从Vibe Coding到Spec Coding:AI编程的演进之路
文章摘要:本文探讨了AI编程的两种方法——Vibe Coding和Spec Coding。Vibe Coding通过自然语言描述让AI生成代码,适合小功能开发但存在幻觉、无状态等问题。Spec Coding则强调结构化需求定义,通过详细规格说明提升AI生成代码的质量,更适合复杂项目。作者推荐使用OpenSpec工具实现Spec Coding,并分享了大模型使用经验。最后提供了经济实惠的GPT5-c
前言
在我刚开始接触AI编程时,公司为我们提供了Cursor的优惠,每个月都能以比较实惠的价格使用这款编程工具。起初,我只是用它来生成注释——每写完一个方法,就让Cursor识别代码意图并自动补上注释。后来,我逐渐尝试将代码也交给AI来写。不过由于生产级的代码不敢完全交给AI,我通常先自己对需求进行分模块、明确每个模块的功能,搭好大致框架后,再详细告诉AI某个部分应该怎么写、怎么实现。这样一来,AI输出的代码也更符合预期。但这样的方式,本质上绝大部分工作还是由我自己完成,AI更像一个“实习生”,主要帮我处理一些琐碎的任务。慢慢地,我开始思考如何更好地使用AI,如何让它真正接管整个需求开发流程。直到后来接触到Spec Coding,才在一定程度上解决了这个问题。
Vibe Coding
先介绍下vibe Coding。Vibe Coding(氛围式编程)是近年来兴起的一种革命性软件开发方法,由AI专家Andrej Karpathy在2025年初提出并推广。其核心理念是让开发者利用大型语言模型,通过自然语言描述而非手动编写每一行代码来构建软件。这意味着,程序员的角色从编码实现者转变为了AI的引导者和优化者。
核心理念与工作流程
Vibe Coding的目标是让开发者专注于解决问题的逻辑和创意,而非繁琐的语法和API细节。正常的工作流程:
- 明确需求:明确需要解决的问题和目标,要做什么。
- 描述给ai:告诉他你要干啥,比如“给我创建一个简单的天气应用,可以显示用户输入城市的当前天气,使用xxx和xxx实现”
- ai生成代码:ai就听从你的命令哼哧哼哧的开始干活,然后给你交付一个做好的项目。
代表工具
比如cursor,github copilot,claude code,codex,opencode等等都可以干这事。
好处
- 提高开发效率:快速生成代码,节省大量手动编码时间。
- 降低编程门槛:只要装好工具充好钱,不会编程的人也能快速弄出来个软件
- 增强创造力:开发者可以更专注于架构设计和业务逻辑等更高层次的问题
不足的地方
- 会有幻觉:经历对话的次数增多,往往会出现化觉,会变笨,会变得答非所问,干活也不利索了,这时候就进退两难了。
- 细节点无法确认:对于范围稍大的变更,一些不确定的细节,ai往往就按照自己发挥了,结果只能是能用,但是达不到预期
