基于yolo11的目标检测模型(护目镜、门开关检测、三脚架、反光背心、五点式安全带等)
收集 & 标注护目镜数据(YOLO 格式)按 7:2:1 划分 train/val/test使用 YOLO11 Nano 在 CPU 上训练在测试集上评估 Precision / Recall / mAP在图片、视频上实际推理验证效果具体项目的细节参见我项目中发布的readme文档前端页面展示如下项目地址主页还有其他个人制作的小工具kyf666plus。
下面的介绍是AI生成的,看看就好,主要以护目镜为例,项目的拉取链接放在文末
想要的直接取拿就行
用 YOLO11 + 自建数据集,打造一个「护目镜佩戴检测」AI 模型(从零到上线)
- 实时检测现场人员是否佩戴护目镜
这篇文章完整展示:如何从零开始,构建一个 YOLO11 护目镜检测模型,包括:
- 数据集准备与划分
- YOLO 格式标注说明
- 模型训练(含 CPU 环境配置)
- 模型评估(Precision / Recall / mAP)
- 实际图片 & 视频推理演示思路
一、项目场景与目标
场景设定:
- 现场监控视频/摄像头画面中,有人进入危险区域;
- 要求这些人员必须佩戴护目镜;
- 我们希望能自动检测画面中是否有人佩戴护目镜,如果检测到,给出框选提示(如画面上叠加检测框)。
本项目目标:
- 只检测一个类别:
护目镜(goggles) - 输入:任意现场图片或视频帧
- 输出:标框 + 置信度
在实现上,我们采用 YOLO11 的 Nano 模型(yolo11n),原因是:
- 模型足够轻量,方便在 CPU 上训练和推理
- Ultralytics 接口统一、易于上手
- 生态成熟,有大量文档与工具
二、数据集准备:自建护目镜检测数据集
项目中,我们将护目镜的数据集统一放在:
D:\数据集标注\护目镜\
├── images\
│ ├── 0001.jpg
│ ├── 0002.jpg
│ └── ...
└── labels\
├── 0001.txt
├── 0002.txt
└── ...
images/:存放所有图片(原始采集的现场画面、截图等)labels/:对应 YOLO 格式的标注文件- 命名规则:
0001.jpg对应0001.txt,一一对应
YOLO 标注格式回顾
YOLO 的每一行标注格式为:
<class_id> <x_center> <y_center> <width> <height>
- 坐标全部是 相对值(0~1),不是像素
- 对于护目镜,我们只有一个类别,所以
class_id = 0 - 若一张图上有多副护目镜,就写多行,每行一个框
一个示例标注(0001.txt)
0 0.432125 0.515224 0.163451 0.087532
表示:
- 类别 0(护目镜)
- 中心点在整张图片相对坐标
(0.432, 0.515) - 宽度约
0.163,高度约0.087
三、数据集划分:train / val / test
为了避免训练和测试混在一起,我们需要把数据集划分为:
- 训练集(train):用于模型学习
- 验证集(val):用于调参 & Early Stop
- 测试集(test):用于最终评估
我们编写了一个小脚本,自动将 images/ 和 labels/ 按 7:2:1 划分为 train/val/test,并保持图像与标注文件一一对应。
# split_goggles_dataset.py
import shutil
from pathlib import Path
from sklearn.model_selection import train_test_split
def split_goggles_dataset(
images_dir=r"D:\数据集标注\护目镜\images",
labels_dir=r"D:\数据集标注\护目镜\labels",
output_root=r"D:\数据集标注\护目镜_yolo_format",
train_ratio=0.7,
val_ratio=0.2,
test_ratio=0.1,
random_state=42,
):
images_dir = Path(images_dir)
labels_dir = Path(labels_dir)
output_root = Path(output_root)
assert abs(train_ratio + val_ratio + test_ratio - 1.0) < 1e-6
# 收集所有图像文件
exts = {".jpg", ".jpeg", ".png", ".bmp", ".tif", ".tiff"}
images = [p for p in images_dir.iterdir() if p.suffix.lower() in exts]
print(f"共找到 {len(images)} 张图片")
# 过滤有标注的
valid_images = []
for img in images:
label = labels_dir / f"{img.stem}.txt"
if label.exists():
valid_images.append(img)
else:
print(f"⚠️ 无对应标注,跳过: {img.name}")
print(f"可用图片: {len(valid_images)}")
# 划分 train / temp
train_imgs, temp_imgs = train_test_split(
valid_images, train_size=train_ratio, random_state(random_state), shuffle=True
)
# 在 temp 中再划分 val / test
val_ratio_adjusted = val_ratio / (val_ratio + test_ratio)
val_imgs, test_imgs = train_test_split(
