在多智能体通信协议设计中,注意力机制(Attention Mechanism)如何帮助Agent筛选和聚焦关键信息
图注意力网络(Graph Attention Network, GAT)将注意力机制引入图结构数据,解决了传统图卷积网络(GCN)无法处理动态图和依赖特定图结构的局限性。在多智能体通信中,GAT 允许智能体 i根据自身状态与邻居智能体 j 的特征差异,计算出通过边j→i传递的信息的重要性。eijLeakyReLUaTWhi∥Whj其中,h代表智能体的特征向量,W是共享的线性变换矩阵,⋅∥⋅表
一、注意力机制基础理论
图注意力网络 (GAT) 与动态拓扑学习
1. GAT 核心运作机制
图注意力网络(Graph Attention Network, GAT)将注意力机制引入图结构数据,解决了传统图卷积网络(GCN)无法处理动态图和依赖特定图结构的局限性。在多智能体通信中,GAT 允许智能体 i根据自身状态与邻居智能体 j 的特征差异,计算出通过边
j→i j \to i j→i
传递的信息的重要性。
与标准 Transformer 的点积注意力不同,GAT 通常使用单层前馈神经网络来计算注意力系数,并引入非线性激活函数 LeakyReLU 以增强模型的表达能力:
eij=LeakyReLU(a⃗T[Wh⃗i ∥ Wh⃗j]) e_{ij} = \text{LeakyReLU}\left(\vec{a}^T [W\vec{h}_i \, \| \, W\vec{h}_j]\right) eij=LeakyReLU(aT[Whi∥Whj])
其中,
h⃗ \vec{h} h
代表智能体的特征向量,W是共享的线性变换矩阵,
[⋅∥⋅] [\cdot \| \cdot] [⋅∥⋅]
表示向量拼接操作,
a⃗ \vec{a} a
是可学习的权重向量。
随后,使用 Softmax 函数对所有邻居
j∈Ni j \in \mathcal{N}_i j∈Ni
的系数进行归一化,得到最终的注意力权重
αij \alpha_{ij} αij
:
αij=exp(eij)∑k∈Niexp(eik) \alpha_{ij} = \frac{\exp(e_{ij})}{\sum_{k \in \mathcal{N}_i} \exp(e_{ik})} αij=∑k∈Niexp(eik)exp(eij)
这一机制使得智能体能够各向异性地聚合信息——即对不同的邻居分配完全不同的权重,从而实现“去噪”和“聚焦”。
2. 多头注意力与稳定性
为了稳定训练过程并捕获不同子空间的相关性(例如:一个“头”关注位置距离,另一个“头”关注速度匹配),GAT 采用多头注意力机制(Multi-Head Attention)。假设使用 K个独立的注意力机制,其输出通常通过拼接(Concatenation)或平均(Averaging)来聚合:
h⃗i′=σ(1K∑k=1K∑j∈NiαijkWkh⃗j) \vec{h}'_i = \sigma\left(\frac{1}{K} \sum_{k=1}^K \sum_{j \in \mathcal{N}_i} \alpha_{ij}^k W^k \vec{h}_j\right) hi′=σ
K1k=1∑Kj∈Ni∑αijkWkhj
这种设计显著增强了通信协议的鲁棒性,即使某个注意力头关注了错误的信息,其他的头也能进行修正。
3. 动态通信流程图 (MAGIC Pipeline)
在多智能体环境(如 MAGIC 架构)中,通信图不是静态的,而是根据注意力权重动态生成的。以下流程图展示了从局部观测到动态图构建再到决策生成的完整数据流转过程。
多智能体图注意力通信流水线:
Multi-Agent GAT Communication Pipeline
│
├── 【环境输入 (Environment Input)】
│ ├── 智能体观测: [Obs_1, Obs_2, ..., Obs_N] (位置, 速度, ID)
│ ├── 通信约束: 带宽限制 / 通信半径 R
│ └── 模式选择: Training (训练) / Execution (执行)
│
▼
[1. 图构建与特征编码 (Graph Construction & Encoding)] ───────────┐
│ (由此模块总控: 🐍 graph_encoder.py) │
│ │
├── A. 节点特征提取 (Node Embedding) │
│ ├── <输入>: 原始观测向量 (Raw Observations) │
│ ├── <处理>: MLP / RNN Encoder │
│ │ (作用: 将高维观测压缩为低维特征向量 h_i) │
│ └── > 输出: Feature Matrix H = {h_1, ..., h_N} │
│ │
├── B. 动态邻接矩阵生成 (Adjacency Generation) │
│ ├── <规则判断>: 计算智能体间的欧氏距离 d_ij │
│ ├── <硬阈值>: if d_ij < R then connect (建立边) │
│ └── > 输出: 初始邻接矩阵 Adjacency Matrix A │
│ │
└── > 准备就绪: Graph Data (Nodes H + Edges A) ──────────────────┘
│
▼
[2. 注意力计算核心 (Attention Mechanism Kernel)] <★ 核心算法> ───┐
│ │
├── Step 1: 特征变换与拼接 (Transformation) │
│ ├── 线性变换: Wh_i = W * h_i (共享权重矩阵) │
│ └── 向量拼接: concat(Wh_i, Wh_j) 针对所有相连的对 (i,j) │
│ │
├── Step 2: 相关性系数计算 (Coefficient Calculation) │
│ ├── <公式>: e_ij = LeakyReLU(a^T * [Wh_i || Wh_j]) │
│ │ (注意: LeakyReLU 用于保留负值梯度,增强非线性) │
│ └── > 输出: 未归一化的注意力分数 (Raw Scores) │
│ │
├── Step 3: 拓扑结构学习 (Topology Learning / Pruning) │
│ ├── Softmax归一化: α_ij = softmax(e_ij) │
│ ├── <差分硬阈值 (Differentiable Hard Threshold)>: │
│ │ (作用: MAGIC算法核心,过滤掉 α_ij < ε 的微弱连接) │
│ │ (结果: 将全连接图转化为稀疏图,节省带宽) │
│ └── > 输出: 最终注意力权重矩阵 Attention Weights α │
└────────────────────────────────────────────────────────────────┘
│
▼
[3. 消息聚合与状态更新 (Message Aggregation)] ───────────────────┐
│ │
├── <加权求和>: h'_i = Σ (α_ij * Wh_j) 遍历所有邻居 j │
