大模型AI知名应用对比:技术解析与实战洞察
本文对比分析了GPT-4、Claude3等六大主流AI模型的技术特性与应用表现。GPT-4以1.8万亿参数领跑,Claude3在数学推理和长文本处理方面表现突出,LLaMA3和BERT则更适用于轻量化部署和垂直场景。研究显示,大模型正向多模态融合、轻量化方向发展,但仍面临计算成本、伦理安全等挑战。未来大模型将与边缘计算结合,实现更广泛的应用落地。
引言
随着深度学习与预训练技术的突破,大模型AI正以前所未有的速度重塑产业格局。本文聚焦GPT-4、Claude 3、LLaMA 3、BERT、文心一言、通义千问六大主流模型,从技术参数、应用场景、性能表现三大维度展开深度对比,揭示各模型的技术特性与适用边界。
一、核心参数对比:规模与能力的量化博弈
1.1 参数规模与训练数据量
通过对比六大模型的参数规模与训练数据量,可直观反映其计算复杂度与知识储备差异:
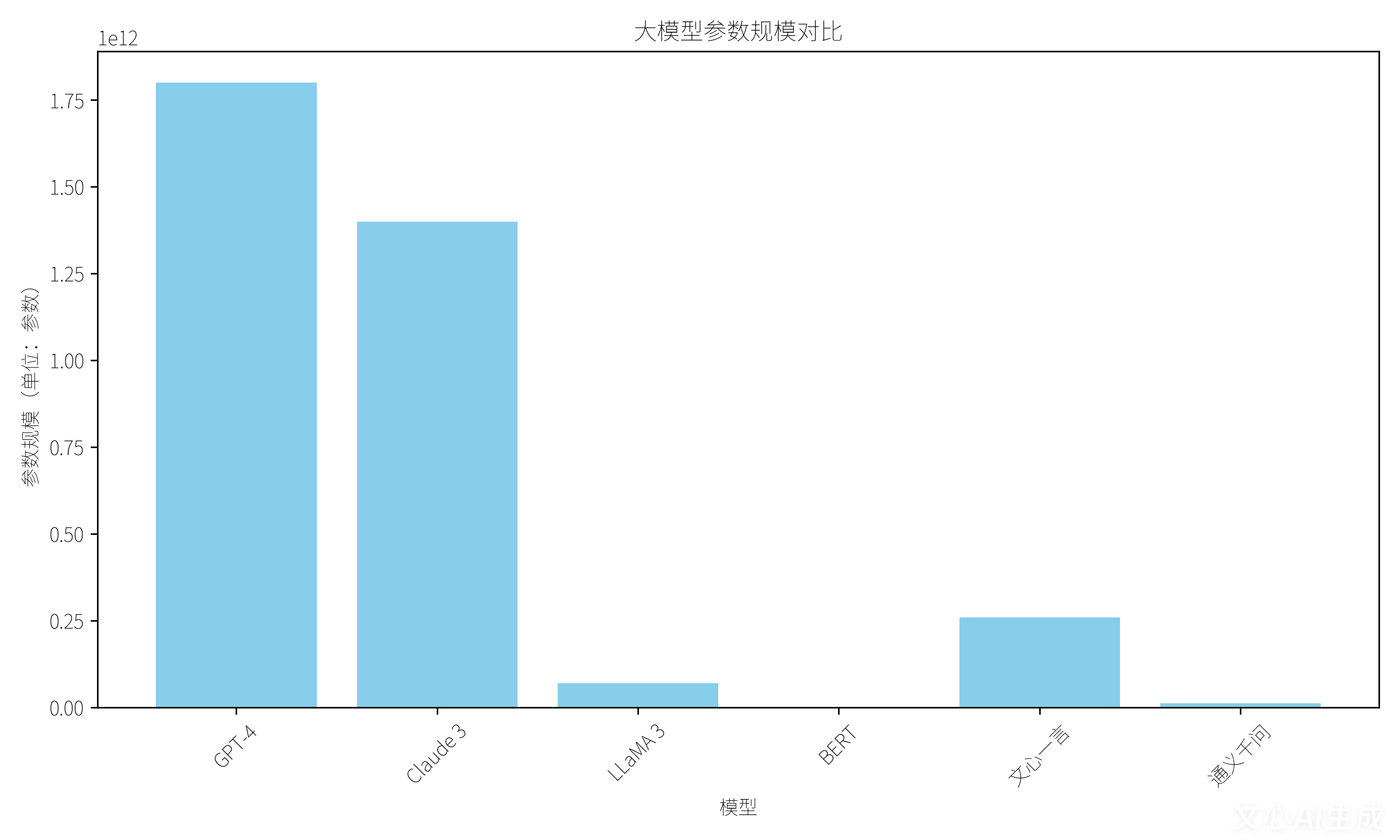
图1 参数规模对比:GPT-4以1.8万亿参数领跑,Claude 3紧随其后达1.4万亿,LLaMA 3以700亿参数实现轻量化部署,BERT则以1.1亿参数专注语义理解任务。
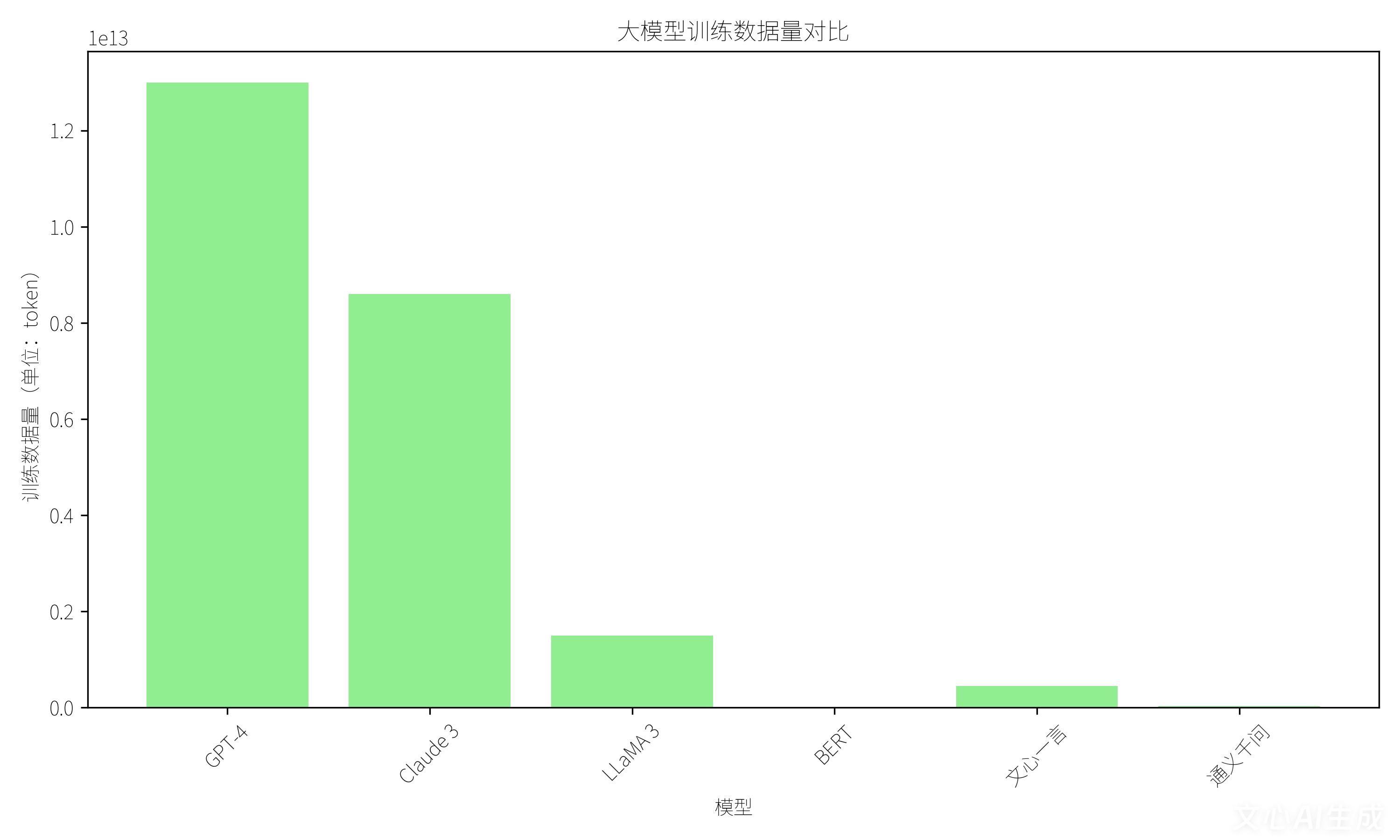
图2 训练数据量对比:GPT-4采用13万亿token训练数据,Claude 3通过8.6万亿token实现知识深度覆盖,LLaMA 3以1.5万亿token平衡性能与效率,BERT则聚焦33亿token实现高精度语义填空。
1.2 上下文长度与数学推理能力
上下文处理能力与数学推理性能直接决定模型在长文本分析与复杂计算任务中的表现:
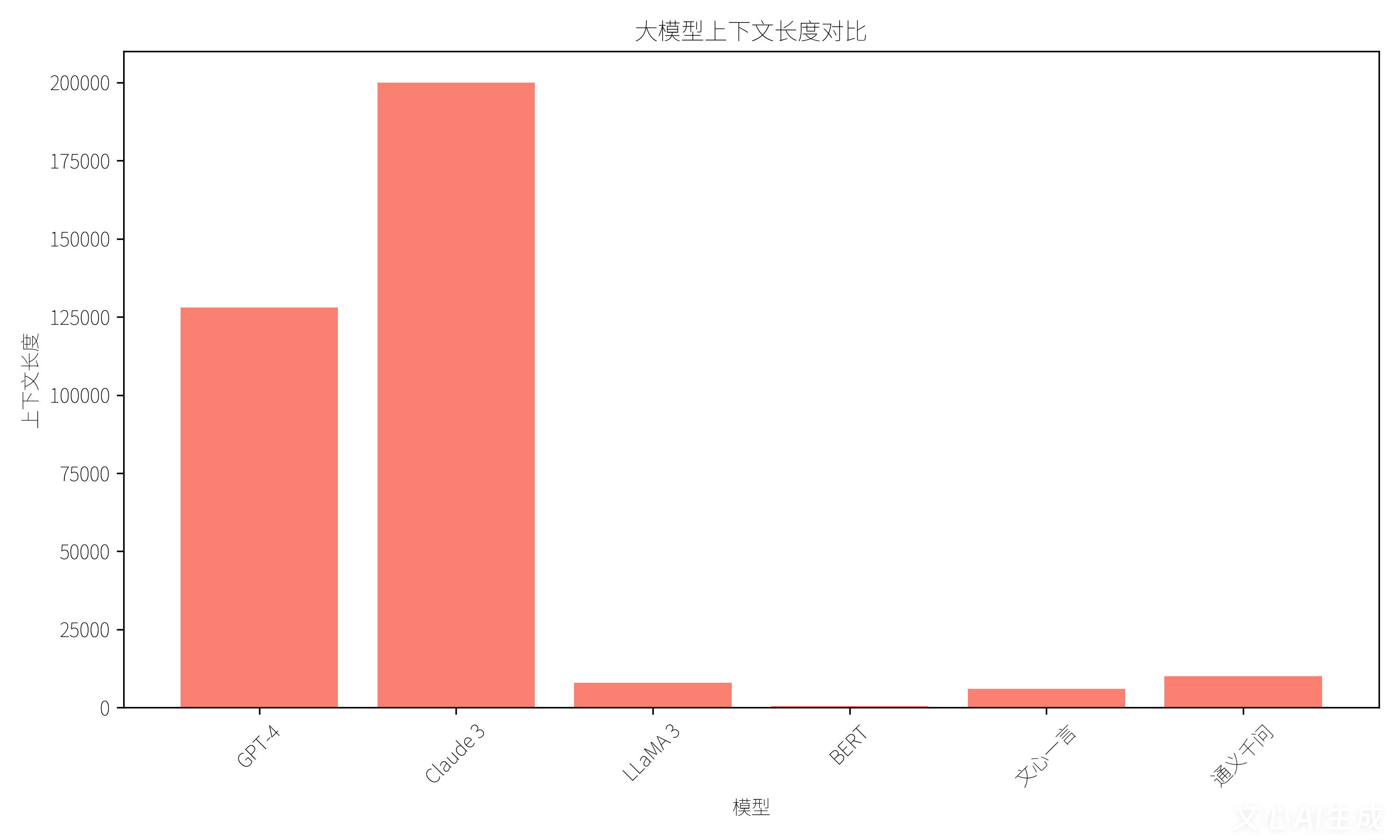