temp_imgs, train_size=val_ratio_adjusted, random_state=random_state, shuffle=True
)
splits = {
"train": train_imgs,
"val": val_imgs,
"test": test_imgs,
}
# 创建目录并拷贝文件
for split_name, split_imgs in splits.items():
img_out = output_root / "images" / split_name
lbl_out = output_root / "labels" / split_name
img_out.mkdir(parents=True, exist_ok=True)
lbl_out.mkdir(parents=True, exist_ok=True)
for img_path in split_imgs:
label_path = labels_dir / f"{img_path.stem}.txt"
shutil.copy2(img_path, img_out / img_path.name)
shutil.copy2(label_path, lbl_out / label_path.name)
print(f"{split_name}: {len(split_imgs)} 张图片")
# 生成 YOLO data.yaml
yaml_path = output_root / "data.yaml"
yaml_content = f"""path: {output_root.as_posix()}
train: images/train
val: images/val
test: images/test
nc: 1
names:
0: goggles
"""
with open(yaml_path, "w", encoding="utf-8") as f:
f.write(yaml_content)
print(f"✅ 数据集划分完成,配置文件: {yaml_path}")
if __name__ == "__main__":
split_goggles_dataset()
执行:
python split_goggles_dataset.py
执行后,你会得到:
D:\数据集标注\护目镜_yolo_format\
├── images\
│ ├── train\
│ ├── val\
│ └── test\
├── labels\
│ ├── train\
│ ├── val\
│ └── test\
└── data.yaml
这就是 YOLO 官方推荐的数据集组织结构。
四、模型训练:基于 YOLO11 Nano(yolo11n)
我们使用 Ultralytics 的 YOLO11 接口进行训练。为了照顾大多数没有 GPU 的环境,特别准备了 CPU 训练版本。
安装依赖
pip install ultralytics
训练脚本
# train_goggles_model.py
from ultralytics import YOLO
from pathlib import Path
def train_goggles_model():
data_yaml = r"D:\数据集标注\护目镜_yolo_format\data.yaml"
if not Path(data_yaml).exists():
print(f"❌ data.yaml 未找到: {data_yaml}")
return
print("🚀 开始训练护目镜检测模型...")
# 加载 YOLO11 Nano 预训练模型
model = YOLO("yolo11n.pt")
results = model.train(
data=data_yaml,
epochs=80, # 视数据量/硬件可调整
imgsz=640,
batch=8, # CPU 可适当调小
device="cpu", # 若有 GPU 可改为 0
workers=2,
name="goggles_detection",
project="runs/detect",
# 适度数据增强
hsv_h=0.015,
hsv_s=0.7,
hsv_v=0.4,
translate=0.1,
scale=0.5,
fliplr=0.5,
mosaic=1.0,
mixup=0.0,
patience=20, # 早停
save=True,
plots=True,
verbose=True,
)
print("\n✅ 训练完成!")
print("最佳模型保存路径:runs/detect/goggles_detection/weights/best.pt")
return results
if __name__ == "__main__":
train_goggles_model()
运行:
python train_goggles_model.py
训练过程中,YOLO 会自动输出损失曲线、PR 曲线、混淆矩阵等图表,保存在 runs/detect/goggles_detection/ 目录下。
五、模型评估:Precision、Recall、mAP
训练完成后,我们需要在 测试集 上评估模型质量,而不是用训练集自嗨。
# eval_goggles_model.py
from ultralytics import YOLO
from pathlib import Path
def eval_goggles_model():
model_path = r"runs/detect/goggles_detection/weights/best.pt"
data_yaml = r"D:\数据集标注\护目镜_yolo_format\data.yaml"
if not Path(model_path).exists():
print(f"❌ 模型文件不存在: {model_path}")
return
model = YOLO(model_path)
print("📊 在测试集上评估模型性能...")
