PaperBanana:AI科研人员画图终于不用头疼了
下午刷到这篇PaperBanana的论文,讲真,这个方向确实戳中了AI科研圈的痛点。写论文最头疼的是什么?不是跑实验,不是调参数,而是画那些方法示意图和统计图表。每次到这个环节,PPT、Visio、Python matplotlib轮番上阵,改来改去,最后还是觉得不够professional。这次北大和谷歌的团队直接放大招,搞了个框架,专门解决学术插图自动化生成的问题。看完之后,第一反应是:这玩意
下午刷到这篇PaperBanana的论文,讲真,这个方向确实戳中了AI科研圈的痛点。写论文最头疼的是什么?不是跑实验,不是调参数,而是画那些方法示意图和统计图表。每次到这个环节,PPT、Visio、Python matplotlib轮番上阵,改来改去,最后还是觉得不够professional。
这次北大和谷歌的团队直接放大招,搞了个PaperBanana框架,专门解决学术插图自动化生成的问题。看完之后,第一反应是:这玩意要是早出来,当年毕业论文能省多少时间啊。

作者阵容:朱大伟(北大&谷歌)、孟睿(谷歌)、Yale Song(谷歌)、魏熙雨(北大)、李素建(北大)、Tomas Pfister(谷歌)、尹镇成(谷歌)
- 论文传送门:https://arxiv.org/abs/2601.23265
- GitHub代码]:https://github.com/dwzhu-pku/PaperBanana
