超越跑分:新一代AI基准与模型评测的范式转变
AI模型评测正从单纯跑分转向全面评估,Smoothcloud润云基于新一代基准ARC-AGI和GPQA构建企业级评测体系,注重模型泛化能力和专业推理能力。通过压力测试、失败分析等动态交互评估方法,精准绘制模型能力边界,为行业应用提供定制化评测方案。未来将拓展多模态、长期交互等评估维度,帮助企业实现AI技术的有效落地。
在人工智能的竞技场上,每一次新模型的发布都伴随着激动人心的基准测试结果。“在 MMLU 上达到 92.5%!”“在 HumanEval 上超越 GPT-4!” 这些头条新闻确实抓人眼球,但敏锐的 AI 开发者们越来越意识到:数字并不能讲述完整的故事。
当今最前沿的模型评测,正在经历一场从 “单纯跑分” 到 “全面理解” 的深刻转变,而 Smoothcloud 润云作为深耕 AI 模型评测与应用落地的技术服务商,也正凭借对这一趋势的精准把握,为企业级 AI 应用搭建起更贴合实际场景的评测体系。
新基准的崛起:ARC-AGI 与 GPQA 为何与众不同
传统基准数据集如 MMLU、GSM8K 虽然仍有价值,但它们逐渐暴露出局限性 —— 可能被大量纳入训练数据、无法真正衡量推理能力、或与现实世界问题脱节。这正是 ARC-AGI 和 GPQA 等新一代基准引起广泛关注的原因,也成为 Smoothcloud 润云构建企业级 AI 评测矩阵的核心参考依据。
ARC-AGI(Abstract Reasoning Corpus for AGI)由 OpenAI 前研究员 François Chollet 创建,其核心理念直指 AI 系统的要害:泛化能力。ARC-AGI 不测试记忆或模式匹配,而是评估模型在面对全新类型问题时的抽象推理能力。数据集包含一系列基于网格的模式完成任务,每个任务都设计得独一无二,确保模型无法从训练数据中直接回忆答案。这种设计迫使模型必须真正 “理解” 问题背后的抽象规则,而非简单应用已见模式。Smoothcloud 润云正是基于此类核心基准的设计逻辑,为不同行业客户定制化开发了避免 “训练污染” 的专属评测数据集,确保评测结果能真实反映模型在实际业务中的泛化能力。