metrics = model.val(
data=data_yaml,
split="test", # 使用我们划分好的 test 集
imgsz=640,
batch=8,
device="cpu", # GPU 则改为 0
)
print("\n📈 评估结果(test 集):")
print(f"mAP50: {metrics.box.map50:.4f}")
print(f"mAP50-95: {metrics.box.map:.4f}")
print(f"Precision: {metrics.box.mp:.4f}")
print(f"Recall: {metrics.box.mr:.4f}")
print("\n详细评估图表保存在:runs/detect/val/(或训练对应目录下)")
if __name__ == "__main__":
eval_goggles_model()
执行:
python eval_goggles_model.py
你会得到类似这样的指标(举例):
mAP50: 0.93
mAP50-95: 0.78
Precision: 0.91
Recall: 0.89
- 若需要尽量避免误报(宁愿漏检也不要误检),就关注 Precision
- 若需要尽量不漏掉没有戴护目镜的人,就关注 Recall
- mAP50-95 反映整体检测能力,可以作为综合指标
六、实际推理:图片 & 视频上的护目镜检测
训练好的模型不仅可以评估,还可以直接用于推理。
1. 图片推理示例
# demo_infer_images.py
from ultralytics import YOLO
from pathlib import Path
def demo_infer_images():
model_path = r"runs/detect/goggles_detection/weights/best.pt"
model = YOLO(model_path)
source_dir = Path(r"D:\数据集标注\护目镜\demo_images") # 放一些待测试图片
output_dir = Path("runs/detect/goggles_demo_images")
for img in source_dir.glob("*.jpg"):
print(f"检测:{img.name}")
model.predict(
source=str(img),
save=True,
project=str(output_dir),
name="",
exist_ok=True,
conf=0.25, # 置信度阈值
)
print(f"✅ 结果已保存到:{output_dir}")
if __name__ == "__main__":
demo_infer_images()
输出的图片会自动叠加检测框和置信度,非常适合演示和效果展示。
2. 视频推理示例(比如监控画面或现场视频)
# demo_infer_video.py
from ultralytics import YOLO
from pathlib import Path
def demo_infer_video():
model_path = r"runs/detect/goggles_detection/weights/best.pt"
model = YOLO(model_path)
video_path = r"D:\数据集标注\护目镜\demo_video\scene1.mp4"
output_dir = Path("runs/detect/goggles_demo_video")
model.predict(
source=video_path,
save=True,
project=str(output_dir),
name="scene1",
exist_ok=True,
conf=0.25,
)
print(f"✅ 视频检测结果保存在:{output_dir / 'scene1'}")
if __name__ == "__main__":
demo_infer_video()
这一步就把模型从“论文里走出来”,变成真正可用的工具。
七、可以落地在哪些场景?
