OpenClaw 叠加Opus直接赛博飞升(原 Clawdbot) 深度解析:打造拥有“永久记忆”的本地 AI 智能体
OpenClaw (Clawdbot) 的成功证明了透明性优于黑箱的理念。通过将记忆回归到最朴素的 Markdown 文件,结合 SQLite 的现代搜索能力,它构建了一个既强大又完全可控的个人 AI 助手。在这个 AI 飞速发展的时代,拥有一个真正属于你、运行在本地、记忆可查可改的 AI 伙伴,或许才是“个人助理”的终极形态
OpenClaw 叠加Opus直接赛博飞升 (原 Clawdbot) 深度解析:打造拥有“永久记忆”的本地 AI 智能体
前言:在 AI 助手领域,仅仅几周时间,Clawdbot(因商标原因现已更名为 OpenClaw)就完成了一个神话——从个人项目到 GitHub 斩获 100,000+ 颗星的现象级工具。由 Peter Steinberger(PSPDFKit 创始人)构建,这款采用 MIT 许可证的开源助手,正在重新定义我们与 AI 的交互方式。
与运行在云端的 ChatGPT 或 Claude 不同,OpenClaw 选择了一条“硬核”路线:本地运行、全系统权限、以及最令人着迷的——基于纯文本文件的持久化记忆系统。
Claude直连平台 🔗Weelinking Opus4.6。 第一时间体验 Opus4.6
🚀 为什么 OpenClaw 与众不同?
在当今的 AI 产品生态中,记忆(Memory)通常是一个黑盒。你无法查看 ChatGPT 到底记住了关于你的什么信息,也无法直接编辑它。
OpenClaw 采取了截然不同的方法:彻底的透明化与本地化。
它不仅是一个聊天机器人,更是一个能自主处理现实世界任务的代理(Agent)。它能管理电子邮件、安排日历、甚至通过 Discord、WhatsApp 或 Telegram 与你即时通讯。但它最核心的护城河在于其全天候的上下文保留能力——它不是把记忆存在某家公司的云端数据库里,而是将其作为 Markdown 文件保存在你的硬盘上,让你拥有 100% 的控制权。
背景补充:OpenClaw 的架构核心是一个名为“Gateway”的守护进程,它连接了你的本地环境与外部消息平台,使 AI 能够像“数字员工”一样 24/7 待命,甚至具备“Heartbeat(心跳)”功能——能够主动醒来执行任务,而不仅仅是被动等待指令。

Claude直连平台 🔗Weelinking Opus4.6。 第一时间体验 Opus4.6
🧠 上下文构建:模型看到了什么?
要理解 OpenClaw 的记忆机制,首先得知道它在处理每一次用户请求时,究竟“看”到了什么。它的输入并非只有当前的对话,而是一个精心分层的“上下文三明治”:
