还在死磕Prompt?大模型Agent的真正核心是工程化架构!建议收藏
文章指出大模型Agent的开发重心已从Prompt Engineering转向Flow Engineering(工作流工程)。核心在于构建规划、记忆(RAG)和工具使用的架构体系,而非依赖单一提示词。作者建议利用LangGraph等框架进行任务编排,采用小模型蒸馏控制成本,并关注Multi-Agent协作模式,强调工程化思维与数据质量才是Agent落地的关键。
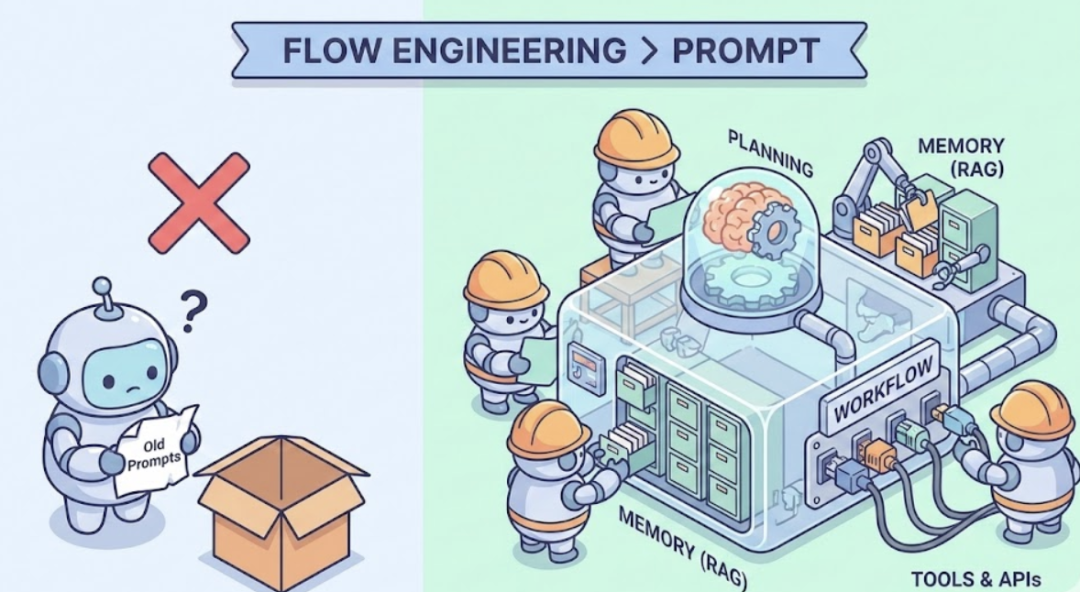
到了现在这个节点,如果你还觉得大模型Agent的核心是Prompt,那你大概率还在做Demo,或者你的业务场景非常边缘。
早在一两年前,大家还在吹捧提示词工程是未来的金饭碗,甚至有人喊出自然语言就是新的编程语言。现在回头看,这话对了一半,但也误导了一大批人。Prompt确实是人机交互的入口,但对于Agent——这种具备自主规划、调用工具、记忆能力的智能体来说,Prompt只是那层皮。
真正的核心是什么?是工程化的架构设计,是工作流的编排,是数据的闭环。
前两天还在跟几个做SaaS的朋友喝茶,他们感慨说,现在的模型太聪明了,聪明到让你觉得以前学的那些提示词技巧都白学了。
早期的Agent开发,大家确实是在炼丹。那时候模型能力弱,不给它念几句咒语它都不知道自己是谁。但现在,情况完全变了。看看现在的头部模型,GPT-5.2系列,无论是Instant版还是Thinking版,或者是Anthropic那边刚出的Claude 4.5 Opus,它们的指令遵循能力已经强到离谱。
最核心的变化是,这些模型内置了极强的推理机制。以前我们需要在Prompt里写一堆Let’s think step by step来诱导模型思考,现在根本不需要。像GPT-5.2 Thinking或者阿里的Qwen3-Max-Thinking,你直接开启思考模式,模型自己就会在内部进行多步推理,把逻辑盘得明明白白。你不需要再用那些花哨的COT诱导,直接说人话,它基本都能懂。
现在的Agent开发,更像是在做传统的后端架构,只不过中间塞进去了一个概率性的黑盒。
我们现在推崇的一个概念,叫做Flow Engineering,也就是工作流工程。这个词在前两年吴恩达大力推崇后,已经成了行业标准。特别是他在2025年10月发布的那个Agentic AI课程,我强烈建议没看过的赶紧去补课。哪怕你是资深开发,看完也会有新启发。他把重心从单一的Prompt优化转移到了多步流程的设计上,明确提出了Reflection、Tool Use、Planning、Multi-Agent Collaboration这四大设计模式。
简单说,就是别指望一个超级Prompt能解决所有问题。
