豆瓣电影数据采集分析推荐系统| Python Vue LSTM 双协同过滤 大模型 人工智能 毕业设计源码
本文介绍了一个基于Python技术的豆瓣电影数据分析与推荐系统。该系统采用Vue+Flask前后端架构,整合了Scrapy爬虫、LSTM情感分析、双协同过滤推荐算法和Echarts可视化等技术。主要功能包括:电影数据采集与展示、多维数据分析(年份/类型/国家)、影评情感预测、个性化推荐以及丰富的可视化呈现(词云、热力图等)。系统通过爬虫获取豆瓣电影数据,利用LSTM分析影评情感,结合协同过滤算法实
·
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2026年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
1、项目介绍
技术栈
Python、Vue、Flask、LSTM 算法、Echarts、Scrapy、MySQL、双协同过滤推荐算法
功能模块
- 主页
- 电影数据展示
- 电影数据分析
- 电影数据统计
- 电影词云图
- 电影年份类型评分分析
- 电影国家分析
- 情感预测
- 信息设置
- 用户登录
- 用户注册
- 数据采集页面
项目介绍
本项目是基于 Python 生态开发的豆瓣电影数据采集分析推荐系统,针对电影市场信息过载、推荐不精准、影评价值未充分利用的痛点,以 Vue 为前端、Flask 为后端,整合 Scrapy 爬虫、LSTM 情感分析、双协同过滤推荐与 Echarts 可视化技术,构建“数据采集 - 情感挖掘 - 精准推荐 - 直观展示”的完整体系。系统通过爬虫抓取并存储豆瓣电影相关数据,利用 LSTM 算法解析影评情感倾向,结合双协同过滤算法实现个性化推荐,再通过多类型可视化图表呈现数据,既帮助用户高效找到契合偏好的电影,也为行业提供有价值的数据分析参考,具备较强的技术深度与实用价值。
2、项目界面
(1)主页
左侧导航栏包含主页、电影库、数据分析、数据统计、词云分析等多个功能模块,可实现多维度的电影数据挖掘与分析。主页面展示评分最高的电影列表,每部影片附带基础信息,还可点击进入详情与影评分析页面,整体用于电影数据的可视化展示与深度分析。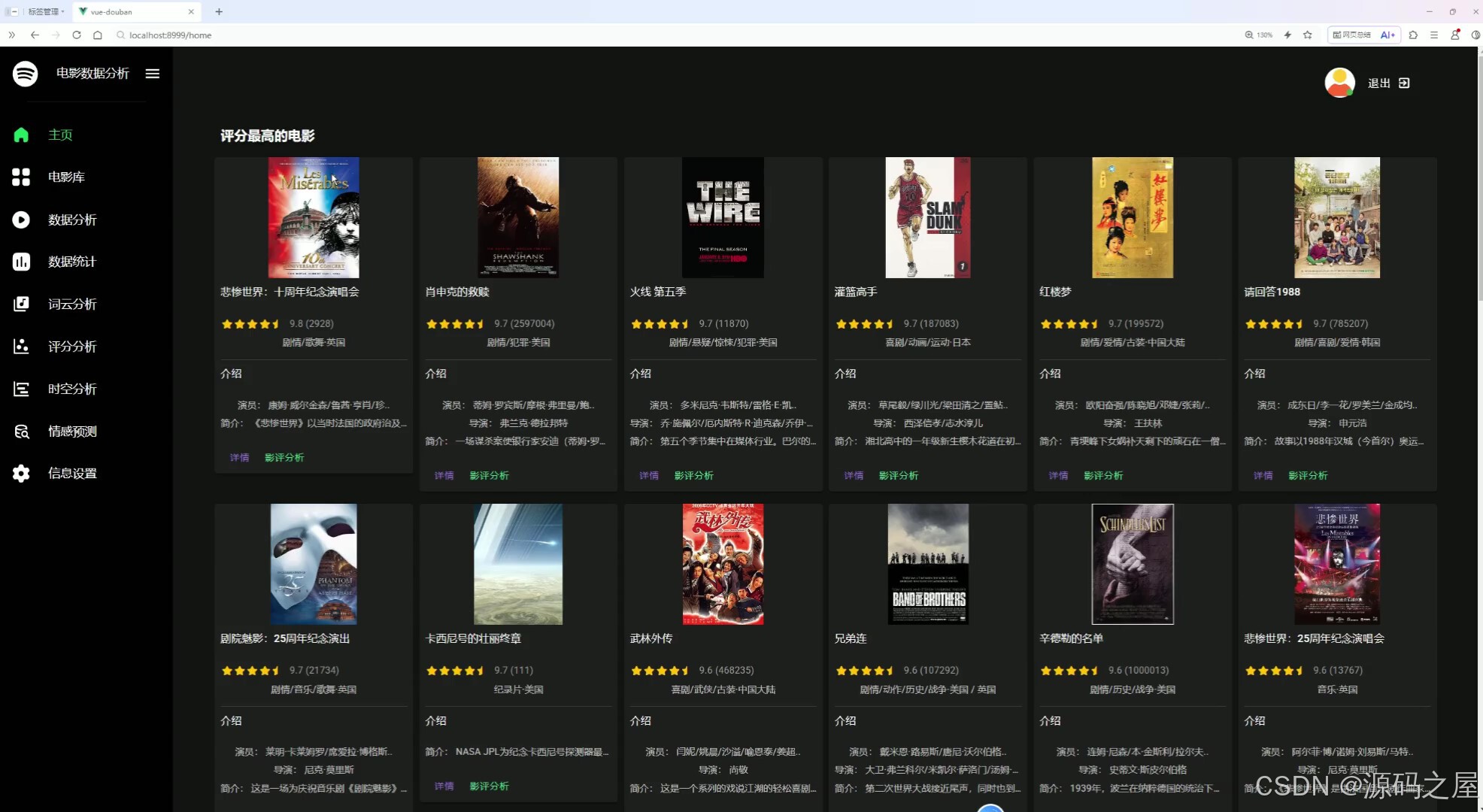
(2)电影数据展示
左侧导航栏支持切换主页、数据分析、数据统计等功能模块。电影库支持关键词搜索,也可按影片类型、国家 / 地区进行筛选。电影库页面展示影片卡片,包含基础信息,点击可进入详情与影评分析页,整体用于影片的检索、筛选与信息查看。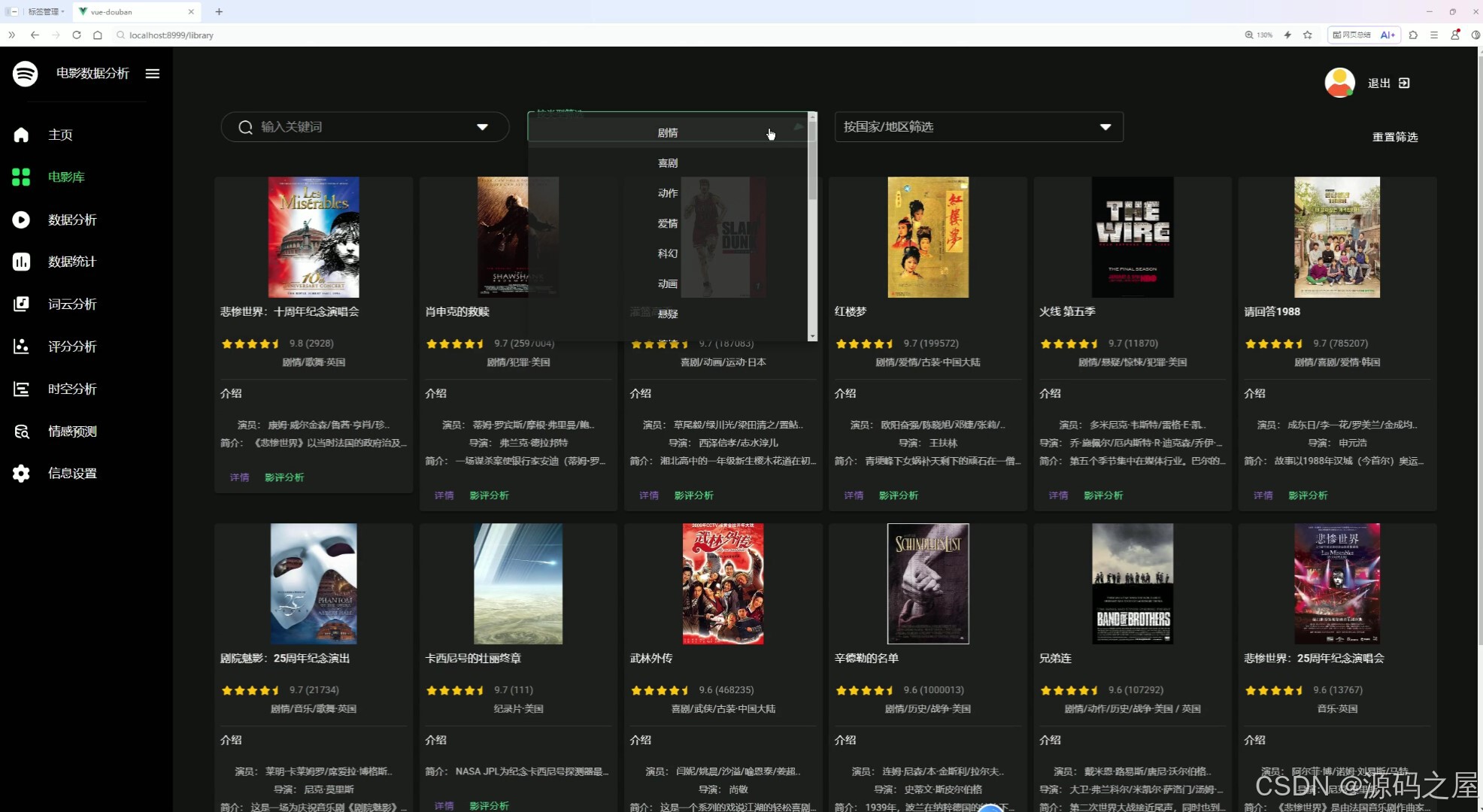