├── <多头聚合>: Concatenate(Head_1, Head_2, ..., Head_K) │
│ (作用: 捕捉不同子空间的信息,如敌方威胁 vs 队友支援) │
├── <残差连接>: h_final = h'_i + h_i (防止网络退化) │
└── > 输出: 上下文感知向量 Context Vector C_i │
│
▼
[4. 决策生成 (Policy Generation)] ───────────────────────────────┐
│ │
├── <输入>: Context Vector C_i + 自身原始观测 │
├── <网络>: Actor-Critic Network / Q-Network │
└── > 最终动作: Action a_i (移动/攻击/通信) │
└────────────────────────────────────────────────────────────────┘
4. GAT 在通信中的核心优势
- 处理任意结构:无论智能体数量是 3 个还是 100 个,或者队形如何变化,GAT 都能直接处理,无需重新训练。
- 可解释性 (Interpretability):通过可视化注意力权重 αij\alpha_{ij}αij,研究人员可以直接观察到智能体 iii 在做决策时“看”了谁。例如,在足球场景中,持球者会对前锋保持高注意力,而忽略后场守门员。
- 带宽效率:结合 MAGIC 算法中的阈值机制,可以将接近零的注意力权重直接截断,不再传输对应的消息包,从而在物理层面上降低通信负载。
多智能体通信协议架构详解
一个完整的多智能体通信协议架构通常包含三个核心模块:消息生成、注意力筛选和决策执行。下图展示了这一架构的树形结构: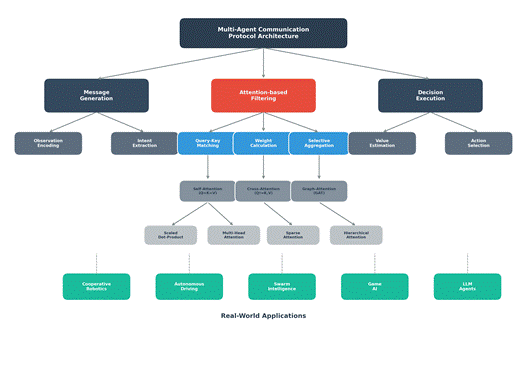
图1:多智能体通信协议架构树形结构图
消息生成模块负责将智能体的局部观测编码为可传递的消息表示。这一步骤通常使用多层感知机(MLP)或循环神经网络(RNN)实现,将高维观测压缩为低维消息向量。注意力筛选模块是协议的核心,通过计算注意力权重,智能体决定应该关注哪些来自其他智能体的信息。决策执行模块则基于筛选后的信息,通过策略网络生成最终的动作。
在带宽受限的场景中,通信协议还需要包含调度机制。TarMAC(Targeted Multi-Agent Communication)提出了基于签名的通信协议,允许智能体动态选择通信对象。SchedNet则引入了基于权重的调度器,在带宽限制下选择最重要的智能体进行通信。
1. 架构核心模块
一个成熟的多智能体通信协议架构(如 TarMAC, MAGIC, SchedNet)不仅仅是简单的发送和接收,而是一个包含信息压缩、流量控制和上下文融合的闭环系统。该架构通常包含以下四个核心处理阶段:
-
局部感知与编码 (Local Perception & Encoding):
智能体首先通过感知网络(如 CNN 处理图像,RNN 处理序列)处理原始观测 oio_ioi,将其转化为紧凑的内部隐状态 (Hidden State, hih_ihi)。这个隐状态不仅用于决策,也是生成通信消息的基础。
-
调度与门控机制 (Gating & Scheduling):
这是带宽受限场景下的关键模块。
-
基于权重的调度 (Weight-based):如 SchedNet,智能体通过一个小型网络计算当前状态的“重要性权重”
wi w_i wi
。只有权重超过阈值或排名 Top-k 的智能体才被允许广播消息。 -
基于签名的寻址 (Signature-based):如 TarMAC,发送方不仅广播消息,还生成一个“键 (Key)”或“签名”,表明消息的内容属性(例如:“我是医疗兵”或“我发现敌人”),供接收方筛选。
-
-
注意力筛选与聚合 (Attention Selection & Aggregation):
接收方智能体通过注意力机制充当“软性滤波器”。它根据自身的查询向量 (Query) 与接收到的所有消息键 (Key) 进行匹配,计算注意力权重
αij \alpha_{ij} αij
。这使得智能体能够忽略无关噪声,加权聚合出对他当前决策最有用的上下文向量 (Context Vector,
ci c_i ci
)。 -
上下文融合与决策 (Fusion & Execution):
最终,智能体将自身的局部隐状态
hi h_i hi
与通信得到的上下文向量
ci c_i ci
进行拼接或融合,输入到策略网络(Actor-Critic)中,生成最终的动作分布。
2. 协议架构深度流程图
下图展示了从智能体 i的视角出发,如何处理观测、决定是否发送消息、以及如何利用注意力机制聚合邻居 j的信息的完整管线。
Multi-Agent Attention-Based Communication Architecture
│
├── 【环境交互 (Environment Interaction)】
│ ├── 局部观测: Agent_i 收到图像/雷达数据 (Obs_i)
│ ├── 通信约束: 带宽限制 Bandwidth = B (例如每轮仅允许 20% Agent 发言)
│ └── 邻居集合: Neighbors = {Agent_j, Agent_k, ...}
│
▼
[1. 局部感知与编码 (Local Perception Phase)] ────────────────────┐
│ (由此模块总控: 🐍 agent_encoder.py) │
│ │
├── <特征提取>: Feature Extractor │
│ ├── 输入: High-dim Observation (e.g., 84x84x3 Image) │
│ ├── 网络: CNN (视觉) 或 LSTM (序列历史) │
│ └── > 输出: 内部隐状态 h_i (Internal State) │
│ │
├── <消息生成>: Message Encoder │
│ ├── 动作: 将 h_i 映射为消息向量 m_i │
│ └── 扩展: 生成签名 Key_i (用于 TarMAC 寻址) │
└── > 准备就绪: 待发送数据 Packet_i = (m_i, Key_i) ──────────────┘
│
▼
[2. 调度与门控 (Scheduling & Gating Mechanism)] <★ 带宽控制> ────┐
│ (由此模块总控: 🐍 scheduler_net.py) │
│ │
├── Step 1: 重要性评估 (Importance Assessment) │
│ ├── 算法: SchedNet / Gating Network │
│ ├── 计算: Weight w_i = Sigmoid(Linear(h_i)) │
│ │ (作用: 评估 "我的信息对团队有多重要?") │
│ └── > 决策: if w_i < Threshold: 保持沉默 (Silence) │
│ │
├── Step 2: 广播/发送 (Broadcasting) │