- Twitter讨论:https://x.com/dwzhu128/status/2018405593976103010
先看效果,直接上图
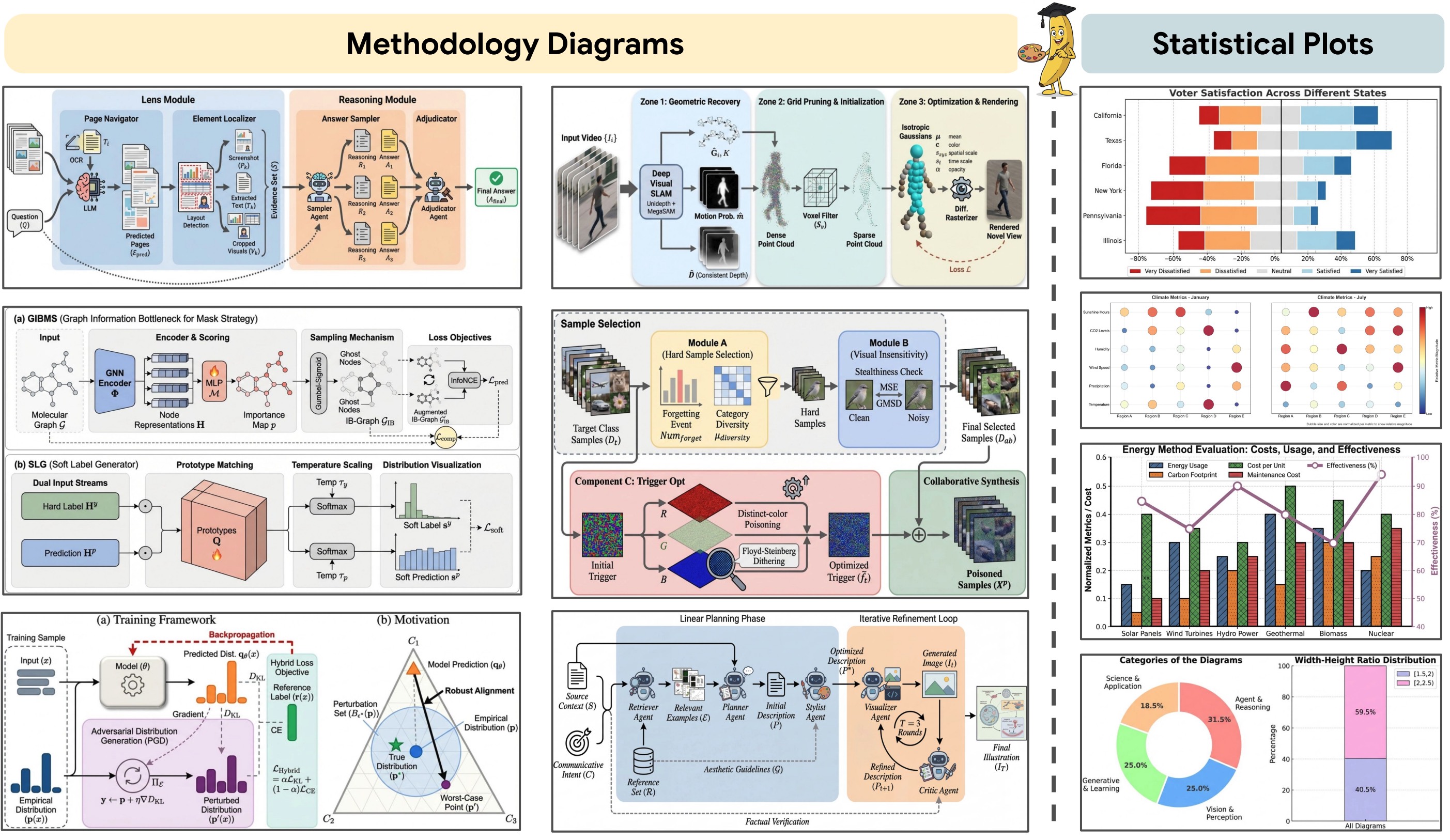
上面这些方法论示意图和统计图,全是PaperBanana自动生成的,质量已经达到发表级别了
为啥需要这个东西
现在AI科学家的自动化已经卷到飞起,写代码、跑实验、分析数据都有工具辅助,但画图这一块还是纯人工在硬刚。一张methodology diagram,从构思到最终定稿,少说也得折腾半天。改审稿意见的时候,图要重画,又是一轮折磨。
PaperBanana就是来解决这个问题的。团队把最新的视觉语言模型(VLM)和图像生成模型整合到一起,弄了个多智能体协同的框架,能自动完成从检索参考、规划内容、设计风格到生成图像、迭代优化的全流程。
更硬核的是,团队还专门构建了PaperBananaBench评测基准,从NeurIPS 2025论文里精选了292个方法示意图作为测试集,覆盖各种研究方向和插图风格。这下评估有标准了,不是自说自话。
实测结果也很能打,在准确性、简洁性、可读性、美观度四个维度上,全面吊打现有baseline。而且这套方法不只能画示意图,统计图表也能搞定。
系统架构:五个智能体分工协作
PaperBanana的核心是5个专业智能体的协同工作,每个agent各司其职。下面这张系统架构图,本身就是PaperBanana生成的(这波自举操作可以的)。