(3)电影数据分析
左侧导航栏可切换至主页、电影库等其他功能模块。本页面通过折线图、面积图等可视化图表,呈现电影上映统计、优质电影发展趋势及各类型电影的上映情况,帮助用户直观把握电影市场的动态与类型分布。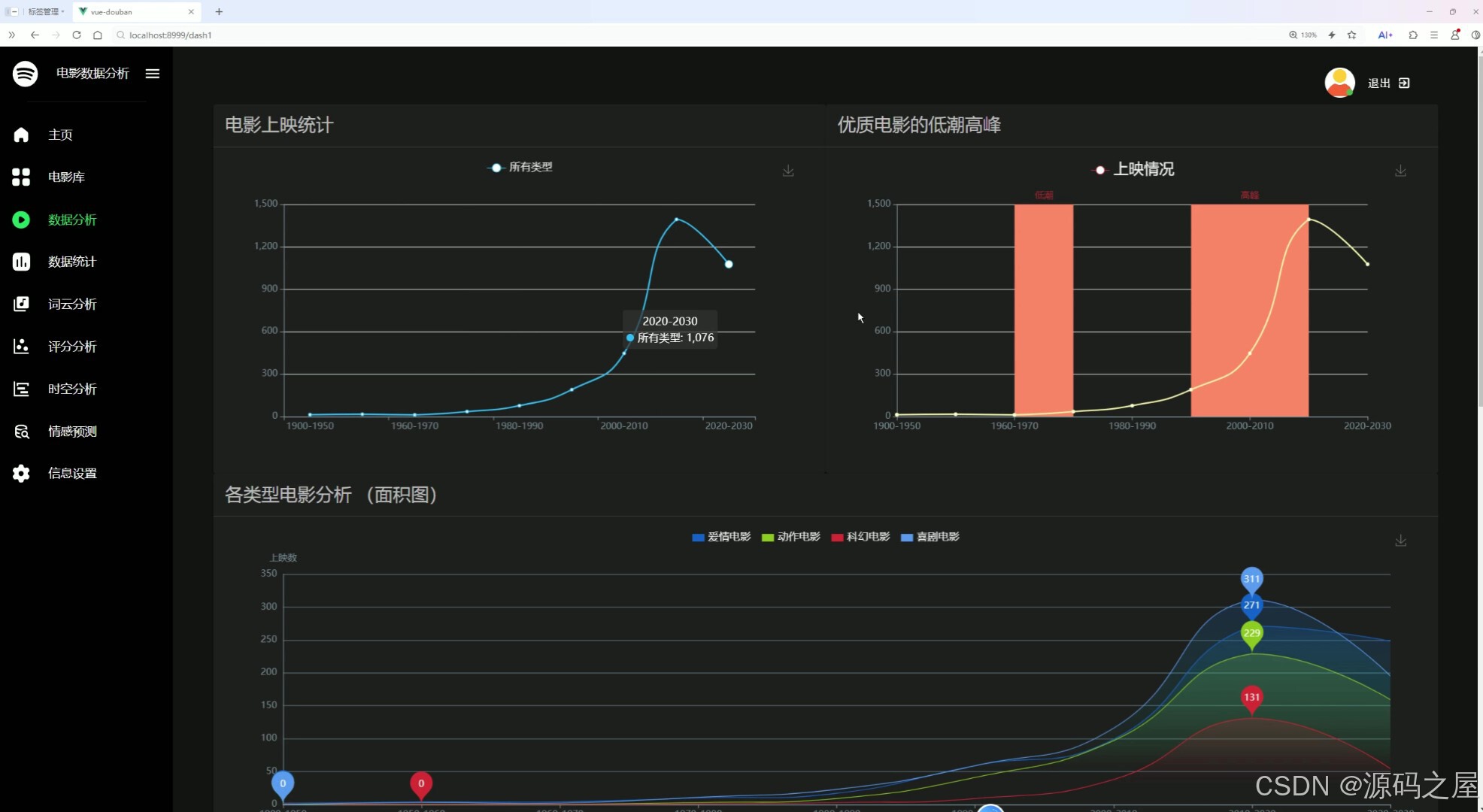
(4)电影数据统计
左侧导航栏可切换到主页、电影库等其他功能模块。本页面通过柱状图、雷达图、饼图等多种可视化图表,展示不同国家 / 地区、不同电影类型的发片量排行与构成,帮助用户直观了解全球电影市场的区域与类型分布特征。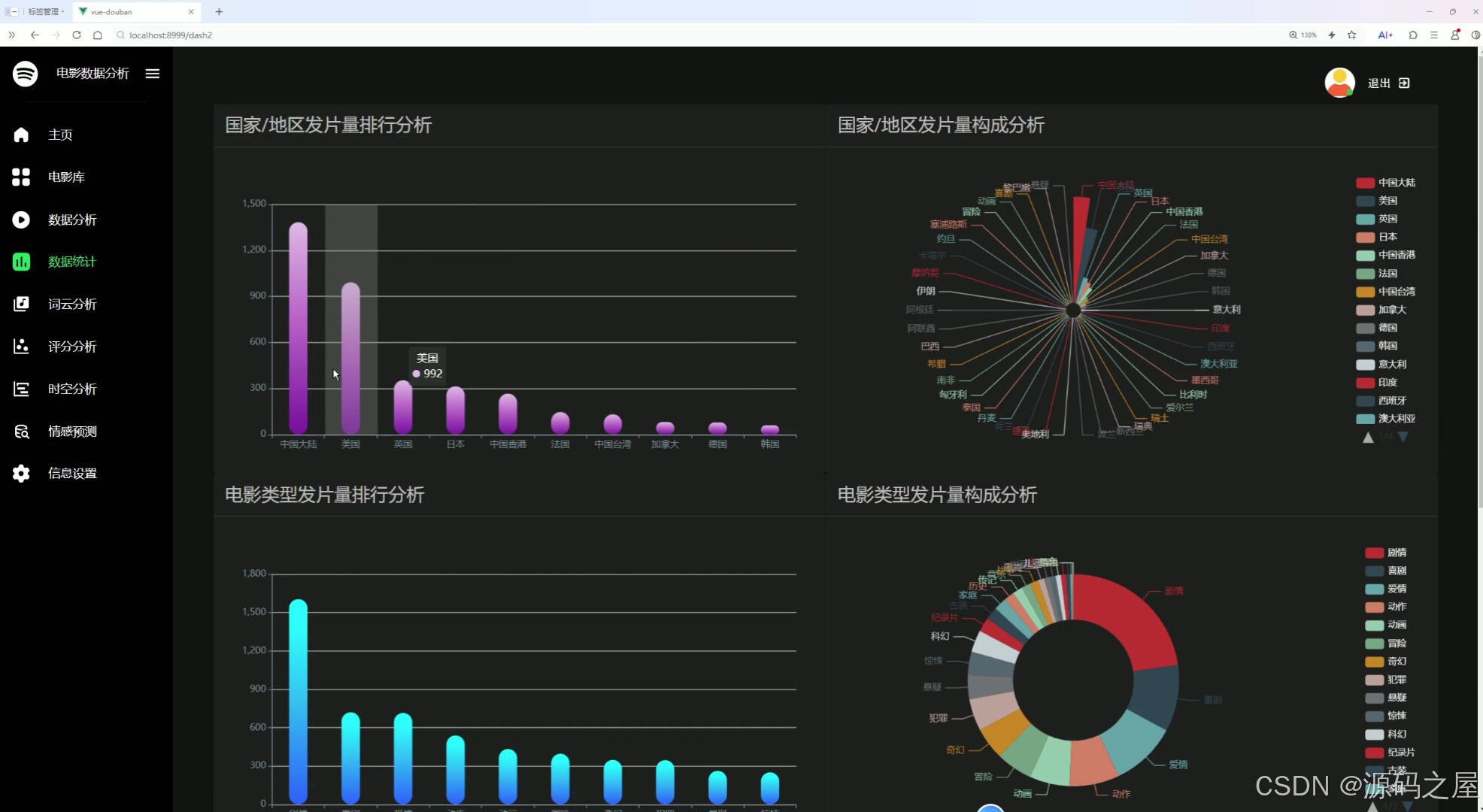
(5)电影词云图
左侧导航栏可切换至主页、电影库等其他功能模块。本页面通过生成电影相关的词云图,将高频关键词以可视化方式呈现,直观反映电影内容中的热门主题与核心元素,帮助用户快速把握电影文本信息的重点。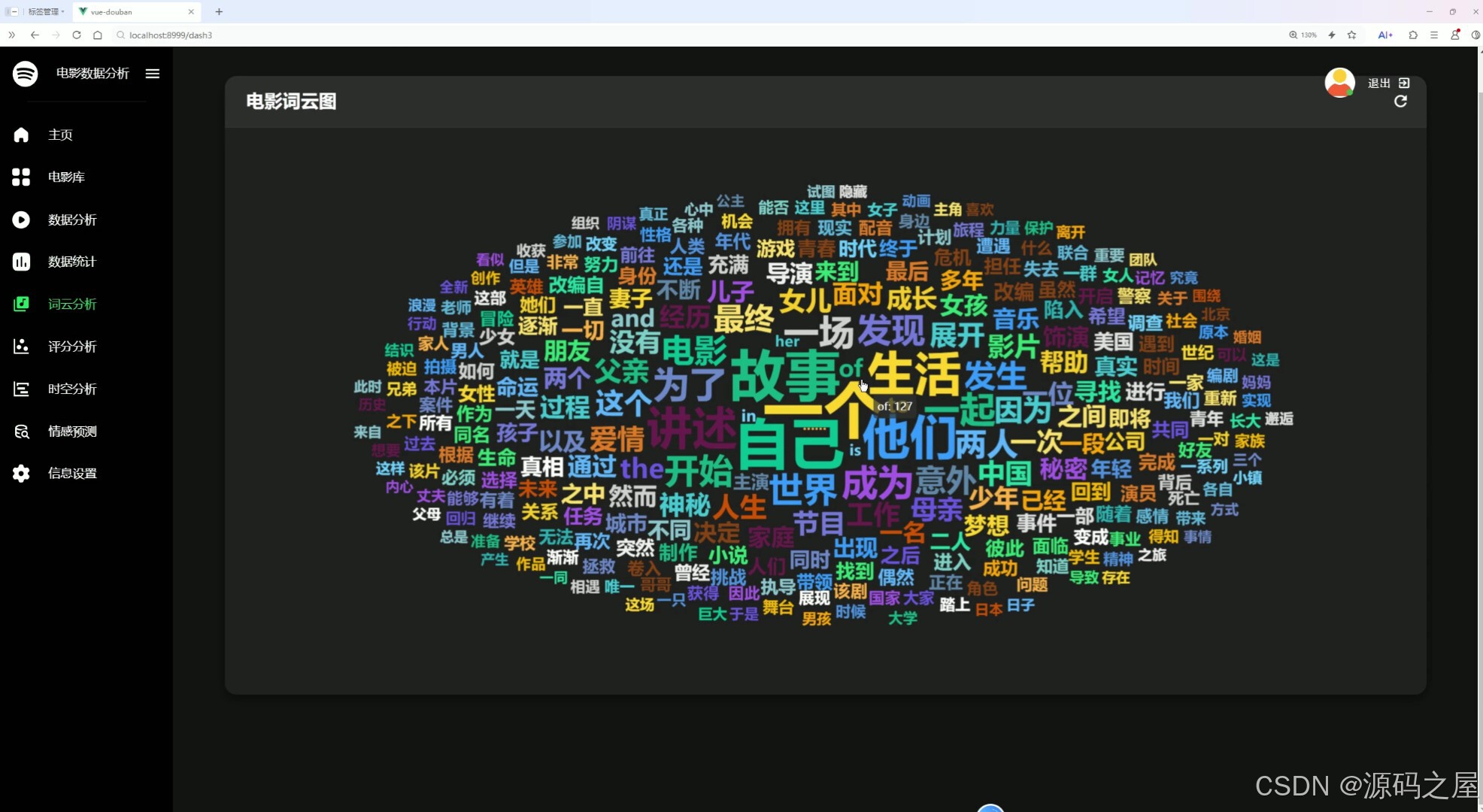
(6)电影年份类型评分分析
左侧导航栏可切换到主页、电影库等其他功能模块。本页面通过散点图形式,从年份、类型、评分三个维度展示电影数据,不同颜色代表不同类型,能直观呈现各类电影的评分随时间的变化趋势,助力用户分析评分与年份、类型的关联。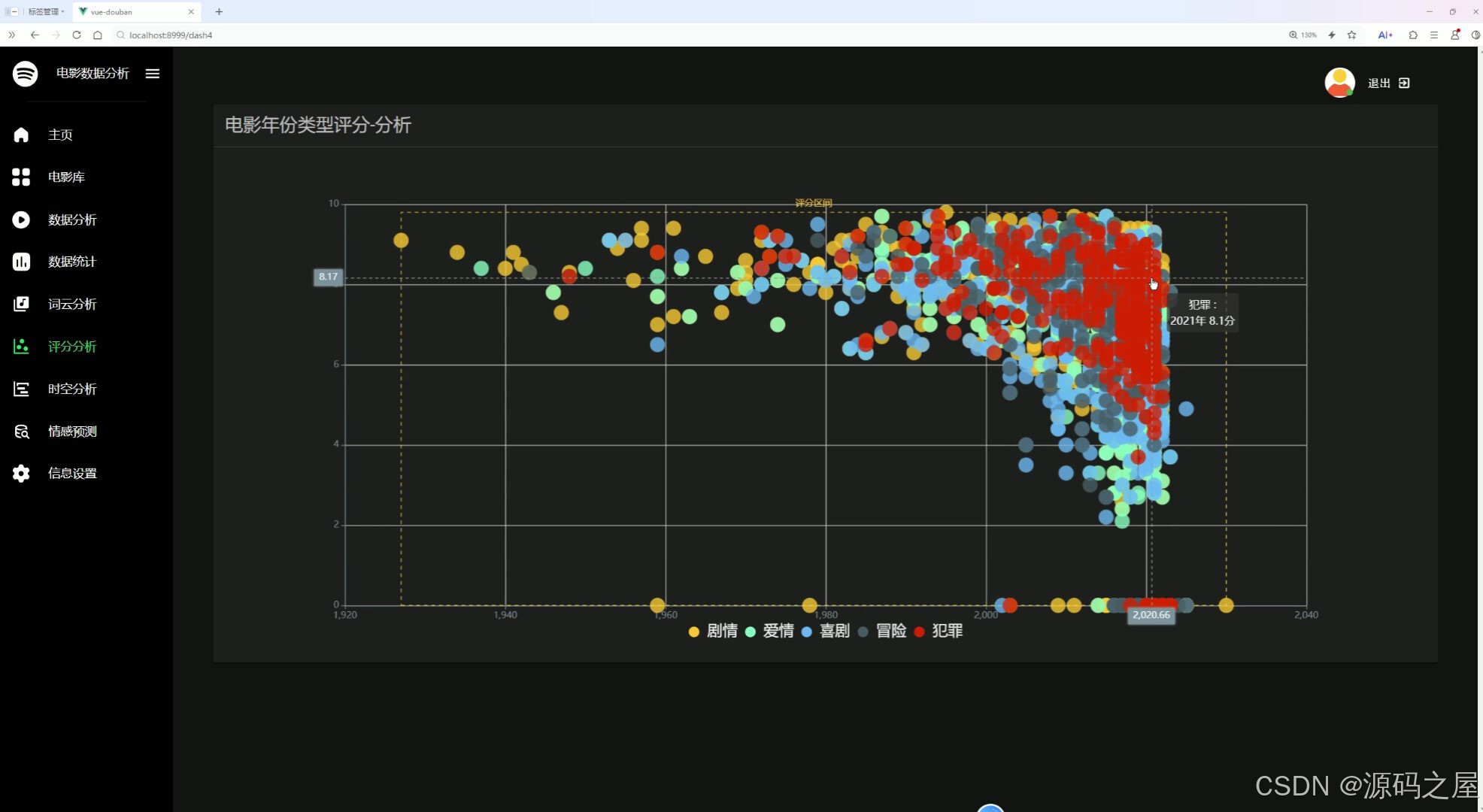
(7)电影国家分析
左侧导航栏可切换到主页、电影库等其他功能模块。本页面通过世界地图热力图展示不同国家的电影产出分布,搭配时间轴分析功能,能直观呈现电影产出的地域特征与时间演变趋势,帮助用户从时空维度把握全球电影市场格局。
(8)情感预测
左侧导航栏可切换到主页、电影库等其他功能模块。本页面支持输入电影评论,通过算法实时分析评论的情感倾向,并给出对应概率,帮助用户快速判断评论的正负向,可用于批量影评的情感趋势挖掘。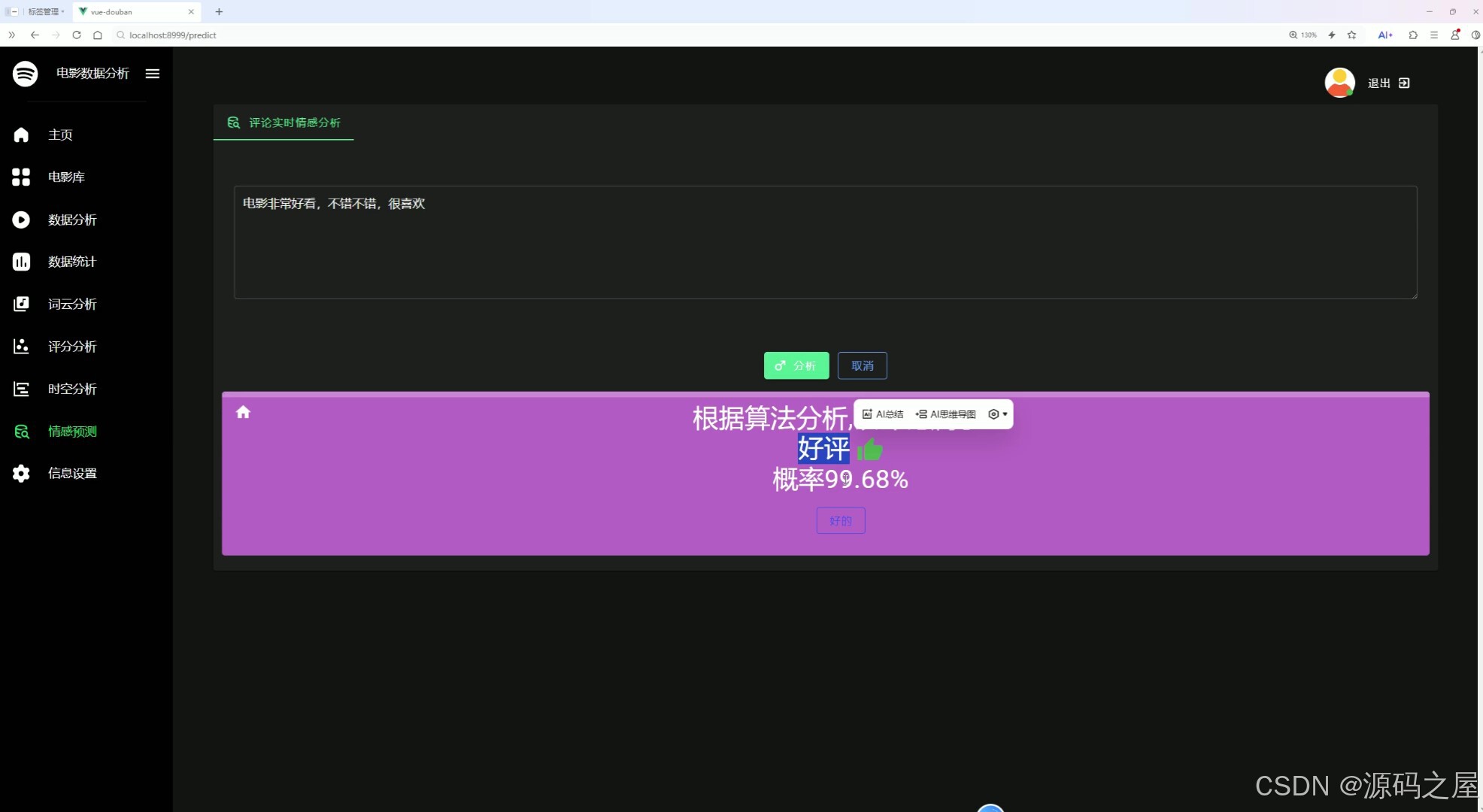
(9)信息设置
左侧导航栏可切换至主页、电影库等其他功能模块。本页面支持管理个人账户信息,包括上传头像、修改姓名、昵称、联系方式等资料,还可设置个人签名与住址,完成信息编辑后可保存修改或取消操作,是系统的个人信息管理入口。
(10)用户登录
