【Azure 架构师学习笔记 】- Azure AI(4)-数据工程在AI系统中的设计(ADF+ADLS+Azure ML)
在上一文中, 我们看到了ADLS 分层设计, 数据版本控制等数据工程的理念在Azure中的实现, 现在加入对Azure ML的实现,构建「可追溯、可复现、可扩展」的AI数据供给体系。我们不是“把数据喂给ML”,而是设计让数据持续健康流动的循环系统。备注:因为在实操过程出现了一些小失误,而目前我们使用数据类型为V2 API, 不支持物理删除,所以只能通过命名其他的方式来重做,因此截图中会出现一些上下
本文属于【Azure 架构师学习笔记】系列。
本文属于【Azure AI】系列。
接上文 【Azure 架构师学习笔记】 - Azure AI(3)-数据工程在AI系统中的设计(ADF+ADLS)
前言
在上一文中, 我们看到了ADLS 分层设计, 数据版本控制等数据工程的理念在Azure中的实现, 现在加入对Azure ML的实现,构建「可追溯、可复现、可扩展」的AI数据供给体系。
我们不是“把数据喂给ML”,而是设计让数据持续健康流动的循环系统。
备注:因为在实操过程出现了一些小失误,而目前我们使用数据类型为V2 API, 不支持物理删除,所以只能通过命名其他的方式来重做,因此截图中会出现一些上下图片名字差异,但是不影响实际的完整流程。
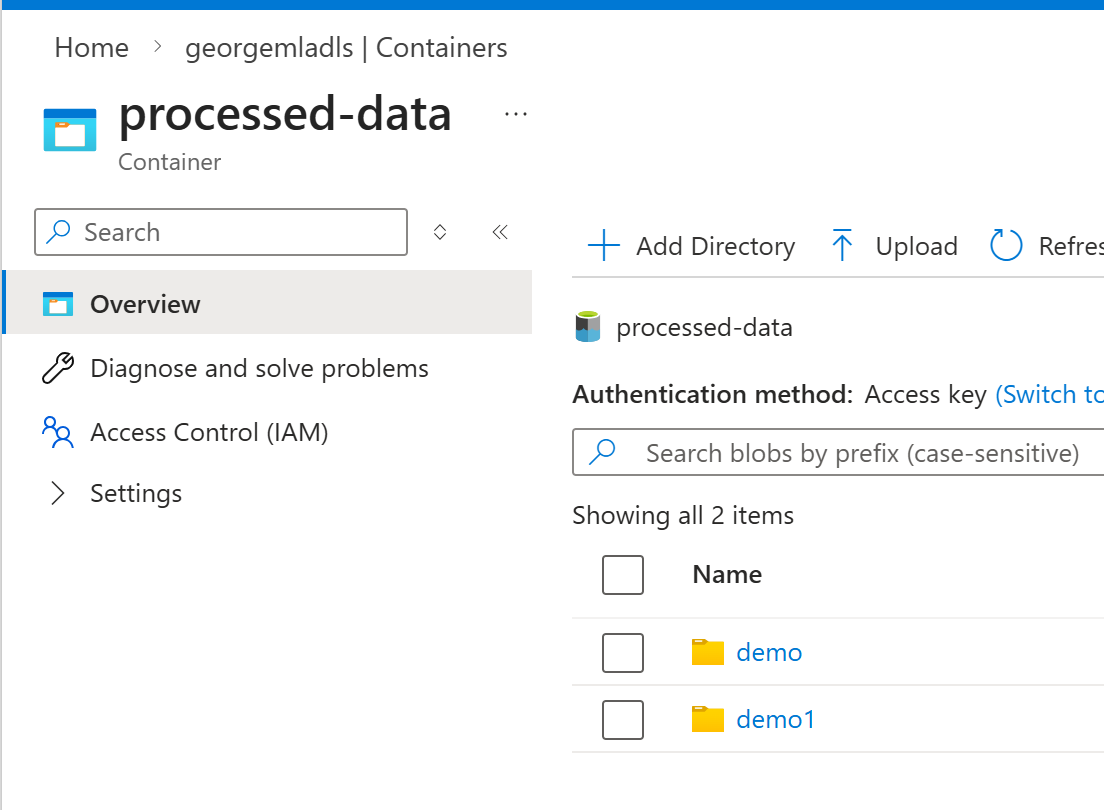
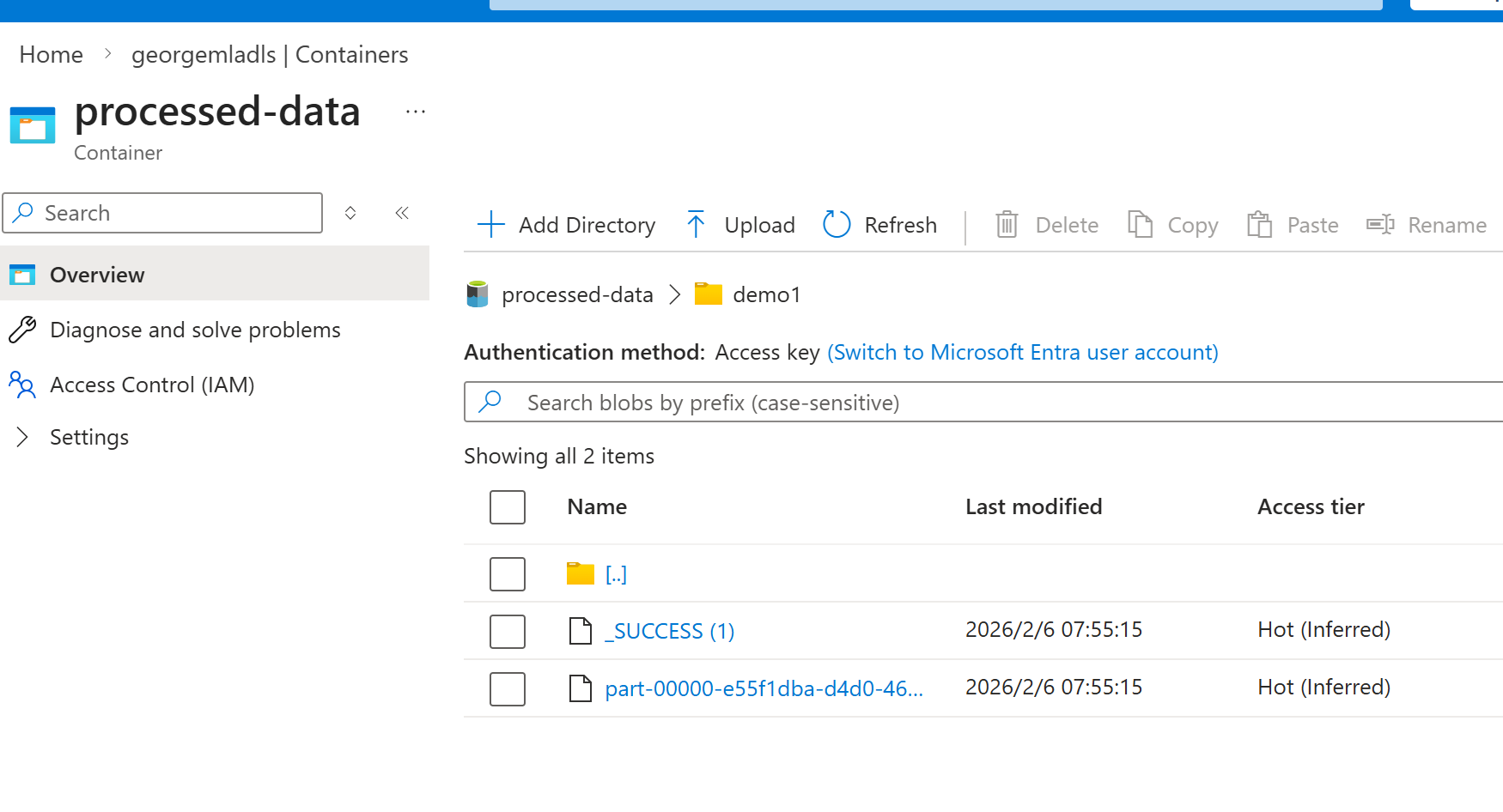
假设我们已经有了数据准备, 比如用前面的ADF生成了多个基于时间或者其他规则的数据文件,类似下面的demo 和demo1。 这里不需要考虑太多具体数据内容。
