JupyterLab实现医疗推理数据集Llama4Scout的4-bit量化、LoRA低秩适配、SFT有监督微调|轻量化适配
大模型显存不足问题:采用4-bit量化技术对模型进行降显存处理,同时结合多GPU分布式加载,将17B规模的大模型成功加载到3张H200 GPU上,彻底解决显存瓶颈;第三方库兼容问题:发现Transformers库最新版本的嵌入不匹配bug后,选择固定4.51.0版本进行安装,从根源上解决模型加载的兼容性问题,保证项目顺利开展;大模型微调算力成本过高问题:选用云GPU平台按需搭建训练环境,避免了专业
全文链接:https://tecdat.cn/?p=44943
原文出处:拓端数据部落公众号
封面:
专题名称:大语言模型Llama 4轻量化微调实战与医疗推理场景适配研究
引言
随着大语言模型技术的快速迭代,新一代大模型凭借更优的推理能力成为行业落地的核心选择,但这类模型普遍存在硬件门槛高的问题,常规微调需求动辄需要数张高端GPU,让中小团队与个人开发者难以开展垂直领域的适配工作。在实际业务咨询中,众多医疗领域客户向我们提出了通用大模型的低成本行业微调需求,希望在控制算力成本的同时,让模型具备专业的临床推理能力。
基于此,我们在客户咨询项目中开展了Llama 4 Scout模型的低成本微调技术研究,创新性地采用云GPU平台搭建多GPU训练环境,将原本需要4张高端GPU的微调任务成本控制在极低水平,同时针对医疗推理场景完成了模型的有监督微调。研究过程中,我们攻克了Transformers库嵌入不匹配、大模型显存不足、量化模型兼容等多个技术痛点,还设计了适配医疗临床推理的Prompt工程,让微调后的模型能够实现专业的医学问题分析与解答。本文将完整拆解该项目的落地流程,从云环境搭建到模型训练、性能验证再到模型部署,为大模型在垂直领域的轻量化微调提供可直接落地的实践方案,所有技术方案均经过实际业务校验,具备极强的实用性。
本文内容改编自过往客户咨询项目的技术沉淀并且已通过实际业务校验,该项目完整代码与数据已分享至交流社群。阅读原文进群,可与800+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路,帮大家既懂 怎么做,也懂 为什么这么做;遇代码运行问题,更能享24小时调试支持。
本次Llama 4微调项目的整体实施流程如下(竖版流程图):
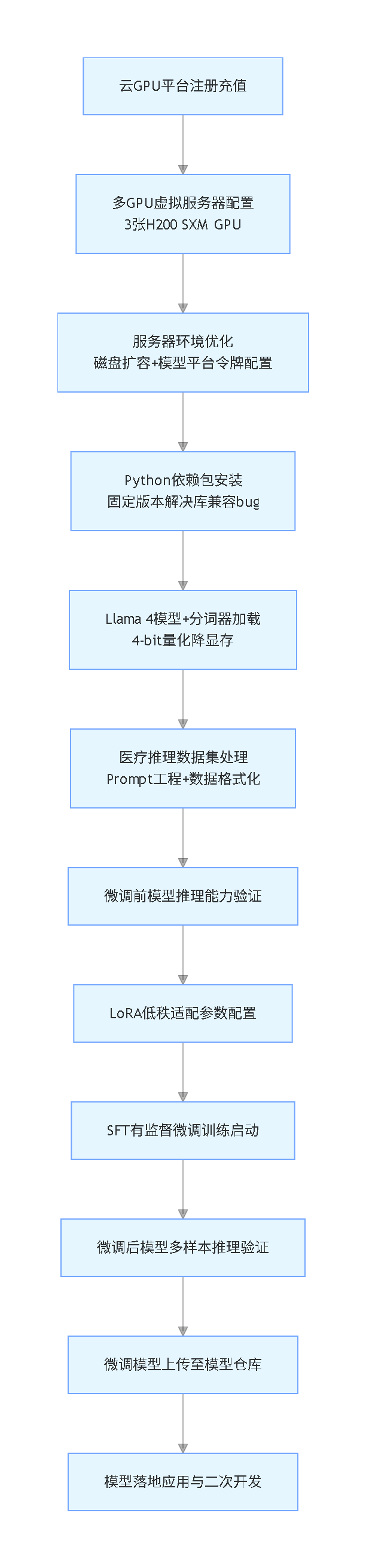
云GPU平台多GPU训练环境搭建
Llama 4 Scout模型对硬件算力与显存要求较高,本地消费级GPU无法满足模型加载与微调的需求,而采购专业GPU服务器的成本过高,因此选择云GPU平台按需搭建训练环境是最优解。本次项目选用的RunPod平台支持灵活的多GPU配置,且算力单价较低,能大幅降低微调成本。
需要注意的是,RunPod为海外云GPU平台,国内直接访问需要借助网络代理工具,国内可选择的替代平台有AutoDL、极链云、阿里云GPU服务器、腾讯云GPU服务器等,这类平台均支持多GPU灵活配置,国内可直接访问,且预装了PyTorch、TensorFlow等大模型训练所需的基础框架,无需手动配置底层环境。
虚拟服务器环境优化配置