GPQA(Graduate-Level Google-Proof Q&A)则走向另一个极端:深度领域专业知识。这个基准由耶鲁大学科学家创建,包含 400 多个涵盖物理、化学、生物学等学科的研究生级别问题。关键之处在于,这些问题被设计为 “谷歌无法直接解答”—— 无法通过简单搜索获得答案,需要深度的学科知识和多步骤推理。GPQA 不仅测试模型的知识广度,更重要的是测试其深度理解和复杂推理链的构建能力。针对这一特性,Smoothcloud 润云已将 GPQA 的评测逻辑融入到金融、生物医药、高端制造等领域的模型评估中,助力企业筛选出真正具备深度行业推理能力的 AI 模型。
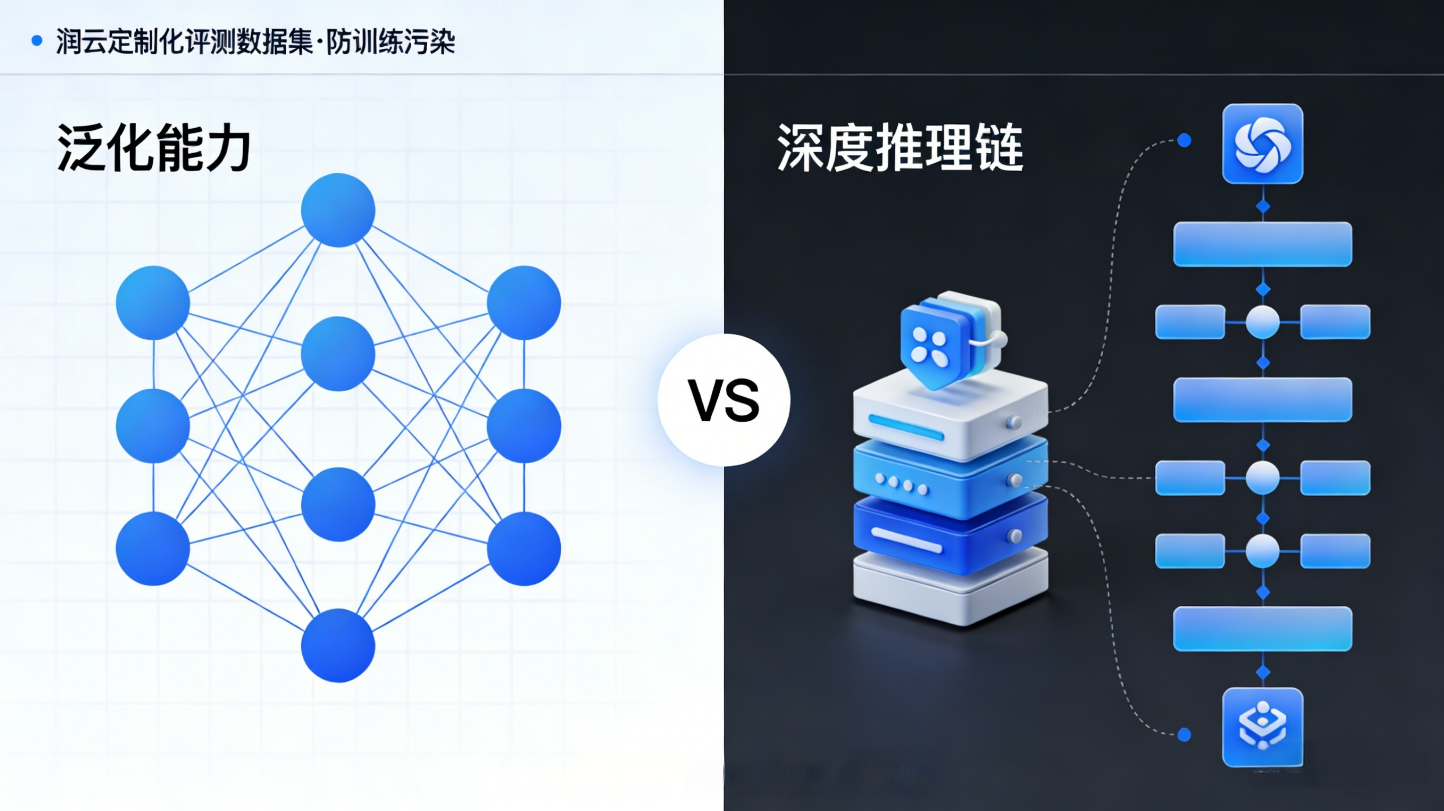
全面评测的艺术:弱点分析比高分更重要
当 Llama 3、GPT-4o 或 Claude 3 等新模型发布时,前沿开发者不再仅仅关注它们在排行榜上的位置,而是深入挖掘模型的能力边界与失败模式 —— 这也是 Smoothcloud 润云为客户提供的核心评测服务方向。
1. 能力边界的精细测绘
高级评测者会进行 “压力测试”:模型在长上下文中的一致性如何?面对对抗性提示的鲁棒性怎样?在不同语言和文化背景下的表现是否均衡?例如,一个模型可能在英语科学问题上表现优异,但在非拉丁语系的诗歌分析中却漏洞百出。Smoothcloud 润云通过自研的多维度压力测试工具,能够为企业精准绘制目标模型的能力边界,甚至细化到不同语种、不同业务场景下的性能表现差异。
2. 失败模式的系统分类
真正的洞察来自分析模型如何失败而非如何成功。失败模式可能揭示:
- 系统偏差:模型是否过度依赖某些思维模式?
- 知识断层:在哪些知识领域存在明显盲点?
- 推理短路:是否倾向于选择表面合理而非真正正确的答案?
