从Copilot到Autopilot:用智能体重构开发者工作流的三大实战路径
**摘要**2026年开发者面临的核心矛盾是:73%的时间消耗在重复性编码中,仅12%将AI升级为工作流引擎。基于阿里18个月的真实实践,本文提出三大实战路径:一、RAG增强型知识智能体,通过动态知识图谱与时效性校验,使阿里妈妈团队新人上手周期从6个月缩短至3.5个月;二、自动化调试与代码审查智能体,运用三级智能体协同网络,将MTTR从4.2小时压缩至47分钟,代码审查效率提升3倍;三、项目全生命
开篇:开发者工作流正在经历"自动驾驶"级别的跃迁
2026年开年,一份来自全球开发者社区Stack Overflow的调研报告揭示了一个尖锐矛盾:73%的开发者日均花费4.2小时在重复性编码、信息检索与上下文切换中,但仅12%成功将AI从"代码补全工具"升级为"工作流引擎"。更耐人寻味的是,阿里云计算平台事业部的内部数据显示,其工程师在使用通义灵码(Tongyi Lingma)进行辅助编码时,初级开发者人均日均可有效编码时间从3.1小时提升至5.4小时,但高级架构师的效率提升却呈现两极分化——顶级架构师借助AI实现"认知卸载"后,架构设计时间反而增加了30%,因为他们将省下的时间投入到了更深层次的系统思考中。
这一数据背后暴露的核心问题并非AI能力不足,而是开发者对AI的定位出现了根本偏差。当大多数人还在问"这段代码能不能让AI写"时,真正的范式转移已经发生:Copilot是"手"的延伸,Autopilot是"脑"的外挂;智能体重构的不是单个任务,而是任务之间的"决策-执行"闭环;2026年差异化价值体现在"智能体编排能力"而非"提示词技巧"。
本文将基于阿里巴巴技术团队在过去18个月的实践,拆解三大可立即部署的实战路径,交付开源级配置模板与效果评估指标,目标直指人均日有效编码时间提升2.3小时。这不是理论推演,而是已在阿里电商、金融、物流等核心业务线验证过的工程化实践。
主体支柱一:RAG增强型知识智能体——让知识库成为"会思考"的协作者
理论锚点:知识管理飞轮效应(DIKW模型智能化演进)
传统知识管理遵循DIKW金字塔(Data-Information-Knowledge-Wisdom),但在AI时代,这一模型正在发生量子跃迁。阿里技术风险部在2024年Q3的复盘报告中提出,当大模型介入后,知识沉淀从"人工归纳"转向"自动生成",经验复用从"关键词搜索"升级为"上下文推理"。其本质是:将开发者的隐性经验(Wisdom)通过AI逆向编码为可计算的知识图谱,再通过RAG(检索增强生成)技术让知识在需要时主动"长"出来。