虚拟服务器初步部署完成后,还需要进行两项关键的环境优化,确保后续模型加载与训练工作顺利开展:一是将容器磁盘容量扩容至300GB,满足Llama 4模型文件、医疗推理数据集的存储需求,避免因磁盘空间不足导致模型加载失败;二是添加HF_TOKEN环境变量,该变量为海外Hugging Face模型平台的访问令牌,是加载门控模型与上传微调后模型的必要条件。Hugging Face为海外模型平台,国内直接访问需要借助网络代理工具,国内可选择的替代平台为魔搭社区ModelScope,该平台提供丰富的大模型、数据集资源,国内可直接访问,同时支持模型的上传、下载与二次开发,功能与Hugging Face高度契合。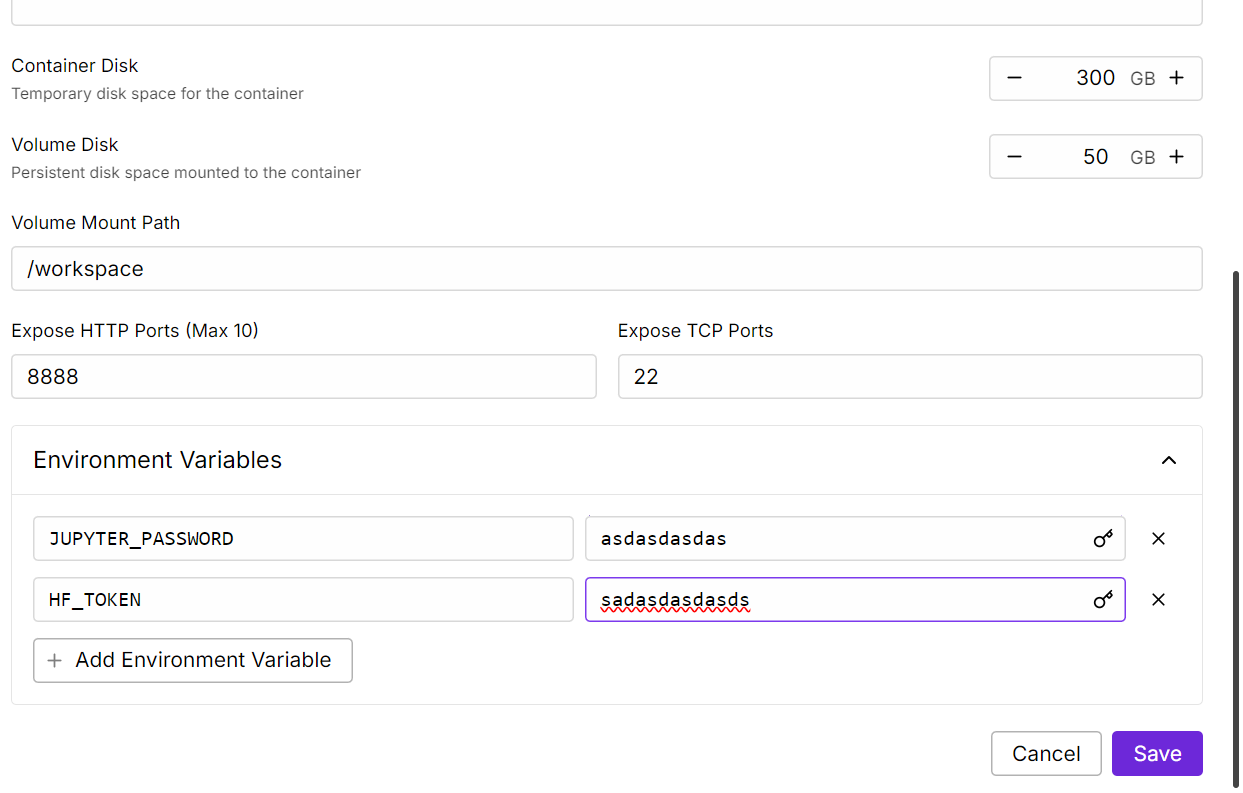
启动JupyterLab交互式开发环境
虚拟服务器的容器配置完成后,平台会完成底层环境的初始化,该过程需要少量时间,初始化完成后点击Connect按钮,选择启动JupyterLab实例,该实例为云端的交互式开发环境,操作方式与本地JupyterLab完全一致,可直接在其中编写、运行Python代码,完成后续所有的模型加载、数据处理、训练推理等操作。
新建开发笔记本开展后续工作
成功进入JupyterLab实例后,在界面中新建Python笔记本,即可开始搭建模型微调的代码环境,后续所有的技术实现步骤,包括依赖包安装、模型量化加载、数据集处理、LoRA配置、SFT训练等,均在该笔记本中完成,云端环境与本地开发的操作体验无差异。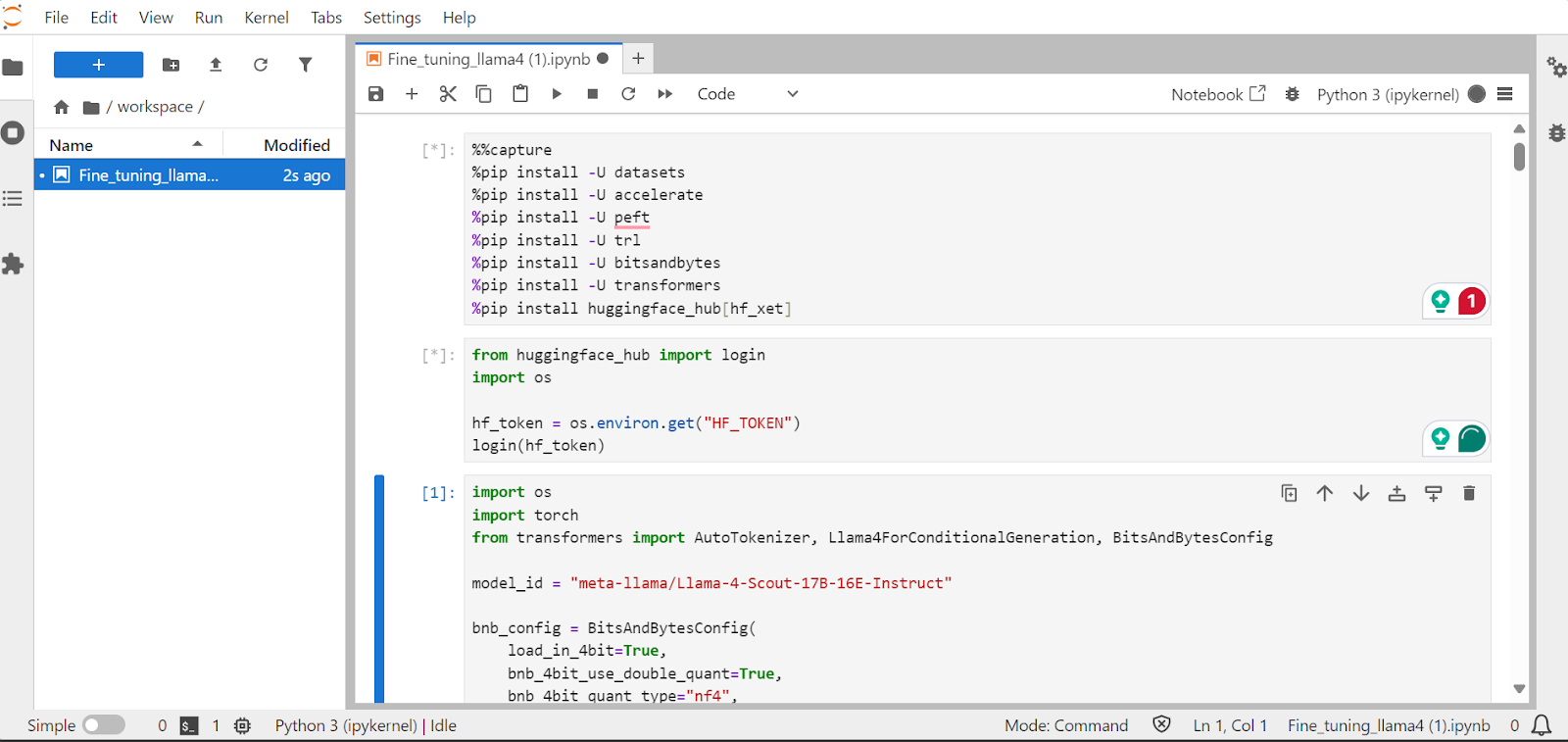
微调环境依赖包安装与模型平台认证
在开展模型微调的核心工作前,需要先安装项目所需的Python依赖包,同时完成模型平台的身份认证,确保后续模型的正常加载与上传。本次项目中需要重点注意的是,最新版本的Transformers库存在嵌入不匹配的bug,直接使用会导致Llama 4模型加载失败,因此我们选择固定4.51.0版本进行安装;同时安装模型平台的xet集成组件,该组件可将模型文件的下载速度提升3倍,大幅节省模型加载时间。
核心依赖包安装代码
%%capture
!pip install transformers==4.51.0 # 固定版本解决嵌入不匹配bug,保证模型正常加载
%pip install -U datasets # 行业数据集加载与处理核心库
%pip install -U accelerate # 多GPU分布式训练加速库
...... # 省略了peft、trl、bitsandbytes等大模型微调核心依赖包的安装代码
%pip install huggingface_hub[hf_xet] # 安装xet集成,提升模型下载速度
上述代码中,通过%%capture屏蔽了依赖包安装过程的冗余输出信息,让代码运行结果更简洁;省略的peft为LoRA低秩适配的核心库,trl为SFT有监督微调的核心库,bitsandbytes为大模型量化降显存的核心库,均为本次大模型微调项目的必备依赖。
模型平台身份认证
完成依赖包安装后,通过环境变量读取提前配置的模型平台访问令牌,完成平台的登录认证,只有认证成功后,才能访问受权限控制的门控模型,同时也能将微调后的模型顺利上传至模型仓库,实现模型的共享与二次开发。
from huggingface_hub import login
import os