- [0] 系统提示词 (System Prompt):静态指令与条件逻辑,定义了它是谁。
- [1] 项目上下文 (Project Context):这是 OpenClaw 的灵魂所在,由一组用户可编辑的 Markdown 文件引导。
- [2] 对话历史 (Conversation History):消息流、工具调用记录以及被压缩的摘要。
- [3] 当前消息 (Current Message):你刚刚发送的内容。
Claude直连平台 🔗Weelinking Opus4.6。 第一时间体验 Opus4.6
核心引导文件
这些文件直接位于智能体的工作区(默认为 ~/clawd/),构成了智能体的“人格”与“职责”。由于它们只是普通的 Markdown 文件,你可以随时用任何文本编辑器修改它们,从而实时改变 AI 的行为:
| 文件名 | 用途 | 关键点 |
|---|---|---|
| AGENTS.md | 智能体核心指令 | 包含记忆指南,告诉 AI 何时读写记忆,以及它的核心任务边界 |
| SOUL.md | 个性与语调 | 定义 AI 是幽默、严肃还是专业(例如:“你是一个喜欢用 emoji 的高效助手”) |
| USER.md | 用户画像 | 关于你的事实(如:你是谁,偏好什么语言,工作习惯等) |
| TOOLS.md | 工具手册 | 外部工具的使用说明,指导 AI 如何调用 API 或本地脚本 |
💾 上下文 (Context) vs. 记忆 (Memory)
这是理解 OpenClaw 架构最关键的分野。很多人混淆了这两个概念,但在 OpenClaw 中它们泾渭分明。
Claude直连平台 🔗Weelinking Opus4.6。 第一时间体验 Opus4.6
1. 上下文 (Context)
- 定义:模型在单次 API 请求中看到的所有内容(系统提示词 + 历史 + 附件)。
- 特性:
- 临时性:仅为当前请求存在。
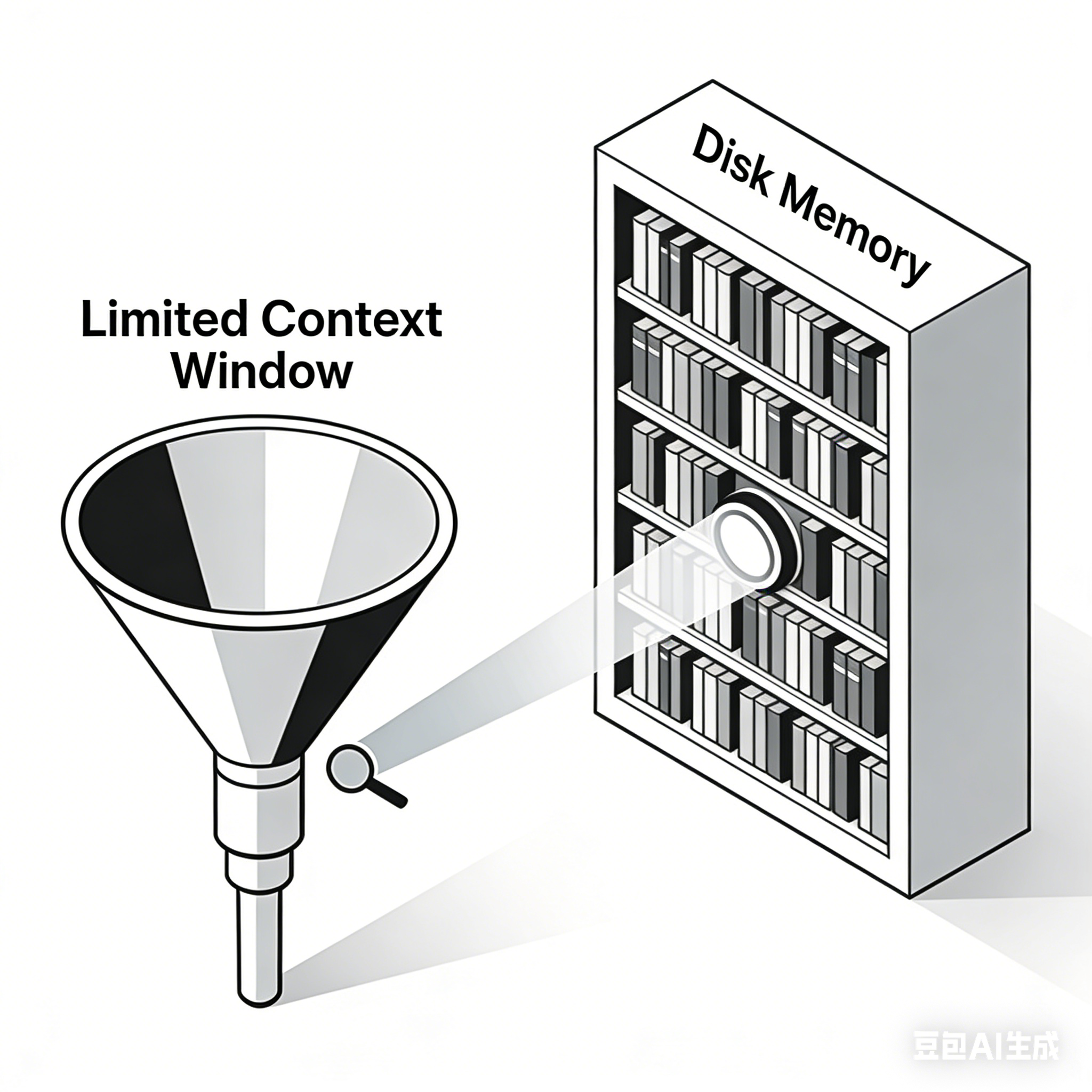
- 有界性:受限于模型的 Context Window(如 Claude 3.5 的 200K token)。一旦超出,旧信息必须被丢弃。
- 昂贵:每一个 token 都要计费,且上下文越长,API 响应速度越慢。
2. 记忆 (Memory)
- 定义:存储在磁盘上的持久化内容。
- 公式:
记忆 = MEMORY.md + memory/*.md + 会话记录 (Transcripts) - 特性:
- 持久性:重启电脑、过几个月后依然存在。
- 无界性:可以无限增长,不受 Token 限制(只受硬盘空间限制)。
- 廉价:存储纯文本几乎零成本。
- 可搜索:通过向量索引进行语义检索,AI 可以在数秒内找到几个月前的一条笔记。
!
