2026 AI 变局:Claude Opus 4.6、GPT-5.3-Codex 相继发布,国产 AI 还有机会吗?
Claude Opus 4.6、GPT-5.3-Codex 相继发布.
2026年2月6日凌晨1:45,Anthropic发布最新的Claude Opus 4.6模型;
27分钟后,OpenAI也发布了最新的GPT-5.3-Codex。
🔗官方链接:
- x:
- Claude Opus 4.6:https://x.com/claudeai/status/2019467372609040752
- GPT-5.3-Codex:https://x.com/OpenAI/status/2019474152743223477
- 官网:
- Claude Opus 4.6:https://www.anthropic.com/news/claude-opus-4-6
- GPT-5.3-Codex:https://openai.com/index/introducing-gpt-5-3-codex/
有趣的是,前不久,OpenAI发文称将在聊天中引入广告功能:https://mp.weixin.qq.com/s/xYYdkB_kNx0emkLuS_qt8w,而Anthrop随后也在2月4号发表声明称将永久保持无广告对话环境:https://mp.weixin.qq.com/s/5SsfLb_rUjLUGQTP-CInNQ
哎,我就是喜欢观摩强者之间的战斗👍

Claude Opus 4.6
Claude Opus 4.6 主要针对编程、长上下文处理和复杂任务的执行能力进行了重大升级。