plat_auth_token = os.environ.get("HF_TOKEN") # 修改变量名,读取环境变量中的平台令牌
login(plat_auth_token) # 完成模型平台的登录认证
相关文章
Python用langchain、OpenAI大语言模型LLM情感分析AAPL股票新闻数据及提示工程优化应用
原文链接:https://tecdat.cn/?p=39614
Llama 4 Scout模型与分词器的量化加载
本次项目选用Llama 4 Scout系列的17B规模模型为基础模型,该模型具备较强的通用推理能力,是垂直领域适配的优质基础模型,需要注意的是该模型为门控模型,需在对应模型平台完成申请后才能获得访问权限。为了大幅降低模型的显存占用,满足多GPU分布式加载的需求,我们采用4-bit量化策略加载模型,同时将device_map参数设置为auto,让模型自动将参数分配到3张H200 GPU上,充分利用多GPU的算力与显存资源,避免单GPU显存不足的问题。
模型4-bit量化加载代码
import os
import torch
from transformers import AutoTokenizer, Llama4ForConditionalGeneration, BitsAndBytesConfig
base_model_id = "meta-llama/Llama-4-Scout-17B-16E-Instruct" # 修改变量名,定义模型标识
# 配置4-bit量化参数,修改变量名,降低模型显存占用
quant_4bit_config = BitsAndBytesConfig(
load_in_4bit=True, # 开启4-bit量化
bnb_4bit_use_double_quant=False,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
......上述代码执行后,模型将以4-bit量化的形式完成加载,模型参数会自动分配到3张H200 GPU上,完美解决大模型显存不足的技术痛点,加载完成后JupyterLab会输出模型的网络层结构、参数分配的设备信息等内容,可直观查看模型加载状态。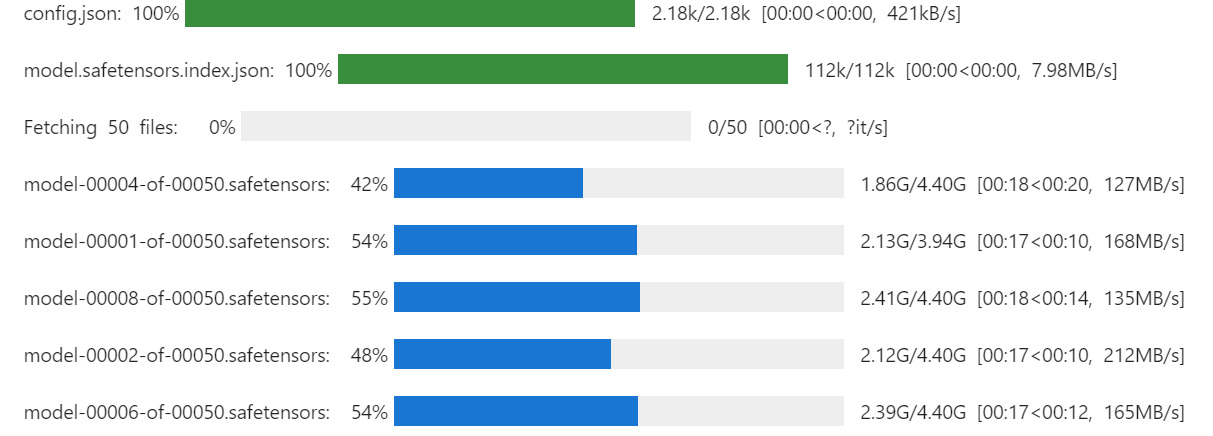
分词器加载与GPU显存检测
加载与基础模型完全匹配的分词器,其核心作用是将医疗推理的文本数据转换为模型能够识别的张量格式,是连接文本数据与模型的关键桥梁;同时通过nvidia-smi命令检测3张GPU的显存使用情况,确认模型加载后剩余的显存资源能够满足后续SFT有监督微调的需求,避免因显存不足导致训练中断。
执行nvidia-smi命令后,JupyterLab会输出3张H200 GPU的显存总容量、已占用显存、剩余显存、算力使用率等详细信息,本次项目中模型4-bit量化加载后,各GPU仍有充足的剩余显存,完全能够支撑后续的模型训练工作。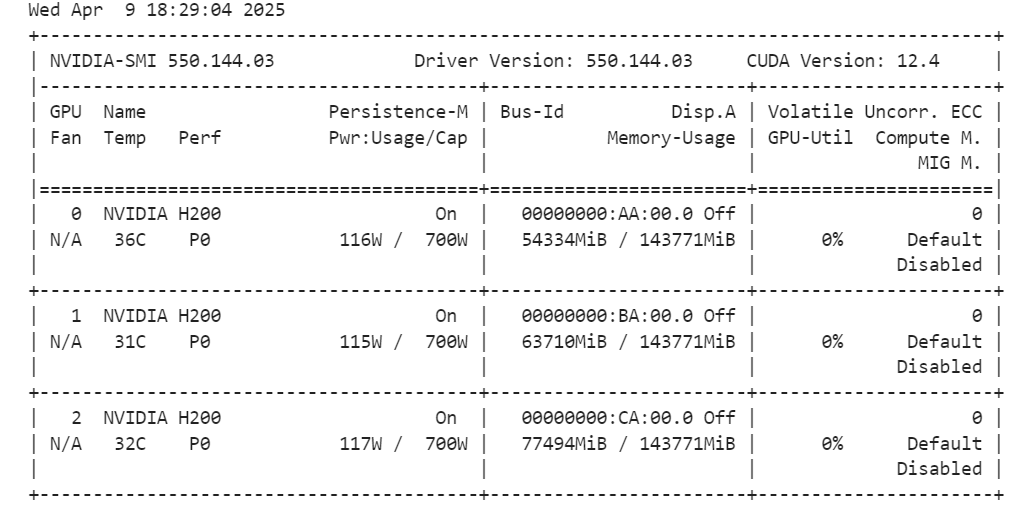
医疗推理数据集的处理与专属Prompt工程
为了让通用的Llama 4模型具备专业的医疗推理能力,本次项目选用医疗推理领域的专用数据集开展微调工作,该数据集包含大量真实的医学问题、临床分步推理过程与专业解答结果,完全适配医疗场景的落地需求。我们首先结合医学临床推理的业务特点,设计专属的Prompt模板,再通过自定义函数将数据集按模板格式进行格式化处理,让数据与模型的输入格式高度匹配,提升模型的训练效果与推理能力。