- 无状态:无记忆的交互模式,新开一个会话ai无法理解目前业务功能的逻辑的上下文。
- 代码逻辑无法闭环:因以上的一些问题,生成的代码短期内可用,但长期来看肯定会成为历史负债,需要人工调整。
结论
Vibe Coding在一些小功能的改动上很有效果,但是在大的需求处理过程中,则不尽人意。
Spec Coding
作为对Vibe Coding某些不足的改进,Spec Coding(规格化编程)代表着一种更严谨、更可控的AI编程范式。如果说Vibe Coding是“草稿式”编程,那么Spec Coding就是“蓝图式”编程。
基本描述
Spec Coding强调在让AI生成代码之前,开发者需要首先将需求进行结构化、形式化的定义,形成机器可测试的明确规格说明。这包括清晰的接口契约(输入/输出)、详细的验收标准(通常采用Given/When/Then等行为驱动开发格式)、以及非功能性约束(如性能指标、安全要求等)
核心流程
- 需求拆解与规格编写:将模糊的自然语言需求转化为可验证的规格。例如,不再是“创建一个用户登录功能”,而是详细定义登录接口的端点、请求参数、成功与失败的响应格式、错误码、密码加密要求、会话超时时间等。
- 提示工程与上下文构建:为AI准备高质量的提示,其中不仅包含上述规格说明,还应明确技术栈、编码规范、依赖版本、目标环境以及测试覆盖率要求等。这相当于为AI提供了详细的施工蓝图和施工标准。
- 分层生成与迭代验证:采用“骨架先行”的策略。先让AI根据规格生成模块接口和数据模型,然后逐步填充业务逻辑和异常处理,最后生成配套的单元测试和集成测试。每一步都结合静态分析工具和测试进行验证,形成“生成-验证-修复”的闭环。
Spec Coding通过引入前置的规格定义,极大地提升了AI生成代码的可控性、准确性和可维护性。它减少了AI的“猜测”空间,将生成过程建立在精确的契约之上,特别适合复杂业务系统、团队协作以及对质量和安全要求高的场景。这是AI编程从“可用”走向“好用”的关键一步。
好了,以上就是一些定义的东西,我们来看具体的使用工具,这里我们用的是openSpec
github地址: https://github.com/Fission-AI/OpenSpec
Open Spec
Open Spec(开放规格)可以看作是Spec Coding理念的进一步延伸和社区化实践。它旨在建立一个开放、共享、标准化的机器可读规格库,以解决不同项目、不同团队之间规格定义重复建设和互操作性差的问题。
要使用open spec需要将本地的node版本提升到20.19.0或更高
// 安装openspec
npm install -g @fission-ai/openspec@latest
// 进入需要使用openspec的项目,初始化
