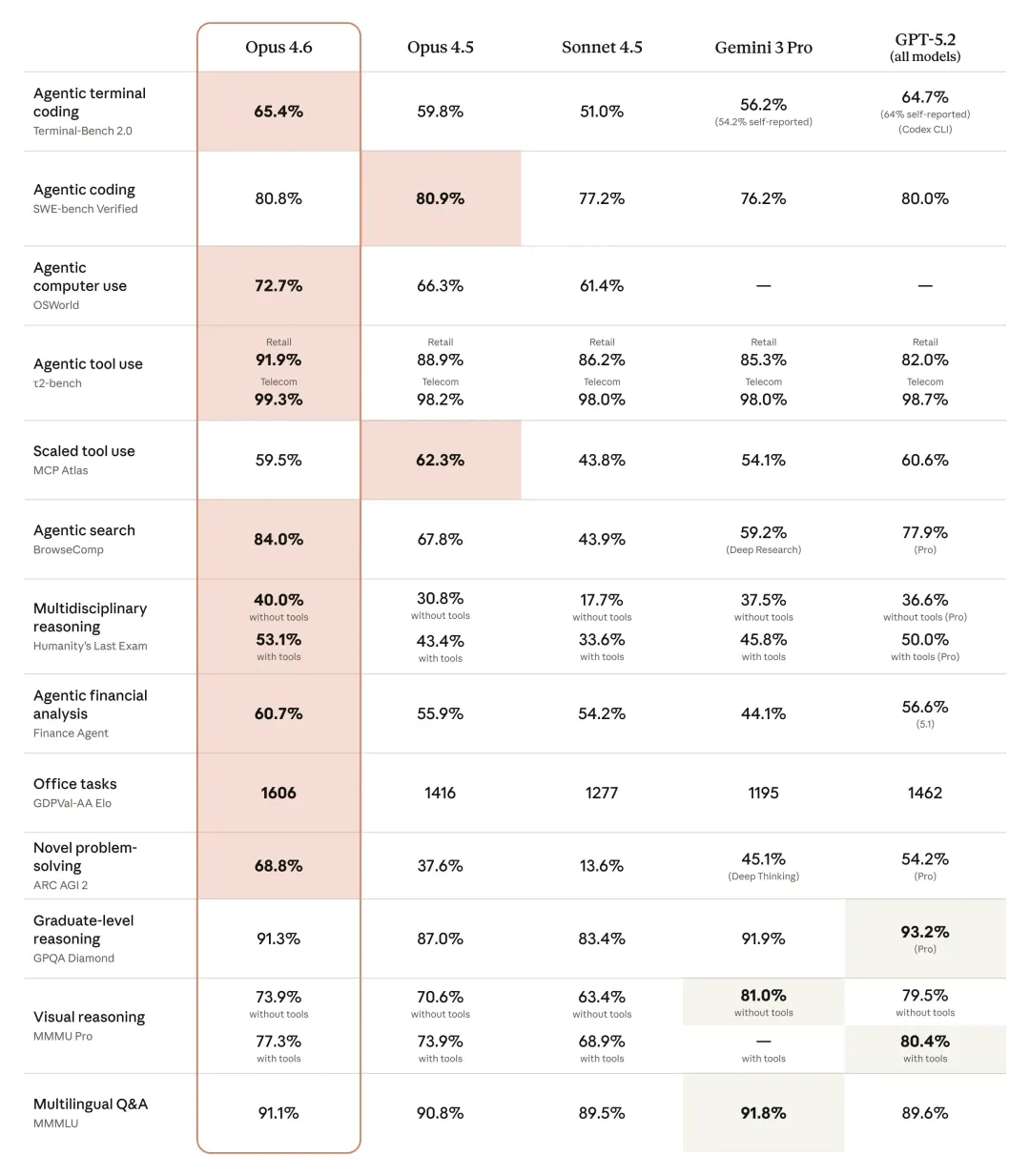
在 Terminal-Bench 2.0 终端编程评测中拿下 65.4%,OSWorld 电脑操作能力达到 72.7%,BrowseComp 网络搜索能力更是飙到 84.0%——比 GPT-5.2 Pro 高出整整6个百分点。
最惊人的是 ARC AGI 2 测试,这项衡量“流体智力”的评估中,Opus 4.6 取得了 68.8% 的分数,几乎摸到了70%的门槛。
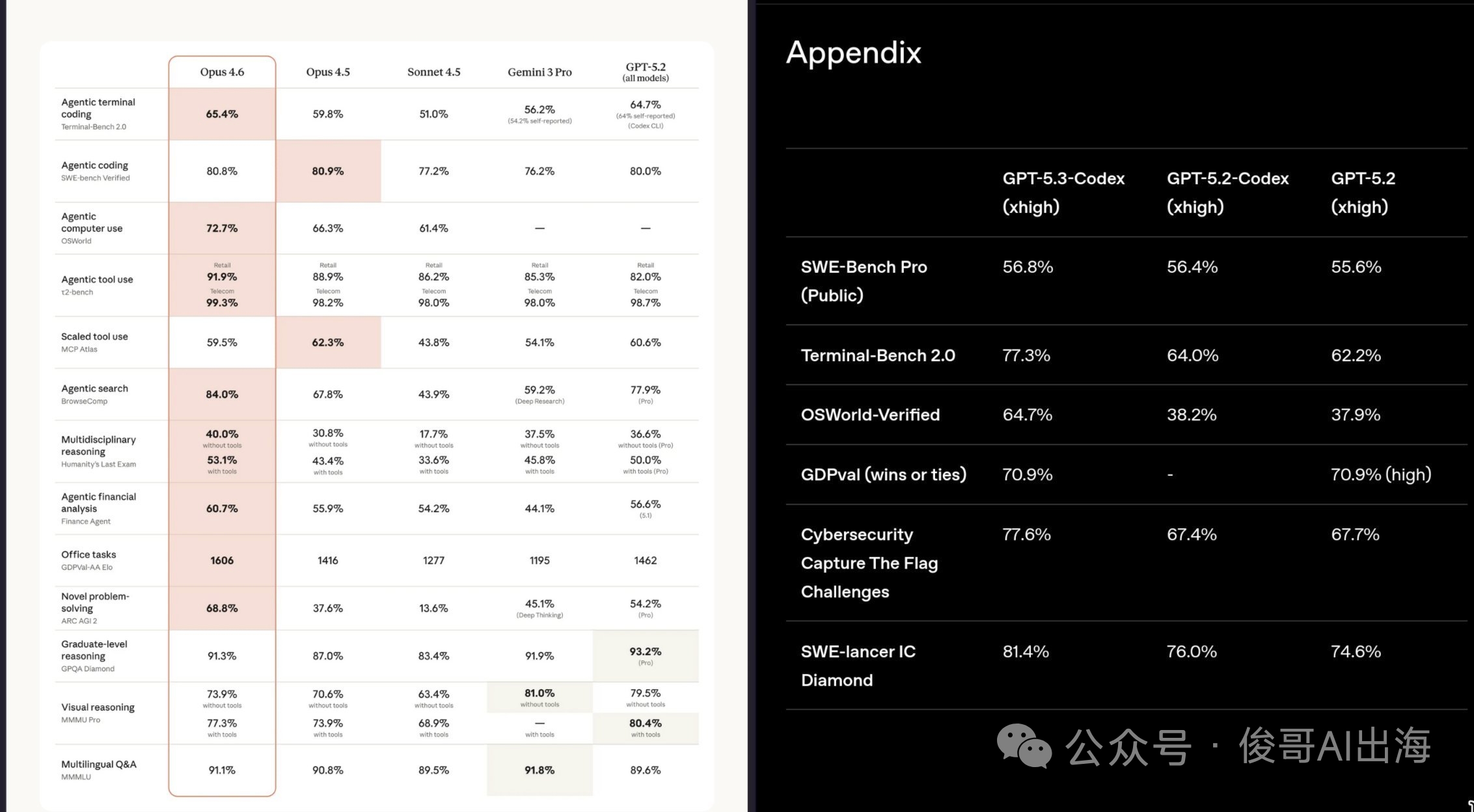
相比之下,GPT-5.3 Codex 的跑分策略显得更为“低调”。在相同的 Terminal-Bench 2.0 评测中,它取得了 77.3% 的成绩,领先 Claude 11.9 个百分点。
关键在于评测标准的不同。OpenAI 选择了更严格的 OSWorld-Verified 标准,在这项修复了300多个问题的重构评测中,GPT-5.3 Codex 仍取得 64.7% 的分数。
“含金量可能更高”,一位不愿具名的AI研究员评价道。