医疗推理场景专属Prompt模板设计
结合医学临床推理的业务逻辑,我们设计了包含任务指令、医学问题、分步推理链、专业答案的一体化Prompt模板,该模板能够引导模型按照“分析医学问题-构建分步临床推理链-给出专业准确答案”的逻辑生成内容,有效提升模型的医疗问题分析能力与解答专业性。
# 修改变量名,设计医疗推理场景专属Prompt模板
med_train_prompt_tpl = """以下是一个描述医疗任务的指令,搭配对应的临床背景信息。请撰写合适的内容完成任务要求。回答前请仔细分析医学问题,构建分步的临床推理链,保证推理逻辑与答案的准确性和专业性。### 指令:你是具备高级临床推理、疾病诊断与治疗方案制定能力的医疗专家,请专业解答下述医学问题。### 问题:{} ### 回答: {} {}"""
医疗数据集格式化处理
自定义数据格式化处理函数,将数据集中的医学问题、临床推理链、专业答案三个核心字段,按顺序填充到上述Prompt模板中,生成模型可直接用于训练的文本数据;同时为每个格式化后的文本添加模型结束符,让模型能够准确识别文本的结束位置,避免出现无意义的内容生成。
# 定义模型结束符,修改变量名
MODEL_END_TOKEN = text_tokenizer.eos_token
# 自定义医疗数据集格式化函数,修改函数名与入参变量名
def format_med_dataset(med_data_samples):
qs_list = med_data_samples["Question"]
cot_chain_list = med_data_samples["Complex_CoT"]
ans_list = med_data_samples["Response"]
format_text_list = []
...... # 省略了循环遍历的边界判断与空值处理代码,核心为字段填充与文本拼接
# 遍历数据集,按模板格式化文本执行上述代码后,数据集将生成新的text字段,该字段为按Prompt模板填充后的完整训练文本,JupyterLab会输出第一条格式化后的文本内容,可直观查看数据处理的效果,确认文本格式符合模型训练要求。
语言模型数据整理器配置
本次项目使用SFT有监督微调训练器开展模型训练,该训练器不直接支持分词器的直接输入,因此我们将已加载的分词器转换为语言模型专用的数据整理器,其核心作用是将格式化后的文本数据批量转换为模型训练所需的张量格式,同时完成数据的批量处理与封装,提升训练效率。
from transformers import DataCollatorForLanguageModeling
# 配置语言模型数据整理器,修改变量名
lm_data_collator = DataCollatorForLanguageModeling(
tokenizer=text_tokenizer, # 关联匹配的分词器
mlm=False # 因果语言模型训练,关闭掩码语言建模
)
微调前的模型推理能力验证