🛠️ 记忆的读写机制
OpenClaw 没有黑魔法,它通过两个专用工具(Tools)让 AI 像人类查阅资料一样访问记忆。
1. 记忆检索 (memory_search)
这是强制性的回忆步骤。在回答关于以前的工作、决策或偏好之前,AI 必须先“查阅大脑”。
{
"name": "memory_search",
"description": "强制性回忆步骤:在回答有关先前工作、决策、日期、人物、偏好或待办事项的问题之前,对 MEMORY.md + memory/*.md 进行语义搜索",
"parameters": {
"query": "我们关于 API 的决定是什么?",
"maxResults": 6,
"minScore": 0.35
}
}
注意 minScore: 0.35,这过滤掉了低相关性的结果,防止 AI 被无关记忆干扰。
Claude直连平台 🔗Weelinking Opus4.6。 第一时间体验 Opus4.6
2. 记忆读取 (memory_get)
搜索定位到文件后,AI 使用此工具精确读取特定行。这模拟了人类“翻开书本阅读特定段落”的行为。
{
"name": "memory_get",
"description": "在 memory_search 后,从记忆文件中读取特定行",
"parameters": {
"path": "memory/2026-01-20.md",
"from": 45,
"lines": 15
}
}
3. 记忆写入
没有专门的 memory_write 工具。为什么?因为记忆就是文件。AI 使用通用的 write 和 edit 工具来直接修改 Markdown 文件。这不仅简化了工具集,还意味着你可以手动打开这些文件进行编辑,后台会自动重新索引,这种“人机共治”的记忆模式非常优雅。
📂 双层记忆存储架构
OpenClaw 的记忆系统设计得非常像人类的笔记习惯,分为“流水账”和“精炼知识”。