02 功能革新,不止是数字游戏
跑分之外,两家公司在产品功能上的创新同样值得关注。
Claude Opus 4.6 最让人振奋的升级是 100万token上下文窗口 的全面开放。对于需要处理大量代码或文档的开发者来说,这意味着再也不用担心“装不下”的问题。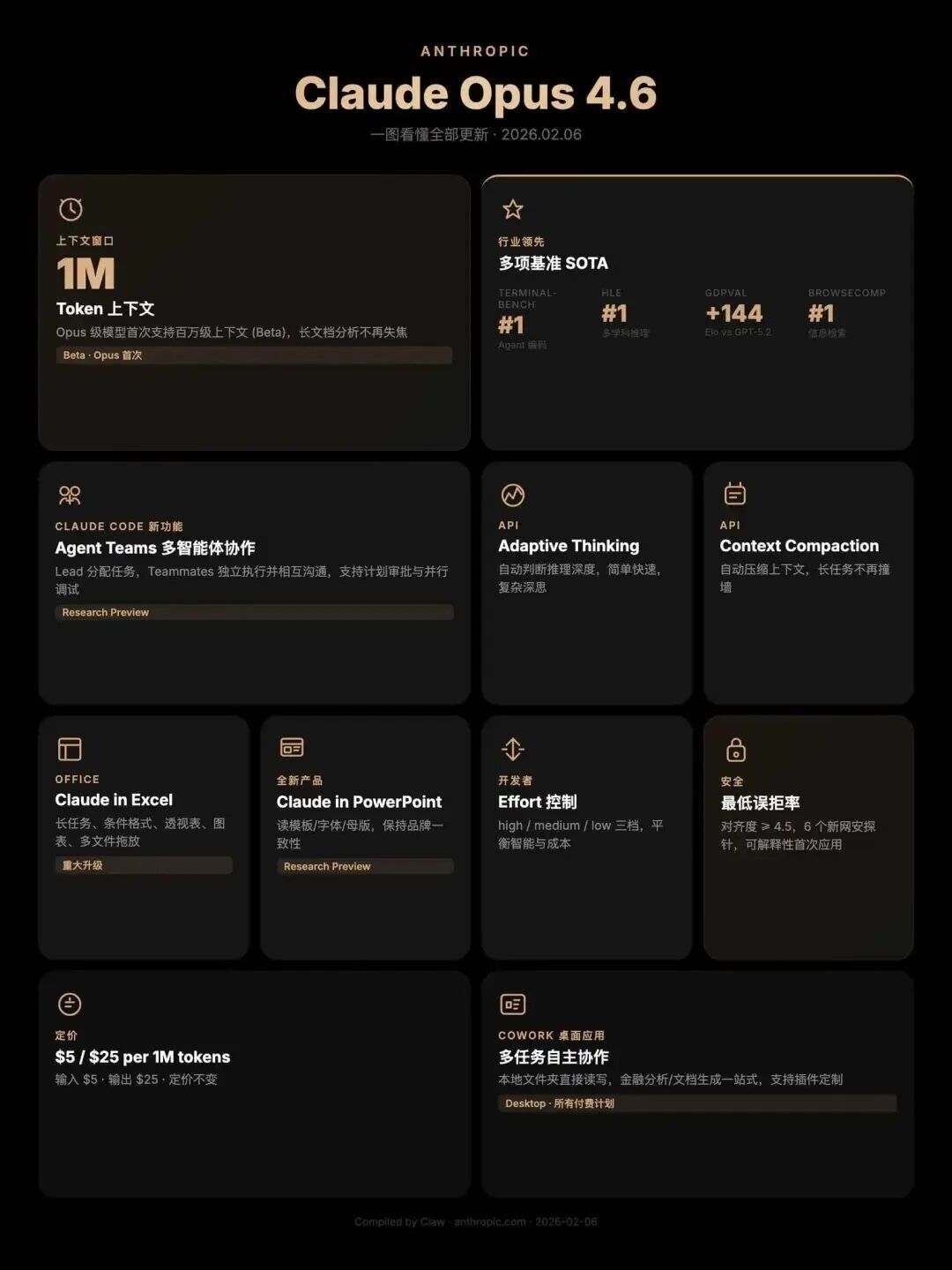
同时引入的 Context Compaction 功能,可以自动压缩旧对话内容,保证长时间任务不中断。Adaptive Thinking 让模型能自主判断思考深度,在速度与质量间找到平衡。
最革命性的更新当属 Agent Teams。不再是单个AI孤军奋战,而是多个AI智能体组成团队,各司其职又相互协作。
想象一下:一个代码审查任务,前端、后端、数据库专家同时开工,发现问题时还能互相沟通质疑——这已经接近人类的团队协作模式。
OpenAI 这边,GPT-5.3 Codex 的突破在于 AI参与自身开发。官方博客中那句“GPT-5.3 Codex是我们第一个在创造自己的过程中发挥重要作用的模型”,透露出了一丝科幻色彩。