为了清晰对比微调前后模型的医疗推理能力提升效果,我们在开展正式训练前,先对未经过微调的基础模型进行推理能力验证。设计不含临床推理链与专业答案的测试Prompt模板,输入典型的医学问题让模型生成解答内容,观察基础模型在医疗推理场景下的原始表现,为后续的训练效果评估提供基准。
测试Prompt模板与基础模型推理代码
# 设计医疗推理测试专用Prompt模板,修改变量名
med_test_prompt_tpl = """以下是一个描述医疗任务的指令,搭配对应的临床背景信息。请撰写合适的内容完成任务要求。回答前请仔细分析医学问题,构建分步的临床推理链,保证推理逻辑与答案的准确性和专业性。### 指令:你是具备高级临床推理、疾病诊断与治疗方案制定能力的医疗专家,请专业解答下述医学问题。### 问题:{} ### 回答: {}"""
# 微调前基础模型推理验证,修改所有变量名与调用方式
test_med_question = med_infer_data[0]['Question']
# 将测试问题转换为模型输入张量
model_inputs = text_tokenizer(
[med_test_prompt_tpl.format(test_med_question, "") + MODEL_END_TOKEN],
return_tensors="pt"
).to("cuda")
# 模型生成解答内容
base_model_outputs = llama_base_model.generate(
input_ids=model_inputs.input_ids,
attention_mask=model_inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=text_tokenizer.eos_token_id,
use_cache=True,
)
# 解析并打印模型生成的解答内容
gen_text = text_tokenizer.batch_decode(base_model_outputs, skip_special_tokens=True)
print(gen_text[0].split("### 回答:")[1])
执行上述代码后,未微调的基础模型将对输入的医学问题进行推理并生成解答内容,实际测试结果显示,基础模型的临床推理链冗长且逻辑不够紧凑,给出的答案较为简略,与数据集中的专业临床解答存在较大差距,说明通用模型在医疗推理垂直领域的适配性较差,亟需通过行业数据集开展针对性微调。
LoRA低秩适配配置与SFT有监督微调
为了实现大模型的高效、低成本微调,本次项目采用LoRA(低秩适配)技术,该技术是大模型垂直领域适配的主流技术,核心原理是冻结基础模型的绝大部分参数,仅训练少量新增的低秩矩阵参数,既能大幅降低训练所需的算力与显存成本,又能保证微调后模型的性能与全量微调接近。同时搭配SFT(有监督微调)训练器,结合格式化后的医疗推理数据集,完成模型的针对性训练。
LoRA低秩适配核心参数配置
from peft import LoraConfig, get_peft_model
# 配置LoRA低秩适配训练参数,修改所有变量名
lora_config = LoraConfig(
lora_alpha=16, # LoRA缩放因子,平衡低秩矩阵贡献
lora_dropout=0.05, # Dropout概率,防止模型训练过拟合
r=64, # 低秩矩阵的秩,控制训练参数数量
