Ollama 本地部署编程大模型 + Zed 编辑器配置指南
隐私顾虑:核心业务逻辑或涉密代码不便上传云端。网络延迟:即时补全对延迟要求极高,网络波动影响体验。成本问题:长期订阅费用是一笔开支。Ollama作为目前最流行的本地大模型运行工具,极大简化了部署流程。配合Zed这款基于 Rust 开发、主打极致性能的编辑器,我们可以在消费级硬件上搭建一套完全免费、离线可用的结对编程环境。通过的组合,我们构建了一个零成本、低延迟、高隐私的本地 AI 编程环境。
摘要:在日常编程中,本地部署 AI 助手不仅能保护代码隐私,还能在无网环境下提供低延迟的代码补全和重构服务。本文将介绍轻量级推理框架 Ollama 的安装,推荐目前开源界第一梯队的编程专用模型(Coding LLMs),并详细演示如何将其接入高性能编辑器 Zed,构建高效的本地开发环境。
关键词:Ollama, Zed Editor, DeepSeek-Coder-V2, Qwen2.5-Coder, 本地AI编程
一、 前言:为什么选择本地编程助手?
对于开发者而言,Copilot 等云端服务虽然强大,但存在以下痛点:
- 隐私顾虑:核心业务逻辑或涉密代码不便上传云端。
- 网络延迟:即时补全对延迟要求极高,网络波动影响体验。
- 成本问题:长期订阅费用是一笔开支。
Ollama 作为目前最流行的本地大模型运行工具,极大简化了部署流程。配合 Zed 这款基于 Rust 开发、主打极致性能的编辑器,我们可以在消费级硬件上搭建一套完全免费、离线可用的结对编程环境。
二、 环境准备与 Ollama 安装
Ollama 对硬件有一定要求,运行 7B 参数模型建议至少拥有 8GB 内存(或 6GB 显存),运行 14B-32B 模型建议 16GB 以上内存(或 12GB+ 显存)。
1. 下载与安装
-
macOS / Linux:
打开终端,执行官方一键安装脚本:curl -fsSL https://ollama.com/install.sh | sh也可以修正systemd的启动脚本,保证服务在局域网监听OLLAMA_HOST,类似如下:
[Unit] Description=Ollama Service After=network-online.target [Service] ExecStart=/usr/local/bin/ollama serve User=ollama Group=ollama Restart=always RestartSec=3 Environment="PATH=/usr/local/bin:/usr/bin:/bin:/usr/games:/usr/local/go/bin" Environment="OLLAMA_HOST=0.0.0.0" [Install] WantedBy=default.target配置完成之后,使用如下命令重新启动或reload配置
# restart sudo systemctl restart ollama # 查看状态 ➜ ~ sudo systemctl status ollama ● ollama.service - Ollama Service Loaded: loaded (/etc/systemd/system/ollama.service; enabled; preset: enabled) Active: active (running) since Fri 2026-01-16 14:34:10 CST; 