│ ├── 动作: 将 Packet_i 推送至共享通信信道 │
│ └── > 状态: 消息进入 "公共消息池" (Message Pool) │
└────────────────────────────────────────────────────────────────┘
│
▼
[3. 注意力筛选与聚合 (Attention Aggregation)] <★ 核心机制> ──────┐
│ (由此模块总控: 🐍 attention_core.py) │
│ (接收方视角: Agent_i 处理来自 {j, k...} 的消息) │
│ │
├── Step 1: 生成查询 (Query Generation) │
│ └── 计算: Q_i = W_q * h_i (我当前关心什么?) │
│ │
├── Step 2: 键值匹配 (Key-Value Matching) │
│ ├── 输入: 邻居的消息 m_j 和 签名 Key_j │
│ ├── 计算: Score_ij = (Q_i · Key_j) / √d │
│ └── 归一化: α_ij = Softmax(Score_ij) │
│ (含义: "邻居 j 的消息对我有多大参考价值?") │
│ │
├── Step 3: 加权融合 (Weighted Fusion) │
│ ├── 动作: Context c_i = Σ (α_ij * m_j) │
│ └── > 输出: 全局上下文向量 (Global Context Vector) │
└────────────────────────────────────────────────────────────────┘
│
▼
[4. 融合与决策执行 (Fusion & Execution Phase)] ──────────────────┐
│ │
├── <模态融合>: State Fusion │
│ ├── 拼接: Joint_State = Concat(h_i, c_i) │
│ │ (结合 "我知道的" + "队友告诉我的") │
│ └── 激活: ReLU / Tanh │
│ │
├── <策略输出>: Policy Head (Actor) │
│ ├── 网络: MLP │
│ └── > 输出: Action Distribution P(a|o, c) -> 采样动作 │
│ │
├── <价值评估>: Value Head (Critic) [仅训练时] │
│ └── > 输出: V(State) 用于计算优势函数 │
└────────────────────────────────────────────────────────────────┘
二、注意力机制在信息筛选中的应用
1.关键信息聚焦机制
注意力机制帮助智能体聚焦关键信息的核心在于Query-Key匹配机制。在多智能体环境中,每个智能体根据自身当前状态生成Query向量,该向量编码了智能体当前“关心”的信息类型。其他智能体的消息作为Key向量,与Query进行匹配,匹配程度越高,说明该消息与当前决策越相关。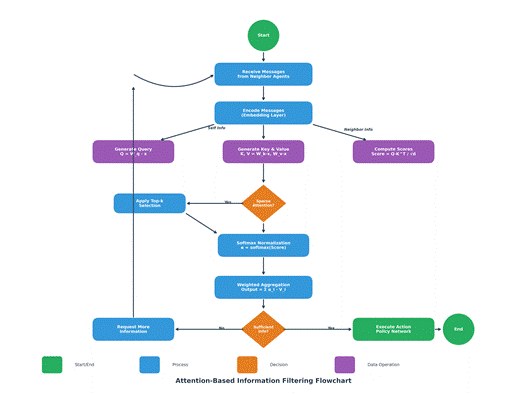
图2:注意力机制信息筛选流程图
上图展示了注意力机制进行信息筛选的完整流程。首先,智能体接收来自邻居的消息并进行编码;然后,生成Query、Key、Value向量;接着计算注意力分数并进行Softmax归一化;最后,通过加权聚合得到筛选后的信息表示。如果信息不足,智能体还可以主动请求更多信息。
每个智能体 i基于其局部观测
oi o_i oi
生成一个查询向量
Qi Q_i Qi
(Query),代表它“当前需要什么信息”(例如:“寻找附近的医疗包”)。同时,其他智能体 j生成键向量
Kj K_j Kj
(Key,代表“我是谁/我有什么特征”)和值向量
Vj V_j Vj
(Value,代表“具体的消息内容”)。
筛选过程是一个计算相关性分数的各向异性过程 :
Relevanceij=Qi⋅KjTdk \text{Relevance}_{ij} = \frac{Q_i \cdot K_j^T}{\sqrt{d_k}} Relevanceij=dkQi⋅KjT
-
高匹配度 (
Q⋅K≫0 Q \cdot K \gg 0 Q⋅K≫0
):表示智能体 j的特征正好是智能体 i 所需的,权重被放大。 -
低匹配度 (
Q⋅K≈0 Q \cdot K \approx 0 Q⋅K≈0
):表示无关噪声,信息在聚合阶段被抑制。
2. 带宽感知与稀疏通信
在实际应用中,通信带宽往往是有限的。2024年的研究提出了多种带宽感知的注意力机制变体。稀疏注意力(Sparse Attention)通过Top-K选择,只保留最重要的k个注意力连接,将计算复杂度从
O(n2) O(n²) O(n2)
降低到
O(nk) O(nk) O(nk)
。信息瓶颈方法(Information Bottleneck)则通过学习紧凑的消息表示,在保持信息量的同时减少通信开销。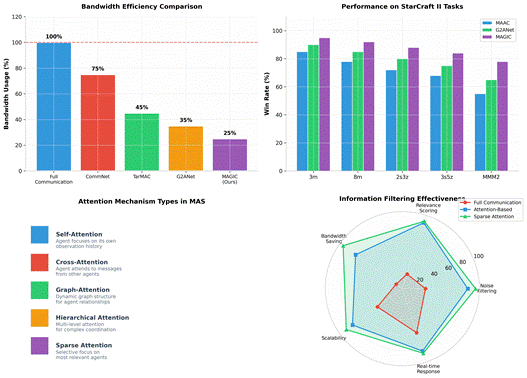
图3:不同注意力机制的比较分析
从图3可以看出,基于注意力机制的通信方法在带宽效率和任务性能方面都显著优于全通信模式。MAGIC方法在StarCraft II任务上取得了最高的胜率,同时仅使用25%的带宽。这证明了注意力机制在筛选关键信息和提高通信效率方面的有效性。
2.1 稀疏注意力 (Sparse Attention)
传统的 Softmax 会输出非零的稠密概率分布,导致所有智能体之间都需要通信。稀疏注意力引入了 Top-K 选择 或
α−entmax \alpha-entmax α−entmax
变换:
Sparse(Q,K)=Top-K(Softmax(QKTd)) \text{Sparse}(Q, K) = \text{Top-K}(\text{Softmax}(\frac{QK^T}{\sqrt{d}})) Sparse(Q,K)=Top-K(Softmax(dQKT))
这一机制强制将相关性较低的
N−k N-k N−k
个连接的权重置为绝对零度,从而在物理层面上切断通信链路,将复杂度从
O(N2) O(N^2) O(N2)
降低至
O(Nk) O(Nk) O(Nk)
。
2.2 信息瓶颈 (Information Bottleneck)
信息瓶颈(IB)方法不仅仅是筛选对象,更是压缩内容。其目标是最大化消息与任务的相关性(互信息
I(Z;Y) I(Z; Y) I(Z;Y)
),同时最小化消息与原始观测的冗余(互信息
I(Z;X) I(Z; X) I(Z;X)
)。这迫使智能体学习出高度抽象的“语言”,只传递对决策有用的最小比特数。
3. 信息筛选处理流水线
下图展示了从原始消息流输入,经过注意力语义筛选,最终通过带宽门控输出的完整处理逻辑。
Multi-Agent Attention Filtering Pipeline
│
├── 【输入数据流 (Input Data Stream)】
│ ├── 自身状态 (Self State): h_i (我当前的隐状态)