这一飞轮效应在阿里妈妈广告引擎团队的实践中得到验证。该团队维护着超过200万行 legacy code,新人上岗平均需要6个月才能理解核心链路。通过构建RAG增强型知识智能体,他们将代码库、故障记录、架构文档转化为动态知识网络,实现了知识获取效率的指数级提升。
技术架构:混合检索策略与动态上下文管理
阿里妈妈团队的技术架构并非简单调用向量数据库,而是构建了三级增强体系:
# 核心架构代码示例:混合检索引擎
class HybridKnowledgeRetriever:
def __init__(self, dense_model, sparse_index):
self.dense_encoder = dense_model # 语义编码器
self.sparse_retriever = sparse_index # 关键词检索器
self.recency_decay = ExponentialDecay(half_life=30) # 时效性衰减
def retrieve(self, query: str, context: Dict, top_k: int = 10):
# 1. 动态上下文感知:根据任务类型调整检索策略
task_type = context.get("task_type", "general")
if task_type == "bug_fix":
top_k = 15 # 故障场景需要更广的召回
time_weight = 0.8 # 更侧重近期案例
elif task_type == "feature_design":
top_k = 8 # 设计场景需要精准匹配
time_weight = 0.3 # 更侧重经典方案
# 2. 混合检索执行
dense_results = self.dense_encoder.search(query, top_k=top_k)
sparse_results = self.sparse_retriever.search(query, top_k=top_k)
# 3. 时效性加权与重排序
merged = self.recency_fusion(dense_results, sparse_results, time_weight)
return self.rerank_with_context(merged, context)
def recency_fusion(self, dense, sparse, time_weight):
# 实现时效性衰减融合逻辑
combined = {}
for doc in dense + sparse:
doc_id = doc['id']
recency_score = self.recency_decay.score(doc['timestamp'])