这个护目镜检测模型,本质上是一个 “单类别目标检测” 模型,适合在以下场景中扩展和复用:
- 工业现场:检测护目镜、安全帽、反光衣等 PPE(Personal Protective Equipment)
- 实验室:实验人员是否佩戴护目镜、手套、口罩
- 建筑工地:识别安全防护用品的佩戴情况
- 学校/培训:用于教学演示,帮助学生理解计算机视觉项目从零到一的全过程
仅需替换数据集,就可以很快构建出新的安全检测模型。
八、总结:从「数据」到「模型」的闭环
这次护目镜检测项目,完整走了一遍:
- 收集 & 标注护目镜数据(YOLO 格式)
- 按 7:2:1 划分 train/val/test
- 使用 YOLO11 Nano 在 CPU 上训练
- 在测试集上评估 Precision / Recall / mAP
- 在图片、视频上实际推理验证效果
具体项目的细节参见我项目中发布的readme文档
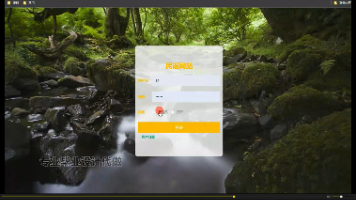
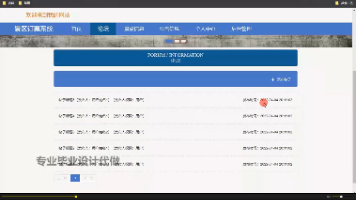
