电商客服工单自动分类(SVM支持向量机)
监控系统(Grafana)实时展示分类准确率、PSI(特征分布漂移)、API错误率,若PSI>0.25(数据分布变化),自动触发模型重训(Airflow调度算法团队重训流程)feature_store/feature_repo/features.py(定义实体、特征视图、在线/离线特征,业务团队通过此调用)(2)算法团队:SVM-RBF核模型训练(model_training/svm/train_
业务痛点:某头部电商平台年客服工单量超3600万,涉及售后、物流、咨询、投诉等12个部门,人工分类存在:
- 效率低:日均10万+工单需200+客服处理,耗时占客服总工时40%
- 准确率低:复杂工单(如“物流延迟+商品破损”跨多部门)分类错误率达25%,导致工单流转延误(平均处理时长增加2小时)
- 标准不一:新客服培训成本高(需1个月掌握分类规则),离职交接易引发分类波动
开发环境与工具链
算法团队:
- 语言:Python 3.9(特征工程/模型训练)、Scala 2.13(Spark数据预处理)
- 文本处理:jieba(结巴分词)、sklearn(TF-IDF)、gensim(关键词提取)
- 特征存储:Feast 0.34(实体:工单ID,特征:TF-IDF向量/关键词数/历史工单频率)
- 模型训练:scikit-learn 1.2(SVM-RBF核)、XGBoost 2.0(类别不平衡处理对比)
- 实验跟踪:MLflow 2.8(记录参数/指标/模型)、Weights & Biases(可视化)
- 版本控制:git@github.com:ecom/algorithm-ticket-classification.git
业务团队:
- 语言:Go 1.20(高性能API)、Java 17(客服系统集成)
- 服务框架:FastAPI 0.104(Python轻量级API)、gRPC(跨语言特征服务调用)
- 服务治理:Kong 3.4(API网关)、Consul 1.16(服务发现)
- 监控:Prometheus 2.47(指标采集)、Grafana 10.2(可视化)
- 版本控制:git@github.com:ecom/business-ticket-classification.git
数据准备与特征变化
(1)原数据结构
① 客服工单系统(ticket_core,Hive表)
② 用户行为日志(user_behavior,Kafka Topic)
// 历史工单记录(用于提取用户工单频率特征)
{ "user_id": "U789", "historical_tickets": 3, "last_department": "售后部" }
③ 部门分类标准库(department_labels,Excel)
(2)数据清洗与特征工程(算法团队负责,重点:文本→TF-IDF特征)
步骤1:数据清洗(Spark批处理)
- 缺失值处理:content为空(占0.1%)用“未知”填充,后续标记为低置信度
- 异常值处理:content长度<5字符(如“查物流”)视为无效,关联用户历史工单补全(如用户最近3单均为物流问题,则归为物流部)
- 去重:基于user_id+content哈希值去重(重复工单占比2%,避免模型过拟合)
步骤2:特征工程(核心:结巴分词+TF-IDF+统计特征)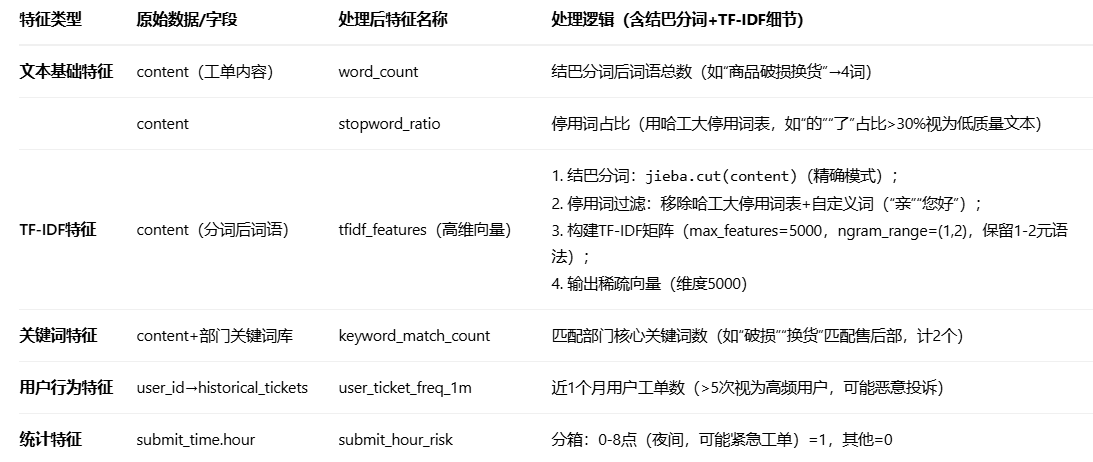
步骤3:特征变化对比表(原数据→处理后特征)

(3)处理后特征矩阵示例(算法团队输出)
代码结构
算法团队仓库(algorithm-ticket-classification)
algorithm-ticket-classification/
├── data_processing/ # 数据预处理(Spark/Scala)
│ ├── src/main/scala/com/ecom/
│ │ ├── DataCleaning.scala # 缺失值/异常值/去重处理
│ │ └── DataDeduplication.scala # 基于user_id+content哈希去重
│ └── build.sbt # Spark依赖(spark-core, spark-sql)
├── feature_engineering/ # 特征工程(Python,按功能拆分)
│ ├── text_processing.py # 结巴分词+停用词过滤+关键词提取
│ ├── tfidf_vectorizer.py # TF-IDF矩阵构建(sklearn TfidfVectorizer)
│ ├── statistical_features.py # 统计特征(词数/频率/分箱)
│ └── requirements.txt # 依赖:jieba, sklearn, pandas
├── model_training/ # 模型训练(分SVM和XGBoost子模块)
│ ├── svm/ # SVM-RBF核模型
│ │ ├── train_svm.py # SVM训练(RBF核,class_weight处理不平衡)
│ │ ├── evaluate_svm.py # 评估(混淆矩阵/F1-score/PSI)
│ │ └── svm_params.yaml # 调参记录(C=10, gamma=0.1)
│ ├── xgboost/ # XGBoost对比模型(处理类别不平衡)