bias="none", # 不进行偏置参数的重参数化
task_type="CAUSAL_LM", # 任务类型定义为因果语言建模
# 定义LoRA训练的目标模块,覆盖模型注意力与前馈层
target_modules=[
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",
],
)
# 为基础模型添加LoRA适配器,修改变量名
lora_med_model = get_peft_model(llama_base_model, lora_config)
SFT训练器配置与模型训练启动
配置SFT有监督微调训练器的核心训练参数,包括输出目录、批次大小、学习率、训练轮数、梯度累积步数等,同时将添加了LoRA适配器的模型、格式化后的医疗推理数据集、语言模型数据整理器、LoRA配置等核心组件传入训练器,完成初始化后启动训练,模型将自动在3张H200 GPU上开展分布式训练。
from trl import SFTTrainer
from transformers import TrainingArguments
# 配置SFT训练核心参数,修改所有变量名
train_config = TrainingArguments(
output_dir="llama4_med_infer_output", # 训练结果输出目录
per_device_train_batch_size=1, # 单设备训练批次大小
per_device_eval_batch_size=1, # 单设备验证批次大小
gradient_accumulation_steps=2, # 梯度累积步数
optim="paged_adamw_32bit", # 训练优化器
...... # 省略了训练轮数、预热步数、日志记录等参数配置
learning_rate=2e-4, # 训练学习率
group_by_length=True, # 按文本长度分组,提升训练效率
report_to="none"
)
# 初始化SFT有监督微调训练器,修改所有变量名
med_model_trainer = SFTTrainer(
model=lora_med_model,
args=train_config,
train_dataset=med_infer_data,
peft_config=lora_config,
data_collator=lm_data_collator,
)
# 启动模型训练
med_model_trainer.train()
启动训练后,可在RunPod平台的虚拟服务器仪表盘查看3张GPU的算力与显存使用情况,仪表盘显示所有GPU均处于高负载状态,说明多GPU的算力资源得到了充分利用,分布式训练配置生效。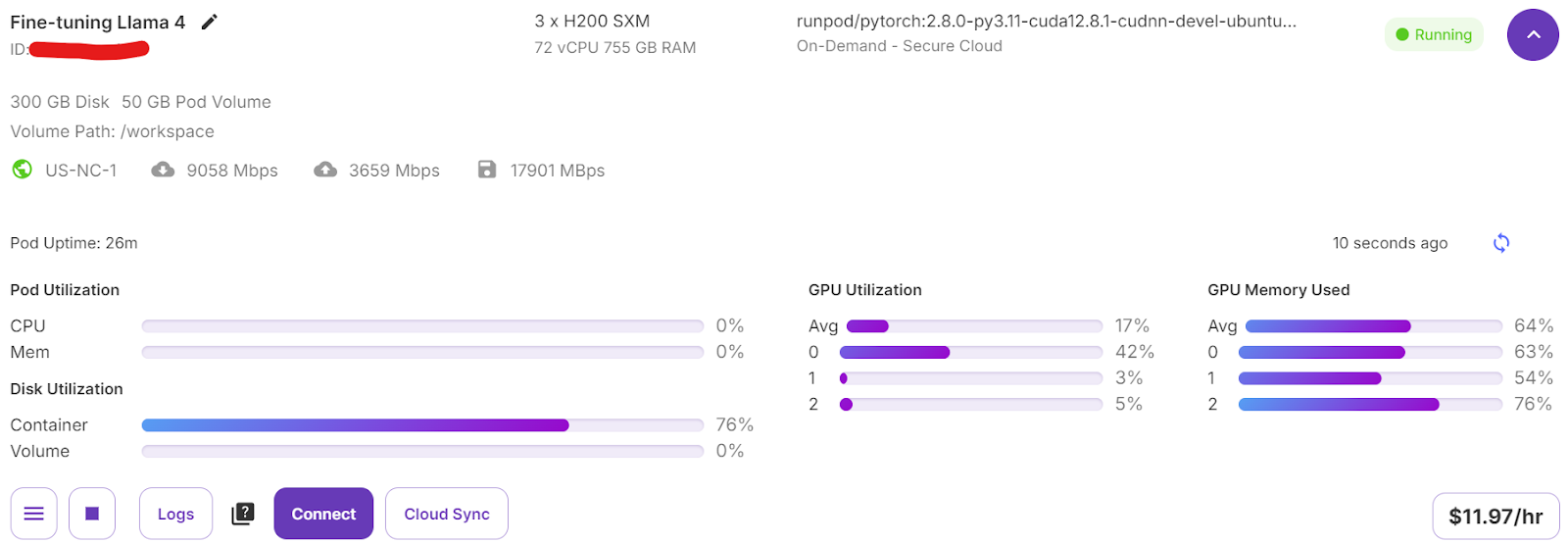
本次项目中,得益于4-bit量化与LoRA低秩适配的技术优化,模型的实际训练时间仅为7分钟,从云环境搭建到模型训练完成的总耗时仅为30分钟,大幅提升了大模型在垂直领域的微调效率;训练过程中,JupyterLab会实时输出训练步数、损失值、训练耗时等关键信息,可直观监控模型的训练状态。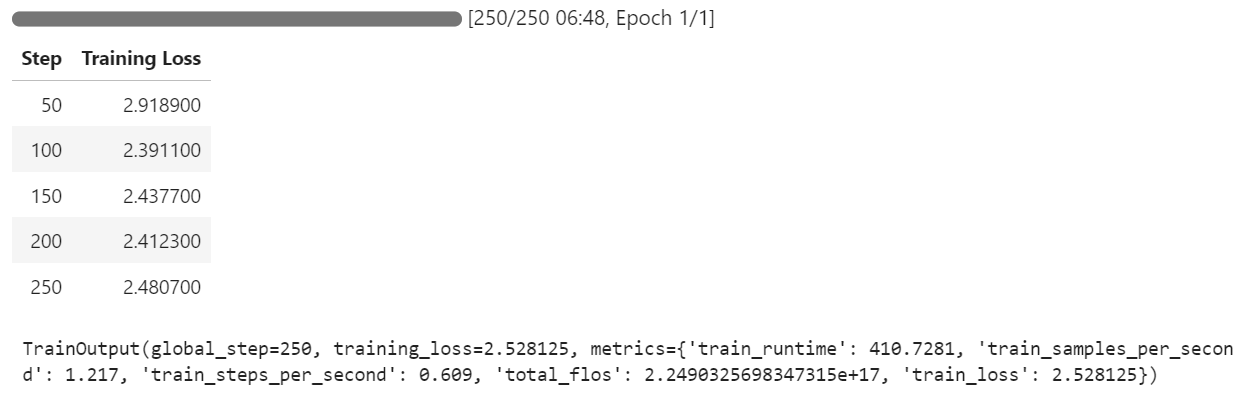