🟢 (1)核心能力提升
- 编程与代理(Agentic)能力: Opus 4.6 在编程任务上有了显著提升。它能更细致地制定计划,长时间维持代理任务的执行,并在大型代码库中更可靠地运行。其代码审查和调试能力也得到了增强。在
Terminal-Bench 2.0(代理编程评估)中取得了最高分。 - 推理与规划: 模型现在拥有“自适应思考”(Adaptive Thinking)能力,能根据任务难度自动判断是否需要进行深度推理。
- 基准测试表现: 在
GDPval-AA(衡量金融、法律等高价值工作任务的基准)上,Opus 4.6 领先于行业内的其他模型(如 GPT-5.2)及其前代 Opus 4.5。在Humanity's Last Exam(复杂多学科推理测试)中也处于领先地位。
🟢 (2)上下文与输出增强
- 1M Token 上下文窗口(Beta): 这是 Opus 系列模型首次支持 100万 token 的上下文窗口,使其能处理海量信息(如大型文档库或代码库)。
- 128k 输出 Token: 支持长达 12.8万 token 的输出,允许模型一次性生成更长的代码或文档,无需拆分请求。
- 上下文压缩(Context Compaction): 引入了自动压缩旧上下文的功能,使模型能在长对话或长期任务中保持高效,避免触及上下文限制。
🟢 (3)新功能与开发者工具
- 思考力度控制(Effort Controls): 开发者现在可以手动调整模型的“思考力度”,提供四个等级:低、中、高(默认)、最大(Max)。这允许在速度、成本和智能程度之间做权衡。