第 1 层:每日日志 (memory/YYYY-MM-DD.md)
这是**仅追加(Append-only)**的每日笔记。AI 全天都在此记录琐事、临时想法和即时发生的对话。它相当于 AI 的“短期记忆流”或“日记”。
2026-01-26.md 示例:
- 上午 10:30:与用户讨论了 REST vs GraphQL。决定使用 REST。
- 下午 02:15:部署了 v2.3.0,一切正常。
- 下午 04:00:用户提到他更喜欢 TypeScript。
第 2 层:长期精选 (MEMORY.md)
这是经过**整理(Curated)**的知识库。当 AI 意识到某个信息具有长期价值(如重大架构决策、关键联系人、用户核心偏好)时,它会将其提炼并写入此文件。
MEMORY.md 示例:
- 用户偏好:首选 TypeScript,讨厌冗长的解释。
- 重要决策:2026-01-20 确定采用 REST 架构。
- 关键联系人:Alice 是设计负责人。
⚙️ 幕后技术:索引与混合搜索
当你或 AI 保存一个记忆文件时,后台会发生一系列复杂的处理,确保这些文本能被机器理解。
Claude直连平台 🔗Weelinking Opus4.6。 第一时间体验 Opus4.6
流程解析
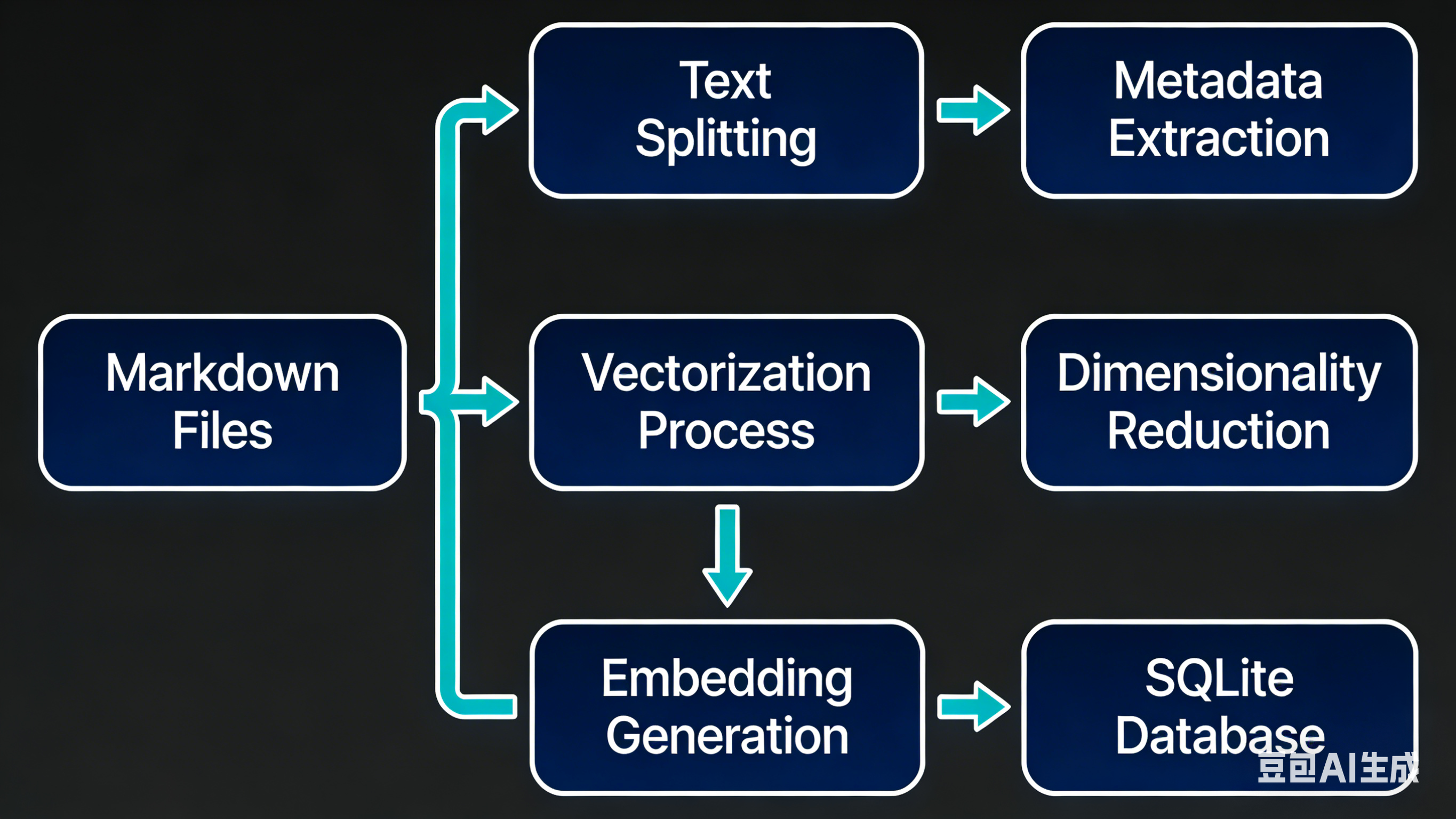
- 文件监听:
Chokidar库监控文件变更(防抖 1.5秒),确保快速写入不会导致重复索引。 - 分块 (Chunking):将文本分割成约 400 token 的块,并保留 80 token 的重叠(Overlap)。重叠至关重要,它确保了跨越块边界的事实(例如一句话被切成两半)能在两个块中都被完整捕获。
- 嵌入 (Embedding):将文本块发送给 OpenAI/Gemini 或本地模型,转化为 1536 维的向量(Vector)。
- 存储:存入
~/.clawdbot/memory/<agentId>.sqlite。
为什么选择 SQLite?