cd your-project
openspec init
初始化后会让选择使用什么编程软件去执行,这里我选择了opencode。在opencode的命令行处就能看见openspec的相关命令。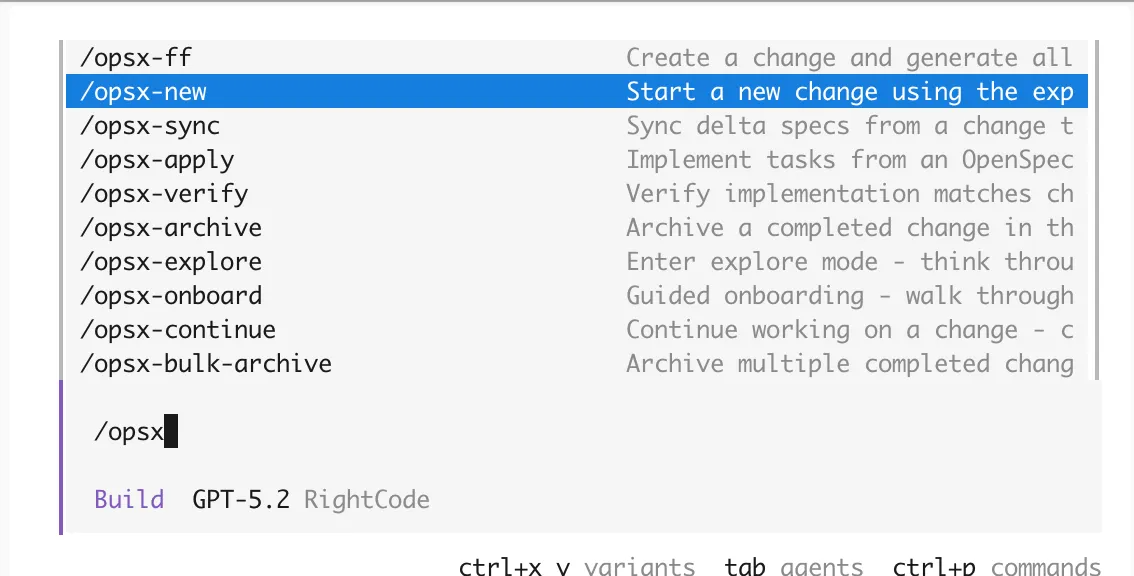
这里我们主要关注四个命令"/opsx-new", “/opsx-continue”, “/opsx-apply”, “/opsx-archive”
openspec的工作流程: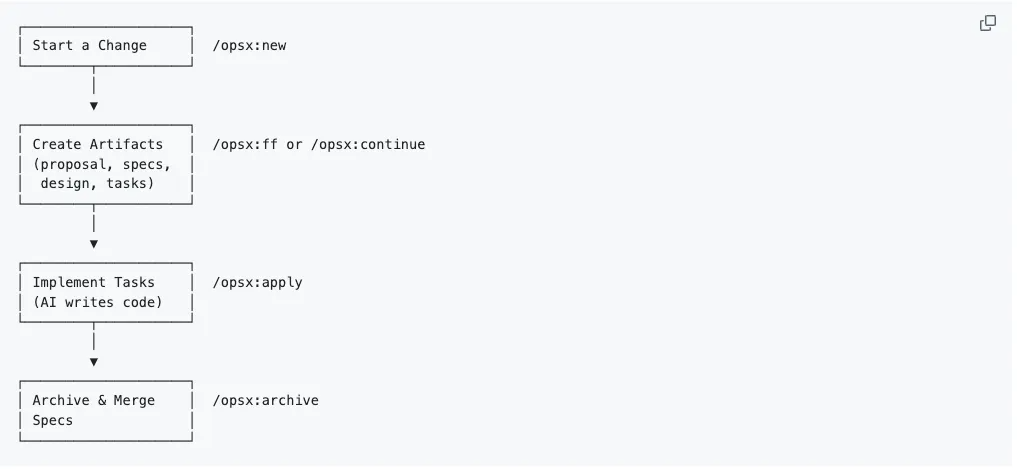
整体可以分为,1. 提出需求 → 2. 不断的确认需求和设计方案 → 3. 执行任务 → 4.归档
亲身试了下,只要最开始的阶段,在需求里写的明白一些,ai会解析需求,并提出问题,我们只需要回答就好了。然后ai会一步一步的将过程实现,我们在一个阶段完成后输入“/opsx:continue”就会进入到下一阶段的执行,在这个阶段如果发现了哪里不对,都可以修改。最后就给我们生成了具体的执行计划。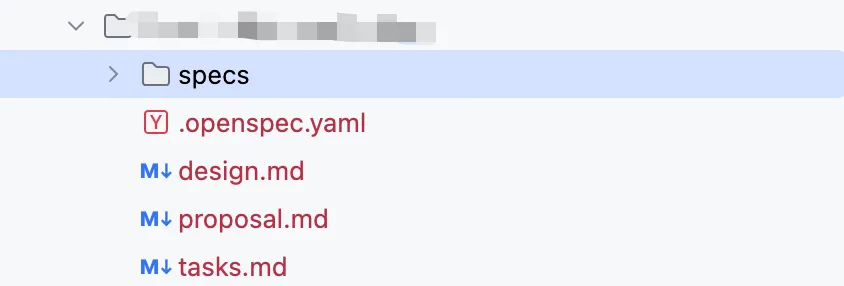
proposal.md
对你的需求做分析:
1. 为什么要做这个需求
2. 要做什么
3. 新增了哪些能力
4. 影响了哪些地方
design.md
技术文档分析:
1. 工程环境解析
2. 本次要做的点
3. api定义
4. 数据模型
5. 中间件
6. 存在的问题,需要你解答的问题
tasks.md
拆分为可执行的具体的模块任务
1. 基础准备与依赖
2. 数据库表
3. 持久层
4. 领域服务
5. web层
6. 前端服务
specs/
具体模块的规范逻辑
生成的task.md会将任务拆解成n个模块,每个模块多个小点,在具体执行之前,跟他说不要一次性全部执行完成,分模块执行,执行完跟你确认,review完后再执行下个模块,不然ai会一股脑全部执行,等你看到结果的时候所有点都执行完了,那改起来又要消耗更多的token,速度也慢。
通过“/opsx:apply”进行执行,执行完不满意再针对某个点进行修改,最后通过“/opsx:archive”进行归档。
便宜大模型推荐
目前国外好用的大模型都很贵,动辄一个月都要上百块。凑巧我最近发现了一个可以低价使用gpt5-codex的中转,如果使用非常频繁就购买中包套餐,量大管饱,前一天用不完会延续到第二天,基本用不完,价格是官网的一半还便宜。
https://www.right.codes/register?aff=ef606aed
如果可以的话用我的推荐码,购买后会返利,我买了60rmb反了15美元。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)