一人抵百人:用 Kimi K2.5 Agent 集群挖掘因子,用 Claude Code 实时调试回测,最后用岭回归 (Ridge) 终结过拟合
【硬核实战】一个人如何抵得上一支量化私募团队?本文打破传统工作流,实战演示了“AI 量化指挥官”架构:利用 Kimi K2.5 Agent 集群进行因子逻辑挖掘,引入岭回归 (Ridge Regression) 的 L2 正则化进行数学去伪,最后通过 Claude Code 原生实时调试功能实现工程落地。内含完整架构源码与可视化图表资源。
引言:量化私募的“去组织化”革命
在华尔街和陆家嘴的某些角落,一场静悄悄的重塑正在发生。被改变的不是人,而是**“研究员+交易员+开发”**这个统御量化圈几十年的铁三角组织架构。
过去,我们要挖一个 Alpha 因子,流程是这样的:实习生读论文 -> 研究员写数学公式 -> 程序员翻译成 C++ -> 交易员盯着实盘。这一套下来,两周过去了,黄花菜都凉了。
现在,我一个指令,Kimi K2.5 Agent 集群在 5 分钟内读完 500 篇最新的 Arxiv 论文并提出 10 个候选因子;我喝口咖啡的功夫,岭回归 (Ridge Regression) 算法已经理性地剔除了其中 9 个伪因子;剩下的 1 个,丢给 Claude Code,它在终端里实时调试回测,连 bug 都不用我修。
这不是遥远的未来,这是我已经跑通的**“硅基一人机构”**架构:
- 想法层 (Idea Layer): Kimi K2.5 —— 不知疲倦的挖掘者。
- 裁判层 (Judge Layer): 岭回归 (L2 正则) —— 严谨客观的数学法官。
- 执行层 (Execution Layer): Claude Code —— 光速落地的工程专家。
本文将带拆解这套架构,并附赠这一整套玩法的核心代码。
第一章:组建硅基投委会 (Kimi K2.5 Agent 集群)
别再只用简单的 Prompt 跟 AI 对话了。大模型的真正战力在于 Multi-Agent Collaboration (多智能体协作)。
在我的架构里,我从不指望一个 Agent 能产出完美因子。我设计了一个“硅基投委会”,包含三个角色:
- Proposer (挖掘者): 发散思维,广泛联想。Prompt: *“基于波动率微笑曲线,给我提出 5 个非线性的动量变种因子。”
- Critic (反驳者): 严谨审视,寻找盲点。Prompt: “看看上面提的因子,如果市场处于单边下跌,这些因子会不会从 Alpha 变成 Beta 甚至 Gamma 风险?”
- Summarizer (宏观分析师): 听取双方辩论,拍板决策。
硅基投委会工作流
利用 Kimi K2.5 强大的长上下文和逻辑推理能力,这两打(Proposer 和 Critic)能在一个下午把过去 10 年的行为金融学理论都推演一遍。最后交到你手里的,已经是经历过“虚拟实盘模拟”的高质量因子雏形。
第二章:数学的严谨验证 (岭回归 Ridge 的 L2 判决)
AI 最大的挑战是什么?是幻觉,是过拟合。Kimi 可能会在成千上万个特征里,给你找出一个“只有在周二下雨且美联储没开会”时才赚钱的无效因子。
这时候,绝对不能主观臆断。必须请出数学界的公正法官 —— 岭回归 (Ridge Regression, L2 Regularization)。
相比于普通的线性回归 (OLS),岭回归引入了惩罚项 λ ∣ ∣ w ∣ ∣ 2 \lambda ||w||^2 λ∣∣w∣∣2。它的核心逻辑是:如果你不够强(对预测贡献不够大),我就把你的系数压缩到趋近于零。
岭迹图 (Ridge Trace):去伪存真
我们来看一段代码,它能生成“岭迹图”。这幅图能够有效地识别伪因子。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Ridge
from sklearn.preprocessing import StandardScaler