页面分为左右两部分,左侧提供创建账户的入口,右侧为用户登录区域,支持输入账号密码、勾选 “记住我”,并设有 “忘记密码” 的辅助功能,验证通过后即可进入系统使用各类数据分析功能。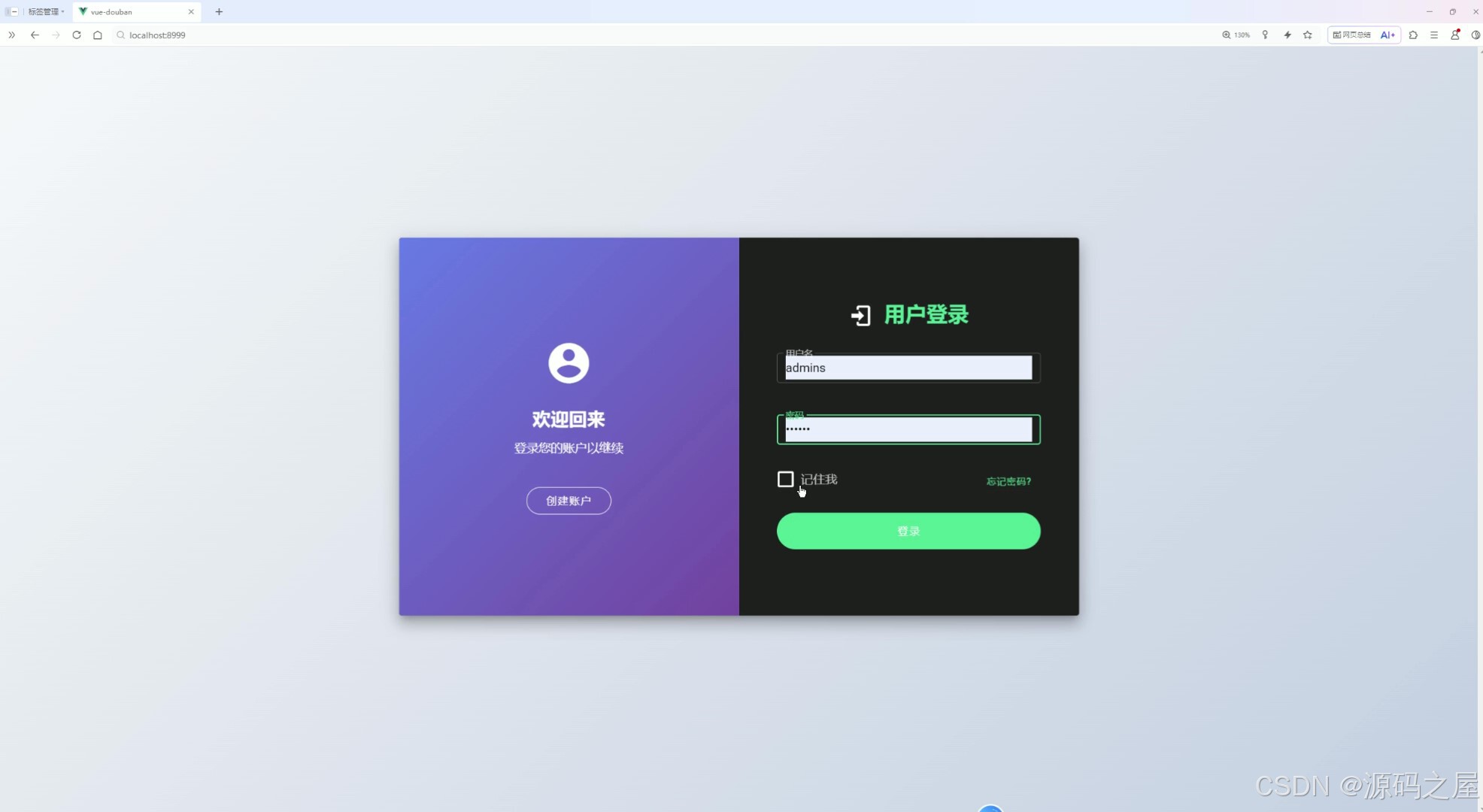
(11)用户注册
页面分为左右两部分,左侧提供返回已有账户登录的入口,右侧为创建账户区域,需填写昵称、用户名、密码等信息,并勾选同意服务条款后,即可完成注册,后续可登录系统使用各类数据分析功能。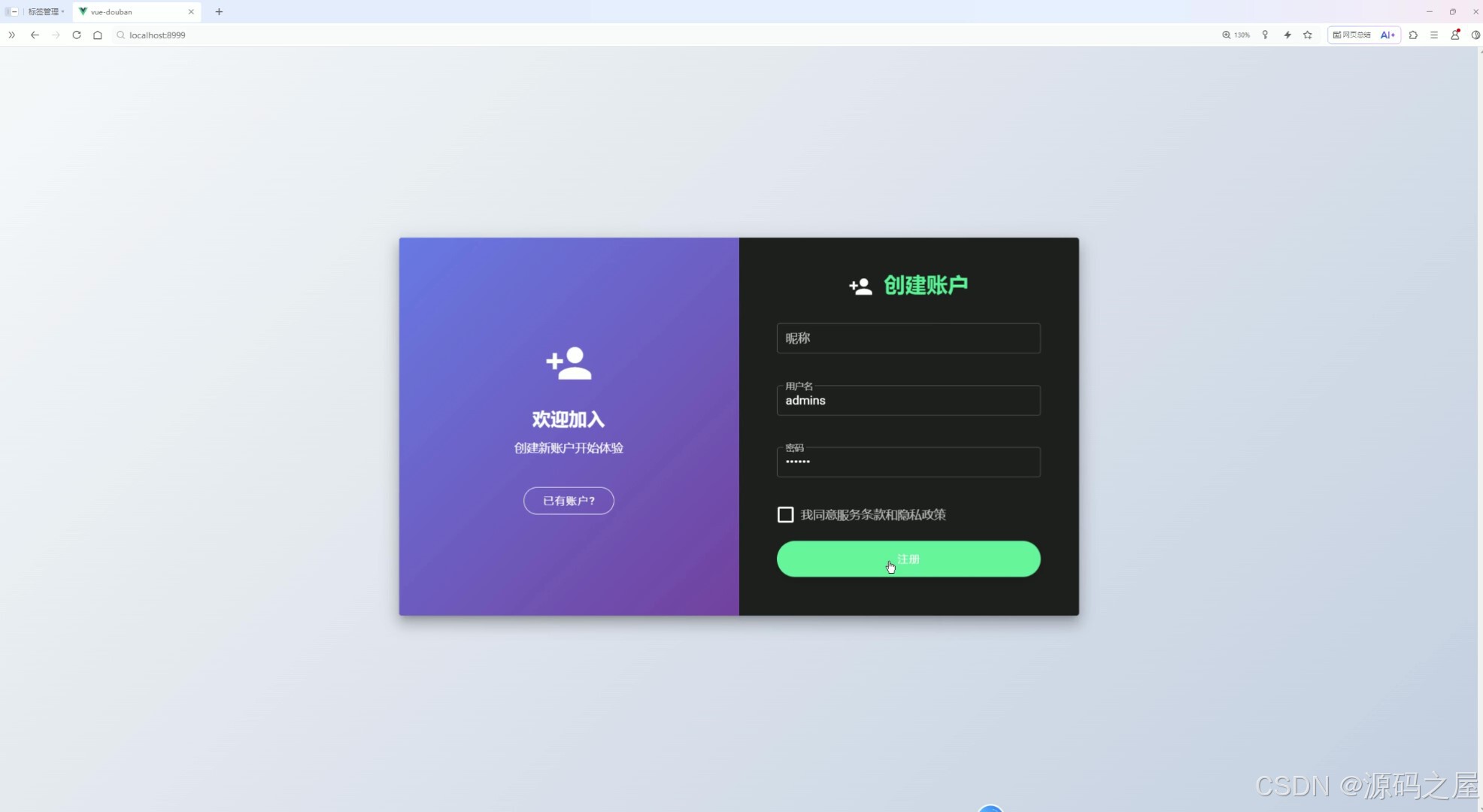
(12)数据采集页面
通过爬虫采集外部平台的电影相关数据,并通过 Flask 后端接口处理情感分析等业务逻辑,为前端功能提供数据支撑。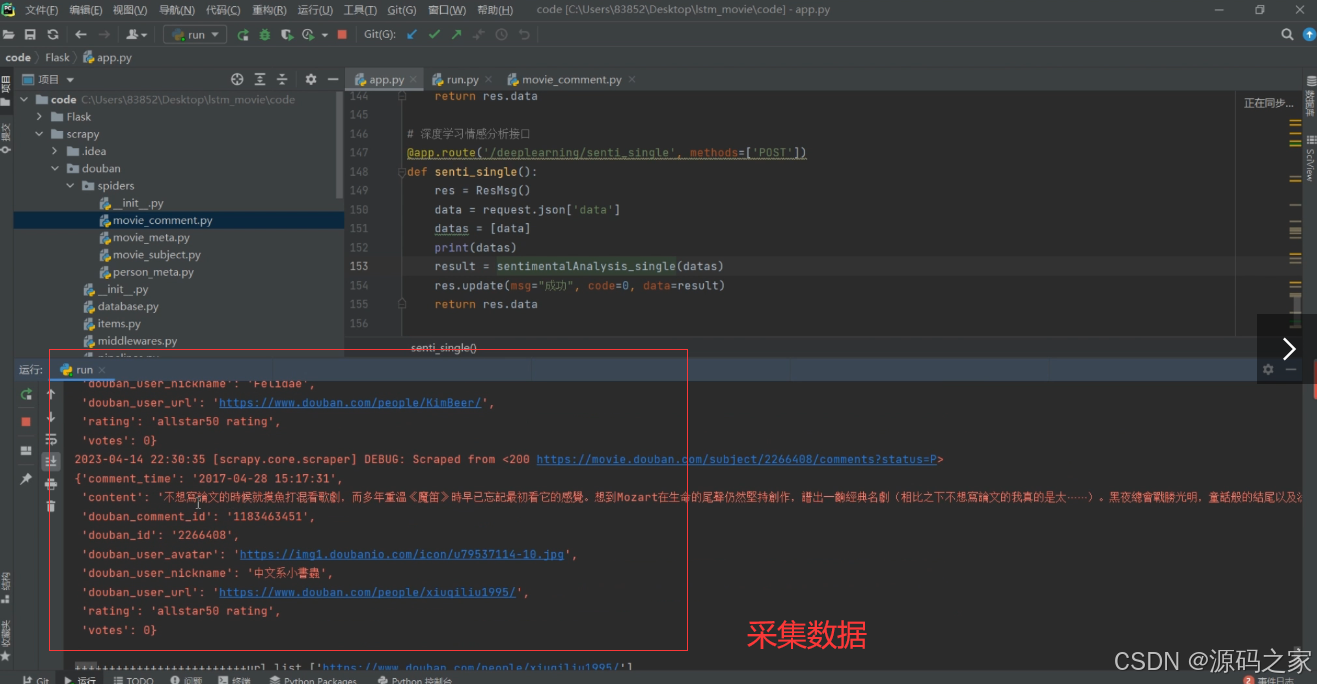
3、项目说明
一、技术栈简要说明
核心技术涵盖 Python 语言、Vue 前端框架、Flask 后端框架,结合 LSTM 深度学习算法实现影评情感分析,通过 Scrapy 爬虫采集豆瓣电影数据,依托 MySQL 数据库存储结构化信息,借助 Echarts 完成数据可视化呈现,采用基于用户与物品的双协同过滤推荐算法,构建全流程技术闭环。
二、功能模块详细介绍
- 主页:左侧设有完整导航栏,包含所有功能模块入口,支持多维度电影数据挖掘与分析操作。主页面聚焦展示评分最高的电影列表,每部影片附带核心基础信息,用户可点击进入详情页及影评分析页面,实现电影数据的可视化展示与深度探索。
- 电影数据展示:支持通过关键词搜索影片,也可按电影类型、国家/地区进行精准筛选。页面以卡片形式呈现影片,清晰展示基础信息,用户点击卡片即可跳转至影片详情与影评分析页面,满足影片检索、筛选与信息查看需求。
- 电影数据分析:通过折线图、面积图等多种可视化图表,直观呈现电影上映统计数据、优质电影发展趋势及各类型电影的上映分布情况,帮助用户快速把握电影市场动态与类型格局。
- 电影数据统计:运用柱状图、雷达图、饼图等丰富图表类型,展示不同国家/地区的发片量排行、各类电影的数量构成等核心数据,助力用户全面了解全球电影市场的区域分布与类型特征。
- 电影词云图:将电影相关的高频关键词以词云可视化形式呈现,直观反映电影内容中的热门主题与核心元素,让用户快速捕捉电影文本信息的重点。
- 电影年份类型评分分析:以散点图为核心展示形式,从年份、类型、评分三个维度联动呈现电影数据,通过不同颜色区分电影类型,清晰呈现各类电影评分随时间的变化趋势,便于分析评分与年份、类型的内在关联。
- 电影国家分析:借助世界地图热力图展示不同国家的电影产出分布,搭配时间轴交互功能,直观呈现电影产出的地域特色与时间演变规律,帮助用户从时空双重维度把握全球电影市场格局。