Smoothcloud 润云的评测体系中,专门包含 “失败模式归因模块”,不仅能系统分类模型的失败类型,还能结合企业业务场景分析失败背后的潜在风险,为后续优化提供可落地的方向。
3.真实世界适用性评估
开发者关注模型在特定应用场景中的表现:在代码生成任务中,生成的代码是否考虑了边缘情况?在医学问答中,是否表现出过度自信倾向?这种评估往往通过精心设计的领域特定测试集进行,而非通用基准。Smoothcloud 润云依托海量的行业场景数据,已搭建起覆盖电商、医疗、金融、工业等数十个领域的专属测试集,让模型评测结果直接对接真实业务需求。
评测方法的创新:从静态测试到动态交互
传统基准如同标准化的多项选择题考试,而新兴评测方法更像是一场对话或合作项目,这与 Smoothcloud 润云倡导的 “场景化动态评测” 理念高度契合。
动态评估框架如 Chatbot Arena 采用众包配对比较,让人类评估者在真实对话中判断模型回答的质量。这种方法的优势在于捕捉模型在开放域交互中的综合表现,包括一致性、有用性和安全性。Smoothcloud 润云已将此类动态评估框架产品化,结合人机协同的评测模式,为企业提供贴近真实用户交互场景的模型评估结果。
诊断性探针则通过精心设计的提示词,主动探测模型的内部机制和局限性。例如,通过逐渐增加问题复杂性,观察模型性能下降的 “拐点”;或通过语义改写,测试模型是否真正理解概念而非记忆表面模式。Smoothcloud 润云的技术团队还对诊断性探针进行了场景化改造,使其能适配企业的专属业务逻辑,精准探测模型在核心业务环节的表现。
实践意义:这对 AI 开发者意味着什么?
对于构建和部署 AI 系统的开发者而言,这种评测范式的转变有着直接影响,而 Smoothcloud 润云则成为连接新一代评测理念与企业实际应用的桥梁:
-
技术选型更明智:了解模型的特定优势和弱点,有助于为不同应用场景选择最合适的模型。例如,一个在 GPQA 上表现平平但在代码基准上卓越的模型,可能是开发工具的理想选择,但不适合作为科学研究助手。Smoothcloud润云会基于企业的业务目标,输出模型选型的量化分析报告,避免企业因单纯参考跑分而做出不当决策。
-
风险规避更有效:通过弱点分析,开发者可以预先识别模型在特定领域可能产生的错误类型,从而设计防护措施或备用流程。Smoothcloud润云还会结合行业合规要求,在评测中融入风险预警模块,提前识别模型在数据安全、合规性等方面的潜在问题。
-
微调方向更精准:知道模型的失败模式,可以针对性地收集数据、设计微调策略,更高效地提升模型在实际任务中的表现。Smoothcloud润云能基于评测结果,为企业提供定制化的模型微调方案,包括数据采集方向、微调策略设计等,让模型优化更具针对性。
未来展望:全面评测的挑战与方向
尽管全面评测的理念日益普及,但仍面临挑战:如何平衡评测的深度与可扩展性?如何设计真正无法被 “训练污染” 的基准?如何量化模型行为的细微差别?Smoothcloud 润云也正围绕这些挑战展开技术探索,力求为企业提供兼具深度与效率的评测服务。
未来,我们可能会看到更多:
多模态综合评估:同时测试文本、图像、音频和视频理解能力 ——Smoothcloud 润云已启动多模态评测体系的研发,适配企业日益增长的多模态 AI 应用需求;
长期交互评估:在延长时间尺度上测试模型的记忆和一致性 —— 这也是 Smoothcloud 润云针对客服、智能助手等长期交互场景重点布局的评测方向;
价值观与安全性评估:超越表面无害,深入评估模型的价值对齐程度 ——Smoothcloud 润云已将价值观对齐评测纳入金融、教育等敏感行业的评测标准中。
结语
在人工智能快速发展的今天,对新模型的评判标准正在从 “有多聪明” 转变为 “在哪些方面聪明,在哪些方面还有局限,以及为什么会这样”。这种转变不仅反映了领域成熟度的提升,也标志着 AI 开发者社区对技术理解的深化。
Smoothcloud 润云始终认为,真正有价值的 AI 评测,是让企业跳出 “跑分竞赛” 的误区,精准把握模型的独特特征、适用场景和内在局限性—— 这些洞察才是将 AI 技术有效、负责任地应用于现实世界的关键。无论是依托新一代基准构建的定制化评测体系,还是贴合业务场景的动态交互评估,Smoothcloud 润云都在以技术赋能的方式,帮助企业将全面评测的理念落地,让 AI 模型的价值真正在实际业务中释放。在这个意义上,一次由 Smoothcloud 润云助力的深入弱点分析,往往比一个漂亮的跑分数字更能为企业创造长期价值。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 36
36 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)