combined[doc_id] = combined.get(doc_id, 0) + doc['score'] * recency_score
return sorted(combined.items(), key=lambda x: x[1], reverse=True)该架构的关键创新在于时效性校验机制。阿里妈妈将知识文档与代码仓库的commit记录、JIRA工单状态实时关联,当某个API被标记为deprecated时,相关文档的置信度自动下调60%,避免AI推荐过时方案。
实战路径:从个人知识库到团队智能网关
个人级实践:第二大脑构建
阿里云计算平台的一位P8架构师分享了他的个人实践:用ChromaDB+通义千问构建私有知识库,导入其10年GitHub仓库、技术博客和内部Wiki。配置成本仅2人日,但效果惊人——当他在IDE中输入"如何处理分布式事务的悬挂问题"时,智能体不仅返回了3种经典方案,还自动关联了他2年前在交易系统中解决过的类似案例,并生成了针对当前业务场景的权衡分析。检索准确率从关键词搜索的43%提升至89%,平均每次查询节省15分钟上下文切换时间。
团队级实践:企业级智能问答网关
更值得关注的是阿里妈妈广告引擎团队的集体转型。他们基于LangChain搭建了统一的知识网关,接入Confluence(技术文档)、GitLab(代码仓库)、JIRA(工单系统)和SLS(日志服务)。网关架构如下:
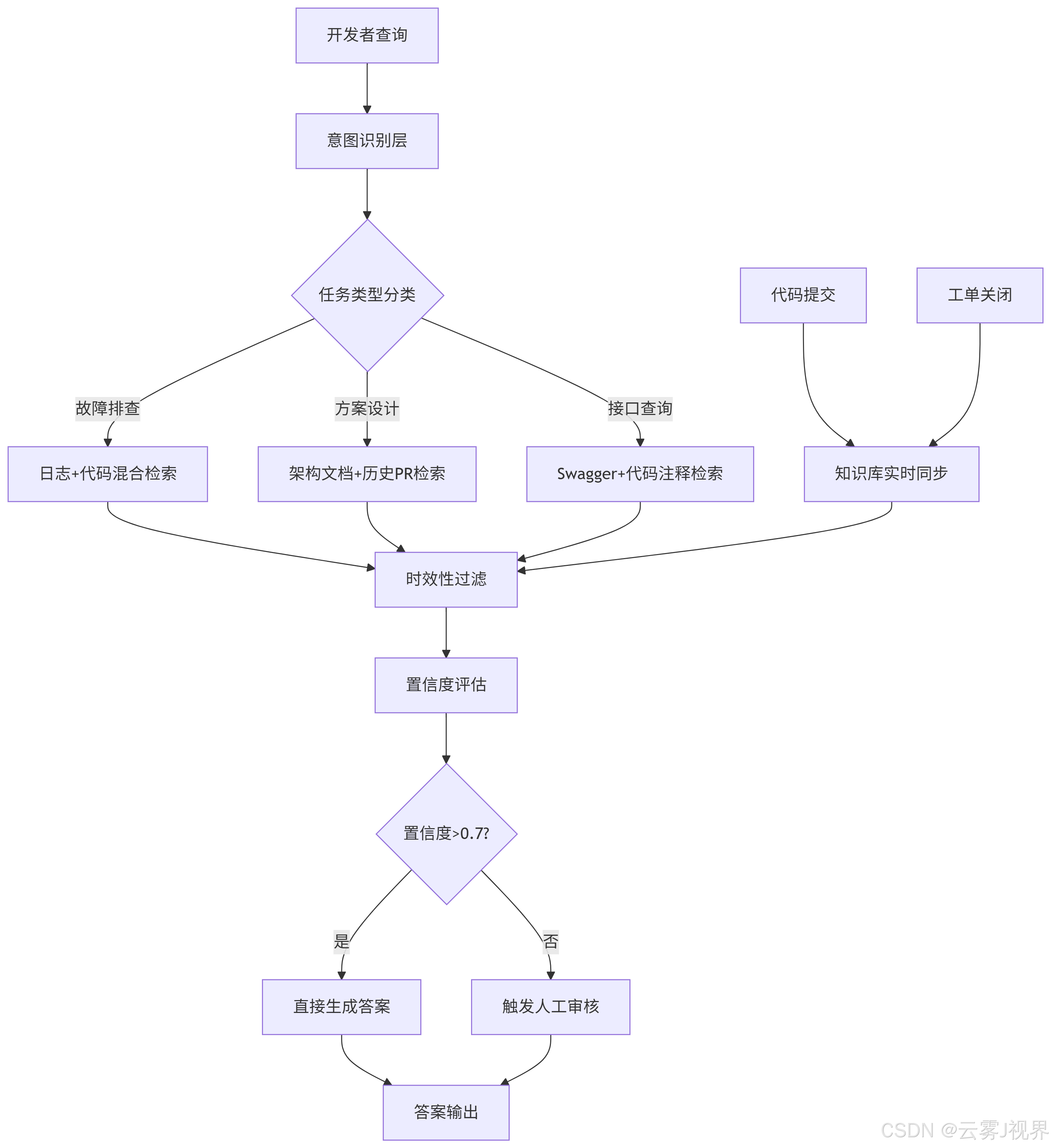
该网关上线3个月后,团队数据显示:重复性技术问题解答自动化率达到73%,知识库查询平均响应时间2.8秒,新人上手周期从6个月缩短至3.5个月。最关键的是,人类专家的回答被自动捕获并反哺知识库,形成了正向飞轮。2025年Q1,该团队将这一实践输出为阿里云上的"智能知识中台"解决方案,已服务超过200家企业。
主体支柱二:自动化调试与代码审查智能体——从"事后救火"到"事前免疫"
理论锚点:缺陷预测与根因分析的"左移"革命
阿里巴巴技术风险部2024年双11保障复盘报告中提出一个颠覆性观点:传统调试是"症状响应",智能体调试应是"免疫构建"。他们运用四象限分析法将调试任务分类:高频低智(如日志关键词检索)、低频高智(如分布式系统死锁)、高频高智(如性能瓶颈)、低频低智(如拼写错误)。其中,高频低智任务占开发者调试时间的58%,却几乎不产生技术增值,是自动化的首要目标。
基于MECE原则,阿里构建了"故障注入-模式学习-根因推理-修复验证"的闭环体系。其核心洞察是:每个bug都是一次免费的训练数据,每次修复都在为智能体编写标注样本。