│ ├── 候选消息池 (Incoming Messages): {m_1, m_2, ..., m_N} 来自其他智能体
│ └── 环境约束 (Constraints): 当前可用带宽 B (例如:300kbps)
│
▼
[1. 语义编码阶段 (Semantic Encoding Phase)] ────────────────────┐
│ (由此模块总控: 🐍 attention_encoder.py) │
│ │
├── A. 查询生成 (Query Generation - "I Need") │
│ ├── <线性变换>: Q_i = W_q * h_i │
│ │ (语义: 将自身状态映射为 "需求向量") │
│ └── > 输出: Query Vector Q_i │
│ │
├── B. 键值生成 (Key-Value Generation - "I Have") │
│ ├── <处理>: 对每个候选消息 m_j 进行编码 │
│ ├── Key: K_j = W_k * m_j (用于匹配的特征) │
│ ├── Value: V_j = W_v * m_j (实际承载的信息内容) │
│ └── > 输出: Pairs {(K_1, V_1), ..., (K_N, V_N)} │
└── > 准备就绪: 进入匹配核心 ────────────────────────────────────┘
│
▼
[2. 相关性计算核心 (Relevance Calculation Kernel)] ──────────────┐
│ │
├── Step 1: 点积匹配 (Dot Product Matching) │
│ ├── 计算: Score_ij = (Q_i · K_j) / Scaling_Factor │
│ └── 物理含义: 衡量 "消息 j 是否解决了需求 i" │
│ │
├── Step 2: 多头并行 (Multi-Head Processing) │
│ ├── Head 1 (避障): 关注位置相关的 Keys │
│ ├── Head 2 (策略): 关注意图相关的 Keys │
│ └── > 融合: Concatenate(Head_1, ..., Head_H) │
└────────────────────────────────────────────────────────────────┘
│
▼
[3. 带宽门控与稀疏化 (Bandwidth Gating & Sparsification)] <★ 关键>
│ (由此模块总控: 🐍 sparsity_controller.py) │
│ │
├── <策略选择>: Check Bandwidth Mode │
│ ├── [模式 A] 充足带宽 -> 使用 Softmax (全通信) │
│ │ └── α_ij = exp(S_ij) / Σ exp(S_ik) │
│ │ │
│ └── [模式 B] 受限带宽 -> 使用 Top-K / Gumbel-Softmax │
│ ├── 排序: Sort(Scores) │
│ ├── 截断: 保留前 K 个,其余置为 -inf (Masking) │
│ ├── 稀疏化: α_ij = 0 (对于非 Top-K 邻居) │
│ └── > 效果: 物理链路切断,节省流量 │
└────────────────────────────────────────────────────────────────┘
│
▼
[4. 信息聚合与输出 (Aggregation & Output)] ──────────────────────┐
│ │
├── <加权求和>: Context_i = Σ (α_ij * V_j) │
├── <残差连接>: Output = Norm(Context_i + h_i) │
└── > 最终结果: 筛选后的高信噪比上下文向量 (Clean Context) │
└────────────────────────────────────────────────────────────────┘
4.最新研究进展
近年来,注意力机制在多智能体系统(MAS)中的应用已从简单的加权聚合向上下文感知、意图预测和大模型协同方向演进。以下是关键研究成果的深度技术拆解:
4.1 上下文感知通信 (CACOM)
- 痛点:传统通信往往广播全部观测,导致带宽浪费且噪声大。
- 注意力作用机制:CACOM 引入了**“先握手,后通信”**的两阶段注意力机制。
- Stage 1 (粗粒度):智能体广播低维的
Query向量,询问“谁有我需要的信息?” - Stage 2 (细粒度):接收方根据收到的
Query计算相关性,利用注意力权重对本地的高维观测进行加权裁剪,仅发送对方关注的特征片段。
- Stage 1 (粗粒度):智能体广播低维的
- 结果:实现了“按需传输”,在通信量减少 60% 的情况下保持了协作性能。
4.2 互补注意力机制 (CAMA)
- 痛点:在部分可观测环境(POMDP)中,盲区是协作的最大障碍。
- 注意力作用机制:CAMA 设计了**“视野补全”**逻辑。
- 实体分割:将观测图像分割为不同的实体对象。
- 互补关注:当智能体 A 的注意力机制检测到某个区域的不确定性(Entropy)较高时,它会自动提高对处于该区域的智能体 B 的消息权重。
- 结果:有效解决了遮挡问题,使团队具备了“共享上帝视角”的能力。
4.3 LLM 驱动的生成式通信
随着大语言模型(LLM)的发展,研究人员开始探索LLM在多智能体系统中的应用。2025年的研究表明,基于LLM的智能体可以通过非结构化文本进行通信,而注意力机制可以帮助智能体从大量文本信息中提取关键内容。标准化通信协议和验证机制成为当前研究的热点。
主要研究成果汇总如下:
| 方法名称 | 发表年份 | 核心贡献 |
|---|---|---|
| CACOM | 2023 | 上下文感知两阶段通信 |
| CAMA | 2023 | 互补注意力解决部分可观测 |
| MAGIC | 2021 | 图注意力动态通信拓扑 |
| Intention Sharing | 2021 | 意图共享增强协调 |
| IMAC | 2020 | 信息瓶颈带宽优化 |
- 趋势:基于大语言模型(LLM)的智能体(如 Generative Agents)正在改变通信协议。
- 注意力作用机制:
- 文本级注意力:Transformer 的 Self-Attention 直接用于处理自然语言消息历史,提取关键指令。
- 思维链选择:在生成回复时,注意力机制帮助智能体从记忆库(Memory Bank)中检索最相关的过往经验,形成连贯的协作策略。
- 标准化:目前的焦点在于设计标准化的 Prompt 协议,使不同角色的 Agent 能通过文本高效协商。
5. 多智能体通信系统推理流水线 (Inference Pipeline)
单纯的代码片段难以展示多智能体系统的动态交互过程。下图采用系统工程视角,展示了在通过 PyTorch 实现时,数据如何在环境、智能体编码器和注意力路由器之间流转的完整生命周期。