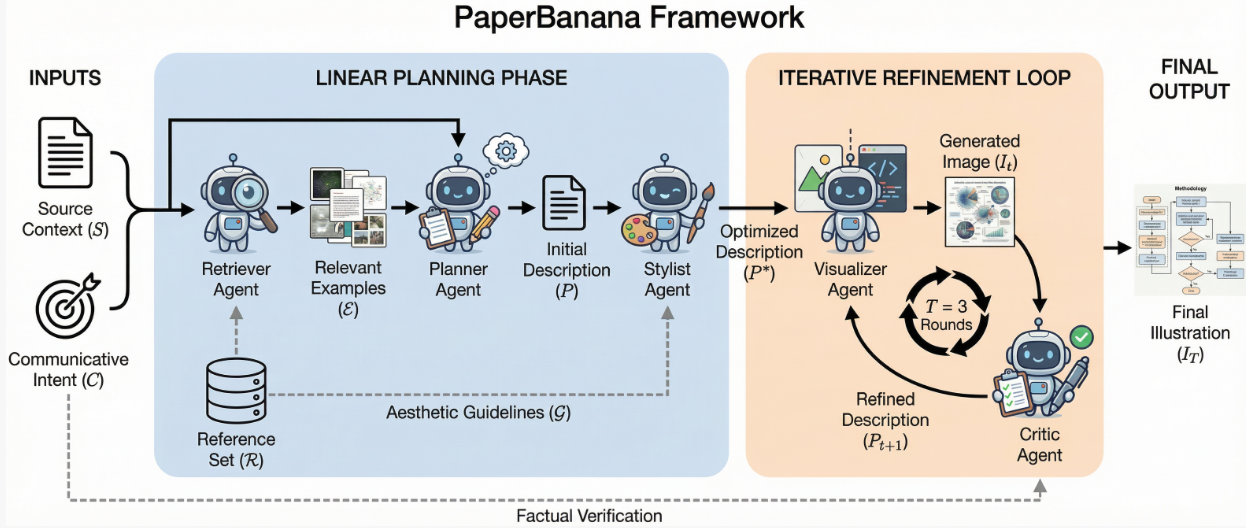
整个pipeline是这样的:
Retriever Agent(检索智能体):先去找相关的参考案例,给后面的智能体提供灵感和指导。这个很关键,有了参考才知道这个领域的图长啥样。
Planner Agent(规划智能体):充当大脑角色,把论文内容和图表caption转化成详细的文字描述。这一步决定了图要画什么、怎么组织。
Stylist Agent(风格智能体):从参考案例里提炼美学规范,保证生成的图符合学术审美。配色、字体、布局这些细节都要考虑到。
Visualizer Agent(可视化智能体):把文字描述真正转换成图像或者可执行代码。methodology diagram用图像生成,统计图表用代码生成,各取所长。
Critic Agent(评审智能体):生成完了不算完,还要跟原始内容对照检查,找问题给反馈,然后迭代优化。这个self-critique机制挺重要的,能明显提升质量。
PaperBananaBench:专门的评测基准
之前这个领域最大的问题是没有标准的benchmark,大家各说各话。团队这次从NeurIPS 2025的论文里筛选了584个高质量样本,一半做测试集,一半做参考集。
构建流程也很严谨:收集解析→过滤筛选→分类整理→人工审核,四道关卡下来,保证数据质量。
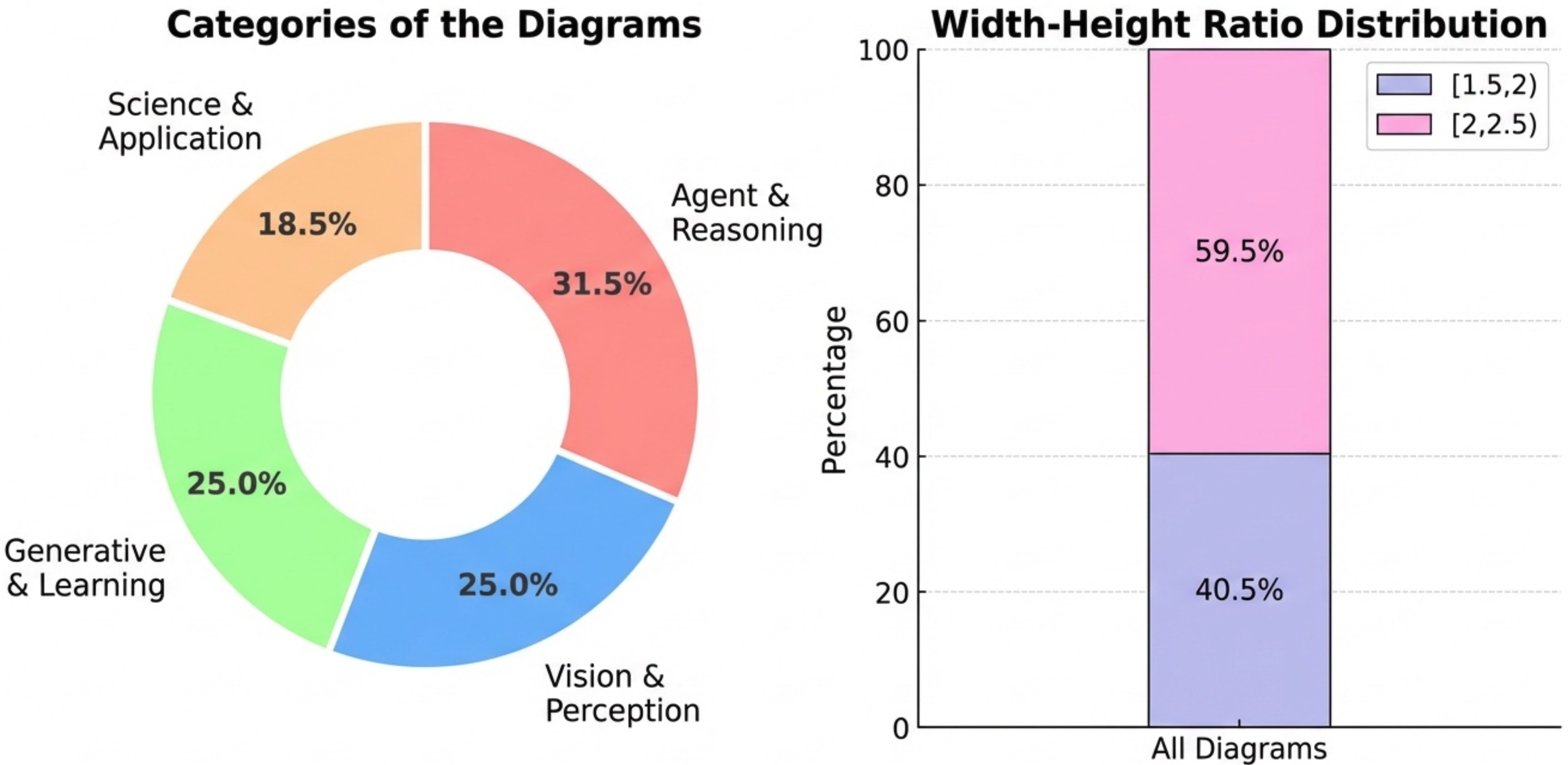
这张统计图也是PaperBanana生成的。测试集292个样本,平均源文本3020个词,图表caption平均70个词