│ │ ├── train_xgb.py # XGBoost训练(scale_pos_weight处理不平衡)
│ │ └── xgb_params.yaml # 调参记录(max_depth=6, learning_rate=0.1)
│ └── requirements.txt # 依赖:sklearn, xgboost, shap
├── feature_store/ # Feast特征存储(明确内容)
│ ├── feature_repo/ # Feast特征仓库(核心!)
│ │ ├── __init__.py
│ │ ├── features.py # 特征定义(实体、特征视图、在线/离线特征)
│ │ └── feature_store.yaml # Feast配置(在线存储Redis,离线存储Parquet)
│ └── deploy_feast.sh # 部署Feast服务到K8s的脚本
├── mlflow_tracking/ # MLflow实验跟踪
│ ├── run_svm_experiment.py # 记录SVM实验(参数/指标/模型)
│ └── run_xgb_experiment.py # 记录XGBoost实验
└── README.md # 算法文档(特征字典/模型输入输出说明)
(1)算法团队:特征存储(Feast,明确内容)
feature_store/feature_repo/features.py(定义实体、特征视图、在线/离线特征,业务团队通过此调用)
from feast import Entity,FeatureView,Field,FileSource,RedisSource
from feast.types import Float32,Int64,String
import pandas as pd
# 1.定义实体:工单ID
ticket_entity = Entity(name="ticket_id",value_type=String,description="工单唯一标识")
# 2.定义离线特征(从数据湖Parquet文件获取,用于模型训练)
offline_source = FileSource(
path="s3://ecom-data-lake/processed/ticket_features.parquet",# 算法团队处理后的特征矩阵
event_timestamp_column="submit_time", # 事件时间戳(用于时间旅行查询)
created_timestamp_column="created_at"
)
# 3.定义在线特征(从Redis读取,用于实时预测,低延迟)
online_source = RedisSource(
host="feast-redis-master", # K8s中Redis服务名
port=6379,
key_field="ticket_id", # 键:工单ID
value_field="feature_vector" # 值:序列化后的特征向量(TF-IDF+统计特征)
)
# 4.定义特征视图(整合实体、特征、数据源)
ticket_features_view = FeatureView(
name="ticket_features",
entities=[ticket_entity],
ttl=timedelta(days=7),# 特征保留7天
schema=[ # 特征列表(与算法团队处理后的特征矩阵对应)
Field(name="word_count", dtype=Int64),
Field(name="stopword_ratio", dtype=Float32),
Field(name="keyword_match_count", dtype=Int64),
Field(name="user_ticket_freq_1m", dtype=Int64),
Field(name="submit_hour_risk", dtype=Int64),
Field(name="tfidf_features", dtype=String) # 稀疏向量序列化后存储(如JSON)
],
source=offline_source,
online_source=online_source
)
feature_store/feature_store.yaml(Feast配置,指定在线/离线存储)
project: ecom_ticket_classification # 项目名称
registry: data/registry.db # 特征注册表路径(存储特征元数据)
provider: local # 本地开发用,生产环境用k8s
online_store:
type: redis
connection_string: "redis://feast-redis-master:6379" # 在线存储Redis地址
offline_store:
type: file # 生产环境用bigquery/snowflake
path: "data/offline_store" # 离线存储路径(Parquet文件)
feature_store/deploy_feast.sh(部署Feast服务到K8s,供业务团队调用)
#!/bin/bash
# 1. 构建Feast Docker镜像(含feature_repo)
docker build -t ecom/feast-feature-server:latest -f Dockerfile.feast .