你要做的是把一个复杂任务拆解。比如你要做一个自动化写研报的Agent。 小白的做法是:写一个几千字的Prompt,告诉模型你是金融专家,你要去搜索,要分析,要写摘要,最后给我输出文章。 结果呢?模型大概率会幻觉,或者中间某一步偷懒,搜出来的东西驴唇不对马嘴。
老手的做法是: 第一步,写一个搜索Agent,专门负责根据关键词去Google Search API或者Bing API拿数据,清洗数据。 第二步,写一个阅读Agent,专门把搜到的长文本做摘要,提取核心指标。 第三步,写一个写作Agent,根据摘要生成大纲。 第四步,写一个审核Agent,检查数据对不对,逻辑顺不顺。
这中间的串联,靠的不是Prompt,而是代码逻辑,是LangGraph这样的编排框架。
说到这,必须得提一嘴LangGraph。前几年大家还吐槽LangChain臃肿,但自从LangChain团队把重心转到LangGraph,并且在2025年发布了1.0正式版之后,它简直就是做复杂Agent的神器。它引入了图的概念来管理状态,让循环和分支变得可控多了。以前那种一条道走到黑的Chain模式早就不够用了,如果你还在死磕那些老旧的Chain,建议赶紧去看看LangGraph的文档,那才是做复杂Agent的正路子。
既然Prompt退居二线,那谁上位了?我觉得是这三样东西的有机结合:规划、记忆和工具使用。
1. 规划能力:让模型学会停下来想一想
最开始我们用ReAct模式,让模型想一步做一步。这在简单场景下够用,但任务一复杂,模型就容易钻牛角尖。
现在的挑战在于,怎么让Agent具备全局观。
比如我们要帮用户订一张复杂的联程机票。模型需要先查航班,再查签证政策,再查酒店。如果查到一半发现签证来不及,它得知道回滚,重新规划航班时间,而不是在那傻傻地继续查酒店。
这需要我们在Prompt之外,通过代码强行插入思考-评估-决策的循环。现在学术界和工业界都在搞Tree of Thoughts或者Plan-and-Solve策略。
这里有个很有意思的开源项目叫MetaGPT,国内团队做的,这两年在GitHub上一直很火,2025年还推出了MGX等新产品。他们的核心理念就是把人类的标准作业程序SOP通过代码硬编码进Agent的交互流程里。他们把一个软件开发任务拆成了产品经理、架构师、工程师几个角色,每个角色只关注自己的那部分。这就是通过架构设计来弥补模型规划能力的不足。大家可以去GitHub上搜一下MetaGPT,它的源码非常值得读,尤其是它怎么定义Role和Action的那部分,是教科书级别的Agent设计。
2. 记忆机制:别指望Context Window能解决一切
很多人有个误区,觉得现在模型支持几百万的上下文,我就把所有资料扔进去不就完了吗?