从统计数据看,这个benchmark还是很有挑战性的。源文本平均3000多词,信息量大;图表类型多样,从简单的流程图到复杂的架构图都有。
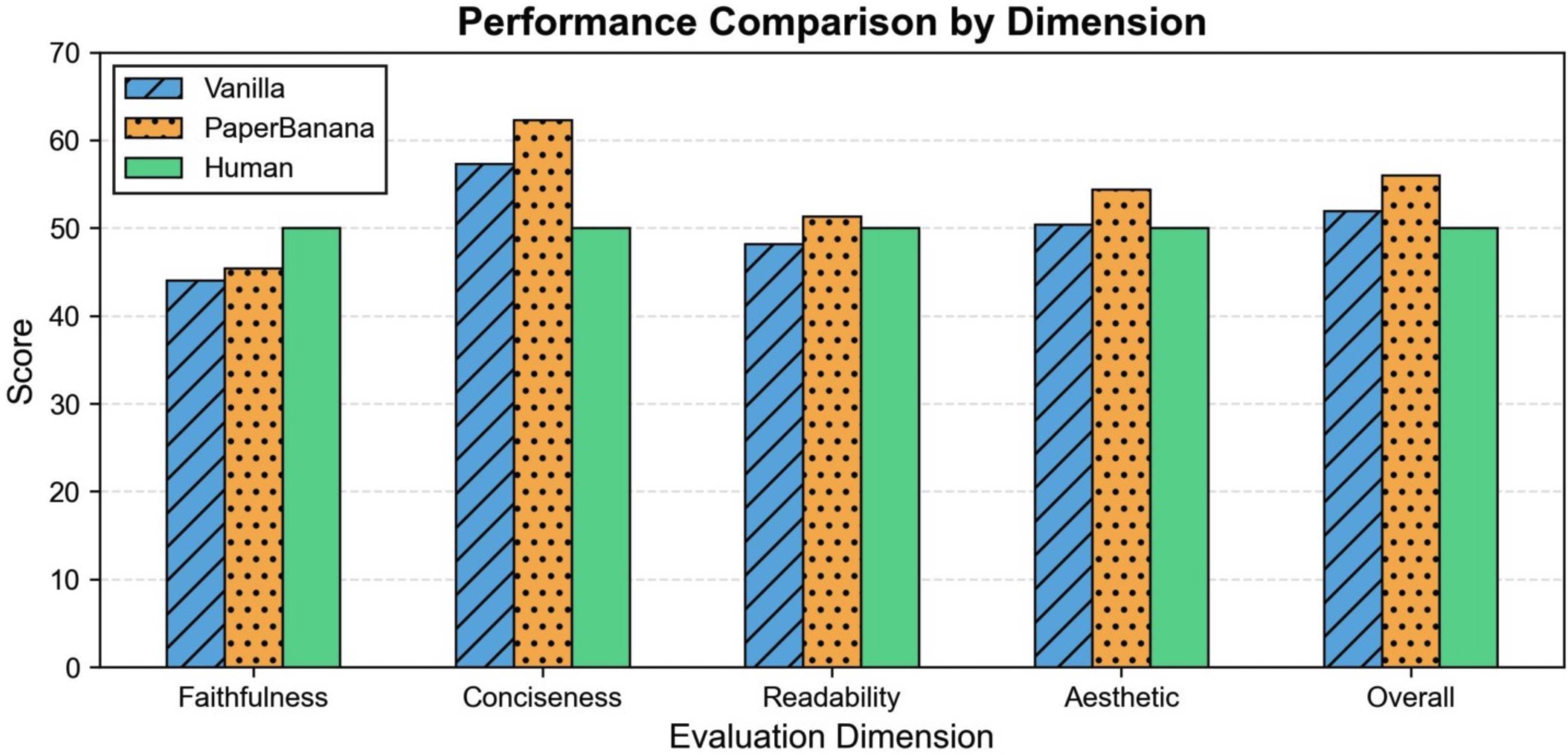
实测效果:全方位碾压baseline
团队在PaperBananaBench上做了完整评估,从四个维度打分:faithfulness(准确性)、conciseness(简洁性)、readability(可读性)、aesthetics(美观度)。
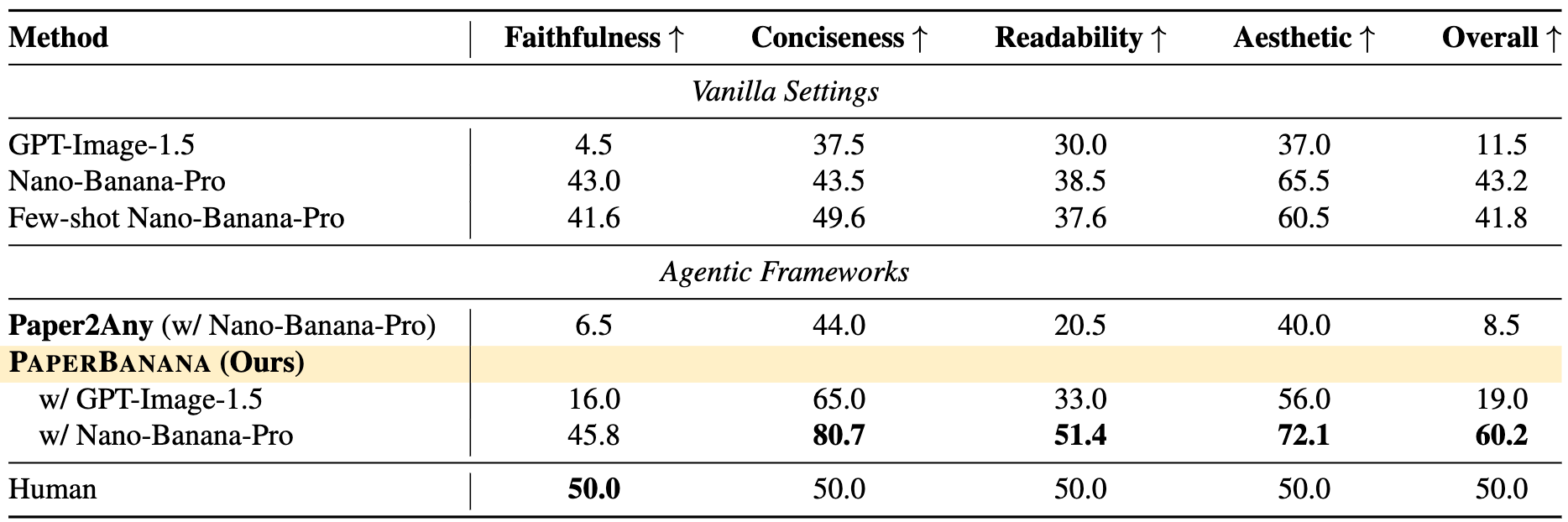
从榜单来看,PaperBanana在所有指标上都是第一梯队,相比vanilla baseline提升明显。特别是aesthetics这一项,毕竟有专门的Stylist Agent在把关。
统计图表生成这块也测了,效果同样能打。下面这张对比图本身就是PaperBanana根据原始数据生成的。
两个有意思的扩展应用
应用1:给人工画的图做美学升级
团队发现,PaperBanana提炼出来的美学guidelines不只能用来生成新图,还能用来改善现有的人工绘制图表。相当于有了一个"AI审美顾问"。
看这个case,原图功能是够了,但配色和排版比较朴素。用PaperBanana的style guidelines优化之后,整体视觉效果上了好几个档次。
应用2:代码生成 vs 图像生成,统计图该怎么做?