图3 上下文长度对比:Claude 3支持20万token超长上下文,GPT-4达12.8万token,LLaMA 3支持8000token,BERT专注512token短文本处理。
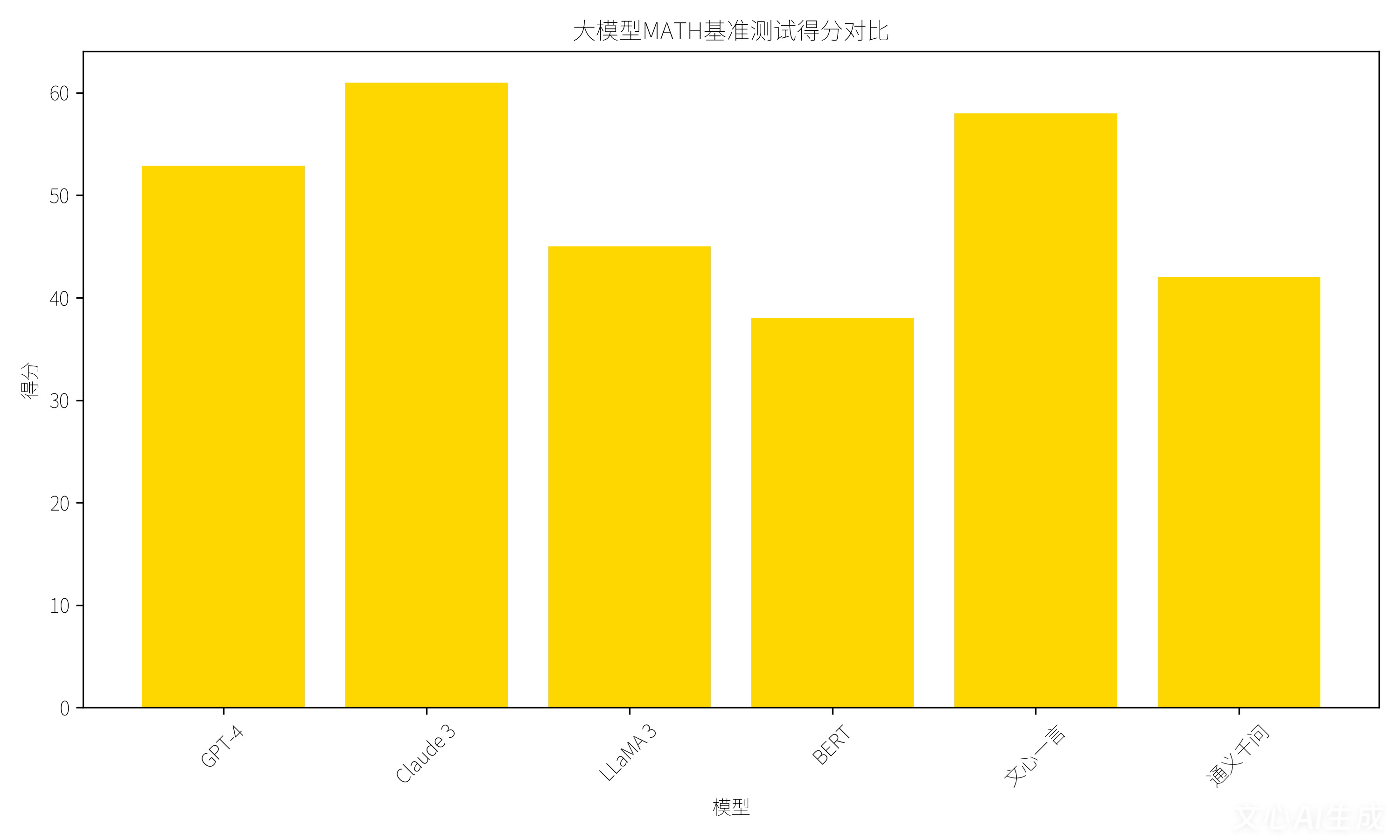
图4 MATH基准测试得分:Claude 3以61分领跑数学推理,GPT-4获52.9分,文心一言达58分,LLaMA 3获45分,BERT专注语义任务获38分。
二、应用场景:从通用生成到垂直专业
2.1 通用生成与多模态融合

图5 大模型应用场景示意图:大模型在智能客服、内容创作、代码生成等领域展现强大能力。GPT-4支持图像-文本跨模态生成,Claude 3实现PDF/图表端到端解析,文心一言完成视频分类与动态图像序列生成。
2.2 垂直领域专业应用
- 金融领域:通义千问构建SWOT分析框架,实现战略决策支持;容犀Copilot打造分期挽留助手,实时推荐应答话术。
- 医疗领域:文修大模型实现病历材料错敏校对,保障医疗文本准确性;DeepSeek通过8.6万亿token训练数据实现疾病预测与药物研发。