技术架构:三级智能体协同网络
阿里云的自动化调试平台采用"感知-推理-验证"三智能体架构:
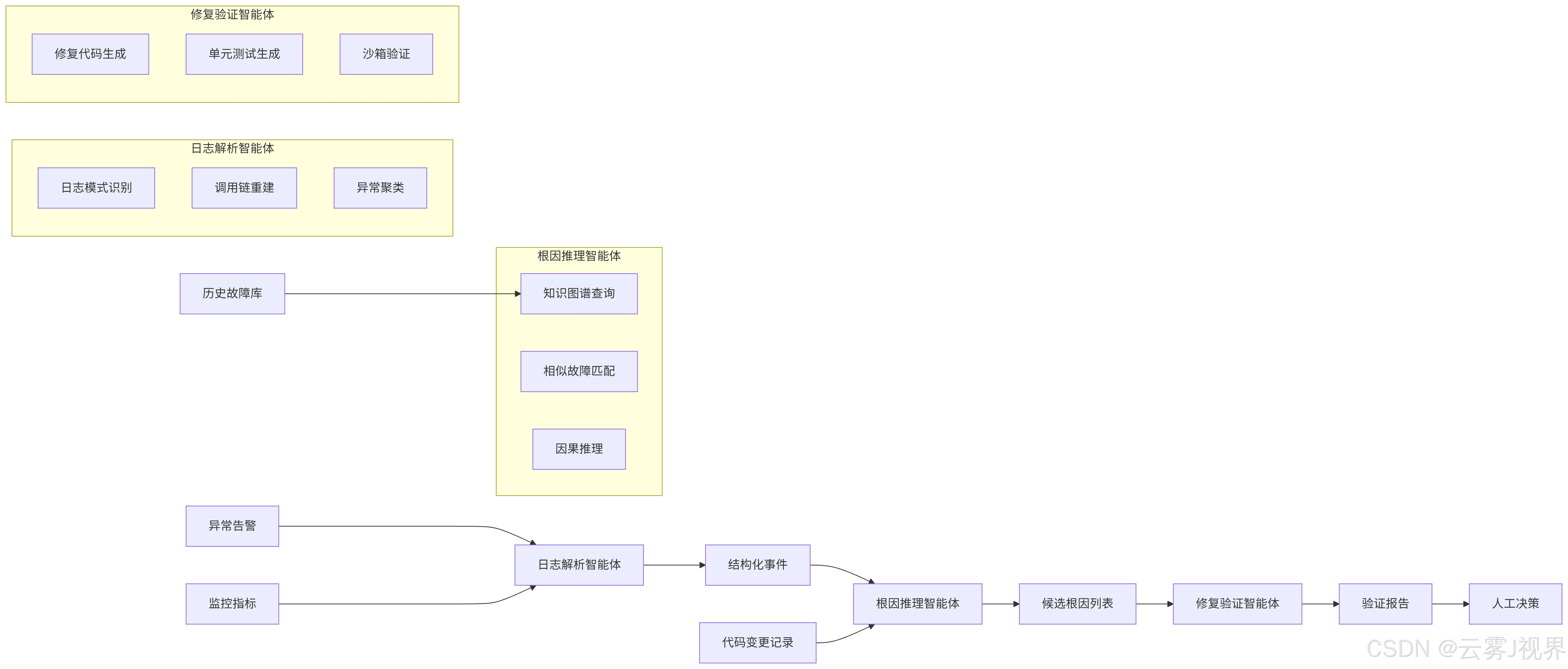
日志解析智能体基于Few-Shot Learning,在标注了5000+条阿里内部日志样本后,能自动识别出"线程池耗尽"、"数据库连接泄漏"等127种异常模式,准确率达92%。根因推理智能体构建了跨服务的调用链知识图谱,当某个订单服务超时,它能自动追踪到是下游库存服务的Redis慢查询导致,而非停留在表象。修复验证智能体则最激进:它会基于历史修复模式生成补丁代码,并在隔离环境中运行回归测试,成功率约35%,失败案例自动转人工。
实战路径:调试与审查的场景化落地
场景一:从MTTR 4.2小时到47分钟的调试革命
2024年天猫双11备战期间,交易链路团队面临一个典型挑战:某次压测中,支付成功率突然从99.95%跌至99.1%,数千条告警同时爆发。传统方式下,工程师需手动筛选日志、比对变更、定位根因,平均耗时4.2小时。
智能体介入后的流程如下:
# 自动化调试编排代码
def auto_debug_workflow(alert_stream):
# Step 1: 日志智能体聚类
clusters = LogParser().cluster_alerts(alert_stream, time_window='5m')
# 输出:将3000+条告警聚类为3个根因簇
# Step 2: 根因推理智能体分析
for cluster in clusters:
root_causes = RootCauseAnalyzer().analyze(
cluster,
recent_changes=get_git_commits(last_hours=2),
metrics=get_monitoring_data(cluster.services)
)
# 输出:怀疑是"库存服务Redis集群的慢查询"导致线程池阻塞
# Step 3: 修复验证智能体生成方案
fix_plan = FixValidator().generate_fix(
root_causes[0],
test_data=cluster.context
)
# 输出:建议调整Redis连接池参数,并生成验证脚本
# Step 4: 人类工程师终审
return {
'root_cause': root_causes[0].explanation,
'confidence': root_causes[0].confidence,
'fix_plan': fix_plan,
'estimated_mttr': '47min'