OpenClaw 并没有使用 Pinecone 或 Milvus 等重量级向量数据库,而是使用了 sqlite-vec(向量搜索扩展)和 FTS5(全文搜索扩展)。这使得它无需依赖外部服务,只需一个轻量级的 .sqlite 文件即可运行。
混合搜索策略 (Hybrid Search)
OpenClaw 并行运行两种搜索,通过加权评分组合结果:
- 向量搜索 (70% 权重):查找语义相似的内容(搜“数据库”能找到“PostgreSQL”)。
- BM25 关键词搜索 (30% 权重):查找精确匹配(搜具体的错误代码或 ID)。
公式:最终得分 = (0.7 * 向量得分) + (0.3 * 文本得分)
这种 70/30 的混合策略解决了纯向量搜索常常忽略精确术语(如人名、日期)的痛点,确保了无论是模糊的概念搜索还是精确的事实查找,都能得到最佳结果。
📉 压缩与修剪:对抗上下文膨胀
即便拥有 200K 甚至 1M 的上下文窗口,长对话最终也会将其填满。OpenClaw 设计了两套机制来应对“遗忘”。
1. 智能压缩 (Compaction)
当上下文接近上限时,系统会将早期的对话总结为一个紧凑的摘要,写入 JSONL 格式的会话记录中,只保留最近的消息原样不动。
关键机制:预压缩刷新 (Pre-compaction Flush)
在压缩发生前,系统会触发一个静默的“记忆刷新”动作。系统会提示 AI:“会话即将压缩,快把重要的东西写进磁盘!” 这确保了关键决策不会因为压缩成摘要而丢失细节。这是防止 AI 变“笨”的关键一步。
2. Cache-TTL 修剪
这是为了省钱。Anthropic 等提供商会缓存 Prompt 前缀(TTL 通常为 5 分钟)。
- 如果缓存有效,Token 成本极低(约降低 90%)。
- 如果缓存失效(例如你去吃了个午饭回来),重新发送整个历史记录非常昂贵。
OpenClaw 会检测缓存是否过期。如果过期,它会在发送请求前自动修剪掉旧的大型工具输出(如几万行的 npm install 日志),只保留结果摘要。这是一种极其聪明的成本优化策略。
Claude直连平台 🔗Weelinking Opus4.6。 第一时间体验 Opus4.6
🌐 多智能体与隔离
OpenClaw 支持多个智能体共存,且默认物理隔离。
- 工作智能体:
~/clawd-work/ - 个人智能体:
~/clawd-personal/
每个智能体有独立的 .sqlite 索引和 Markdown 目录。除非你显式允许,否则它们无法通过 memory_search 搜索到对方的记忆。
AI 智能体可以读取彼此的记忆吗? 默认情况下不能。这为“工作”与“生活”的分离提供了天然的保障。例如,你的“个人智能体”不会在搜索周末计划时,意外读取到你“工作智能体”中的保密代码。
结语
OpenClaw (Clawdbot) 的成功证明了**“透明性优于黑箱”**的理念。通过将记忆回归到最朴素的 Markdown 文件,结合 SQLite 的现代搜索能力,它构建了一个既强大又完全可控的个人 AI 助手。
在这个 AI 飞速发展的时代,拥有一个真正属于你、运行在本地、记忆可查可改的 AI 伙伴,或许才是“个人助理”的终极形态。
Claude直连平台 🔗Weelinking Opus4.6。 第一时间体验 Opus4.6
参考资料
- OpenClaw GitHub 仓库 (原 Clawdbot)
- Peter Steinberger 的 X (Twitter)
- Opus4.6直连站

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)