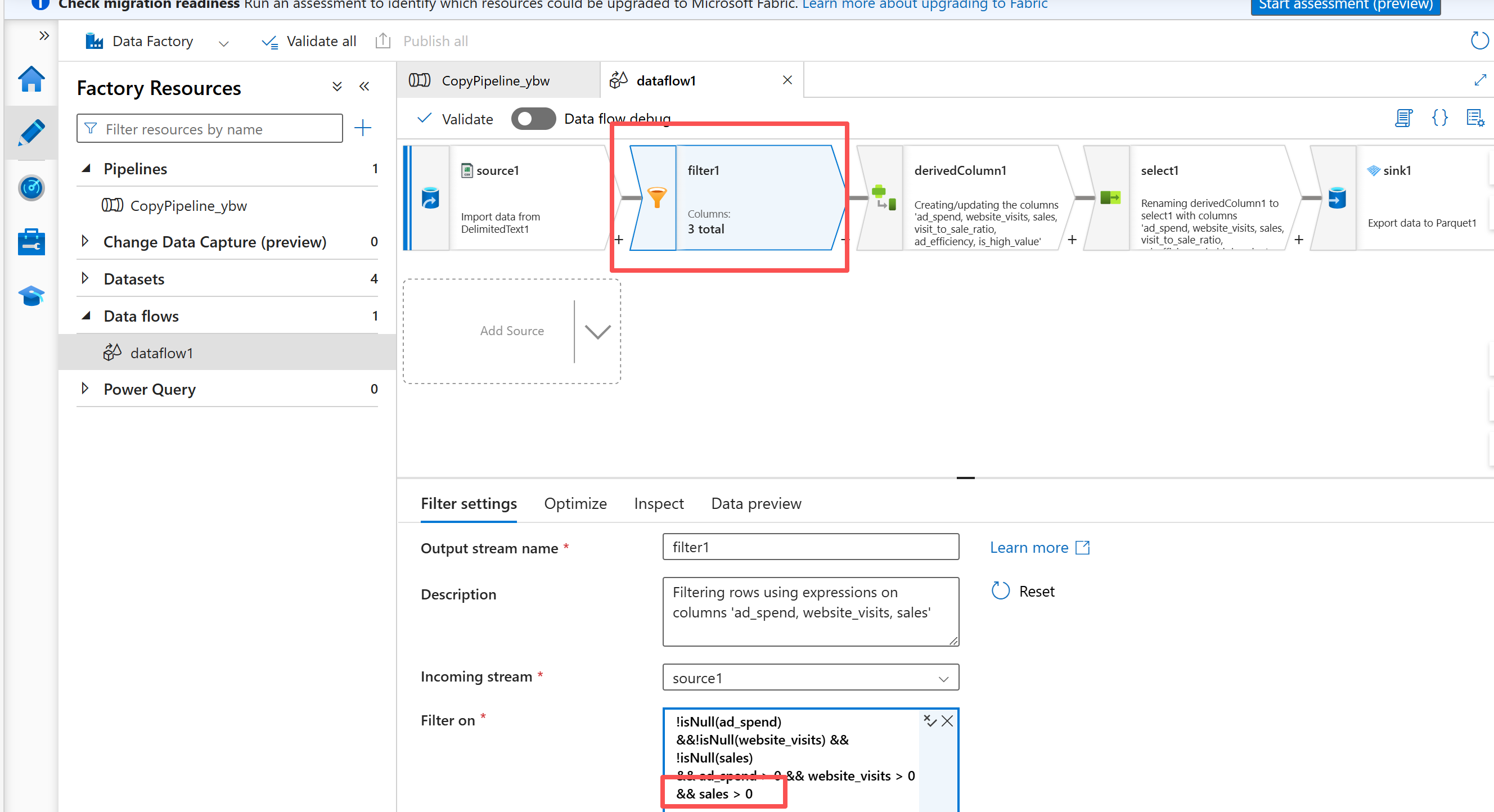
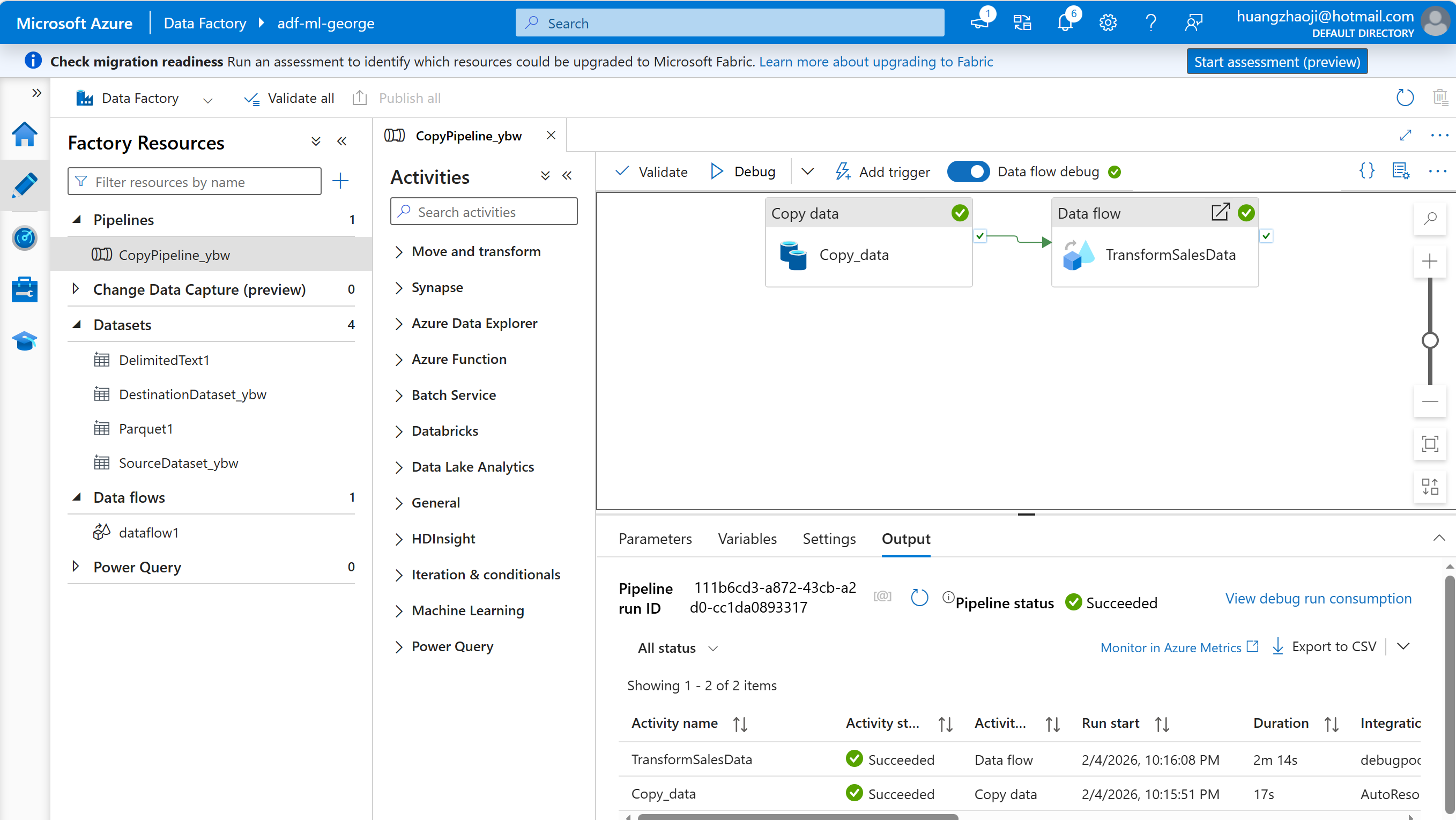
解耦设计
在Azure ML 中,我们尽可能不要直接访问ADLS (或者数据源),而是生成数据资产(类似Azure Databricks里面的Unity Catalog 的volume)。
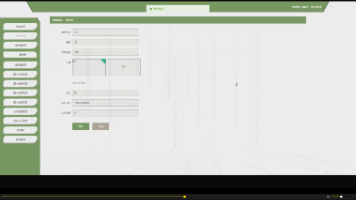
创建数据资产: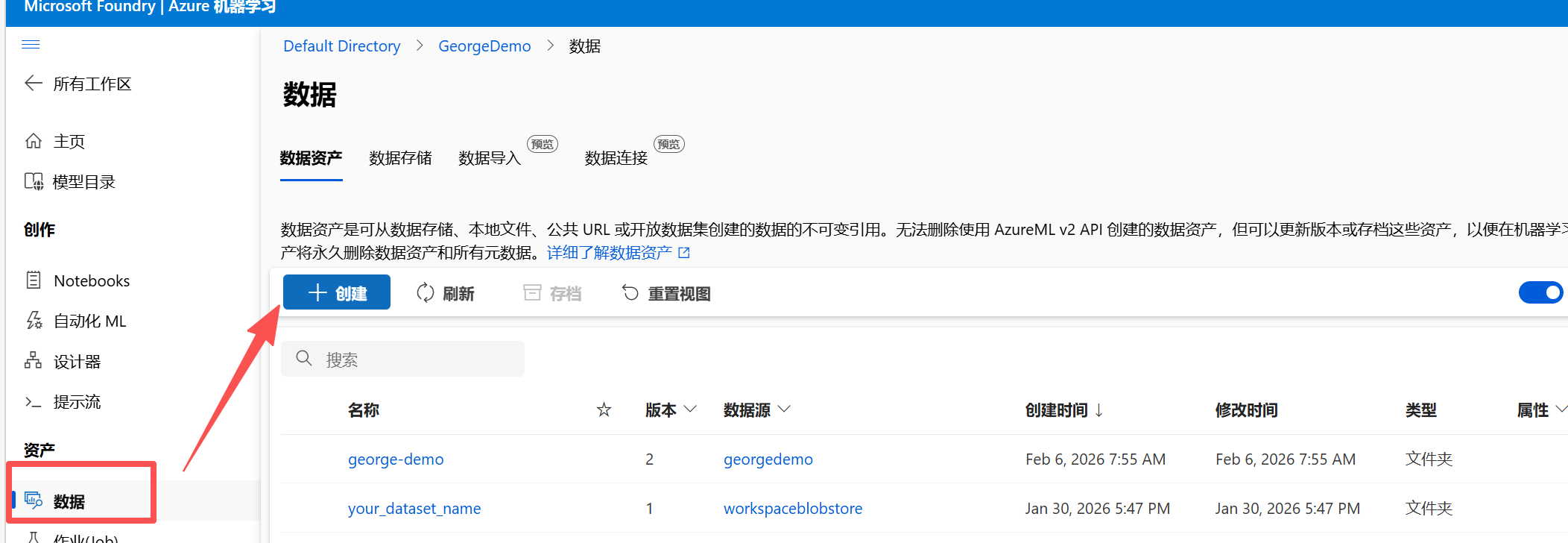
配置权限:这里可能会提示里面的提醒,这个时候使用下一个截图的RBAC 来解决即可。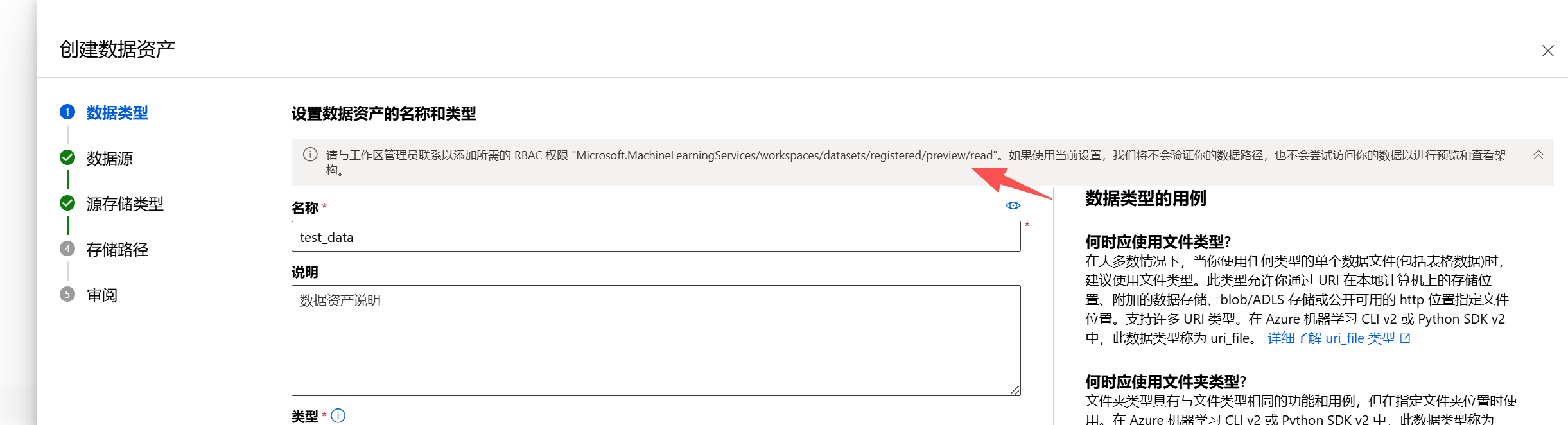