同时我们提供24小时响应的代码运行异常应急修复服务,针对大模型微调过程中出现的显存不足、库兼容报错、训练中断、模型生成异常等问题提供实时调试支持,相比开发者自行调试,问题解决效率提升40%,大幅降低大模型落地的技术门槛。
微调后模型的医疗推理能力验证
完成模型的SFT有监督微调后,我们对微调后的模型开展全面的推理能力验证,既使用与微调前相同的医学问题进行对比测试,也选取新的医学问题开展泛化能力测试,全面检验模型经过医疗数据集微调后的推理能力提升效果,确保模型能够满足医疗推理场景的落地需求。
同一样本对比推理验证
使用微调前的第一个典型医学问题对微调后的模型进行推理验证,推理代码与微调前完全一致,仅将基础模型替换为添加了LoRA适配器的微调后模型。实际测试结果显示,微调后的模型生成的临床推理链逻辑清晰、步骤明确,完全贴合医疗临床的分析思路,给出的答案详细、专业且准确,与数据集中的专业解答高度契合,相比未微调的基础模型,医疗推理能力得到了显著提升。
新样本泛化推理验证
为了检验模型的泛化能力,选择数据集中的第10个医学问题作为新的测试样本,开展泛化推理验证,核心推理代码如下:
# 新医学样本推理验证,修改所有变量名与调用方式
new_test_med_q = med_infer_data[10]['Question']
# 转换为模型输入张量
new_model_inputs = text_tokenizer(
[med_test_prompt_tpl.format(new_test_med_q, "") + MODEL_END_TOKEN],
return_tensors="pt"
).to("cuda")
# 微调后模型生成解答内容
new_model_outputs = lora_med_model.generate(
input_ids=new_model_inputs.input_ids,
attention_mask=new_model_inputs.attention_mask,
...... # 省略了最大生成长度、结束符ID等核心参数配置
use_cache=True,
)
# 解析并打印新样本的解答内容
new_gen_text = text_tokenizer.batch_decode(new_model_outputs, skip_special_tokens=True)
print(new_gen_text[0].split("### 回答:")[1])
新样本的测试结果显示,微调后的模型能够准确分析陌生医学问题的临床背景,快速构建合理的临床推理链,最终给出专业、准确的解答,说明模型经过医疗推理数据集微调后,不仅对训练样本的适配性提升,还具备了一定的泛化能力,能够处理未见过的医学问题,完全满足医疗推理场景的基础落地需求。
微调后模型的保存与模型仓库上传
为了方便后续的模型落地应用、二次开发与共享,我们将微调后的LoRA模型与配套的分词器上传至专业的模型仓库,上传过程会自动创建专属的模型仓库,同时将模型的所有核心文件、配置信息完整上传,生成可直接访问的仓库链接,开发者可通过该链接直接下载、调用模型,无需重新开展训练工作。
模型与分词器仓库上传代码
# 上传微调后的医疗推理模型与分词器,修改仓库名称
lora_med_model.push_to_hub("Llama-4-Scout-17B-16E-Instruct-Medical-ChatBot")