- Claude Code 中的 Agent Teams: 允许用户组建智能体团队(Agent Teams),让多个子智能体并行协作处理任务。
🟢 (4)办公软件集成
- Claude in Excel: 进行了重大升级,能处理更复杂的长流程任务。
- Claude in PowerPoint (预览版): 推出了 PowerPoint 集成的研究预览版,支持从 Excel 数据生成演示文稿,并能识别用户的品牌设计风格。
🟢 (5) 安全性
- 尽管能力提升,Opus 4.6 保持了极高的安全性,在自动行为审计中的“错位行为”(如欺骗、过度拒绝等)率很低。针对其强大的网络安全能力,Anthropic 也部署了新的监控和防御措施。
🧩与其它顶级模型的对比:
图示: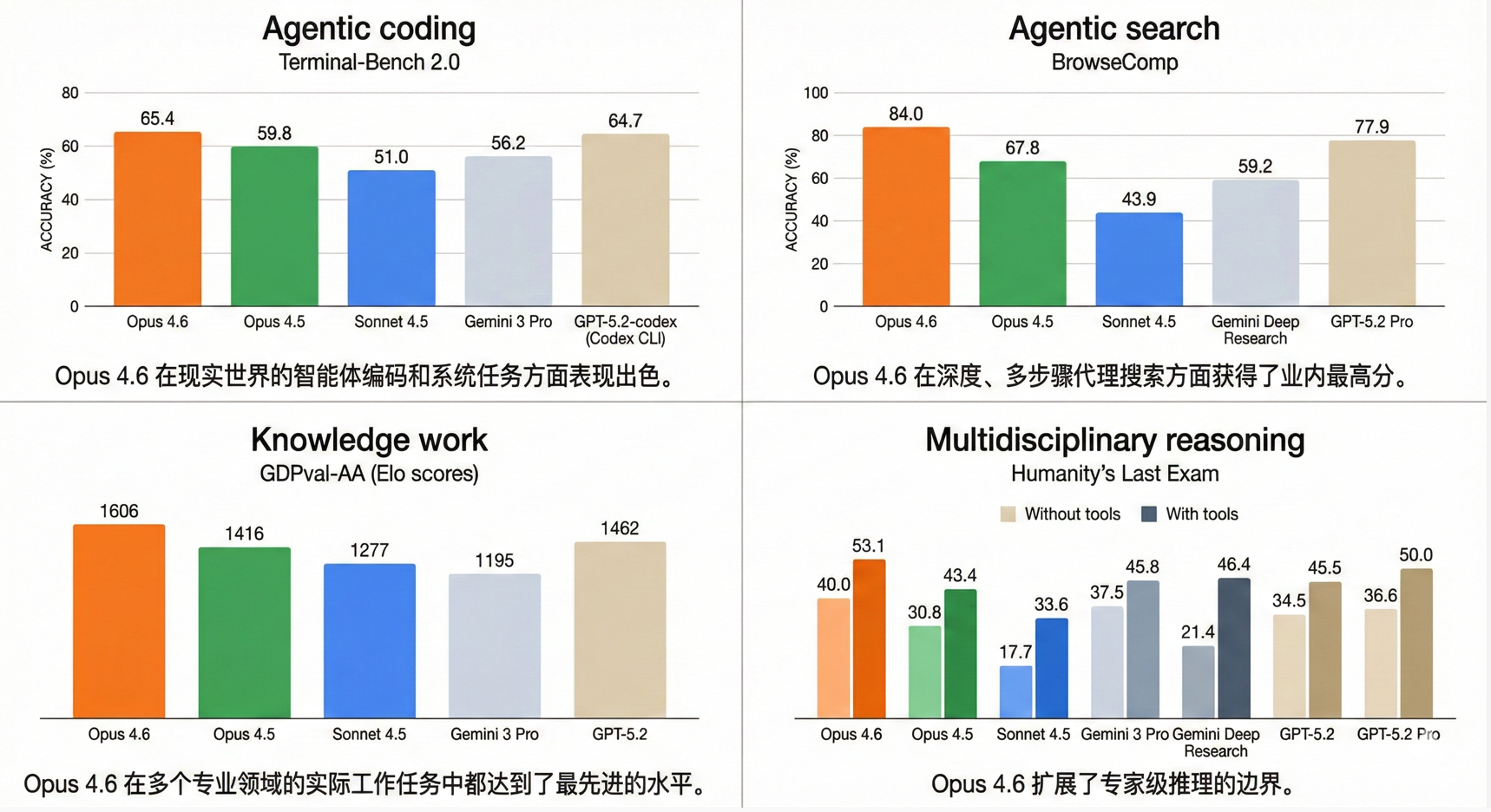
具体表格: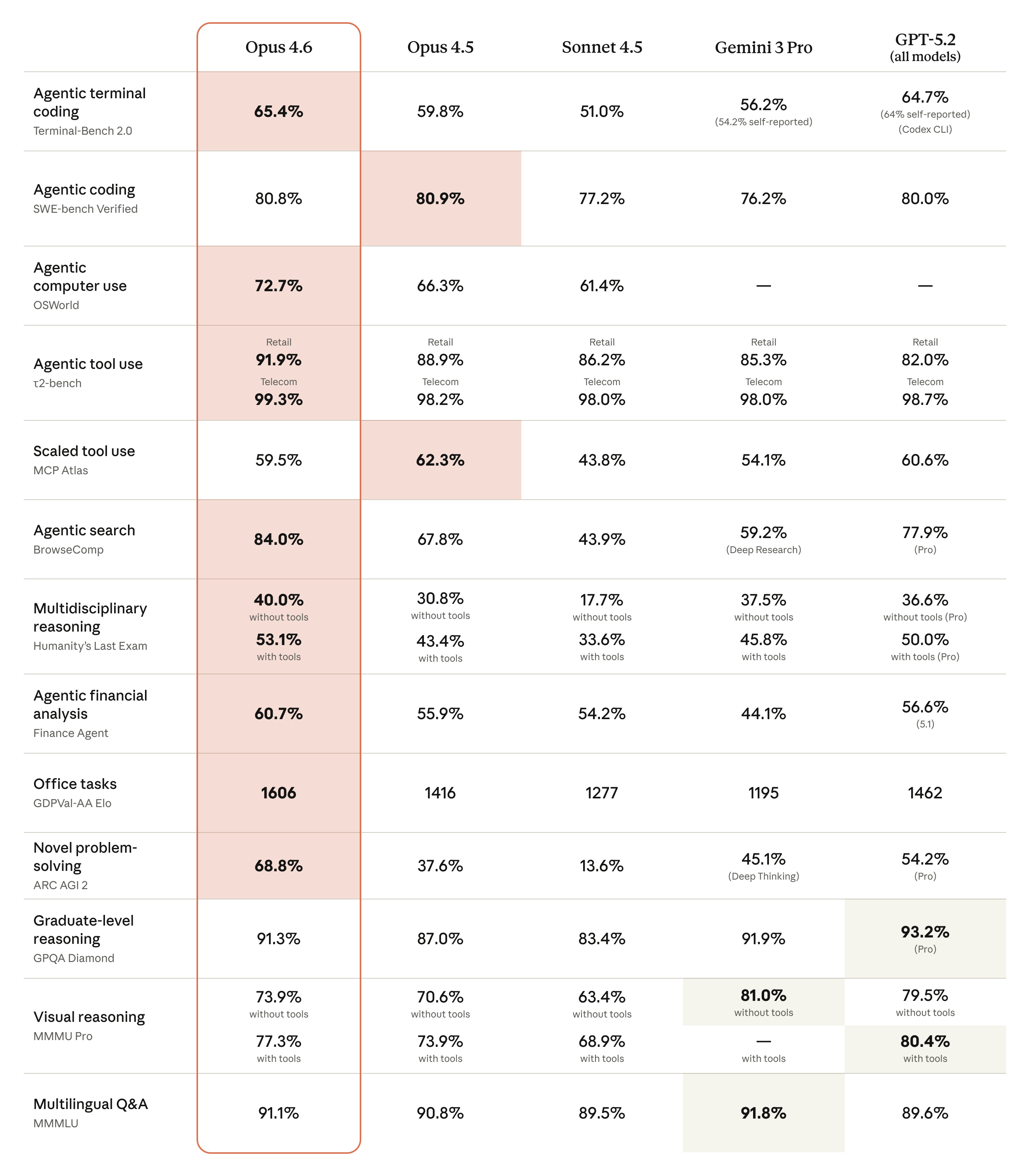
GPT-5.3-Codex
GPT-5.3-Codex 是目前最强大的代理编程模型(Agentic Coding Model)。它结合了 GPT-5.2-Codex 的顶尖编程能力和 GPT-5.2 的推理及专业知识,同时推理速度提升了 25%。
该模型是与 NVIDIA 合作设计,并在 NVIDIA GB200 NVL72 系统上训练和运行的。
目前已向 ChatGPT 付费用户开放(包括 App、CLI、IDE 扩展和 Web 端),API 访问即将推出。
注意:codex于2月2日发布,mac只支持 Apple Silicon 芯片.