实际上,Codex团队使用早期版本模型来调试训练过程、管理部署、诊断测试结果。AI正在帮助创造更强的AI,这种自我进化的可能性令人深思。
03 实战演示,从游戏到生产力
功能说得再强,不如看看实际能做什么。
OpenAI 展示了两个由 GPT-5.3 Codex 完全自主开发的游戏:一个包含多赛车、八地图、道具系统的竞速游戏,和一个拥有完整氧气压力管理系统的潜水探索游戏。
关键是,这些游戏都是 Codex 在几天时间内,通过数百万token的自主迭代完成的。更棒的是,你现在可以在 Codex 工作时随时介入调整,无需停止任务——这对开发者体验是质的提升。
Anthropic 则在生产力场景深耕。全新的 Claude in Excel 插件支持数据透视表编辑、图表修改、条件格式设置等高级功能;Claude in PowerPoint 能根据现有模板创建演示文稿,保持品牌一致性。
两大巨头的分野逐渐清晰:OpenAI 强化代码创造与自主迭代能力,Anthropic 深耕企业级生产工具集成。
04 开发者困境,选择困难症爆发
面对如此强大的两个模型,开发者们陷入了幸福的烦恼。
一位资深程序员在社交媒体上吐槽:“我习惯用 Claude Opus 4.5 做创意原型和主体开发,然后用 GPT-5.2 Codex 进行精准调试和BUG修复。现在两个都升级了,我该换工作流吗?”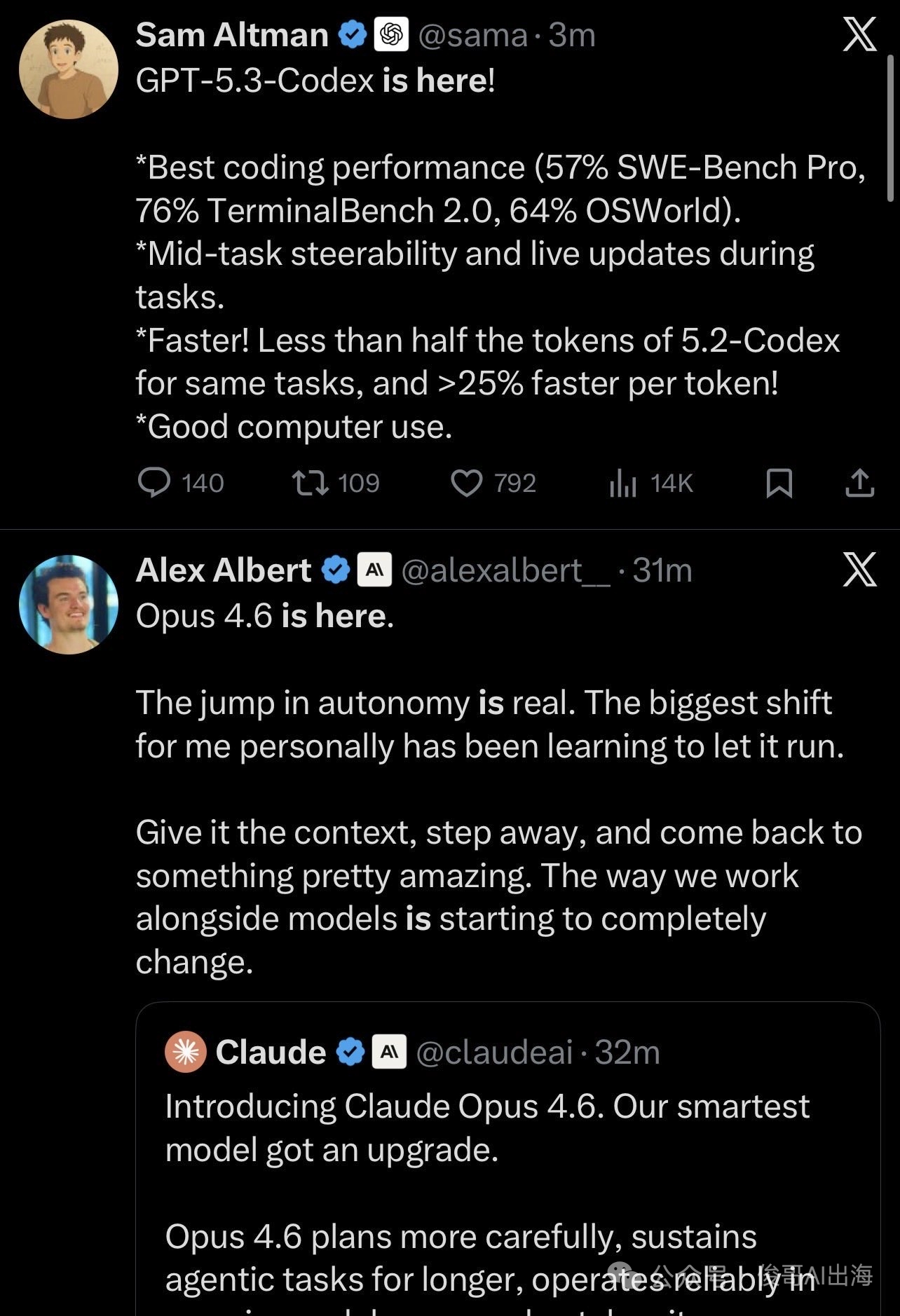
实际测试显示,Claude Opus 4.6 在创意生成、文档处理和复杂逻辑推理上表现卓越,而 GPT-5.3 Codex 在具体编码任务、特别是系统级开发中仍有优势。
但问题来了:普通开发者如何同时获取这两大顶尖模型?官网注册?API申请?环境配置?每一步都是门槛。
更不用说网络访问的稳定性问题、账户被封的风险,以及同时管理多个API密钥的繁琐。当你想对比两个模型对同一问题的解决方案时,切换平台的时间成本高得令人抓狂。
05 一键解锁,Weelinking 的中转智慧
这就是为什么我们需要 Weelinking AI 中转平台。
在大多数开发者还在为访问问题头疼时,Weelinking 已经提供了 一站式双模型解决方案。无需复杂注册,不用处理API限额,更不必担心网络波动。
通过 Weelinking,你可以:
- 实时对比:同时向 Claude Opus 4.6 和 GPT-5.3 Codex 提问,横向比较输出结果
- 智能路由:根据任务类型自动选择最优模型,创意工作走Claude,编码调试走Codex

- 成本优化:统一计费,智能分配token使用,避免单一模型过度消耗
- 稳定访问:专业线路保障,告别“连接失败”的红色提示
“这就像同时拥有了两名顶级工程师,”一位早期用户反馈道,“一个擅长架构设计,一个专注代码实现,而我是他们的项目经理。”
平台还内置了 提示词库 和 工作流模板,将资深开发者的最佳实践固化下来。无论是全栈项目开发、算法优化,还是产品文档撰写,都能找到对应的启动模板。
06 未来已来,只是尚未均匀分布
AI的发展速度已经超出了大多数人的想象。当 Claude Opus 4.6 在 ARC AGI 2 测试中接近70%的分数,当 GPT-5.3 Codex 开始参与自身开发,我们正站在一个技术奇点的前夜。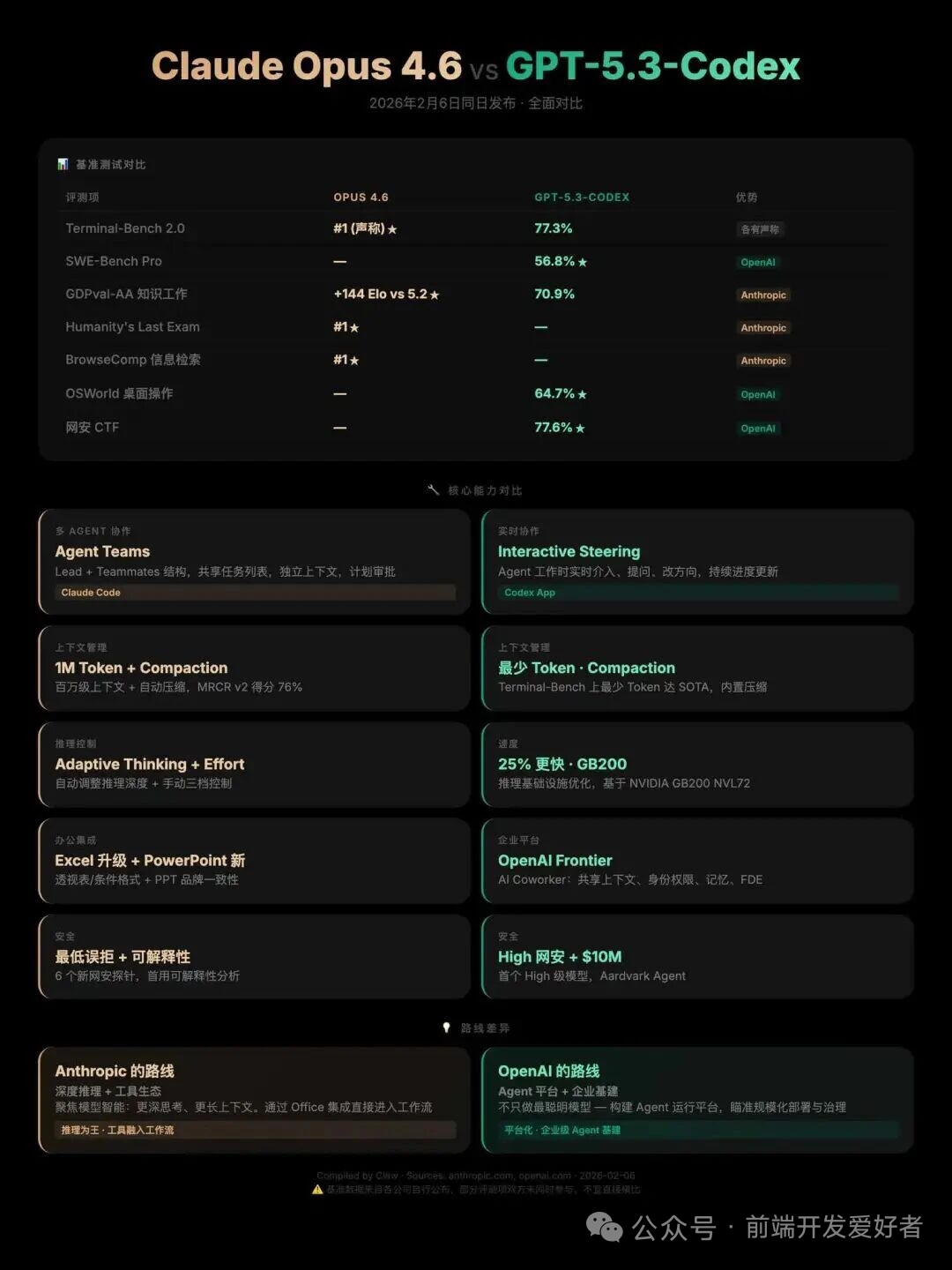
传统软件行业正在经历前所未有的范式转变。代码不再是逐行编写,而是通过自然语言描述生成;调试不再是手工排查,而是AI辅助定位;甚至软件架构也不再完全由人类设计。
在这场变革中,工具的选择决定了效率的边界。执着于单一模型就像只使用一种编程语言——在某些场景下高效,在其他场景下束手束脚。
Weelinking 的价值在于 降低顶级AI的获取门槛。它不生产模型,但让模型变得触手可及;不改变技术本质,但改变技术的使用方式。
凌晨5点,数字世界的另一场对决刚刚开始。Gemini 的下一步棋还未落下,但 Claude 与 GPT 的这轮交锋已经重新划定了势力范围。
未来不会等待那些犹豫不决的人。当顶级AI的能力变得如此接近,选择不再是非此即彼,而是如何让它们协同工作——而这,正是聪明工具的价值所在。
点击体验 Weelinking开启你的新搭子,立即开启你的双AI引擎工作流。在这场AI春晚中,最好的座位不是观众席,而是驾驶舱。
参考资料:
-
国内接入技术支持:Weelinking开发者平台
-
图片来源于网络

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)