统计图表到底是用代码画(matplotlib/seaborn),还是直接让图像生成模型画?团队做了个对比实验。
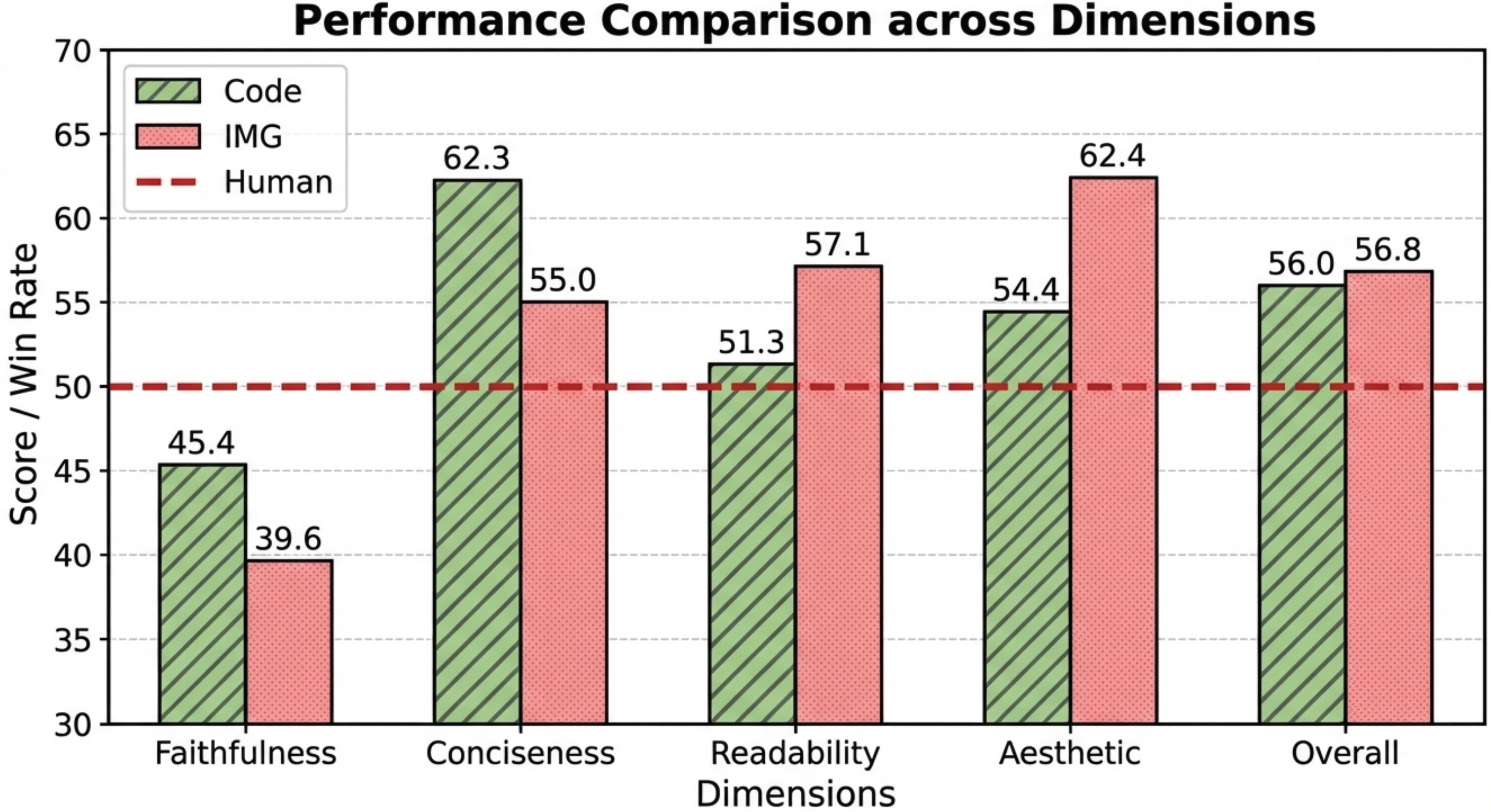
这张对比图也是PaperBanana生成的
结论挺明确:图像生成模型做出来的图更好看,但容易出现数值幻觉或者元素重复;代码生成的准确性更高,但视觉效果一般。各有权衡,看具体需求。
实战案例:直观感受差距
Methodology Diagram生成
给定相同的论文内容和caption,看看不同方法的生成效果。
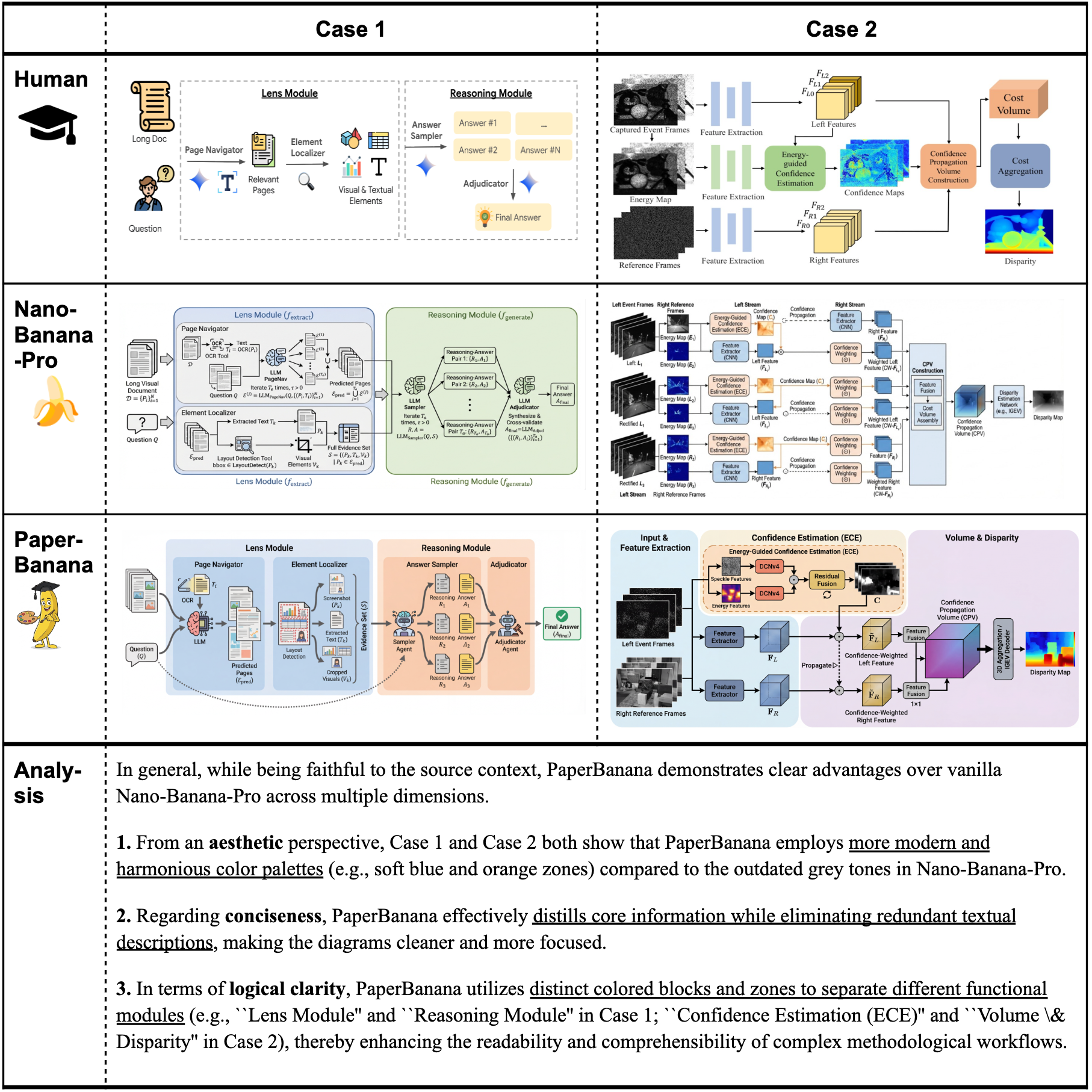
vanilla版本的Nano-Banana-Pro生成的图,配色老气,内容冗长,一看就是"AI味"很重。PaperBanana生成的图简洁清爽,配色现代,关键是准确表达了原文意思,这才是publication-ready的水平。