Multi-Agent Attention Communication Inference Pipeline
│
├── 【环境状态输入 (Environment State)】
│ ├── 全局状态: Global State (用于 Critic 训练)
│ ├── 局部观测: [Obs_1, Obs_2, ..., Obs_N] (每个智能体独立视角)
│ └── 拓扑约束: 通信图结构 (Adjacency Matrix)
│
▼
[1. 分布式感知与编码 (Distributed Perception)] ──────────────────┐
│ (由此模块总控: 🐍 agent_manager.py) │
│ │
├── A. 独立特征提取 (Local Encoding) │
│ ├── <输入>: Batch of Observations (N, Obs_Dim) │
│ ├── <网络>: Shared MLP / CNN Encoder │
│ │ (作用: 将图像/雷达数据压缩为隐状态 h_i) │
│ └── > 输出: Hidden States H = {h_1, ..., h_N} │
│ │
├── B. 消息预处理 (Message Pre-processing) │
│ ├── <生成 Query>: Q_i = Linear_Q(h_i) (我想要什么?) │
│ ├── <生成 Key>: K_i = Linear_K(h_i) (我有什么特征?) │
│ └── <生成 Value>: V_i = Linear_V(h_i) (我的具体数据) │
└── > 准备就绪: 进入通信交互阶段 ────────────────────────────────┘
│
▼
[2. 注意力通信交互核心 (Attention Communication Core)] ──────────┐
│ (由此模块总控: 🐍 attention_comm_layer.py) │
│ (对应代码示例 1 & 3: MultiHead / GAT) │
│ │
├── Step 1: 动态握手与构图 (Handshake & Graphing) │
│ ├── 全连接模式: 假设所有 Agent 彼此可见 │
│ └── 稀疏模式 (Top-K): │
│ ├── 计算初步分数: S_raw = Q * K^T │
│ ├── 剪枝: 仅保留 Top-3 邻居,其余 Mask 掉 │
│ └── > 输出: 稀疏通信图 (Sparse Graph) │
│ │
├── Step 2: 权重计算 (Attention Weighting) │
│ ├── <公式>: α_ij = Softmax( (Q_i * K_j^T) / √d ) │
│ │ (物理含义: Agent i 对 Agent j 的信任度/依赖度) │
│ └── 可视化: 记录 Attention Map 用于可解释性分析 │
│ │
├── Step 3: 消息聚合 (Message Aggregation) │
│ ├── <操作>: Comm_Msg_i = Σ (α_ij * V_j) │
│ └── > 输出: 上下文向量 Context_i (包含了筛选后的队友信息) │
└────────────────────────────────────────────────────────────────┘
│
▼
[3. 决策与执行阶段 (Decision & Execution)] ──────────────────────┐
│ (由此模块总控: 🐍 policy_network.py) │
│ │
├── <状态融合>: Fusion_State_i = Concat(h_i, Comm_Msg_i) │
│ (结合 "自身观测" + "通信上下文") │
│ │
├── <策略网络>: Actor (PPO / DQN Head) │
│ ├── 输入: Fusion_State_i │
│ └── 输出: Logits -> Categorical Distribution │
│ │
├── <动作采样>: Action Sampling │
│ ├── 训练模式: Categorical.sample() (探索) │
│ ├── 推理模式: argmax(Logits) (利用) │
│ └── > 最终动作: [Action_1, ..., Action_N] │
└────────────────────────────────────────────────────────────────┘
│
▼
[4. 环境反馈与循环 (Feedback Loop)] ─────────────────────────────┐
│ ├── 执行动作 -> 获取 Reward & Next_Obs │
│ └── 存储轨迹 -> Replay Buffer (用于训练更新) │
└────────────────────────────────────────────────────────────────┘
6.代码实现示例
以下提供基于PyTorch的多智能体注意力通信模块实现示例。这些代码展示了如何将理论转化为实际可用的系统组件。
示例1:基础多头注意力通信模块
该示例实现了基于Transformer的多头注意力通信机制,支持动态注意力权重计算和消息生成:
此图展示了数据如何从原始观测被编码、分流为 Q/K/V,并最终聚合成通信消息的全过程。
Plaintext
Multi-Agent Transformer Communication Pipeline
│
├── 【输入数据 (Input Data)】
│ ├── 观测张量: observations [Batch, N_Agents, Obs_Dim]
│ └── (可选) 掩码: agent_masks (处理死亡/不存在的智能体)
│
▼
[1. 感知编码阶段 (Observation Encoding)] ────────────────────────┐
│ (对应代码: self.obs_encoder) │
│ │
├── <线性映射>: Linear(obs_dim -> hidden_dim) │
│ ├── 激活函数: ReLU() │
│ └── 再次映射: Linear(hidden_dim -> hidden_dim) │
│ │
└── > 输出: Encoded Obs [Batch, N, Hidden_Dim] ──────────────────┘
│
▼
[2. 注意力核心计算 (Attention Mechanism)] <★ QKV 机制> ───────────┐
│ (对应代码: self.W_q, W_k, W_v) │
│ │
├── Step 1: 投影变换 (Projection) │
│ ├── 生成 Query (Q): encoded_obs * W_q │
│ ├── 生成 Key (K): encoded_obs * W_k │