大错特错。
首先是贵。Token都是钱啊,你每次对话都带几本书进去,老板的钱包受不了。 其次是Lost in the Middle现象。虽说现在的GPT-5.2和Claude 4.5这方面优化了不少,但塞得越多,它的注意力越分散,幻觉风险依然存在。
所以,Agent的核心竞争力之一,是怎么构建长期记忆。
这就没法绕开RAG。但现在的RAG已经不是简单的切片、存向量数据库、检索这么简单了。 现在的RAG要做混合检索,要做重排序,甚至要做知识图谱。
在这一块,LlamaIndex依然是当之无愧的老大。相比LangChain的大而全,LlamaIndex在数据层面的处理要细腻很多。特别是它最近推出的LlamaAgents,专门用来部署文档驱动的Agent,还有LlamaSheets这些工具,极大地强化了Agent的检索和记忆能力。如果你的业务重依赖知识库,LlamaIndex是首选。
3. 工具使用:Agent的手脚
模型本身只是个大脑,它要干活必须得有手脚。这就是Function Calling。
到了2026年,头部模型的工具调用能力已经非常鲁棒了。GPT-5.2和Claude 4.5在处理复杂的JSON结构、参数修正上几乎不出错。
现在的核心挑战不在于怎么调用,而在于业务逻辑的闭环。
比如你给Agent配了100个API工具。用户问个天气,Agent得从这100个里挑出那个查天气的API。如果工具描述写得不清楚,模型很容易选错。或者模型填参数填错了,API报错了,Agent能不能自己看懂报错信息,然后修正参数重试?
这块非常考验Prompt的精细度和代码的鲁棒性。我们在生产环境里,甚至会专门写一个模型层,用来校验和修正Agent生成的JSON参数,防止因为少个括号或者字段类型不对导致整个任务挂掉。
说完了核心,咱们来聊聊那些让开发者半夜薅头发的挑战。这才是大家最关心的,也是劝退很多人的原因。
1. 延迟是最大的敌人
做Demo的时候,你等个10秒钟觉得没啥,模型在思考嘛,挺酷的。 放到线上业务里,用户问个问题,转圈转了30秒,用户早跑了。
Agent的运作机制决定了它快不起来。 思考一次 -> 调一次工具 -> 等工具返回 -> 再思考 -> 再生成。这是一个串行的过程。如果是一个复杂的ReAct循环,来回倒腾个五六次,那时间就是指数级增长。
现在的解决思路主要有两个: 一个是流式输出。虽然结果没算完,但先把能吐的字吐出来,缓解用户焦虑。 另一个是小模型+大模型。规划路径用大模型,具体执行简单的任务用小模型。
提到小模型,不得不提Meta刚出的Llama 4系列,特别是Scout和Maverick这两个版本,原生多模态,MoE架构,端侧部署效果极好。如果你对数据隐私和延迟敏感,完全可以用Ollama在本地跑个Llama 4,配合Groq这种专用的推理芯片服务,速度能起飞。Groq现在的推理速度能达到每秒几百个Token,简直是做Agent的神器,强烈建议去体验一下。
2. 稳定性与死循环
这是最搞人心态的。有时候模型会陷入逻辑死循环。 比如: Agent:我要查天气。 工具:参数错误,请提供城市。 Agent:我要查天气。 工具:参数错误,请提供城市。 Agent:我要查天气。
它就这样一直转,直到把Token限额耗尽。
在代码里,我们需要设置非常严格的停止条件和兜底策略。比如限制最大循环次数是5次,超过了就强制跳出,并告诉用户我搞不定了,转人工吧。
3. 评估难题:你怎么知道它变强了?