美学提升的更多案例
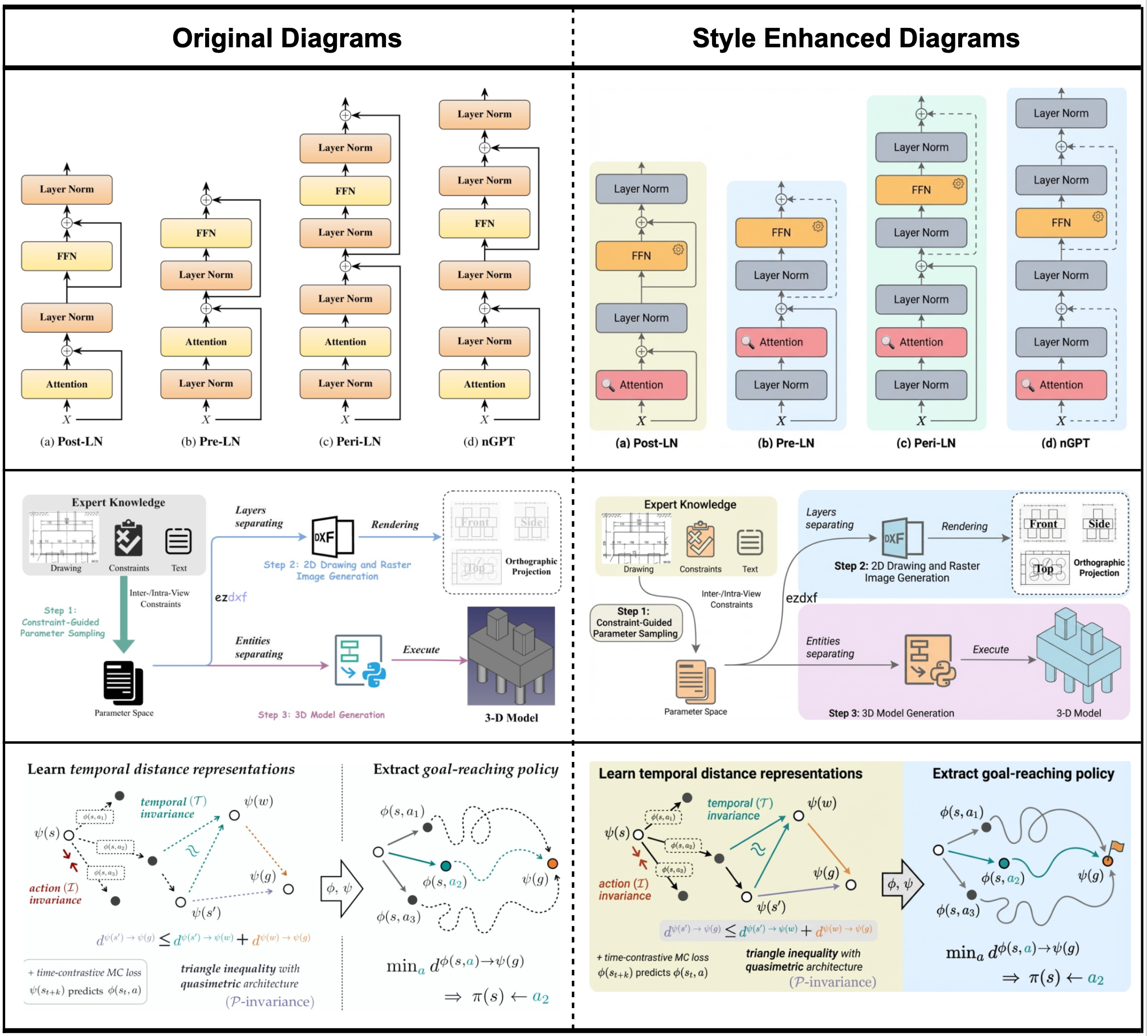
看这几组对比,原图都是能用的,但用style guidelines润色之后,配色、字体、图形元素都有明显改善,整体质感提升了。
统计图表:代码 vs 图像生成
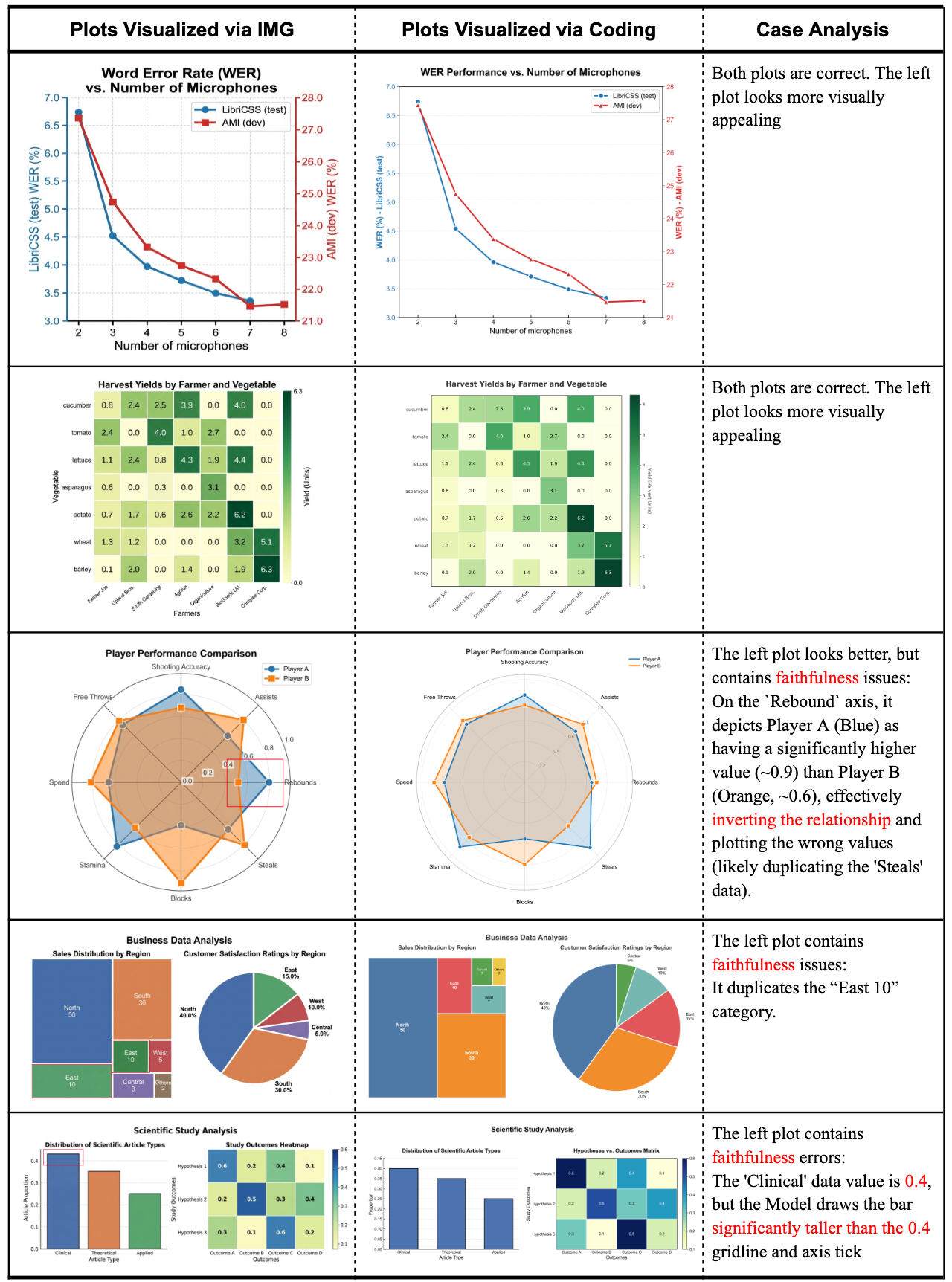
这个case很典型。图像生成的版本视觉效果确实更好,但仔细看会发现数值有偏差;代码生成的版本数据准确,但视觉上平淡一些。
也有翻车的时候
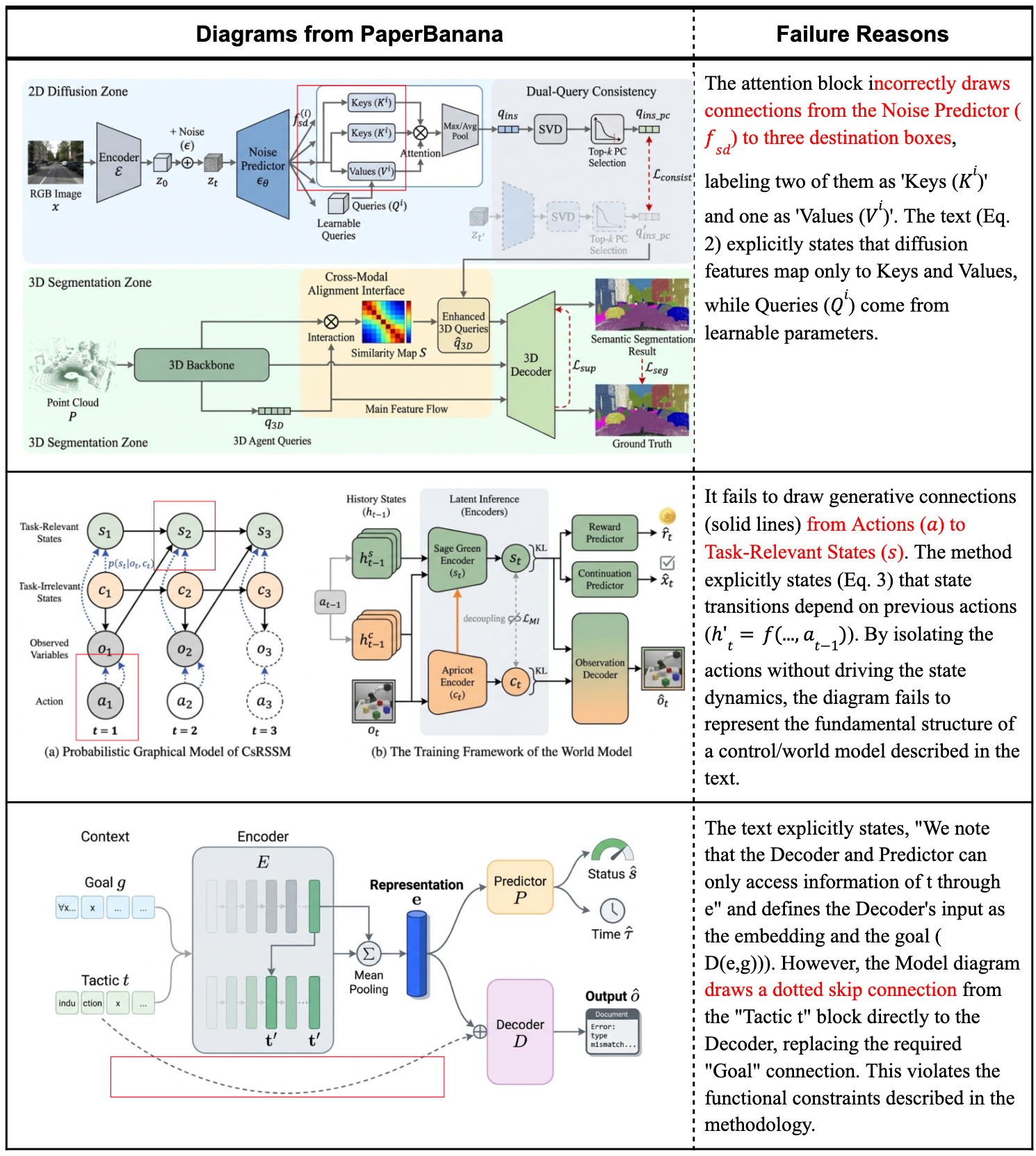
团队也很诚实,把failure cases放出来了。主要问题集中在连接错误上,比如节点之间的连线画错、连多了或者连少了。