# 2. 推送镜像到仓库
docker push ecom/feast-feature-server:latest
# 3. 部署到K8s(StatefulSet+Service,确保稳定网络标识)
kubectl apply -f k8s/feast-statefulset.yaml
kubectl apply -f k8s/feast-service.yaml # 暴露gRPC端口6566
(2)算法团队:SVM-RBF核模型训练(model_training/svm/train_svm.py)
import joblib
import pandas as pd
import numpy as np
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split,GridSearchCV
from sklearn.preprocessing import StandardScaler
from feature_entineering.tfidf_vectorizer import load_tfidf_matrix # 加载TF-IDF特征
from feature_engineering.statistical_features import load_statistical_features # 加载统计特征
import mlflow
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def load_features_and_labels(feature_path:str,label_path:str)->tuple:
"""加载特征矩阵(TF-IDF+统计特征)和标签(部门ID)"""
# 加载TF=IDF(文本特征提取方法,)特征(TF-IDF+统计特征)核标签(部门ID)
tfidf_matrix,ticket_ids = load_tfidf_matrix(feature_path)
# 加载统计特征(DataFrame:word_count, stopword_ratio等)
stat_features = load_statistical_features(label_path) # 含ticket_id和标签department
# 合并特征(TF-IDF稀疏矩阵+统计特征密集矩阵)
from scipy.sparse import hstack
X = hstack([tfidf_matrix, stat_features.drop(columns=["ticket_id", "department"]).values])
y = stat_features["department"] # 标签:12个部门ID(DEP01-DEP12)
return X,y,ticket_ids
def handle_class_imbalance(X:np.ndarray,y:ndarray)->tuple:
"""处理类别不平衡:XGBoost作为对比,SVM用class_weight='balanced'"""
"""处理类别不平衡:XGBoost作为对比,SVM用class_weight='balanced'"""
# 方案1:SVM原生支持class_weight(自动调整类别权重,少数类权重高)
svm_class_weight = "balanced"
# 方案2:XGBoost(作为对比,用scale_pos_weight,但多分类需用sample_weight)
# 此处仅演示,实际用XGBoost时单独训练
return svm_class_weight
def train_svm_rbf(X_train:np.ndarray,y_train:np.ndarray,class_weight:str)->SVC:
"""训练SVM-RBF核模型(重点:RBF核参数调优)"""
# 初始化SVM模型(RBF核,class_weight处理不平衡)
svm = SVC(
kernel="rbf", # 径向基函数核(高维映射)
C=10, # 惩罚系数(调参后最优值,C越大对误分类惩罚越重)
gamma=0.1, # 核函数系数(调参后最优值,gamma越小映射空间越平滑)
class_weight=class_weight, # 平衡类别权重(欺诈/少数类样本权重高)
probability=True, # 输出概率(用于业务侧风险分级)
random_state=42,
verbose=1 # 输出训练日志
)
# 网格搜索调优(可选,此处用预调参结果)
# param_grid = {"C": [1, 10, 100], "gamma": [0.01, 0.1, 1]}
# grid_search = GridSearchCV(svm, param_grid, cv=5, scoring="f1_macro")
# grid_search.fit(X_train, y_train)
# svm = grid_search.best_estimator_
# 训练模型
svm.fit(X_train, y_train)
logger.info(f"SVM-RBF训练完成,参数:C={svm.C}, gamma={svm.gamma}")
return svm
def evaluate_model(model:SVC,X_test:np.ndarray,y_test:np.ndarray)->dict:
"""评估模型性能(多分类F1-score、混淆矩阵)"""
"""评估模型性能(多分类F1-score、混淆矩阵)"""
y_pred = model.predict(X_test)
report = classification_report(y_test, y_pred, output_dict=True)
f1_macro = f1_score(y_test, y_pred, average="macro") # 宏平均F1(关注少数类)
logger.info(f"测试集F1-macro: {f1_macro:.4f},分类报告:\n{report}")
return {"f1_macro": f1_macro, "classification_report": report}
if __name__=="__main__":
# 加载特征(算法团队处理后的TF-IDF+统计特征)
X,y,_ = load_features_and_labels(