3 weeks 0 days ago Main PID: 2686061 (ollama) Tasks: 55 (limit: 52943) Memory: 6.6G CPU: 1d 14h 14min 45.100s CGroup: /system.slice/ollama.service ├─2686061 /usr/local/bin/ollama serve └─2970526 /usr/local/bin/ollama runner --model /usr/share/ollama/.ollama/models/blobs/sha256-60e05f2100071479f596b964f89f510f057ce397ea22f2833a0cfe029bfc2463 --port 40991 ... -
Windows:
请直接访问官网下载安装包:https://ollama.com/download/windows
2. 验证服务状态
安装完成后,在终端输入以下命令,确认服务已启动且版本正常:
ollama --version
# 输出示例: ollama version is 0.5.x
若服务未启动,可手动运行 ollama serve。
三、 编程模型推荐 (Coding LLMs)
模型更新迭代极快,截至目前,以下几款模型在代码生成(Code Generation)、代码补全(In-fill)和逻辑推理方面表现优异,且适合本地部署。
1. 首推:DeepSeek Coder V2 (深度求索)
特点:国产开源模型的里程碑,专门针对代码和数学进行了强化。V2 版本采用了 MoE(混合专家)架构,在保持推理速度的同时,代码理解能力大幅提升,支持 300+ 种编程语言。
- 适用场景:复杂的算法实现、代码重构、Bug 修复。
- 部署命令:
# 推荐:Lite版本 (约16B总参数,激活参数较小,适合16G+内存) ollama pull deepseek-coder-v2 # 配置受限用户:V1的 6.7B 版本依然很能打 ollama pull deepseek-coder:6.7b
2. 综合最强:Qwen 2.5 Coder (通义千问)
特点:阿里巴巴开源的最新一代代码模型。在 HumanEval 等基准测试中表现亮眼,指令遵循能力极强,中文注释和文档理解能力是所有模型中最好的。
- 适用场景:日常业务代码编写、中文技术文档阅读辅助。
- 部署命令:
# 7B 版本 (适合 8G-16G 内存,速度快) ollama pull qwen2.5-coder:7b # 1.5B/3B 版本 (适合低配笔记本或后台常驻) ollama pull qwen2.5-coder:1.5b
3. 稳健基座:Llama 3.1
特点:Meta 的开源基座模型。虽然不是专门为代码微调(Instruct),但凭借强大的通用逻辑推理能力,在处理复杂的系统架构设计或多轮技术对话时表现稳定。
- 适用场景:技术方案咨询、架构设计讨论。
- 部署命令:
ollama pull llama3.1
4. 极客选择:Mistral / Codestral
特点:欧洲团队 Mistral AI 出品,以“参数小、性能强”著称,生成的代码风格简洁,上下文窗口利用率高。
- 部署命令:
ollama pull mistral
四、 实战:接入 Zed 编辑器
Zed 编辑器原生支持 AI 辅助编程,且对 Ollama 的支持已经非常成熟。
步骤 1:准备模型