# --- 模拟:生成共线性数据 (真实因子 + 噪音伪因子) ---
np.random.seed(42)
n_samples, n_features = 100, 10
X = np.random.randn(n_samples, n_features)
# 只有前两个特征是真实的,其他都是噪音或共线性特征
y = 3 * X[:, 0] + 5 * X[:, 1] + 0.5 * np.random.randn(n_samples)
# --- 核心:岭回归路径 ---
alphas = np.logspace(-2, 4, 100)
coefs = []
for a in alphas:
ridge = Ridge(alpha=a)
ridge.fit(X, y)
coefs.append(ridge.coef_)
# --- 可视化 ---
# (完整绘图代码见附件 ridge_judge_visualizer.py)
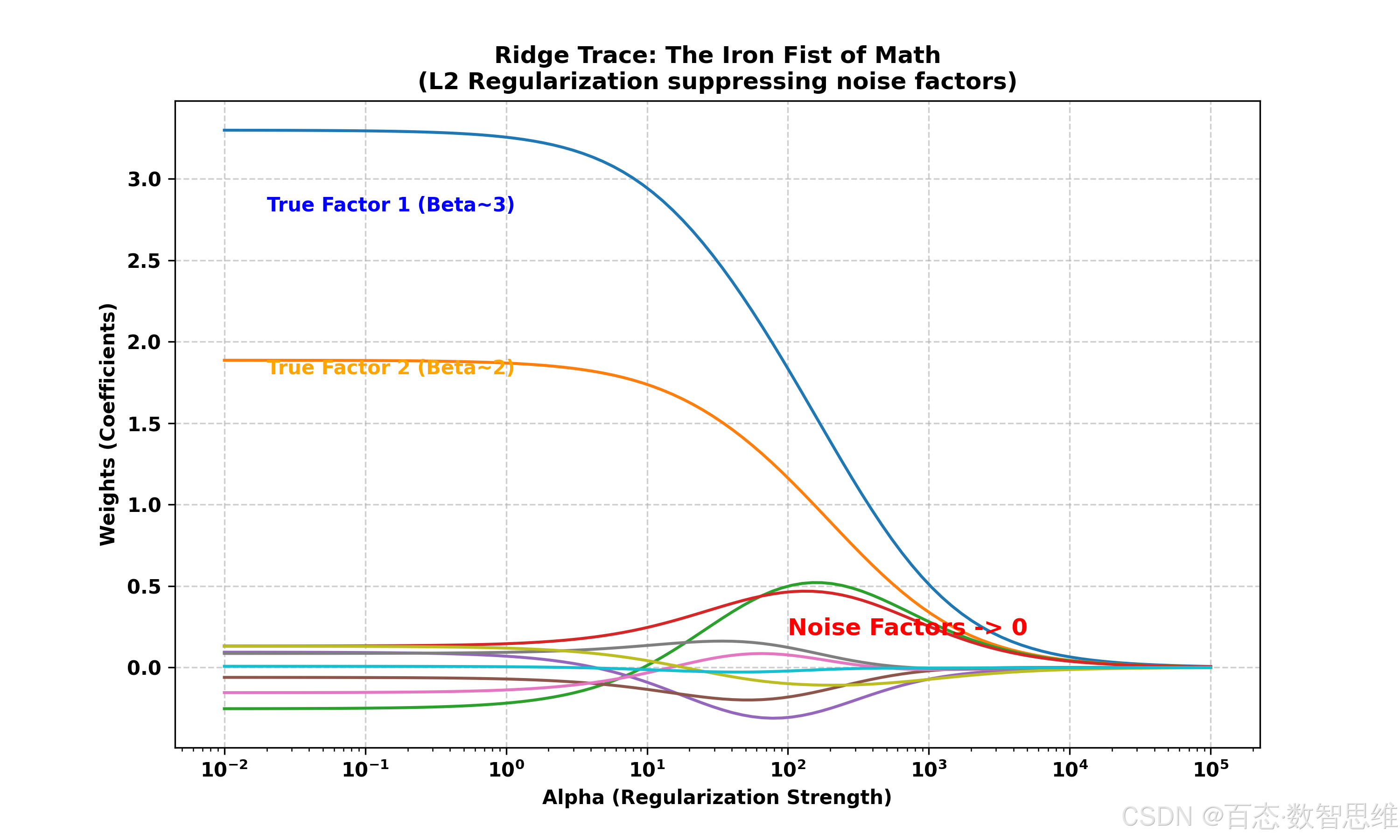
图表解读:随着 α \alpha α (惩罚力度) 增大,那 8 个噪音因子的系数会迅速衰减归零,被有效过滤;而那 2 个真正的 Alpha 因子,系数依然挺立。这就是 L2 的降维筛选。
第三章:极速落地 (Claude Code 的实时调试与全栈生成)
因子验证通过,到了写回测代码环节。这是人类最痛苦的时候:Pandas 的索引对不齐、Look-ahead Bias (未来函数) 像幽灵一样潜伏。
这时候,Claude Code 登场。
Claude Code 不仅仅是写代码,它是一个具备 Shell 权限的 Agent。它能自己运行代码,自己看 Traceback,自己改 Bug。
场景重现:未来函数的狩猎
有一次,我的回测收益率高得离谱。我知道肯定有 Bug,但我不想找。我直接把终端权限交给 Claude Code:
User: “回测夏普比率 8.0,这也太假了。检查一下数据预处理部分是不是用到了未来数据,跑一下自测脚本。”
Claude Code (Terminal):
Running backtest_v1.py ...Warning: DataFrame at index 2024-01-05 accessed data from 2024-01-06.Detected 'shift(-1)' usage in signal generation without lag.Fixing... Replacing shift(-1) with shift(1).Re-running...Done. New Sharpe Ratio: 1.2. (这才是真实的)。
它不只是一段代码生成器,它是活的。它在你的本地环境里,像一个不需要睡觉的高级工程师,24 小时待命。
结语:从“写代码”到“指挥官”
在这个时代,如果还在纠结 pandas.merge 怎么写,已经输了。
未来的 Quant,核心竞争力只有两个:
- 数学直觉:知道用 Ridge 防过拟合,知道用 HMM 建模市场状态。
- 指挥能力:知道怎么把 Kimi 的脑洞、Claude 的执行力和数学工具链串联起来。
现在,去下载附件里的代码,组建你的硅基军团吧。
附件清单
AI_Quant_Agent_Cluster_Pack.zip 包含:
kimi_agent_committee.py- 硅基投委会辩论模拟ridge_judge_visualizer.py- 岭回归 (Ridge Trace) 可视化工具claude_debug_simulation.py- Claude Code 自动调试逻辑演示

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 19
19 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)