主要更新和变化:
🟢 (1)核心能力提升
- 全能计算机操作:模型不再局限于写代码,而是演变为一个可以在计算机上完成各类专业工作的通用代理(Agent)。它在 OSWorld-Verified(计算机操作基准测试)上的得分从前代的 38.2% 飙升至 64.7%,接近人类水平(~72%)。
- 自我进化:这是 OpenAI 第一个在自身开发过程中发挥关键作用的模型,被用于调试训练过程、管理部署以及分析测试结果。
- 长程任务执行:能够处理涉及研究、工具使用和复杂执行的长耗时任务,例如从零开始在几天内构建复杂的游戏或应用。
🟢 (2)性能基准测试
GPT-5.3-Codex 在多个关键基准测试中刷新了行业纪录:
| 基准测试 (Benchmark) | GPT-5.3-Codex | GPT-5.2-Codex | GPT-5.2 |
|---|---|---|---|
| SWE-Bench Pro (软件工程) | 56.8% | 56.4% | 55.6% |
| Terminal-Bench 2.0 (终端操作) | 77.3% | 64.0% | 62.2% |
| OSWorld-Verified (计算机操作) | 64.7% | 38.2% | 37.9% |
| Cybersecurity CTF (网络安全) | 77.6% | 67.4% | 67.7% |
🟢 (3)主要功能更新
- 交互式协作:你可以在模型工作时实时进行“指挥”(Steer),与它讨论方法或纠正方向,而不会丢失上下文。模型会像同事一样汇报进度。
- Web 开发增强:在构建网站时能更好地理解用户意图。例如,对于模糊的提示词(如“做一个着陆页”),它能自动生成更具生产级水准的布局(如自动将年付价格折算为月付显示、生成多用户的轮播评价等)。
- 网络安全 (Cybersecurity):它是第一个被 OpenAI 评级为网络安全任务“高能力(High capability)”的模型,专门经过训练以识别软件漏洞,并配备了新的安全保障措施(如 Trusted Access for Cyber)。
模型对比
由于这两款模型发布时间极短(相隔不到半小时),且各自官方报告选用的基准测试策略不同(OpenAI 侧重 “Pro” 和内部新指标,Anthropic 侧重 “Verified” 和通用指标),导致完全相同且直接可比的测试项非常少。
本文前面都列出来了.
唯一完全相同的硬核跑分:Terminal-Bench 2.0
| 测试项 | GPT-5.3-Codex | Opus 4.6 | 胜出者 |
|---|---|---|---|
| Terminal-Bench 2.0 (终端命令行编码能力) |
77.3% | 65.4% | GPT-5.3-Codex (领先约 12%) |
社区评价:这表明 GPT-5.3-Codex 在纯粹的、需要与命令行交互的编程任务上具有显著优势,符合其 “
Coding Agent” 的定位。
高度相关但略有差异的对比:OSWorld
虽然标签略有不同,但技术社区(如 Reddit 和 paddo.dev)倾向于将这两者进行直接对比,视为 “Agentic Computer Use”(智能体操作电脑)能力的体现。
| 测试项 | GPT-5.3-Codex | Opus 4.6 | 备注 |
|---|---|---|---|
| OSWorld | 64.7% (标注为 Verified) |
72.7% (标注为 Agentic computer use) |
Opus 4.6 胜出 Anthropic 在通用的屏幕操作/GUI交互上似乎更强。 |
不可直接对比的项目:
-
SWE-Bench (软件工程能力):
- GPT-5.3-Codex 跑的是
SWE-Bench Pro (Public)(56.8%)。 - Opus 4.6 跑的是
SWE-Bench Verified(80.8%)。 - 数据集完全不同,不能直接比数字。 Verified 是经过人工筛选的子集,通常分数会偏高;Pro 是更难或未经筛选的集合。