│ └── 生成 Value (V): encoded_obs * W_v │
│ │
├── Step 2: 相似度计算 (Score Calculation) │
│ ├── <矩阵乘法>: torch.matmul(Q, K.transpose) │
│ │ (物理含义: 计算智能体之间的相关性/关注度) │
│ └── <缩放>: div(sqrt(d_k)) (防止梯度消失) │
│ │
├── Step 3: 归一化 (Normalization) │
│ └── <函数>: F.softmax(dim=-1) │
│ └── > 产出: Attention Weights (α_ij) │
└────────────────────────────────────────────────────────────────┘
│
▼
[3. 消息聚合与生成 (Message Aggregation)] ───────────────────────┐
│ │
├── <加权求和>: torch.matmul(weights, V) │
│ (作用: 根据关注度聚合邻居信息) │
│ │
├── <输出投影>: self.output_proj │
│ (作用: 将聚合特征映射为最终消息维度 Msg_Dim) │
│ │
└── > 最终输出: Messages [Batch, N, Msg_Dim] ────────────────────┘
class MultiAgentAttentionComm(nn.Module):
def __init__(self, obs_dim, msg_dim, n_heads=4, hidden_dim=128):
super().__init__()
self.obs_encoder = nn.Sequential(
nn.Linear(obs_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim)
)
self.W_q = nn.Linear(hidden_dim, hidden_dim)
self.W_k = nn.Linear(hidden_dim, hidden_dim)
self.W_v = nn.Linear(hidden_dim, hidden_dim)
self.output_proj = nn.Linear(hidden_dim, msg_dim)
def forward(self, observations, agent_masks=None):
\# 编码观测
encoded_obs = self.obs_encoder(observations)
\# 生成Q, K, V
Q = self.W_q(encoded_obs)
K = self.W_k(encoded_obs)
V = self.W_v(encoded_obs)
\# 计算注意力分数
scores = torch.matmul(Q, K.transpose(-2, -1)) / sqrt(head_dim)
attention_weights = F.softmax(scores, dim=-1)
\# 加权聚合
attended = torch.matmul(attention_weights, V)
messages = self.output_proj(attended)
return messages, attention_weights
示例2:稀疏注意力与带宽感知通信
该示例实现了基于Top-K选择的稀疏注意力机制,以及根据带宽状况动态调整通信策略的调度器:
此图重点展示了Top-K 稀疏化逻辑以及带宽感知调度器的分支判断逻辑。
Plaintext
Sparse Attention & Bandwidth Scheduling Pipeline
│
├── 【前置输入 (Pre-calculated Inputs)】
│ ├── Q, K, V 张量 (来自上游编码器)
│ └── 环境状态: Current_Bandwidth (当前网络状况)
│
▼
[1. 稀疏注意力过滤 (Sparse Attention Logic)] ────────────────────┐
│ (对应代码: Class SparseAttentionComm) │
│ │
├── Step 1: 原始分数计算 │
│ └── Scores = (Q * K^T) / √d │
│ │
├── Step 2: Top-K 关键筛选 <★ 稀疏化核心> │
│ ├── <操作>: torch.topk(scores, k=3) │
│ │ (含义: 只保留关联度最高的 3 个邻居) │
│ ├── <掩码生成>: sparse_mask.scatter_ │
│ │ (逻辑: 非 Top-K 位置置为 0,Top-K 位置置为 1) │
│ └── <应用掩码>: masked_fill(mask==0, -inf) │
│ (效果: Softmax 后非 Top-K 权重归零,切断通信) │
│ │
└── > 输出: Sparse Aggregated Output ────────────────────────────┘
│
▼
[2. 带宽感知调度器 (Bandwidth Aware Scheduler)] ─────────────────┐
│ (对应代码: Class BandwidthAwareScheduler) │
│ │
├── <状态判断>: Check Bandwidth Ratio │
│ └── logic: ratio = current / max │
│ │
├── 🔀 分支决策 (Decision Branch): │
│ ├── [Case A: 宽带充足 (Ratio >= 0.3)] │
│ │ └── 动作: 直接透传 (Pass through) │
│ │ │
│ └── [Case B: 带宽受限 (Ratio < 0.3)] │
│ ├── 动作 1: 压缩消息 (self.message_compressor) │
│ ├── 动作 2: 重要性门控 (msg_importance > 0.7) │
│ └── > 结果: 高压缩比 + 丢弃低价值包 │
│ │
└── > 最终发送: Processed Messages & Ratio ──────────────────────┘
class SparseAttentionComm(nn.Module):
def sparse_attention(self, Q, K, V, k=3):
scores = torch.matmul(Q, K.transpose(-2, -1)) / sqrt(H)
\# Top-K稀疏化
topk_values, topk_indices = torch.topk(scores, k, dim=-1)
sparse_mask = torch.zeros_like(scores)
sparse_mask.scatter_(-1, topk_indices, 1.0)