前端页面展示如下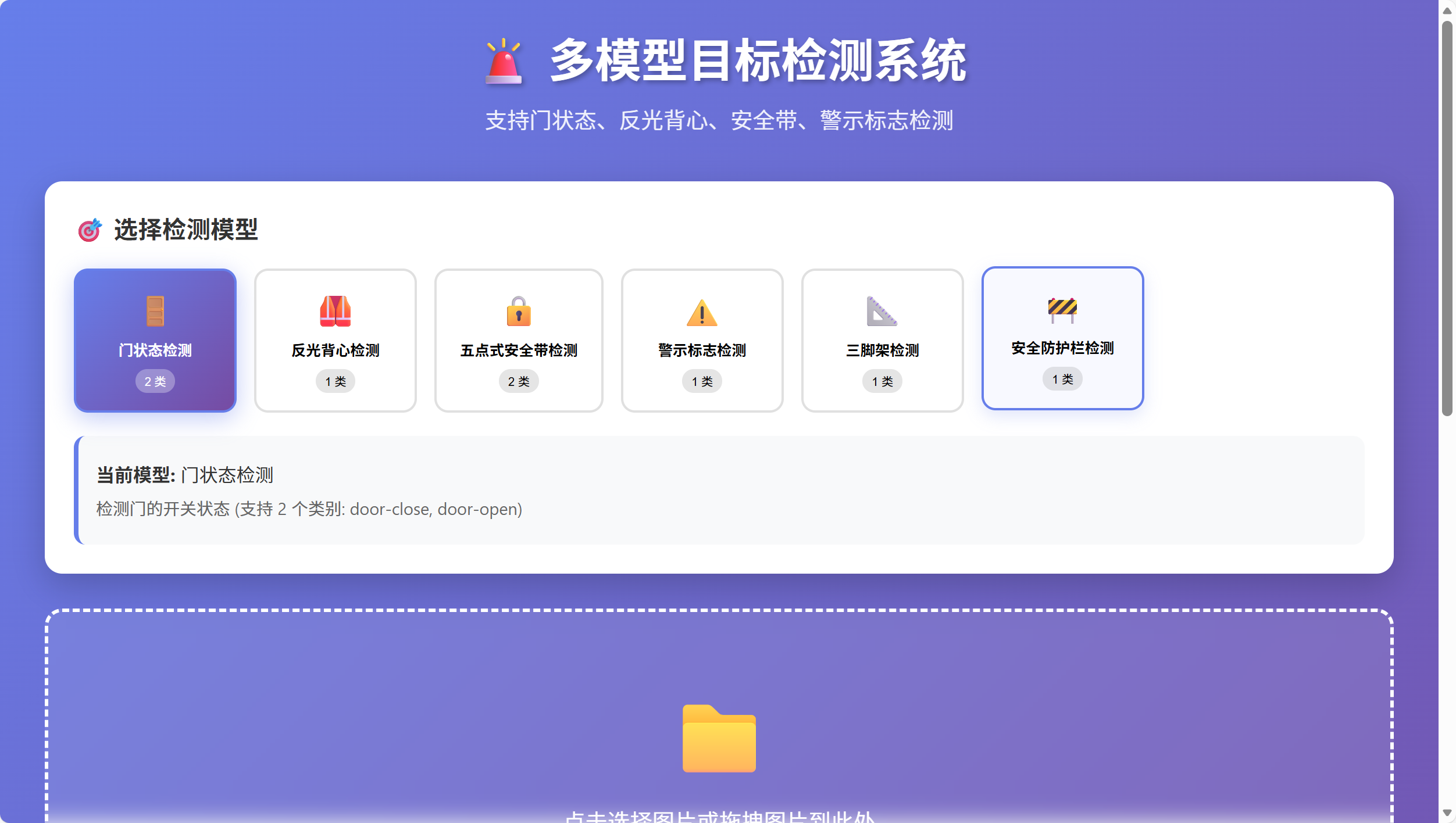
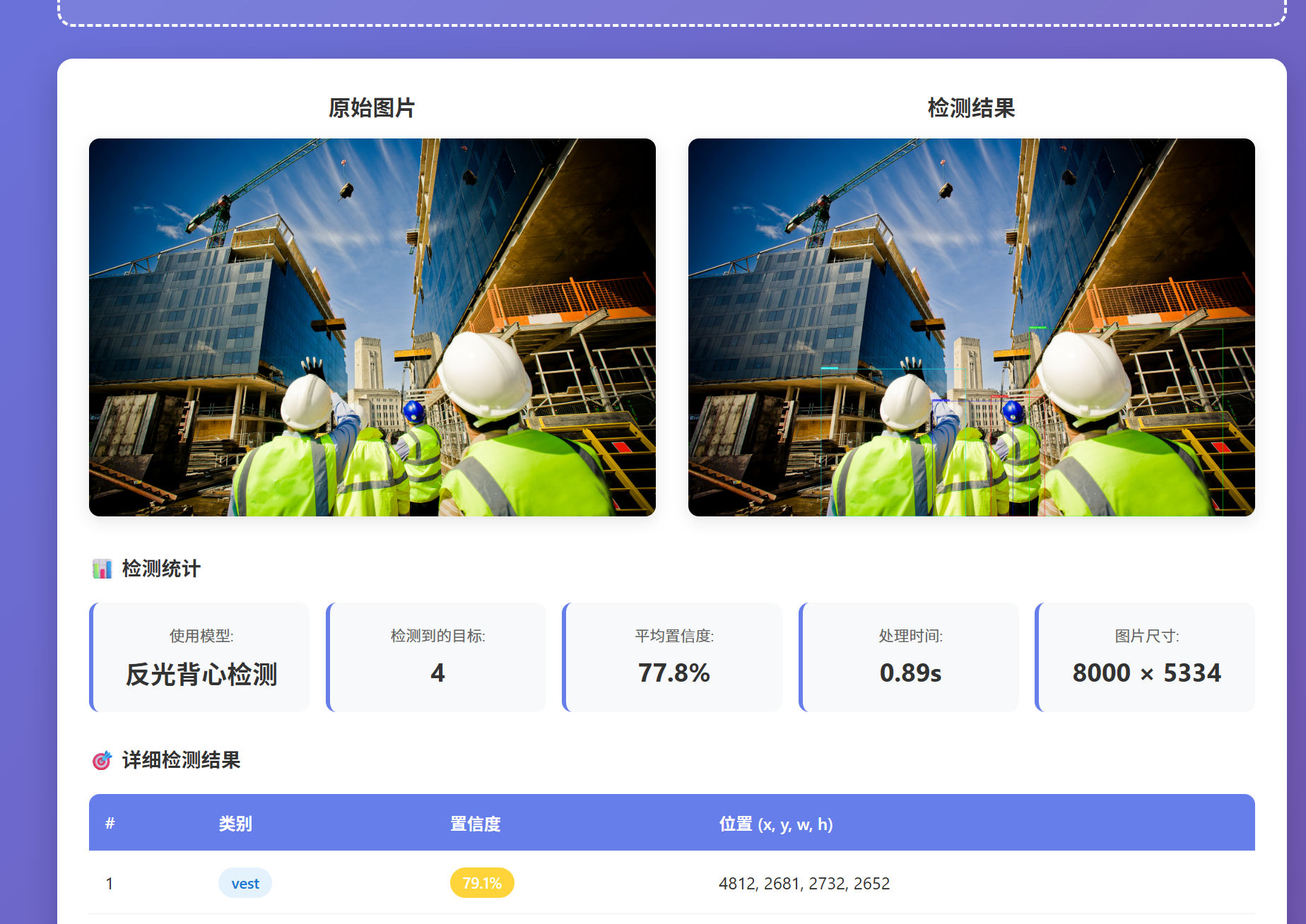
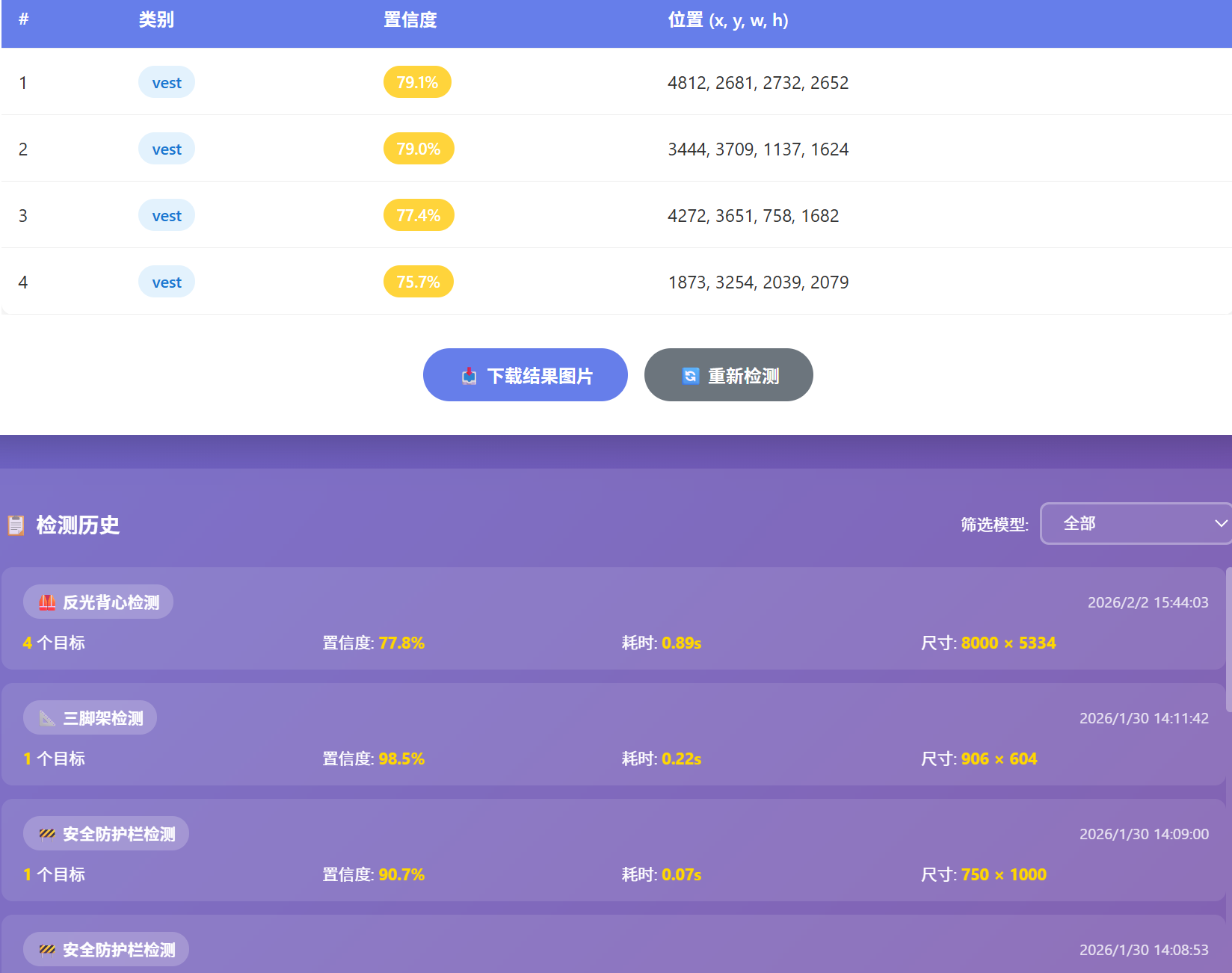
项目地址
https://github.com/kyf666plus/yolo11-.git
主页还有其他个人制作的小工具
kyf666plus

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)