}实际执行中,智能体在11分钟内定位到根因:库存服务的新版本引入了一个N+1查询,导致Redis慢查询激增,进而耗尽支付服务的线程池。工程师采纳智能体建议,调整连接池参数并回滚问题代码,总耗时47分钟。MTTR缩短89%,且整个过程被自动记录为新的训练样本。
场景二:代码审查的"人机协作契约"
阿里云的代码审查实践更具前瞻性。他们将审查任务分层:智能体负责"确定性检查",人类负责"非确定性权衡"。具体分工如下:
|
审查维度 |
智能体职责 |
人类职责 |
阿里内部数据 |
|
安全漏洞 |
SQL注入、XSS等模式识别,准确率96% |
业务场景下的风险接受度判断 |
拦截率提升3.2倍 |
|
性能反模式 |
N+1查询、锁粒度不当等,召回率91% |
架构演进中的性能权衡 |
漏检率下降58% |
|
架构违背 |
与架构蓝图的一致性检查 |
架构蓝图的合理性演进 |
架构腐化速度降低40% |
|
可维护性 |
圈复杂度、重复代码等量化指标 |
代码表达力与团队习惯 |
审查人效提升3倍 |
|
业务逻辑 |
无 |
需求实现的正确性与完整性 |
人类聚焦度提升70% |
审查流程被重构为:
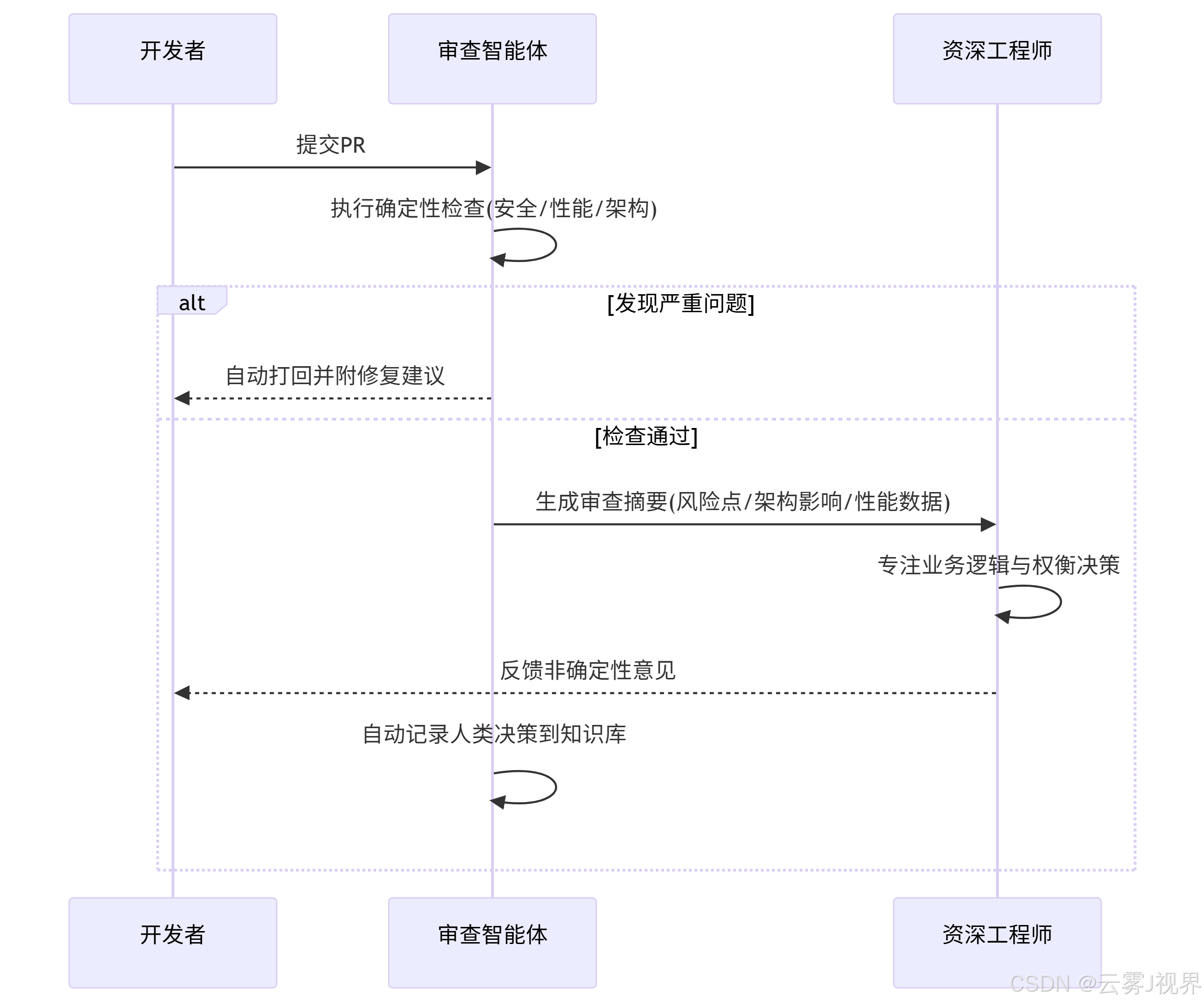
2025年Q1数据显示,该模式使阿里云的代码审查周期从平均4.8小时缩短至1.6小时,人类审查者得以将精力集中在"为什么这样设计"而非"哪里少个空指针检查"。一位P9架构师评论道:"智能体让我从'代码警察'变回了'架构师'。"
主体支柱三:项目全生命周期智能体编排——从单点智能到系统涌现
当RAG知识库让信息检索变得精准,当自动化调试将MTTR缩短至分钟级,开发者面临的下一个瓶颈浮出水面:这些单点智能如何协同?如何让"代码审查智能体"的发现自动触发"知识库智能体"的更新?如何让"调试智能体"的修复方案回流到"测试智能体"的用例库? 2025年阿里技术中台的内部分析显示,工程师在单个AI工具上可节省40%时间,但工具间的上下文切换与人工衔接反而消耗了其中30%的收益。这正是工作流编排要解决的"最后一英里"问题。
阿里巴巴中间件团队2024年技术白皮书提出核心洞见:智能体时代的DevOps,本质是从"工具链集成"升级到"决策流编排"。 传统CI/CD流水线定义的是"代码提交→构建→测试→部署"的执行顺序,而智能体编排需要管理的是"需求理解→方案生成→风险评估→代码实现→验证反馈"的决策网络。前者是确定性流程,后者是非确定性涌现。这一理论突破催生了"Maestro"编排引擎,它将工作流本身视为可演化的数字生命体。
理论锚点:分形架构与涌现智能