确保你已经 Pull 了需要的模型,例如我们使用 qwen2.5-coder 作为主力:
ollama pull qwen2.5-coder
步骤 2:配置 Zed (settings.json)
- 打开 Zed。
- 使用快捷键
Cmd/Ctrl + ,打开设置页面。 - 在用户设置(User Settings)中,添加或修改
assistant和language_models字段。
推荐配置如下:
{
"assistant": {
"default_model": {
"provider": "ollama",
"model": "qwen2.5-coder:latest"
},
"version": "2"
},
"language_models": {
"ollama": {
"api_url": "http://localhost:11434",
"available_models": [
{
"name": "qwen2.5-coder:latest",
"max_tokens": 16384 // 根据显存情况调整
},
{
"name": "deepseek-coder-v2:latest",
"max_tokens": 16384
}
]
}
}
}
注意:如果不手动指定
available_models,Zed 也会尝试自动读取 Ollama 中的模型列表,但手动指定可以避免一些识别错误。
opt: 也可以界面配置如下:
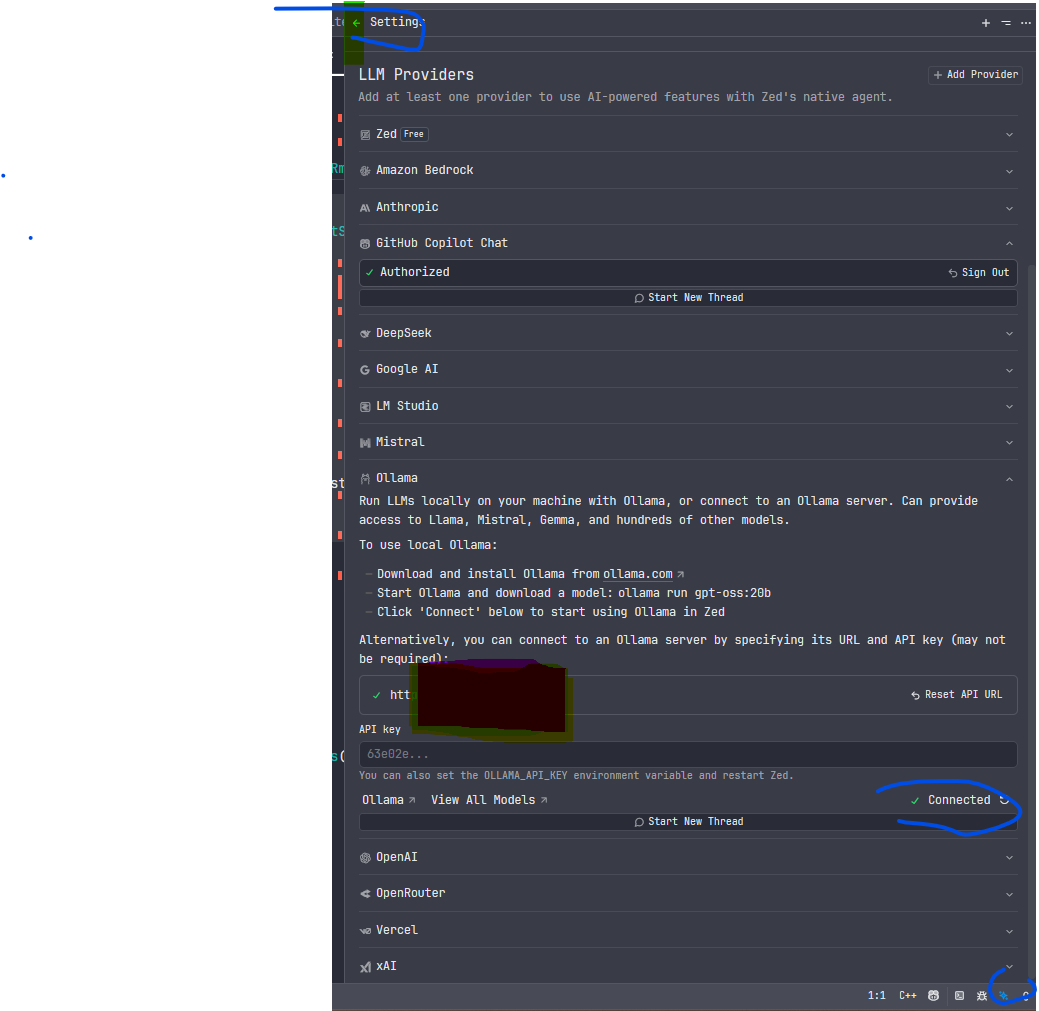
步骤 3:使用体验
配置完成后,有两种主要使用方式: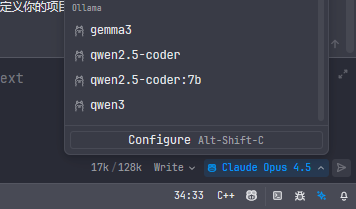
-
Assistant Panel (右侧对话栏):
- 用途:像和 ChatGPT 聊天一样,询问代码逻辑、生成样板代码或解释报错信息。
- Tip:在输入框中输入
/file可以引用当前项目中的文件作为上下文。
-
Inline Assist (行内生成的):
- 用途:直接在代码文件中让 AI 重写函数、添加注释或生成代码块。
五、 常见问题排查
-
Zed 提示 Connection Refused:
- 检查 Ollama 是否在运行 (
ollama ps)。 - 检查是否修改了 Ollama 的默认端口(11434)。
- 如果是 Windows/WSL 环境,确保 localhost 网络转发正常。
- 检查 Ollama 是否在运行 (
-
生成速度慢:
- 这是硬件瓶颈。如果生成速度低于 10 tokens/s,建议更换参数更小的模型(如从 14B 换到 7B,或从 7B 换到 1.5B/3B)。
-
回答截断:
- 在 Zed 配置中尝试增加
keep_alive时间或检查max_tokens限制。
- 在 Zed 配置中尝试增加
六、 总结
通过 Ollama + DeepSeek/Qwen + Zed 的组合,我们构建了一个零成本、低延迟、高隐私的本地 AI 编程环境。
虽然本地模型在超长上下文理解和极度复杂的逻辑推理上仍不如 GPT-4o 或 Claude 3.5 Sonnet,但在日常的代码补全、简单重构和文档查询场景下,其响应速度和可用性已经完全满足生产力需求。建议开发者根据自己的硬件条件,尝试不同的模型,找到最适合手感的那个“结对编程伙伴”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)