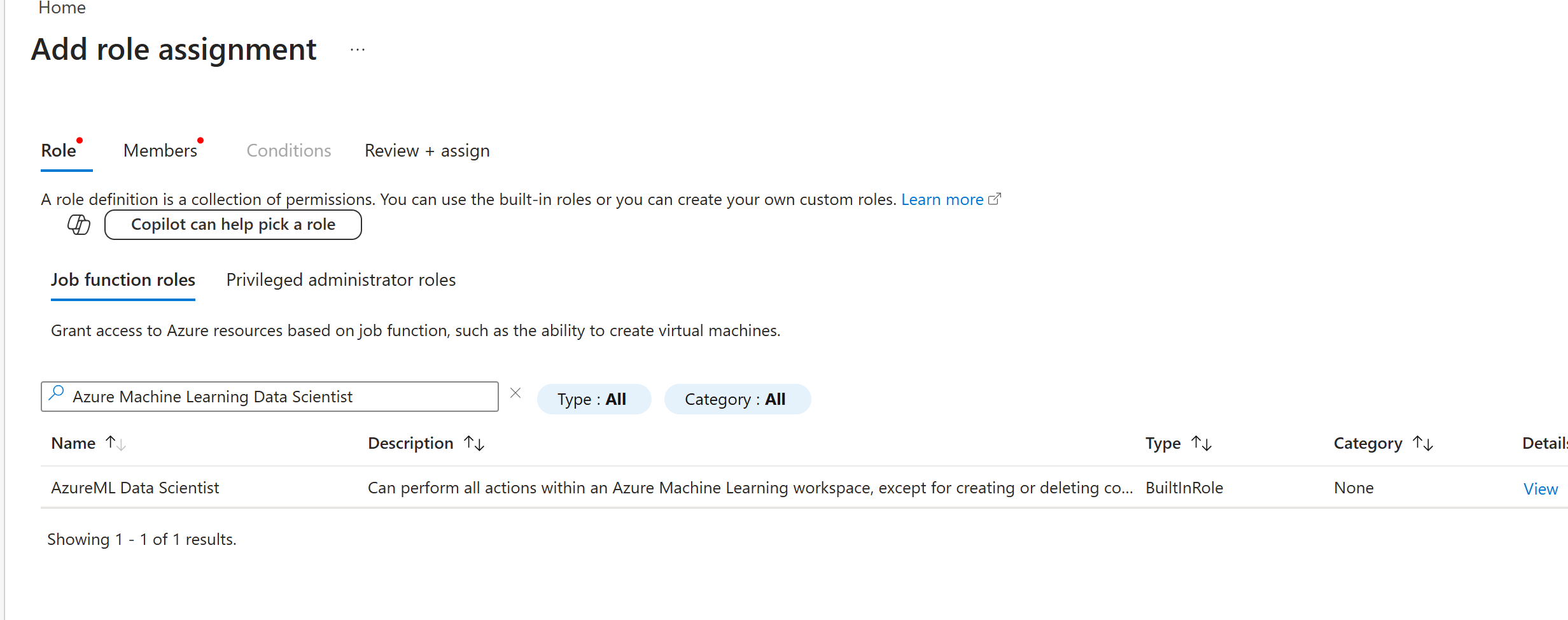
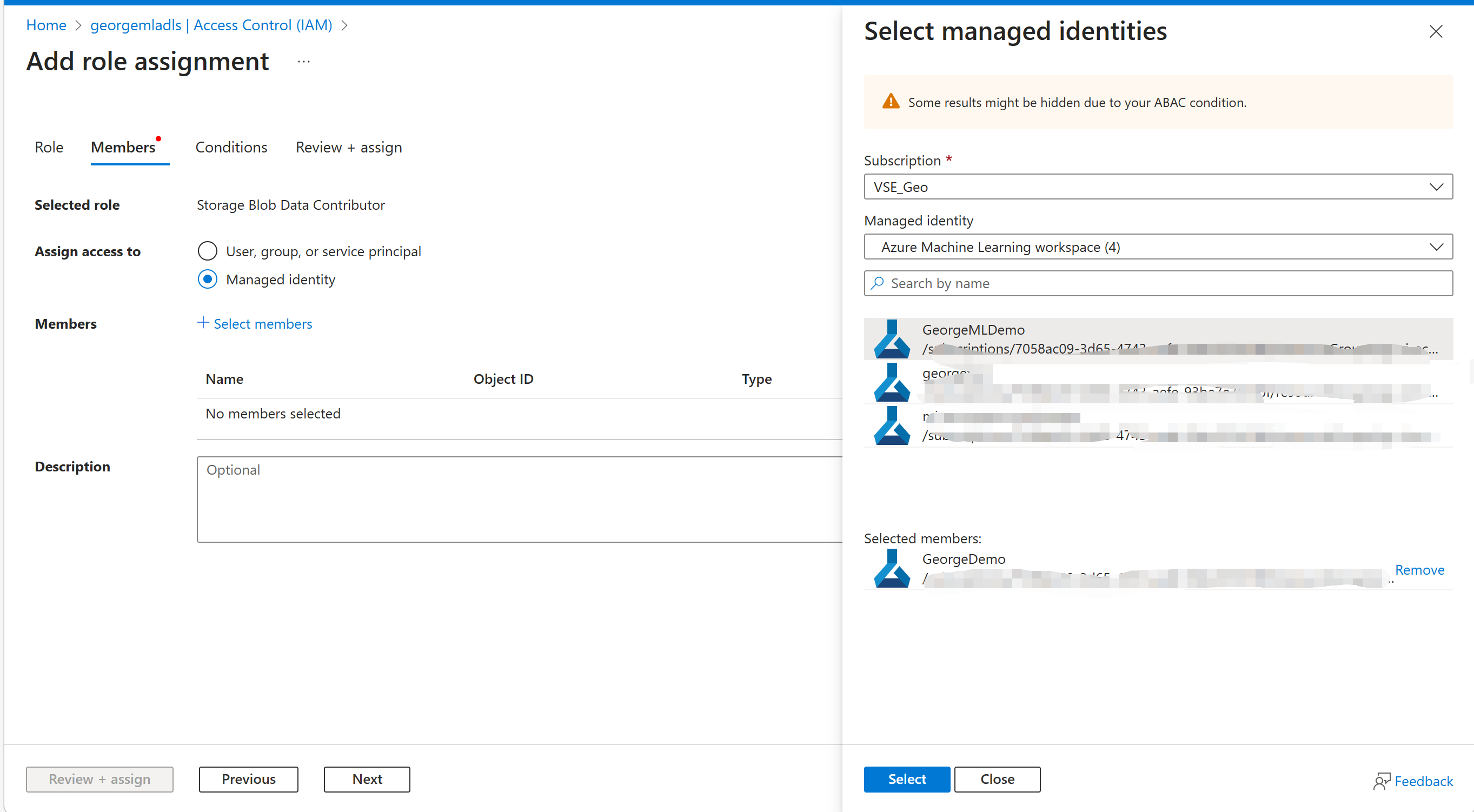
授权后继续创建资产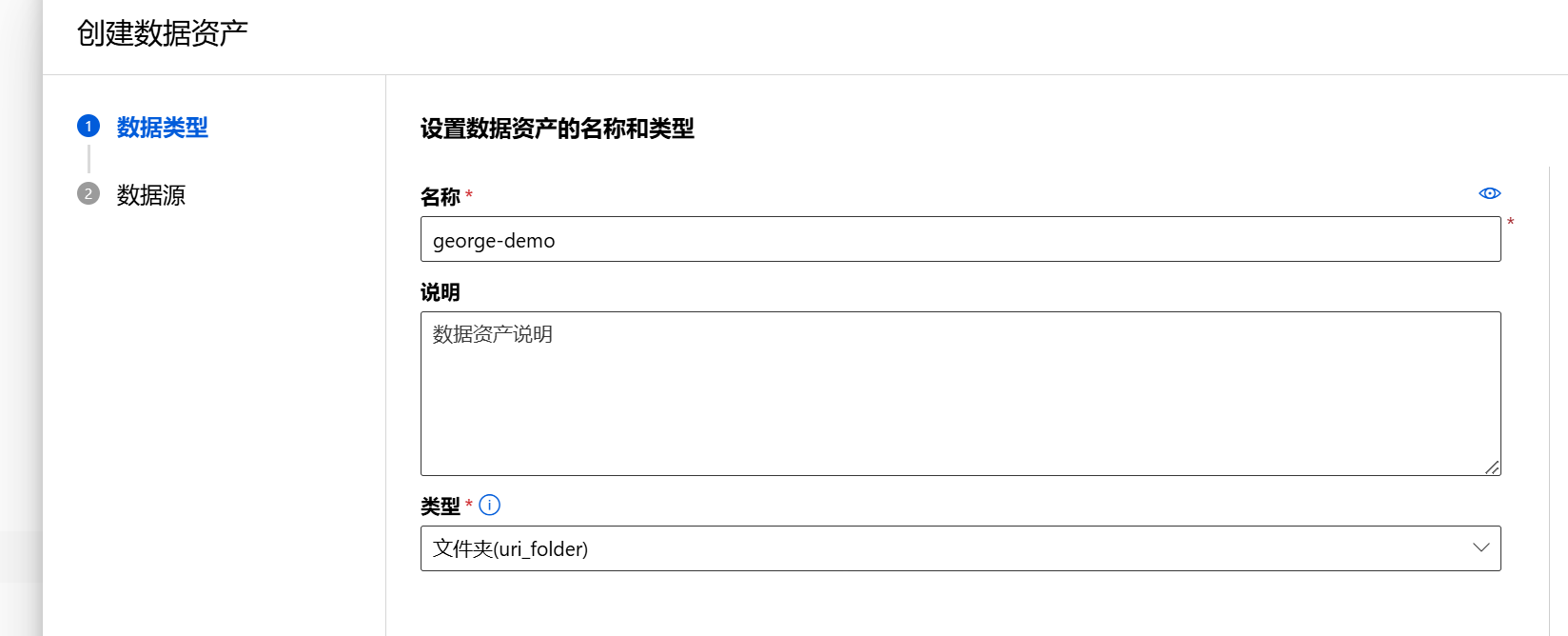
这里选择Azure 存储作为数据源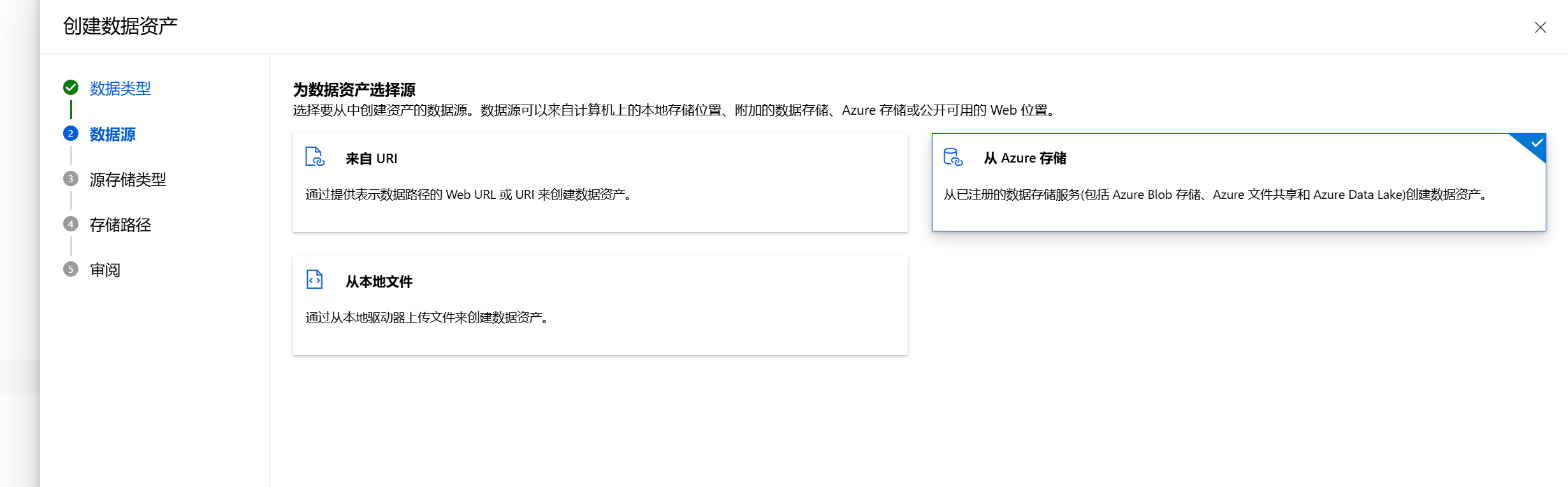
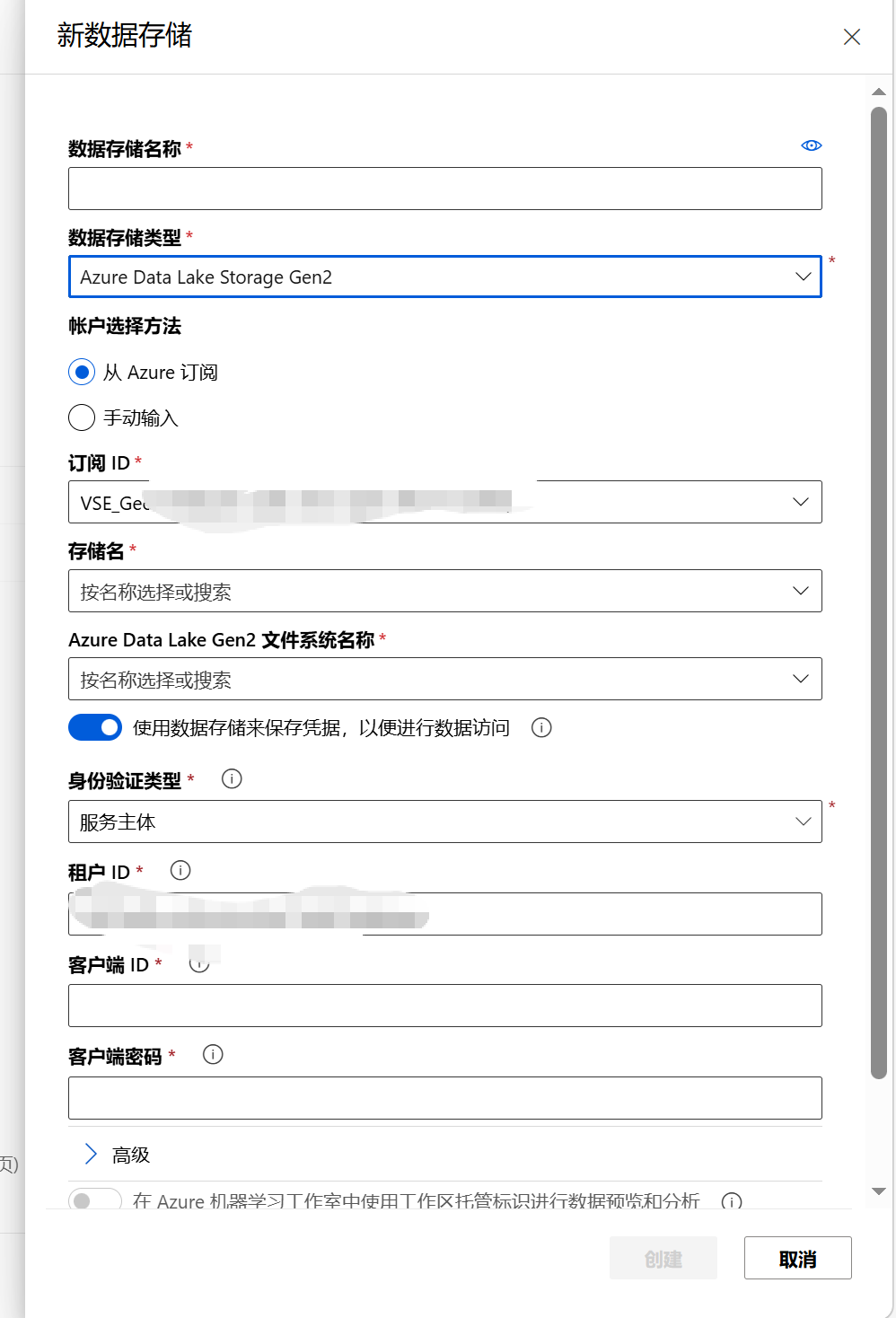
这里有个小插曲:
留意我下面截图中红色❌, 因为一开始我使用了完整的路径,并确认要进行数据验证(下面“跳过数据验证”没被启用),所以它校验不通过,后续尝试发现只输入容器内的相对路径:demo/(因为数据存储已经绑定了georgemladls账户和processed-data容器,这里只需要填容器里的文件夹路径);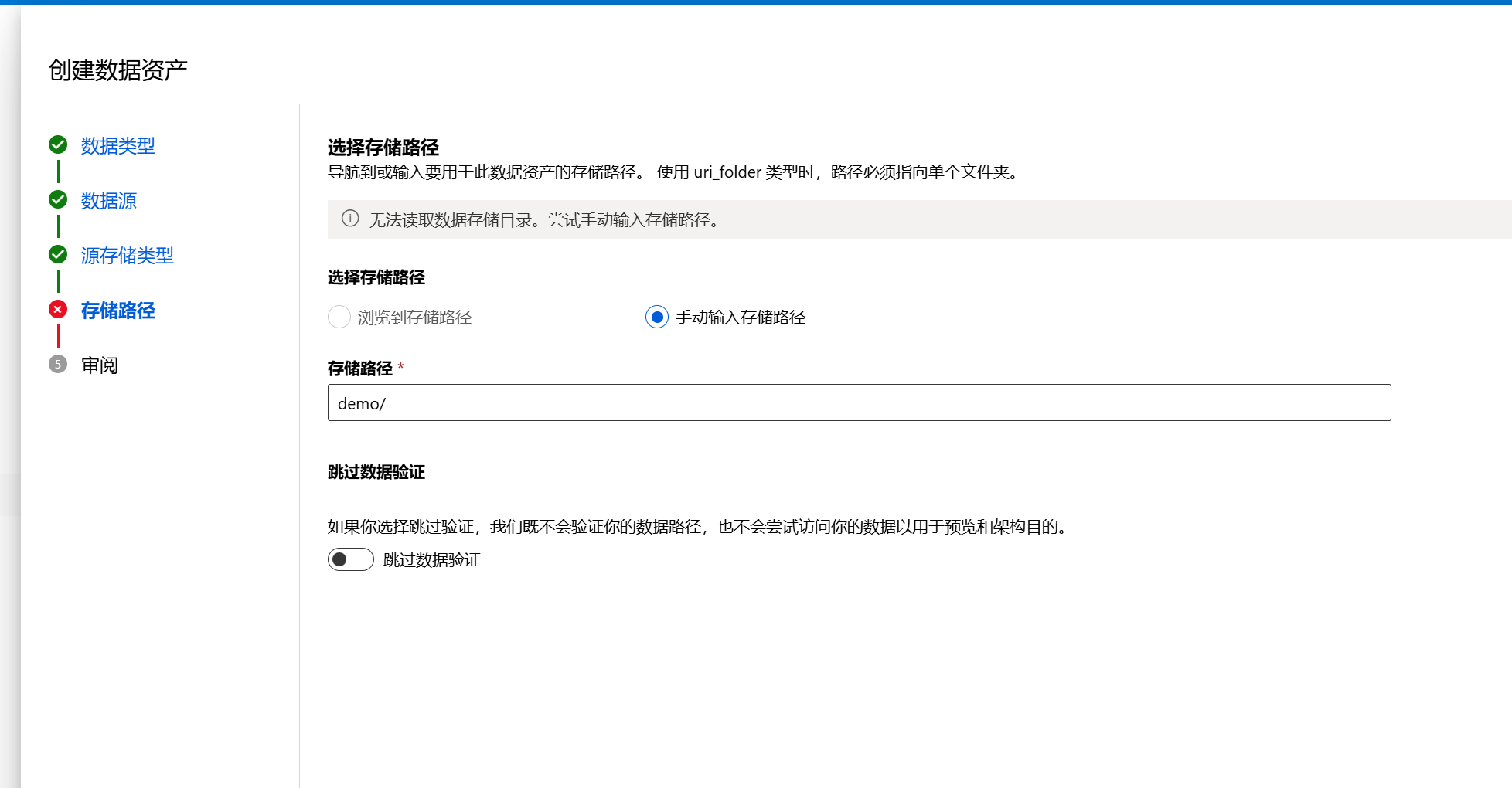
验证成功并创建了数据资产:
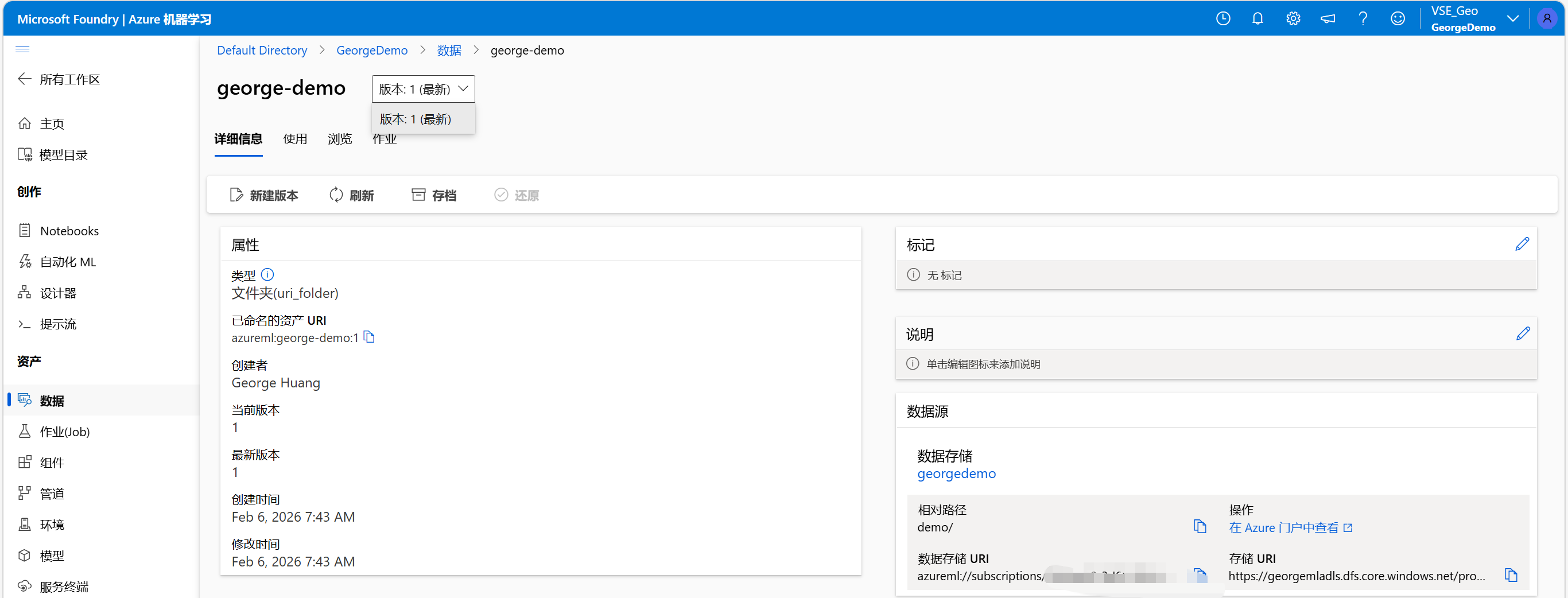
可以正常看到里面的数据:
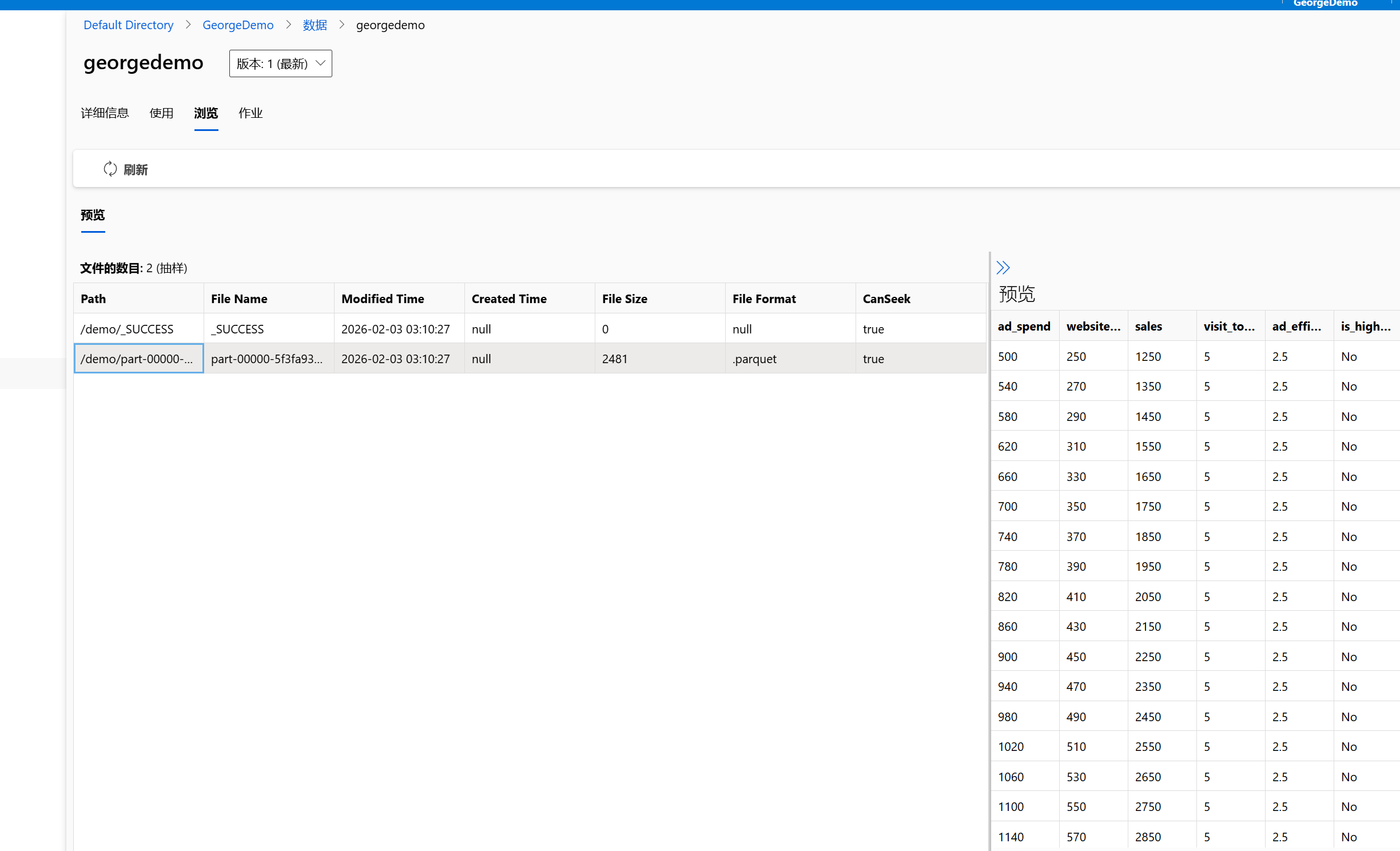
关于数据工程的考虑
-
ML工程师只需引用数据集。 无需关心ADLS路径变更(如容器迁移) 符合‘关注点分离’架构原则”
-
特征复用设计 通配符*.parquet自动包含所有特征文件,多模型共享同一特征库
血缘控制
我们知道数据工程中血缘,版本的控制极其重要,比如下面我们可以看到当前版本是1, 显示最新。 