AI发展新范式:从规模扩张到效率密度优化的神经修剪革命
AI发展正经历从规模扩张到效率优化的范式转变,类似于人脑神经突触的修剪机制。研究表明,单纯增加参数规模已呈现边际效益递减,2025年行业开始转向稀疏激活、模型压缩和密度优化三大技术路径。这些方法借鉴人脑的高效连接机制,通过动态修剪冗余连接提升计算效率。尽管当前AI修剪仍依赖人工设计,与人脑自主调节存在本质差异,但这一转变正在重塑行业格局,推动AI向更可持续的方向发展。智能的本质或许不在于规模大小,
通过人脑的发展规律,设想AI发展的方向
前言
作为AI的初学者,希望通过费曼学习法,通过学习+输出文章或视频讲解的方式,事项快速学习。今天的第一篇文章,是我自己突然想到的一个问题,当然这个问题可能很多人都思考过了。我通过跟ai的问答,给出一个解答。
提示:以下是本篇文章正文内容,下面案例可供参考
一、通过人脑类比AI,我所想到的问题
人脑的使用率很低,很多神经元连接会在成年后根据环境选择断掉,只保留必要的神经元连接。ai的发展趋势是否也有类似规律,达到某一瓶颈后,并不是参数越多或连接越多越好。
二、通过与AI讨论得到的解答
AI发展新范式:从规模扩张到效率密度优化的神经修剪革命
2025年11月,当某科技巨头宣布其最新AI模型参数规模首次停止增长时,整个行业都屏住了呼吸。这个曾以"参数竞赛"为核心战略的公司,突然调转船头,将研发重点转向"效率密度优化"——这一幕像极了人类大脑从童年到成年的发育过程:不是神经元越多越好,而是精准修剪冗余连接,让每一份计算资源都产生最大价值。今天,我们就来深入探讨AI领域正在发生的这场"神经修剪革命"。
规模定律的黄昏:2025年的AI发展拐点
2018年至2024年间,AI模型参数规模呈现出惊人的增长曲线:从BERT的3.4亿参数,到GPT-3的1750亿,再到PaLM 2的5.4万亿,短短六年增长了160倍。但这条陡峭的上升线在2025年上半年出现了明显的斜率变化——根据斯坦福AI指数报告显示,模型性能提升与参数规模的正相关系数从2020年的0.92骤降至2025年Q1的0.37。
更令人警醒的是计算效率的断崖式下跌。OpenAI的内部测试数据显示,要使模型在MMLU基准上提升1%,2022年需要增加30%的参数规模,而到2024年底这个数字已经飙升至180%。"我们正在接近一个荒谬的临界点,"DeepMind首席科学家Demis Hassabis在2025年AI峰会上直言,“按照当前趋势,到2028年训练一个先进模型将消耗全球1%的电力。”
这种边际效益递减的背后,是对AI发展底层逻辑的误判。过去十年,行业沉迷于"越大越好"的简单线性思维,却忽视了一个基本生物学事实:人类大脑拥有约860亿个神经元,但真正活跃的连接只占15-20%。儿童时期过度生长的神经突触,会在青春期通过"修剪机制"保留最有效的连接——这不是退化,而是更高层次的进化。
AI的三大"神经修剪"技术路径
面对规模陷阱,AI研究正从三个维度构建新的"修剪"技术体系,这些方法虽然技术路径不同,但共同目标都是提升"效率密度"——即单位计算资源产生的智能输出。