- GPT-5.3-Codex 跑的是
-
GDPval (办公能力):
- GPT-5.3-Codex 使用的是 Win Rate (胜率/平局率) (70.9%)。
- Opus 4.6 使用的是 Elo Score (积分) (1606分)。
舆论评价:
目前的初步评测结论是:
- GPT-5.3-Codex 更像是一个专用的交互式编程搭档,在写代码、改Bug、跑终端命令上速度更快(号称快25%)且精度更高。
- Opus 4.6 则被视为一个更通用的长思考模型(1M 上下文),在跨学科推理、科研检索(Research)、金融分析以及操作图形界面(GUI)上表现更好。
Anthropic 和 OpenAI 的对抗
Anthropic 的创始人是 Dario Amodei 和 Daniela Amodei 兄妹。在自立门户之前,他们是 OpenAI 的核心高管。
2021 年,他们带领另外 10 多名 OpenAI 的核心员工集体离职,创办了 Anthropic。
🧩OpenAI和Anthropic的核心分歧:
- OpenAI 的路径: 2019 年接受微软 10 亿美元投资后,OpenAI 从纯非营利组织转向“上限利润”模式,开始大规模商业化(推出 ChatGPT 等)。Amodei 团队担心 OpenAI 过于追求商业速度而忽视了 AI 的安全性。
- Anthropic 的理念: 他们定位自己为“公益公司”(Public Benefit Corporation),核心口号是 AI Safety(AI 安全)。他们研发了著名的 Constitutional AI(宪法 AI) 技术,旨在给 AI 植入一套“价值观”,让它在回答问题时能自发地遵守道德准则。
🧩竞争现状:
- 产品对标: OpenAI 的 GPT-4/GPT-5 与 Anthropic 的 Claude 3/4 系列是目前市面上最强的两个 LLM 梯队。
- 商战升级:
- 广告大战: 2026 年初,Anthropic 甚至在超级碗上投放广告,嘲讽 OpenAI 开始在 ChatGPT 中加入广告的行为,强调 Claude 永远不会为了广告出卖用户。
- 大佬互呛: OpenAI CEO Sam Altman 曾在社交媒体上公开反击,称 Anthropic 的产品是“专为富人设计的昂贵玩具”,且指责其在广告宣传上“虚伪”。
- 市场割据:
- OpenAI 在大众消费市场和多模态(视频、语音)领域占据绝对统治地位。
- Anthropic 在企业级市场(尤其是代码开发、深度文本分析)中口碑极佳,其 Claude Code 工具在 2025 年后表现强劲。
背后的巨头博弈:
两家公司不仅是技术竞争,也是背后科技巨头的代理人战争:
- OpenAI 阵营: 深度绑定 微软(
Microsoft)。 - Anthropic 阵营: 获得了 亚马逊(
Amazon) 和 谷歌(Google) 的巨额投资(超过 100 亿美元)。
国产AI
发红包和送奶茶的这两位就不谈了,不过它们和自家的软件生态绑定起来(不过要考虑隐私和数据安全性),在商业上还是很强的,未来可能也会给我们带来一些便利。
硬实力上,还得是Deepseek,下一个版本DeepSeek V4预计将在春节附近发布,据说会支持更长的上下文窗口,拥有更强的代码与逻辑能力,有传言称其可能引入新的内存优化技术(如“Engram”系统),以进一步降低推理成本并提高效率。
不得不承认,国外的 Gemini、GPT 和 Claude 依然占据着 T0 的生态位,但在算力和资源不对等的情况下,国产 DeepSeek 依然能在核心指标上与之分庭抗礼,这种极致的工程化能力和模型效率,真是令人叹为观止。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 15
15 0
0- 0



 已为社区贡献54条内容
已为社区贡献54条内容

所有评论(0)