借助本文一开始时的新文件夹,我们可以创建这个数据集的新版本,指向新的文件夹demo1。以此类推可以对ML 中的数据集,指向多个数据源并附以不同的版本号做标识。
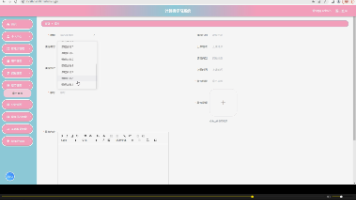
选择新建版本。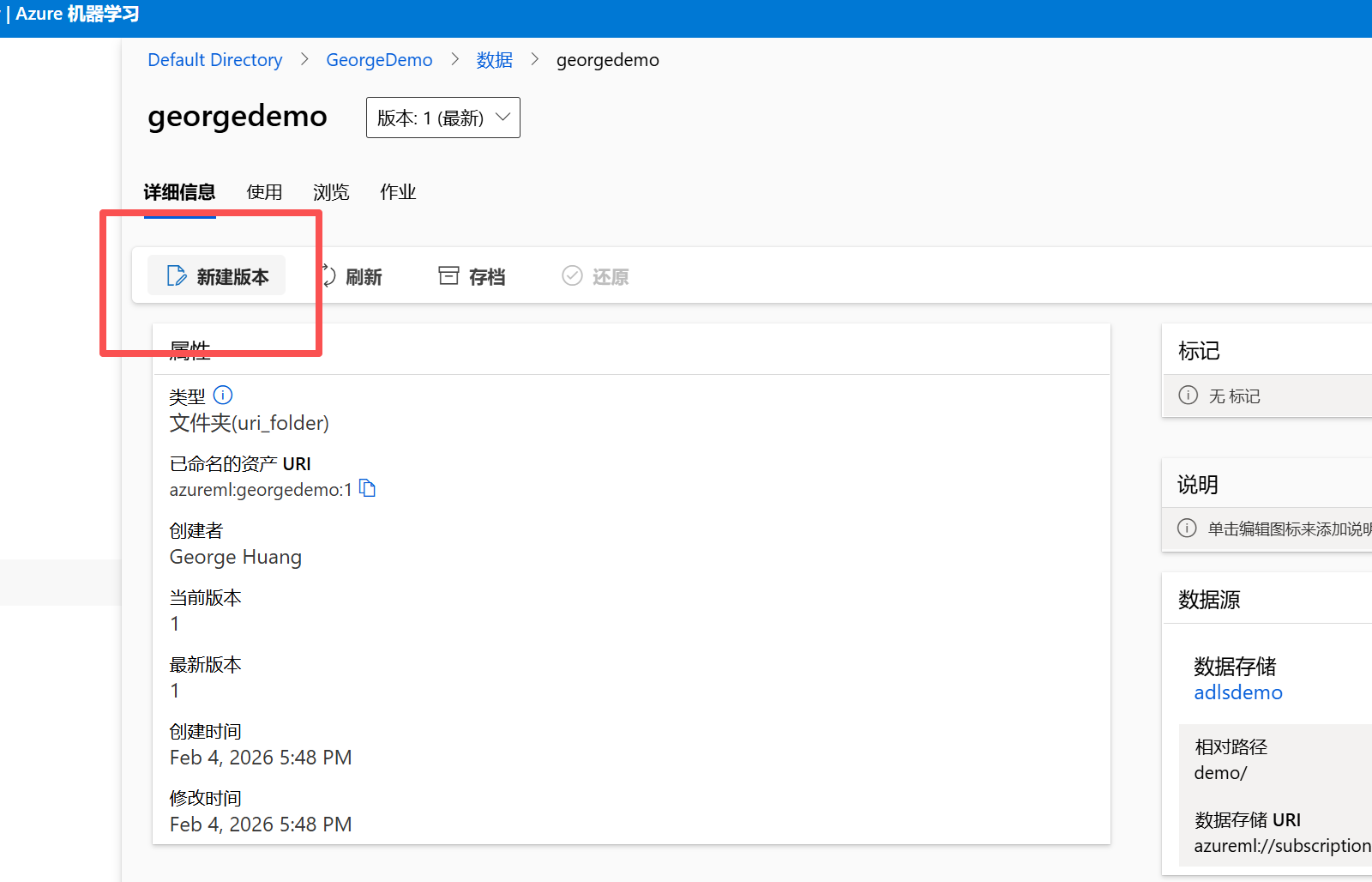
这里的一些基础信息是不可修改的。
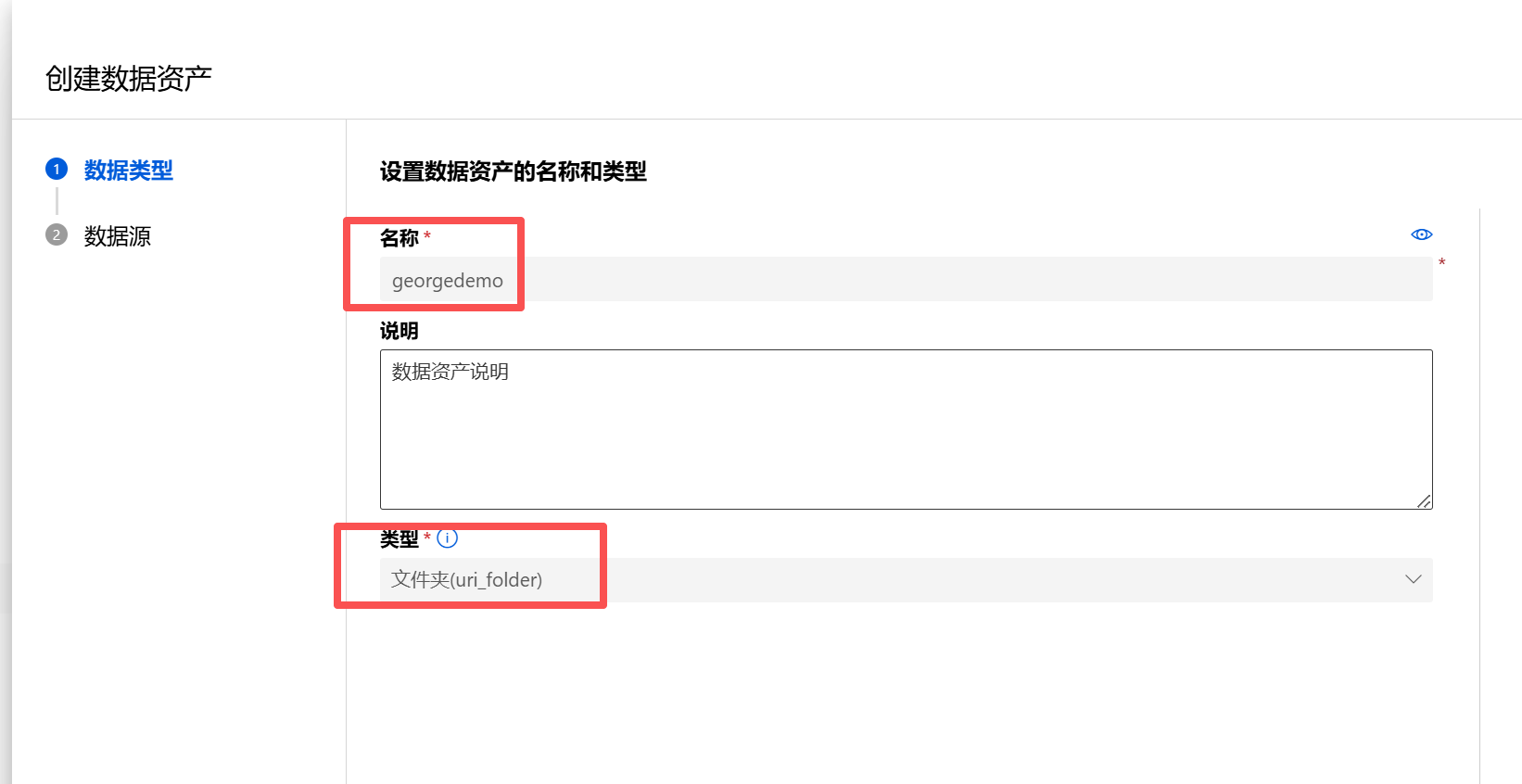
选择新路径: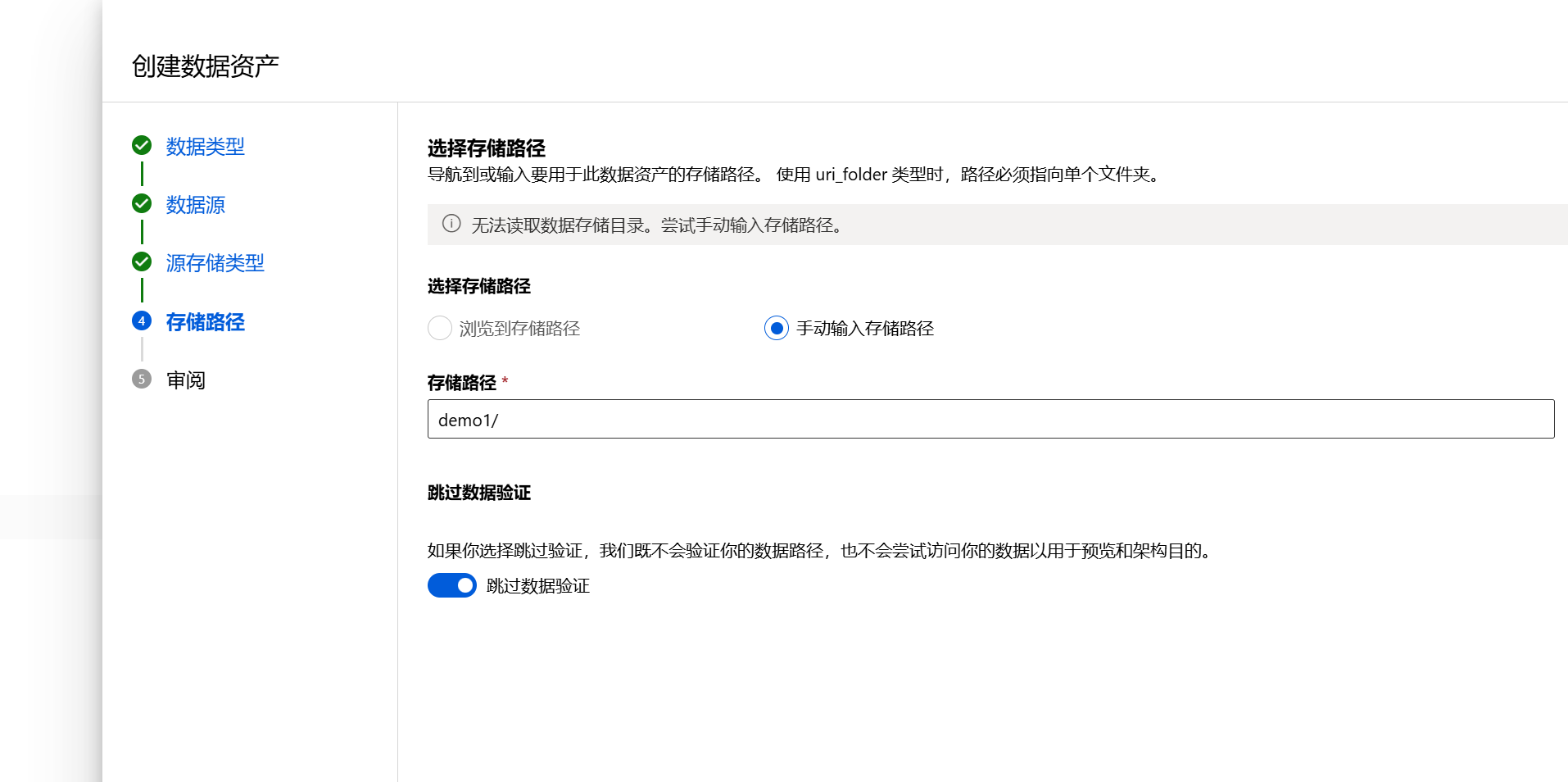
此时可以看到出现了一个新的版本2,并显示最新。
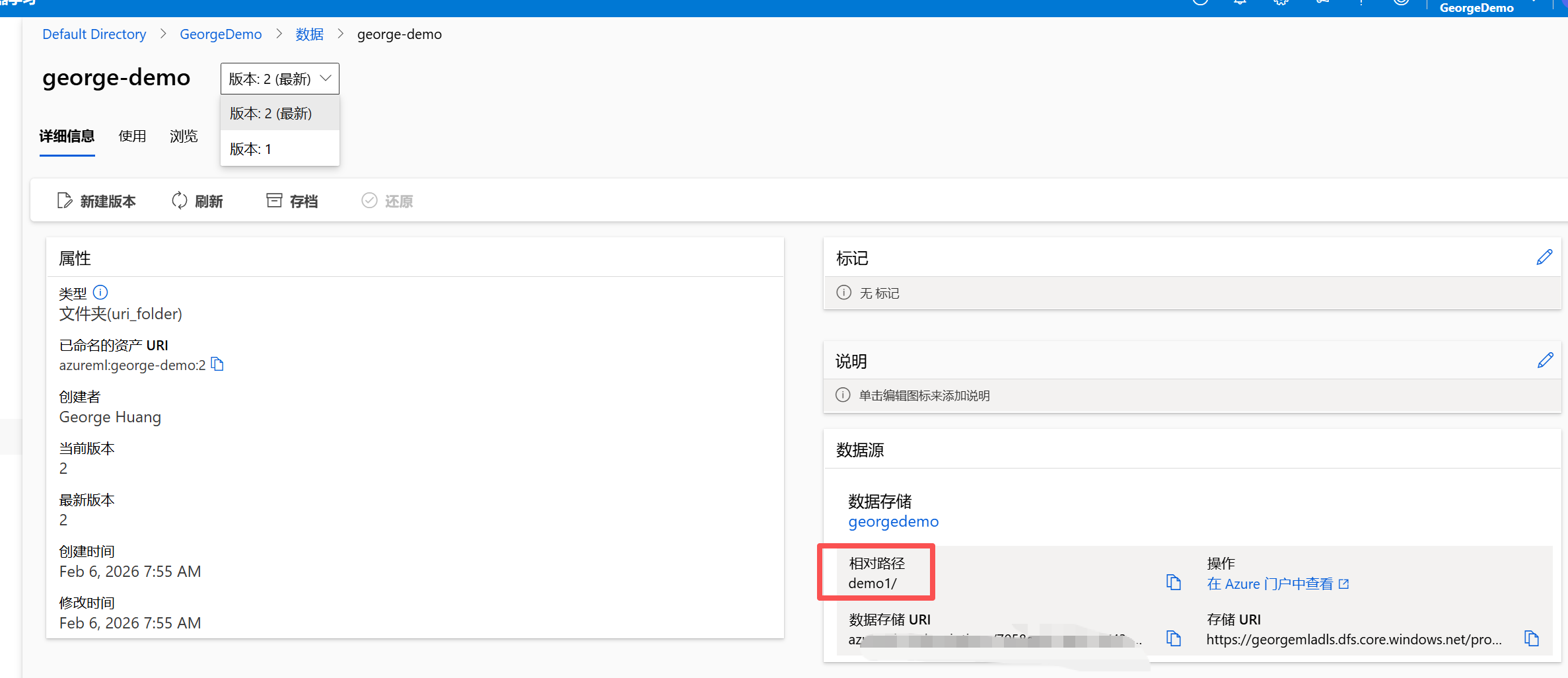
通过切换版本我们就可以访问不同的数据源。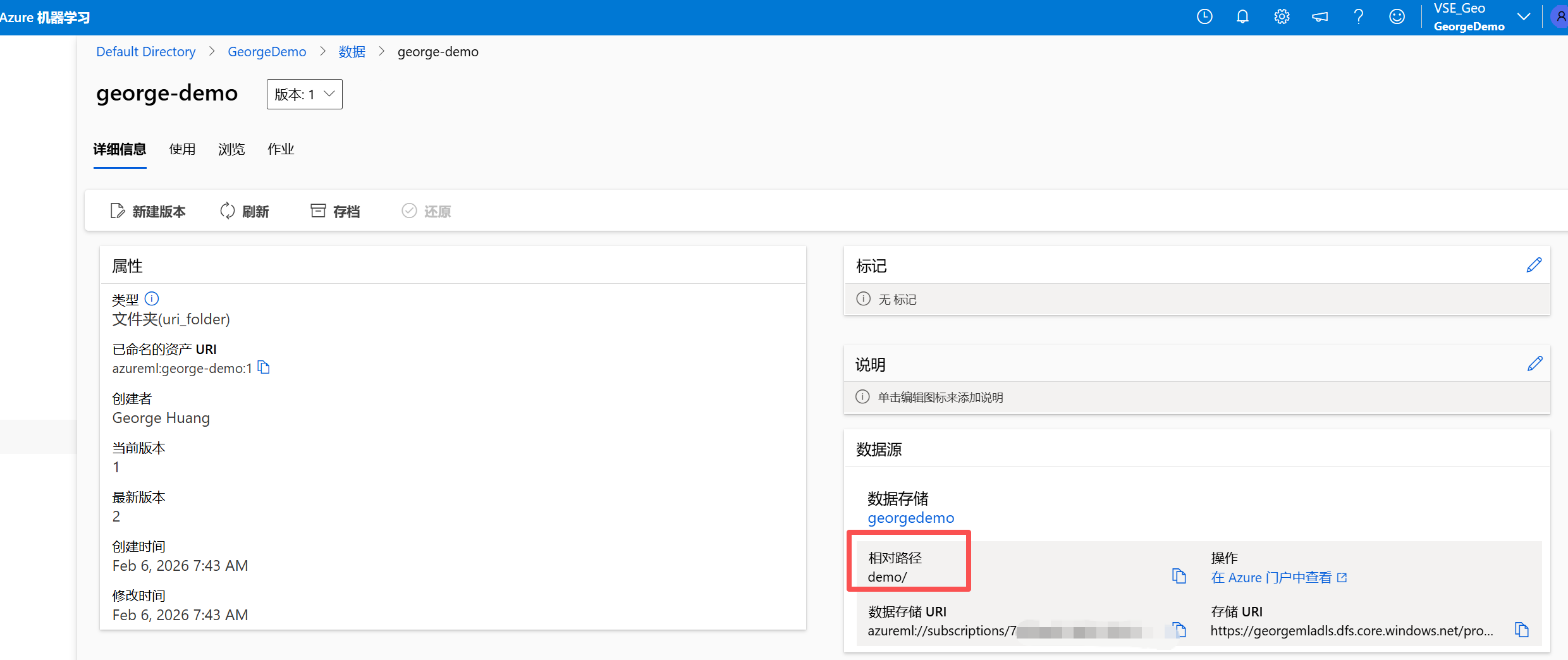