初步分析发现,Critic Agent往往识别不出这类连接问题,说明这可能是底层模型感知能力的局限。这个问题确实棘手,因为连接关系是图表逻辑的核心,出错影响很大。
个人看法
看了论文效果,PaperBanana整体还是很能打的,成功率已经挺高了。对于科研人员来说,就算不能100%自动化,能帮忙生成初稿也能省不少时间。
特别喜欢它的multi-agent架构设计,每个agent职责清晰,可以单独优化。Critic Agent的self-critique机制也很实用,让生成质量有保障。
不过也要看到,这个方向还有提升空间。比如复杂的连接关系识别,还有一些领域特定的图表样式(比如生物信息学的pathway图),可能需要further fine-tuning。
另外,benchmark虽然是从NeurIPS论文里选的,但AI领域的插图风格相对统一,其他学科(比如物理、化学)的图表风格差异更大,泛化性还得继续验证。
总的来说,这个工作方向很实用,解决了真实痛点。代码已经开源了,感兴趣的可以去GitHub试试。说不定下次写论文,画图这个环节真就不用那么头疼了。
不过还没有完全开放,大家可以关注下:This is the repository for PaperBanana. Our code and dataset will be released in ~2 weeks.
PS:论文里那些图,很多都是PaperBanana自己生成的,这波self-hosting操作确实有意思。就像用自己训练的模型写自己的论文,AI做AI research的感觉越来越强了。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 24
24 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)