稀疏激活技术正在重塑神经网络的工作方式。传统模型中,输入数据会激活几乎所有神经元,就像让整个大脑同时处理一个简单问题。而稀疏激活技术则通过动态路由机制,只激活与当前任务相关的神经元子集。DeepMind在2025年发布的SparseGPT模型采用了"注意力门控"机制,使激活神经元比例从100%降至平均8.7%,在保持性能不变的前提下,计算效率提升了11倍。更令人振奋的是,随着任务复杂度增加,这种稀疏性会动态调整——处理简单任务时激活5%神经元,面对复杂推理时则提升至22%,这种自适应机制与人脑的资源分配方式高度相似。
模型压缩技术则像是AI的"突触修剪手术"。其中最具代表性的量化技术,正从传统的INT8向更激进的INT4甚至二进制量化推进。NVIDIA在2025年推出的Hopper2架构支持的FP4混合精度计算,使模型存储需求降低75%,同时通过硬件级优化将推理速度提升3倍。另一个突破来自结构化剪枝领域,MIT团队开发的"神经外科医生"算法能够识别并移除冗余连接,在ImageNet数据集上,他们成功将ResNet-50的参数减少60%,而Top-1准确率仅下降0.8%。这些技术组合使用时效果更为惊人:Google将T5模型经过量化+剪枝+知识蒸馏三重压缩后,在移动设备上实现了实时运行,性能达到原始模型的92%,而资源消耗仅为原来的1/23。
密度法则代表了一种全新的设计哲学——不是事后修剪,而是从出生就构建高效网络。这一领域的先锋是2024年出现的"神经架构搜索"(NAS)技术,通过强化学习自动发现高效网络结构。华为诺亚实验室开发的AutoSparse架构在CIFAR-100数据集上超越了人工设计的ResNeXt,参数却减少72%。更具革命性的是"神经可塑性"模型,这类系统能像人脑一样随着使用不断调整连接强度,DeepMind的Plasticine模型在持续学习任务中,通过动态调整突触权重,将灾难性遗忘率降低了83%,这种"用进废退"的特性,正是生物神经系统的核心优势。
人脑与AI修剪机制的本质差异
尽管AI的"神经修剪"借鉴了脑科学启发,但两者在本质上存在着深刻差异,理解这些差异或许是突破AGI瓶颈的关键。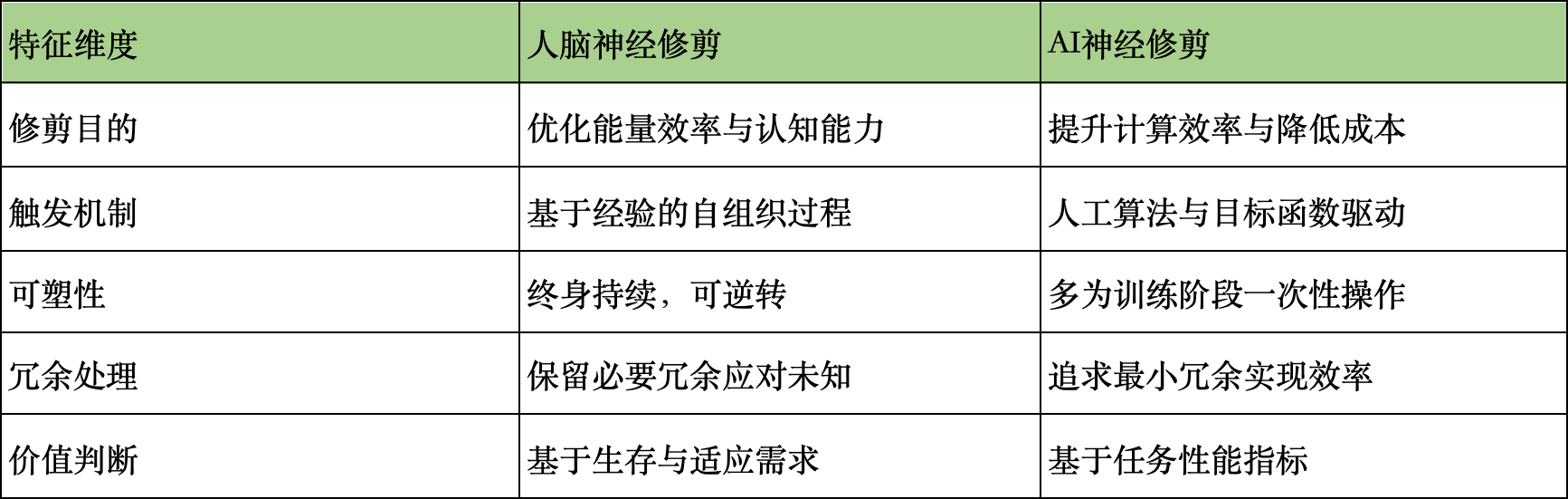
最根本的差异在于修剪的"自主性"。人脑的突触修剪是一个自组织过程,受到环境刺激、学习经验和内在需求的动态调节,没有预设目标却能涌现出复杂智能。而当前AI的修剪则完全依赖人工设计的目标函数和评价指标,本质上是一种"自上而下"的优化。这导致AI系统往往在特定任务上表现出色,却缺乏人脑那种"无用之用"的冗余美感——那些看似"浪费"的神经连接,恰恰是创造力和跨领域迁移能力的源泉。
另一个关键区别在于时间维度。人脑的修剪贯穿整个生命周期,儿童期大量修剪,成年后仍保持动态调整,这种持续可塑性使人能够终身学习。而AI系统的修剪大多发生在训练阶段,部署后便基本固定,难以像人脑一样通过持续使用来优化连接结构。不过,最新的"在线修剪"研究正在尝试突破这一限制,Google DeepMind在2025年提出的"终身修剪"框架,使模型能够在部署后根据实际数据分布持续优化连接结构,这一进展缩小了AI与生物智能在动态适应能力上的差距。
行业范式转移:从规模竞赛到效率革命
这场效率革命正在重塑AI行业的竞争格局和价值链条。2025年第二季度,全球AI芯片市场出现了一个值得玩味的数据:传统通用GPU的销量同比下降12%,而专为稀疏计算优化的专用ASIC芯片销量增长了210%。这种结构性变化背后,是行业价值评估体系的根本转变——过去投资者关注模型参数规模和算力投入,现在则更看重"每瓦性能"和"单位数据效率"。
初创公司正在这个新赛道上获得前所未有的机会。专注于模型压缩技术的SparseTech在2025年完成B轮融资,估值达到12亿美元,其核心产品能将LLM模型压缩至原来的1/10而保持95%性能。更具颠覆性的是效率优先的新型AI公司,如仅30人团队的NexusAI,凭借其独创的"神经密度优化"技术,在医疗影像分析任务上超越了Google Health的模型,而计算成本仅为后者的1/20。
大型科技公司也在加速转型。Meta在2025年开发者大会上宣布"效率优先"战略,将模型效率指标纳入工程师KPI;Google则重组了其AI研究部门,将原本独立的"规模研究组"与"效率研究组"合并,强调两者协同创新。这种转变不仅是技术路线的调整,更是组织文化的重塑——当"用更少做更多"成为行业共识,AI发展将进入更可持续的新阶段。
教育体系也在响应这场变革。斯坦福大学在2025年秋季首次开设"神经效率设计"课程,MIT则将"稀疏计算"纳入计算机科学核心课程。这种人才培养的转向,预示着效率优化将成为未来AI工程师的核心能力。
AGI的通关密钥:向人脑学习"智能密度"
当我们站在2026年的门槛回望,AI发展正来到一个关键的十字路口。参数规模竞赛的时代已经结束,效率密度优化的新篇章刚刚开启。但要真正接近通用人工智能(AGI),我们或许需要更深刻地理解人脑的"智能密度"本质——不是神经元的数量,也不是连接的多少,而是系统整体的"协同效率"。
人脑的神奇之处在于其"小世界网络"特性:局部高度聚类,全局又保持短路径连接。这种结构使大脑能以极低的能量消耗实现高效信息处理——仅20瓦功率,却能完成超级计算机需要兆瓦级能耗才能实现的复杂认知任务。最新研究表明,人脑的信息处理效率是当前最先进AI系统的100万倍以上,这种差距主要来自于我们对"智能本质"的理解还停留在表面。
未来的AI系统可能需要融合三大要素:生物启发的动态修剪机制、自组织的网络结构演化,以及基于环境交互的价值学习。DeepMind在2025年底发布的"ProtoAGI"系统首次尝试整合这些要素,其核心不是固定的网络结构,而是一套"修剪规则"和"生长规则",使系统能够根据经验自主优化连接网络。初步测试显示,该系统在跨领域学习任务上的表现超越了传统模型,而资源消耗降低了85%。
结语:智能的本质是减法而非加法
从孩童时期过度生长的神经网络,到成年后精准高效的神经连接;从AI领域疯狂的参数竞赛,到如今的效率密度革命——这条发展路径揭示了一个深刻道理:智能的进化往往不是加法,而是减法。不是拥有更多,而是精简到本质。
当我们思考AGI的未来时,或许应该少关注"多大规模",多思考"如何精准";少追求"无所不能",多探索"如何高效"。人脑通过数百万年进化形成的神经修剪机制,不仅是生物适应环境的智慧,也可能是AI突破当前瓶颈的关键。
最后,留给大家一个值得深思的问题:如果智能的本质是高效而非规模,那么我们衡量AI进步的标准是否从一开始就错了?当我们放弃参数崇拜,真正开始理解"少即是多"的智能哲学时,AGI的曙光是否就会出现在眼前?这个问题的答案,或许将决定未来十年AI发展的方向。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)