feature_path = "data/processed/tfidf_matrix.npz",
label_path = "data/processed/stat_features.csv"
)
# 划分训练集/测试集(分层抽样,保持部门分布)
X_train,X_test,y_train,y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# 处理类别不平衡(SVM用class_weight)
class_weight = handle_class_imbalance(X_train,y_train)
# 训练SVM-RBF模型
svm_model = train_svm_rbf(X_train,y_train,class_weight)
# 评估模型
eval_metrics = evaluate_model(svm_model,X_test,y_test)
# 保存模型(供业务团队调用)
joblib.dump(svm_model,"model/svm_rbf_ticket_classifier.pkl")
# 记录MLflow实验
with mlfolw.start_fun(run_name="svm_rbf_ticket_classification"):
mlflow.log_param("kernel", "rbf")
mlflow.log_param("C", 10)
mlflow.log_param("gamma", 0.1)
mlflow.log_metric("f1_macro", eval_metrics["f1_macro"])
mlflow.sklearn.log_model(svm_model, "svm_rbf_model")
logger.info("模型训练完成,已保存至model/svm_rbf_ticket_classifier.pkl")
业务团队仓库(business-ticket-classification)
business-ticket-classification/
├── api_gateway/ # Kong API网关配置
│ ├── kong.yml # 路由规则(/classify转发至工单分类服务)
│ └── auth_plugin.lua # JWT认证插件
├── ticket_classification_service/ # 工单分类微服务(FastAPI)
│ ├── main.py # 服务入口(加载模型+Feast客户端)
│ ├── predictor.py # 核心预测逻辑(调用SVM模型+特征服务)
│ ├── schemas.py # 请求/响应模型(Pydantic)
│ └── requirements.txt # 依赖:fastapi, uvicorn, feast, joblib
├── monitoring/ # 监控配置
│ ├── prometheus_rules.yml # 告警规则(F1-score<0.9触发重训)
│ └── grafana_dashboards/ # 面板(API延迟、分类准确率、PSI)
└── deployment/ # K8s部署配置
├── svm-model-deployment.yaml # SVM模型服务Deployment
└── feast-service-deployment.yaml # Feast特征服务Deployment
工单分类服务(调用算法团队特征服务+模型,predictor.py)
import joblib
import pandas as pd
from feast import FeatureStore # 调用算法团队的Feast特征服务
from pydantic import BaseModel # 请求、响应模型
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# 1.定义请求、响应模型
class TicketRequest(BaseModel):
ticket_id: str # 工单ID(业务系统生成,唯一标识)
content: str # 工单内容(非结构化文本)
user_id: str # 用户ID(用于获取历史工单特征)
submit_time: str # 提交时间(ISO格式)
class ClassificationResponse(BaseModel):
ticket_id: str
predicted_department: str # 预测部门ID(如DEP01)
confidence: float # 预测置信度(0-1)
key_keywords: list[str] # 关键匹配关键词(如["破损", "换货"])
timestamp: str
class TicketClassifier:
def __init__(self,model_path:str,feast_repo_path:str,feast_registry_url:str):
"""初始化:加载算法团队的SVM模型和Feast特征服务客户端"""
# 加载SVM模型(算法团队输出的joblib文件)
self.model = joblib.load(model_path)
#连接算法团队部署的Feast服务(gRPC地址,K8s内部域名)
self.feature_store = FeatureStore(
repo_path=feast_repo_path, # 本地特征仓库(开发用),生产用远程registry
registry=feast_registry_url # 算法团队Feast注册表URL(如http://feast-registry:8080)
)
logger.info("工单分类器初始化完成:模型加载成功,Feast服务连接成功")
def extract_keywords(self,content:str) -> list[str]:
"""结巴分词+关键词提取(复用算法团队的特征工程逻辑)"""
import jieba
from feature_engineering.text_processing import load_stopwords # 算法团队提供的停用词表
stopwords = load_stopwords()
words = jieba.cut(content) # 结巴分词(精确模式)
keywords = [word for word in words if word not in stopwords and len(word) > 1]