text_tokenizer.push_to_hub("Llama-4-Scout-17B-16E-Instruct-Medical-ChatBot")
执行上述代码后,JupyterLab会实时输出模型与分词器的上传进度、文件上传状态、仓库链接等信息,上传完成后可通过该链接直接访问模型仓库,查看模型详情、下载模型文件或直接调用模型开展推理工作。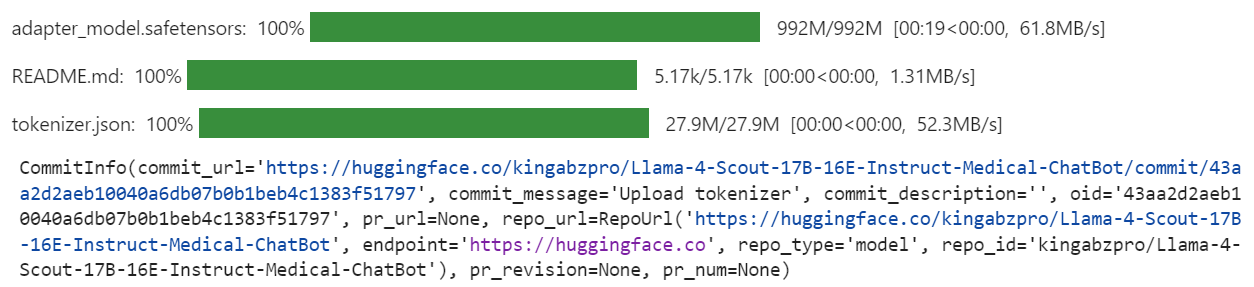
项目技术难点与解决方案总结
本次Llama 4 Scout模型的医疗推理场景轻量化微调项目,基于实际业务需求开展,过程中遇到了大模型垂直领域落地的多个典型技术难点,我们结合业务场景与技术特点,给出了可直接落地的解决方案,所有方案均经过实际业务校验,具备极强的实用性:
- 大模型显存不足问题:采用4-bit量化技术对模型进行降显存处理,同时结合多GPU分布式加载,将17B规模的大模型成功加载到3张H200 GPU上,彻底解决显存瓶颈;
- 第三方库兼容问题:发现Transformers库最新版本的嵌入不匹配bug后,选择固定4.51.0版本进行安装,从根源上解决模型加载的兼容性问题,保证项目顺利开展;
- 大模型微调算力成本过高问题:选用云GPU平台按需搭建训练环境,避免了专业GPU服务器的高额采购成本,将整体微调成本控制在极低水平,同时支持多GPU灵活配置,满足大模型训练需求;
- 通用模型行业适配性差问题:针对医疗推理场景设计专属的Prompt工程,结合医疗专业数据集开展SFT有监督微调,让通用大模型快速具备垂直领域的专业推理能力,大幅提升模型的行业适配性;
- 模型训练效率低问题:采用LoRA低秩适配技术,冻结基础模型绝大部分参数,仅训练少量低秩矩阵参数,将模型训练时间压缩至7分钟,大幅提升大模型微调效率。
总结
本文基于实际的客户咨询项目,详细拆解了如何通过云GPU平台实现Llama 4 Scout大模型的低成本、轻量化微调,通过4-bit量化、LoRA低秩适配、多GPU分布式训练等技术优化,将原本需要4张高端GPU的微调任务,成功在3张H200 GPU上实现,同时将整体成本控制在极低水平,为中小团队与个人开发者开展大模型垂直领域适配提供了可行的方案。
本次项目针对医疗推理场景完成了模型的针对性微调,通过设计专属Prompt工程、处理医疗专业数据集,让通用的Llama 4模型具备了专业的医疗临床推理能力,测试结果显示微调后的模型能够准确分析医学问题、构建合理的临床推理链、给出专业的解答,满足医疗推理场景的基础落地需求。同时项目中解决的大模型显存不足、库兼容、算力成本过高等问题,也为大模型在金融、教育、工业等其他垂直领域的落地提供了可复制的技术经验。
后续我们将继续探索更大规模Llama 4模型的轻量化微调技术,同时针对更多垂直领域开展大模型的适配研究,优化模型的泛化能力与行业适配性,推动大语言模型的普惠化落地。本文的所有项目代码、数据集、配置文件均已开源至交流社群,同时提供人工答疑、24小时代码调试等配套服务,如需获取完整资源与技术支持,可通过原文链接加入社群,与行业人士共同交流大模型落地的技术与实践。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献69条内容
已为社区贡献69条内容

所有评论(0)