- 情感预测:支持用户输入电影评论文本,通过 LSTM 算法实时分析评论的情感倾向,输出正面、负面或中性的分类结果及对应概率,可用于批量影评的情感趋势挖掘,为用户决策提供参考。
- 信息设置:提供个人账户信息管理功能,用户可上传或更换头像,修改姓名、昵称、联系方式等基础资料,还能设置个人签名与住址,编辑完成后可选择保存修改或取消操作,是系统的个人信息管理核心入口。
- 用户登录:页面分左右两部分设计,左侧提供创建账户的注册入口,右侧为登录核心区域,支持输入账号密码、勾选“记住我”功能,同时设有“忘记密码”辅助找回通道,验证通过后即可进入系统使用全部数据分析功能。
- 用户注册:页面采用左右分区布局,左侧设置返回已有账户的登录入口,右侧为注册操作区域,用户需填写昵称、用户名、密码等必要信息,勾选同意服务条款后,即可完成注册,后续可登录系统使用各类功能。
- 数据采集页面:通过 Scrapy 爬虫定向采集外部平台的电影相关数据,包括电影基础信息、用户影评等,结合 Flask 后端接口处理情感分析等核心业务逻辑,为前端所有功能模块提供稳定、可靠的数据支撑。
三、项目总结
本项目围绕电影市场信息过载、推荐不精准、影评价值未充分利用的核心痛点,构建了“数据采集 - 情感挖掘 - 精准推荐 - 直观展示”的完整体系。通过 Scrapy 爬虫与 MySQL 数据库保障数据来源的稳定性与结构化,利用 LSTM 算法深度挖掘影评情感价值,结合双协同过滤算法实现个性化推荐,再通过 Echarts 可视化让复杂数据直观易懂。系统功能覆盖从用户注册登录、数据采集处理到分析推荐、信息管理的全流程,既帮助用户高效找到契合情感偏好的电影,也为电影行业提供有价值的数据分析参考,兼具技术深度与实用价值,推动电影推荐从“泛化”向“情感驱动型精准化”转型。
4、核心代码
import json
import os
import random
import time
from flask import Flask, request, jsonify, send_from_directory
from flask_sqlalchemy import SQLAlchemy
from flask_marshmallow import Marshmallow
from sqlalchemy.sql import func
from api.alipayApi import payBp
from api.baiduApi import idocr