- 教育领域:LLaMA 3结合BERT实现成语补全与错别字纠正,通义千问生成个性化学习计划。
三、架构解析:从Transformer到多模态融合

图6 大模型架构示意图:主流大模型均基于Transformer架构,通过多头自注意力机制实现长距离依赖捕捉。GPT系列采用解码器-only架构,Claude 3集成视觉解析模块实现多模态输入处理,文心一言通过知识图谱增强事实性验证,BERT采用编码器架构专注语义理解任务。
四、技术趋势与挑战
4.1 发展趋势
- 模型轻量化:LLaMA 3通过700亿参数实现性能与效率平衡,BERT通过400MB模型体积支持边缘设备部署。
- 多模态融合:GPT-4V实现图像-文本跨模态理解,文心一言完成视频动态序列生成。
- 持续学习:DeepSeek通过每月15%行业报告更新实现知识保鲜,Claude 3支持在线增量训练。
4.2 核心挑战
- 计算资源消耗:GPT-4训练成本达数百万美元,推理需高端GPU支持。
- 伦理与安全:需通过内容过滤与伦理对齐机制保障输出安全性。
- 小样本适应:BERT通过领域自适应技术实现小样本场景高精度表现。
结论
大模型AI正朝着"更大、更强、更专业"的方向演进。GPT-4与Claude 3在通用生成与复杂推理领域表现卓越,LLaMA 3与BERT在轻量化部署与垂直场景中展现独特优势,文心一言与通义千问在多模态生成与企业服务领域实现创新突破。未来,大模型将与小模型协同工作,通过云端-边缘协同实现复杂任务处理与实时响应的平衡,推动AI技术在更多领域的深度应用与价值创造。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 10
10 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)