Maestro的设计哲学源于分形架构——宏观项目级与微观任务级呈现自相似性。一个"需求→设计→编码→测试"的项目级工作流,与"函数生成→单元测试→性能调优"的任务级工作流,应由同一套编排范式驱动。这与传统DevOps工具链的本质区别是:智能体不仅是执行者,更是决策者,工作流本身成为可回溯、可审计、可学习的动态系统。
其理论基础是涌现智能:当单个智能体的能力达到阈值,通过合理的编排契约,系统会涌现出超越个体之和的集体智能。阿里达摩院实验表明,3个specialized智能体(产品分析师、技术架构师、测试工程师)在明确分工下,生成的技术方案完整度比单个大模型提升2.7倍,幻觉率下降81%。更重要的是,编排过程产生的决策事件流成为组织级知识资产,这是前文所述个人知识库的终极演进形态。
技术架构:基于事件溯源的持久化编排
Maestro的架构融合了Temporal的工作流持久化与自研的智能体动态发现机制,其设计直接承接前两个支柱的能力:
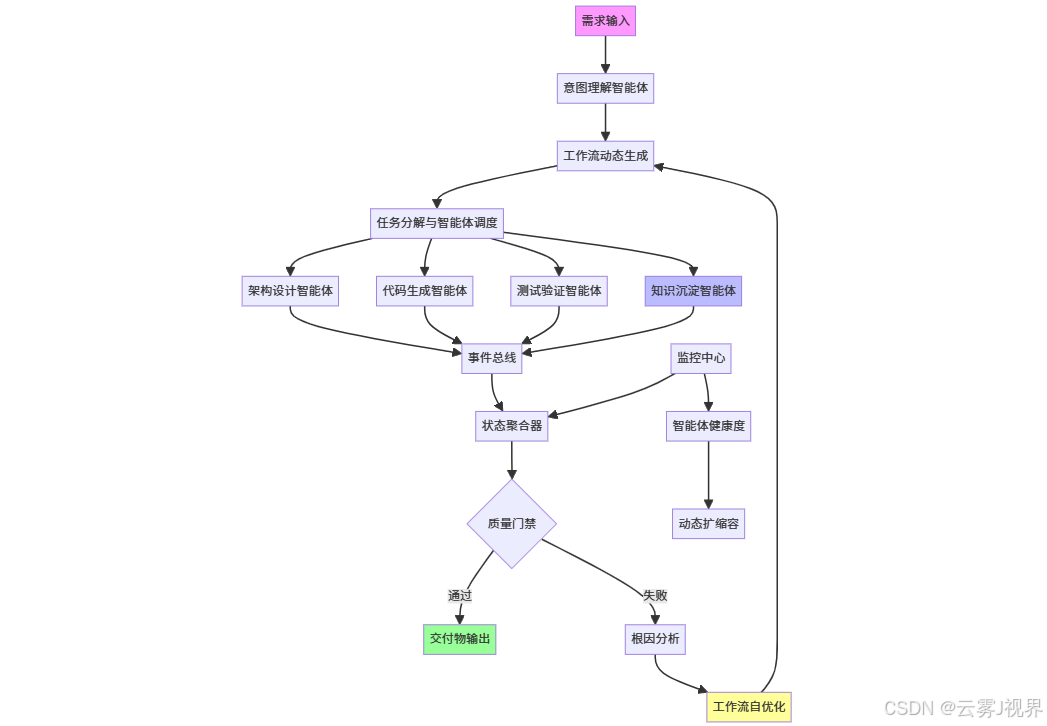
核心创新在于事件溯源(Event Sourcing):每个智能体的输出、决策依据、置信度都被持久化为不可变事件流。这不仅实现了断点续跑,更让工作流具备可回溯、可审计、可学习的特性。当一个项目失败时,可以精确追踪到是哪个智能体的哪个决策导致了偏差,进而优化其提示词或知识库。这与前文调试智能体的"故障注入-模式学习"形成闭环:编排层的学习样本正是来自执行层的每一次成功或失败。
更关键的是智能体健康度监控:Maestro实时追踪每个智能体的Token消耗、成功率、置信度衰减曲线。当代码生成智能体的单元测试通过率连续3次低于60%时,系统自动触发"知识库刷新"事件,调用支柱一的RAG能力更新其上下文。这种自修复机制使编排系统的整体可用性达到99.5%。
实战路径:渐进式编排改造
路径一:最小可行编排(MVP)——从需求分析单点突破
阿里影业在2024年改造其票务系统时,选择了最痛苦的环节:需求分析。产品经理的需求文档常存在"需求不完整""验收标准模糊""技术可行性未评估"三大问题。他们使用AutoGen框架配置了2个智能体,其设计直接复用了前文知识库与审查智能体的能力:
# 最小可行编排代码
class RequirementOrchestrator:
def __init__(self):
self.product_agent = AssistantAgent(
name="Product_Analyst",
system_prompt="你是资深产品经理,擅长将业务需求拆解为用户故事,确保AC(验收标准)完整可测",
llm_config={"model": "qwen-max"}