from api.movieApi import movieBp
from api.orderApi import orderBp
from base.code import ResponseCode
from base.core import JSONEncoder
from base.response import ResMsg
from api.testApi import bp
from api.userApi import userBp
import logging
from deeplearning.predict_lstm import sentimentalAnalysis_single
from models.movie import getWords
# Flask配置
from utils.smsutil import Sms
app = Flask(__name__)
app.register_blueprint(bp, url_prefix='/test')
# 注册用户相关的方法
app.register_blueprint(userBp, url_prefix='/user')
# 注册电影相关的方法
app.register_blueprint(movieBp, url_prefix='/movie')
app.register_blueprint(payBp, url_prefix='/alipay')
app.register_blueprint(orderBp, url_prefix='/order') # 订单接口
# 数据库配置信息
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql+pymysql://root:123456@localhost/flask_douban_comment'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
# 前端返回的JSON用ASCII编码关闭,否则浏览器里面看到的文本会是乱码
app.config['JSON_AS_ASCII'] = False
# Flask必须的配置
app.config['SECRET_KEY'] = 'KJDFLSjfldskj'
UPLOAD_FOLDER="upload"
app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER
basedir = os.path.abspath(os.path.dirname(__file__))
ALLOWED_EXTENSIONS = set(['txt','png','jpg','xls','JPG','PNG','gif','GIF'])
# 日志系统配置
# handler = logging.FileHandler('./error.log', encoding='UTF-8')
# logging_format = logging.Formatter(
# '%(asctime)s - %(levelname)s - %(filename)s - %(funcName)s - %(lineno)s - %(message)s')
# handler.setFormatter(logging_format)
# app.logger.addHandler(handler)
# 返回json格式转换 使用这个的话就不需要每次都写json返回了,简化代码
app.json_encoder = JSONEncoder
# SQLAlchemy 为ORM框架,即用来简化操作数据库的包,具体内容需要学习ORM相关知识
db = SQLAlchemy(app)
# Marshmallow 是用来封装返回SQLAlchemy 的返回结果的,通过这个包可以直接把数据转成JSON,从而返回给前端使用
ma = Marshmallow(app)
# 一个测试的方法,可以测试服务器是否启动了
@app.route('/test')
def test(): # put application's code here
res = ResMsg()
test_dict = dict(name="zhang", age=19)
res.update(data=test_dict, code=0)
# data = dict(code=ResponseCode.SUCCESS,
# msg=ResponseMessage.SUCCESS,
# data=test_dict)
return res.data
# return jsonify(res.data)
# 用来捕捉服务器运行过程中的500-内部错误,并给前端返回信息
@app.errorhandler(500)
def special_exception_handler(error):
app.logger.error(error)
return '请联系管理员', 500
#判断文件后缀
def allowed_file(filename):