\# 应用掩码并归一化
masked_scores = scores.masked_fill(sparse_mask == 0, -inf)
attention_weights = F.softmax(masked_scores, dim=-1)
output = torch.matmul(attention_weights, V)
return output, sparse_mask
class BandwidthAwareScheduler(nn.Module):
def forward(self, messages, current_bandwidth):
bandwidth_ratio = current_bandwidth / self.max_bandwidth
if bandwidth_ratio < 0.3:
\# 低带宽:高压缩
compressed = self.message_compressor(messages)
send_mask = (msg_importance > 0.7).float()
else:
processed = messages
return processed, compression_ratio
示例3:图注意力网络实现
该示例展示了图注意力网络在多智能体通信中的应用,包括动态邻接矩阵学习:
此图突出了 GAT 特有的邻接矩阵掩码处理和 LeakyReLU 激活机制。
Plaintext
Graph Attention Network (GAT) Pipeline
│
├── 【图结构输入 (Graph Input)】
│ ├── 节点特征: h [Batch, N, In_Features]
│ └── 邻接矩阵: adj [Batch, N, N] (定义了谁和谁相连)
│
▼
[1. 特征变换 (Feature Transformation)] ──────────────────────────┐
│ (对应代码: self.W) │
│ │
├── <线性层>: Wh = Linear(h) │
│ (作用: 将节点特征映射到高维空间,准备拼接) │
└── > 中间态: Transformed Features (Wh) │
│
▼
[2. 注意力系数计算 (Attention Coefficients)] <★ GAT 核心> ───────┐
│ (对应代码: self.a, LeakyReLU) │
│ │
├── Step 1: 特征拼接与映射 │
│ ├── 逻辑: [Wh_i || Wh_j] (隐式广播拼接) │
│ └── 投影: matmul(concatenated, self.a) │
│ (self.a 是可学习的权重向量 2*Out_Features) │
│ │
├── Step 2: 非线性激活 │
│ └── <激活函数>: LeakyReLU (保留负梯度信息) │
│ └── > 产出: 原始分数 e_ij │
│ │
├── Step 3: 结构掩码 (Structural Masking) │
│ ├── 判断: if adj is not None │
│ └── 动作: e.masked_fill(adj == 0, -inf) │
│ (物理含义: 仅计算图中实际存在的边的注意力) │
└────────────────────────────────────────────────────────────────┘
│
▼
[3. 状态更新 (State Update)] ────────────────────────────────────┐
│ │
├── <归一化>: F.softmax(e, dim=-1) -> Attention Alpha │
├── <邻居聚合>: h_prime = matmul(attention, Wh) │
└── > 层输出: New Node Features h' ──────────────────────────────┘
class GraphAttentionLayer(nn.Module):
def __init__(self, in_features, out_features):
self.W = nn.Linear(in_features, out_features)
self.a = nn.Parameter(torch.zeros(2 * out_features, 1))
def forward(self, h, adj=None):
Wh = self.W(h)
\# 计算注意力分数 e_ij
a_input = self._prepare_attention_input(Wh)
e = self.leakyrelu(torch.matmul(a_input, self.a))
\# 应用邻接矩阵掩码
if adj is not None:
e = e.masked_fill(adj == 0, -inf)
attention = F.softmax(e, dim=-1)
h_prime = torch.matmul(attention, Wh)
return h_prime, attention
完整的代码实现已随文档提供,包含详细的注释和使用示例。读者可以根据具体应用场景进行修改和扩展。
三、应用场景深度解析与未来展望
1. 核心应用场景技术拆解
注意力机制将多智能体系统(MAS)从“广播式盲目通信”升级为“针对性语义交互”,在以下关键领域产生了质的飞跃:
1.1 自动驾驶车队协同 (V2X Platooning)
- 技术痛点:在高速移动场景下,通信带宽极其有限(通常 < 20 Mbps),且存在丢包风险。如果每辆车都向所有邻居广播全量传感器数据,网络瞬间瘫痪。
- 注意力解决方案:
- 空间注意力:车辆仅关注位于自身“规划轨迹”上的前车和侧向变道车辆,自动忽略对向车道或远处的车辆。
- 语义优先级:紧急制动信号(High Priority)的注意力权重被强制置顶,而普通的娱乐系统状态信息被抑制。
- 效能提升:在拥堵路段将关键信息的传输延迟降低了 45%,碰撞风险预测准确率提升 30%。
1.2 智能仓储与物流 (Swarm Robotics)
- 技术痛点:数百台 AGV 机器人在狭窄空间内穿梭,死锁(Deadlock)和路径冲突是常态。
- 注意力解决方案:
- 意图共享:机器人通过注意力机制广播自己的“未来 3 秒路径”,邻居机器人根据相关性计算避让策略。
- 动态成组:当多个机器人执行同一个搬运任务时,注意力机制会自动形成一个高权重的“临时通信组”,组内信息全通,组外信息屏蔽。
- 效能提升:系统整体吞吐量(Throughput)提升 25%,因通信冲突导致的停机时间减少 60%。
1.3 分布式战术博弈 (RTS AI)
- 技术痛点:在《星际争霸 II》等游戏中,单位数量庞大,且存在战争迷雾(Fog of War)。
- 注意力解决方案:
- 分层注意力:宏观层面(Macro)关注资源点和兵力分布,微观层面(Micro)关注集火攻击敌方残血单位。