传统的NLP任务,我们有BLEU、ROUGE这些指标,算个分就完事了。 Agent怎么评测?它是一个动态的过程。它这次做对了,下次换个参数可能就做错了。
目前的现状是:缺一套公认的、好用的评测框架。
我们现在的做法通常是构建一个黄金数据集,然后用另一个更强的模型去当裁判,也就是LLM-as-a-Judge。
比如我录制了100个用户的真实查询和正确的操作路径。每次代码更新后,让Agent把这100个题跑一遍,记录成功率。 这里推荐一个工具叫LangSmith,也是LangChain家的。它虽然是收费的,但对于调试Agent真的很有用。它能把Agent运行的每一步Trace都记录下来,你能清晰地看到是在哪一步模型想岔了,还是检索没搜到东西。如果没有这种可视化工具,调试Agent就像在黑夜里抓瞎。
另外,学术界这两年也出了不少新东西,比如AgentBench推出了针对Function Calling的特别版(AgentBench FC),更贴近生产环境了。虽然学术评测和工业界场景有差距,但能给你选模型提供一个参考。
4. 成本控制
这个其实是老板最关心的。Agent是Token吞噬兽。 一个复杂的任务,可能要在后台跑几千个Token的思考过程,最后只给用户输出一句话。这几千个Token都是成本。
如果你的业务不赚钱,单纯靠Agent去烧,很快就会难以为继。 所以现在的趋势是模型蒸馏。先用GPT-5.2 Pro跑通流程,收集大量的高质量数据,然后用这些数据去微调一个更小的模型,比如Llama 4或者Qwen 3。
让小模型学会大模型的思考套路,这样既降低了成本,又提高了速度。国内的阿里的Qwen3系列,特别是那个Qwen3-Max-Thinking,在推理能力和工具使用上对标甚至局部超越了GPT-5.2,但价格却便宜不少,性价比极高。我们在很多国内业务场景里都在用它。
既然单个Agent容易钻牛角尖,那就搞一群。
到了2026年,Multi-Agent已经是绝对的主流了,单打独斗的Agent很难处理现在的复杂需求。
早期的AutoGen虽然理念先进,但那会儿调试起来太痛苦了。好在微软后来把它跟Semantic Kernel搞到了一起,推出了全新的Microsoft Agent Framework。现在的版本支持跨语言、异步事件驱动,解决了早期很多痛点,已经成了企业级多Agent开发的首选。
它的逻辑是:让几个Agent扮演不同的角色,互相聊天,互相纠错。
举个写代码的例子:
User Proxy:我要个贪吃蛇游戏。 Coder:写了一段Python代码。 Critic:运行了一下,报错了,告诉Coder哪里不对。 Coder:收到,我改一下。 Critic:再运行,没报错,但界面太丑。 Designer:我给点CSS建议。
通过这种对话式的协作,往往能搞定单个模型搞不定的复杂任务。
如果你觉得微软那套框架太重,还有一个选择叫CrewAI。这两年它增长非常猛,2025年还办了自己的Signal大会。它是基于LangChain构建的,主打的是基于角色的协作,写起来比AutoGen稍微Pythonic一点,对开发者更友好。如果你想尝试多智能体,可以先从CrewAI入手,它的文档写得挺人话的。
写了这么多,最后来点干货总结。
- 忘掉Prompt Engineering,拥抱Flow Engineering。 不要试图用一句话操控神灵,要用工程师的思维去设计系统。Prompt只是函数的一个参数,而不是函数本身。
- 数据质量大于模型参数。 你的RAG检索得准不准,你的工具描述清不清楚,比你用GPT-5.2还是Claude 4.5更重要。把功夫花在清洗知识库、打磨API文档上。
- 一定要做评估。 哪怕是最土的测试脚本,也要有。不要凭感觉上线。上线后一定要有Trace追踪,监控每一步的Token消耗和耗时。
- 架构先行。 别上来就写代码,先用图把你的Agent流程画出来。是单Agent循环,还是多Agent协作?想清楚了再动手。
这个行业变化太快了,但工程化的思维、对数据的敬畏、对场景的理解,这些东西是不会变的。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 25
25 0
0- 0



 已为社区贡献259条内容
已为社区贡献259条内容

所有评论(0)