return '.' in filename and filename.rsplit('.',1)[1] in ALLOWED_EXTENSIONS
@app.route('/file/upload', methods=['POST'], strict_slashes=False)
def api_upload():
res = ResMsg()
file_dir=os.path.join(basedir, app.config['UPLOAD_FOLDER'])
if not os.path.exists(file_dir):
os.makedirs(file_dir)
f = request.files['myfile']
if f and allowed_file(f.filename):
fname = f.filename
# fname = secure_filename(f.filename)
print(fname)
ext = fname.rsplit('.', 1)[1]
unix_time = int(time.time())
new_filename = str(unix_time)+'.'+ext
f.save(os.path.join(file_dir, new_filename))
res.update(data=new_filename, code=0)
return res.data
@app.route('/file/idocr', methods=['POST'], strict_slashes=False)
def api_id_ocr():
res = ResMsg()
file_dir=os.path.join(basedir, app.config['UPLOAD_FOLDER'])
if not os.path.exists(file_dir):
os.makedirs(file_dir)
f = request.files['myfile']
if f and allowed_file(f.filename):
fname = f.filename
# fname = secure_filename(f.filename) 有中文这个会有问题
# print(fname)
ext = fname.rsplit('.', 1)[1]
unix_time = int(time.time())
new_filename = str(unix_time)+'.'+ext
f.save(os.path.join(file_dir, new_filename))
current_path = os.path.dirname(__file__)
idno, name = idocr(current_path + '/upload/' + new_filename)
res.update(data=dict(idno=idno,pic=new_filename,name=name), code=0)
return res.data
@app.route('/file/download/<filename>/')
def api_download(filename):
# print('下载..' + filename)
return send_from_directory('upload', filename, as_attachment=False)
#阿里云短信接口
@app.route('/sms/sendSms', methods=['POST'])
def sendSms():
res = ResMsg()
phone = request.json['phone']
code = random.randint(100000, 999999)
response = json.loads(Sms().sendCode(phone, code))
if response['Code'] == "OK":
res.update(msg="发送成功", code=0, data=code)
else:
res.update(msg="发送失败", code=-1)
return res.data
# 深度学习情感分析接口
@app.route('/deeplearning/senti_single', methods=['POST'])
def senti_single():
res = ResMsg()
data = request.json['data']
datas = [data]
print(datas)
result = sentimentalAnalysis_single(datas)
res.update(msg="成功", code=0, data=result)
return res.data
if __name__ == '__main__':
app.run(debug=True,host='0.0.0.0',port=8080)
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)