return keywords[:5] # 取前5个关键词(业务测展示用)
def get_realtime_features(self,ticket_id:str,user_id:str)->pd.DataFrame:
"""调用算法团队的Feast特征服务,获取实时特征(在线特征)"""
feature_refs = [
"word_count", "stopword_ratio", "keyword_match_count",
"user_ticket_freq_1m", "submit_hour_risk"
]
# 从Feast获取实时特征(实体:ticket_id,关联user_id)
# 注:Feast支持多实体,此处简化为ticket_id,实际可加user_id作为实体
feature_vector = self.feature_store.get_online_features(
entity_rows=[{"ticket_id": ticket_id}], # 实体行(工单ID)
features=feature_refs # 特征引用列表
).to_dict() # 转为字典:{feature_name: [value]}
return pd.DataFrame(feature_vector)
def predict(self,request:TicketRequest)->ClassificationResponse:
"""核心预测逻辑:融合实时特征+模型预测"""
try:
# 1.提取工单内容关键词(结巴分词+停用词过滤,复用算法团队逻辑)
key_keywords = self.extract_keywords(request.content)
# 2.调用Feast特征服务,并获取实时特征(算法团队维护的在线特征)
realtime_features = self.get_realtime_features(
ticket_id = request.ticket_id,
user_id = request.user_id
)
if realtime_features.empty:
raise ValueError(f"Feast服务未找到ticket_id={request.ticket_id}的特征")
# 3.构造TF-IDF特征(实时计算,因工单内容是最新文本)
from feature_engineering.tfidf_vectorizer import vectorize_text # 算法团队提供的TF-IDF向量化函数
tfidf_vector = vectorize_text([request.content]) # 输入文本列表,输出稀疏向量
# 合并特征(TF-IDF向量+实时统计特征)
from scipy.sparse import hstack
X = hstack([tfidf_vector, realtime_features.values])
# 5.调用SVM-RBF模型预测部门和置信度
predicted_dept_idx = self.model.predict(X)[0] # 预测部门索引
dept_mapping = self.model.classes_ #部门ID列表如["DEP01", "DEP02", ...])
predicted_department = dept_mapping[predicted_dept_idx]
confidence = self.model.predict_proba(X)[0][predicted_dept_idx] # 置信度(最高类概率)
# 6. 构造响应
return ClassificationResponse(
ticket_id=request.ticket_id,
predicted_department=predicted_department,
confidence=round(confidence, 4),
key_keywords=key_keywords,
timestamp=pd.Timestamp.now().isoformat()
)
except Exception as e:
logger.error(f"预测失败:ticket_id={request.ticket_id}, 错误={str(e)}", exc_info=True)
raise
部署后应用
Step 1:工单提交时实时分类
客服系统(如Zendesk)通过Webhook调用业务团队API网关:POST https://api.ecom.com/ticket/classify
请求体(TicketRequest):
{
"ticket_id": "TK20231001",
"content": "订单20231001,物流显示已签收但未收到,联系快递员电话不通",
"user_id": "U123",
"submit_time": "2023-10-02T10:30:00"
}
Step 2:API处理与响应
工单分类服务调用TicketClassifier.predict(),内部流程:
- 结巴分词+停用词过滤提取关键词(如“物流”“签收”“未收到”)
- 调用Feast服务获取实时特征(如用户近1月工单数=2,提交时间10:30→非夜间=0)
- 构造TF-IDF特征(基于“物流”“快递员”等词权重)
- SVM-RBF模型预测部门(物流部,DEP02),置信度0.95
响应体(ClassificationResponse):
{
"ticket_id": "TK20231001",
"predicted_department": "DEP02",
"confidence": 0.95,
"key_keywords": ["物流", "签收", "未收到", "快递员"],
"timestamp": "2023-10-02T10:30:05"
}
Step 3:工单自动分配与监控
客服系统根据predicted_department自动分配至对应部门队列(如物流部),并在工单看板标注置信度(<0.7时标黄,需人工复核)
监控系统(Grafana)实时展示分类准确率、PSI(特征分布漂移)、API错误率,若PSI>0.25(数据分布变化),自动触发模型重训(Airflow调度算法团队重训流程)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 34
34 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)