建立物理版本 ↔ 逻辑版本映射(数据血缘核心!)
在后续的训练中,我们可以使用版本1 作为开发,校验,版本2 作为实际的数据进行训练。同时通过这种映射使得ML 工程师专注于模型而不是数据搬运。
小结
在这个数据工程主题中:
- 分层架构设计(数据湖)
Raw层:保留原始CSV(带时间戳)→ 满足GDPR审计
Processed层:ADF数据流输出Parquet(含某些操作模拟特征)→ 特征复用基石
关键决策:特征计算放在ADF而非ML训练时 → 减少训练耗时40%,支持多模型共享。 - 双重版本控制体系
物理层:ADF文件名时间戳(通过ADF 搭配时间戳,形成不同的.parquet文件)
→ 防覆盖、可追溯原始快照
逻辑层:Azure ML数据集版本(v1.0/v1.1)
→ ML工程师友好引用
血缘映射:v1.0 ↔ xxx.parquet
→ 任何模型问题5分钟内定位根源 - 解耦与抽象设计
ML训练代码:Dataset.get_by_name(‘george-demo’, version=1)
无需硬编码ADLS路径 → 存储迁移时零代码修改
通配符*.parquet设计 → 自动包含增量特征文件 - 工程价值量化
数据准备:人工2天 → ADF自动化15分钟
模型迭代:特征复用使新模型开发效率↑40%
问题排查:数据血缘使根因定位从小时级→分钟级

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 14
14 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)