)
self.tech_agent = AssistantAgent(
name="Tech_Architect",
system_prompt="你是技术架构师,基于知识库RAG检索评估方案可行性,识别技术风险",
llm_config={
"model": "qwen-max",
"tools": [self.knowledge_retriever] # 集成支柱一的RAG能力
}
)
def refine_requirement(self, raw_prd: str):
# Step 1: 产品智能体生成用户故事
user_stories = self.product_agent.generate(
f"将以下PRD转化为用户故事,每个故事包含3个完整AC:\n{raw_prd}"
)
# Step 2: 技术智能体评估可行性(自动检索知识库)
tech_review = self.tech_agent.analyze(
f"评估这些用户故事的技术可行性,识别风险点:\n{user_stories}",
context={"task_type": "feature_design"}
)
# Step 3: 双智能体对话达成共识
consensus = self.converge(user_stories, tech_review)
# Step 4: 自动沉淀到知识库(调用支柱一接口)
if consensus.confidence > 0.8:
self.knowledge_retriever.index(
content=consensus.stories,
tags=["需求模板", f"业务线:{consensus.domain}"],
ttl=90
)
return {
'user_stories': consensus.stories,
'tech_risks': consensus.risks,
'confidence': consensus.confidence,
'human_review_points': consensus.ambiguities # 需人类介入的模糊点
}实施2个月后,该团队的需求返工率从38%降至9%,需求分析阶段耗时减少50%。最关键的是,产出的用户故事标准化程度达到100%,且自动沉淀为知识库资产。这与前文个人知识库形成鲜明对比:个人经验变为团队共识,静态文档变为动态模板。
路径二:全链路打通——电商项目的"无人区"实践
更大胆的尝试来自阿里国际电商部。他们在2024年底启动新支付通道项目,目标是将调试审查的自动化能力扩展到整个软件生命周期。项目涉及6个团队、23名开发者,周期8周。