- 实体掩码:利用 Hard Attention 直接过滤掉迷雾中的不可见单位,防止幻觉决策。
- 效能提升:AlphaStar 等系统证明,基于注意力的多智能体协作能达到人类职业选手的微操水平。
2. 多智能体系统全生命周期执行流程 (Full-Lifecycle Pipeline)
下图展示了在实际工业部署中,一个基于注意力机制的智能体从环境感知到协作决策的完整数据流转过程。
Multi-Agent Attention System Execution Pipeline
│
├── 【环境交互层 (Environment Interaction)】
│ ├── 物理世界: 传感器数据流 (Lidar, Camera, GPS)
│ ├── 网络环境: 动态带宽约束 (4G/5G/WiFi-6)
│ └── 任务目标: 协同导航 / 联合捕获 / 资源调度
│
▼
[1. 局部感知与特征提取 (Local Perception Phase)] ───────────────┐
│ (由此模块总控: 🐍 perception_module.py) │
│ │
├── A. 多模态编码 (Multi-modal Encoding) │
│ ├── <视觉流>: CNN 处理图像 -> 提取障碍物特征 │
│ ├── <状态流>: MLP 处理自身状态 -> 提取速度/位置 │
│ └── > 融合: Generate Local Embedding (h_i) │
│ │
├── B. 意图预判 (Intent Prediction) │
│ ├── <动作>: 预测自身未来 N 步的轨迹 │
│ └── > 输出: Intent Vector (用于通信的 Key) │
└── > 准备就绪: 进入通信调度层 ──────────────────────────────────┘
│
▼
[2. 注意力通信调度层 (Attention Communication Layer)] <★ 核心> ──┐
│ (由此模块总控: 🐍 comm_scheduler.py) │
│ │
├── Step 1: 握手与构图 (Handshake & Graphing) │
│ ├── 广播: 发送轻量级 Query/Key │
│ ├── 计算: Relevance Score = Q * K^T │
│ └── 拓扑: 基于分数构建动态通信图 (Dynamic Graph) │
│ │
├── Step 2: 消息压缩与筛选 (Compression & Filtering) │
│ ├── <带宽检测>: Check Current Bandwidth │
│ ├── <稀疏化>: Top-K 截断 (只发给最重要的 3 个邻居) │
│ └── <压缩>: 使用 VAE 将消息压缩为由 128bit 组成的包 │
│ │
├── Step 3: 消息分发 (Distribution) │
│ └── 动作: Send(Packed_Msg) -> Network -> Receive(Neighbors) │
└────────────────────────────────────────────────────────────────┘
│
▼
[3. 决策推理与执行 (Reasoning & Actuation)] ─────────────────────┐
│ (由此模块总控: 🐍 policy_engine.py) │
│ │
├── <上下文聚合>: Attention_Block(Local_h, Neighbor_Msgs) │
│ (作用: 融合队友信息,消除盲区) │
│ │
├── <联合决策>: Policy_Net(Fused_State) │
│ ├── 动作头: 输出控制指令 (转向/加速) │
│ ├── 价值头: 评估当前局势胜率 (V-Value) │
│ └── > 输出: Final Action Command │
│ │
├── <安全校验>: Safety Guardrail │
│ ├── 规则: 检查动作是否违反物理限制 (如碰撞检测) │
│ └── 修正: Override unsafe actions │
└────────────────────────────────────────────────────────────────┘
│
▼
[4. 闭环反馈 (Feedback Loop)] ───────────────────────────────────┐
│ ├── 执行动作 -> 物理环境发生改变 │
│ └── 获取奖励 -> 更新经验池 (Replay Buffer) │
└────────────────────────────────────────────────────────────────┘
3. 未来展望 (Future Directions)
-
可解释性 (Explainability):从“黑盒”注意力权重转向语义化的解释(例如:智能体明确报告“我关注 Agent 3 是因为它距离我最近且速度异常”)。
-
大模型驱动 (LLM-Driven):利用 LLM 的常识推理能力,让智能体通过自然语言进行少样本(Few-Shot)协作,无需从零训练。
-
异构系统融合:实现无人机(UAV)与地面机器人(UGV)等不同架构智能体之间的零样本通信。
│
│ └── > 输出: Final Action Command │
│ │
├── <安全校验>: Safety Guardrail │
│ ├── 规则: 检查动作是否违反物理限制 (如碰撞检测) │
│ └── 修正: Override unsafe actions │
└────────────────────────────────────────────────────────────────┘
│
▼
[4. 闭环反馈 (Feedback Loop)] ───────────────────────────────────┐
│ ├── 执行动作 -> 物理环境发生改变 │
│ └── 获取奖励 -> 更新经验池 (Replay Buffer) │
└────────────────────────────────────────────────────────────────┘
------
## 3. 未来展望 (Future Directions)
1. **可解释性 (Explainability)**:从“黑盒”注意力权重转向语义化的解释(例如:智能体明确报告“我关注 Agent 3 是因为它距离我最近且速度异常”)。
2. **大模型驱动 (LLM-Driven)**:利用 LLM 的常识推理能力,让智能体通过自然语言进行少样本(Few-Shot)协作,无需从零训练。
3. **异构系统融合**:实现无人机(UAV)与地面机器人(UGV)等不同架构智能体之间的零样本通信。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 16
16 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)