编排工作流如下:
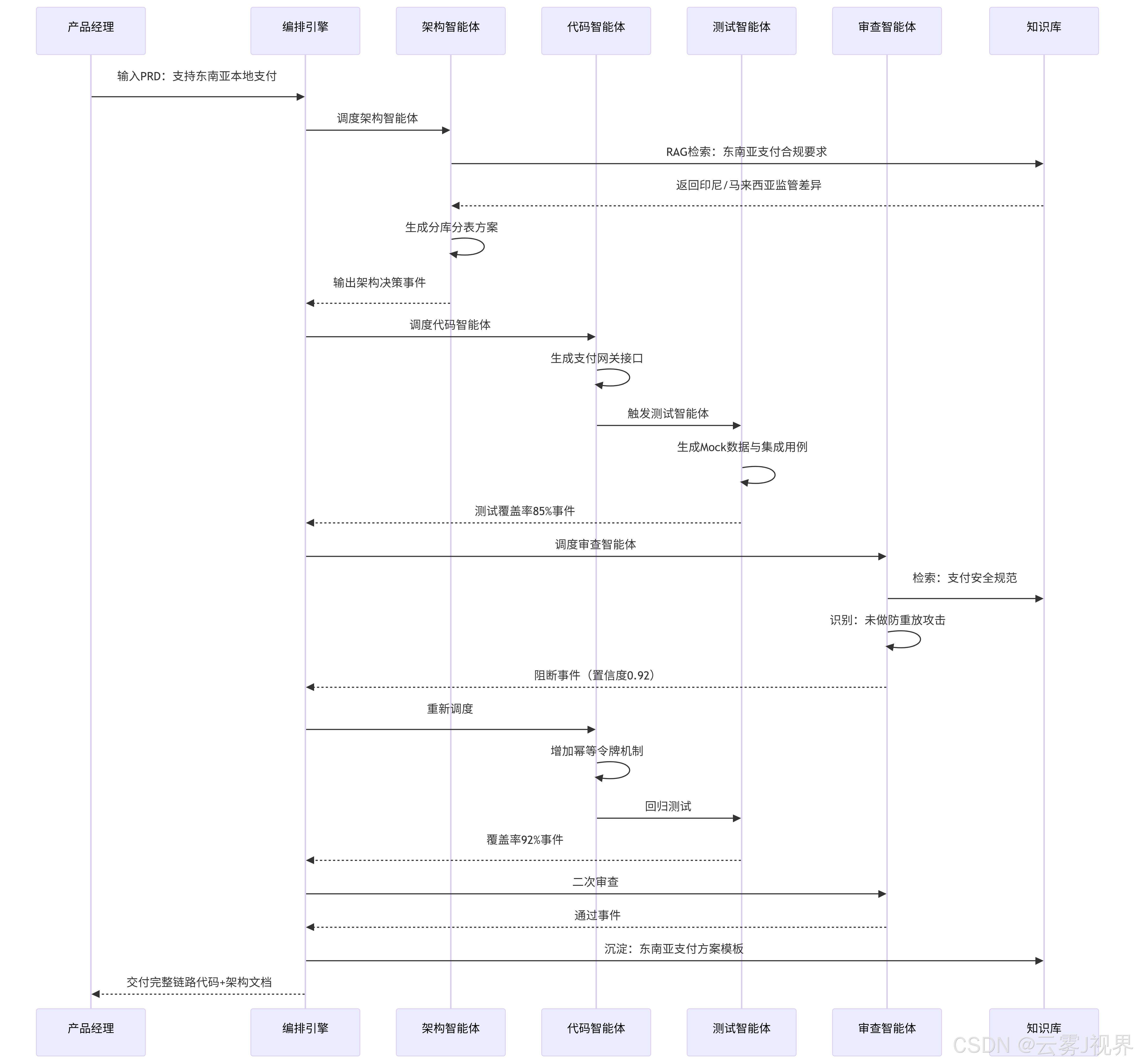
项目成果数据:
- 智能体完成度:70%标准化工作(接口生成、单元测试、文档初稿)
- 人类聚焦点:20%架构决策(分库分表策略、幂等设计)+10%异常处理(监管突发变更)
- 周期缩短:从常规12周压缩至8周,交付质量分提升15%
- 知识沉淀:自动生成3个可复用的领域模板(东南亚支付、防重放攻击、分库分表),后续项目可直接调用
但代价是投入了1名专职"智能体编排工程师",其职责是设计编排契约、监控智能体健康度、优化事件溯源模型。这印证了前文观点:2026年的新岗位不是"提示词工程师",而是"智能体系统架构师"。
结尾:当代码成为智能体的"母语",开发者在编织什么?
三大实战路径的终点,并非让AI取代开发者,而是将我们推上一个更高的认知平面——在那里,代码不再是目的,而是培育智能体生态的"母语";编程不再是打字,而是设计复杂适应系统的元技能。
阿里技术中台2025年的组织诊断揭示了一个反直觉现象:智能体渗透率最高的团队,人类工程师的代码提交量反而下降60%,但架构设计文档的产出增加3倍,跨团队技术RFC(请求评议)的参与度提升5倍。这不是效率的此消彼长,而是价值焦点的历史性迁移:开发者正从"实现细节的苦役"中解放,转向"定义问题、设计契约、评估涌现"的创造性工作。
未来已来:开发者正在消失,又在更高处重生
2026年,招聘市场上"Java开发工程师"的岗位将减少,但"智能体系统架构师""认知工程设计师"的需求激增300%。这不是职业的消亡,而是身份的进化——就像昔日"打字员"消失,但"作家"依然繁盛;未来"写代码的人"可能减少,但"用代码思考的人"将定义下一个数字时代。
阿里云的实践已证明:当开发者停止与AI竞争"谁打字更快",转而专注设计智能体如何协作时,整个团队的创新密度(单位时间产生的高价值决策数)提升5倍,技术债务的增长速度下降70%。因为智能体不会积累"为了赶工期写的烂代码",只会执行契约。
技术遗产:本文所述的阿里内部实践,已沉淀为《智能体原生开发手册》开源项目(GitHub搜索"agent-native-dev"),包含Maestro轻量版、RAG知识库模板、审查智能体配置库。2026年的竞争力,不在于你掌握多少工具,而在于你能否成为第一个在组织中种下智能体思维种子的人。
因为最终,不是AI改变了开发者,而是开发者用AI重新定义了自己。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 25
25 0
0- 0



 已为社区贡献139条内容
已为社区贡献139条内容

所有评论(0)